
Lernpfad
Microsoft Azure Grundlagen (AZ-900)
9 Std.
Azure Data Factory (ADF) ist ein Cloud-basierter Datenintegrationsdienst von Microsoft Azure.
Da datengestützte Entscheidungen immer wichtiger für den Geschäftsbetrieb werden, ist die Nachfrage nach Cloud-basierten Datenverarbeitungstools so hoch wie nie zuvor! Weil ADF ein top Service ist, suchen Firmen immer öfter nach Datenprofis mit praktischer Erfahrung, die ihre Datenpipelines verwalten und ihre Systeme zusammenführen können.
In diesem Artikel wollen wir angehende ADF-Profis mit den wichtigsten Fragen und Antworten für Vorstellungsgespräche zu Azure Data Factory unterstützen – mit allgemeinen, technischen, fortgeschrittenen und szenariobasierten Fragen – und dabei Tipps geben, wie man das Vorstellungsgespräch meistert.
Azure Data Factory ist ein Cloud-basierter ETL-Dienst, mit dem du datengesteuerte Workflows erstellen kannst, um die Datenübertragung und -transformation zu organisieren und zu automatisieren. Der Service lässt sich mit verschiedenen Datenquellen und -zielen vor Ort und in der Cloud verbinden.
Da Teams immer mehr auf Cloud-native Infrastrukturen umsteigen, wird es immer wichtiger, Daten über verschiedene Umgebungen hinweg zu verwalten. Die Integration von ADF in das Azure-Ökosystem und Datenquellen von Drittanbietern macht das einfacher, sodass Fachwissen über den Dienst bei Unternehmen echt gefragt ist.
Automatisierte BI-Architektur mit Azure Data Factory. Bildquelle: Microsoft
In diesem Abschnitt schauen wir uns grundlegende Fragen an, die oft in Interviews gestellt werden, um dein Allgemeinwissen über ADF zu checken. Diese Fragen prüfen dein Verständnis von grundlegenden Konzepten, Architektur und Komponenten.
Beschreibung: Diese Frage wird oft gestellt, um zu sehen, ob du die Grundlagen von ADF verstehst.
Beispielantwort: Die Hauptkomponenten von Azure Data Factory sind:
Beschreibung: Diese Frage testet dein Verständnis davon, wie Azure Data Factory die sichere und effiziente Übertragung hybrider Daten ermöglicht.
Beispielantwort: Azure Data Factory macht es möglich, Daten sicher zwischen Cloud- und lokalen Umgebungen zu verschieben. Das geht über die selbst gehostete Integrationslaufzeit (IR), die als Brücke zwischen ADF und lokalen Datenquellen fungiert.
Wenn du zum Beispiel Daten von einem lokalen SQL Server in den Azure Blob Storage verschiebst, verbindet sich der selbst gehostete IR sicher mit dem lokalen System. Dadurch kann ADF Daten übertragen und gleichzeitig die Sicherheit durch Verschlüsselung während der Übertragung und im Ruhezustand gewährleisten. Das ist besonders praktisch für Hybrid-Cloud-Szenarien, wo die Daten auf lokale und Cloud-Infrastrukturen verteilt sind.
Beschreibung: Diese Frage checkt, wie gut du verstehst, wie ADF Pipelines mit verschiedenen Triggertypen automatisiert und plant.
Beispielantwort: In Azure Data Factory werden Trigger benutzt, um Pipeline-Ausführungen automatisch zu starten, je nachdem, welche Bedingungen erfüllt sind oder nach einem bestimmten Zeitplan. Es gibt drei Haupttypen von Triggern:
