Courses
Machine Learning với mô hình dựa trên cây trong Python
5 giờ
117.2K
Ngày nay, nhiều tổ chức lớn sử dụng một số hình thức mô hình dự đoán để tối đa hóa doanh thu và thúc đẩy tăng trưởng.
Machine learning có nhiều trường hợp sử dụng ở các lĩnh vực khác nhau. Chẳng hạn, các nền tảng đăng ký như Netflix và Spotify dùng machine learning để gợi ý nội dung dựa trên hoạt động của người dùng trên ứng dụng.
Hệ thống gợi ý mang lại giá trị kinh doanh trực tiếp vì trải nghiệm người dùng tốt hơn sẽ khiến khách hàng có khả năng tiếp tục gia hạn đăng ký. Đây là ví dụ về mô hình machine learning không giám sát.
Tương tự, một nhà cung cấp dịch vụ di động có thể dùng machine learning để phân tích cảm nhận người dùng và điều chỉnh gói sản phẩm theo nhu cầu thị trường. Đây là ví dụ về mô hình machine learning có giám sát.
Tất cả mô hình machine learning có thể được phân loại thành có giám sát hoặc không giám sát. Khác biệt lớn nhất là thuật toán có giám sát cần dữ liệu huấn luyện đầu vào và đầu ra đã gán nhãn, trong khi mô hình không giám sát có thể xử lý tập dữ liệu thô, chưa gán nhãn.
Mô hình machine learning có giám sát sau đó có thể phân loại chi tiết hơn thành thuật toán hồi quy và phân loại, sẽ được giải thích kỹ hơn trong bài viết này.
Thuật toán hồi quy được dùng để dự đoán một kết quả liên tục (y) dựa trên các biến độc lập (x).
Ví dụ, xem bảng dưới đây:
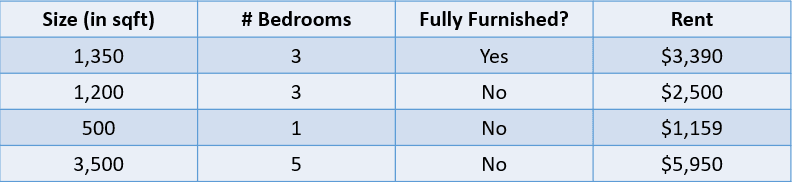
Hình do tác giả cung cấp
Trong trường hợp này, chúng ta muốn dự đoán tiền thuê nhà dựa trên diện tích, số phòng ngủ và việc có nội thất đầy đủ hay không. Biến phụ thuộc “Rent” là số, điều này khiến đây là bài toán hồi quy.
Một bài toán có nhiều biến đầu vào như trên được gọi là hồi quy đa biến.
Một ngộ nhận thường thấy ở người mới học khoa học dữ liệu là mô hình hồi quy có thể được đánh giá bằng độ chính xác (accuracy). Accuracy là thước đo dùng để đánh giá hiệu năng của mô hình phân loại, sẽ được giải thích sau trong bài viết.
Ngược lại, mô hình hồi quy được đánh giá bằng các thước đo như MAE (Mean Absolute Error), MSE (Mean Squared Error) và RMSE (Root Mean Squared Error).
Hãy thêm giá trị dự đoán vào bài toán giá thuê nhà phía trên và đánh giá các dự đoán này bằng một vài thước đo hồi quy:

Hình do tác giả cung cấp
MAE tính tổng chênh lệch giữa tất cả giá trị thực và dự đoán, rồi chia cho tổng số quan sát. Đây là công thức tính MAE:
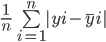
Hãy tính MAE của các giá trị trên bằng công thức này:
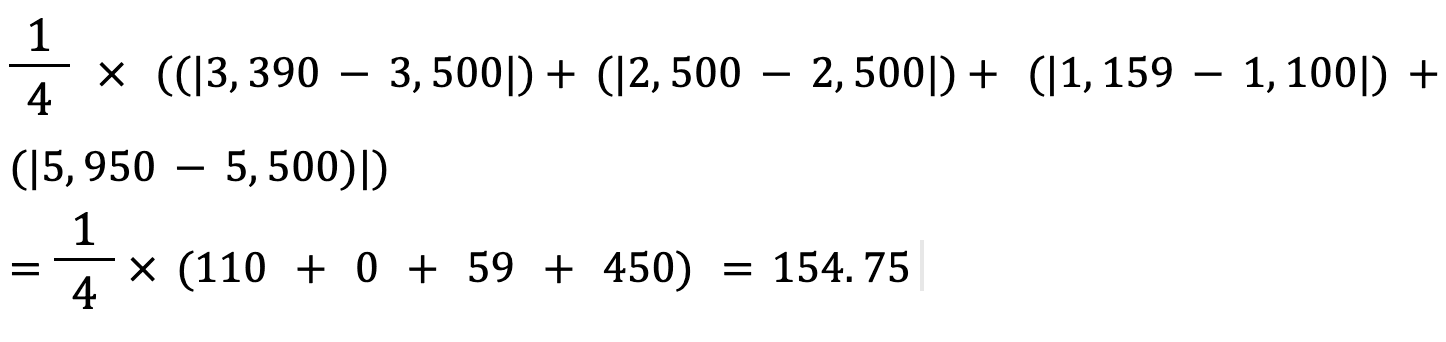
MAE giữa giá thực và giá dự đoán của nhà vào khoảng 155 USD.
Công thức tính MSE của mô hình tương tự như MAE:
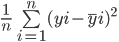
Lưu ý trong khi MAE tính khoảng cách tuyệt đối trung bình giữa giá trị thực và dự đoán, MSE tìm khoảng cách bình phương trung bình giữa chúng.
Hãy tính MSE giữa các giá trị thực và dự đoán ở trên:
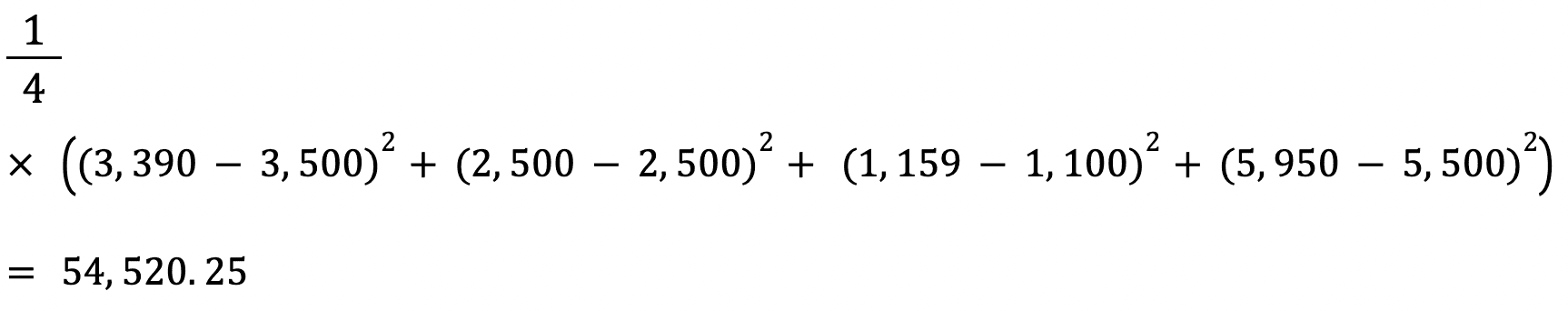
RMSE của một ước lượng được tính bằng căn bậc hai của MSE. Một lợi thế của RMSE so với MSE là sai số trả về cùng đơn vị với biến ta đang dự đoán.
