Kurs
Maschinelles Lernen mit baumbasierten Modellen in Python
5 Std.
116.3K
Viele große Unternehmen nutzen heute eine Form der Vorhersagemodellierung, um ihren Umsatz zu maximieren und das Unternehmenswachstum zu fördern.
Maschinelles Lernen hat eine Vielzahl von Anwendungsfällen in verschiedenen Bereichen. Abonnementbasierte Plattformen wie Netflix und Spotify nutzen beispielsweise maschinelles Lernen, um Inhalte auf der Grundlage der Nutzeraktivitäten in der Anwendung zu empfehlen.
Empfehlungssysteme bringen diesen Unternehmen einen direkten geschäftlichen Nutzen, da ein besseres Nutzererlebnis die Wahrscheinlichkeit erhöht, dass die Kunden die Plattform weiterhin abonnieren. Dies ist ein Beispiel für ein unüberwachtes maschinelles Lernmodell.
Ähnlich könnte ein Mobilfunkanbieter maschinelles Lernen nutzen, um die Stimmung der Nutzer/innen zu analysieren und sein Produktangebot entsprechend der Marktnachfrage zu gestalten. Dies ist ein Beispiel für ein überwachtes maschinelles Lernmodell.
Alle Modelle des maschinellen Lernens können als beaufsichtigt oder unbeaufsichtigt klassifiziert werden. Der größte Unterschied zwischen den beiden ist, dass ein überwachter Algorithmus gelabelte Eingabe- und Ausgabedaten für das Training benötigt, während ein unüberwachtes Modell rohe, nicht gelabelte Datensätze verarbeiten kann.
Überwachte maschinelle Lernmodelle lassen sich weiter in Regressions- und Klassifizierungsalgorithmen unterteilen, die in diesem Artikel näher erläutert werden.
Regressionsalgorithmen werden verwendet, um ein kontinuierliches Ergebnis (y) anhand unabhängiger Variablen (x) vorherzusagen.
Schau dir zum Beispiel die folgende Tabelle an:
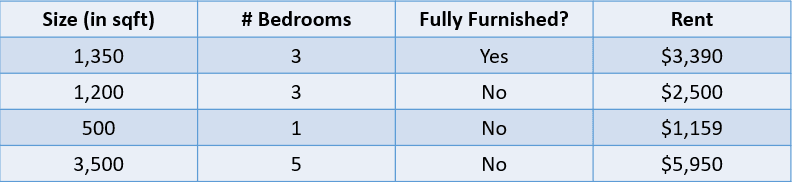
Bild vom Autor
In diesem Fall möchten wir die Miete eines Hauses anhand seiner Größe, der Anzahl der Schlafzimmer und der Tatsache, ob es voll möbliert ist, vorhersagen. Die abhängige Variable "Miete" ist numerisch, was dies zu einem Regressionsproblem macht.
Ein Problem mit vielen Eingangsvariablen wie das obige wird als multivariates Regressionsproblem bezeichnet.
Ein weit verbreiteter Irrglaube von Anfängern der Datenwissenschaft ist, dass ein Regressionsmodell anhand einer Metrik wie der Genauigkeit bewertet werden kann. Die Genauigkeit ist eine Kennzahl, mit der die Leistung von Klassifizierungsmodellen bewertet wird, wie später in diesem Artikel erläutert wird.
Regressionsmodelle hingegen werden mit Kennzahlen wie MAE (Mean Absolute Error), MSE (Mean Squared Error) und RMSE (Root Mean Squared Error) bewertet.
Fügen wir dem obigen Hauspreisproblem einen vorhergesagten Wert hinzu und bewerten wir diese Vorhersagen mithilfe einiger Regressionsmetriken:

Bild vom Autor
Der mittlere absolute Fehler berechnet die Summe der Differenz zwischen allen wahren und vorhergesagten Werten und teilt diese durch die Gesamtzahl der Beobachtungen. Hier ist die Formel zur Berechnung der MAE:
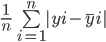
Berechnen wir den mittleren absoluten Fehler der oben genannten Werte mit dieser Formel:
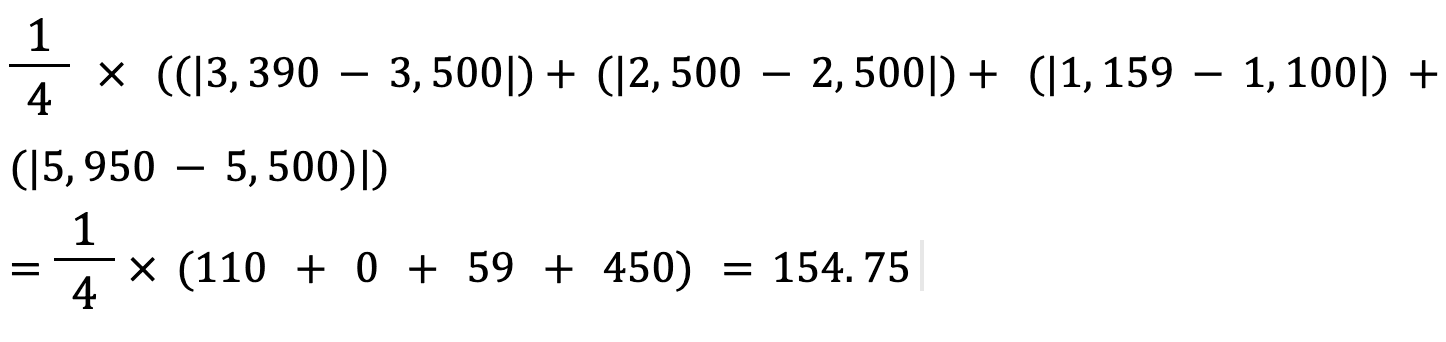
Der mittlere absolute Fehler zwischen dem tatsächlichen und dem vorhergesagten Hauspreis beträgt etwa 155 $.
Die Formel zur Berechnung des mittleren quadratischen Fehlers eines Modells ist ähnlich wie die des mittleren absoluten Fehlers:
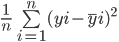
Beachte, dass der mittlere absolute Fehler den durchschnittlichen absoluten Abstand zwischen dem tatsächlichen und dem vorhergesagten Wert berechnet, während der mittlere quadratische Fehler den gemittelten quadratischen Abstand zwischen dem tatsächlichen und dem vorhergesagten Wert ermittelt.
