Kursus
Machine Learning dengan Model Berbasis Pohon di Python
5 Hr
117.2K
Saat ini, banyak organisasi besar menggunakan bentuk pemodelan prediktif untuk memaksimalkan pendapatan dan mendorong pertumbuhan bisnis.
Machine learning memiliki beragam use case di berbagai domain. Platform berbasis langganan seperti Netflix dan Spotify, misalnya, menggunakan machine learning untuk merekomendasikan konten berdasarkan aktivitas pengguna pada aplikasi.
Sistem rekomendasi memberikan nilai bisnis langsung kepada perusahaan-perusahaan ini karena pengalaman pengguna yang lebih baik akan meningkatkan kemungkinan pelanggan terus berlangganan. Ini adalah contoh model machine learning tanpa pengawasan (unsupervised).
Demikian pula, penyedia layanan seluler mungkin menggunakan machine learning untuk menganalisis sentimen pengguna dan menyusun penawaran produknya sesuai dengan permintaan pasar. Ini adalah contoh model machine learning terawasi (supervised).
Semua model machine learning dapat diklasifikasikan sebagai terawasi (supervised) atau tanpa pengawasan (unsupervised). Perbedaan terbesar di antara keduanya adalah algoritma terawasi memerlukan data pelatihan berlabel untuk input dan output, sedangkan model tanpa pengawasan dapat memproses dataset mentah yang tidak berlabel.
Model machine learning terawasi selanjutnya dapat diklasifikasikan menjadi algoritma regresi dan klasifikasi, yang akan dijelaskan lebih rinci dalam artikel ini.
Algoritma regresi digunakan untuk memprediksi keluaran kontinu (y) menggunakan variabel independen (x).
Sebagai contoh, perhatikan tabel di bawah ini:
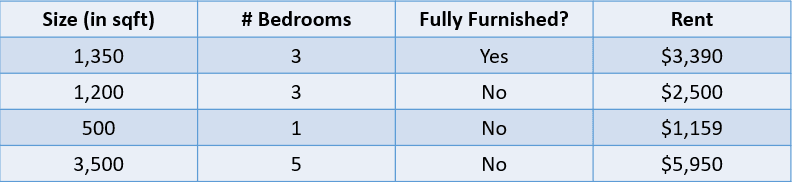
Gambar oleh penulis
Dalam kasus ini, kita ingin memprediksi sewa rumah berdasarkan ukurannya, jumlah kamar tidur, dan apakah rumah tersebut berperabot lengkap. Variabel terikat, “Sewa”, bersifat numerik, yang menjadikan ini masalah regresi.
Masalah dengan banyak variabel input seperti di atas disebut masalah regresi multivariat.
Salah kaprah yang umum pada pemula data science adalah bahwa model regresi dapat dievaluasi menggunakan metrik seperti akurasi. Akurasi adalah metrik untuk menilai kinerja model klasifikasi, seperti yang akan dijelaskan nanti di artikel ini.
Model regresi, di sisi lain, dievaluasi menggunakan metrik seperti MAE (Mean Absolute Error), MSE (Mean Squared Error), dan RMSE (Root Mean Squared Error).
Mari tambahkan nilai prediksi pada masalah harga sewa di atas dan evaluasi prediksi tersebut menggunakan beberapa metrik regresi:

Gambar oleh penulis
Mean absolute error menghitung jumlah selisih antara semua nilai aktual dan prediksi, lalu membaginya dengan jumlah total observasi. Berikut adalah rumus untuk menghitung MAE:
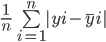
Mari hitung Mean Absolute Error dari nilai-nilai di atas menggunakan rumus ini:
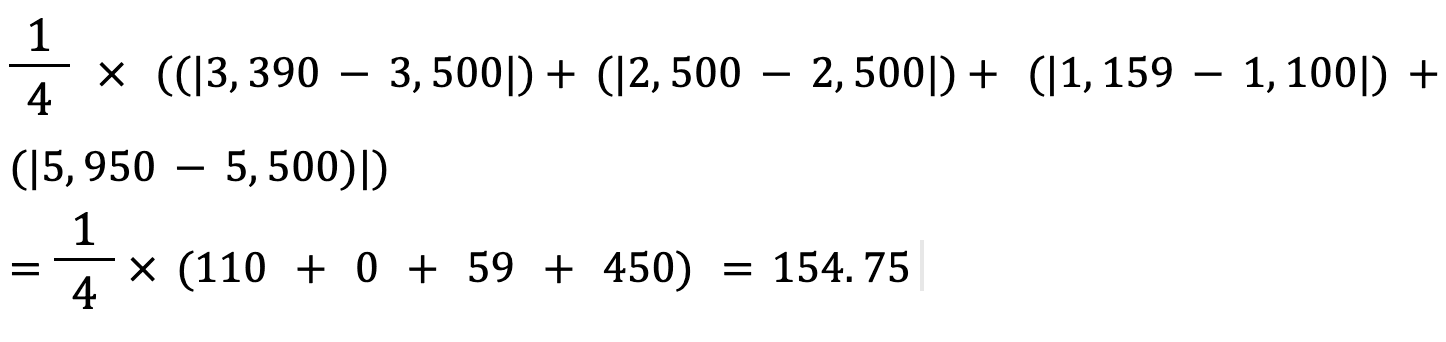
Mean absolute error antara harga rumah aktual dan prediksi kira-kira $155.
Rumus untuk menghitung mean squared error model serupa dengan mean absolute error:
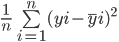
Perhatikan bahwa sementara mean absolute error menghitung jarak absolut rata-rata antara nilai aktual dan prediksi, mean squared error mencari jarak kuadrat rata-rata antara nilai aktual dan prediksi.
Mari hitung MSE antara nilai aktual dan nilai prediksi di atas:
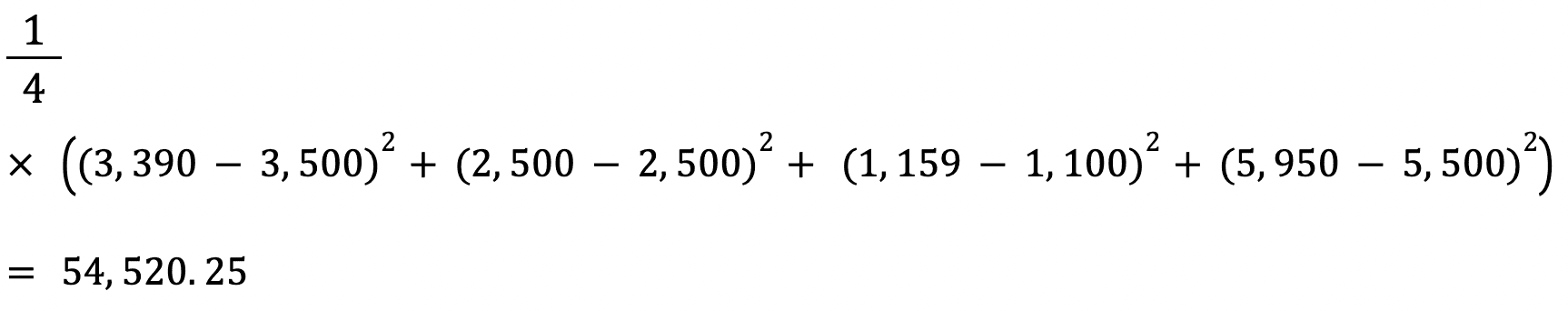
RMSE dari suatu penaksir dihitung dengan mencari akar kuadrat dari mean squared error-nya. Salah satu kelebihan menghitung RMSE dibanding MSE adalah kesalahannya dikembalikan dalam satuan yang sama dengan variabel yang kita prediksi.
