Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
Os modelos de aprendizado de máquina são algoritmos que podem identificar padrões ou fazer previsões em conjuntos de dados não vistos. Diferentemente dos programas baseados em regras, esses modelos não precisam ser codificados explicitamente e podem evoluir com o tempo à medida que novos dados entram no sistema.
Este artigo apresentará os diferentes tipos de problemas que podem ser resolvidos com o aprendizado de máquina. Em seguida, você aprenderá sobre os oito algoritmos de aprendizado de máquina mais populares usados pelos cientistas de dados para resolver problemas de negócios.
Ao final deste artigo, você estará familiarizado com a teoria e a intuição matemática por trás desses modelos, além de saber como implementá-los usando a biblioteca Scikit-Learn em Python.
Explicaremos conceitos complexos de aprendizado de máquina em linguagem simples, e este artigo é recomendado para aspirantes à ciência de dados que não tenham formação sólida em matemática ou estatística.
Atualmente, muitas organizações de grande porte usam alguma forma de modelagem preditiva para maximizar a receita e impulsionar o crescimento dos negócios.
O aprendizado de máquina tem uma variedade de casos de uso em diferentes domínios. As plataformas baseadas em assinatura, como Netflix e Spotify, por exemplo, usam o aprendizado de máquina para recomendar conteúdo com base na atividade do usuário no aplicativo.
Os sistemas de recomendação agregam valor comercial direto a essas empresas, uma vez que uma melhor experiência do usuário fará com que os clientes continuem assinando a plataforma. Esse é um exemplo de um modelo de aprendizado de máquina não supervisionado.
Da mesma forma, um provedor de serviços móveis pode usar o aprendizado de máquina para analisar o sentimento do usuário e selecionar sua oferta de produtos de acordo com a demanda do mercado. Esse é um exemplo de um modelo de aprendizado de máquina supervisionado.
Todos os modelos de aprendizado de máquina podem ser classificados como supervisionados ou não supervisionados. A maior diferença entre os dois é que um algoritmo supervisionado requer dados de treinamento de entrada e saída rotulados, enquanto um modelo não supervisionado pode processar conjuntos de dados brutos e não rotulados.
Os modelos supervisionados de aprendizado de máquina podem ser classificados em algoritmos de regressão e classificação, que serão explicados em mais detalhes neste artigo.
Os algoritmos de regressão são usados para prever um resultado contínuo (y) usando variáveis independentes (x).
Por exemplo, observe a tabela abaixo:
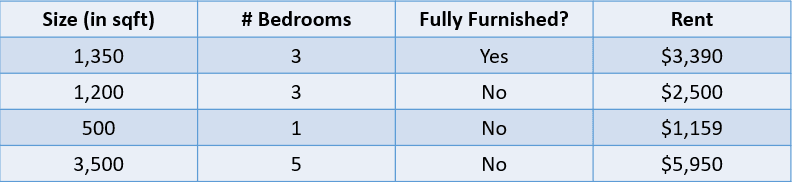
Imagem do autor
Nesse caso, gostaríamos de prever o aluguel de uma casa com base em seu tamanho, no número de quartos e se ela está totalmente mobiliada. A variável dependente, "Aluguel", é numérica, o que torna este um problema de regressão.
Um problema com muitas variáveis de entrada, como o problema acima, é chamado de problema de regressão multivariada.
Uma concepção errônea comum dos iniciantes em ciência de dados é que um modelo de regressão pode ser avaliado usando uma métrica como a precisão. A precisão é uma métrica usada para avaliar o desempenho dos modelos de classificação, como será explicado mais adiante neste artigo.
Os modelos de regressão, por outro lado, são avaliados usando métricas como MAE (erro absoluto médio), MSE (erro quadrático médio) e RMSE (raiz do erro quadrático médio).