Berechnen wir nun den MSE zwischen den tatsächlichen und den vorhergesagten Werten:
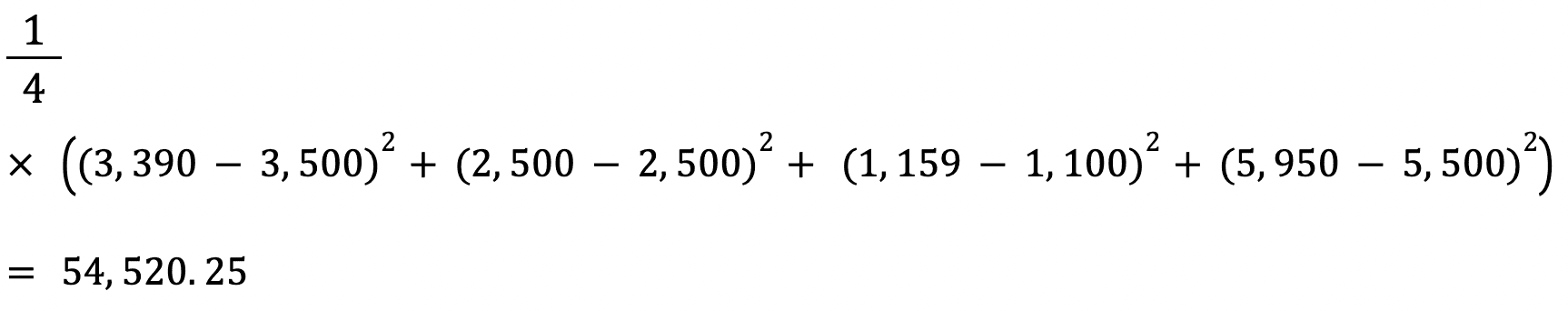
Der RMSE eines Schätzers wird berechnet, indem die Quadratwurzel des mittleren quadratischen Fehlers ermittelt wird. Ein Vorteil der Berechnung des RMSE eines Datensatzes gegenüber dem MSE ist, dass der Fehler in der gleichen Einheit der vorhergesagten Variable angegeben wird.
In diesem Fall beträgt der RMSE zum Beispiel √54.520,25=233,5. Dieser Wert ist interpretierbar, da er sich auf den Hauspreis bezieht, während der mittlere quadratische Fehler nicht interpretierbar ist.
Nachdem du nun das Konzept der Regression verstanden hast, wollen wir uns die verschiedenen Arten von Regressionsmodellen ansehen:
Die lineare Regression ist ein linearer Ansatz zur Modellierung der Beziehung zwischen einer abhängigen und einer oder mehreren unabhängigen Variablen. Bei diesem Algorithmus geht es darum, eine Linie zu finden, die am besten zu den vorliegenden Daten passt.
Hier ist eine visuelle Darstellung, wie ein einfaches lineares Regressionsmodell funktioniert:
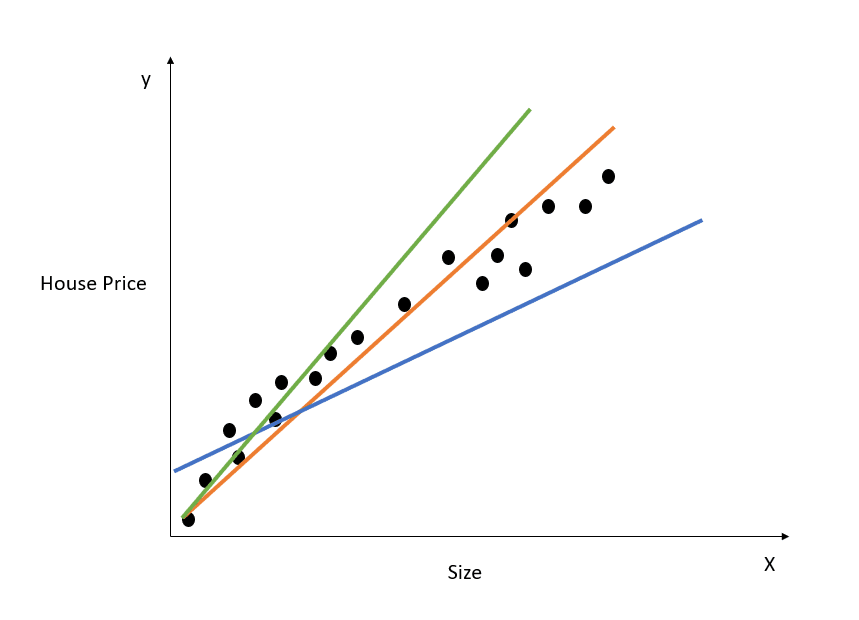
Bild vom Autor
Die obige Grafik zeigt die Beziehung zwischen Hauspreis und Größe. Das lineare Regressionsmodell wird eine Linie erstellen, die diese Beziehung am besten abbildet. Alle Hauspreisvorhersagen für verschiedene Werte der Größe liegen auf der Linie der besten Anpassung.
Beachte, dass im obigen Diagramm drei Linien eingezeichnet sind. Welche dieser Linien ist die "Linie der besten Anpassung"?
Anhand des Diagramms oben können wir sehen, dass die orangefarbene Linie allen dargestellten Datenpunkten am nächsten ist. Daher können wir intuitiv sagen, dass sie die "Linie der besten Anpassung" darstellt.
Hier ist eine formalere Erklärung, wie die beste Anpassungslinie bei der linearen Regression gefunden wird:
Die Gleichung einer geraden Linie ist y=mx+c. Dabei steht m für die Steigung der Linie und c für den y-Achsenabschnitt . Es gibt unendlich viele Möglichkeiten, diese Linie zu ziehen, da es unendlich viele mögliche Werte für m und c gibt.
Die beste Anpassungsgerade, auch bekannt als die Regressionsgerade der kleinsten Quadrate, wird durch Minimierung der Summe der quadratischen Abstände zwischen den wahren und den vorhergesagten Werten gefunden:
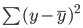
Du kannst das Tutorial Grundlagen der linearen Regression in Python lesen, um ein tieferes Verständnis des maschinellen Lernmodells der linearen Regression und seiner Implementierung zu erlangen.
Die Ridge-Regression ist eine Erweiterung des oben beschriebenen linearen Regressionsmodells. Es ist eine Technik, die verwendet wird, um die Koeffizienten eines Regressionsmodells so niedrig wie möglich zu halten.
Ein Problem bei einem einfachen linearen Regressionsmodell ist, dass seine Koeffizienten groß werden können, wodurch das Modell empfindlicher auf Eingaben reagiert. Das kann zu einer Überanpassung führen.
Nehmen wir ein einfaches Beispiel, um das Konzept der Überanpassung zu verstehen:
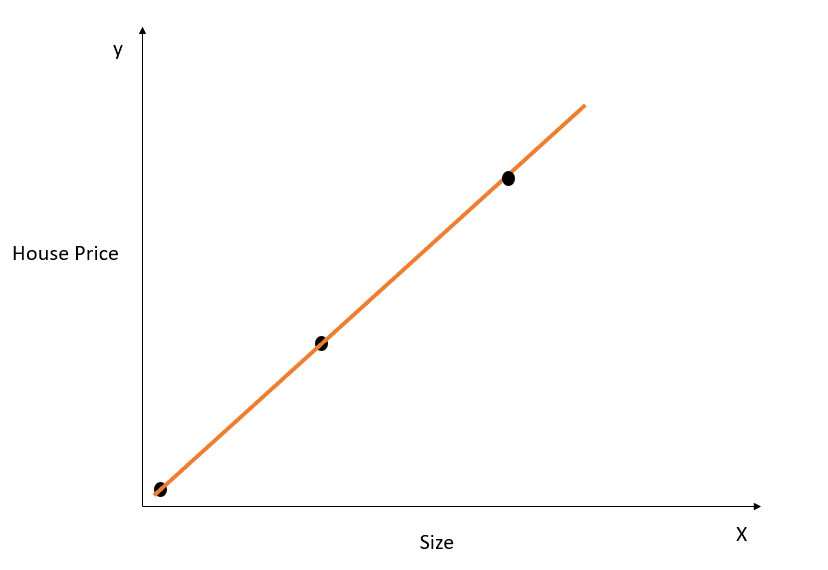
Bild vom Autor
In der obigen Abbildung modelliert die Anpassungsgerade die Beziehung zwischen X und y perfekt, und die Summe des quadratischen Abstands zwischen den wahren und den vorhergesagten Werten ist 0. Erinnere dich daran, dass die Gleichung für diese Linie y=mx+c lautet .