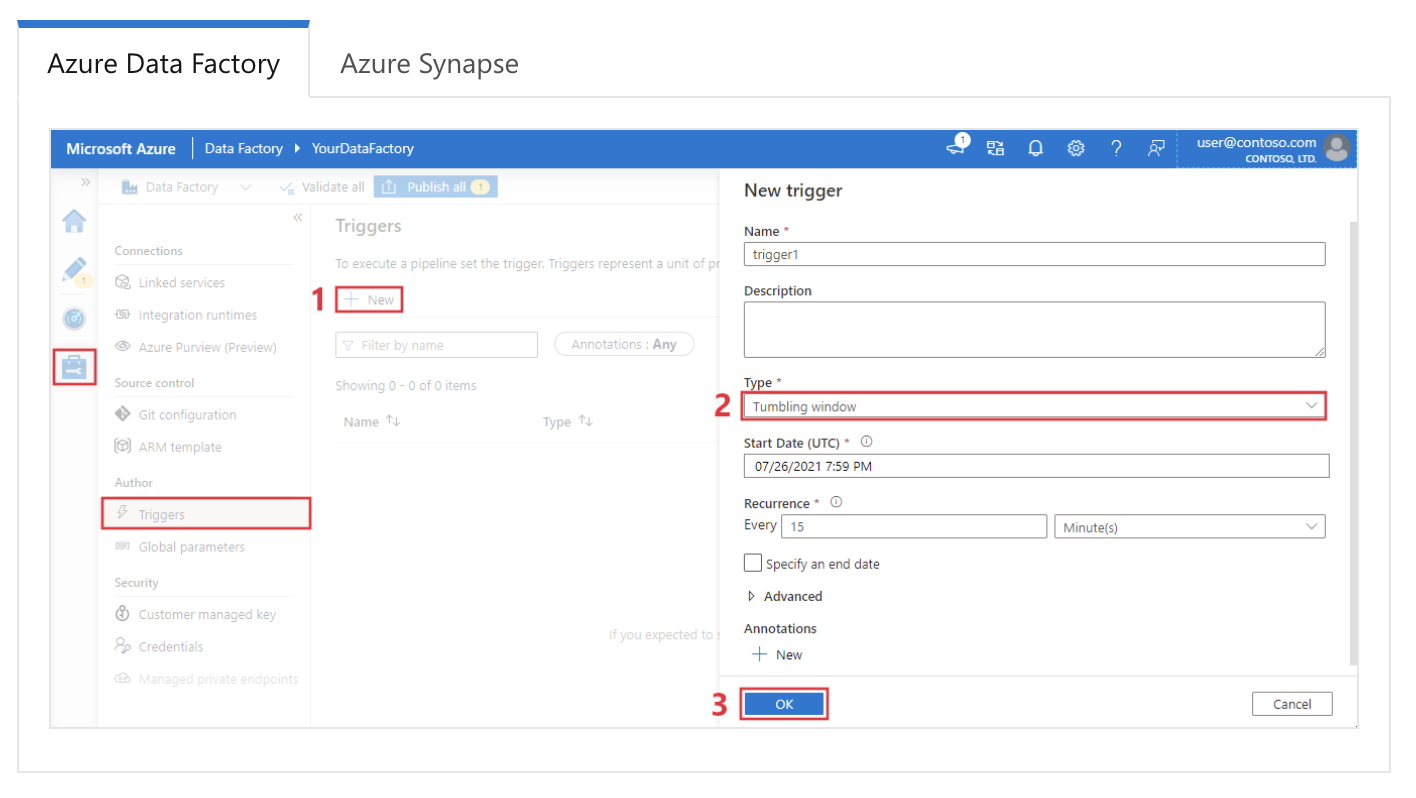
Einrichten eines Triggers für ein gleitendes Fenster in Azure Data Factory. Bildquelle: Microsoft.
Beschreibung: Diese Frage checkt, wie gut du die verschiedenen Aufgaben kennst, die ADF-Pipelines machen können.
Beispielantwort: Azure Data Factory-Pipelines können verschiedene Arten von Aktivitäten machen. Das sind die häufigsten:
|
Art der Aktivität |
Beschreibung |
|
Datenbewegung |
Verschiebt Daten zwischen unterstützten Datenspeichern (z. B. Azure Blob Storage, SQL-Datenbank) mit der Kopieraktivität. |
|
Datenumwandlung |
Enthält Datenflussaktivitäten für die Datenumwandlungslogik mit Spark, Mapping-Datenflüsse für ETL-Operationen und Wrangling-Datenflüsse für die Datenvorbereitung. |
|
Kontrollfluss |
Bietet Kontrolle über die Pipeline-Ausführung mithilfe von Aktivitäten wie „ForEach“, „If Condition“, „Switch“, „Wait“ und „Until“, um bedingte Logik zu erstellen. |
|
Externe Ausführung |
Führt externe Anwendungen oder Funktionen aus, darunter Azure Functions, Webaktivitäten (Aufruf von REST-APIs) und gespeicherte Prozeduraktivitäten für SQL. |
|
Benutzerdefinierte Aktivitäten |
Ermöglicht die Ausführung von benutzerdefiniertem Code in benutzerdefinierten Aktivitäten mithilfe von .NET- oder Azure Batch-Diensten und bietet so Flexibilität für anspruchsvolle Datenverarbeitungsanforderungen. |
|
Andere Dienstleistungen |
Unterstützt HDInsight-, Databricks- und Data Lake Analytics-Aktivitäten, die sich mit anderen Azure-Analysediensten für komplexe Datenaufgaben verbinden lassen. |
Beschreibung: Diese Frage testet, wie gut du dich mit den Überwachungs- und Debugging-Tools von ADF auskennst.
Beispielantwort: Azure Data Factory hat eine coole Schnittstelle zum Überwachen und Debuggen über die Registerkarte „Überwachen“ im Azure-Portal. Hier kann ich Pipeline-Läufe verfolgen, Aktivitätsstatus anzeigen und Fehler diagnostizieren. Jede Aktivität erzeugt Protokolle, die man sich ansehen kann, um Fehler zu finden und Probleme zu beheben.
Außerdem kann Azure Monitor so eingestellt werden, dass es bei Pipeline-Fehlern oder Performance-Problemen Warnungen verschickt. Zum Debuggen schaue ich mir normalerweise zuerst die Protokolle für fehlgeschlagene Aktivitäten an, überprüfe die Fehlerdetails und führe die Pipeline nach Behebung des Problems erneut aus.
Beschreibung: Diese Frage prüft, ob du über die neuesten Entwicklungen der Datenplattform von Microsoft auf dem Laufenden bist.
Beispielantwort: Obwohl beide die gleiche Engine nutzen, ist Data Factory in Fabric ein SaaS-Angebot (Software as a Service), das in das Fabric-Ökosystem eingebunden ist, während Azure Data Factory (ADF) eine PaaS-Ressource (Platform as a Service) ist. Die wichtigsten Unterschiede sind:
Beschreibung: Diese Frage testet dein Wissen über die Sicherheitsmechanismen von ADF zum Schutz von Daten während ihres gesamten Lebenszyklus.