Dalam kasus ini, misalnya, RMSE adalah √54.520,25=233,5. Nilai ini dapat ditafsirkan karena dinyatakan dalam satuan harga rumah, sedangkan Mean Squared Error tidak.
Sekarang setelah Anda memahami konsep regresi, mari kita lihat berbagai jenis model regresi:
Regresi linear adalah pendekatan linear untuk memodelkan hubungan antara variabel terikat dan satu atau lebih variabel independen. Algoritma ini melibatkan pencarian garis yang paling sesuai dengan data yang ada.
Berikut adalah representasi visual cara kerja model regresi linear sederhana:
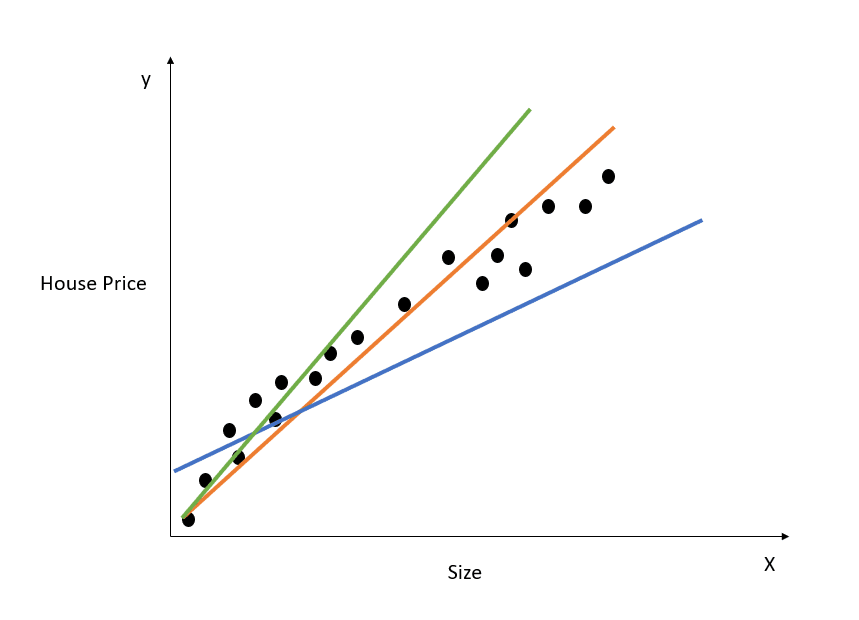
Gambar oleh penulis
Grafik di atas menampilkan hubungan antara harga rumah dan ukuran. Model regresi linear akan membuat garis yang paling merepresentasikan hubungan ini. Semua prediksi harga rumah terhadap berbagai nilai ukuran akan berada pada garis best fit tersebut.
Perhatikan bahwa ada tiga garis yang digambar pada diagram di atas. Manakah dari garis-garis ini yang merupakan “garis terbaik” (line of best fit)?
Hanya dengan melihat diagram di atas, kita dapat melihat bahwa garis oranye paling dekat dengan semua titik data yang ditampilkan. Jadi, secara intuitif kita dapat mengatakan bahwa itulah “garis terbaik.”
Berikut penjelasan yang lebih formal tentang bagaimana garis terbaik ditemukan dalam regresi linear:
Persamaan garis lurus adalah y=mx+c. Di sini, m merepresentasikan kemiringan garis dan c merepresentasikan titik potong y. Ada tak terhitung cara untuk menggambar garis ini, karena ada tak terhitung nilai yang mungkin untuk m dan c.
Garis terbaik, juga dikenal sebagai garis regresi kuadrat terkecil (least squares), ditemukan dengan meminimalkan jumlah jarak kuadrat antara nilai aktual dan nilai prediksi:
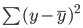
Anda dapat membaca tutorial Esensi Regresi Linear di Python untuk memahami lebih mendalam model machine learning regresi linear dan implementasinya.
Regresi ridge adalah pengembangan dari model regresi linear yang dijelaskan di atas. Ini adalah teknik untuk menjaga koefisien model regresi serendah mungkin.
Salah satu masalah pada model regresi linear sederhana adalah koefisiennya dapat menjadi besar, yang membuat model lebih sensitif terhadap input. Hal ini dapat menyebabkan overfitting.
Mari ambil contoh sederhana untuk memahami konsep overfitting:
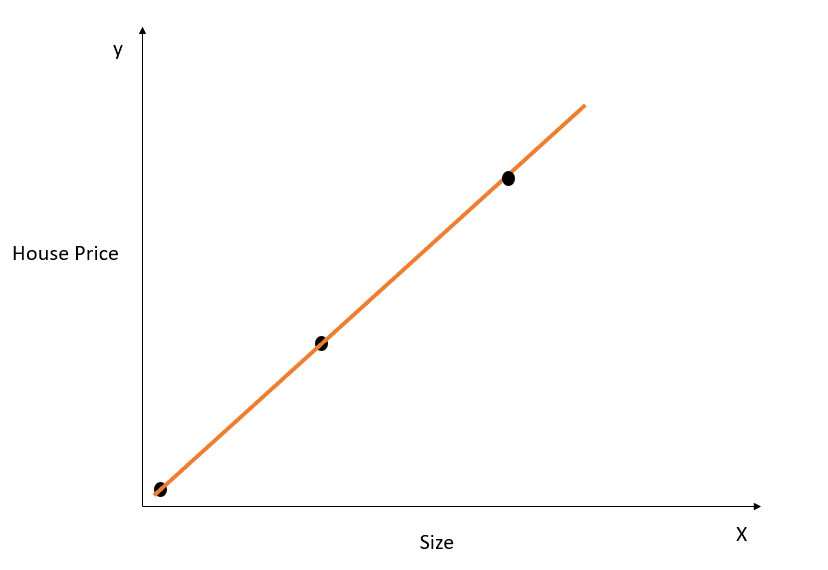
Gambar oleh penulis
Pada gambar di atas, garis terbaik memodelkan hubungan antara X dan y dengan sempurna, dan jumlah jarak kuadrat antara nilai aktual dan prediksi adalah 0. Ingat bahwa persamaan untuk garis ini adalah y=mx+c.
