
Track
Microsoft Azure Fundamentals (AZ-900)
9 hr
Azure Data Factory (ADF) is a cloud-based data integration service provided by Microsoft Azure.
As data-driven decision-making becomes a central aspect of business operations, the demand for cloud-based data engineering tools is at an all-time high! Since ADF is a leading service, companies increasingly seek data professionals with hands-on experience to manage their data pipelines and integrate their systems.
In this article, we aim to guide aspiring ADF professionals through essential Azure Data Factory interview questions and answers—covering general, technical, advanced, and scenario-based questions —while offering tips on acing the interview.
Azure Data Factory is a cloud-based ETL service that enables you to create data-driven workflows for orchestrating and automating data movement and transformation. The service integrates with various data sources and destinations on-premises and in the cloud.
As teams move towards cloud-native infrastructures, a growing need exists to manage data across diverse environments. ADF’s integration with Azure's ecosystem and third-party data sources facilitates this, making expertise with the service a highly sought-after skill by organizations.
Automated BI architecture using Azure Data Factory. Image source: Microsoft
In this section, we will focus on foundational questions often asked in interviews to gauge your general knowledge of ADF. These questions test your understanding of basic concepts, architecture, and components.
Description: This question is often asked to evaluate whether you understand the building blocks of ADF.
Example answer: The main components of Azure Data Factory are:
Description: This question tests your understanding of how Azure Data Factory facilitates hybrid data movement securely and efficiently.
Example answer: Azure Data Factory enables secure data movement between cloud and on-premise environments through the Self-hosted Integration Runtime (IR), which acts as a bridge between ADF and on-premise data sources.
For example, when moving data from an on-premise SQL Server to Azure Blob Storage, the self-hosted IR securely connects to the on-premise system. This allows ADF to transfer data while ensuring security through encryption in transit and at rest. This is particularly useful for hybrid cloud scenarios where data is distributed across on-prem and cloud infrastructures.
Description: This question evaluates your understanding of how ADF automates and schedules pipelines using different trigger types.