Diese Linie passt zwar perfekt auf den Trainingsdatensatz, lässt sich aber wahrscheinlich nicht gut auf die Testdaten übertragen. Dieses Phänomen wird als Overfitting bezeichnet. In diesem Artikel erfährst du mehr über Overfitting.
Einfach ausgedrückt: Ein hochkomplexes Modell erkennt unnötige Nuancen im Trainingsdatensatz, die in der realen Welt nicht vorkommen. Dieses Modell wird bei den Trainingsdaten extrem gut abschneiden, aber bei Datensätzen, die nicht trainiert wurden, unterdurchschnittlich.
Ein lineares Regressionsmodell mit großen Koeffizienten ist anfällig für Overfitting.
Bei der Ridge-Regression handelt es sich um eine Regularisierungstechnik, die den Algorithmus dazu zwingt, kleinere Koeffizienten zu wählen, indem er seine Verlustfunktion mit zusätzlichen Kosten bestraft.
Wie im vorherigen Abschnitt gezeigt, wollen wir den Fehler bei einer einfachen linearen Regression minimieren:
Bei der Ridge-Regression ändert sich diese Gleichung geringfügig, und zu dem oben genannten Fehler wird ein Strafterm hinzugefügt:
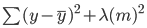
Beachte, dass es einen Wert (lambda) gibt, der mit den Koeffizienten des Modells multipliziert wird. Da dieses Modell nur eine Variable hat, gibt es einen einzigen Koeffizienten, zu dem ein Strafterm hinzugefügt wird. Wenn es mehrere unabhängige Variablen gibt, wird lambda mit der Summe der quadrierten Koeffizienten multipliziert.
Dieser Strafterm bestraft das Modell für die Wahl größerer Koeffizienten. Ziel ist es, die Koeffizientenwerte so zu verkleinern, dass die Koeffizienten von Variablen mit einem geringen Beitrag zum Ergebnis nahe bei 0 liegen. Das reduziert die Modellvarianz und hilft, die Überanpassung zu verringern.
Beachte, dass ein Lambda-Wert von 0 keinerlei Auswirkung hat und der Strafterm eliminiert wird. Ein höherer Lambda-Wert führt zu einer größeren Schrumpfungsstrafe, und die Modellkoeffizienten nähern sich der Null.
Achte bei der Wahl des Lambda-Werts darauf, dass du ein Gleichgewicht zwischen Einfachheit und guter Anpassung an die Trainingsdaten findest. Ein höherer Lambda-Wert führt zu einem einfachen, verallgemeinerten Modell, aber wenn du einen zu hohen Wert wählst, besteht die Gefahr der Unteranpassung. Andererseits kann die Wahl eines Lambdawertes, der sehr nahe bei Null liegt, zu einem sehr komplexen Modell führen.
Die Lasso-Regression ist eine weitere Erweiterung der linearen Regression, bei der die Modellkoeffizienten durch Hinzufügen eines Strafterms zur Kostenfunktion verkleinert werden.
Hier ist der Fehler, der bei der Lassoregression minimiert werden muss:
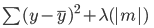
Beachte, dass diese Gleichung der eines Ridge-Regressionsmodells entspricht, nur dass wir Lambda nicht mit dem Quadrat des Koeffizienten multiplizieren, sondern mit dem absoluten Wert des Koeffizienten.
Der größte Unterschied zwischen Ridge- und Lasso-Regression besteht darin, dass bei der Ridge-Regression die Modellkoeffizienten zwar gegen Null schrumpfen können, aber nie wirklich Null werden. Bei der Lasso-Regression ist es möglich, dass die Modellkoeffizienten zu Null werden.
Wenn der Koeffizient einer unabhängigen Variable Null erreicht, kann das Merkmal aus dem Modell ausgeschlossen werden. Das reduziert den Merkmalsraum und macht den Algorithmus einfacher zu interpretieren, was der größte Vorteil der Lassoregression ist.
Daher kann die Lasso-Regression auch als Merkmalsauswahlverfahren verwendet werden, da Variablen mit geringer Bedeutung Koeffizienten haben können, die den Wert Null erreichen und vollständig aus dem Modell entfernt werden.
Du kannst mit der Scikit-Learn-Bibliothek lineare, Ridge- und Lasso-Regressionsmodelle erstellen:
1. Lineare Regression
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Um das Modell auf deinen Trainingsdatensatz anzuwenden, führe aus:
lr_model.fit(X_train,y_train)2. Ridge Regression
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)Der Lambda-Term kann bei der Definition des Modells über den Parameter "alpha" konfiguriert werden.
3. Lasso-Regression
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Wenn du mehr über lineare Modelle und deren Erstellung in Python erfahren möchtest, besuche unseren Kurs Einführung in die lineare Modellierung in Python.
Wir verwenden Klassifizierungsalgorithmen, um ein diskretes Ergebnis (y) anhand unabhängiger Variablen (x) vorherzusagen. Die abhängige Variable ist in diesem Fall immer eine Klasse oder Kategorie.
Zum Beispiel ist die Vorhersage, ob ein Patient aufgrund seiner Risikofaktoren wahrscheinlich eine Herzerkrankung entwickeln wird, ein Klassifizierungsproblem:
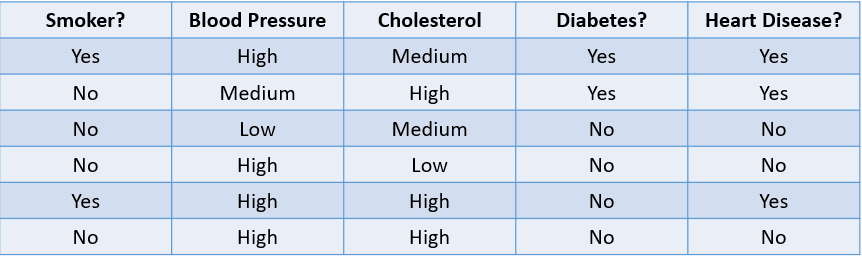
Bild vom Autor
Die Tabelle oben zeigt ein Klassifizierungsproblem mit vier unabhängigen Variablen und einer abhängigen Variable, der Herzkrankheit. Da es nur zwei mögliche Ergebnisse gibt (Ja und Nein), nennt man dies ein binäres Klassifizierungsproblem.
Andere Beispiele für ein binäres Klassifizierungsproblem sind die Klassifizierung, ob eine E-Mail Spam oder legitim ist, die Vorhersage der Kundenabwanderung oder die Entscheidung, ob jemandem ein Kredit gewährt werden soll.
Ein Mehrklassen-Klassifizierungsproblem ist ein Problem mit drei oder mehr möglichen Ergebnissen, z. B. die Wettervorhersage oder die Unterscheidung zwischen verschiedenen Tierarten.
Es gibt viele Möglichkeiten, ein Klassifizierungsmodell zu bewerten. Obwohl die Genauigkeit die am häufigsten verwendete Kennzahl ist, ist sie nicht immer die zuverlässigste.