Vamos adicionar um valor previsto ao problema do preço do imóvel acima e avaliar essas previsões usando algumas métricas de regressão:

Imagem do autor
O erro absoluto médio calcula a soma da diferença entre todos os valores reais e previstos e divide esse valor pelo número total de observações. Aqui está a fórmula para calcular o MAE:
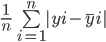
Vamos calcular o erro médio absoluto dos valores acima usando esta fórmula:
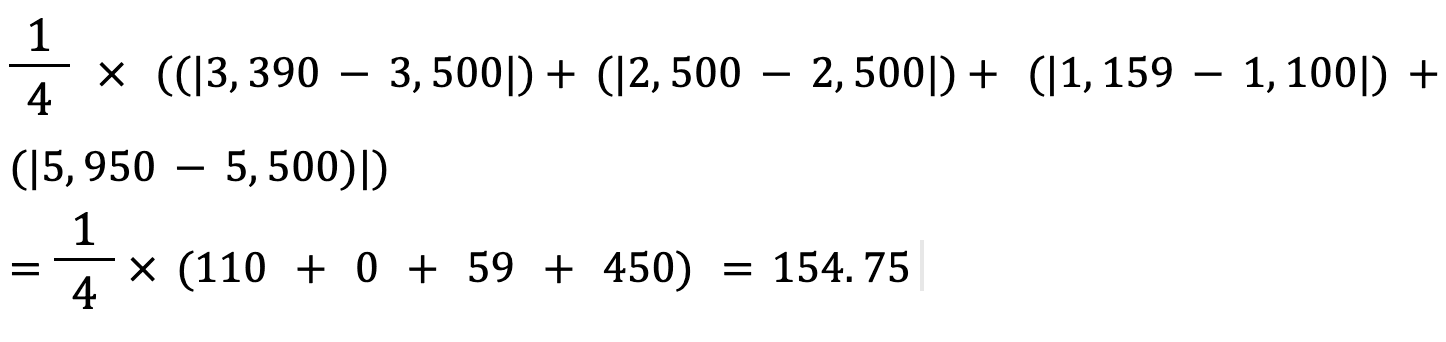
O erro absoluto médio entre o preço real e o previsto do imóvel é de aproximadamente US$ 155.
A fórmula para calcular o erro quadrático médio de um modelo é semelhante à do erro absoluto médio:
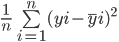
Observe que, enquanto o erro absoluto médio calcula a distância absoluta média entre o valor real e o previsto, o erro quadrático médio encontra a distância quadrada média entre os valores real e previsto.
Vamos calcular o MSE entre os valores reais e previstos acima:
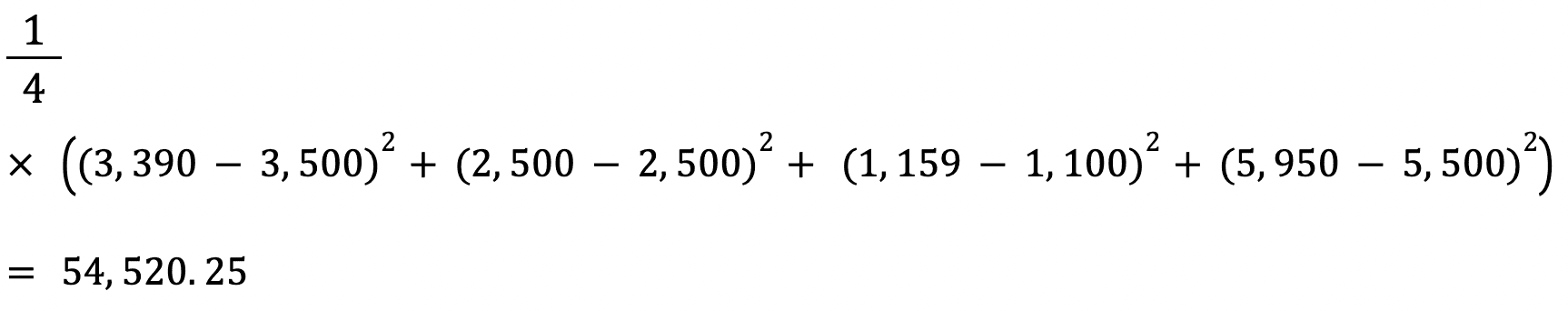
O RMSE de um estimador é calculado encontrando a raiz quadrada de seu erro quadrático médio. Uma vantagem de calcular o RMSE de um conjunto de dados em relação ao seu MSE é que o erro é retornado na mesma unidade da variável que estamos prevendo.
Nesse caso, por exemplo, o RMSE é √54,520.25=233.5. Esse valor é interpretável, pois é em termos de preço do imóvel, enquanto o erro quadrático médio não é.
Agora que você entende o conceito de regressão, vamos examinar os diferentes tipos de modelos de regressão:
A regressão linear é uma abordagem linear para modelar a relação entre uma variável dependente e uma ou mais variáveis independentes. Esse algoritmo envolve encontrar uma linha que melhor se ajuste aos dados em questão.