Beispielantwort: Azure Data Factory sorgt mit verschiedenen Mechanismen für Datensicherheit.
Zuerst verschlüsselt es Daten, egal ob sie gerade übertragen werden oder gespeichert sind, und nutzt dabei Protokolle wie TLS und AES, um die Datenübertragung sicher zu machen. ADF ist mit Azure Active Directory (AAD) für die Authentifizierung verbunden und nutzt die rollenbasierte Zugriffskontrolle (RBAC), um zu regeln, wer auf die Fabrik zugreifen und sie verwalten darf.
Außerdem können verwaltete Identitäten ADF dabei helfen, sicher auf andere Azure-Dienste zuzugreifen, ohne dass Anmeldedaten offengelegt werden müssen. Für die Netzwerksicherheit unterstützt ADF private Endpunkte, damit der Datenverkehr im Azure-Netzwerk bleibt und eine zusätzliche Schutzschicht hinzukommt.
Beschreibung: Diese Frage checkt, ob du verstehst, welche unterschiedlichen Rollen Linked Services und Datasets in ADF haben.
Beispielantwort: In Azure Data Factory macht ein Linked Service die Verbindung zu einer externen Datenquelle oder einem Rechendienst klar, ähnlich wie eine Verbindungszeichenfolge. Es enthält die Authentifizierungsinfos, die du brauchst, um dich mit der Ressource zu verbinden.
Ein Datensatz hingegen ist die konkrete Datenmenge, mit der du arbeiten wirst, wie zum Beispiel eine Tabelle in einer Datenbank oder eine Datei im Blob Storage.
Während der verknüpfte Dienst sagt, wo die Daten sind, beschreibt der Datensatz, wie sie aussehen und wie sie aufgebaut sind. Diese beiden Teile arbeiten zusammen, um den Datenaustausch und die Datenumwandlung zu vereinfachen.
Technische Interviewfragen drehen sich oft darum, wie gut du bestimmte Funktionen verstehst, wie sie umgesetzt werden und wie sie zusammenwirken, um effektive Datenpipelines aufzubauen. Diese Fragen checken deine praktische Erfahrung und dein Wissen über die Kernkomponenten und Funktionen von ADF.
Beschreibung: Diese Frage testet deine Fähigkeit, Strategien zur Fehlerbehandlung in ADF-Pipelines umzusetzen.
Beispielantwort: Die Fehlerbehandlung in Azure Data Factory kann mithilfe von Wiederholungsrichtlinien und Fehlerbehandlungsaktivitäten gemacht werden. ADF hat eingebaute Wiederholungsmechanismen, bei denen du die Anzahl der Wiederholungsversuche und das Intervall zwischen den Wiederholungsversuchen einstellen kannst, wenn eine Aktivität nicht klappt.
Wenn zum Beispiel eine Kopieraktivität wegen eines vorübergehenden Netzwerkproblems nicht klappt, kannst du die Aktivität so einstellen, dass sie es dreimal mit jeweils 10 Minuten Pause zwischen den Versuchen noch mal versucht.
Außerdem können Bedingungen für die Abhängigkeit von Aktivitäten wie „Fehler“, „Abgeschlossen“ und „Übersprungen“ bestimmte Aktionen auslösen, je nachdem, ob eine Aktivität klappt oder nicht.
Ich könnte zum Beispiel einen Pipeline-Ablauf so einrichten, dass bei einem Fehler einer Aktivität eine benutzerdefinierte Fehlerbehandlungsaktivität, wie das Senden einer Warnung oder das Ausführen eines Fallback-Prozesses, passiert.
Beschreibung: Diese Frage checkt, wie gut du die Computerinfrastruktur hinter der Datenübertragung und der Aktivitätsverteilung in ADF verstehst.
Beispielantwort: Die Integration Runtime (IR) ist die Recheninfrastruktur, die Azure Data Factory für die Datenübertragung, -transformation und -verteilung nutzt. Es ist super wichtig, um zu regeln, wie und wo Daten verarbeitet werden, und kann je nach Quelle, Ziel und Transformationsanforderungen optimiert werden. Für mehr Kontext: Es gibt drei Arten von IR:
|
Integration Runtime (IR)-Typ |
Beschreibung |
|
Azure-Integrationslaufzeit |
Wird für Datenbewegungen und -transformationen in Azure-Rechenzentren genutzt. Es unterstützt Kopiervorgänge, Datenflusstransformationen und leitet Aktivitäten an Azure-Ressourcen weiter. |
|
Selbst gehostete Integrationslaufzeit |
Installiert auf lokalen oder virtuellen Maschinen in einem privaten Netzwerk, um die Datenintegration zwischen lokalen, privaten und Azure-Ressourcen zu ermöglichen. Nützlich, um Daten von lokal auf Azure zu kopieren. |
|
Azure-SSIS-Integrationslaufzeit |
Damit kannst du deine vorhandenen SQL Server Integration Services (SSIS)-Pakete in Azure verschieben und dort ausführen, wobei die Ausführung von SSIS-Paketen nativ in Azure Data Factory unterstützt wird. Perfekt für Leute, die SSIS-Workloads ohne viel Aufwand migrieren wollen. |
Beschreibung: Diese Frage testet, ob du verstehst, wie die Parametrisierung in ADF funktioniert, um wiederverwendbare und flexible Pipelines zu erstellen.