Trong trường hợp này, chẳng hạn, RMSE là √54.520,25 = 233,5. Giá trị này có thể diễn giải vì tính theo đơn vị giá thuê nhà, trong khi MSE thì không.
Giờ bạn đã hiểu khái niệm hồi quy, hãy xem các loại mô hình hồi quy khác nhau:
Hồi quy tuyến tính là cách tiếp cận tuyến tính để mô hình hóa mối quan hệ giữa một biến phụ thuộc và một hoặc nhiều biến độc lập. Thuật toán này tìm một đường thẳng khớp tốt nhất với dữ liệu hiện có.
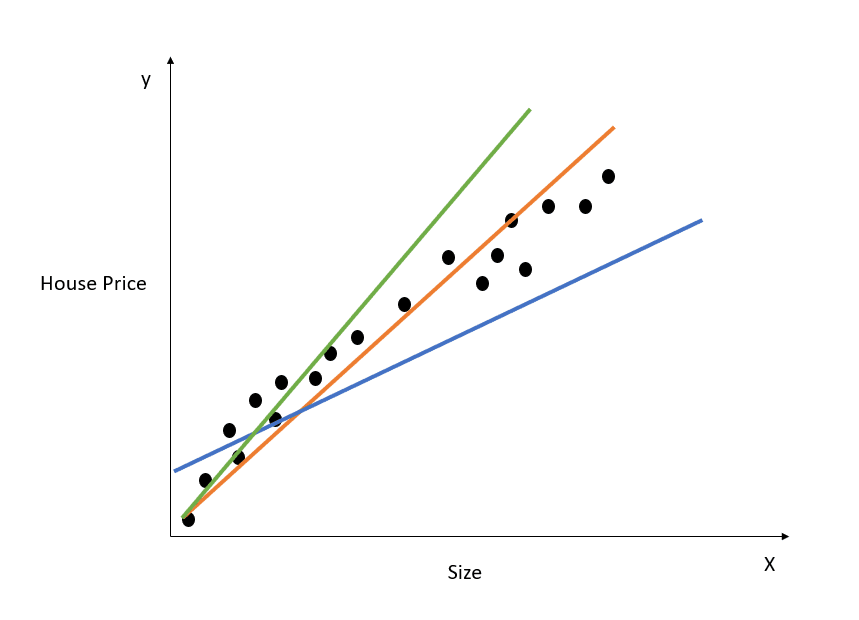
Đây là minh họa trực quan cách mô hình hồi quy tuyến tính đơn hoạt động:
Hình do tác giả cung cấp
Biểu đồ trên thể hiện mối quan hệ giữa giá nhà và diện tích. Mô hình hồi quy tuyến tính sẽ tạo ra một đường thẳng mô tả tốt nhất mối quan hệ này. Mọi dự đoán giá nhà tương ứng với các giá trị diện tích khác nhau sẽ nằm trên đường khớp tốt nhất.
Quan sát có ba đường được vẽ. Đường nào là “đường khớp tốt nhất”?
Chỉ cần nhìn biểu đồ, ta thấy đường màu cam gần với tất cả các điểm dữ liệu nhất. Do đó, trực quan mà nói, đó là “đường khớp tốt nhất.”
Dưới đây là giải thích chính quy hơn về cách tìm đường khớp tốt nhất trong hồi quy tuyến tính:
Phương trình đường thẳng là y = mx + c. Ở đây, m là độ dốc và c là giao điểm với trục y. Có vô số cách vẽ đường này vì có vô số giá trị khả dĩ cho m và c.
Đường khớp tốt nhất, còn gọi là đường hồi quy bình phương tối thiểu, được tìm bằng cách tối thiểu hóa tổng khoảng cách bình phương giữa giá trị thực và dự đoán:
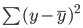
Bạn có thể đọc bài hướng dẫn Các yếu tố thiết yếu của hồi quy tuyến tính trong Python để hiểu sâu hơn về mô hình hồi quy tuyến tính và cách triển khai.
Hồi quy ridge là một phần mở rộng của mô hình hồi quy tuyến tính ở trên. Đây là kỹ thuật nhằm giữ cho các hệ số của mô hình hồi quy nhỏ nhất có thể.
Một vấn đề của hồi quy tuyến tính đơn là hệ số có thể trở nên lớn, khiến mô hình nhạy với đầu vào hơn. Điều này có thể dẫn đến quá khớp (overfitting).
Hãy lấy một ví dụ đơn giản để hiểu khái niệm quá khớp:
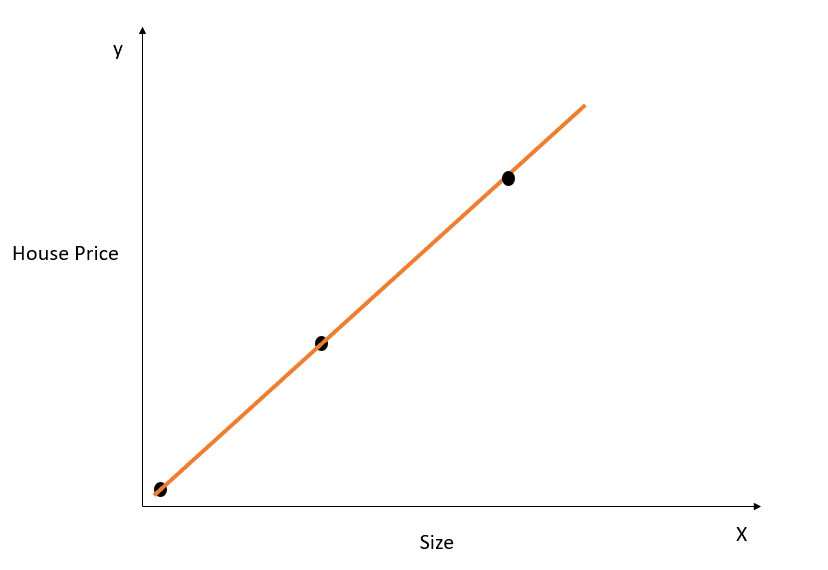
Hình do tác giả cung cấp
Trong hình trên, đường khớp tốt nhất mô tả hoàn hảo mối quan hệ giữa X và y, và tổng khoảng cách bình phương giữa giá trị thực và dự đoán bằng 0. Nhớ rằng phương trình của đường này là y = mx + c.