Example answer: In Azure Data Factory, triggers are used to automatically initiate pipeline executions based on specific conditions or schedules. There are three main types of triggers:
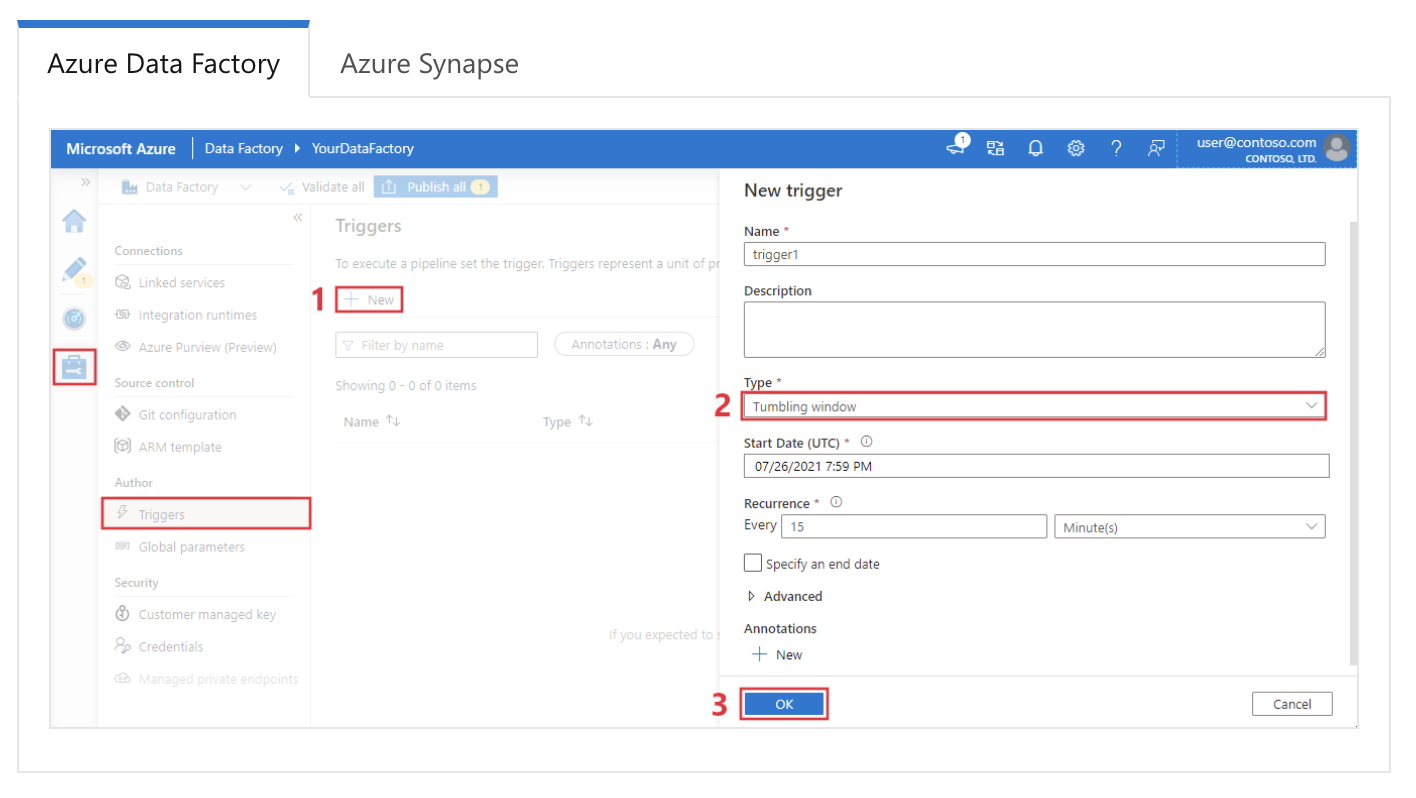
Configuring a tumbling window trigger in Azure Data Factory. Image source: Microsoft.
Description: This question assesses your knowledge of the various tasks that ADF pipelines can perform.
Example answer: Azure Data Factory pipelines support several types of activities. These are the most common ones:
|
Activity type |
Description |
|
Data movement |
Moves data between supported data stores (e.g., Azure Blob Storage, SQL Database) with the Copy Activity. |
|
Data transformation |
Includes Data Flow Activity for data transformation logic using Spark, Mapping Data Flows for ETL operations, and Wrangling Data Flows for data prep. |
|
Control flow |
Provides control over pipeline execution using activities like ForEach, If Condition, Switch, Wait, and Until to create conditional logic. |
|
External execution |
Executes external applications or functions, including Azure Functions, Web Activities (calling REST APIs), and Stored Procedure Activities for SQL. |
|
Custom activities |
Allows the execution of custom code in Custom Activity using .NET or Azure Batch services, providing flexibility for advanced data processing needs. |
|
Other services |
Supports HDInsight, Databricks, and Data Lake Analytics activities, which integrate with other Azure analytics services for complex data tasks. |
Description: This question checks your familiarity with ADF’s monitoring and debugging tools.
Example answer: Azure Data Factory provides a robust monitoring and debugging interface through the Monitor tab in the Azure portal. I can track pipeline runs, view activity statuses, and diagnose failures here. Each activity generates logs, which can be reviewed to identify errors and troubleshoot issues.
Additionally, Azure Monitor can be configured to send alerts based on pipeline failures or performance issues. For debugging, I typically start by looking at the logs for failed activities, review the error details, and then rerun the pipeline after fixing the issue.
Description: This question tests whether you are up-to-date with Microsoft's latest data platform evolution.
Example answer: While both share the same engine, Data Factory in Fabric is a SaaS (Software as a Service) offering integrated into the Fabric ecosystem, whereas Azure Data Factory (ADF) is a PaaS (Platform as a Service) resource. Key differences include:
Description: This question evaluates your knowledge of ADF’s security mechanisms for protecting data throughout its lifecycle.