Aqui está uma representação visual de como funciona um modelo de regressão linear simples:
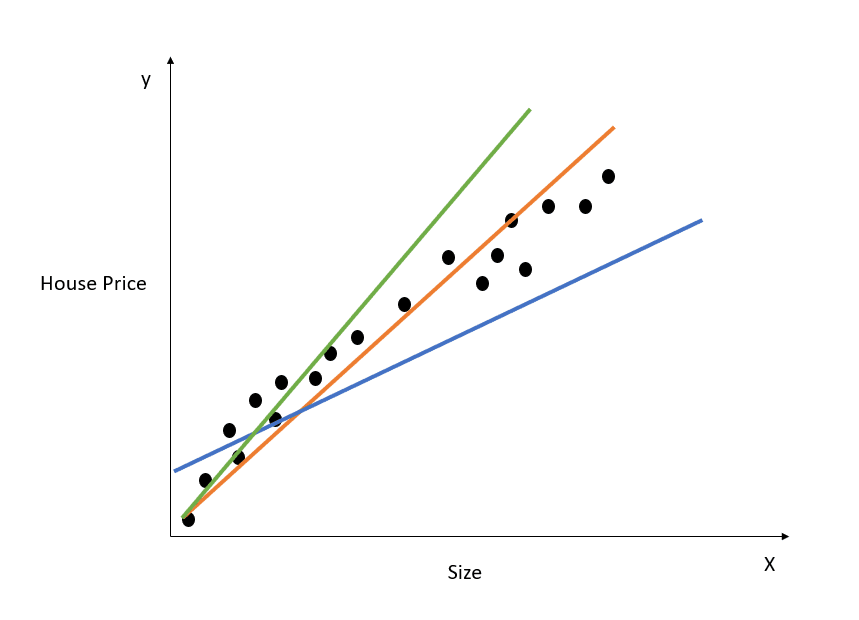
Imagem do autor
O gráfico acima mostra a relação entre o preço e o tamanho da casa. O modelo de regressão linear criará uma linha que melhor modela essa relação. Todas as previsões de preços de imóveis relativos a diferentes valores de tamanho estarão na linha de melhor ajuste.
Observe que há três linhas desenhadas no diagrama acima. Qual dessas linhas é a "linha de melhor ajuste"?
Observando o diagrama acima, podemos ver que a linha laranja é a mais próxima de todos os pontos de dados mostrados. Portanto, podemos dizer intuitivamente que ela representa a "linha de melhor ajuste".
Aqui está uma explicação mais formal sobre como a linha de melhor ajuste é encontrada na regressão linear:
A equação de uma linha reta é y=mx+c. Aqui, m representa a inclinação da linha e c representa sua interceptação y . Há infinitas maneiras de traçar essa linha, pois há infinitos valores possíveis para m e c.
A linha de melhor ajuste, também conhecida como linha de regressão de mínimos quadrados, é encontrada minimizando a soma da distância quadrada entre os valores reais e previstos:
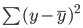
Você pode ler o tutorial Essentials of Linear Regression in Python para obter uma compreensão mais profunda do modelo de aprendizado de máquina de regressão linear e sua implementação.
A regressão Ridge é uma extensão do modelo de regressão linear explicado acima. É uma técnica usada para manter os coeficientes de um modelo de regressão tão baixos quanto possível.
Um problema com um modelo de regressão linear simples é que seus coeficientes podem se tornar grandes, o que torna o modelo mais sensível aos inputs. Isso pode levar a um ajuste excessivo.
Vamos usar um exemplo simples para entender o conceito de sobreajuste:
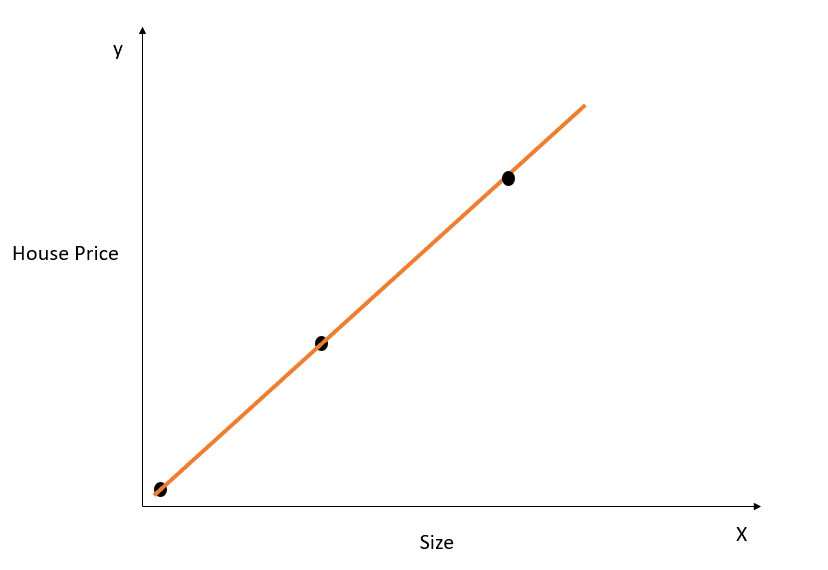
Imagem do autor
Na figura acima, a linha de melhor ajuste modela perfeitamente a relação entre X e y, e a soma da distância quadrada entre os valores reais e previstos é 0. Lembre-se de que a equação dessa linha é y=mx+c.