Beispielantwort: Die Parametrisierung in Azure Data Factory ermöglicht eine dynamische Pipeline-Ausführung, bei der du bei jedem Durchlauf verschiedene Werte übergeben kannst.
In einer Kopieraktivität könnte ich zum Beispiel Parameter verwenden, um den Pfad der Quelldatei und den Zielordner dynamisch festzulegen. Ich würde die Parameter auf Pipeline-Ebene festlegen und sie an den entsprechenden Datensatz oder die entsprechende Aktivität weitergeben.
Hier ist ein einfaches Beispiel:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Durch die Parametrisierung kann man Pipelines wiederverwenden und einfach skalieren, indem man die Eingaben während der Laufzeit dynamisch anpasst.
Beschreibung: Diese Frage testet dein Wissen über die Datenumwandlung in ADF, ohne dass du externe Rechendienste brauchst.
Beispielantwort: Mit einem Mapping-Datenfluss in Azure Data Factory kannst du Daten umwandeln, ohne Code schreiben oder Daten außerhalb des ADF-Ökosystems verschieben zu müssen. Es bietet eine visuelle Oberfläche, auf der du komplexe Transformationen erstellen kannst.
Die Datenflüsse laufen auf Spark-Clustern in der verwalteten Umgebung von ADF ab, was skalierbare und effiziente Datenumwandlungen ermöglicht.
In einem typischen Transformationsszenario könnte ich zum Beispiel einen Datenfluss nutzen, um zwei Datensätze zusammenzuführen, die Ergebnisse zu aggregieren und die Ausgabe an einen neuen Speicherort zu schreiben – alles visuell und ohne externe Dienste wie Databricks.
Beschreibung: Diese Frage testet, wie du mit dynamischen Schemaänderungen während der Datenumwandlung umgehen kannst.
Beispielantwort: Schema Drift ist, wenn sich die Struktur der Quelldaten mit der Zeit verändert.
Azure Data Factory geht mit Schemaabweichungen um, indem es die Option „Schemaabweichung zulassen” in „Datenflüsse zuordnen” anbietet. Dadurch kann sich ADF automatisch an Änderungen im Schema der eingehenden Daten anpassen, wie zum Beispiel das Hinzufügen oder Entfernen neuer Spalten, ohne das ganze Schema neu definieren zu müssen.
Wenn ich Schema-Drift aktiviere, kann ich eine Pipeline so einrichten, dass Spalten dynamisch zugeordnet werden, auch wenn sich das Quellschema ändert.
Schema-Drift-Option in Azure Data Factory zulassen. Bildquelle: Microsoft
Beschreibung: Diese Frage checkt, wie gut du dich mit modernen Methoden der kontinuierlichen Datenerfassung im Vergleich zur Stapelverarbeitung auskennst.
Beispielantwort: Die CDC-Ressource in ADF bietet eine Low-Code-Möglichkeit, um geänderte Daten aus Quellen (wie einer SQL- oder Cosmos-Datenbank) ohne komplizierte Wasserzeichenlogik immer wieder an einen Zielort zu kopieren.
Anders als ein normaler Pipeline-Trigger, der nach einem Zeitplan läuft, läuft die CDC-Ressource ständig (oder in kleinen Stapeln) und verfolgt automatisch Einfügungen, Aktualisierungen und Löschungen an der Quelle und wendet sie auf das Ziel an. Es ist super für Situationen, in denen Daten fast in Echtzeit synchronisiert werden müssen.
Die fortgeschrittenen Interviewfragen gehen tiefer auf die ADF-Funktionen ein und konzentrieren sich auf Leistungsoptimierung, Anwendungsfälle aus der Praxis und fortgeschrittene Architekturentscheidungen.
Diese Fragen sollen deine Erfahrung mit komplizierten Datenszenarien und deine Fähigkeit, schwierige Probleme mit ADF zu lösen, einschätzen.
Beschreibung: Diese Frage checkt, wie gut du Probleme lösen und die Effizienz der Pipeline verbessern kannst.
Beispielantwort: Ich nutze meistens ein paar Strategien, um die Leistung einer Azure Data Factory-Pipeline zu verbessern.
Zuerst stelle ich sicher, dass Parallelität genutzt wird, indem ich Concurrent Pipeline Runs verwende, um Daten parallel zu verarbeiten, wo es geht. Ich nutze auch die Partitionierung in der Kopieraktivität, um große Datensätze aufzuteilen und kleinere Teile gleichzeitig zu übertragen.
Eine andere wichtige Optimierung ist, die richtige Integrationslaufzeit auszuwählen, je nachdem, was die Datenquelle und die Transformationsanforderungen sind. Zum Beispiel kann die Verwendung eines selbst gehosteten IR für lokale Daten die Übertragung von lokalen Daten in die Cloud beschleunigen.
Außerdem kann das Aktivieren von Staging in der Kopieraktivität die Leistung verbessern, indem große Datensätze vor dem endgültigen Laden zwischengespeichert werden.
Beschreibung: Diese Frage checkt, wie gut du das sichere Verwalten von Anmeldedaten in ADF verstehst.