Dù đường này khớp hoàn hảo trên dữ liệu huấn luyện, nó có thể không khái quát hóa tốt trên dữ liệu kiểm tra. Hiện tượng này gọi là quá khớp; bạn có thể đọc thêm bài về overfitting để tìm hiểu thêm.
Nói đơn giản, mô hình quá phức tạp sẽ học cả những chi tiết vụn vặt của dữ liệu huấn luyện không phản ánh thế giới thực. Mô hình sẽ hoạt động cực tốt trên dữ liệu huấn luyện nhưng kém trên dữ liệu ngoài tập huấn luyện.
Một mô hình hồi quy tuyến tính với hệ số lớn dễ bị quá khớp.
Hồi quy ridge là một kỹ thuật regularization buộc thuật toán chọn hệ số nhỏ hơn bằng cách phạt hàm mất mát với một chi phí bổ sung.
Như phần trước đã nêu, đây là lỗi mà ta muốn tối thiểu hóa trong hồi quy tuyến tính đơn:
Trong hồi quy ridge, phương trình này sẽ thay đổi một chút, và một hạng phạt sẽ được thêm vào lỗi trên:
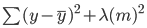
Lưu ý có một giá trị (lambda) nhân với các hệ số của mô hình. Vì mô hình này chỉ có một biến, có một hệ số với hạng phạt đi kèm. Nếu có nhiều biến độc lập, lambda sẽ nhân với tổng bình phương các hệ số.
Hạng phạt này “trừng phạt” mô hình khi chọn hệ số lớn. Mục tiêu là làm co nhỏ các hệ số để những biến đóng góp ít vào kết quả sẽ có hệ số gần 0. Điều này giảm phương sai mô hình và giúp giảm quá khớp.
Quan sát rằng lambda bằng 0 sẽ không có tác dụng gì, và hạng phạt bị loại bỏ. Giá trị lambda cao hơn sẽ thêm mức phạt co lớn hơn, và các hệ số sẽ tiến gần về 0.
Khi chọn lambda, hãy cân bằng giữa sự đơn giản và mức độ khớp tốt với dữ liệu huấn luyện. Lambda cao cho mô hình đơn giản, khái quát hóa tốt, nhưng quá cao có nguy cơ thiếu khớp (underfitting). Ngược lại, chọn lambda quá gần 0 có thể dẫn đến mô hình quá phức tạp.
Hồi quy lasso là một phần mở rộng khác của hồi quy tuyến tính, làm co hệ số mô hình bằng cách thêm hạng phạt vào hàm chi phí.
Đây là lỗi cần tối thiểu hóa trong hồi quy lasso:
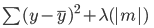
Lưu ý phương trình này giống hồi quy ridge, ngoại trừ việc thay vì nhân lambda với bình phương hệ số, ta nhân với giá trị tuyệt đối của hệ số.
Khác biệt lớn nhất giữa ridge và lasso là trong ridge, dù hệ số có thể co về gần 0, chúng không thực sự bằng 0. Trong lasso, hệ số mô hình có thể bằng 0.
Nếu hệ số của một biến độc lập về 0, đặc trưng đó có thể bị loại khỏi mô hình. Điều này giảm không gian đặc trưng và giúp thuật toán dễ diễn giải hơn, đây là ưu điểm lớn nhất của lasso.
Vì vậy, hồi quy lasso cũng có thể dùng như kỹ thuật chọn đặc trưng, vì các biến ít quan trọng có thể có hệ số về 0 và bị loại hoàn toàn khỏi mô hình.
Bạn có thể xây dựng các mô hình hồi quy tuyến tính, ridge và lasso bằng thư viện Scikit-Learn:
1. Hồi quy tuyến tính
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Để huấn luyện mô hình trên tập dữ liệu training, chạy:
lr_model.fit(X_train,y_train)2. Hồi quy Ridge
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)Tham số lambda có thể cấu hình qua tham số “alpha” khi định nghĩa mô hình.
3. Hồi quy Lasso
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Nếu bạn muốn học thêm về các mô hình tuyến tính và cách xây dựng chúng trong Python, hãy tham gia khóa Giới thiệu mô hình tuyến tính trong Python.
Chúng ta dùng thuật toán phân loại để dự đoán một kết quả rời rạc (y) dựa trên các biến độc lập (x). Biến phụ thuộc trong trường hợp này luôn là một lớp hoặc danh mục.
Ví dụ, dự đoán khả năng một bệnh nhân mắc bệnh tim dựa trên các yếu tố rủi ro là một bài toán phân loại:
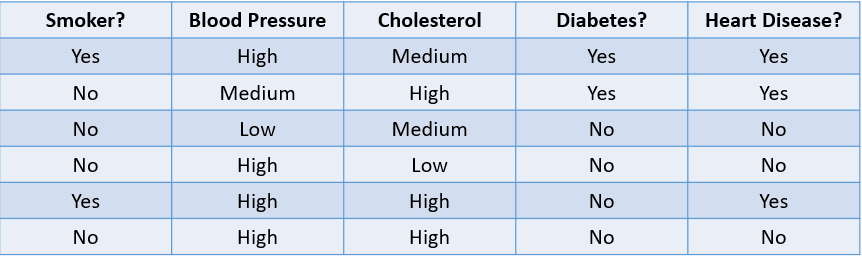
Hình do tác giả cung cấp
Bảng trên minh họa bài toán phân loại với bốn biến độc lập và một biến phụ thuộc là bệnh tim. Vì chỉ có hai kết quả khả dĩ (Yes và No), đây gọi là bài toán phân loại nhị phân.
Các ví dụ khác của phân loại nhị phân gồm phân loại email là spam hay hợp lệ, dự đoán rời bỏ khách hàng, và quyết định có cấp khoản vay cho ai đó hay không.
Bài toán phân loại đa lớp có ba hoặc nhiều kết quả, như dự báo thời tiết hoặc phân biệt các loài động vật.
Có nhiều cách đánh giá mô hình phân loại. Dù accuracy là thước đo dùng nhiều nhất, nó không phải lúc nào cũng đáng tin cậy nhất.