Embora essa linha tenha um ajuste perfeito no conjunto de dados de treinamento, ela provavelmente não se generalizaria bem para os dados de teste. Esse fenômeno é chamado de sobreajuste, e você pode ler este artigo sobre sobreajuste para saber mais sobre ele.
Em palavras simples, um modelo altamente complexo captará nuances desnecessárias do conjunto de dados de treinamento que não se refletem no mundo real. Esse modelo terá um desempenho extremamente bom nos dados de treinamento, mas terá um desempenho inferior em conjuntos de dados fora dos quais foi treinado.
Um modelo de regressão linear com coeficientes grandes é propenso ao ajuste excessivo.
A regressão Ridge é uma técnica de regularização que forçará o algoritmo a escolher coeficientes menores, penalizando sua função de perda para incluir um custo adicional.
Conforme mostrado na seção anterior, aqui está o erro que queremos minimizar na regressão linear simples:
Na regressão de cumeeira, essa equação será ligeiramente alterada e um termo de penalidade será adicionado ao erro acima:
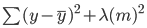
Observe que há um valor (lambda) multiplicado aos coeficientes do modelo. Como esse modelo tem apenas uma variável, há um único coeficiente com um termo de penalidade adicionado a ele. Se houver várias variáveis independentes, o lambda será multiplicado pela soma dos coeficientes ao quadrado.
Esse termo de penalidade pune o modelo por escolher coeficientes maiores. O objetivo aqui é reduzir os valores do coeficiente de modo que as variáveis com uma contribuição menor para o resultado tenham seus coeficientes próximos de 0. Isso reduz a variação do modelo e ajuda a atenuar o ajuste excessivo.
Observe que um valor lambda de 0 não terá efeito algum, e o termo de penalidade é eliminado. Um valor maior de lambda adicionará uma penalidade de redução maior, e os coeficientes do modelo se aproximarão de zero.
Ao escolher um valor lambda, certifique-se de encontrar um equilíbrio entre simplicidade e um bom ajuste dos dados de treinamento. Um valor lambda mais alto resulta em um modelo simples e generalizado, mas a escolha de um valor muito alto acarreta o risco de subadaptação. Por outro lado, a escolha de um valor de lambda muito próximo de zero pode levar a um modelo altamente complexo.
A regressão Lasso é outra extensão da regressão linear que reduz os coeficientes do modelo adicionando um termo de penalidade à sua função de custo.
Aqui está o erro que precisa ser minimizado na regressão de laço:
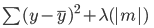
Observe que essa equação é como a de um modelo de regressão de cumeeira, exceto que, em vez de multiplicar lambda pelo quadrado do coeficiente, estamos multiplicando-o pelo valor absoluto do coeficiente.
A maior diferença entre a regressão ridge e a regressão lasso é que, na regressão ridge, embora os coeficientes do modelo possam diminuir em direção a zero, eles nunca se tornam zero. Na regressão com laço, é possível que os coeficientes do modelo se tornem zero.
Se o coeficiente de uma variável independente chegar a zero, o recurso poderá ser eliminado do modelo. Isso reduz o espaço de recursos e torna o algoritmo mais fácil de interpretar, o que é a maior vantagem da regressão lasso.
Devido a isso, a regressão lasso também pode ser usada como uma técnica de seleção de recursos, pois as variáveis com baixa importância podem ter coeficientes que chegam a zero e serão totalmente removidas do modelo.
Você pode criar modelos de regressão linear, ridge e lasso usando a biblioteca Scikit-Learn:
1. Regressão linear
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Para ajustar o modelo em seu conjunto de dados de treinamento, execute:
lr_model.fit(X_train,y_train)2. Regressão Ridge
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)O termo lambda pode ser configurado por meio do parâmetro "alpha" ao definir o modelo.
