Kurs
Python ile Ağaç Tabanlı Modellerle Machine Learning
5 sa
117.2K
Günümüzde birçok büyük kuruluş, geliri en üst düzeye çıkarmak ve iş büyümesini desteklemek için bir tür kestirimsel modelleme kullanmaktadır.
Makine öğreniminin farklı alanlarda çeşitli kullanım senaryoları vardır. Örneğin, Netflix ve Spotify gibi abonelik tabanlı platformlar, uygulamadaki kullanıcı etkinliğine göre içerik önermek için makine öğrenimini kullanır.
Öneri sistemleri, daha iyi bir kullanıcı deneyimi müşterilerin platforma abone olmaya devam etmesini olası kılacağı için bu şirketlere doğrudan iş değeri katar. Bu, gözetimsiz bir makine öğrenimi modeline örnektir.
Benzer şekilde, bir mobil servis sağlayıcı, kullanıcı duyarlılığını analiz etmek ve ürün teklifini pazar talebine göre şekillendirmek için makine öğrenimini kullanabilir. Bu, gözetimli bir makine öğrenimi modeline örnektir.
Tüm makine öğrenimi modelleri gözetimli veya gözetimsiz olarak sınıflandırılabilir. İkisi arasındaki en büyük fark, gözetimli bir algoritmanın etiketli giriş ve çıkış eğitim verilerine ihtiyaç duyması, gözetimsiz bir modelin ise ham, etiketlenmemiş veri kümelerini işleyebilmesidir.
Gözetimli makine öğrenimi modelleri daha sonra regresyon ve sınıflandırma algoritmaları olarak ayrılabilir; bunlar bu makalede daha ayrıntılı olarak açıklanacaktır.
Regresyon algoritmaları, bağımsız değişkenler (x) kullanarak sürekli bir çıktıyı (y) tahmin etmek için kullanılır.
Örneğin, aşağıdaki tabloya bakın:
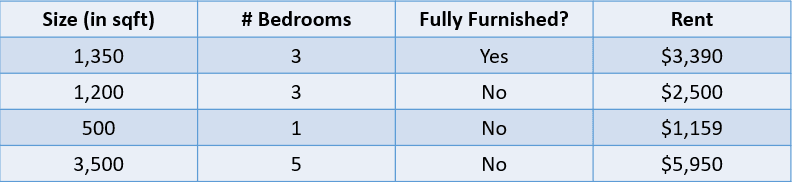
Görsel: yazar
Bu durumda, bir evin kirasını boyutuna, yatak odası sayısına ve tamamen mobilyalı olup olmadığına göre tahmin etmek istiyoruz. Bağımlı değişken olan “Kira” sayısaldır; bu da bunu bir regresyon problemi yapar.
Yukarıdaki gibi çok sayıda giriş değişkenine sahip bir probleme çok değişkenli regresyon problemi denir.
Veri bilimine yeni başlayanların yaygın bir yanılgısı, bir regresyon modelinin doğruluk gibi bir ölçütle değerlendirilebileceğidir. Doğruluk, bu makalede daha sonra açıklanacağı üzere sınıflandırma modellerinin performansını değerlendirmek için kullanılan bir ölçüttür.
Öte yandan, regresyon modelleri MAE (Ortalama Mutlak Hata), MSE (Ortalama Kare Hata) ve RMSE (Kök Ortalama Kare Hata) gibi ölçütlerle değerlendirilir.
Yukarıdaki ev fiyatı problemine bir tahmin değeri ekleyelim ve bu tahminleri birkaç regresyon ölçütü kullanarak değerlendirelim:

Görsel: yazar
Ortalama mutlak hata, tüm gerçek ve tahmin edilen değerler arasındaki farkların toplamını hesaplar ve bunu toplam gözlem sayısına böler. MAE’yi hesaplama formülü şöyledir:
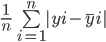
Yukarıdaki değerlerin Ortalama Mutlak Hatasını bu formülle hesaplayalım:
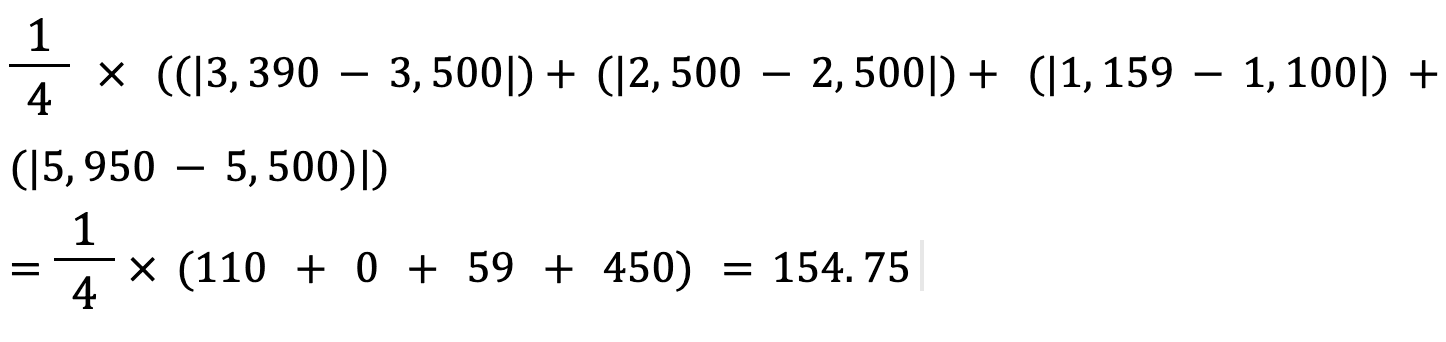
Gerçek ve tahmin edilen ev fiyatı arasındaki ortalama mutlak hata yaklaşık 155 $’dır.
Bir modelin ortalama kare hatasını hesaplama formülü, ortalama mutlak hatanınkine benzerdir:
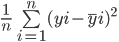
Ortalama mutlak hata, gerçek ve tahmin edilen değer arasındaki ortalama mutlak mesafeyi hesaplarken; ortalama kare hata, gerçek ve tahmin edilen değerler arasındaki ortalama kare mesafeyi bulur.