Meskipun garis ini sangat cocok pada dataset pelatihan, kemungkinan besar tidak akan menggeneralisasi dengan baik pada data uji. Fenomena ini disebut overfitting, dan Anda dapat membaca artikel tentang overfitting untuk mempelajarinya lebih lanjut.
Sederhananya, model yang sangat kompleks akan menangkap nuansa yang tidak perlu dari dataset pelatihan yang tidak tercermin di dunia nyata. Model ini akan berkinerja sangat baik pada data pelatihan namun berkinerja buruk pada dataset di luar apa yang dilatih.
Model regresi linear dengan koefisien besar rentan terhadap overfitting.
Regresi ridge adalah teknik regularisasi yang akan memaksa algoritma memilih koefisien yang lebih kecil dengan menambahkan biaya tambahan pada fungsi loss-nya.
Seperti ditunjukkan pada bagian sebelumnya, berikut adalah error yang ingin kita minimalkan dalam regresi linear sederhana:
Pada regresi ridge, persamaan ini akan sedikit berubah, dan sebuah penalti akan ditambahkan pada error di atas:
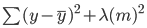
Perhatikan ada nilai (lambda) yang dikalikan dengan koefisien model. Karena model ini hanya memiliki satu variabel, ada satu koefisien dengan penalti yang ditambahkan. Jika ada beberapa variabel independen, lambda akan dikalikan dengan jumlah kuadrat koefisien.
Istilah penalti ini menghukum model yang memilih koefisien besar. Tujuannya adalah mengecilkan nilai koefisien sehingga variabel dengan kontribusi kecil terhadap keluaran akan memiliki koefisien mendekati 0. Ini mengurangi varians model dan membantu mengurangi overfitting.
Perhatikan bahwa nilai lambda 0 tidak akan berdampak apa pun, dan istilah penalti dihilangkan. Nilai lambda yang lebih tinggi akan menambah penalti penyusutan yang lebih besar, dan koefisien model akan semakin mendekati nol.
Saat memilih nilai lambda, pastikan menyeimbangkan antara kesederhanaan dan kecocokan yang baik pada data pelatihan. Nilai lambda yang lebih tinggi menghasilkan model yang sederhana dan tergeneralisasi, namun memilih nilai yang terlalu tinggi berisiko menyebabkan underfitting. Di sisi lain, memilih nilai lambda yang sangat mendekati nol dapat menghasilkan model yang sangat kompleks.
Regresi lasso adalah pengembangan lain dari regresi linear yang mengecilkan koefisien model dengan menambahkan penalti pada fungsi biayanya.
Berikut adalah error yang perlu diminimalkan dalam regresi lasso:
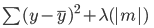
Perhatikan bahwa persamaan ini mirip dengan model regresi ridge, kecuali, alih-alih mengalikan lambda dengan kuadrat koefisien, kita mengalikannya dengan nilai absolut koefisien.
Perbedaan terbesar antara regresi ridge dan lasso adalah pada regresi ridge, meskipun koefisien model dapat mengecil mendekati nol, nilainya tidak pernah benar-benar menjadi nol. Pada regresi lasso, koefisien model dapat menjadi nol.
Jika koefisien variabel independen mencapai nol, fitur tersebut dapat dihapus dari model. Ini mengurangi ruang fitur dan membuat algoritma lebih mudah diinterpretasikan, yang merupakan kelebihan terbesar dari regresi lasso.
Karena itu, regresi lasso juga dapat digunakan sebagai teknik pemilihan fitur, karena variabel dengan kepentingan rendah dapat memiliki koefisien yang mencapai nol dan akan dihapus sepenuhnya dari model.
Anda dapat membangun model regresi linear, ridge, dan lasso menggunakan pustaka Scikit-Learn:
1. Regresi Linear
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Untuk memasangkan model pada dataset pelatihan Anda, jalankan:
lr_model.fit(X_train,y_train)2. Regresi Ridge
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)Istilah lambda dapat dikonfigurasi melalui parameter “alpha” saat mendefinisikan model.
3. Regresi Lasso
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Jika Anda ingin mempelajari lebih lanjut tentang model linear dan cara membangunnya di Python, ikuti kursus Introduction to Linear Modeling in Python kami.
Kita menggunakan algoritma klasifikasi untuk memprediksi keluaran diskret (y) menggunakan variabel independen (x). Variabel terikat, dalam hal ini, selalu berupa kelas atau kategori.
Misalnya, memprediksi apakah seorang pasien berisiko mengidap penyakit jantung berdasarkan faktor risikonya adalah masalah klasifikasi:
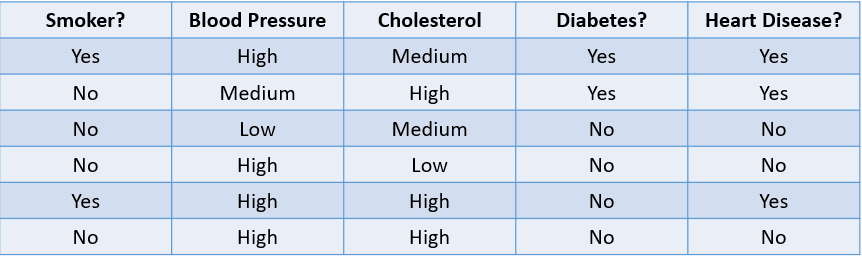
Gambar oleh penulis
Tabel di atas menampilkan masalah klasifikasi dengan empat variabel independen dan satu variabel terikat, penyakit jantung. Karena hanya ada dua kemungkinan keluaran (Ya dan Tidak), ini disebut masalah klasifikasi biner.
Contoh lain dari masalah klasifikasi biner termasuk mengklasifikasikan apakah email adalah spam atau bukan, prediksi churn pelanggan, dan keputusan apakah akan memberikan pinjaman kepada seseorang.
Masalah klasifikasi multikelas adalah masalah dengan tiga atau lebih kemungkinan keluaran, seperti peramalan cuaca atau membedakan berbagai spesies hewan.
Ada banyak cara untuk mengevaluasi model klasifikasi. Meski akurasi adalah metrik yang paling sering digunakan, itu tidak selalu yang paling andal.