3. Regressão Lasso
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Se você quiser saber mais sobre modelos lineares e como criá-los em Python, faça nosso curso Introduction to Linear Modeling in Python.
Usamos algoritmos de classificação para prever um resultado discreto (y) usando variáveis independentes (x). A variável dependente, nesse caso, é sempre uma classe ou categoria.
Por exemplo, prever se um paciente tem probabilidade de desenvolver uma doença cardíaca com base em seus fatores de risco é um problema de classificação:
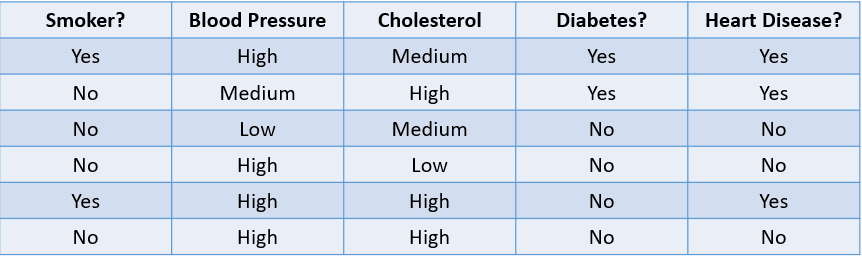
Imagem do autor
A tabela acima mostra um problema de classificação com quatro variáveis independentes e uma variável dependente, doença cardíaca. Como há apenas dois resultados possíveis (Sim e Não), isso é chamado de problema de classificação binária.
Outros exemplos de um problema de classificação binária incluem classificar se um e-mail é spam ou legítimo, prever a rotatividade de clientes e decidir se deve conceder um empréstimo a alguém.
Um problema de classificação multiclasse é aquele com três ou mais resultados possíveis, como a previsão do tempo ou a distinção entre diferentes espécies de animais.
Há muitas maneiras de avaliar um modelo de classificação. Embora a precisão seja a métrica mais usada, ela nem sempre é a mais confiável.
Vamos dar uma olhada em alguns métodos comuns usados para avaliar um algoritmo de classificação com base no conjunto de dados abaixo:
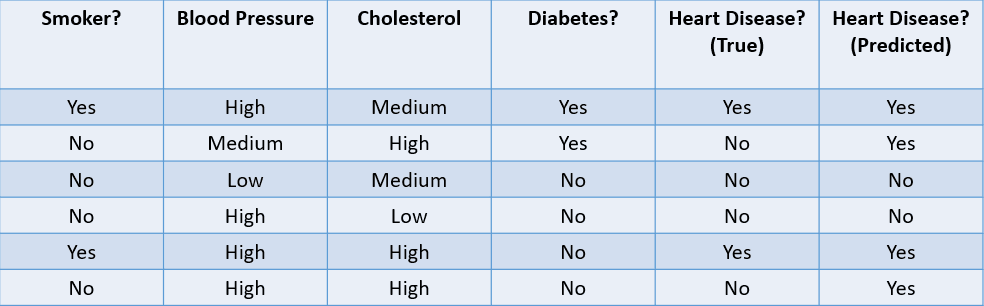
Imagem do autor
1. Precisão: A precisão pode ser definida como a fração de previsões corretas feitas pelo modelo de aprendizado de máquina.
A fórmula para calcular a precisão é a seguinte:

Nesse caso, a precisão é 46, ou 0,67.
2. Precisão: A precisão é uma métrica usada para calcular a qualidade das previsões positivas feitas pelo modelo. Ele é definido como:
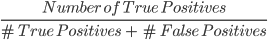
O modelo acima tem uma precisão de 24, ou 0,5.
3. Recall: O recall é usado para calcular a qualidade das previsões negativas feitas pelo modelo. Ele é definido como:
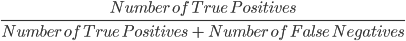
O modelo acima tem um recall de 2/2 ou 1.
Vamos dar uma olhada em um exemplo simples para entender a diferença entre precisão e recuperação:
Existe uma doença rara e fatal que afeta uma fração da população. 95% dos pacientes no banco de dados de um hospital não têm a doença, enquanto apenas 5% têm. Se criarmos um algoritmo de aprendizado de máquina que preveja que ninguém tem a doença, a precisão do treinamento desse modelo será de 95%. Apesar da alta precisão, sabemos que esse não é um bom modelo, pois não consegue identificar os pacientes com a doença.