Yukarıdaki gerçek ve tahmin edilen değerler arasındaki MSE’yi hesaplayalım:
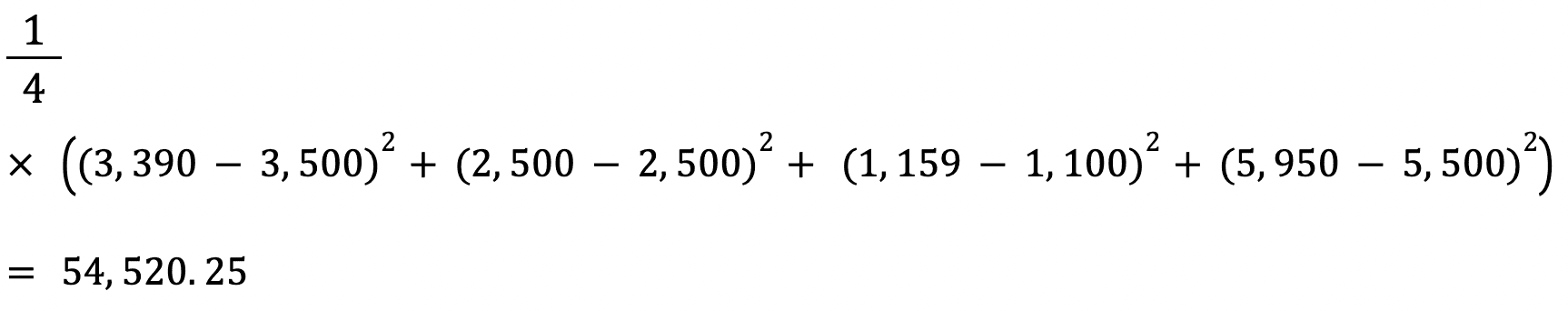
Bir tahmin edicinin RMSE’si, ortalama kare hatasının karekökü alınarak hesaplanır. Bir veri kümesinin MSE’si yerine RMSE’sini hesaplamanın bir avantajı, hatanın, tahmin ettiğimiz değişkenle aynı birimde döndürülmesidir.
Bu durumda, örneğin RMSE, √54.520,25=233,5’tir. Bu değer, ev fiyatı cinsinden olduğu için yorumlanabilirdir; oysa Ortalama Kare Hata değeri öyle değildir.
Artık regresyon kavramını anladığınıza göre, farklı regresyon modeli türlerine bakalım:
Doğrusal regresyon, bağımlı değişken ile bir veya daha fazla bağımsız değişken arasındaki ilişkiyi modellemek için doğrusal bir yaklaşımdır. Bu algoritma, eldeki verilere en iyi uyan bir doğru bulmayı içerir.
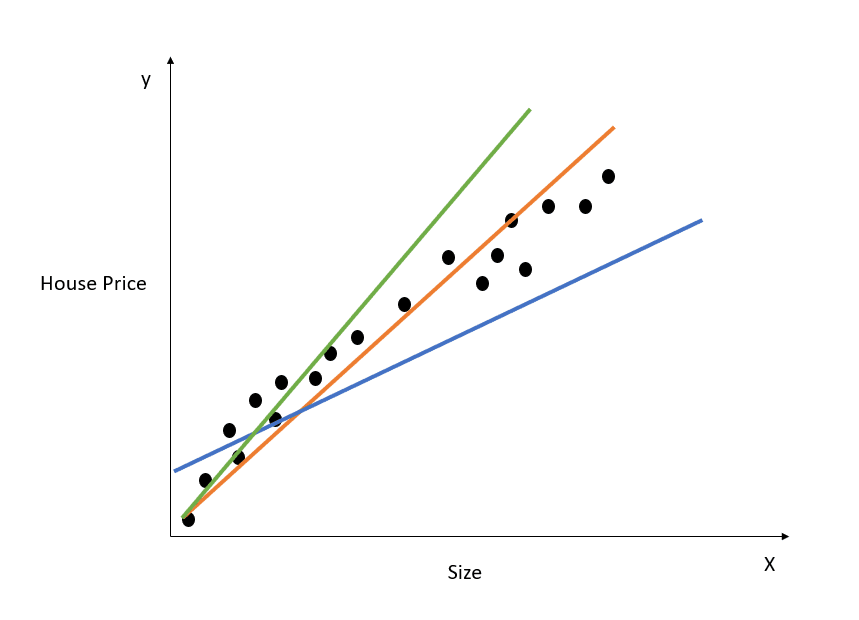
İşte basit doğrusal regresyon modelinin nasıl çalıştığına dair görsel bir temsil:
Görsel: yazar
Yukarıdaki grafik ev fiyatı ile büyüklüğü arasındaki ilişkiyi göstermektedir. Doğrusal regresyon modeli, bu ilişkiyi en iyi şekilde modelleyen bir doğru oluşturacaktır. Farklı büyüklük değerlerine göre yapılan tüm ev fiyatı tahminleri en iyi uyum doğrusunun üzerinde yer alacaktır.
Şemada üç doğrunun çizildiğine dikkat edin. Bunlardan hangisi “en iyi uyum doğrusu”dur?
Yukarıdaki diyagrama bakarak, turuncu doğrunun gösterilen tüm veri noktalarına en yakın olduğunu görebiliriz. Dolayısıyla sezgisel olarak bunun “en iyi uyum doğrusu”nu temsil ettiğini söyleyebiliriz.
Doğrusal regresyonda en iyi uyum doğrusunun nasıl bulunduğuna dair daha resmi bir açıklama şöyledir:
Bir doğrunun denklemi y=mx+c’dir. Burada m doğrunun eğimini, c ise y kesişimini temsil eder. m ve c için sonsuz olası değer olduğundan, bu doğruyu çizmenin de sonsuz yolu vardır.
En iyi uyum doğrusu, en küçük kareler regresyon doğrusu olarak da bilinir ve gerçek ile tahmin edilen değerler arasındaki kareli mesafelerin toplamını en aza indirerek bulunur:
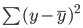
Doğrusal regresyon makine öğrenimi modeli ve uygulaması hakkında daha derin bir anlayış kazanmak için Python’da Doğrusal Regresyonun Temelleri eğitimini okuyabilirsiniz.
Ridge regresyonu, yukarıda açıklanan doğrusal regresyon modelinin bir uzantısıdır. Bir regresyon modelinin katsayılarını mümkün olduğunca düşük tutmak için kullanılan bir tekniktir.
Basit doğrusal regresyon modelinde yaşanan sorunlardan biri, katsayıların büyük değerlere ulaşabilmesi ve modelin girdilere daha duyarlı hâle gelmesidir. Bu da aşırı öğrenmeye yol açabilir.
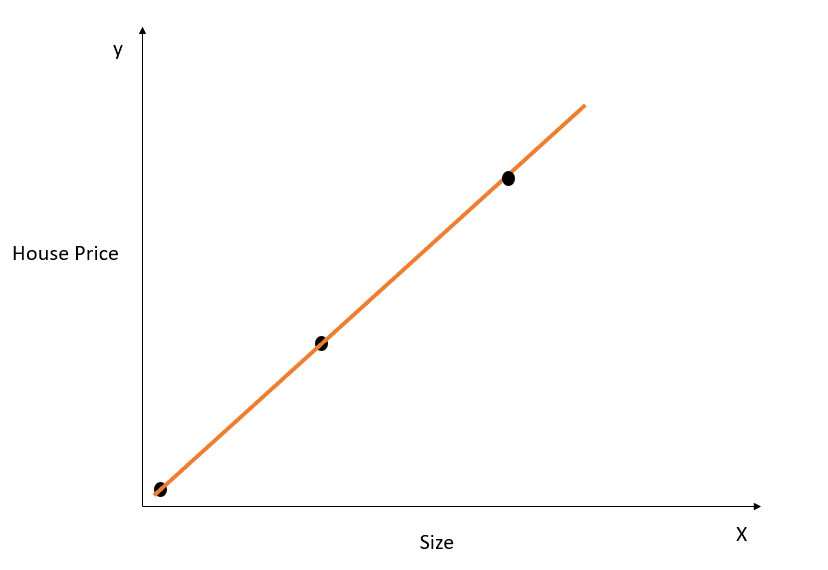
Aşırı öğrenme kavramını anlamak için basit bir örnek ele alalım:
Görsel: yazar
Yukarıdaki şekilde, en iyi uyum doğrusu X ile y arasındaki ilişkiyi mükemmel şekilde modellemekte ve gerçek ile tahmin edilen değerler arasındaki kareli mesafelerin toplamı 0 olmaktadır. Bu doğrunun denkleminin y=mx+c olduğunu hatırlayın.