Mari kita lihat beberapa metode umum untuk mengevaluasi algoritma klasifikasi berdasarkan dataset di bawah ini:
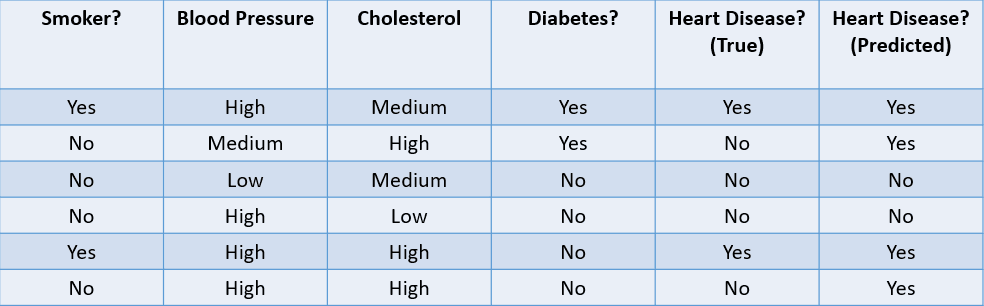
Gambar oleh penulis
1. Akurasi: Akurasi dapat didefinisikan sebagai porsi prediksi benar yang dibuat oleh model machine learning.
Rumus untuk menghitung akurasi adalah:

Dalam kasus ini, akurasinya adalah 4⁄6, atau 0,67.
2. Presisi: Presisi adalah metrik untuk menghitung kualitas prediksi positif yang dibuat oleh model. Didefinisikan sebagai:
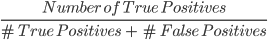
Model di atas memiliki presisi 2⁄4, atau 0,5.
3. Recall: Recall digunakan untuk menghitung kualitas prediksi negatif yang dibuat oleh model. Didefinisikan sebagai:
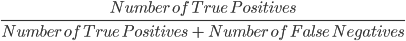
Model di atas memiliki recall 2/2 atau 1.
Mari lihat contoh sederhana untuk memahami perbedaan antara presisi dan recall:
Ada penyakit langka dan mematikan yang memengaruhi sebagian kecil populasi. 95% pasien dalam basis data rumah sakit tidak memiliki penyakit tersebut, sementara hanya 5% yang memilikinya. Jika kita membangun algoritma machine learning yang memprediksi bahwa tidak ada yang memiliki penyakit itu, maka akurasi pelatihan model ini adalah 95%. Terlepas dari akurasi yang tinggi, kita tahu ini bukan model yang baik karena gagal mengidentifikasi pasien yang memiliki penyakit.
Di sinilah metrik seperti presisi dan recall berperan. Presisi, atau spesifisitas, memberi tahu kita kemampuan model untuk dengan benar mengidentifikasi orang yang tidak memiliki penyakit. Recall, atau sensitivitas, menunjukkan seberapa baik model mengidentifikasi orang yang memiliki penyakit.
Nilai presisi dan recall yang “baik” bersifat subjektif dan bergantung pada use case Anda.
Dalam skenario prediksi penyakit ini, kita selalu ingin mengidentifikasi orang yang memiliki penyakit, meskipun ini berisiko menghasilkan positif palsu. Di sini, kita akan membangun model dengan recall yang lebih tinggi daripada presisi.
Di sisi lain, jika kita membangun model yang mencegah pelaku jahat masuk ke sebuah situs web e-commerce, kita mungkin menginginkan presisi yang lebih tinggi karena memblokir pengguna yang sah akan menyebabkan penurunan penjualan.
Kita sering menggunakan metrik bernama F1-Score untuk mencari rata-rata harmonik dari presisi dan recall suatu pengklasifikasi. Sederhananya, F1-Score menggabungkan presisi dan recall ke dalam satu metrik dengan menghitung rata-ratanya.
AUC, atau Area Under the Curve, adalah metrik populer lainnya yang digunakan untuk mengukur kinerja model klasifikasi. AUC suatu algoritma memberi tahu kita tentang kemampuannya dalam membedakan kelas positif dan negatif.
Untuk mempelajari lebih lanjut tentang ukuran seperti AUC dan cara perhitungannya, ikuti kursus Supervised Learning in R oleh Datacamp.
Sekarang, mari lihat berbagai jenis model klasifikasi dan cara kerjanya:
Regresi logistik adalah model klasifikasi sederhana yang memprediksi probabilitas terjadinya suatu peristiwa.
Berikut contoh cara kerja model regresi logistik:
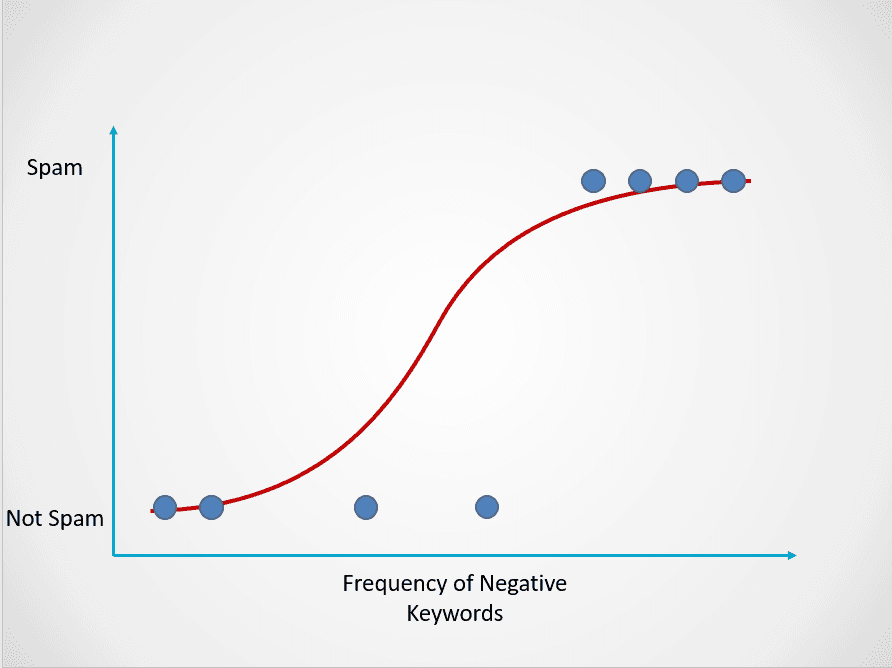
Gambar oleh penulis
Grafik di atas menampilkan fungsi logistik yang memetakan data email ke dalam dua kategori: “Spam” dan “Bukan Spam” berdasarkan frekuensi kata kunci negatif dalam teksnya.
Perhatikan bahwa, berbeda dengan algoritma regresi linear, regresi logistik dimodelkan dengan kurva berbentuk S. Ini dikenal sebagai fungsi logistik dan memiliki rumus sebagai berikut:
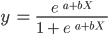
Sementara fungsi linear tidak memiliki batas atas dan bawah, fungsi logistik berada dalam rentang 0 hingga 1. Model memprediksi probabilitas antara 0 hingga 1, yang menentukan kelas tempat titik data tersebut berada.