É nesse ponto que entram métricas como precisão e recall. A precisão, ou especificidade, nos informa a capacidade do modelo de identificar corretamente as pessoas sem a doença. O recall, ou sensibilidade, nos diz quão bem o modelo identifica as pessoas com a doença.
Um valor "bom" de precisão e recuperação é subjetivo e depende de seu caso de uso.
Nesse cenário de previsão de doenças, sempre queremos identificar pessoas com a doença, mesmo que isso implique o risco de um falso positivo. Aqui, criaremos o modelo para ter maior recall do que precisão.
Por outro lado, se tivéssemos que criar um modelo que impedisse a entrada de agentes mal-intencionados em um site de comércio eletrônico, poderíamos querer uma precisão maior, pois o bloqueio de usuários legítimos levaria a um declínio nas vendas.
Geralmente, usamos uma métrica chamada F1-Score para encontrar a média harmônica da precisão e da recuperação de um classificador. Simplificando, o F1-Score combina precisão e recall em uma única métrica, calculando sua média.
A AUC, ou Área sob a Curva, é outra métrica popular usada para medir o desempenho de um modelo de classificação. O AUC de um algoritmo nos informa sobre sua capacidade de distinguir entre classes positivas e negativas.
Para saber mais sobre medidas como a AUC e como elas são calculadas, faça o curso Aprendizado supervisionado em R da Datacamp.
Agora, vamos examinar os diferentes tipos de modelos de classificação e como eles funcionam:
A regressão logística é um modelo de classificação simples que prevê a probabilidade de ocorrência de um evento.
Aqui está um exemplo de como o modelo de regressão logística funciona:
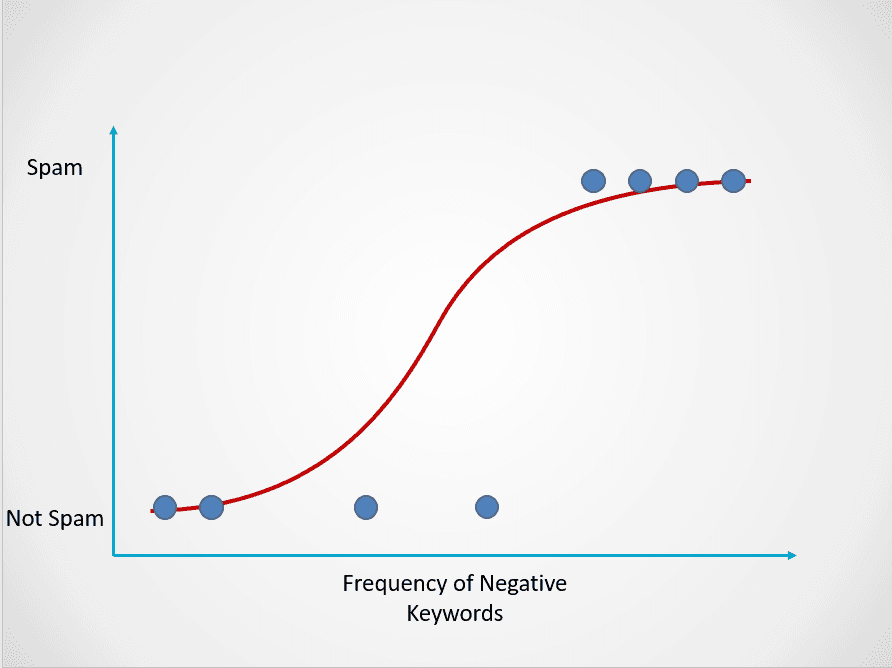
Imagem do autor
O gráfico acima exibe uma função logística que mapeia os dados de e-mail em duas categorias: "Spam" e "Not Spam" com base na frequência de palavras-chave negativas em seu texto.
Observe que, diferentemente do algoritmo de regressão linear, a regressão logística é modelada com uma curva em forma de S. Isso é conhecido como função logística e tem a seguinte fórmula:
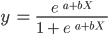
Enquanto a função linear não tem um limite superior e inferior, a função logística varia entre 0 e 1. O modelo prevê uma probabilidade que varia de 0 a 1, o que determina a classe à qual o ponto de dados pertence.
Nesse exemplo de e-mail de spam, se o texto contiver poucas ou nenhuma palavra-chave suspeita, a probabilidade de ser spam será baixa e próxima de 0. Por outro lado, um e-mail com muitas palavras-chave suspeitas terá uma alta probabilidade de ser spam, próxima de 1.
