
Cursus
Microsoft Azure Fundamentals (AZ-900)
9 h
Azure Data Factory (ADF) est un service d'intégration de données basé sur le cloud fourni par Microsoft Azure.
La prise de décision fondée sur les données devenant un aspect central des opérations commerciales, la demande en outils d'ingénierie des données basés sur le cloud atteint des sommets sans précédent. ADF étant un service de premier plan, les entreprises recherchent de plus en plus des professionnels des données ayant une expérience pratique pour gérer leurs pipelines de données et intégrer leurs systèmes.
Dans cet article, nous souhaitons guider les professionnels ADF en devenir à travers les questions et réponses essentielles d'un entretien Azure Data Factory, couvrant des questions générales, techniques, avancées et basées sur des scénarios, tout en offrant des conseils pour réussir l'entretien.
Azure Data Factory est un service ETL basé sur le cloud qui vous permet de créer des workflows axés sur les données afin d'orchestrer et d'automatiser le déplacement et la transformation des données. Le service s'intègre à diverses sources et destinations de données sur site et dans le cloud.
À mesure que les équipes migrent vers des infrastructures cloud natives, il devient de plus en plus nécessaire de gérer les données dans divers environnements. L'intégration d'ADF à l'écosystème Azure et à des sources de données tierces facilite cette tâche, rendant ainsi l'expertise dans l'utilisation de ce service très recherchée par les organisations.
Architecture BI automatisée utilisant Azure Data Factory. Source de l'image : Microsoft
Dans cette section, nous nous concentrerons sur les questions fondamentales fréquemment posées lors des entretiens afin d'évaluer vos connaissances générales sur ADF. Ces questions évaluent votre compréhension des concepts fondamentaux, de l'architecture et des composants.
Description : Cette question est fréquemment posée afin d'évaluer si vous comprenez les éléments constitutifs de l'ADF.
Exemple de réponse : Les principaux composants d'Azure Data Factory sont les suivants :
Description : Cette question évalue votre compréhension de la manière dont Azure Data Factory facilite le transfert hybride de données de manière sécurisée et efficace.
Exemple de réponse : Azure Data Factory permet le transfert sécurisé des données entre les environnements cloud et sur site grâce au Self-hosted Integration Runtime (IR), qui sert de passerelle entre ADF et les sources de données sur site.
Par exemple, lors du transfert de données d'un serveur SQL local vers Azure Blob Storage, l'IR auto-hébergé se connecte de manière sécurisée au système local. Cela permet à ADF de transférer des données tout en garantissant leur sécurité grâce au chiffrement pendant leur transit et leur stockage. Cela est particulièrement utile dans les scénarios de cloud hybride où les données sont réparties entre les infrastructures sur site et dans le cloud.
Description : Cette question évalue votre compréhension de la manière dont ADF automatise et planifie les pipelines à l'aide de différents types de déclencheurs.