Dalam contoh email spam ini, jika teks mengandung sedikit atau tidak ada kata kunci mencurigakan, maka probabilitasnya menjadi spam akan rendah dan mendekati 0. Sebaliknya, email dengan banyak kata kunci mencurigakan akan memiliki probabilitas tinggi menjadi spam, mendekati 1.
Probabilitas ini kemudian diubah menjadi keluaran klasifikasi:
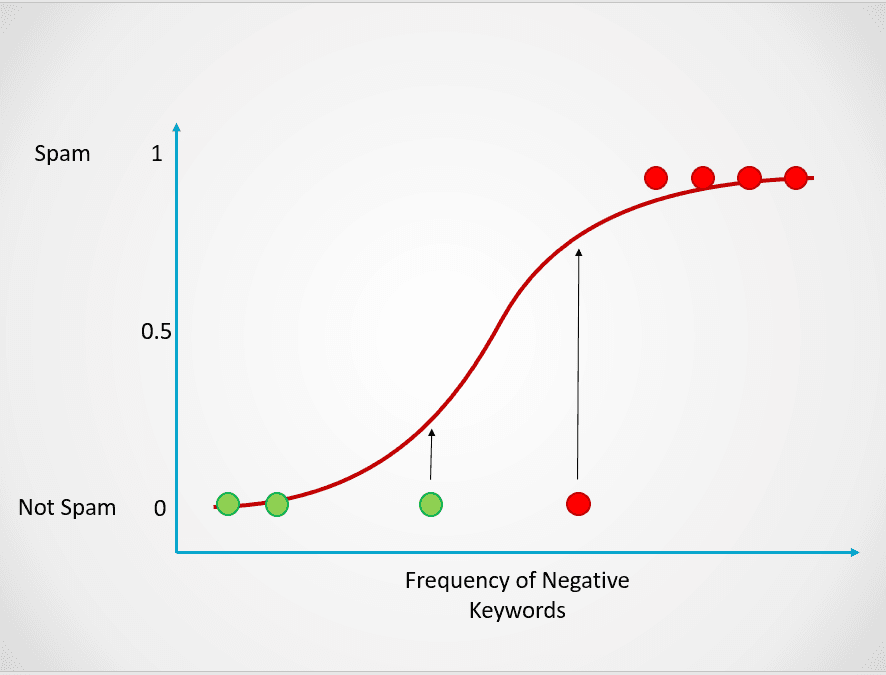
Gambar oleh penulis
Semua titik berwarna merah memiliki probabilitas >= 0,5 untuk menjadi spam. Oleh karena itu, mereka diklasifikasikan sebagai spam dan model regresi logistik akan menghasilkan keluaran klasifikasi 1. Titik berwarna hijau memiliki probabilitas < 0,5 untuk menjadi spam, sehingga diklasifikasikan oleh model sebagai “Bukan Spam” dan akan menghasilkan keluaran klasifikasi 0.
Untuk masalah klasifikasi biner seperti di atas, ambang default model regresi logistik adalah 0,5, yang berarti titik data dengan probabilitas lebih tinggi dari 0,5 akan otomatis diberi label 1. Nilai ambang ini dapat diubah secara manual sesuai use case Anda untuk mencapai hasil yang lebih baik.
Sekarang, ingat bahwa dalam regresi linear, kita menemukan garis terbaik dengan meminimalkan jumlah error kuadrat antara nilai prediksi dan nilai sebenarnya. Dalam regresi logistik, bagaimanapun, koefisien diestimasi menggunakan teknik bernama maximum likelihood estimation alih-alih least squares.
Baca tutorial regresi logistik Python untuk mempelajari lebih lanjut tentang konsep maximum likelihood estimation dan cara kerja regresi logistik.
KNN adalah algoritma klasifikasi yang mengklasifikasikan suatu titik data berdasarkan kelompok tempat titik-titik data terdekatnya berada.
Berikut contoh sederhana untuk menunjukkan cara kerja model K-Nearest Neighbors:
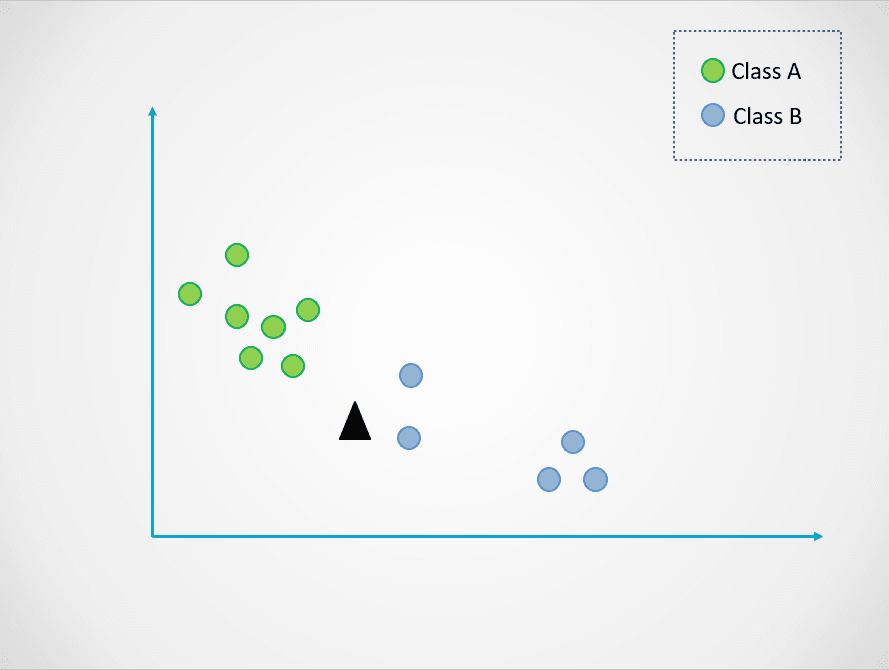
Gambar oleh penulis
Pada diagram di atas, ada dua kelas titik data - A dan B. Segitiga hitam mewakili titik data baru yang perlu diklasifikasikan ke salah satu dari dua kelas ini.
Algoritma K-Nearest Neighbors bekerja seperti ini:
Pada visual di atas, nilai k adalah 1. Ini berarti kita hanya melihat satu tetangga terdekat dari segitiga hitam dan menetapkan titik data tersebut ke kelas itu. Titik data baru paling dekat dengan titik biru, sehingga kita menempatkannya ke kelas B.