Essa probabilidade é então transformada em um resultado de classificação:
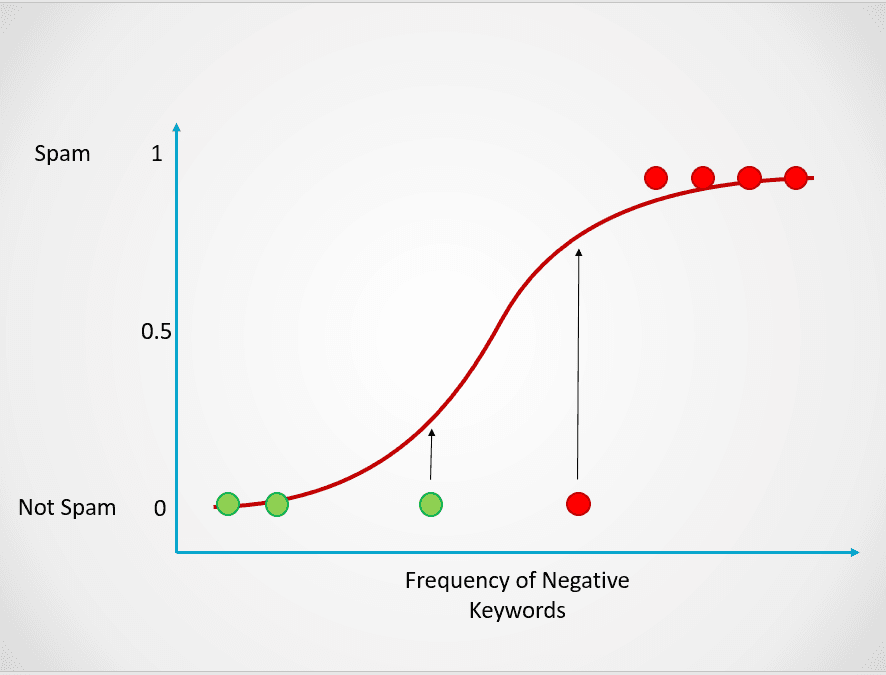
Imagem do autor
Todos os pontos coloridos em vermelho têm uma probabilidade >= 0,5 de serem spam. Portanto, eles são classificados como spam e o modelo de regressão logística retornará um resultado de classificação igual a 1. Os pontos coloridos em verde têm uma probabilidade < 0,5 de serem spam, portanto, são classificados pelo modelo como "Not Spam" e retornarão um resultado de classificação igual a 0.
Para problemas de classificação binária como o acima, o limite padrão de um modelo de regressão logística é 0,5, o que significa que os pontos de dados com probabilidade maior que 0,5 receberão automaticamente um rótulo de 1. Esse valor limite pode ser alterado manualmente, dependendo do seu caso de uso, para obter melhores resultados.
Agora, lembre-se de que, na regressão linear, encontramos a linha de melhor ajuste minimizando a soma do erro quadrático entre os valores previstos e os valores reais. Na regressão logística, entretanto, os coeficientes são estimados usando uma técnica chamada estimativa de máxima verossimilhança em vez de mínimos quadrados.
Leia o tutorial de regressão logística do Python para saber mais sobre o conceito de estimativa de máxima verossimilhança e como funciona a regressão logística.
O KNN é um algoritmo de classificação que classifica um ponto de dados com base no grupo ao qual pertencem os pontos de dados mais próximos a ele.