Bu doğru eğitim veri kümesinde mükemmel uyum sağlasa da, muhtemelen test verisine iyi genellenmeyecektir. Bu olgu aşırı öğrenme olarak adlandırılır; daha fazla bilgi için aşırı öğrenme hakkındaki bu makaleyi okuyabilirsiniz.
Basitçe ifade etmek gerekirse, aşırı derecede karmaşık bir model, gerçek dünyada yansımayan, eğitim veri kümesinin gereksiz inceliklerini yakalar. Bu model eğitim verisinde son derece iyi performans gösterir, ancak eğitim dışındaki veri kümelerinde zayıf kalır.
Büyük katsayılara sahip bir doğrusal regresyon modeli aşırı öğrenmeye yatkındır.
Ridge regresyonu, kayıp fonksiyonuna ek bir maliyet ekleyerek algoritmayı daha küçük katsayılar seçmeye zorlayan bir düzenlileştirme tekniğidir.
Önceki bölümde gösterildiği gibi, basit doğrusal regresyonda en aza indirmek istediğimiz hata şudur:
Ridge regresyonunda bu denklem biraz değişir ve yukarıdaki hataya bir ceza terimi eklenir:
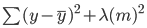
Modelin katsayılarıyla çarpılan bir (lambda) değeri olduğuna dikkat edin. Bu model yalnızca bir değişkene sahip olduğundan, tek bir katsayıya bir ceza terimi eklenmiştir. Birden fazla bağımsız değişken varsa, lambda kareleri alınmış katsayıların toplamıyla çarpılacaktır.
Bu ceza terimi, daha büyük katsayılar seçtiği için modeli cezalandırır. Amaç, katsayı değerlerini küçültmektir; böylece sonuca az katkı yapan değişkenlerin katsayıları 0’a yakın olur. Bu, model varyansını azaltır ve aşırı öğrenmeyi hafifletmeye yardımcı olur.
Lambda değerinin 0 olması hiçbir etki yaratmayacak ve ceza terimi ortadan kalkacaktır. Daha yüksek bir lambda değeri daha büyük bir küçültme cezası ekler ve model katsayıları sıfıra daha çok yaklaşır.
Bir lambda değeri seçerken, basitlik ile eğitim verisine iyi uyum arasında denge kurduğunuzdan emin olun. Daha yüksek bir lambda değeri, basit ve genellenebilir bir modelle sonuçlanır; ancak çok yüksek bir değer seçmek eksik öğrenme riskini doğurur. Öte yandan, sıfıra çok yakın bir lambda değeri seçmek aşırı derecede karmaşık bir modele yol açabilir.
Lasso regresyonu, maliyet fonksiyonuna bir ceza terimi ekleyerek model katsayılarını küçülten bir başka doğrusal regresyon uzantısıdır.
Lasso regresyonda en aza indirilmesi gereken hata şöyledir:
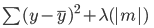
Bu denklemin ridge regresyon modeline benzediğine, ancak katsayının karesiyle lambda çarpmak yerine, katsayının mutlak değeriyle çarptığımıza dikkat edin.
Ridge ve lasso regresyonu arasındaki en büyük fark, ridge regresyonda model katsayılarının sıfıra yaklaşabilmesine rağmen asla tam olarak sıfır olmamasıdır. Lasso regresyonda ise model katsayılarının sıfır olması mümkündür.
Bir bağımsız değişkenin katsayısı sıfıra ulaşırsa, bu özellik modelden çıkarılabilir. Bu, özellik uzayını daraltır ve algoritmayı yorumlamayı kolaylaştırır; bu da lasso regresyonunun en büyük avantajıdır.
Bu nedenle lasso regresyonu, önemi düşük değişkenlerin katsayılarının sıfıra ulaşarak tamamen modelden çıkarılabilmesi sayesinde bir özellik seçimi tekniği olarak da kullanılabilir.
Scikit-Learn kütüphanesini kullanarak doğrusal, ridge ve lasso regresyon modelleri oluşturabilirsiniz:
1. Doğrusal Regresyon
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Modeli eğitim veri kümenize uydurmak için şunu çalıştırın:
lr_model.fit(X_train,y_train)2. Ridge Regresyonu
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)Lambda terimi, modeli tanımlarken “alpha” parametresi üzerinden yapılandırılabilir.
3. Lasso Regresyonu
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Doğrusal modeller ve bunların Python’da nasıl oluşturulacağı hakkında daha fazla bilgi edinmek isterseniz, Python’da Doğrusal Modellemenin Giriş kursumuzu alın.
Sınıflandırma algoritmalarını, bağımsız değişkenler (x) kullanarak ayrık bir çıktıyı (y) tahmin etmek için kullanırız. Bu durumda bağımlı değişken her zaman bir sınıf veya kategoridir.
Örneğin, bir hastanın risk faktörlerine göre kalp hastalığı geliştirme olasılığını tahmin etmek bir sınıflandırma problemidir:
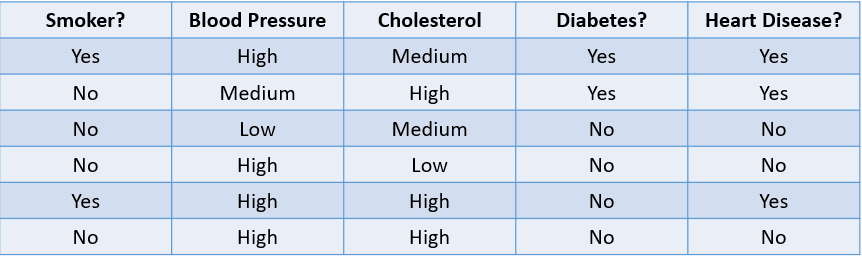
Görsel: yazar
Yukarıdaki tablo, dört bağımsız değişken ve bir bağımlı değişken (kalp hastalığı) içeren bir sınıflandırma problemini göstermektedir. Yalnızca iki olası sonuç (Evet ve Hayır) olduğu için buna ikili sınıflandırma problemi denir.
İkili sınıflandırmaya diğer örnekler: bir e-postanın spam olup olmadığını belirlemek, müşteri kaybı (churn) tahmini ve bir kişiye kredi verilip verilmeyeceğine karar vermek.
Çok sınıflı bir sınıflandırma problemi ise hava durumu tahmini veya farklı hayvan türlerini ayırt etmek gibi üç veya daha fazla olası sonuca sahiptir.
Bir sınıflandırma modelini değerlendirmenin birçok yolu vardır. Doğruluk en çok kullanılan ölçüt olsa da, her zaman en güvenilir olanı değildir.