Schauen wir uns einige gängige Methoden an, um einen Klassifizierungsalgorithmus anhand des unten stehenden Datensatzes zu bewerten:
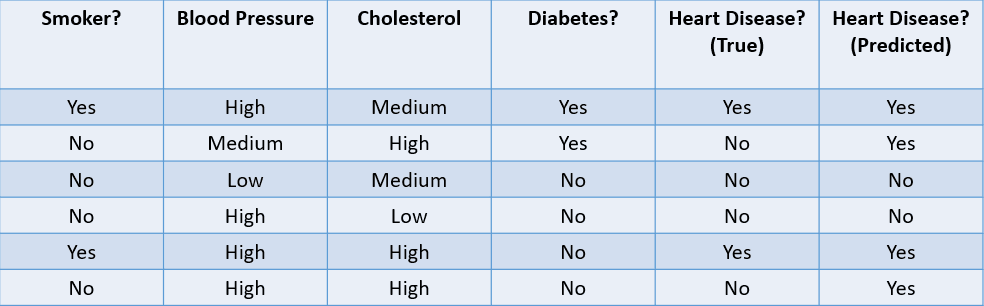
Bild vom Autor
1. Genauigkeit: Die Genauigkeit kann als der Anteil der richtigen Vorhersagen des maschinellen Lernmodells definiert werden.
Die Formel zur Berechnung der Genauigkeit lautet:

In diesem Fall beträgt die Genauigkeit 46, also 0,67.
2. Präzision: Die Genauigkeit ist eine Kennzahl, mit der die Qualität der positiven Vorhersagen des Modells berechnet wird. Sie ist definiert als:
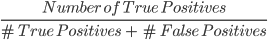
Das obige Modell hat eine Genauigkeit von 24, also 0,5.
3. Rückruf: Der Recall wird verwendet, um die Qualität der negativen Vorhersagen des Modells zu berechnen. Sie ist definiert als:
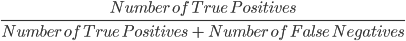
Das obige Modell hat einen Rückruf von 2/2 oder 1.
Schauen wir uns ein einfaches Beispiel an, um den Unterschied zwischen Precision und Recall zu verstehen:
Es gibt eine seltene, tödliche Krankheit, die nur einen Bruchteil der Bevölkerung betrifft. 95% der Patienten in der Datenbank eines Krankenhauses haben die Krankheit nicht, während nur 5% sie haben. Wenn wir einen maschinellen Lernalgorithmus entwickeln, der vorhersagt, dass niemand die Krankheit hat, dann liegt die Trainingsgenauigkeit dieses Modells bei 95 %. Trotz der hohen Genauigkeit wissen wir, dass dies kein gutes Modell ist, da es nicht in der Lage ist, Patienten mit der Krankheit zu identifizieren.
Hier kommen Metriken wie Precision und Recall ins Spiel. Die Präzision oder Spezifität gibt an, wie gut das Modell in der Lage ist, Menschen ohne die Krankheit zu identifizieren. Der Recall oder die Sensitivität sagt uns, wie gut das Modell Menschen mit der Krankheit identifiziert.
Ein "guter" Präzisions- und Erinnerungswert ist subjektiv und hängt von deinem Anwendungsfall ab.
In diesem Szenario der Krankheitsvorhersage wollen wir immer Menschen mit der Krankheit identifizieren, auch wenn dies mit dem Risiko eines falsch positiven Ergebnisses verbunden ist. Hier bauen wir das Modell so auf, dass es eine höhere Auffindbarkeit als Genauigkeit hat.
Wenn wir hingegen ein Modell entwickeln, das böswillige Akteure daran hindert, eine E-Commerce-Website zu betreten, wollen wir vielleicht eine höhere Präzision, da die Sperrung legitimer Nutzer zu einem Umsatzrückgang führen würde.
Wir verwenden oft eine Metrik namens F1-Score, um den harmonischen Mittelwert der Präzision und des Recalls eines Klassifikators zu ermitteln. Einfach ausgedrückt, kombiniert der F1-Score Präzision und Recall zu einer einzigen Metrik, indem er ihren Durchschnitt berechnet.
AUC, oder Area Under the Curve, ist eine weitere beliebte Kennzahl zur Messung der Leistung eines Klassifizierungsmodells. Der AUC eines Algorithmus sagt uns etwas über seine Fähigkeit, zwischen positiven und negativen Klassen zu unterscheiden.
Um mehr über Kennzahlen wie AUC und ihre Berechnung zu erfahren, besuche den Kurs Supervised Learning in R von Datacamp.
Schauen wir uns nun die verschiedenen Arten von Klassifizierungsmodellen an und wie sie funktionieren:
Die logistische Regression ist ein einfaches Klassifikationsmodell, das die Wahrscheinlichkeit des Eintretens eines Ereignisses vorhersagt.
Hier ist ein Beispiel dafür, wie das logistische Regressionsmodell funktioniert:
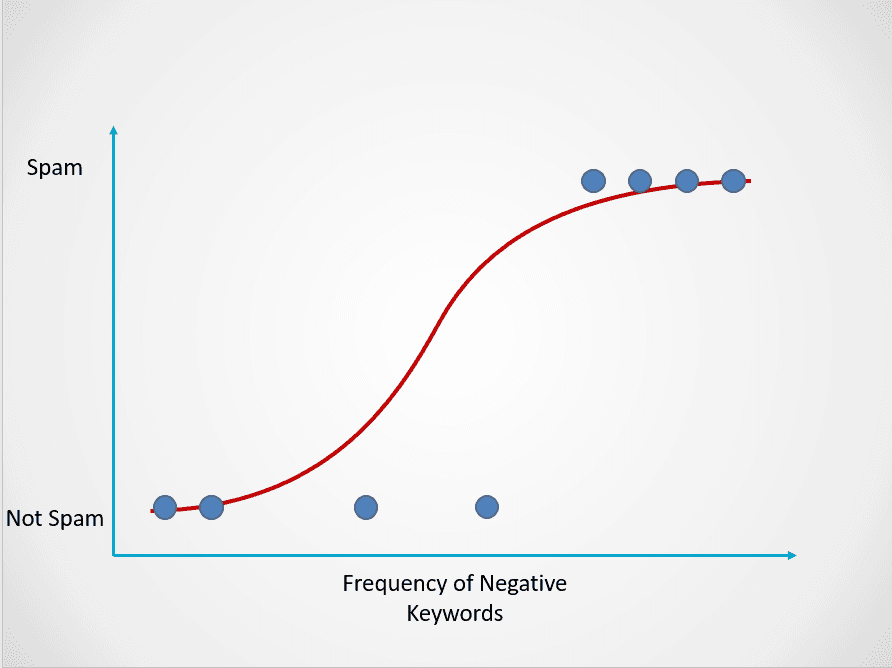
Bild vom Autor
Das Diagramm oben zeigt eine logistische Funktion, die E-Mail-Daten in zwei Kategorien einteilt: "Spam" und "Nicht-Spam" basierend auf der Häufigkeit der negativen Schlüsselwörter im Text.
Beachte, dass die logistische Regression, anders als die lineare Regression, mit einer S-förmigen Kurve modelliert wird. Dies wird als logistische Funktion bezeichnet und hat folgende Formel:
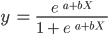
Während die lineare Funktion keine obere und untere Grenze hat, liegt die logistische Funktion zwischen 0 und 1. Das Modell sagt eine Wahrscheinlichkeit zwischen 0 und 1 voraus, die die Klasse bestimmt, zu der der Datenpunkt gehört.