Hãy xem một số phương pháp phổ biến để đánh giá thuật toán phân loại dựa trên tập dữ liệu dưới đây:
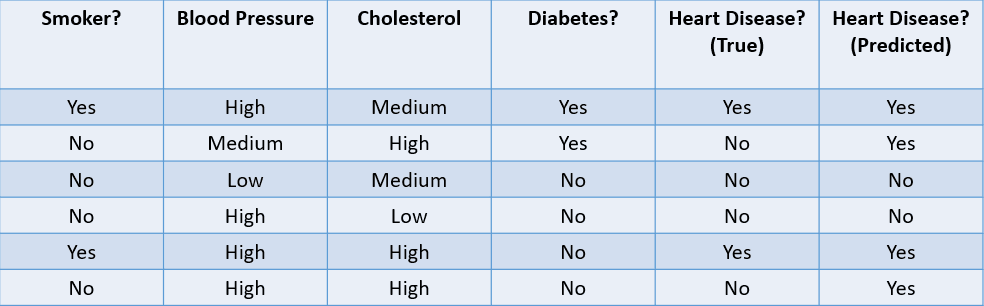
Hình do tác giả cung cấp
1. Accuracy: Accuracy được định nghĩa là tỷ lệ dự đoán đúng do mô hình machine learning đưa ra.
Công thức tính accuracy là:

Trong trường hợp này, accuracy là 4/6, tức 0,67.
2. Precision: Precision là thước đo chất lượng các dự đoán dương tính do mô hình đưa ra. Được định nghĩa là:
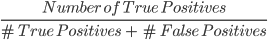
Mô hình trên có precision là 2/4, tức 0,5.
3. Recall: Recall dùng để tính chất lượng các dự đoán âm tính do mô hình đưa ra. Được định nghĩa là:
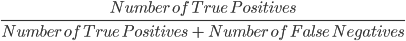
Mô hình trên có recall là 2/2 hay 1.
Hãy xem ví dụ đơn giản để hiểu khác biệt giữa precision và recall:
Có một căn bệnh hiếm, gây tử vong ảnh hưởng đến một phần nhỏ dân số. 95% bệnh nhân trong cơ sở dữ liệu bệnh viện không mắc bệnh, chỉ 5% mắc. Nếu ta xây mô hình dự đoán không ai mắc bệnh, accuracy huấn luyện của mô hình sẽ là 95%. Dù accuracy cao, ta biết đây không phải mô hình tốt vì không nhận diện được bệnh nhân mắc bệnh.
Đây là lúc các thước đo như precision và recall phát huy tác dụng. Precision (độ đặc hiệu) cho biết khả năng mô hình nhận diện đúng người không mắc bệnh. Recall (độ nhạy) cho biết mô hình nhận diện tốt người mắc bệnh đến đâu.
Giá trị precision và recall “tốt” là chủ quan và phụ thuộc trường hợp sử dụng.
Trong kịch bản dự đoán bệnh này, ta luôn muốn nhận diện người mắc bệnh, ngay cả khi có nguy cơ dương tính giả. Ở đây, ta sẽ xây mô hình ưu tiên recall cao hơn precision.
Ngược lại, nếu xây mô hình ngăn chặn tác nhân độc hại truy cập website thương mại điện tử, ta có thể muốn precision cao hơn vì chặn nhầm người dùng hợp pháp sẽ làm giảm doanh số.
Chúng ta thường dùng thước đo gọi là F1-Score để tìm trung bình điều hòa của precision và recall. Nói đơn giản, F1-Score kết hợp precision và recall thành một thước đo bằng cách tính trung bình của chúng.
AUC (Area Under the Curve) là thước đo phổ biến khác dùng để đo hiệu năng mô hình phân loại. AUC cho biết khả năng thuật toán phân biệt giữa lớp dương và âm.
Để tìm hiểu thêm về các thước đo như AUC và cách tính, hãy tham gia khóa Supervised Learning in R của Datacamp.
Giờ, hãy xem các loại mô hình phân loại khác nhau và cách chúng hoạt động:
Hồi quy logistic là mô hình phân loại đơn giản dự đoán xác suất một sự kiện xảy ra.
Dưới đây là ví dụ cách mô hình hồi quy logistic hoạt động:
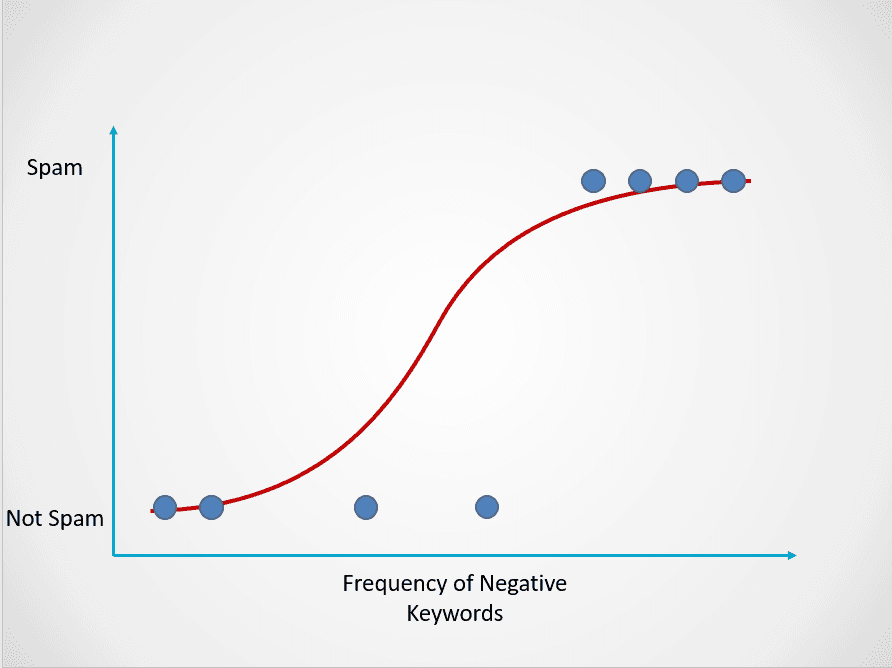
Hình do tác giả cung cấp
Biểu đồ trên hiển thị hàm logistic ánh xạ dữ liệu email vào hai nhóm: “Spam” và “Không spam” dựa trên tần suất từ khóa tiêu cực trong nội dung.
Khác với hồi quy tuyến tính, hồi quy logistic được mô hình bằng đường cong hình chữ S. Đây là hàm logistic với công thức sau:
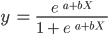
Trong khi hàm tuyến tính không có cận trên và cận dưới, hàm logistic nằm trong khoảng từ 0 đến 1. Mô hình dự đoán một xác suất trong khoảng 0–1, xác định lớp mà điểm dữ liệu thuộc về.
Trong ví dụ email rác này, nếu nội dung chứa rất ít hoặc không có từ khóa đáng ngờ, xác suất là spam sẽ thấp và gần 0. Ngược lại, email có nhiều từ khóa đáng ngờ sẽ có xác suất là spam cao, gần 1.