Beispielantwort: Azure Key Vault ist echt wichtig, um sensible Infos wie Verbindungszeichenfolgen, Passwörter und API-Schlüssel in Azure Data Factory zu schützen. Anstatt Geheimnisse in Pipelines oder Linked Services fest zu programmieren, benutze ich Key Vault, um diese Geheimnisse zu speichern und zu verwalten.
Die ADF-Pipeline kann während der Laufzeit sicher Geheimnisse aus Key Vault abrufen und so sicherstellen, dass Anmeldeinformationen geschützt bleiben und nicht im Code offengelegt werden. Wenn ich zum Beispiel einen verknüpften Dienst einrichte, um eine Verbindung zu einer Azure SQL-Datenbank herzustellen, würde ich eine geheime Referenz aus Key Vault verwenden, um mich sicher zu authentifizieren.
Beschreibung: Diese Frage testet, wie gut du dich mit Versionskontrolle und automatisierter Bereitstellung in ADF auskennst.
Beispielantwort: Azure Data Factory lässt sich für CI/CD-Workflows mit Azure DevOps oder GitHub verbinden. Normalerweise richte ich ADF so ein, dass es sich mit einem Git-Repository verbindet, damit die Versionskontrolle für Pipelines, Datensätze und verknüpfte Dienste funktioniert. Der Prozess umfasst das Erstellen von Branches, das Vornehmen von Änderungen in einer Entwicklungsumgebung und das anschließende Committen dieser Änderungen in das Repository.
Für die Bereitstellung unterstützt ADF ARM-Vorlagen, die exportiert und in verschiedenen Umgebungen wie Staging und Produktion verwendet werden können. Mit Pipelines kann ich den Bereitstellungsprozess automatisieren und sicherstellen, dass Änderungen getestet und effizient in verschiedenen Umgebungen eingeführt werden.
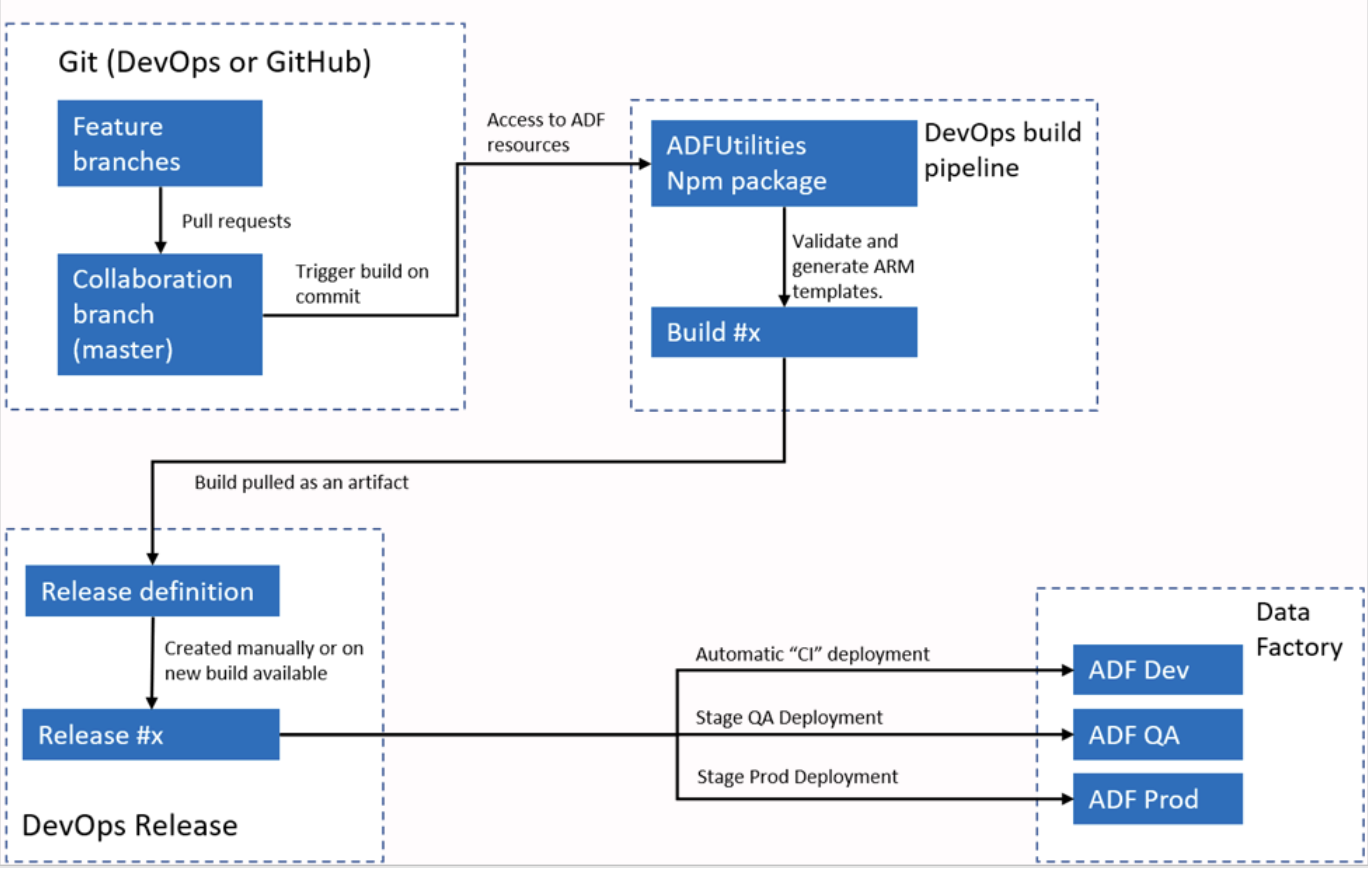
Automatischer CI/CI-Workflow mit Azure Data Factory. Bildquelle: Microsoft.