Exemple de réponse : Dans Azure Data Factory, les déclencheurs sont utilisés pour lancer automatiquement l'exécution de pipelines en fonction de conditions ou de calendriers spécifiques. Il existe trois principaux types de déclencheurs :
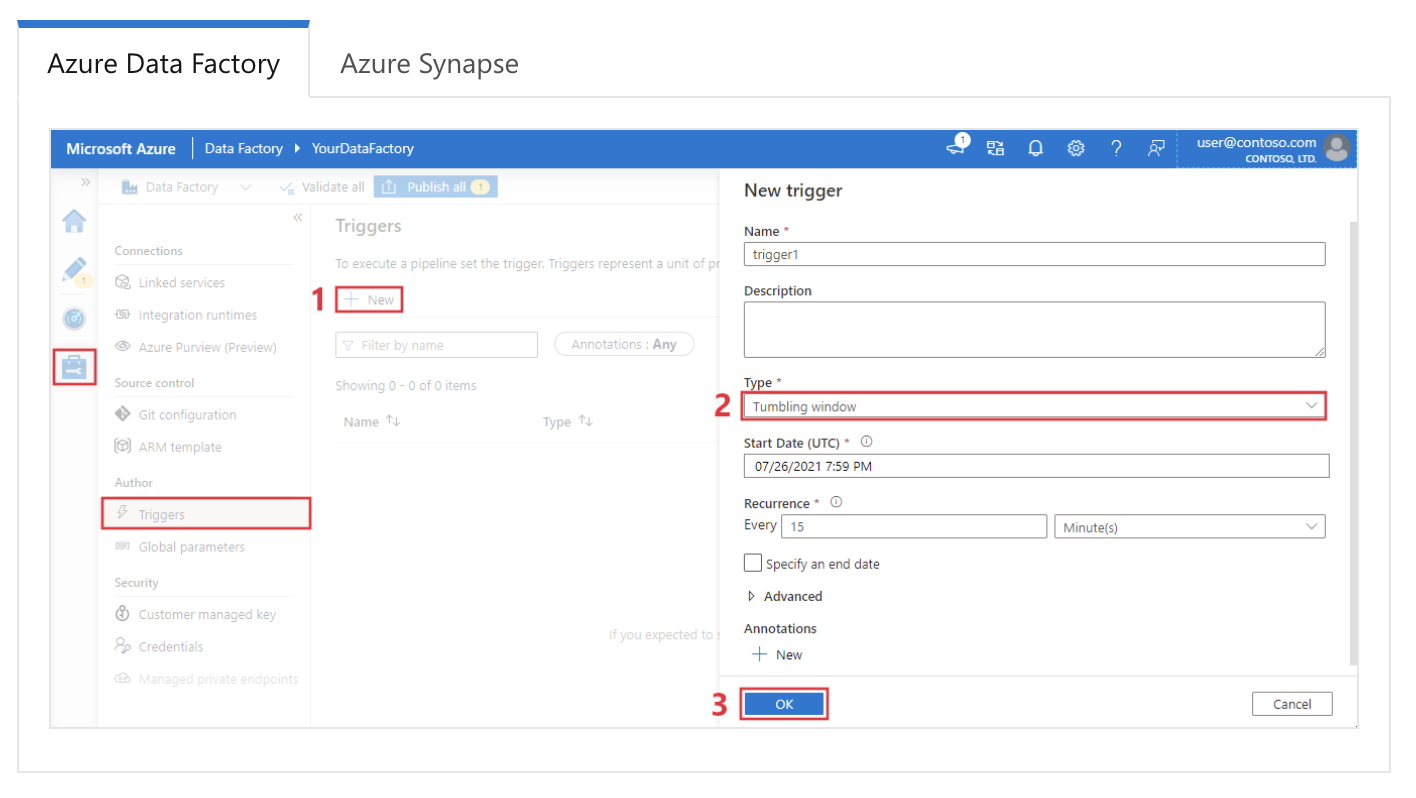
Configuration d'un déclencheur de fenêtre glissante dans Azure Data Factory. Source de l'image : Microsoft.
Description : Cette question évalue votre connaissance des différentes tâches que peuvent effectuer les pipelines ADF.
Exemple de réponse : Les pipelines Azure Data Factory prennent en charge plusieurs types d'activités. Voici les plus courants :
|
Type d'activité |
Description |
|
Transfert de données |
Transfère les données entre les magasins de données pris en charge (par exemple, Azure Blob Storage, SQL Database) à l'aide de l'activité Copier. |
|
Transformation des données |
Comprend l'activité Data Flow pour la logique de transformation des données à l'aide de Spark, Mapping Data Flows pour les opérations ETL et Wrangling Data Flows pour la préparation des données. |
|
Contrôle du flux |
Permet de contrôler l'exécution du pipeline à l'aide d'activités telles que ForEach, If Condition, Switch, Wait et Until pour créer une logique conditionnelle. |
|
Exécution externe |
Exécute des applications ou des fonctions externes, notamment Azure Functions, des activités Web (appelant des API REST) et des activités de procédure stockée pour SQL. |
|
Activités personnalisées |
Permet l'exécution de code personnalisé dans une activité personnalisée à l'aide des services .NET ou Azure Batch, offrant ainsi une flexibilité pour les besoins avancés en matière de traitement des données. |
|
Autres services |
Prend en charge les activités HDInsight, Databricks et Data Lake Analytics, qui s'intègrent à d'autres services d'analyse Azure pour les tâches complexes liées aux données. |
Description : Cette question évalue votre connaissance des outils de surveillance et de débogage d'ADF.
Exemple de réponse: Azure Data Factory offre une interface de surveillance et de débogage robuste via l'onglet Monitor (Surveillance) du portail Azure. Je peux suivre les exécutions des pipelines, consulter l'état des activités et diagnostiquer les défaillances ici. Chaque activité génère des journaux qui peuvent être examinés afin d'identifier les erreurs et de résoudre les problèmes.
De plus, Azure Monitor peut être configuré pour envoyer des alertes en cas de défaillance du pipeline ou de problèmes de performances. Pour le débogage, je commence généralement par examiner les journaux des activités ayant échoué, j'analyse les détails de l'erreur, puis je relance le pipeline après avoir corrigé le problème.
Description : Cette question évalue si vous êtes au courant des dernières évolutions de la plateforme de données Microsoft.
Exemple de réponse : Bien que les deux partagent le même moteur, Data Factory dans Fabric est une offre SaaS (Software as a Service) intégrée à l'écosystème Fabric, tandis qu'Azure Data Factory (ADF) est une ressource PaaS (Platform as a Service). Les principales différences sont les suivantes :
Description : Cette question évalue vos connaissances des mécanismes de sécurité d'ADF pour la protection des données tout au long de leur cycle de vie.