Sau đó, xác suất này được chuyển thành kết quả phân loại:
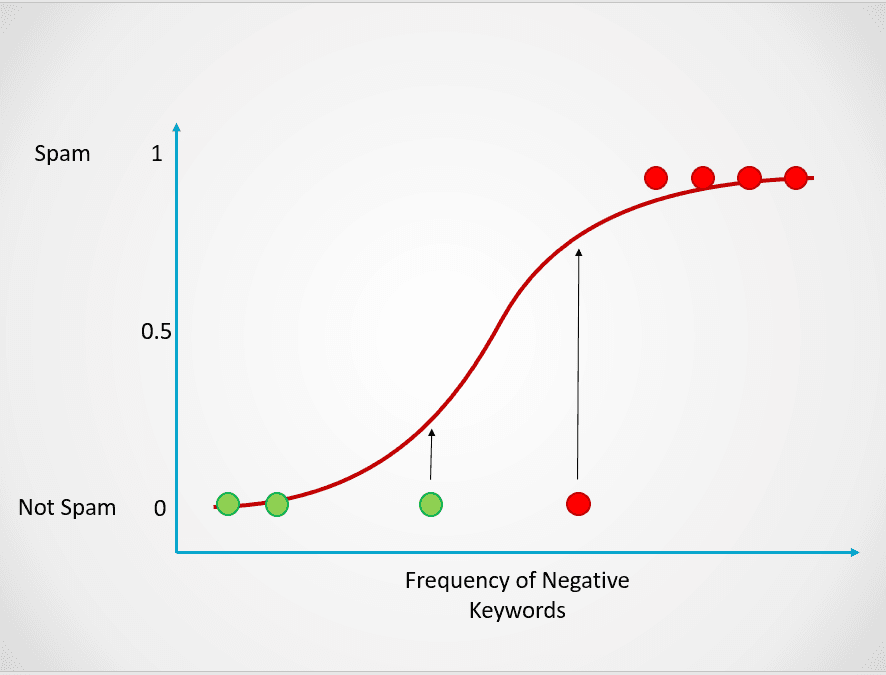
Hình do tác giả cung cấp
Tất cả các điểm màu đỏ có xác suất >= 0,5 là spam. Do đó, chúng được phân loại là spam và mô hình hồi quy logistic trả về kết quả phân loại là 1. Các điểm màu xanh lá có xác suất < 0,5 là spam, nên được mô hình phân loại là “Không spam” và trả về 0.
Với các bài toán phân loại nhị phân như trên, ngưỡng mặc định của hồi quy logistic là 0,5, nghĩa là điểm dữ liệu có xác suất lớn hơn 0,5 sẽ tự động được gán nhãn 1. Giá trị ngưỡng này có thể thay đổi thủ công tùy theo trường hợp sử dụng để đạt kết quả tốt hơn.
Nhắc lại, trong hồi quy tuyến tính, ta tìm đường khớp tốt nhất bằng cách tối thiểu hóa tổng sai số bình phương giữa giá trị dự đoán và thực. Tuy nhiên, trong hồi quy logistic, các hệ số được ước lượng bằng kỹ thuật ước lượng hợp lý cực đại (maximum likelihood estimation) thay vì bình phương tối thiểu.
Đọc bài hướng dẫn hồi quy logistic trong Python để tìm hiểu thêm về ước lượng hợp lý cực đại và cách hồi quy logistic hoạt động.
KNN là thuật toán phân loại phân loại một điểm dữ liệu dựa trên nhóm mà các điểm dữ liệu gần nó nhất thuộc về.
Dưới đây là ví dụ đơn giản minh họa cách mô hình K-Nearest Neighbors hoạt động:
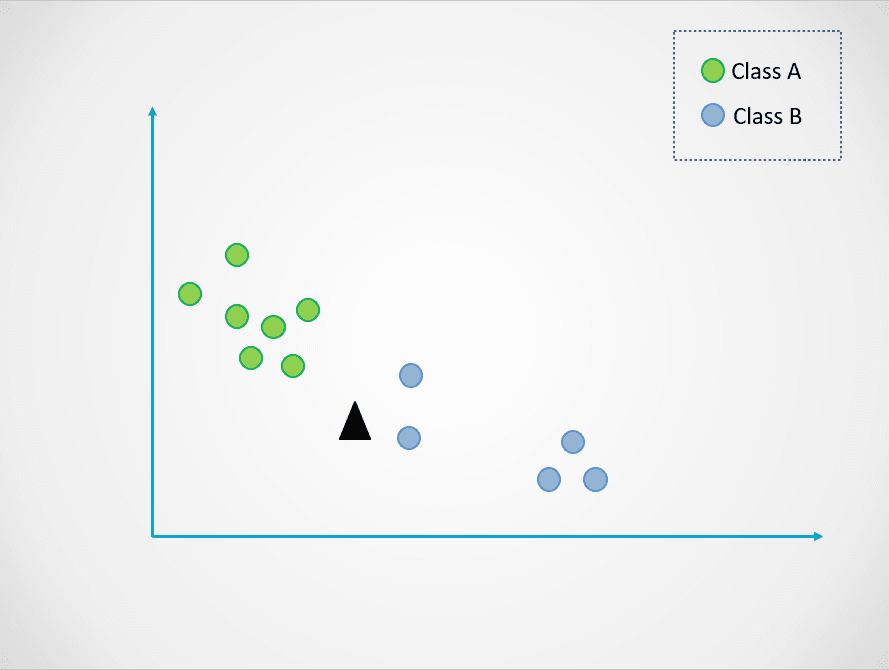
Hình do tác giả cung cấp
Trong sơ đồ trên, có hai lớp điểm dữ liệu - A và B. Tam giác đen đại diện cho một điểm dữ liệu mới cần được phân loại vào một trong hai lớp này.
Thuật toán K-Nearest Neighbors hoạt động như sau:
Trong hình trên, giá trị k bằng 1. Điều này nghĩa là ta chỉ nhìn một láng giềng gần nhất với tam giác đen và gán điểm dữ liệu vào lớp đó. Điểm mới gần điểm màu xanh dương nhất, nên gán vào lớp B.