Beschreibung: Diese Frage checkt, wie gut du die Möglichkeiten von ADF im Umgang mit hybriden Datenumgebungen verstehst.
Beispielantwort: Um eine hybride Datenpipeline mit Azure Data Factory zu erstellen, musst du die selbst gehostete Integrationslaufzeit (IR) nutzen, um die Lücke zwischen lokalen und Cloud-Umgebungen zu schließen. Der IR wird auf einem Rechner im lokalen Netzwerk installiert, sodass ADF Daten sicher zwischen lokalen und Cloud-Ressourcen wie Azure Blob Storage oder Azure SQL Database verschieben kann.
Wenn ich zum Beispiel SQL Server-Daten vor Ort in einen Azure Data Lake verschieben muss, richte ich den selbst gehosteten IR ein, um sicher auf den SQL Server zuzugreifen, definiere Datensätze für Quelle und Ziel und benutze eine Kopieraktivität, um die Daten zu verschieben. Ich könnte auch Transformationen oder Reinigungsschritte mit Mapping Data Flows hinzufügen.
Beschreibung: Diese Frage testet deine Fähigkeit, dynamische Schema-Zuordnungen in komplexen Datenflüssen zu konfigurieren.
Beispielantwort: Dynamisches Mapping in einem Mapping-Datenfluss macht es einfacher, wenn sich das Schema der Quelldaten ändert. Ich setze dynamisches Mapping mit der Auto-Mapping-Funktion in Data Flow um, die Quellspalten automatisch nach Namen den Zielspalten zuordnet.
Ich nutze abgeleitete Spalten und Ausdruckssprache in Datenflüssen, um Spalten basierend auf ihren Metadaten dynamisch zuzuweisen oder zu ändern, wenn es um komplexere Szenarien geht. Dieser Ansatz ist super, wenn es um Schema-Drift geht oder wenn die Datenpipeline mehrere verschiedene Quellschemata ohne manuelles Remapping verarbeiten muss.
Beschreibung: Diese Frage testet, ob du Pipelines entwerfen kannst, die den Datenverwaltungsstandards deines Unternehmens entsprechen.
Beispielantwort: ADF lässt sich direkt mit Microsoft Purview verbinden, um Herkunftsdaten zu übertragen. Wenn eine Pipeline läuft, schickt ADF Metadaten an Purview, die Folgendes beschreiben:
So können Datenverwalter den Datenfluss im ganzen Unternehmen sehen. Du verbindest sie, indem du die ADF-Instanz im Purview Governance-Portal registrierst.
Verhaltens- und szenariobasierte Interviewfragen konzentrieren sich darauf, wie die Kandidaten ihre technischen Fähigkeiten in echten Situationen anwenden.
Diese Fragen helfen dabei, die Fähigkeiten zur Problemlösung, Fehlerbehebung und Optimierung in komplexen Datenabläufen zu beurteilen. Außerdem geben sie einen Einblick in die Art und Weise, wie ein Bewerber Entscheidungen trifft, und in seine Erfahrung mit Herausforderungen bei der Datenintegration und ETL-Prozessen.
Beschreibung: Diese Frage checkt deine Fähigkeiten, Probleme zu lösen, vor allem wenn es um Pipeline-Ausfälle oder unerwartete Probleme geht.
Beispielantwort: Bei einem Projekt hatte ich immer wieder Probleme mit der Pipeline, wenn ich versucht habe, Daten von einem lokalen SQL Server zu Azure Blob Storage zu übertragen.
Die Fehlerprotokolle zeigen, dass es beim Verschieben der Daten zu einem Timeout gekommen ist. Zur Fehlerbehebung habe ich zuerst die Konfiguration der selbst gehosteten Integrationslaufzeit (IR) überprüft, die für die lokale Datenverbindung zuständig war.
Bei der Überprüfung hab ich festgestellt, dass der Rechner, auf dem das IR läuft, viel CPU-Leistung verbraucht, was zu Verzögerungen bei der Datenübertragung führt.
Um das Problem zu lösen, habe ich die Rechenleistung des Computers erhöht und die Daten mit den Einstellungen der Kopieraktivität in kleinere Teile aufgeteilt, um die Arbeitslast zu verteilen.
Dadurch konnten Daten parallel verarbeitet werden, was die Ladezeiten verkürzte und Zeitüberschreitungen verhinderte. Nach den Änderungen lief die Pipeline ohne Probleme und der Fehler war weg.
Beschreibung: Diese Frage checkt, ob du Optimierungstechniken in Daten-Workflows erkennen und anwenden kannst.
Beispielantwort: Bei einem Projekt, wo wir viele Finanzdaten aus verschiedenen Quellen bearbeiten mussten, hat die erste Pipeline wegen der großen Datenmenge einfach zu lange gedauert. Um das zu optimieren, habe ich zuerst Parallelität aktiviert, indem ich mehrere Kopieraktivitäten eingerichtet habe, die gleichzeitig laufen und jede eine andere Datensatzpartition verarbeitet.