Exemple de réponse : Azure Data Factory garantit la sécurité des données grâce à plusieurs mécanismes.
Tout d'abord, il utilise le chiffrement pour les données en transit et au repos, en employant des protocoles tels que TLS et AES pour sécuriser les transferts de données. ADF s'intègre à Azure Active Directory (AAD) pour l'authentification et utilise le contrôle d'accès basé sur les rôles (RBAC) pour restreindre l'accès et la gestion de l'usine.
De plus, les identités gérées permettent à ADF d'accéder en toute sécurité à d'autres services Azure sans exposer les informations d'identification. Pour la sécurité du réseau, ADF prend en charge les points de terminaison privés, garantissant ainsi que le trafic de données reste au sein du réseau Azure et ajoutant une couche de protection supplémentaire.
Description : Cette question évalue votre compréhension des différents rôles que jouent les services liés et les ensembles de données dans ADF.
Exemple de réponse : Dans Azure Data Factory, un service lié définit la connexion à une source de données externe ou à un service de calcul, de manière similaire à une chaîne de connexion. Il contient les informations d'authentification nécessaires pour se connecter à la ressource.
Un ensemble de données, quant à lui, représente les données spécifiques avec lesquelles vous travaillerez, telles qu'un tableau dans une base de données ou un fichier dans Blob Storage.
Alors que le service lié définit l'emplacement des données, l'ensemble de données décrit leur apparence et leur structure. Ces deux composants fonctionnent conjointement pour faciliter le transfert et la transformation des données.
Les questions techniques posées lors des entretiens portent souvent sur votre compréhension de fonctionnalités spécifiques, leur mise en œuvre et la manière dont elles s'articulent pour créer des pipelines de données efficaces. Ces questions évaluent votre expérience pratique et vos connaissances des composants et fonctionnalités principaux d'ADF.
Description : Cette question évalue votre capacité à mettre en œuvre des stratégies de gestion des erreurs dans les pipelines ADF.
Exemple de réponse : La gestion des erreurs dans Azure Data Factory peut être mise en œuvre à l'aide de stratégies de réessai et d'activités de gestion des erreurs. ADF propose des mécanismes de nouvelle tentative intégrés, qui vous permettent de configurer le nombre de nouvelles tentatives et l'intervalle entre celles-ci en cas d'échec d'une activité.
Par exemple, si une activité de copie échoue en raison d'un problème réseau temporaire, il est possible de configurer l'activité pour qu'elle effectue trois tentatives supplémentaires, espacées de dix minutes chacune.
De plus, les conditions de dépendance des activités définies, telles que l'échec, l'achèvement et l'omission, peuvent déclencher des actions spécifiques selon que l'activité réussit ou échoue.
Par exemple, je pourrais définir un flux de pipeline de telle sorte qu'en cas d'échec d'une activité, une activité personnalisée de gestion des erreurs, telle que l'envoi d'une alerte ou l'exécution d'un processus de secours, soit exécutée.
Description : Cette question évalue votre compréhension de l'infrastructure informatique qui sous-tend le transfert de données et la répartition des activités dans ADF.
Exemple de réponse : L'environnement d'exécution d'intégration (IR) est l'infrastructure informatique qu'Azure Data Factory utilise pour effectuer le déplacement des données, leur transformation et la répartition des activités. Il est essentiel pour gérer la manière dont les données sont traitées et leur emplacement, et il peut être optimisé en fonction de la source, de la destination de l's et des exigences de transformation. Pour plus de contexte, il existe trois types d'IR :
|
Type d'environnement d'exécution d'intégration (IR) |
Description |
|
Runtime d'intégration Azure |
Utilisé pour les activités de transfert et de transformation des données au sein des centres de données Azure. Il prend en charge les activités de copie, les transformations de flux de données et distribue les activités aux ressources Azure. |
|
Environnement d'exécution d'intégration auto-hébergé |
Installé sur site ou sur des machines virtuelles dans un réseau privé pour permettre l'intégration des données entre les ressources sur site, privées et Azure. Utile pour transférer des données d'un environnement local vers Azure. |
|
Moteur d'exécution d'intégration Azure-SSIS |
Permet de transférer vos packages SQL Server Integration Services (SSIS) existants vers Azure, en prenant en charge l'exécution native des packages SSIS dans Azure Data Factory. Idéal pour les utilisateurs qui souhaitent migrer des charges de travail SSIS sans modifications importantes. |
Description : Cette question évalue votre compréhension du fonctionnement de la paramétrisation dans ADF afin de créer des pipelines réutilisables et flexibles.