Aşağıdaki veri kümesine dayalı olarak bir sınıflandırma algoritmasını değerlendirmek için kullanılan bazı yaygın yöntemlere bakalım:
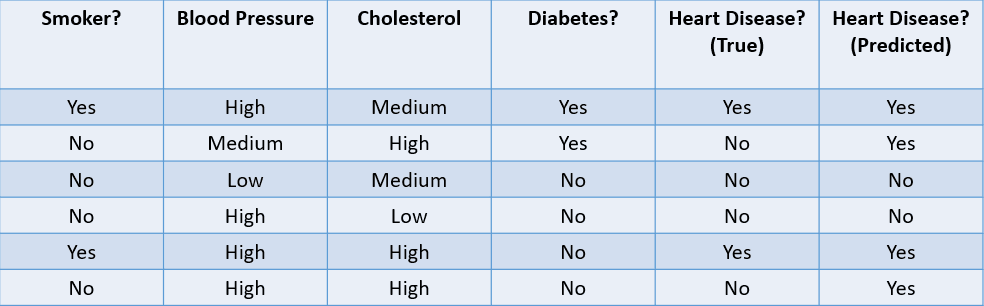
Görsel: yazar
1. Doğruluk (Accuracy): Doğruluk, makine öğrenimi modeli tarafından yapılan doğru tahminlerin oranı olarak tanımlanabilir.
Doğruluğu hesaplama formülü şöyledir:

Bu durumda doğruluk 4/6, yani 0,67’dir.
2. Kesinlik (Precision): Kesinlik, modelin yaptığı pozitif tahminlerin kalitesini hesaplamak için kullanılan bir ölçüttür. Şöyle tanımlanır:
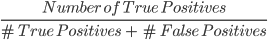
Yukarıdaki modelin kesinliği 2/4, yani 0,5’tir.
3. Duyarlılık (Recall): Duyarlılık, modelin negatif tahminlerinin kalitesini hesaplamak için kullanılır. Şöyle tanımlanır:
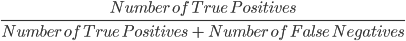
Yukarıdaki modelin duyarlılığı 2/2, yani 1’dir.
Kesinlik ve duyarlılık arasındaki farkı anlamak için basit bir örneğe bakalım:
Nüfusun küçük bir kısmını etkileyen nadir ve ölümcül bir hastalık vardır. Bir hastanenin veri tabanındaki hastaların %95’i bu hastalığa sahip değildir, yalnızca %5’i sahiptir. Eğer kimsenin hastalığı olmadığını tahmin eden bir makine öğrenimi algoritması kurarsak, bu modelin eğitim doğruluğu %95 olacaktır. Yüksek doğruluğa rağmen, hastalığı olan hastaları tanımlayamadığı için bunun iyi bir model olmadığını biliyoruz.
İşte bu noktada kesinlik ve duyarlılık gibi ölçütler devreye girer. Kesinlik (özgüllük), modelin hastalığı olmayan kişileri doğru tanımlama becerisini söyler. Duyarlılık (duyarlık), modelin hastalığı olan kişileri ne kadar iyi tanımladığını gösterir.
“İyi” bir kesinlik ve duyarlılık değeri özneldir ve kullanım durumunuza bağlıdır.
Bu hastalık tahmini senaryosunda, yanlış pozitif riski olsa bile hastalığı olan kişileri her zaman tespit etmek isteriz. Burada, modeli kesinlikten ziyade daha yüksek duyarlılığa sahip olacak şekilde kuracağız.
Öte yandan, kötü niyetli aktörlerin bir e-ticaret web sitesine girişini engelleyen bir model kuracak olsaydık, meşru kullanıcıları engellemek satışlarda düşüşe yol açacağından daha yüksek kesinlik isteyebiliriz.
Çoğu zaman, bir sınıflandırıcının kesinliği ve duyarlılığının harmonik ortalamasını bulmak için F1-Skoru adı verilen bir ölçüt kullanırız. Basitçe, F1-Skoru kesinlik ve duyarlılığı ortalamalarını alarak tek bir ölçütte birleştirir.
AUC (Eğri Altındaki Alan), bir sınıflandırma modelinin performansını ölçmek için kullanılan bir başka popüler ölçüttür. Bir algoritmanın AUC’si, pozitif ve negatif sınıfları ayırt etme becerisi hakkında bilgi verir.
AUC gibi ölçüler ve bunların nasıl hesaplandığı hakkında daha fazla bilgi edinmek için Datacamp’in R ile Gözetimli Öğrenme kursunu alın.
Şimdi, farklı sınıflandırma modeli türlerine ve nasıl çalıştıklarına bakalım:
Lojistik regresyon, bir olayın gerçekleşme olasılığını tahmin eden basit bir sınıflandırma modelidir.
İşte lojistik regresyon modelinin nasıl çalıştığına dair bir örnek:
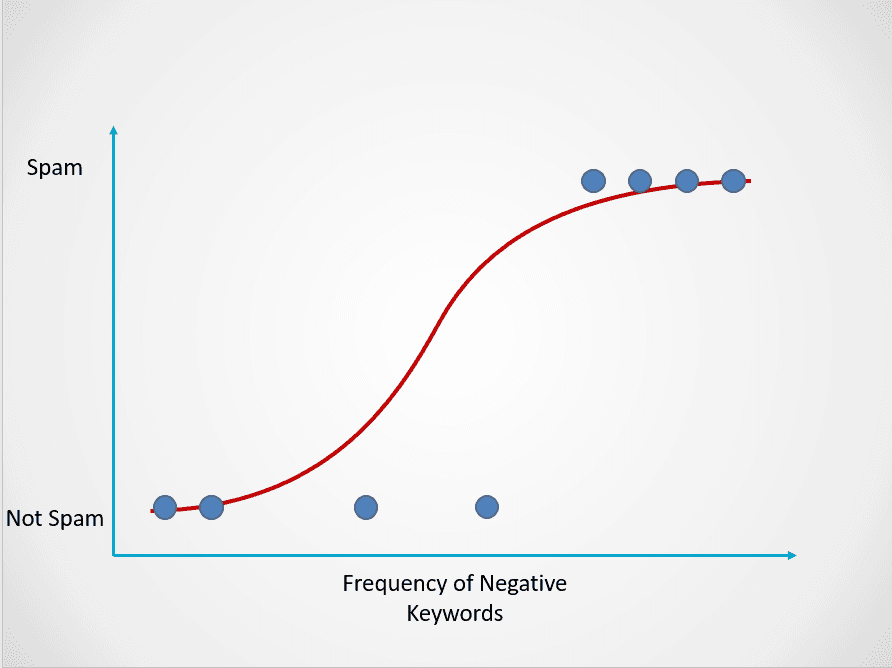
Görsel: yazar
Yukarıdaki grafik, metindeki olumsuz anahtar kelime sıklığına göre e-posta verilerini “Spam” ve “Spam Değil” olmak üzere iki kategoriye eşleyen lojistik fonksiyonu göstermektedir.