Wenn der Text in dieser Spam-E-Mail wenig bis gar keine verdächtigen Schlüsselwörter enthält, ist die Wahrscheinlichkeit, dass es sich um Spam handelt, gering und liegt nahe bei 0. Andererseits hat eine E-Mail mit vielen verdächtigen Schlüsselwörtern eine hohe Wahrscheinlichkeit, Spam zu sein, die nahe bei 1 liegt.
Diese Wahrscheinlichkeit wird dann in ein Klassifizierungsergebnis umgewandelt:
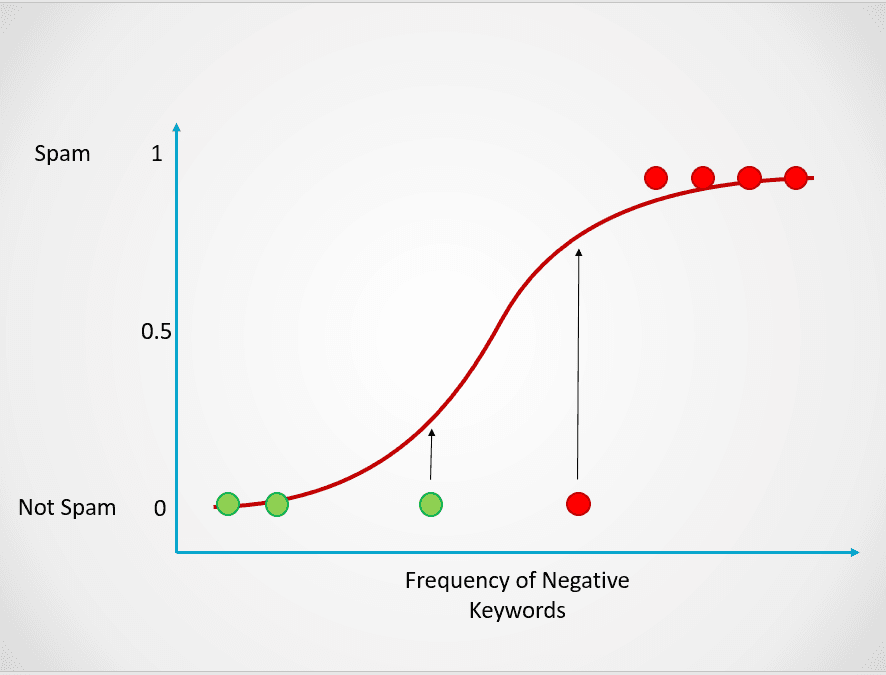
Bild vom Autor
Alle rot gefärbten Punkte haben eine Wahrscheinlichkeit von >= 0,5, Spam zu sein. Daher werden sie als Spam eingestuft und das logistische Regressionsmodell liefert ein Klassifizierungsergebnis von 1. Die grün gefärbten Punkte haben eine Wahrscheinlichkeit von < 0,5, dass es sich um Spam handelt. Daher werden sie vom Modell als "Kein Spam" eingestuft und ergeben ein Klassifizierungsergebnis von 0.
Bei binären Klassifizierungsproblemen wie dem obigen ist der Standardschwellenwert eines logistischen Regressionsmodells 0,5, was bedeutet, dass Datenpunkte mit einer höheren Wahrscheinlichkeit als 0,5 automatisch mit 1 gekennzeichnet werden. Dieser Schwellenwert kann je nach Anwendungsfall manuell geändert werden, um bessere Ergebnisse zu erzielen.
Erinnere dich daran, dass wir bei der linearen Regression die beste Anpassungslinie gefunden haben, indem wir die Summe der quadratischen Fehler zwischen den vorhergesagten und den wahren Werten minimiert haben. Bei der logistischen Regression werden die Koeffizienten jedoch nicht mit der Methode der kleinsten Quadrate, sondern mit der sogenannten Maximum-Likelihood-Schätzung geschätzt.
Lies das Python-Tutorial zur logistischen Regression, um mehr über das Konzept der Maximum-Likelihood-Schätzung zu erfahren und wie die logistische Regression funktioniert.
KNN ist ein Klassifizierungsalgorithmus, der einen Datenpunkt danach klassifiziert, zu welcher Gruppe die ihm am nächsten liegenden Datenpunkte gehören.
Hier ist ein einfaches Beispiel, das zeigt, wie das K-Nächste-Nachbarn-Modell funktioniert:
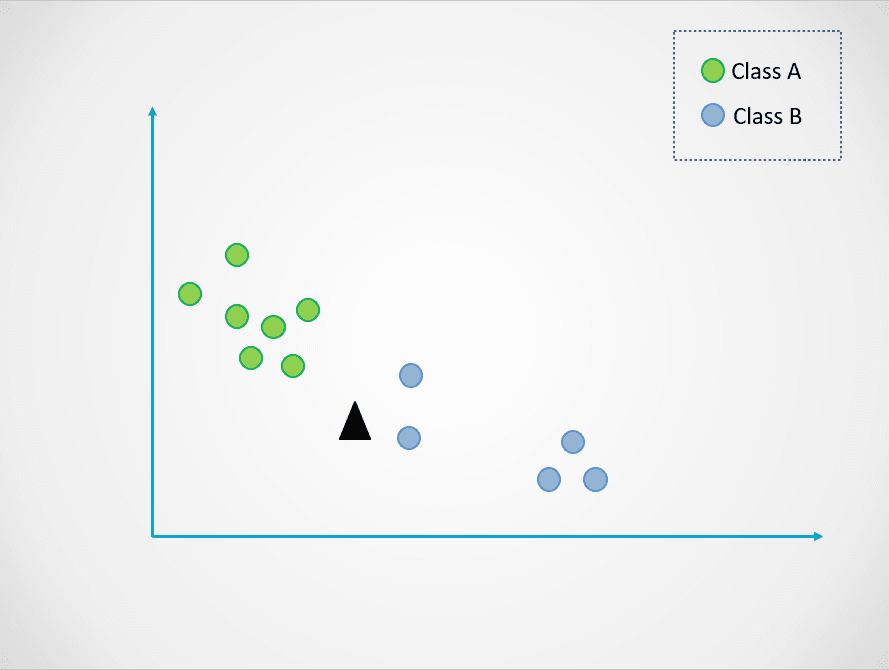
Bild vom Autor
Im obigen Diagramm gibt es zwei Klassen von Datenpunkten - A und B. Das schwarze Dreieck steht für einen neuen Datenpunkt, der in eine dieser beiden Klassen eingeordnet werden muss.
Der K-Nächste-Nachbarn-Algorithmus funktioniert folgendermaßen:
In der Abbildung oben ist der Wert von k 1. Das bedeutet, dass wir uns nur einen nächsten Nachbarn des schwarzen Dreiecks ansehen und den Datenpunkt dieser Klasse zuordnen. Der neue Datenpunkt liegt dem blauen Punkt am nächsten, also ordnen wir ihn der Klasse B zu.