Exemple de réponse : La paramétrisation dans Azure Data Factory permet une exécution dynamique du pipeline, où vous pouvez saisir différentes valeurs à chaque exécution.
Par exemple, dans une activité Copier, je pourrais utiliser des paramètres pour spécifier dynamiquement le chemin d'accès au fichier source et le dossier de destination. Je définirais les paramètres au niveau du pipeline et les transmettrais à l'ensemble de données ou à l'activité concerné.
Voici un exemple simple :
{
"name": "CopyPipeline",
"type": "Copy",
"parameters": {
"sourcePath": { "type": "string" },
"destinationPath": { "type": "string" }
},
"activities": [
{
"name": "Copy Data",
"type": "Copy",
"source": {
"path": "@pipeline().parameters.sourcePath"
},
"sink": {
"path": "@pipeline().parameters.destinationPath"
}
}
]
}La paramétrisation rend les pipelines réutilisables et facilite la mise à l'échelle en ajustant dynamiquement les entrées pendant l'exécution.
Description : Cette question évalue vos connaissances en matière de transformation des données dans ADF sans avoir recours à des services informatiques externes.
Exemple de réponse : Un flux de données de mappage dans Azure Data Factory vous permet d'effectuer des transformations sur les données sans avoir à écrire de code ni à déplacer les données en dehors de l'écosystème ADF. Il fournit une interface visuelle qui vous permet de créer des transformations complexes.
Les flux de données sont exécutés sur des clusters Spark au sein de l'environnement géré par ADF, ce qui permet des transformations de données évolutives et efficaces.
Par exemple, dans un scénario de transformation classique, je pourrais utiliser un flux de données pour joindre deux ensembles de données, agréger les résultats et enregistrer la sortie vers une nouvelle destination, le tout de manière visuelle et sans services externes tels que Databricks.
Description : Cette question évalue votre capacité à gérer les modifications dynamiques de schéma lors de la transformation des données.
Exemple de réponse : La dérive de schéma fait référence aux modifications apportées à la structure des données sources au fil du temps.
Azure Data Factory traite les dérives de schéma en proposant l'option Autoriser la dérive de schéma dans le mappage des flux de données. Cela permet à ADF de s'adapter automatiquement aux modifications apportées au schéma des données entrantes, telles que l'ajout ou la suppression de nouvelles colonnes, sans avoir à redéfinir l'ensemble du schéma.
En activant la dérive de schéma, je peux configurer un pipeline pour mapper dynamiquement les colonnes, même si le schéma source change.
Autoriser l'option de dérive de schéma dans Azure Data Factory. Source de l'image : Microsoft
Description : Cette question évalue votre connaissance des méthodes modernes d'ingestion continue de données par rapport au traitement par lots.
Exemple de réponse : La ressource CDC dans ADF offre une méthode low-code pour répliquer en continu les données modifiées depuis des sources (telles qu'une base de données SQL ou Cosmos) vers une destination sans logique de tatouage complexe.
Contrairement à un déclencheur de pipeline standard qui s'exécute selon un calendrier défini, la ressource CDC fonctionne en continu (ou par micro-lots), en suivant automatiquement les insertions, les mises à jour et les suppressions à la source et en les appliquant à la cible. Il est particulièrement adapté aux scénarios nécessitant une synchronisation des données en temps quasi réel.
Les questions d'entretien avancées explorent plus en profondeur les fonctionnalités ADF, en mettant l'accent sur l'optimisation des performances, les cas d'utilisation concrets et les décisions architecturales avancées.
Ces questions visent à évaluer votre expérience avec des scénarios de données complexes et votre capacité à résoudre des problèmes difficiles à l'aide d'ADF.
Description : Cette question évalue votre capacité à résoudre les problèmes et à améliorer l'efficacité du pipeline.
Exemple de réponse : Je suis généralement plusieurs stratégies pour optimiser les performances d'un pipeline Azure Data Factory.
Tout d'abord, je m'assure que le parallélisme est exploité en utilisant des exécutions de pipeline simultanées pour traiter les données en parallèle lorsque cela est possible. J'utilise également le partitionnement dans l'activité de copie pour diviser les grands ensembles de données et transférer simultanément des segments plus petits.
Une autre optimisation importante consiste à sélectionner le bon environnement d'exécution d'intégration en fonction de la source de données et des exigences de transformation. Par exemple, l'utilisation d'un IR auto-hébergé pour les données sur site peut accélérer les transferts entre le site et le cloud.
De plus, l'activation de la mise en attente dans l'activité de copie peut améliorer les performances en mettant en mémoire tampon les grands ensembles de données avant leur chargement final.
Description : Cette question évalue votre compréhension de la gestion sécurisée des identifiants dans ADF.