Sekarang, mari ubah nilai k. Mari coba dua kemungkinan nilai k, 3 dan 7:
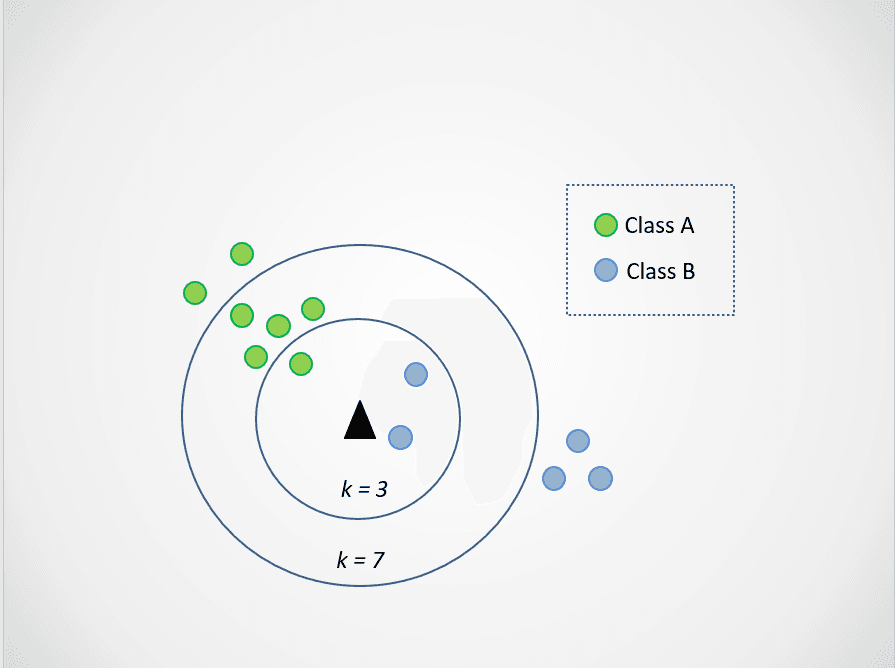
Gambar oleh penulis
Sekarang, perhatikan bahwa ketika kita memilih k=3, titik data baru berada di antara dua kategori. Ini berarti kita memilih kelas mayoritas. Dua tetangga terdekat berwarna biru, dan satu tetangga terdekat berwarna hijau, sehingga titik data kembali ditetapkan ke kelas dengan titik biru, kelas B.
Namun saat k=7, keadaannya berubah. Sekarang, dua tetangga terdekat berwarna biru, dan tujuh berwarna hijau. Dalam kasus ini, titik data akan ditetapkan ke kelas hijau, kelas A.
Memilih nilai k yang berbeda akan memengaruhi kelas mana yang ditetapkan pada titik baru.
Memilih nilai yang terlalu kecil bisa berisik dan rentan terhadap outlier, sementara memilih nilai yang besar dapat membuat Anda mengabaikan kategori dengan titik data lebih sedikit.
Jika Anda ingin mempelajari lebih lanjut tentang algoritma K-Nearest Neighbors dan cara memilih nilai “k” yang optimal, baca tutorial KNN ini.
Berikut beberapa potongan kode yang dapat Anda gunakan untuk membangun model klasifikasi di Python menggunakan pustaka Scikit-Learn:
1. Regresi Logistik
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Model berbasis pohon adalah algoritma machine learning terawasi yang membangun struktur seperti pohon untuk membuat prediksi. Model ini dapat digunakan untuk masalah klasifikasi maupun regresi.
Pada bagian ini, kita akan mengeksplorasi dua model machine learning berbasis pohon yang paling umum digunakan: decision tree dan random forest.
Decision tree adalah algoritma machine learning berbasis pohon yang paling sederhana. Model ini memungkinkan kita untuk terus membagi dataset berdasarkan parameter tertentu hingga keputusan akhir dibuat.
Berikut contoh sederhana yang menunjukkan cara kerja algoritma decision tree:
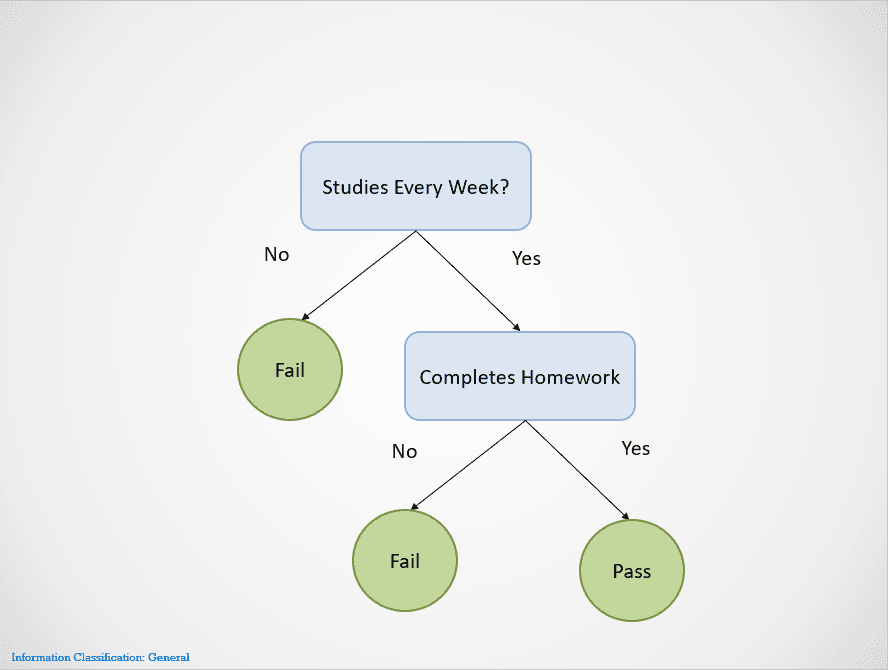
Gambar oleh penulis
Decision tree melakukan pemisahan pada node yang berbeda hingga diperoleh suatu keluaran.
Dalam kasus ini, jika seorang siswa tidak belajar setiap minggu, mereka akan gagal. Jika mereka belajar setiap minggu tetapi tidak menyelesaikan pekerjaan rumah, hasilnya tetap “Gagal.” Mereka hanya akan lulus jika belajar setiap minggu dan menyelesaikan semua pekerjaan rumah.
Perhatikan bahwa decision tree di atas pertama-tama memisahkan pada variabel “Belajar Setiap Minggu?”. Lalu berhenti memisahkan jika jawabannya “Tidak,” dengan menyatakan bahwa siswa akan gagal.
Decision tree akan memilih variabel yang pertama kali dipakai untuk memisahkan berdasarkan metrik bernama entropi. Pohon akan berhenti memisahkan ketika diperoleh “pemisahan murni,” yaitu ketika semua titik data termasuk dalam satu kelas.