Ändern wir nun den Wert von k. Probieren wir zwei mögliche Werte für k aus, 3 und 7:
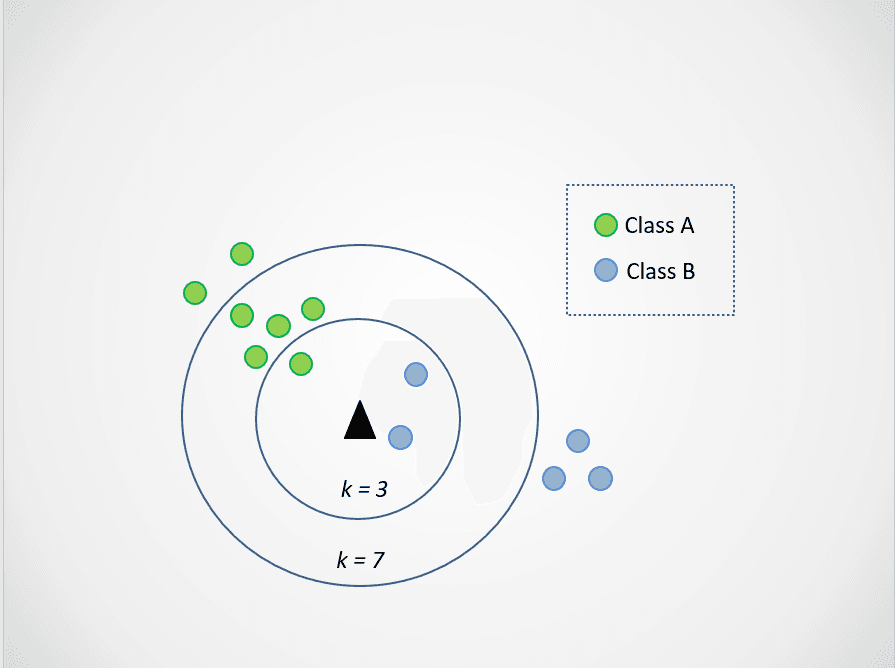
Bild vom Autor
Wenn wir nun k=3 wählen, liegt der neue Datenpunkt zwischen zwei Kategorien. Das bedeutet, dass wir die Mehrheitsklasse auswählen. Zwei nächste Nachbarn sind blau und ein nächster Nachbar ist grün, also wird der Datenpunkt wieder der Klasse mit den blauen Punkten, Klasse B, zugeordnet.
Wenn k=7 ist, ändern sich die Dinge jedoch. Jetzt sind zwei der nächsten Nachbarn blau und sieben grün. In diesem Fall wird der Datenpunkt der grünen Klasse, Klasse A, zugeordnet.
Die Wahl unterschiedlicher Werte für k hat Auswirkungen darauf, welcher Klasse der neue Punkt zugeordnet wird.
Wenn du einen zu kleinen Wert auswählst, kann er verrauscht sein und zu Ausreißern führen, während du bei einem großen Wert möglicherweise Kategorien mit weniger Datenpunkten übersiehst.
Wenn du mehr über den K-Nächste-Nachbarn-Algorithmus und die Auswahl eines optimalen "k"-Werts erfahren möchtest, lies dieses KNN-Tutorial.
Hier sind einige Codeschnipsel, mit denen du ein Klassifizierungsmodell in Python mit der Scikit-Learn-Bibliothek erstellen kannst:
1. Logistische Regression
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-Nächste Nachbarn
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Baumbasierte Modelle sind überwachte maschinelle Lernalgorithmen, die eine baumähnliche Struktur aufbauen, um Vorhersagen zu treffen. Sie können sowohl für Klassifizierungs- als auch für Regressionsprobleme verwendet werden.
In diesem Abschnitt werden wir zwei der am häufigsten verwendeten baumbasierten maschinellen Lernmodelle untersuchen: Entscheidungsbäume und Zufallswälder.
Ein Entscheidungsbaum ist der einfachste baumbasierte maschinelle Lernalgorithmus. Mit diesem Modell können wir den Datensatz anhand bestimmter Parameter kontinuierlich aufteilen, bis eine endgültige Entscheidung getroffen wird.
Hier ist ein einfaches Beispiel, das zeigt, wie der Entscheidungsbaum-Algorithmus funktioniert:
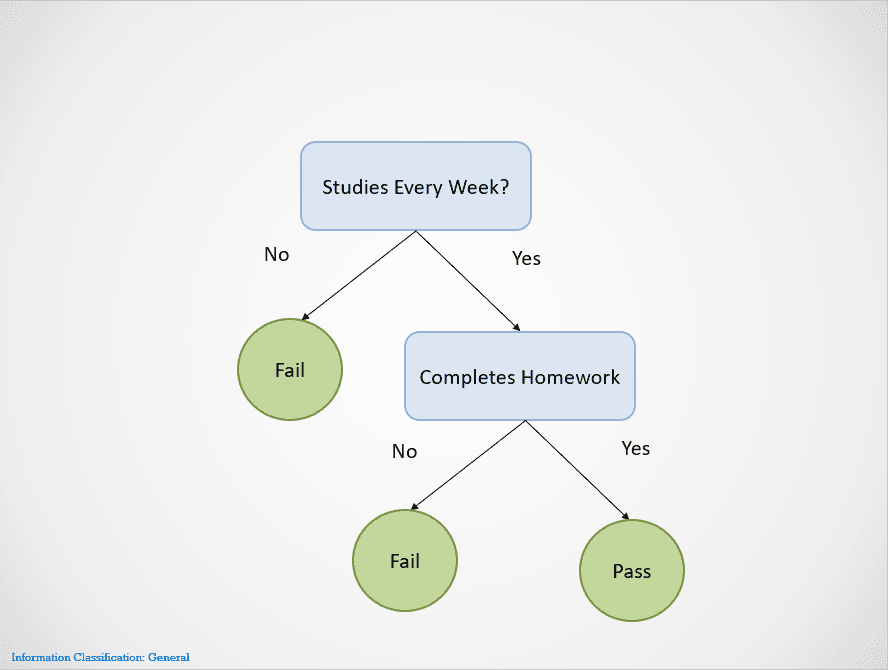
Bild vom Autor
Entscheidungsbäume teilen sich an verschiedenen Knoten auf, bis ein Ergebnis erzielt wird.
Wenn ein Schüler in diesem Fall nicht jede Woche lernt, wird er durchfallen. Wenn sie jede Woche lernen, aber ihre Hausaufgaben nicht erledigen, ist das Ergebnis immer noch "Durchgefallen". Sie werden nur bestehen, wenn sie jede Woche lernen und alle Hausaufgaben erledigen.
Beachte, dass der obige Entscheidungsbaum sich zuerst bei der Variable "Studierst du jede Woche?" aufspaltet. Wenn die Antwort "Nein" lautet, wird die Aufteilung abgebrochen und der/die Schüler/in fällt durch.
Der Entscheidungsbaum wählt eine Variable aus, die er anhand der Entropie zuerst aufteilt. Es hört auf zu splitten, wenn ein "reiner Split" erreicht wird, d.h. wenn alle Datenpunkte zu einer einzigen Klasse gehören.
Es gibt viele Möglichkeiten, einen Entscheidungsbaum zu erstellen. Der Baum muss ein Merkmal finden, das er als erstes, zweites, drittes usw. aufspalten kann. Diese Struktur wird auf der Grundlage einer Metrik namens Informationsgewinn erstellt. Der bestmögliche Entscheidungsbaum ist derjenige mit dem höchsten Informationsgewinn.