Exemple de réponse : Azure Key Vault joue un rôle essentiel dans la sécurisation des informations sensibles telles que les chaînes de connexion, les mots de passe et les clés API au sein d'Azure Data Factory. Au lieu d'intégrer les secrets dans les pipelines ou les services liés, j'utilise Key Vault pour stocker et gérer ces secrets.
Le pipeline ADF peut récupérer en toute sécurité les secrets à partir de Key Vault pendant l'exécution, garantissant ainsi que les informations d'identification restent protégées et ne sont pas exposées dans le code. Par exemple, lors de la configuration d'un service lié pour se connecter à une base de données SQL Azure, j'utiliserais une référence secrète provenant de Key Vault pour m'authentifier de manière sécurisée.
Description : Cette question évalue votre connaissance du contrôle de version et du déploiement automatisé dans ADF.
Exemple de réponse : Azure Data Factory s'intègre à Azure DevOps ou GitHub pour les workflows CI/CD. Je configure généralement ADF pour qu'il se connecte à un référentiel Git, ce qui permet le contrôle de version pour les pipelines, les ensembles de données et les services liés. Le processus consiste à créer des branches, à apporter des modifications dans un environnement de développement, puis à valider ces modifications dans le référentiel.
Pour le déploiement, ADF prend en charge les modèles ARM qui peuvent être exportés et utilisés dans différents environnements, tels que les environnements de test et de production. Grâce aux pipelines, je peux automatiser le processus de déploiement, garantissant ainsi que les modifications sont testées et mises en œuvre efficacement dans différents environnements.
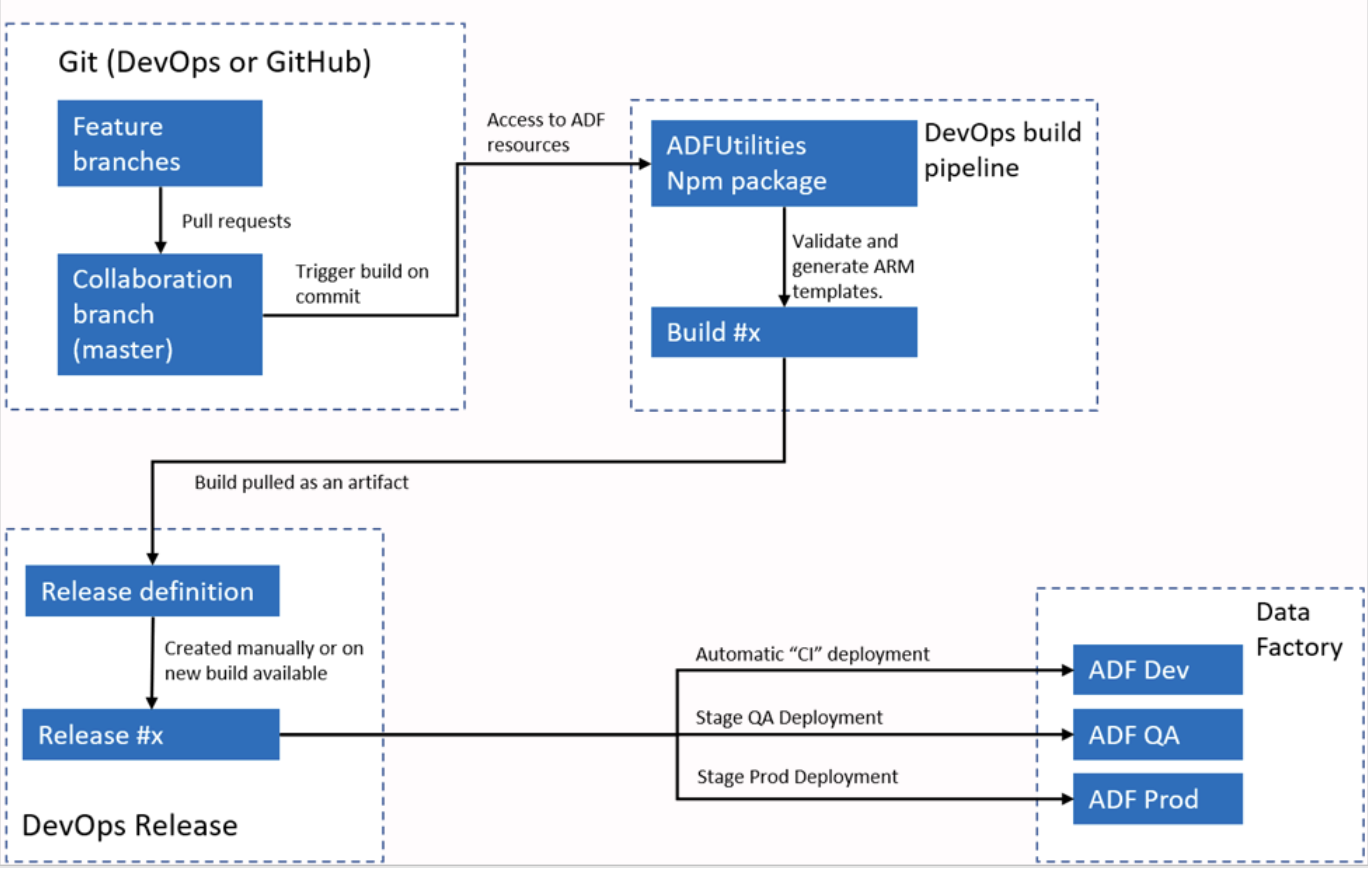
Workflow CI/CI automatisé Azure Data Factory. Source de l'image :e : Microsoft.