Doğrusal regresyon algoritmasından farklı olarak, lojistik regresyonun S şeklinde bir eğriyle modellendiğine dikkat edin. Bu, lojistik fonksiyon olarak bilinir ve aşağıdaki formüle sahiptir:
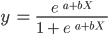
Doğrusal fonksiyonun bir üst ve alt sınırı yokken, lojistik fonksiyon 0 ile 1 arasında değişir. Model, 0 ile 1 arasında değişen bir olasılık tahmin eder ve bu, veri noktasının ait olduğu sınıfı belirler.
Bu spam e-posta örneğinde, metin çok az veya hiç şüpheli anahtar kelime içermiyorsa spam olma olasılığı düşük olacak ve 0’a yakın olacaktır. Öte yandan, çok sayıda şüpheli anahtar kelime içeren bir e-postanın spam olma olasılığı yüksek olacak ve 1’e yakın olacaktır.
Bu olasılık daha sonra bir sınıflandırma sonucuna dönüştürülür:
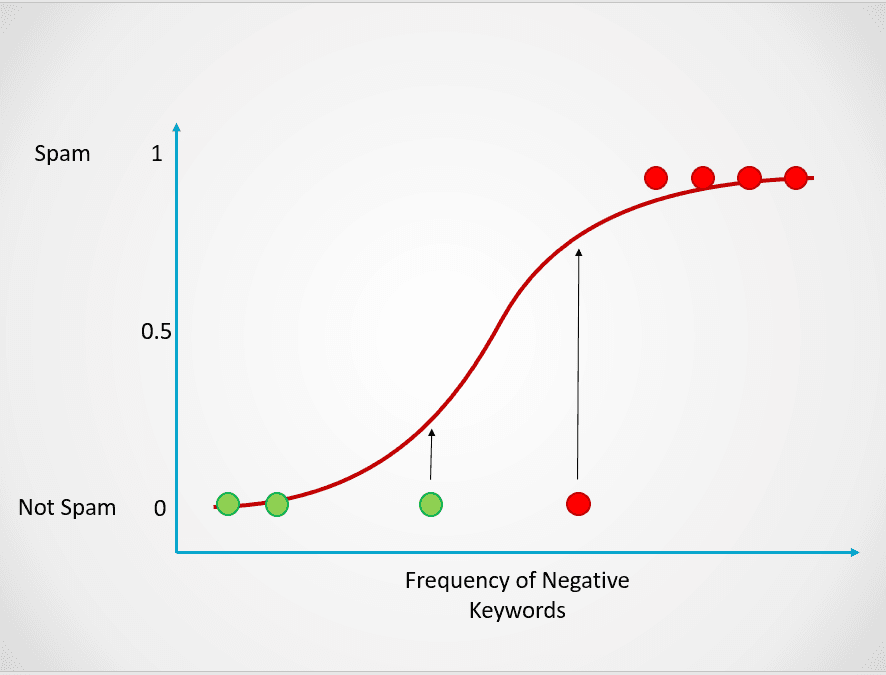
Görsel: yazar
Kırmızı renkle gösterilen tüm noktaların spam olma olasılığı >= 0,5’tir. Bu nedenle spam olarak sınıflandırılırlar ve lojistik regresyon modeli 1 sınıflandırma sonucu döndürür. Yeşil renkteki noktaların spam olma olasılığı < 0,5’tir; bu yüzden model tarafından “Spam Değil” olarak sınıflandırılır ve 0 sınıflandırma sonucu döndürürler.
Yukarıdaki gibi ikili sınıflandırma problemlerinde, lojistik regresyon modelinin varsayılan eşik değeri 0,5’tir; bu, 0,5’ten yüksek olasılığa sahip veri noktalarının otomatik olarak 1 etiketi alacağı anlamına gelir. Bu eşik değerini, kullanım durumunuza bağlı olarak daha iyi sonuçlar elde etmek için manuel olarak değiştirebilirsiniz.
Şimdi, doğrusal regresyonda en iyi uyum doğrusunu, tahmin edilen ve gerçek değerler arasındaki kareli hataların toplamını en aza indirerek bulduğumuzu hatırlayın. Ancak lojistik regresyonda, katsayılar en küçük kareler yerine azami olabilirlik kestirimi adı verilen bir teknik kullanılarak tahmin edilir.
Azami olabilirlik kestirimi kavramı ve lojistik regresyonun nasıl çalıştığı hakkında daha fazla bilgi edinmek için Python lojistik regresyon eğitimini okuyun.
KNN, bir veri noktasını, ona en yakın veri noktalarının ait olduğu gruba göre sınıflandıran bir sınıflandırma algoritmasıdır.
İşte K-En Yakın Komşu modelinin nasıl çalıştığını gösteren basit bir örnek:
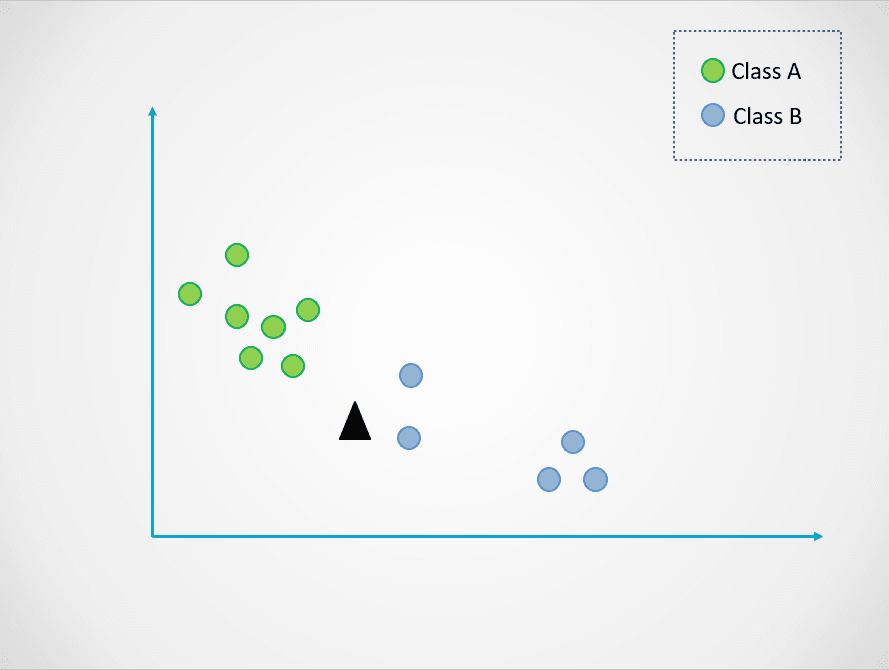
Görsel: yazar
Yukarıdaki diyagramda A ve B olmak üzere iki sınıf veri noktası vardır. Siyah üçgen, bu iki sınıftan birine sınıflandırılması gereken yeni bir veri noktasını temsil eder.
K-En Yakın Komşu algoritması şöyle çalışır:
Yukarıdaki görselde k değeri 1’dir. Bu, siyah üçgene yalnızca en yakın bir komşuya baktığımız ve veri noktasını o sınıfa atadığımız anlamına gelir. Yeni veri noktası mavi noktaya en yakındır; bu yüzden B sınıfına atarız.