Wenn du mehr über die Funktionsweise von Entscheidungsbäumen und Metriken wie Entropie und Informationsgewinn erfahren möchtest, findest du in diesem Artikel über die Klassifizierung von Python-Entscheidungsbäumen weitere Details.
Einer der größten Vorteile von Entscheidungsbäumen ist, dass sie gut interpretierbar sind. Es ist einfach, rückwärts zu arbeiten und zu verstehen, wie ein Entscheidungsbaum auf der Grundlage des Trainingsdatensatzes zu seinem endgültigen Ergebnis gekommen ist.
Allerdings sind Entscheidungsbäume auch sehr anfällig für Overfitting, wenn man sie vollständig wachsen lässt. Das liegt daran, dass sie so konzipiert sind, dass sie alle Stichproben des Trainingsdatensatzes perfekt aufspalten, wodurch sie nicht gut auf externe Daten verallgemeinern können.
Dieser Nachteil von Entscheidungsbäumen kann mit dem Random-Forest-Algorithmus behoben werden.
Das Random-Forest-Modell ist ein baumbasierter Algorithmus, der uns hilft, einige der Probleme, die bei der Verwendung von Entscheidungsbäumen auftreten, zu entschärfen, z. B. das Overfitting. Zufallswälder werden erstellt, indem die Vorhersagen mehrerer Entscheidungsbaummodelle kombiniert werden und ein einziges Ergebnis liefern.
Dies geschieht in zwei Schritten:
Im Falle eines Regressionsproblems ist das Ergebnis die durchschnittliche Vorhersage aller Entscheidungsbäume.
Hier ist eine einfache Grafik, die zeigt, wie der Random Forest Algorithmus funktioniert:
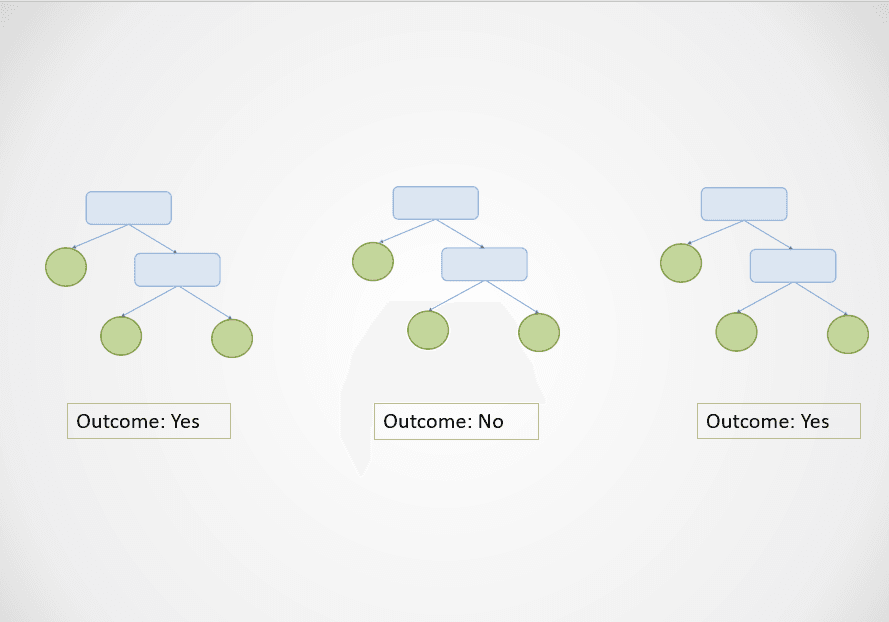
Bild vom Autor
Im obigen Diagramm sagen der erste und der dritte Entscheidungsbaum "Ja" voraus, während der zweite "Nein" voraussagt.
Da es sich um eine Klassifizierungsaufgabe handelt, wird die Mehrheitsklasse ausgewählt. In diesem Fall wird der Random-Forest-Algorithmus auf der Grundlage der Vorhersagen von 2 der 3 Entscheidungsbäume das Endergebnis "Ja" liefern.
Einer der größten Vorteile des Random-Forest-Algorithmus ist, dass er sich gut verallgemeinern lässt, da er die Ergebnisse mehrerer Entscheidungsbäume kombiniert, die auf einer Teilmenge von Merkmalen trainiert wurden.
Während sich die Ergebnisse eines einzelnen Entscheidungsbaums aufgrund einer kleinen Änderung im Trainingsdatensatz drastisch ändern können, tritt dieses Problem beim Random-Forest-Algorithmus nicht auf, da der Trainingsdatensatz viele Male abgetastet wird.
Führe die folgenden Codezeilen aus, um einen baumbasierten maschinellen Lernalgorithmus mit Scikit-Learn zu erstellen:
1. Entscheidungsbaum
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Zufallsforsten
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Bislang haben wir uns mit überwachten maschinellen Lernmodellen beschäftigt, um Klassifizierungs- und Regressionsprobleme zu lösen. Jetzt werden wir uns mit einem beliebten Ansatz des unüberwachten Lernens beschäftigen, dem Clustering.
Einfach ausgedrückt ist das Clustering die Aufgabe, eine Gruppe von Objekten zu bilden, die einander ähnlich sind, sich aber von anderen unterscheiden. Diese Technik kann in verschiedenen Geschäftsbereichen eingesetzt werden, z. B. bei der Empfehlung von Filmen für Nutzer mit ähnlichen Sehgewohnheiten auf einer Videostreaming-Website, bei der Erkennung von Anomalien und bei der Kundensegmentierung.
In diesem Abschnitt werden wir einen Algorithmus namens K-Means-Clustering untersuchen - das einfachste und beliebteste Modell des maschinellen Lernens, das für unüberwachte Lernaufgaben verwendet wird.
Das K-Means-Clustering ist eine unbeaufsichtigte maschinelle Lerntechnik, mit der ähnliche Objekte in Daten gruppiert werden können.
Hier ist ein Beispiel dafür, wie der K-Means Clustering-Algorithmus funktioniert:

Bild vom Autor
Schritt 1: Das Bild oben besteht aus unbeschrifteten Beobachtungen, die nicht gruppiert wurden. Zu Beginn wird jede Beobachtung nach dem Zufallsprinzip einem Cluster zugewiesen. Dann wird für jeden Cluster ein Schwerpunkt berechnet.