Description : Cette question évalue votre compréhension des capacités d'ADF dans la gestion d'environnements de données hybrides.
Exemple de réponse : La conception d'un pipeline de données hybride avec Azure Data Factory nécessite l'utilisation du runtime d'intégration auto-hébergé (IR) pour relier les environnements sur site et cloud. L'IR est installé sur une machine au sein du réseau local, ce qui permet à ADF de transférer des données en toute sécurité entre les ressources locales et les ressources cloud telles qu'Azure Blob Storage ou Azure SQL Database.
Par exemple, lorsque je dois transférer des données SQL Server sur site vers un Azure Data Lake, je configure l'IR auto-hébergé pour accéder en toute sécurité au serveur SQL, je définis les ensembles de données pour la source et la destination, puis j'utilise une activité de copie pour déplacer les données. Je pourrais également ajouter des transformations ou des étapes de nettoyage à l'aide de Mapping Data Flows.
Description : Cette question évalue votre capacité à configurer des mappages de schémas dynamiques dans des flux de données complexes.
Exemple de réponse : Le mappage dynamique dans un flux de données de mappage offre une grande flexibilité lorsque le schéma des données source est susceptible de changer. Je mets en œuvre le mappage dynamique à l'aide de la fonctionnalité de mappage automatique dans Data Flow, qui mappe automatiquement les colonnes source aux colonnes de destination par nom.
J'utilise les colonnes dérivées et le langage d'expression dans les flux de données pour attribuer ou modifier dynamiquement des colonnes en fonction de leurs métadonnées dans des scénarios plus complexes. Cette approche est utile en cas de dérive de schéma ou lorsque le pipeline de données doit traiter plusieurs schémas sources différents sans remappage manuel.
Description : Cette question évalue votre capacité à concevoir des pipelines conformes aux normes de gouvernance des données de l'entreprise.
Exemple de réponse : ADF s'intègre nativement à Microsoft Purview pour transmettre les données de traçabilité. Lorsqu'un pipeline est exécuté, ADF envoie des métadonnées à Purview décrivant :
Cela permet aux responsables des données de visualiser le flux de données au sein de l'organisation. Vous les connectez en enregistrant l'instance ADF dans le portail de gouvernance Purview.
Les questions d'entretien comportementales et basées sur des scénarios se concentrent sur la manière dont les candidats appliquent leurs compétences techniques dans des situations réelles.
Ces questions permettent d'évaluer les capacités de résolution de problèmes, de dépannage et d'optimisation dans le cadre de flux de données complexes. Ils fournissent également des informations sur le processus décisionnel du candidat et son expérience dans la gestion des défis liés à l'intégration des données et aux processus ETL.
Description : Cette question évalue vos compétences en matière de résolution de problèmes, en particulier lorsque vous êtes confronté à des défaillances de pipeline ou à des problèmes imprévus.
Exemple de réponse : Dans le cadre d'un projet, j'ai rencontré des échecs répétés lors du transfert de données d'un serveur SQL local vers Azure Blob Storage.
Les journaux d'erreurs ont indiqué un problème de délai d'attente pendant le processus de transfert des données. Pour résoudre le problème, j'ai d'abord vérifié la configuration du runtime d'intégration (IR) auto-hébergé, qui était responsable de la connexion aux données sur site.
Après vérification, j'ai constaté que la machine hébergeant l'IR utilisait une grande partie de la puissance du processeur, ce qui entraînait des retards dans le transfert des données.
Pour résoudre ce problème, j'ai augmenté la puissance de traitement de la machine et réparti la charge de travail en partitionnant les données en petits morceaux à l'aide des paramètres de l'activité Copier.
Cela a permis un traitement parallèle des données, réduisant ainsi les temps de chargement et évitant les délais d'attente. Après les modifications, le pipeline a fonctionné correctement, éliminant l'erreur.
Description : Cette question évalue votre capacité à identifier et à mettre en œuvre des techniques d'optimisation dans les flux de données.