Example answer: Azure Data Factory ensures data security through several mechanisms.
First, it uses encryption for data both in transit and at rest, employing protocols like TLS and AES to secure data transfers. ADF integrates with Azure Active Directory (AAD) for authentication and uses Role-Based Access Control (RBAC) to restrict who can access and manage the factory.
Additionally, Managed Identities allow ADF to securely access other Azure services without exposing credentials. For network security, ADF supports Private Endpoints, ensuring that data traffic stays within the Azure network and adding another layer of protection.
Description: This question assesses your understanding of the different roles Linked Services and Datasets play in ADF.
Example answer: In Azure Data Factory, a Linked Service defines the connection to an external data source or compute service, much like a connection string. It includes the authentication information needed to connect to the resource.
A Dataset, on the other hand, represents the specific data you’ll be working with, such as a table in a database or a file in Blob Storage.
While the Linked Service defines where the data is, the Dataset describes what it looks like and how it’s structured. These two components work together to facilitate data movement and transformation.
Technical interview questions often focus on your understanding of specific features, their implementations, and how they work together to build effective data pipelines. These questions assess your hands-on experience and knowledge of ADF's core components and capabilities.
Description: This question tests your ability to implement error-handling strategies in ADF pipelines.
Example answer: Error handling in Azure Data Factory can be implemented using Retry Policies and Error Handling Activities. ADF offers built-in retry mechanisms, where you can configure the number of retries and the interval between retries if an activity fails.
For example, if a Copy Activity fails due to a temporary network issue, you can configure the activity to retry 3 times with a 10-minute interval between each attempt.
In addition, Set-Acivity Dependency Conditions like Failure, Completion, and Skipped can trigger specific actions depending on whether an activity succeeds or fails.
For instance, I could define a pipeline flow such that upon an activity's failure, a custom error-handling activity, like sending an alert or executing a fallback process, is executed.
Description: This question evaluates your understanding of the computing infrastructure behind data movement and activity dispatch in ADF.
Example answer: The Integration Runtime (IR) is the compute infrastructure that Azure Data Factory uses to perform data movement, transformation, and activity dispatch. It is central to managing how and where data is processed, and it can be optimized based on the source, destination, and transformation requirements. For further context, there are three types of IR:
|
Integration Runtime (IR) Type |
Description |
|
Azure Integration Runtime |
Used for data movement and transformation activities within Azure data centers. It supports copy activities, data flow transformations, and dispatches activities to Azure resources. |
|
Self-hosted Integration Runtime |
Installed on-premises or virtual machines in a private network to enable data integration across on-premises, private, and Azure resources. Useful for copying data from on-premises to Azure. |
|
Azure-SSIS Integration Runtime |
Allows you to lift and shift your existing SQL Server Integration Services (SSIS) packages into Azure, supporting SSIS package execution natively within Azure Data Factory. Ideal for users who want to migrate SSIS workloads without extensive rework. |
Description: This question checks your understanding of how parameterization works in ADF to make reusable and flexible pipelines.
Example answer: Parameterization in Azure Data Factory allows for dynamic pipeline execution, where you can pass in different values during each run.
For example, in a Copy Activity, I could use parameters to specify the source file path and destination folder dynamically. I would define the parameters at the pipeline level and pass them to the relevant dataset or activity.
Here’s a simple example:
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}Parameterization makes pipelines reusable and allows for easy scaling by adjusting inputs dynamically during runtime.
Description: This question evaluates your knowledge of data transformation in ADF without needing external compute services.
Example answer: A Mapping Data Flow in Azure Data Factory allows you to perform transformations on data without writing code or moving data outside the ADF ecosystem. It provides a visual interface where you can build complex transformations.
Data flows are executed on Spark clusters within ADF’s managed environment, which allows for scalable and efficient data transformations.
For example, in a typical transformation scenario, I could use a data flow to join two datasets, aggregate the results, and write the output to a new destination—all visually and without external services like Databricks.
Description: This question tests your ability to manage dynamic schema changes during data transformation.