Şimdi k değerini değiştirelim. 3 ve 7 olmak üzere iki olası k değeri deneyelim:
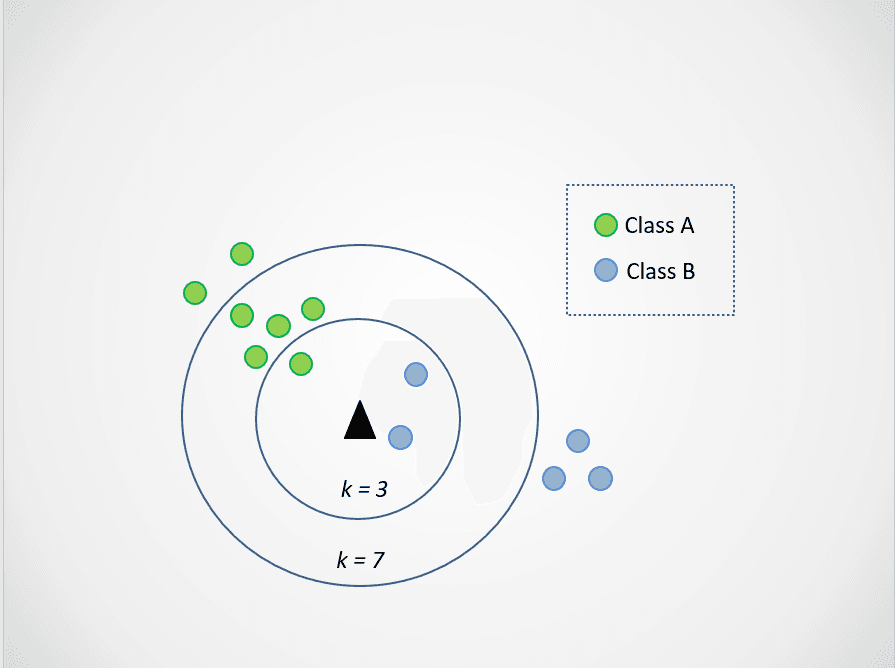
Görsel: yazar
Şimdi, k=3 seçtiğimizde, yeni veri noktasının iki kategori arasında kaldığına dikkat edin. Bu durumda çoğunluk sınıfını seçeriz. İki en yakın komşu mavi, bir en yakın komşu yeşildir; dolayısıyla veri noktası yine mavi noktaların sınıfı olan B sınıfına atanacaktır.
Ancak k=7 olduğunda işler değişir. Artık iki en yakın komşu mavi, yedisi yeşildir. Bu durumda veri noktası yeşil sınıfa, yani A sınıfına atanacaktır.
Farklı k değerleri seçmek, yeni noktanın hangi sınıfa atanacağını etkiler.
Çok küçük bir değer seçmek gürültülü olabilir ve aykırı değerlere duyarlıdır; büyük bir değer seçmek ise daha az veri noktasına sahip kategorileri gözden kaçırmanıza neden olabilir.
K-En Yakın Komşu algoritması ve en uygun “k” değerinin nasıl seçileceği hakkında daha fazla bilgi edinmek isterseniz, bu KNN eğitimini okuyun.
Scikit-Learn kütüphanesini kullanarak Python’da bir sınıflandırma modeli kurmak için kullanabileceğiniz bazı kod parçacıkları şunlardır:
1. Lojistik Regresyon
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-En Yakın Komşu
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Ağaç tabanlı modeller, tahmin yapmak için ağaç benzeri bir yapı oluşturan gözetimli makine öğrenimi algoritmalarıdır. Hem sınıflandırma hem de regresyon problemleri için kullanılabilirler.
Bu bölümde, en yaygın kullanılan ağaç tabanlı makine öğrenimi modellerinden ikisini inceleyeceğiz: karar ağaçları ve rastgele ormanlar.
Karar ağacı, en basit ağaç tabanlı makine öğrenimi algoritmasıdır. Bu model, nihai bir karar verilene kadar veri setini belirli parametrelere göre sürekli olarak bölmemize olanak tanır.
İşte karar ağacı algoritmasının nasıl çalıştığını gösteren basit bir örnek:
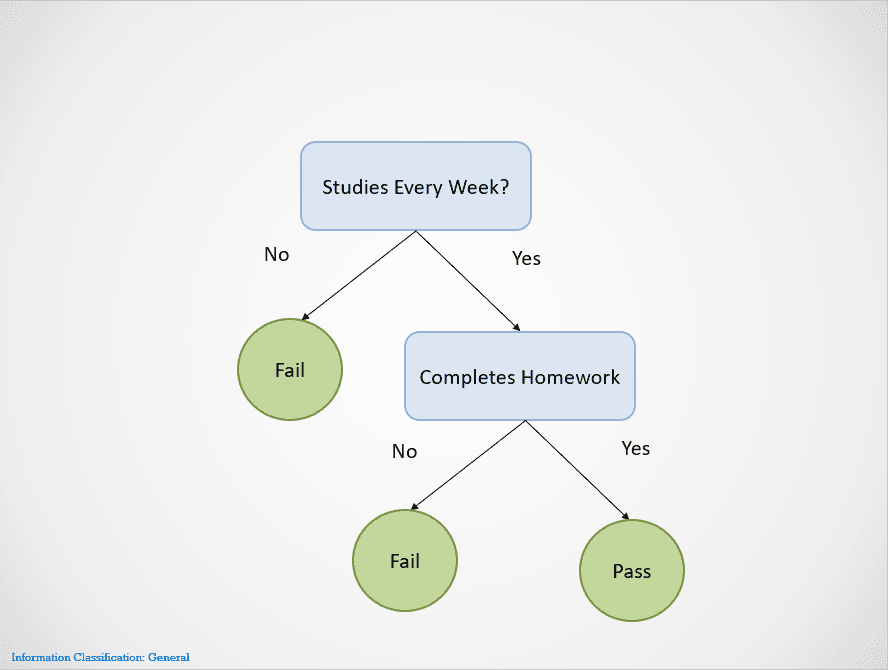
Görsel: yazar
Karar ağaçları, bir sonuca ulaşılana kadar farklı düğümler üzerinden bölme yapar.
Bu durumda, bir öğrenci her hafta çalışmıyorsa kalır. Her hafta çalışsa da ödevlerini tamamlamıyorsa sonuç yine “Kalır”dır. Sadece her hafta çalışır ve tüm ödevlerini bitirirse geçer.
Yukarıdaki karar ağacının önce “Her Hafta Çalışıyor mu?” değişkenine göre bölündüğüne dikkat edin. Yanıt “Hayır” ise bölmeyi durdurur ve öğrencinin kalacağını söyler.
Karar ağacı, önce hangi değişkende bölüneceğini, entropi adı verilen bir ölçüte göre seçer. Tüm veri noktaları tek bir sınıfa ait olduğunda, yani “saf bölünme” elde edildiğinde bölmeyi durdurur.
Bir karar ağacı pek çok şekilde oluşturulabilir. Ağaç, önce, ikinci, üçüncü vb. hangi özellikle bölüneceğini bulmalıdır. Bu yapı, bilgi kazanımı adı verilen bir ölçüte göre oluşturulur. En iyi karar ağacı, bilgi kazanımı en yüksek olandır.