Exemple de réponse : Dans le cadre d'un projet où nous devions traiter de grandes quantités de données financières provenant de plusieurs sources, le pipeline initial prenait trop de temps à s'exécuter en raison du volume de données. Afin d'optimiser ce processus, j'ai initialement activé le parallélisme en configurant plusieurs activités de copie pour qu'elles s'exécutent simultanément, chacune traitant une partition différente de l'ensemble de données.
Ensuite, j'ai utilisé la fonctionnalité de mise en attente dans l'activité Copier pour stocker temporairement les données dans Azure Blob Storage avant de les traiter davantage, ce qui a considérablement amélioré le débit. J'ai également utilisé les optimisations du flux de données en mettant en cache les tables de recherche utilisées dans les transformations.
Ces ajustements ont amélioré les performances du pipeline de 40 %, réduisant ainsi le temps d'exécution.
Description : Cette question évalue votre capacité à gérer les modifications imprévues du schéma et à garantir le bon fonctionnement des pipelines.
Exemple de réponse : Oui, dans l'un de mes projets, le schéma d'une source de données (une API externe) a subi une modification inattendue lorsqu'une nouvelle colonne a été ajoutée à l'ensemble de données. Cela a entraîné l'échec du pipeline, car le schéma dans le flux de données de mappage n'était plus aligné.
Pour remédier à cela, j'ai activé l'option Autoriser la dérive du schéma dans le flux de données, ce qui a permis au pipeline de détecter et de gérer automatiquement les modifications apportées au schéma.
De plus, j'ai configuré le mappage dynamique des colonnes à l'aide de colonnes dérivées, ce qui a permis de garantir que la nouvelle colonne était capturée sans coder en dur les noms de colonnes spécifiques. Cela a permis de garantir que le pipeline puisse s'adapter aux modifications futures du schéma sans intervention manuelle.
Description : Cette question évalue votre capacité à gérer l'intégration de données provenant de plusieurs sources, une exigence courante dans les processus ETL complexes.
Exemple de réponse : Dans le cadre d'un projet récent, j'ai dû intégrer des données provenant de trois sources : un serveur SQL sur site, Azure Data Lake et une API REST. J'ai utilisé une combinaison d'un runtime d'intégration auto-hébergé pour la connexion SQL Server sur site et d'un runtime d'intégration Azure pour les services basés sur le cloud.
J'ai développé un pipeline qui utilise l'activité Copier pour extraire des données du serveur SQL et de l'API REST, les transformer à l'aide de flux de données de mappage et les combiner avec les données stockées dans Azure Data Lake.
En paramétrant les pipelines, j'ai assuré une certaine flexibilité dans le traitement de différents ensembles de données et calendriers. Cela a permis l'intégration de données provenant de plusieurs sources, ce qui était essentiel pour la plateforme d'analyse de données du client.
Description : Cette question examine la manière dont vous identifiez et gérez les problèmes liés à la qualité des données au sein de vos flux de travail.
Exemple de réponse : Dans un cas, j'ai travaillé sur un pipeline qui extrayait les données clients d'un système CRM. Cependant, les données contenaient des valeurs manquantes et des doublons, ce qui a eu une incidence sur le rapport final. Afin de résoudre ces problèmes liés à la qualité des données, j'ai intégré un flux de données dans le pipeline qui effectue des opérations de nettoyage des données.
J'ai utilisé des filtres pour éliminer les doublons et une division conditionnelle pour traiter les valeurs manquantes. J'ai configuré une recherche pour toutes les données manquantes ou incorrectes afin d'extraire les valeurs par défaut d'un ensemble de données de référence. À la fin de ce processus, la qualité des données a été considérablement améliorée, garantissant ainsi la précision et la fiabilité des analyses en aval.
Description : Cette question évalue votre expérience en matière de transformations de données avancées à l'aide d'ADF.
Exemple de réponse : Dans le cadre d'un projet de reporting financier, j'ai dû fusionner des données transactionnelles provenant de plusieurs sources, appliquer des agrégations et générer des rapports récapitulatifs pour différentes régions. Le défi résidait dans le fait que chaque source de données présentait une structure et une convention de nommage légèrement différentes. J'ai mis en œuvre la transformation à l'aide de Mapping Data Flows.
Tout d'abord, j'ai normalisé les noms des colonnes dans tous les ensembles de données à l'aide des colonnes dérivées. Ensuite, j'ai appliqué des agrégations pour calculer des indicateurs spécifiques à chaque région, tels que le chiffre d'affaires total et la valeur moyenne des transactions. Enfin, j'ai utilisé une transformation pivot pour remodeler les données afin de faciliter la création de rapports. L'ensemble de la transformation a été réalisé au sein d'ADF, en tirant parti de ses transformations intégrées et de son infrastructure évolutive.
Description : Cette question évalue votre compréhension des pratiques de sécurité des données dans ADF.