Example answer: Schema drift refers to changes in source data structure over time.
Azure Data Factory addresses schema drift by offering the Allow Schema Drift option in Mapping Data Flows. This allows ADF to automatically adjust to changes in the schema of incoming data, like new columns being added or removed, without redefining the entire schema.
By enabling schema drift, I can configure a pipeline to dynamically map columns even if the source schema changes.
Allow schema drift option in Azure Data Factory. Image source: Microsoft
Description: This question evaluates your familiarity with modern, continuous data ingestion methods versus batch processing.
Example answer: The CDC resource in ADF provides a low-code way to continuously replicate changed data from sources (like a SQL or Cosmos database) to a destination without complex watermark logic.
Unlike a standard pipeline trigger that runs on a schedule, the CDC resource runs continuously (or in micro-batches), automatically tracking inserts, updates, and deletes at the source and applying them to the target. It is ideal for scenarios requiring near real-time data synchronization.
Advanced interview questions delve into deeper ADF functionalities, focusing on performance optimization, real-world use cases, and advanced architectural decisions.
These questions are meant to gauge your experience with complex data scenarios and your ability to solve challenging problems using ADF.
Description: This question assesses your ability to troubleshoot and improve pipeline efficiency.
Example answer: I typically follow several strategies to optimize the performance of an Azure Data Factory pipeline.
First, I ensure that parallelism is leveraged by using Concurrent Pipeline Runs to process data in parallel where possible. I also use Partitioning within the Copy Activity to split large datasets and transfer smaller chunks concurrently.
Another important optimization is selecting the right Integration Runtime based on the data source and transformation requirements. For example, using a Self-hosted IR for on-premise data can speed up on-prem to cloud transfers.
Additionally, enabling Staging in the Copy Activity can improve performance by buffering large datasets before final loading.
Description: This question evaluates your understanding of secure credentials management in ADF.
Example answer: Azure Key Vault plays a critical role in securing sensitive information like connection strings, passwords, and API keys within Azure Data Factory. Instead of hardcoding secrets in pipelines or Linked Services, I use Key Vault to store and manage these secrets.
The ADF pipeline can securely retrieve secrets from Key Vault during runtime, ensuring that credentials remain protected and not exposed in code. For example, when setting up a Linked Service to connect to an Azure SQL Database, I would use a secret reference from Key Vault to authenticate securely.
Description: This question checks your familiarity with version control and automated deployment in ADF.
Example answer: Azure Data Factory integrates with Azure DevOps or GitHub for CI/CD workflows. I typically configure ADF to connect to a Git repository, enabling version control for pipelines, datasets, and Linked Services. The process involves creating branches, making changes in a development environment, and then committing those changes to the repository.
For deployment, ADF supports ARM templates that can be exported and used in different environments, like staging and production. Using pipelines, I can automate the deployment process, ensuring that changes are tested and promoted efficiently through different environments.