Karar ağaçlarının nasıl çalıştığı ve entropi ile bilgi kazanımı gibi ölçütler hakkında daha fazla bilgi edinmek için bu Python karar ağacı sınıflandırma makalesi daha fazla ayrıntı içerir.
Karar ağaçlarının en büyük avantajlarından biri yüksek yorumlanabilir olmalarıdır. Eğitim veri kümesine dayanarak bir karar ağacının nihai sonuca nasıl ulaştığını geriye dönük anlamak kolaydır.
Bununla birlikte, karar ağaçları tamamen büyümeye bırakılırsa aşırı öğrenmeye oldukça yatkındır. Bunun nedeni, eğitim veri kümesindeki tüm örnekler üzerinde kusursuz bölünmeler yapacak şekilde tasarlanmalarıdır; bu da harici verilere iyi genelleme yapamamalarına yol açar.
Karar ağaçlarının bu dezavantajı, rastgele orman algoritması kullanılarak çözülebilir.
Rastgele orman modeli, karar ağaçları kullanılırken ortaya çıkan sorunlardan bazılarını, özellikle aşırı öğrenmeyi hafifletmemize yardımcı olan ağaç tabanlı bir algoritmadır. Rastgele ormanlar, birden çok karar ağacı modelinin yaptığı tahminleri birleştirerek tek bir çıktı döndürür.
Bunu iki adımda yapar:
Regresyon probleminde ise sonuç, tüm karar ağaçlarının ortalama tahmini olacaktır.
İşte rastgele orman algoritmasının nasıl çalıştığını gösteren basit bir görsel:
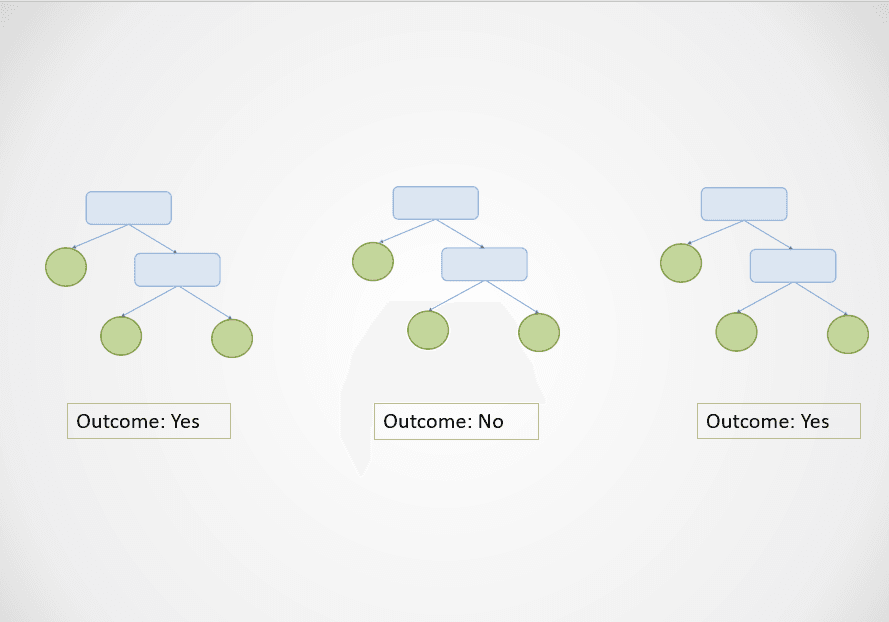
Görsel: yazar
Yukarıdaki diyagramda birinci ve üçüncü karar ağacı “Evet”, ikincisi ise “Hayır” tahmin etmiştir.
Bu bir sınıflandırma görevi olduğundan, çoğunluk sınıfı seçilir. Bu durumda, 3 karar ağacından 2’sinin tahminine dayanarak rastgele orman algoritması nihai sonuç olarak “Evet” döndürecektir.
Rastgele orman algoritmasının en büyük avantajlarından biri, birden çok karar ağacının çıktılarını, özelliklerin bir alt kümesi üzerinde eğitilerek birleştirmesi nedeniyle iyi genelleme yapabilmesidir.
Ayrıca, tek bir karar ağacının çıktısı eğitim veri kümesindeki küçük bir değişikliğe bağlı olarak büyük ölçüde değişebilirken, rastgele orman algoritmasında eğitim veri kümesi birçok kez örneklendiği için bu sorun ortaya çıkmaz.
Scikit-Learn ile ağaç tabanlı bir makine öğrenimi algoritması kurmak için aşağıdaki kod satırlarını çalıştırın:
1. Karar Ağacı
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Rastgele Ormanlar
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Şimdiye kadar sınıflandırma ve regresyon problemlerini ele almak için gözetimli makine öğrenimi modellerini inceledik. Şimdi, kümeleme adı verilen popüler bir gözetimsiz öğrenme yaklaşımına dalacağız.
Basitçe, kümeleme birbirine benzer olan nesneleri, diğerlerinden farklı olacak şekilde gruplama işidir. Bu tekniğin, bir video akış sitesinde benzer izleme kalıplarına sahip kullanıcılara film önermek, anomali tespiti ve müşteri segmentasyonu gibi çeşitli iş kullanım alanları vardır.
Bu bölümde, gözetimsiz öğrenme görevleri için kullanılan en basit ve en popüler makine öğrenimi modeli olan K-Ortalamalar (K-Means) kümelemesi adlı bir algoritmayı inceleyeceğiz.
K-Ortalamalar kümelemesi, verideki benzer nesneleri bir araya toplamak için kullanılan gözetimsiz bir makine öğrenimi tekniğidir.
İşte K-Ortalamalar kümelemesi algoritmasının nasıl çalıştığına dair bir örnek:

Görsel: yazar
Adım 1: Yukarıdaki görsel, henüz gruplandırılmamış etiketlenmemiş gözlemlerden oluşur. Başlangıçta, her bir gözlem rastgele bir kümeye atanacaktır. Daha sonra her küme için bir merkez (centroid) hesaplanacaktır.