Dann hab ich die Staging-Funktion in der Kopieraktivität genutzt, um die Daten vor der weiteren Verarbeitung vorübergehend im Azure Blob Storage zwischenzuspeichern, was den Durchsatz echt verbessert hat. Ich habe auch Datenflussoptimierungen genutzt, indem ich Lookup-Tabellen zwischengespeichert habe, die bei Transformationen verwendet werden.
Diese Anpassungen haben die Leistung der Pipeline um 40 % verbessert und die Ausführungszeit verkürzt.
Beschreibung: Diese Frage checkt, wie du mit unerwarteten Schemaänderungen umgehst und sicherstellst, dass die Pipelines funktionieren.
Beispielantwort: Ja, bei einem meiner Projekte hat sich das Schema einer Datenquelle (einer externen API) plötzlich geändert, als eine neue Spalte zum Datensatz hinzugefügt wurde. Das hat dazu geführt, dass die Pipeline nicht mehr funktioniert hat, weil das Schema im Mapping-Datenfluss nicht mehr übereinstimmte.
Um das zu lösen, habe ich die Option „Schema Drift zulassen“ im Datenfluss aktiviert, damit die Pipeline Änderungen im Schema automatisch erkennen und verarbeiten kann.
Außerdem habe ich mit „Derived Columns” eine dynamische Spaltenzuordnung gemacht, damit die neue Spalte erfasst wird, ohne dass ich bestimmte Spaltennamen fest einprogrammieren musste. Dadurch konnte die Pipeline ohne manuelle Eingriffe an zukünftige Schemaänderungen angepasst werden.
Beschreibung: Diese Frage checkt, wie gut du mit der Integration von Daten aus mehreren Quellen klarkommst, was bei komplexen ETL-Prozessen oft gefragt ist.
Beispielantwort: In einem aktuellen Projekt musste ich Daten aus drei Quellen zusammenführen: einem lokalen SQL Server, Azure Data Lake und einer REST-API. Ich habe eine Kombination aus einer selbst gehosteten Integrationslaufzeit für die lokale SQL Server-Verbindung und einer Azure-Integrationslaufzeit für die Dienste in der Cloud verwendet.
Ich hab 'ne Pipeline gemacht, die mit der Kopieraktivität Daten aus dem SQL Server und der REST-API geholt, sie mit Mapping Data Flows umgewandelt und mit den Daten aus dem Azure Data Lake kombiniert hat.
Durch die Parametrisierung der Pipelines habe ich dafür gesorgt, dass verschiedene Datensätze und Zeitpläne flexibel gehandhabt werden können. Das hat die Datenintegration aus verschiedenen Quellen möglich gemacht, was für die Datenanalyseplattform des Kunden echt wichtig war.
Beschreibung: Diese Frage geht darum, wie du Probleme mit der Datenqualität in deinen Pipeline-Workflows erkennst und löst.
Beispielantwort: In einem Fall habe ich an einer Pipeline gearbeitet, die Kundendaten aus einem CRM-System extrahiert hat. Allerdings hatten die Daten fehlende Werte und Duplikate, was sich auf die endgültige Berichterstattung ausgewirkt hat. Um diese Probleme mit der Datenqualität zu lösen, habe ich einen Datenfluss in die Pipeline eingebaut, der die Daten bereinigt.
Ich hab Filter benutzt, um doppelte Einträge zu entfernen, und eine bedingte Aufteilung, um fehlende Werte zu bearbeiten. Ich hab 'ne Suche für fehlende oder falsche Daten eingerichtet, um Standardwerte aus 'nem Referenzdatensatz zu holen. Am Ende dieses Prozesses war die Datenqualität deutlich besser, was dafür sorgte, dass die nachgelagerten Analysen genau und zuverlässig waren.
Beschreibung: Diese Frage checkt deine Erfahrung mit fortgeschrittenen Datentransformationen mit ADF.
Beispielantwort: Bei einem Finanzberichterstattungsprojekt musste ich Transaktionsdaten aus verschiedenen Quellen zusammenführen, Aggregationen anwenden und zusammenfassende Berichte für verschiedene Regionen erstellen. Die Herausforderung war, dass jede Datenquelle eine etwas andere Struktur und Namenskonvention hatte. Ich hab die Umwandlung mit Mapping Data Flows gemacht.
Zuerst hab ich die Spaltennamen in allen Datensätzen mit abgeleiteten Spalten einheitlich gemacht. Dann habe ich Aggregationen benutzt, um regionsspezifische Kennzahlen wie Gesamtumsatz und durchschnittlichen Transaktionswert zu berechnen. Schließlich habe ich die Daten mit einer Pivot-Transformation umgestaltet, damit man sie leichter in Berichten nutzen kann. Die ganze Umwandlung wurde innerhalb von ADF gemacht, wobei die integrierten Umwandlungsfunktionen und die skalierbare Infrastruktur genutzt wurden.
Beschreibung: Diese Frage checkt, wie gut du die Datensicherheitspraktiken in ADF verstehst.