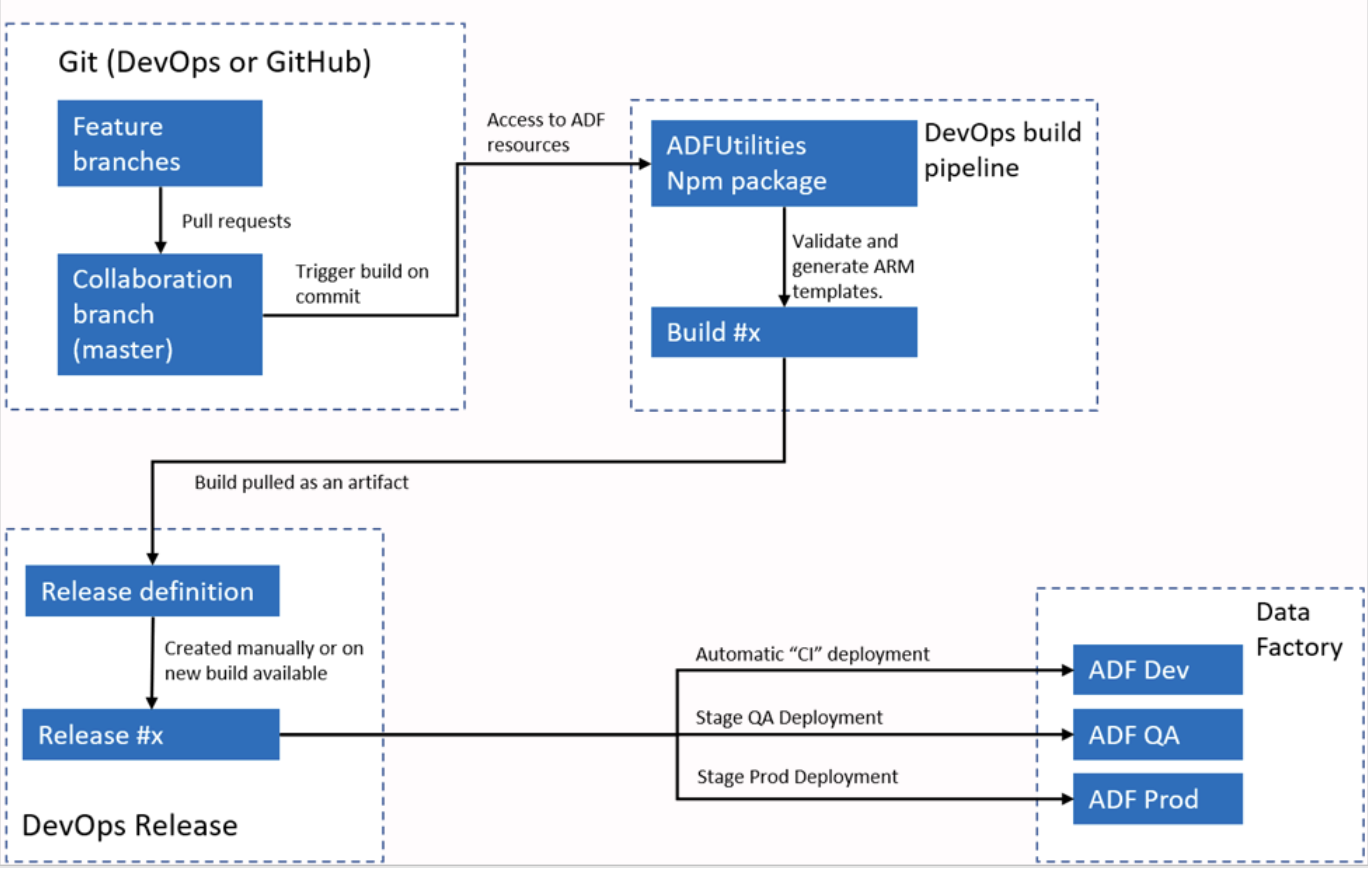
Azure Data Factory automated CI/CI workflow. Image source: Microsoft.
Description: This question evaluates your understanding of ADF’s capabilities in handling hybrid data environments.
Example answer: Designing a hybrid data pipeline with Azure Data Factory requires using the Self-hosted Integration Runtime (IR) to bridge on-premise and cloud environments. The IR is installed on a machine within the on-premise network, which allows ADF to move data securely between on-premise and cloud resources like Azure Blob Storage or Azure SQL Database.
For instance, when I need to transfer on-prem SQL Server data to an Azure Data Lake, I would set up the Self-hosted IR to securely access the SQL Server, define datasets for the source and destination, and use a Copy Activity to move the data. I could also add transformations or cleansing steps using Mapping Data Flows.
Description: This question tests your ability to configure dynamic schema mappings in complex data flows.
Example answer: Dynamic mapping in a Mapping Data Flow allows for flexibility when the source data schema can change. I implement dynamic mapping by using the Auto Mapping feature in Data Flow, which automatically maps source columns to destination columns by name.