Giờ, hãy thay đổi k. Thử hai giá trị k là 3 và 7:
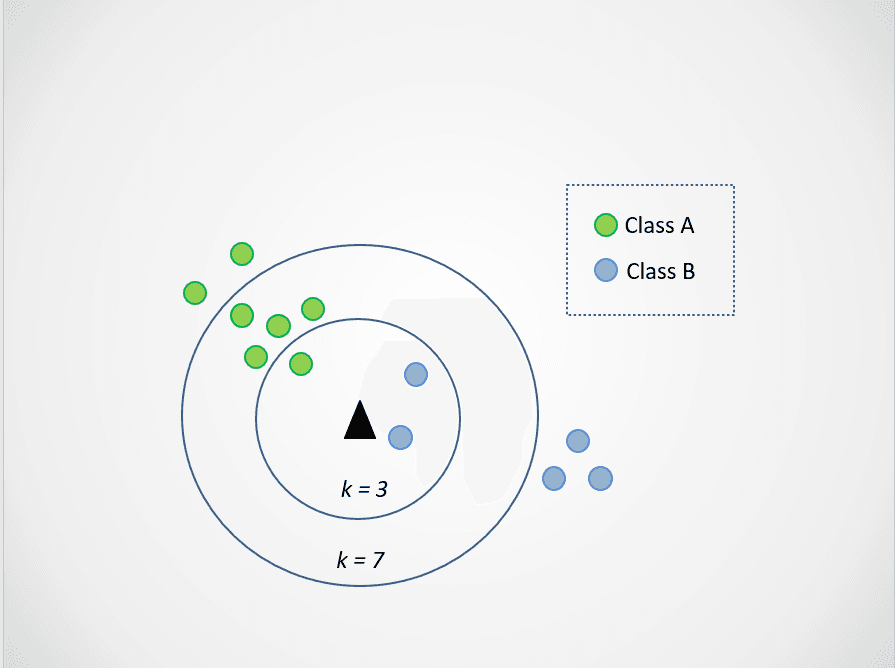
Hình do tác giả cung cấp
Hãy để ý khi chọn k=3, điểm dữ liệu mới nằm giữa hai hạng mục. Điều này nghĩa là ta chọn lớp chiếm đa số. Hai láng giềng gần nhất là xanh dương, một là xanh lá, nên điểm dữ liệu tiếp tục được gán vào lớp có điểm xanh dương, lớp B.
Tuy nhiên, khi k=7, mọi thứ thay đổi. Giờ có hai láng giềng gần nhất màu xanh dương và bảy màu xanh lá. Trong trường hợp này, điểm dữ liệu sẽ được gán vào lớp xanh lá, lớp A.
Chọn các giá trị k khác nhau sẽ ảnh hưởng đến lớp mà điểm mới được gán.
Chọn k quá nhỏ có thể nhiễu và nhạy với ngoại lệ, trong khi chọn k lớn có thể khiến bạn bỏ qua các hạng mục có ít điểm dữ liệu.
Nếu bạn muốn tìm hiểu thêm về K-Nearest Neighbors và cách chọn giá trị “k” tối ưu, hãy đọc hướng dẫn KNN này.
Dưới đây là một số đoạn mã bạn có thể dùng để xây dựng mô hình phân loại trong Python với thư viện Scikit-Learn:
1. Hồi quy Logistic
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Các mô hình dạng cây là thuật toán machine learning có giám sát, xây dựng cấu trúc dạng cây để đưa ra dự đoán. Chúng có thể dùng cho cả bài toán phân loại và hồi quy.
Trong phần này, chúng ta sẽ khám phá hai mô hình dạng cây thường dùng nhất: cây quyết định và rừng ngẫu nhiên.
Cây quyết định là thuật toán đơn giản nhất trong các mô hình dạng cây. Mô hình này cho phép chúng ta liên tục chia nhỏ tập dữ liệu dựa trên những tham số cụ thể cho đến khi đưa ra quyết định cuối cùng.
Dưới đây là ví dụ đơn giản minh họa cách thuật toán cây quyết định hoạt động:
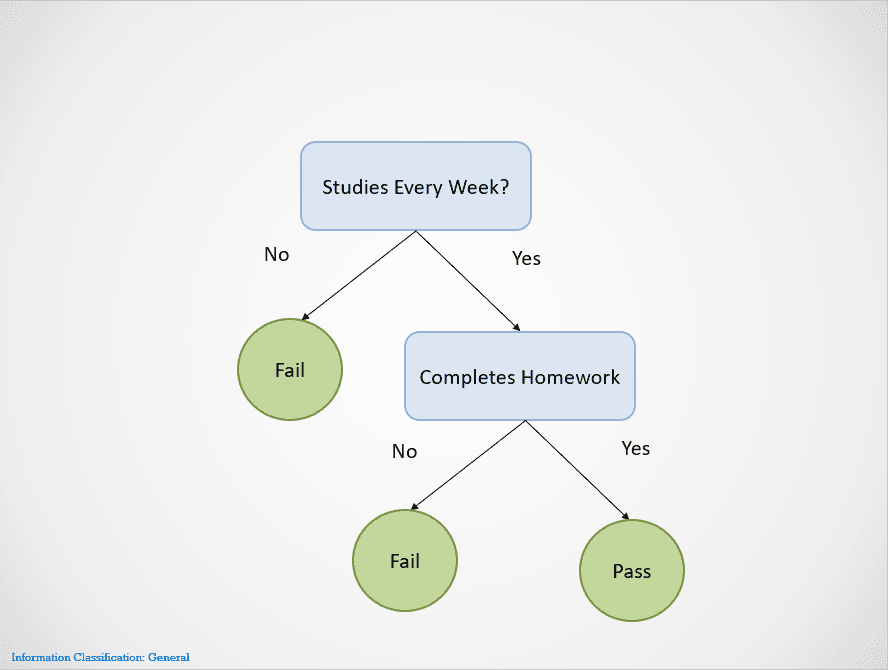
Hình do tác giả cung cấp
Cây quyết định chia tách ở các nút khác nhau cho đến khi thu được kết quả.
Trong trường hợp này, nếu một học sinh không học mỗi tuần, các em sẽ trượt. Nếu học mỗi tuần nhưng không làm bài tập, kết quả vẫn là “Trượt”. Các em chỉ đỗ nếu vừa học mỗi tuần vừa hoàn thành toàn bộ bài tập.
Lưu ý cây quyết định trên tách trước theo biến “Học mỗi tuần?”. Sau đó dừng tách nếu câu trả lời là “Không”, và nói học sinh sẽ trượt.
Cây quyết định sẽ chọn biến để tách trước dựa trên thước đo gọi là entropy. Nó sẽ dừng tách khi đạt “tách thuần khiết”, tức khi tất cả điểm dữ liệu thuộc một lớp duy nhất.
Có nhiều cách xây dựng cây quyết định. Cây cần tìm đặc trưng để tách đầu tiên, thứ hai, thứ ba, v.v. Cấu trúc này được tạo dựa trên thước đo gọi là thông tin thu được (information gain). Cây quyết định tốt nhất là cây có information gain cao nhất.
Để tìm hiểu thêm cách cây quyết định hoạt động, cùng các thước đo như entropy và information gain, bài viết về phân loại bằng cây quyết định trong Python có thêm chi tiết.