Exemple de réponse : Dans le cadre d'un projet, nous avons dû traiter des données clients sensibles qui devaient être transférées de manière sécurisée depuis un serveur SQL local vers une base de données SQL Azure. J'ai utilisé Azure Key Vault pour stocker les informations d'identification de la base de données et sécuriser les données, en veillant à ce que les informations sensibles telles que les mots de passe ne soient pas codées en dur dans le pipeline ou les services liés.
De plus, j'ai mis en place le chiffrement des données lors de leur transfert en activant les connexions SSL entre le serveur SQL sur site et Azure.
J'ai également utilisé le contrôle d'accès basé sur les rôles (RBAC) pour restreindre l'accès au pipeline ADF, garantissant ainsi que seuls les utilisateurs autorisés puissent le déclencher ou le modifier. Cette configuration a permis d'assurer à la fois la sécurité du transfert des données et une gestion adéquate des accès.
Description : Cette question évalue votre capacité à mettre en œuvre des exécutions de pipeline déclenchées par des événements.
Exemple de réponse : Dans un scénario, le pipeline devait s'exécuter chaque fois qu'un nouveau fichier contenant des données de vente était téléchargé vers Azure Blob Storage. Pour mettre cela en œuvre, j'ai utilisé un déclencheur basé sur les événements dans Azure Data Factory. Le déclencheur était configuré pour surveiller les événements « Blob créé » dans un conteneur spécifique, et dès qu'un nouveau fichier était téléchargé, il déclenchait automatiquement le pipeline.
Cette approche événementielle garantissait que le pipeline ne s'exécutait que lorsque de nouvelles données étaient disponibles, éliminant ainsi le besoin d'une exécution manuelle ou programmée. Le pipeline a ensuite traité le fichier, l'a transformé et l'a chargé dans l'entrepôt de données pour une analyse plus approfondie.
Description : Cette question évalue votre expérience en matière de migration de processus ETL traditionnels vers le cloud à l'aide d'ADF.
Exemple de réponse : Dans le cadre d'un projet visant à migrer un processus ETL existant basé sur SSIS d'un environnement sur site vers le cloud, j'ai utilisé Azure Data Factory avec Azure-SSIS Integration Runtime.
Tout d'abord, j'ai évalué les packages SSIS existants afin de m'assurer qu'ils étaient compatibles avec ADF et j'ai apporté les modifications nécessaires pour gérer les sources de données basées sur le cloud.
J'ai configuré Azure-SSIS IR pour exécuter les packages SSIS dans le cloud tout en conservant les workflows existants. Pour le nouvel environnement cloud, j'ai également remplacé certaines des activités ETL traditionnelles par des composants ADF natifs tels que les activités de copie et le mappage des flux de données, ce qui a amélioré les performances globales et l'évolutivité des flux de données.
Description : Cette question évalue votre maturité opérationnelle et votre compréhension du modèle de facturation d'ADF.
Exemple de réponse : Je commencerais par analyser le rapport Pipeline Run Consumption dans Azure Monitor afin d'identifier les facteurs de coût (par exemple, un nombre élevé d'heures de calcul Data Flow ou un nombre excessif d'appels API). Les stratégies d'optimisation courantes comprennent :
La préparation à un entretien Azure Data Factory nécessite une compréhension approfondie des aspects techniques et pratiques de la plateforme. Il est essentiel de démontrer votre connaissance des fonctionnalités principales d'ADF et votre capacité à les appliquer dans des scénarios concrets.
Voici mes meilleurs conseils pour vous aider à vous préparer à l'entretien :
Azure Data Factory est un outil performant pour créer des solutions ETL basées sur le cloud, et l'expertise dans ce domaine est très recherchée dans le monde de l'ingénierie des données.
Dans cet article, nous avons examiné les questions essentielles à poser lors d'un entretien, allant des concepts généraux aux questions techniques et basées sur des scénarios, en soulignant l'importance de la connaissance des fonctionnalités et des outils ADF. Les exemples concrets de gestion de pipeline, de transformation de données et de dépannage illustrent les compétences essentielles requises dans un environnement ETL basé sur le cloud.
Pour approfondir vos connaissances sur Microsoft Azure, nous vous recommandons de suivre des cours fondamentaux sur l'architecture, la gestion et la gouvernance Azure, tels que Comprendre Microsoft Azure, Comprendre l'architecture et les services Microsoft Azure et Comprendre la gestion et la gouvernance Microsoft Azure. Ces ressources offrent des informations précieuses sur l'écosystème Azure dans son ensemble, complétant vos connaissances sur Azure Data Factory et vous préparant à une carrière réussie dans l'ingénierie des données.
Veuillez approfondir vos connaissances sur Azure grâce à ces cours.
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
blog
Nathaniel Taylor-Leach
8 min
Tutoriel
Samuel Shaibu