I use Derived Columns and Expression Language in Data Flows to dynamically assign or modify columns based on their metadata for more complex scenarios. This approach helps when dealing with schema drift or when the data pipeline needs to handle multiple different source schemas without manual remapping.
Description: This question checks your ability to design pipelines that comply with enterprise data governance standards.
Example answer: ADF integrates natively with Microsoft Purview to push lineage data. When a pipeline runs, ADF sends metadata to Purview describing:
This allows data stewards to visualize the flow of data across the organization. You connect them by registering the ADF instance within the Purview governance portal.
Behavioral and scenario-based interview questions focus on how candidates apply their technical skills in real-world situations.
These questions help assess problem-solving, troubleshooting, and optimization capabilities within complex data workflows. They also provide insight into a candidate’s decision-making process and experience in handling challenges related to data integration and ETL processes.
Description: This question evaluates your problem-solving skills, especially when dealing with pipeline failures or unexpected issues.
Example answer: In one project, I had a consistently failing pipeline when attempting to transfer data from an on-premise SQL Server to Azure Blob Storage.
The error logs indicated a timeout issue during the data movement process. To troubleshoot, I first checked the Self-hosted Integration Runtime (IR) configuration, which was responsible for the on-premise data connection.
Upon inspection, I found that the machine hosting the IR was using a lot of CPU power, which was causing delays in data transfer.
To resolve the issue, I increased the machine’s processing power and distributed the workload by partitioning the data into smaller chunks using the Copy Activity settings.
This allowed for parallel data processing, reducing load times and preventing timeouts. After the changes, the pipeline ran successfully, eliminating the error.
Description: This question assesses your ability to identify and implement optimization techniques in data workflows.
Example answer: In a project where we had to process large amounts of financial data from multiple sources, the initial pipeline took too long to execute due to the volume of data. To optimize this, I initially enabled parallelism by setting up multiple Copy Activities to run concurrently, each handling a different dataset partition.
Next, I used the staging feature in the Copy Activity to temporarily buffer the data in Azure Blob Storage before processing it further, significantly improving throughput. I also used Data Flow optimizations by caching lookup tables used in transformations.
These adjustments improved the pipeline's performance by 40%, reducing execution time.
Description: This question checks how you manage unexpected schema changes and ensure pipelines remain functional.
Example answer: Yes, in one of my projects, the schema of a data source (an external API) changed unexpectedly when a new column was added to the dataset. This caused the pipeline to fail since the schema in the Mapping Data Flow was no longer aligned.
To address this, I enabled the Allow Schema Drift option in the Data Flow, which allowed the pipeline to detect and handle changes in the schema automatically.
Additionally, I configured dynamic column mapping using Derived Columns, which ensured that the new column was captured without hardcoding specific column names. This ensured the pipeline could adapt to future schema changes without manual intervention.
Description: This question evaluates your ability to handle multi-source data integration, a common requirement in complex ETL processes.
Example answer: In a recent project, I needed to integrate data from three sources: an on-premise SQL Server, Azure Data Lake, and a REST API. I used a combination of a Self-hosted Integration Runtime for the on-premise SQL Server connection and an Azure Integration Runtime for the cloud-based services.
I created a pipeline that used the Copy Activity to pull data from the SQL Server and REST API, transform it using Mapping Data Flows, and combine it with data stored in Azure Data Lake.
By parameterizing the pipelines, I ensured flexibility in handling different datasets and schedules. This enabled data integration from multiple sources, which was crucial for the client’s data analytics platform.
Description: This question examines how you identify and handle data quality problems within your pipeline workflows.
Example answer: In one case, I was working on a pipeline that extracted customer data from a CRM system. However, the data contained missing values and duplicates, which affected the final reporting. To address these data quality issues, I incorporated a Data Flow in the pipeline that performed data cleansing operations.
I used filters to remove duplicates and a conditional split to handle missing values. I set up a lookup for any missing or incorrect data to pull in default values from a reference dataset. By the end of this process, the data quality was significantly improved, ensuring that the downstream analytics were accurate and reliable.
Description: This question tests your experience with advanced data transformations using ADF.