Một ưu điểm lớn của cây quyết định là khả năng diễn giải cao. Dễ dàng lần ngược và hiểu cách cây quyết định đi đến kết quả cuối cùng dựa trên dữ liệu huấn luyện.
Tuy nhiên, cây quyết định cũng rất dễ quá khớp nếu để phát triển tự do. Vì chúng được thiết kế để tách hoàn hảo trên mọi mẫu của dữ liệu huấn luyện, nên khó khái quát hóa tốt cho dữ liệu bên ngoài.
Nhược điểm này của cây quyết định có thể giải quyết bằng thuật toán rừng ngẫu nhiên.
Mô hình random forest là thuật toán dạng cây giúp giảm bớt một số vấn đề khi dùng cây quyết định, trong đó có quá khớp. Rừng ngẫu nhiên được tạo bằng cách kết hợp dự đoán của nhiều mô hình cây quyết định và trả về một đầu ra duy nhất.
Thuật toán làm điều này qua hai bước:
Trong bài toán hồi quy, đầu ra sẽ là trung bình dự đoán của tất cả các cây quyết định.
Dưới đây là hình minh họa đơn giản cách thuật toán rừng ngẫu nhiên hoạt động:
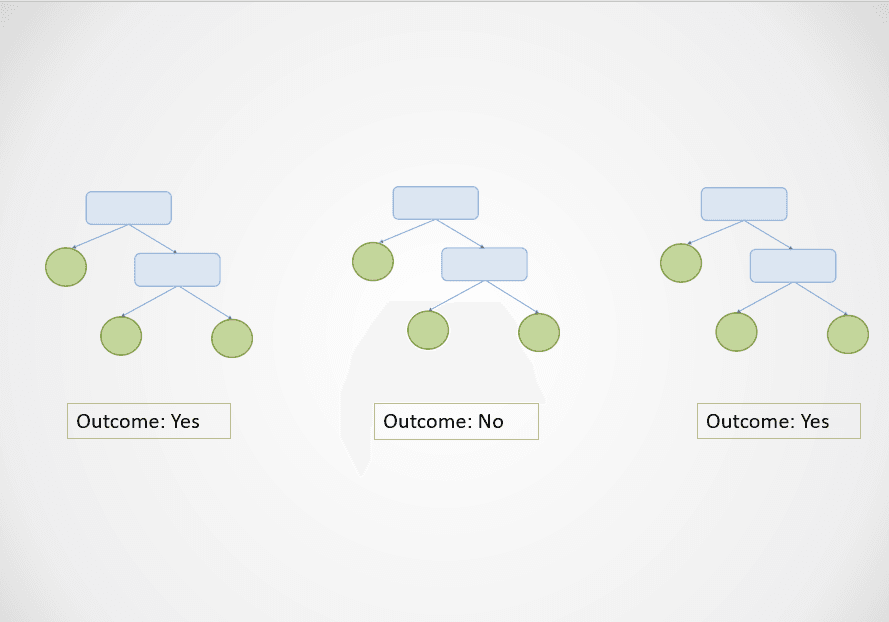
Hình do tác giả cung cấp
Trong sơ đồ trên, cây quyết định thứ nhất và thứ ba dự đoán “Yes” trong khi cây thứ hai dự đoán “No”.
Vì đây là tác vụ phân loại, lớp chiếm đa số được chọn. Trong trường hợp này, thuật toán rừng ngẫu nhiên sẽ trả về kết quả cuối là “Yes” dựa trên dự đoán của 2 trong 3 cây.
Một ưu điểm lớn của rừng ngẫu nhiên là khả năng khái quát hóa tốt, vì nó kết hợp đầu ra của nhiều cây quyết định được huấn luyện trên các tập con đặc trưng.
Hơn nữa, trong khi đầu ra của một cây quyết định đơn lẻ có thể thay đổi đáng kể khi dữ liệu huấn luyện thay đổi nhỏ, vấn đề này không xảy ra với rừng ngẫu nhiên vì tập dữ liệu huấn luyện được lấy mẫu nhiều lần.
Chạy các dòng mã sau để xây dựng thuật toán machine learning dạng cây với Scikit-Learn:
1. Cây quyết định
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Rừng ngẫu nhiên
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Tới giờ, chúng ta đã khám phá các mô hình machine learning có giám sát để giải quyết bài toán phân loại và hồi quy. Giờ, chúng ta sẽ đi vào một phương pháp học không giám sát phổ biến gọi là phân cụm.
Nói đơn giản, phân cụm là nhiệm vụ tạo nhóm các đối tượng giống nhau với nhau và khác với nhóm khác. Kỹ thuật này có nhiều ứng dụng kinh doanh, như gợi ý phim cho người dùng có thói quen xem tương tự trên trang phát video, phát hiện bất thường và phân khúc khách hàng.
Trong phần này, chúng ta sẽ xem xét thuật toán gọi là K-Means — mô hình machine learning đơn giản và phổ biến nhất dùng cho các tác vụ học không giám sát.
K-Means là kỹ thuật machine learning không giám sát dùng để nhóm các đối tượng tương tự nhau trong dữ liệu.
Dưới đây là ví dụ cách thuật toán K-Means hoạt động:

Hình do tác giả cung cấp
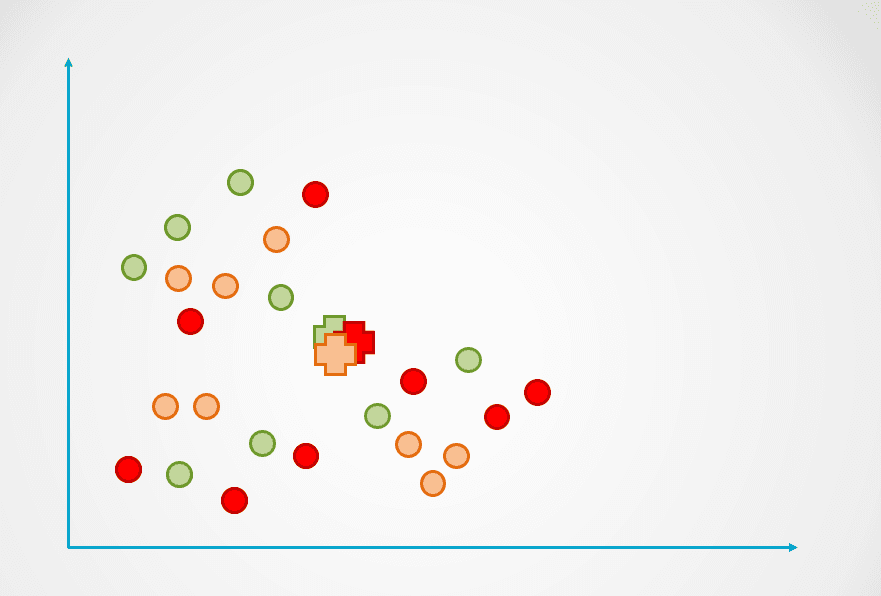
Bước 1: Hình trên gồm các quan sát chưa gán nhãn, chưa được nhóm. Ban đầu, mỗi quan sát sẽ được gán ngẫu nhiên vào một cụm. Sau đó, một tâm cụm (centroid) sẽ được tính cho mỗi cụm.