Ada banyak cara untuk membangun decision tree. Pohon perlu menemukan fitur untuk dipisahkan pertama, kedua, ketiga, dan seterusnya. Struktur ini dibuat berdasarkan metrik bernama information gain. Decision tree terbaik adalah yang memiliki information gain tertinggi.
Untuk mempelajari lebih lanjut cara kerja decision tree, beserta metrik seperti entropi dan information gain, artikel klasifikasi decision tree dengan Python ini memiliki detail lebih lanjut.
Salah satu kelebihan terbesar decision tree adalah tingkat keterjelasannya yang tinggi. Mudah untuk menelusuri balik dan memahami bagaimana decision tree memperoleh hasil akhirnya berdasarkan dataset pelatihan.
Namun, decision tree juga sangat rentan terhadap overfitting jika dibiarkan tumbuh tanpa batas. Ini karena pohon dirancang untuk membagi secara sempurna pada semua sampel dataset pelatihan, yang membuatnya tidak mampu menggeneralisasi dengan baik ke data eksternal.
Kekurangan decision tree ini dapat diatasi dengan menggunakan algoritma random forest.
Model random forest adalah algoritma berbasis pohon yang membantu mengurangi beberapa masalah yang muncul saat menggunakan decision tree, salah satunya overfitting. Random forest dibuat dengan menggabungkan prediksi yang dibuat oleh banyak model decision tree dan mengembalikan satu keluaran.
Ini dilakukan dalam dua langkah:
Dalam kasus masalah regresi, keluarannya adalah rata-rata prediksi dari semua decision tree.
Berikut visual sederhana yang menunjukkan cara kerja algoritma random forest:
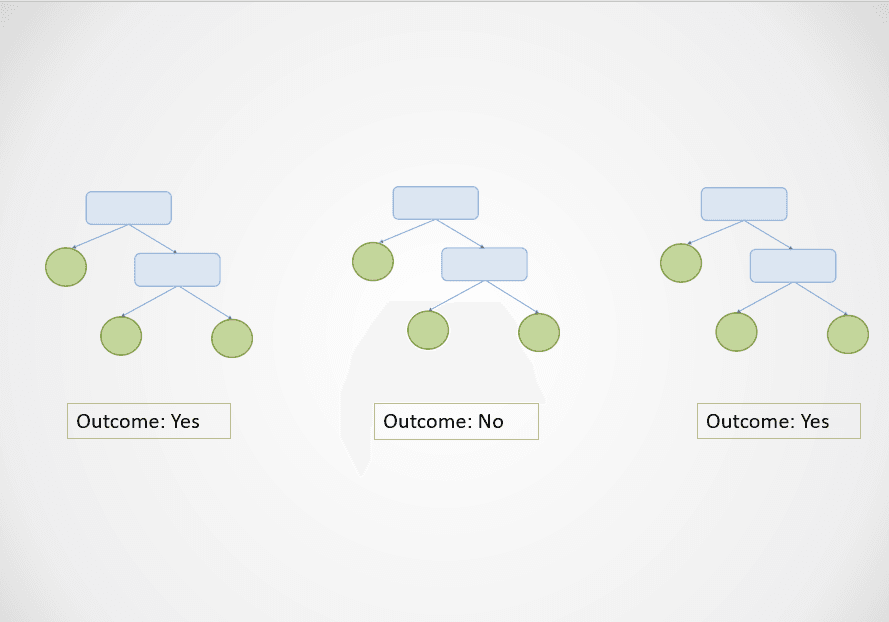
Gambar oleh penulis
Pada diagram di atas, decision tree pertama dan ketiga memprediksi “Ya” sementara yang kedua memprediksi “Tidak.”
Karena ini adalah tugas klasifikasi, kelas mayoritas dipilih. Dalam kasus ini, algoritma random forest akan mengembalikan hasil akhir “Ya” berdasarkan prediksi 2 dari 3 decision tree.
Salah satu kelebihan terbesar algoritma random forest adalah kemampuannya untuk menggeneralisasi dengan baik, karena ia menggabungkan keluaran dari beberapa decision tree yang dilatih pada subset fitur.
Selain itu, sementara keluaran dari satu decision tree dapat sangat bervariasi berdasarkan perubahan kecil pada dataset pelatihan, masalah ini tidak muncul pada algoritma random forest karena dataset pelatihan diambil sampelnya berkali-kali.
Jalankan baris kode berikut untuk membangun algoritma machine learning berbasis pohon dengan Scikit-Learn:
1. Decision Tree
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Random Forest
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Sejauh ini, kita telah mengeksplorasi model machine learning terawasi untuk menyelesaikan masalah klasifikasi dan regresi. Sekarang, kita akan membahas pendekatan pembelajaran tanpa pengawasan yang populer bernama clustering.
Sederhananya, clustering adalah tugas membuat kelompok objek yang mirip satu sama lain tetapi berbeda dari yang lain. Teknik ini memiliki berbagai use case bisnis, seperti merekomendasikan film kepada pengguna dengan pola tontonan serupa di situs streaming video, deteksi anomali, dan segmentasi pelanggan.
Pada bagian ini, kita akan menelaah algoritma bernama K-Means clustering—model machine learning tanpa pengawasan yang paling sederhana dan paling populer.
K-Means clustering adalah teknik machine learning tanpa pengawasan yang digunakan untuk mengelompokkan objek-objek serupa dalam data.
Berikut contoh cara kerja algoritma K-Means clustering:

Gambar oleh penulis
Langkah 1: Gambar di atas terdiri dari observasi tanpa label yang belum dikelompokkan. Awalnya, setiap observasi akan ditetapkan ke sebuah klaster secara acak. Sebuah centroid kemudian dihitung untuk setiap klaster.