Diese sind in der folgenden Abbildung mit dem "+"-Symbol dargestellt:
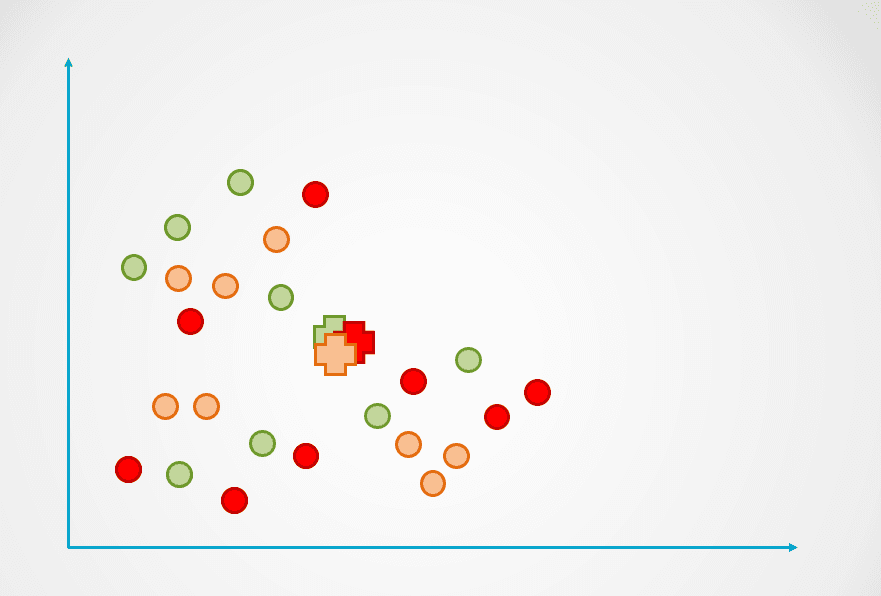
Bild vom Autor
Schritt 2: Als Nächstes wird der Abstand jedes Datenpunktes zum Schwerpunkt gemessen und jeder Punkt wird dem nächstgelegenen Schwerpunkt zugeordnet:
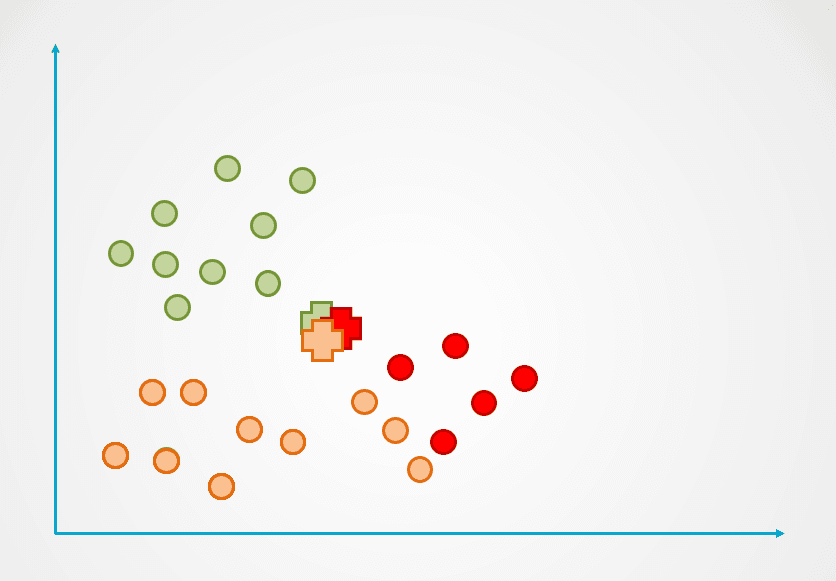
Bild vom Autor
Schritt 3: Der Schwerpunkt des neuen Clusters wird dann neu berechnet, und die Datenpunkte werden entsprechend neu zugewiesen.
Schritt 4: Dieser Vorgang wird so lange wiederholt, bis keine Datenpunkte mehr neu zugewiesen werden:
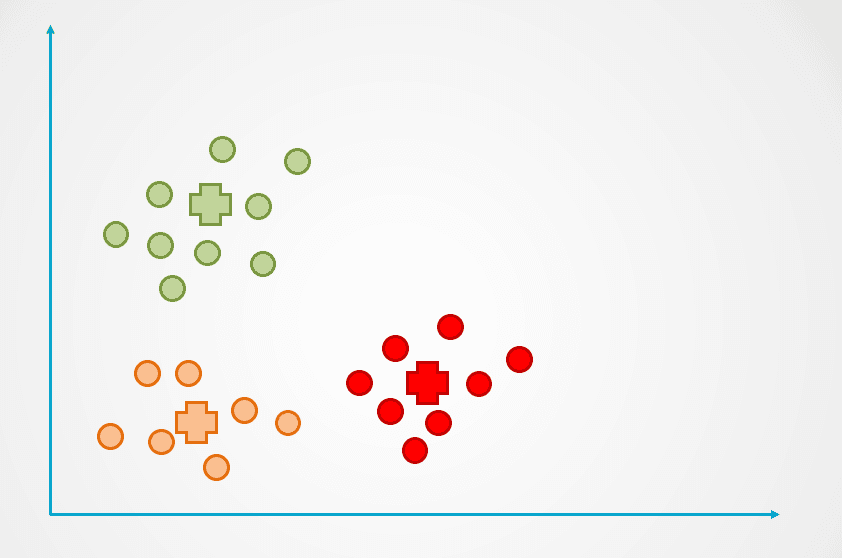
Bild vom Autor
Beachte, dass im obigen Beispiel drei Cluster erstellt wurden. Die Anzahl der Cluster wird beim K-Means-Clusteralgorithmus als "k" bezeichnet und muss von uns festgelegt werden.
Es gibt verschiedene Möglichkeiten, "k" in K-Means auszuwählen, die beliebteste davon ist die Ellbogenmethode. Bei dieser Technik wird der Fehler für eine unterschiedliche Anzahl von Clustern in einem Diagramm aufgetragen und der Wendepunkt der Kurve als "k" gewählt.
In unserem Tutorial zum K-Means-Clustering in Python erfährst du mehr über die Ellbogenmethode und die Funktionsweise des K-Means-Clustering.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')Das Argument n_clusters gibt die Anzahl der Cluster "k" an, die du beim Aufbau des Algorithmus definieren musst.
Wenn du es geschafft hast, den ganzen Artikel zu lesen, gratuliere ich dir! Du kennst jetzt einige der beliebtesten überwachten und unüberwachten maschinellen Lernmodelle und Algorithmen und weißt, wie sie zur Lösung einer Vielzahl von Vorhersageproblemen eingesetzt werden können.
Um ein/e Datenwissenschaftler/in zu werden, musst du verstehen, wie die verschiedenen Arten von maschinellen Lernmodellen funktionieren, um sie zur Lösung eines Problems anzuwenden. Wenn du zum Beispiel ein Modell erstellen möchtest, das interpretierbar ist und wenig Rechenzeit benötigt, kann es sinnvoll sein, einen Entscheidungsbaum zu erstellen. Wenn dein Ziel jedoch darin besteht, ein Modell zu erstellen, das gut verallgemeinert, kannst du stattdessen einen Random-Forest-Algorithmus verwenden.
Es ist auch wichtig zu verstehen, wie man Modelle des maschinellen Lernens bewertet. Ein "gutes" Modell ist subjektiv und hängt stark von deinem Anwendungsfall ab. Bei Klassifizierungsproblemen zum Beispiel ist eine hohe Genauigkeit allein kein Indikator für ein gutes Modell. Als Datenwissenschaftler musst du Metriken wie Präzision, Recall und F1-Score überprüfen, um eine bessere Vorstellung davon zu bekommen, wie gut dein Modell funktioniert.
Wenn du ein tieferes Verständnis von Machine Learning-Modellen als die in diesem Artikel behandelten Konzepte erlangen möchtest, besuche den Kurs Machine Learning Scientist with Python. In diesem Lernpfad lernst du die Theorie hinter der Funktionsweise von Machine-Learning-Modellen und wie sie in Python implementiert werden können. Außerdem lernst du in diesem Kurs Techniken zur Datenaufbereitung wie Normalisierung, Dekorrelation und Merkmalsauswahl kennen.
Kurse zum maschinellen Lernen
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Sejal Jaiswal
Tutorial
Mark Pedigo
Tutorial
Derrick Mwiti
Tutorial
Sejal Jaiswal