Bunlar aşağıdaki diyagramda “+” sembolüyle gösterilmiştir:
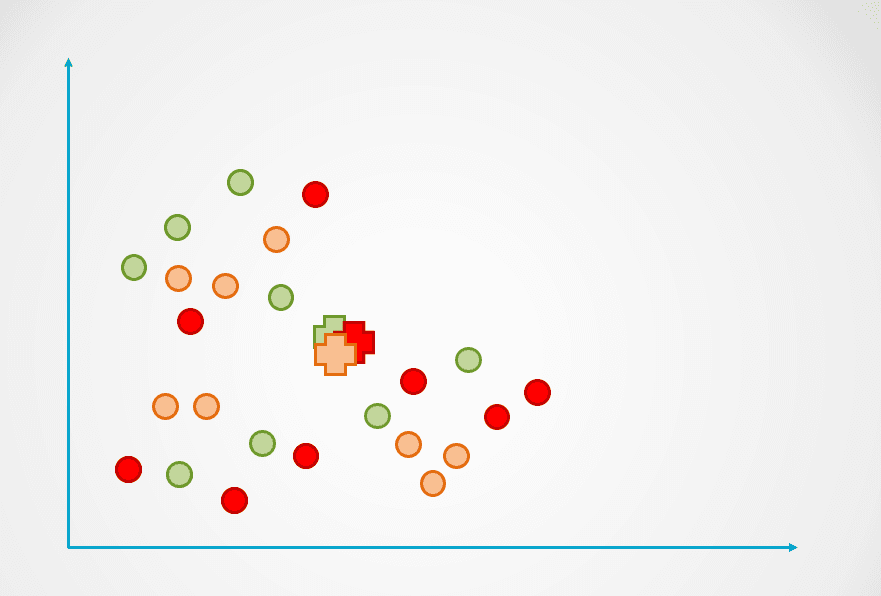
Görsel: yazar
Adım 2: Daha sonra, her veri noktasının merkeze olan mesafesi ölçülür ve her nokta en yakın merkeze atanır:
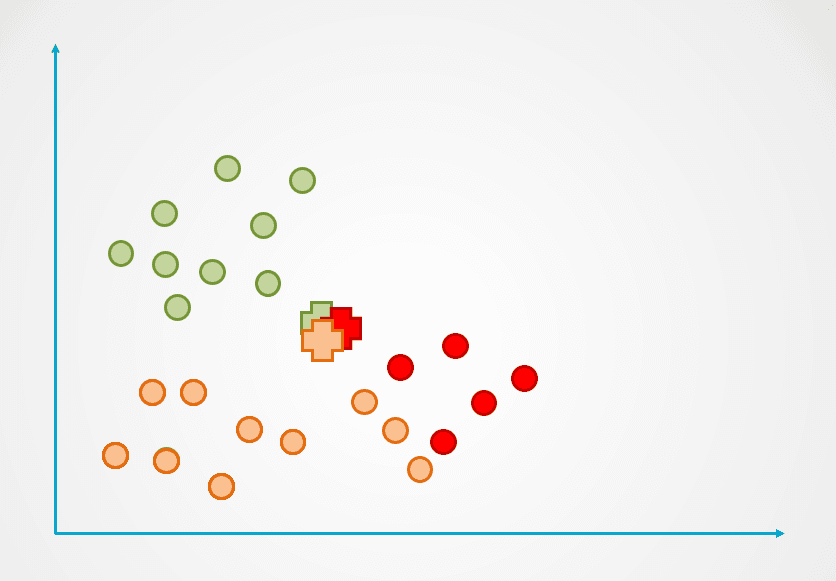
Görsel: yazar
Adım 3: Yeni kümenin merkezi yeniden hesaplanır ve veri noktaları buna göre yeniden atanır.
Adım 4: Veri noktaları artık yeniden atanmaya devam etmediği ana kadar bu süreç tekrarlanır:
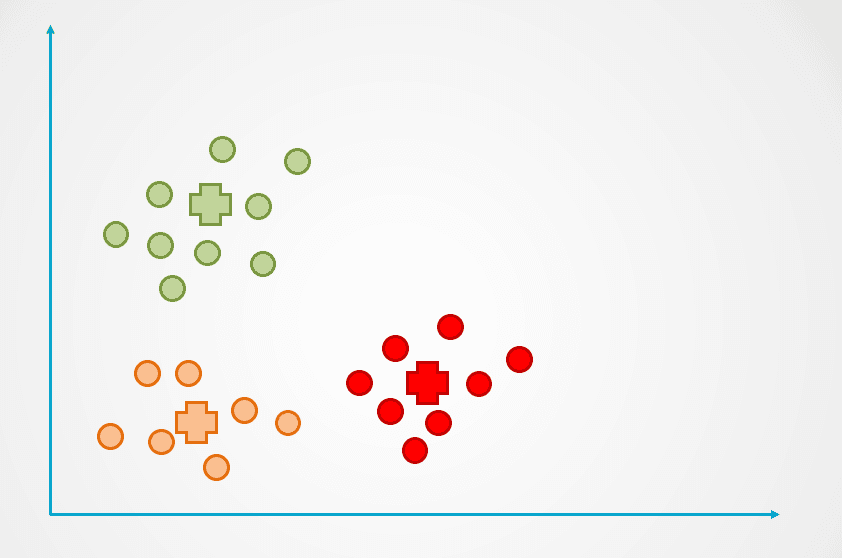
Görsel: yazar
Yukarıdaki örnekte üç küme oluşturulduğuna dikkat edin. K-Ortalamalar kümeleme algoritmasında küme sayısı “k” olarak adlandırılır ve bunu bizim belirlememiz gerekir.
K-Ortalamalarda “k” seçmenin birkaç farklı yolu vardır; bunların en popüleri dirsek yöntemidir. Bu teknik, farklı küme sayıları için hatayı bir grafikte çizmek ve eğrinin kırılma noktasını “k” olarak seçmekten oluşur.
Dirsek yöntemi ve K-Ortalamalar kümelemesinin iç işleyişini keşfetmek için Python ile K-Ortalamalar kümeleme eğitimimizde daha fazla bilgi edinin.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')n_clusters bağımsız değişkeni, algoritmayı kurarken tanımlamanız gereken “k” küme sayısını belirtir.
Bu makalenin tamamını takip edebildiyseniz tebrikler! Artık en popüler gözetimli ve gözetimsiz makine öğrenimi modellerinin ve algoritmalarının bazılarını ve bunların çeşitli kestirimsel modelleme problemlerini çözmek için nasıl uygulanacağını biliyorsunuz.
Bir veri bilimci olmak için, farklı makine öğrenimi modeli türlerinin nasıl çalıştığını anlamanız ve bunları bir problemi çözmek için uygulayabilmeniz gerekir. Örneğin, yorumlanabilir ve düşük hesaplama süresine sahip bir model oluşturmak istiyorsanız, bir karar ağacı oluşturmak mantıklı olabilir. Öte yandan, amacınız iyi genelleme yapan bir model kurmaksa, bunun yerine bir rastgele orman algoritması oluşturmayı tercih edebilirsiniz.
Ayrıca makine öğrenimi modellerini nasıl değerlendireceğinizi anlamak da önemlidir. “İyi” bir model özneldir ve kullanım durumunuza büyük ölçüde bağlıdır. Örneğin, sınıflandırma problemlerinde yalnızca yüksek doğruluk iyi bir model göstergesi değildir. Bir veri bilimci olarak, modelinizin ne kadar iyi performans gösterdiğini daha iyi anlamak için kesinlik, duyarlılık ve F1-Skoru gibi ölçütleri gözden geçirmeniz gerekir.
Bu makalede ele alınan kavramların ötesinde makine öğrenimi modellerini daha derinlemesine anlamak isterseniz, Python ile Makine Öğrenimi Bilimcisi kursunu alın. Bu kariyer yolu, makine öğrenimi modellerinin nasıl çalıştığının teorisini ve Python’da nasıl uygulanacaklarını öğretecektir. Ayrıca derste normalleştirme, korelasyonun giderilmesi ve özellik seçimi gibi veri hazırlama tekniklerini de öğreneceksiniz.
Makine Öğrenimi Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