Ini diwakili dengan simbol “+” pada diagram di bawah:
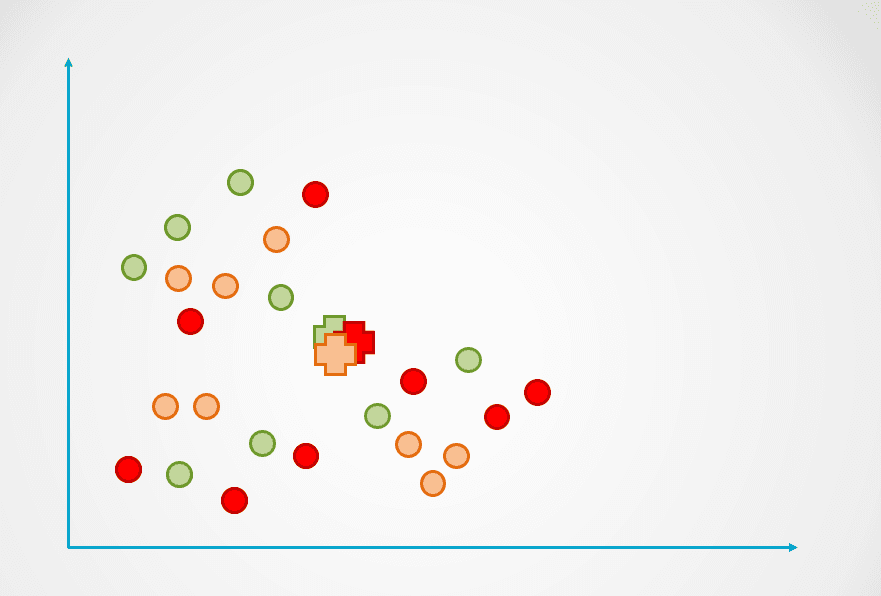
Gambar oleh penulis
Langkah 2: Selanjutnya, jarak setiap titik data ke centroid diukur, dan setiap titik ditetapkan ke centroid terdekat:
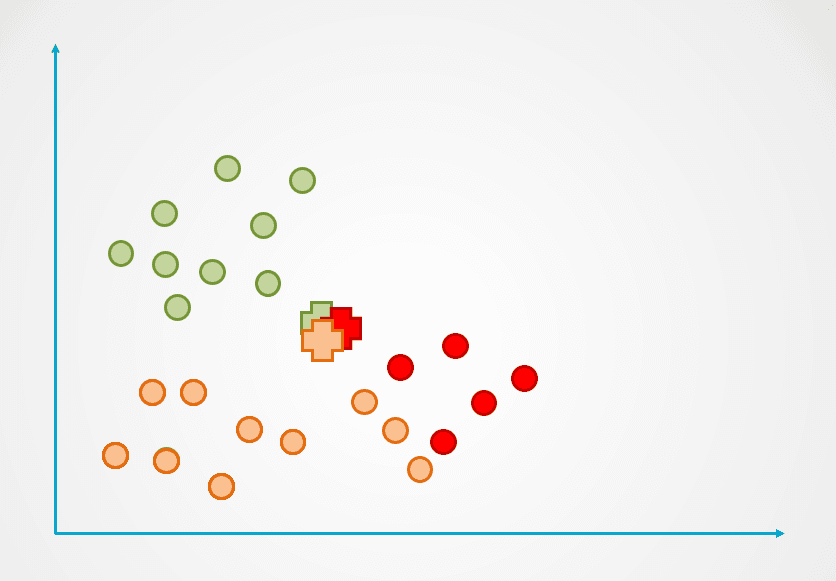
Gambar oleh penulis
Langkah 3: Centroid klaster baru kemudian dihitung ulang, dan titik-titik data akan ditetapkan ulang sesuai.
Langkah 4: Proses ini diulangi hingga titik-titik data tidak lagi ditetapkan ulang:
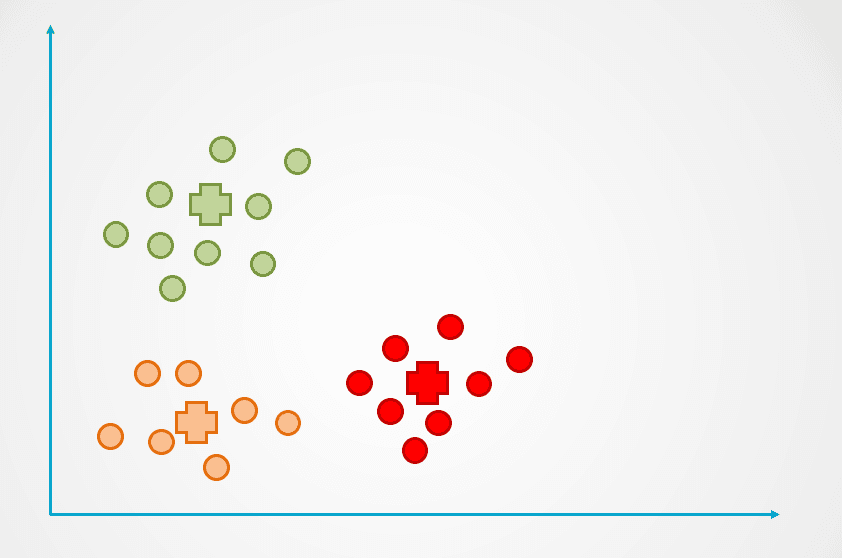
Gambar oleh penulis
Perhatikan bahwa tiga klaster dibuat pada contoh di atas. Jumlah klaster disebut “k” dalam algoritma K-Means clustering, dan ini harus kita tentukan.
Ada beberapa cara untuk memilih “k” dalam K-Means, yang paling populer adalah metode siku (elbow method). Teknik ini melibatkan pemetaan error untuk jumlah klaster yang berbeda pada grafik dan memilih titik belok kurva sebagai “k.”
Pelajari lebih lanjut dalam tutorial K-Means clustering di Python kami untuk mengetahui elbow method dan cara kerja internal K-Means clustering.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')Argumen n_clusters menunjukkan jumlah klaster “k” yang perlu Anda tentukan saat membangun algoritma.
Jika Anda berhasil mengikuti seluruh artikel ini, selamat! Anda sekarang mengetahui beberapa model dan algoritma machine learning terawasi dan tanpa pengawasan yang paling populer serta bagaimana menerapkannya untuk menyelesaikan berbagai masalah pemodelan prediktif.
Untuk menjadi seorang data scientist, Anda perlu memahami cara kerja berbagai jenis model machine learning agar dapat menerapkannya untuk menyelesaikan masalah. Misalnya, jika Anda ingin membangun model yang mudah diinterpretasikan dan memiliki waktu komputasi rendah, masuk akal untuk membuat decision tree. Namun, jika tujuan Anda membuat model yang menggeneralisasi dengan baik, Anda bisa memilih membangun algoritma random forest.
Penting juga untuk memahami cara mengevaluasi model machine learning. “Model yang baik” bersifat subjektif dan sangat bergantung pada use case Anda. Dalam masalah klasifikasi, misalnya, akurasi tinggi saja tidak menunjukkan model yang baik. Sebagai data scientist, Anda perlu meninjau metrik seperti presisi, recall, dan F1-Score untuk mendapatkan gambaran yang lebih baik tentang kinerja model Anda.
Jika Anda ingin memahami model machine learning lebih dalam dari konsep yang dibahas dalam artikel ini, ikuti kursus Machine Learning Scientist with Python. Jalur karier ini akan mengajarkan teori di balik cara kerja model machine learning dan bagaimana mengimplementasikannya di Python. Anda juga akan mempelajari teknik persiapan data seperti normalisasi, dekorrelasi, dan pemilihan fitur dalam kursus tersebut.
Kursus Machine Learning
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