Beispielantwort: In einem Projekt mussten wir mit sensiblen Kundendaten arbeiten, die sicher von einem lokalen SQL Server zur Azure SQL-Datenbank übertragen werden mussten. Ich habe Azure Key Vault benutzt, um die Datenbank-Anmeldedaten zu speichern und die Daten zu schützen. So habe ich sichergestellt, dass sensible Infos wie Passwörter nicht fest in der Pipeline oder den Linked Services programmiert wurden.
Außerdem habe ich die Datenverschlüsselung während der Datenübertragung eingerichtet, indem ich SSL-Verbindungen zwischen dem lokalen SQL Server und Azure aktiviert habe.
Ich hab auch die rollenbasierte Zugriffskontrolle (RBAC) benutzt, um den Zugriff auf die ADF-Pipeline einzuschränken, damit nur Leute, die das dürfen, sie auslösen oder ändern können. Diese Konfiguration hat sowohl für eine sichere Datenübertragung als auch für eine ordnungsgemäße Zugriffsverwaltung gesorgt.
Beschreibung: Diese Frage checkt, ob du in der Lage bist, ereignisgesteuerte Pipeline-Ausführungen umzusetzen.
Beispielantwort: In einem Fall musste die Pipeline immer dann laufen, wenn eine neue Datei mit Verkaufsdaten in den Azure Blob Storage hochgeladen wurde. Um das hinzukriegen, hab ich einen ereignisbasierten Trigger in Azure Data Factory benutzt. Der Trigger war so eingestellt, dass er auf „Blob Created“-Ereignisse in einem bestimmten Container achtete, und sobald eine neue Datei hochgeladen wurde, startete er automatisch die Pipeline.
Dieser ereignisgesteuerte Ansatz hat dafür gesorgt, dass die Pipeline nur dann lief, wenn neue Daten da waren, sodass manuelle Ausführung oder geplante Läufe nicht mehr nötig waren. Die Pipeline hat dann die Datei bearbeitet, umgewandelt und zur weiteren Analyse ins Data Warehouse geladen.
Beschreibung: Diese Frage checkt deine Erfahrung mit der Migration von traditionellen ETL-Prozessen in die Cloud mit ADF.
Beispielantwort: Bei einem Projekt, wo ein bestehender SSIS-basierter ETL-Prozess von lokal in die Cloud verlegt werden sollte, habe ich Azure Data Factory mit der Azure-SSIS Integration Runtime benutzt.
Zuerst habe ich die vorhandenen SSIS-Pakete überprüft, um sicherzustellen, dass sie mit ADF kompatibel sind, und die notwendigen Änderungen vorgenommen, um Datenquellen auf der Cloud zu verarbeiten.
Ich habe Azure-SSIS IR eingerichtet, um die SSIS-Pakete in der Cloud auszuführen und dabei die bestehenden Workflows beizubehalten. Für die neue Cloud-Umgebung habe ich auch ein paar der klassischen ETL-Aktivitäten durch native ADF-Komponenten wie Kopieraktivitäten und Datenflusszuordnungen ersetzt, was die Gesamtleistung und Skalierbarkeit der Daten-Workflows verbessert hat.
Beschreibung: Diese Frage checkt, wie gut du mit dem Abrechnungsmodell von ADF klarkommst und es verstehst.
Beispielantwort: Ich würde zuerst den Bericht „Pipeline Run Consumption“ in Azure Monitor anschauen, um die Kostenfaktoren zu finden (z. B. viele Rechenstunden für den Datenfluss oder zu viele API-Aufrufe). Zu den gängigen Optimierungsstrategien gehören:
Um dich auf ein Vorstellungsgespräch für Azure Data Factory vorzubereiten, musst du die technischen und praktischen Aspekte der Plattform richtig gut verstehen. Es ist wichtig, dass du deine Kenntnisse über die wichtigsten Funktionen von ADF und deine Fähigkeit, diese in realen Szenarien anzuwenden, unter Beweis stellst.
Hier sind meine besten Tipps, um dich auf das Vorstellungsgespräch vorzubereiten:
Azure Data Factory ist ein echt starkes Tool zum Erstellen von ETL-Lösungen in der Cloud, und Leute, die sich damit auskennen, sind in der Welt des Data Engineering echt gefragt!
In diesem Artikel haben wir uns mit wichtigen Interviewfragen beschäftigt, die von allgemeinen Konzepten bis hin zu technischen und szenariobasierten Fragen reichen, und dabei betont, wie wichtig es ist, die Funktionen und Tools von ADF zu kennen. Die Beispiele aus der Praxis zu Pipeline-Management, Datentransformation und Fehlerbehebung zeigen, welche Fähigkeiten man in einer Cloud-basierten ETL-Umgebung braucht.
Wenn du dein Wissen über Microsoft Azure vertiefen willst, solltest du dir die grundlegenden Kurse zu Azure-Architektur, -Verwaltung und -Governance ansehen, wie zum Beispiel „Microsoft Azure verstehen“, „Microsoft Azure-Architektur und -Dienste verstehen“ und „Microsoft Azure-Verwaltung und -Governance verstehen“. Diese Ressourcen bieten dir wertvolle Einblicke in das breitere Azure-Ökosystem, ergänzen dein Wissen über Azure Data Factory und bereiten dich auf eine erfolgreiche Karriere im Bereich Data Engineering vor.
Lerne mit diesen Kursen mehr über Azure!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Mark Pedigo