Example answer: In a financial reporting project, I had to merge transactional data from multiple sources, apply aggregations, and generate summary reports for different regions. The challenge was that each data source had a slightly different structure and naming convention. I implemented the transformation using Mapping Data Flows.
First, I standardized the column names across all datasets using Derived Columns. Next, I applied aggregations to calculate region-specific metrics, such as total sales and average transaction value. Finally, I used a pivot transformation to reshape the data for easy reporting. The entire transformation was done within ADF, leveraging its built-in transformations and scalable infrastructure.
Description: This question evaluates your understanding of data security practices in ADF.
Example answer: In one project, we were dealing with sensitive customer data that needed to be securely transferred from an on-premise SQL Server to Azure SQL Database. I used Azure Key Vault to store the database credentials and secure the data, ensuring that sensitive information like passwords was not hardcoded in the pipeline or Linked Services.
Additionally, I implemented Data Encryption during data movement by enabling SSL connections between the on-premise SQL Server and Azure.
I also used role-based access control (RBAC) to restrict access to the ADF pipeline, ensuring that only authorized users could trigger or modify it. This setup ensured both secure data transfer and proper access management.
Description: This question assesses your ability to implement event-driven pipeline executions.
Example answer: In one scenario, the pipeline needed to run whenever a new file containing sales data was uploaded to Azure Blob Storage. To implement this, I used an Event-Based Trigger in Azure Data Factory. The trigger was set to listen for Blob Created events in a specific container, and as soon as a new file was uploaded, it automatically triggered the pipeline.
This event-driven approach ensured that the pipeline only ran when new data was available, eliminating the need for manual execution or scheduled runs. The pipeline then processed the file, transformed it, and loaded it into the data warehouse for further analysis.
Description: This question evaluates your experience migrating traditional ETL processes to the cloud using ADF.
Example answer: In a project to migrate an existing SSIS-based ETL process from on-premise to the cloud, I used Azure Data Factory with the Azure-SSIS Integration Runtime.
First, I assessed the existing SSIS packages to ensure they were compatible with ADF and made necessary modifications to handle cloud-based data sources.
I set up the Azure-SSIS IR to run the SSIS packages in the cloud while maintaining the existing workflows. For the new cloud environment, I also replaced some of the traditional ETL activities with native ADF components like Copy Activities and Mapping Data Flows, which improved the overall performance and scalability of the data workflows.
Description: This question tests your operational maturity and understanding of ADF's billing model.
Example answer: I would first analyze the Pipeline Run Consumption report in Azure Monitor to identify the cost drivers (e.g., high Data Flow compute hours or excessive API calls). Common optimization strategies include:
Preparing for an Azure Data Factory interview requires a deep understanding of the platform's technical and practical aspects. It's essential to demonstrate your knowledge of ADF's core features and your ability to apply them in real-world scenarios.
Here are my best tips to help you get ready for the interview:
Azure Data Factory is a powerful tool for building cloud-based ETL solutions, and expertise in it is highly sought after in the data engineering world!
In this article, we explored essential interview questions ranging from general concepts to technical and scenario-based, emphasizing the importance of knowledge of ADF features and tools. The real-world examples of pipeline management, data transformation, and troubleshooting illustrate the critical skills required in a cloud-based ETL environment.
To deepen your understanding of Microsoft Azure, consider exploring foundational courses on Azure architecture, management, and governance, such as Understanding Microsoft Azure, Understanding Microsoft Azure Architecture and Services, and Understanding Microsoft Azure Management and Governance. These resources offer valuable insights into the broader Azure ecosystem, complementing your knowledge of Azure Data Factory and preparing you for a successful career in data engineering.
Learn more about Azure with these courses!
Track
Course
Course
blog
Dhiraj Kumar
15 min
blog
Josep Ferrer
15 min
blog
Nisha Arya Ahmed
15 min
blog
Fatos Morina
15 min
blog
Abid Ali Awan
15 min
blog
Thalia Barrera
15 min