Chúng được biểu diễn bằng ký hiệu “+” trong sơ đồ dưới đây:
Hình do tác giả cung cấp
Bước 2: Tiếp theo, đo khoảng cách từ mỗi điểm dữ liệu đến tâm cụm, và gán mỗi điểm vào tâm gần nhất:
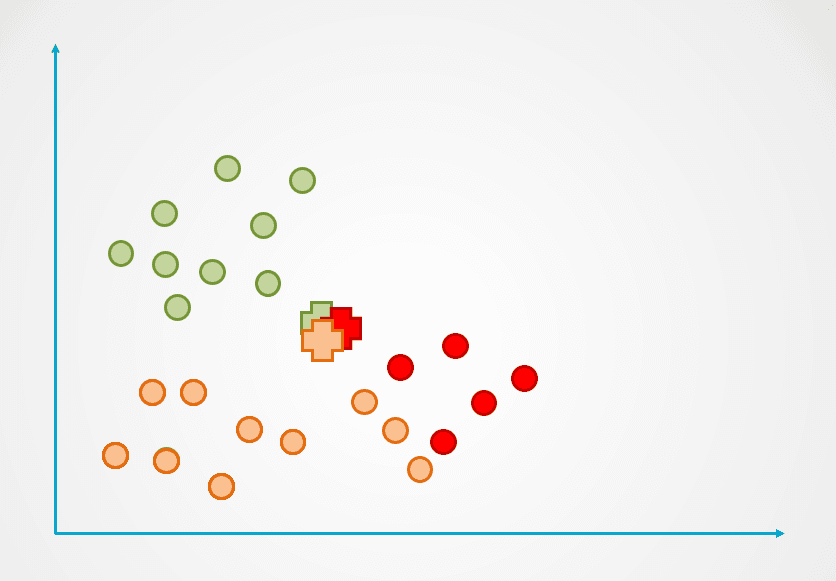
Hình do tác giả cung cấp
Bước 3: Sau đó tính lại tâm của cụm mới, và các điểm dữ liệu sẽ được gán lại tương ứng.
Bước 4: Lặp lại quá trình cho đến khi các điểm dữ liệu không còn bị gán lại nữa:
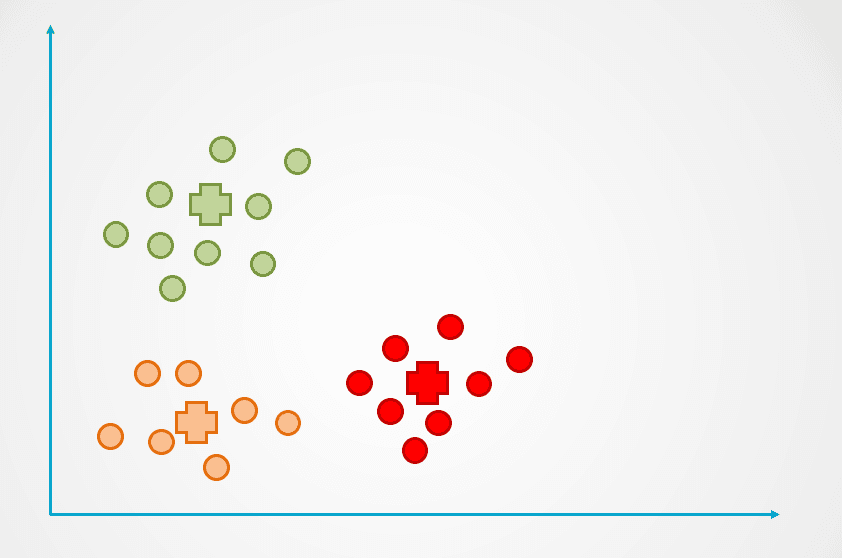
Hình do tác giả cung cấp
Quan sát rằng đã tạo ra ba cụm trong ví dụ trên. Số cụm được gọi là “k” trong thuật toán K-Means, và chúng ta phải tự xác định.
Có vài cách chọn “k” trong K-Means, phổ biến nhất là phương pháp khuỷu tay (elbow method). Kỹ thuật này gồm vẽ đồ thị lỗi cho số cụm khác nhau và chọn điểm gãy của đường cong làm “k.”
Tìm hiểu thêm trong hướng dẫn K-Means clustering trong Python để khám phá phương pháp khuỷu tay và cơ chế bên trong của K-Means.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')Đối số n_clusters chỉ số lượng cụm “k” mà bạn cần xác định khi xây dựng thuật toán.
Nếu bạn theo dõi được toàn bộ bài viết này, xin chúc mừng! Giờ bạn đã biết về một số mô hình và thuật toán machine learning có giám sát và không giám sát phổ biến, cũng như cách áp dụng chúng để giải quyết nhiều bài toán mô hình dự đoán.
Để trở thành nhà khoa học dữ liệu, bạn cần hiểu cách các loại mô hình machine learning hoạt động để áp dụng chúng vào giải quyết vấn đề. Ví dụ, nếu bạn muốn xây mô hình dễ diễn giải và có thời gian tính toán thấp, có thể hợp lý khi tạo cây quyết định. Tuy nhiên, nếu mục tiêu là tạo mô hình khái quát hóa tốt, bạn có thể chọn xây thuật toán rừng ngẫu nhiên.
Bạn cũng cần hiểu cách đánh giá mô hình machine learning. Một mô hình “tốt” là khái niệm chủ quan và phụ thuộc mạnh vào trường hợp sử dụng. Trong bài toán phân loại chẳng hạn, chỉ số accuracy cao thôi chưa phản ánh mô hình tốt. Là nhà khoa học dữ liệu, bạn cần xem xét các thước đo như precision, recall và F1-Score để có cái nhìn tốt hơn về hiệu năng mô hình.
Nếu bạn muốn hiểu sâu hơn về mô hình machine learning so với những khái niệm đã đề cập trong bài, hãy tham gia khóa Machine Learning Scientist with Python. Lộ trình nghề nghiệp này sẽ dạy bạn lý thuyết hoạt động của các mô hình machine learning và cách triển khai trong Python. Bạn cũng sẽ học các kỹ thuật chuẩn bị dữ liệu như chuẩn hóa, khử tương quan và chọn đặc trưng trong khóa học.
Khóa học Machine Learning
Courses
Courses
Courses