Aqui está um exemplo simples para demonstrar como o modelo K-Nearest Neighbors funciona:
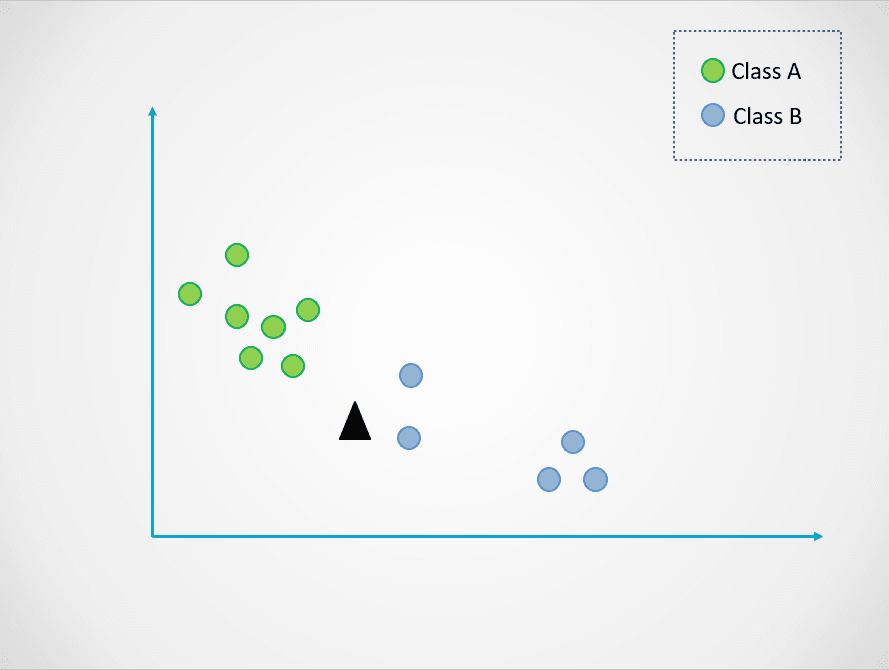
Imagem do autor
No diagrama acima, há duas classes de pontos de dados - A e B. O triângulo preto representa um novo ponto de dados que precisa ser classificado em uma dessas duas classes.
O algoritmo K-Nearest Neighbors funciona da seguinte forma:
Na imagem acima, o valor de k é 1. Isso significa que analisamos apenas um vizinho mais próximo do triângulo preto e atribuímos o ponto de dados a essa classe. O novo ponto de dados está mais próximo do ponto azul, portanto, o atribuímos à classe B.
Agora, vamos alterar o valor de k. Vamos tentar dois valores possíveis de k, 3 e 7:
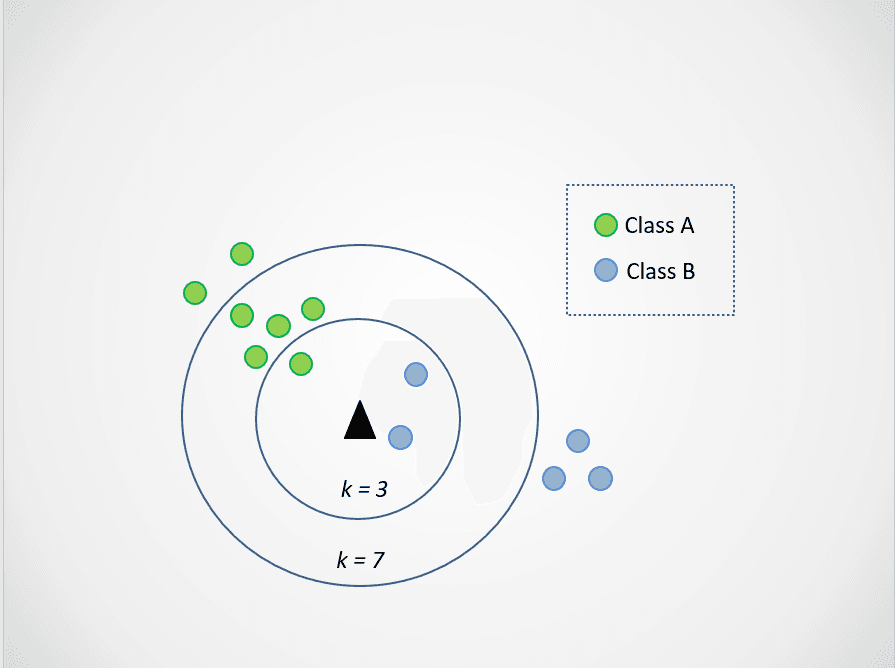
Imagem do autor
Agora, observe que, quando escolhemos k=3, o novo ponto de dados está entre duas categorias. Isso significa que escolhemos a classe majoritária. Dois vizinhos mais próximos são azuis e um vizinho mais próximo é verde, portanto, o ponto de dados será novamente atribuído à classe com pontos azuis, a classe B.
Entretanto, quando k=7, as coisas mudam. Agora, dois vizinhos mais próximos são azuis e sete são verdes. Nesse caso, o ponto de dados será atribuído à classe verde, classe A.
A escolha de valores diferentes de k afetará a classe à qual o novo ponto será atribuído.
A seleção de um valor muito pequeno pode ser ruidosa e sujeita a discrepâncias, enquanto a seleção de um valor grande pode fazer com que você ignore categorias com menos pontos de dados.
Se você quiser saber mais sobre o algoritmo K-Nearest Neighbors e como selecionar um valor "k" ideal, leia este tutorial do KNN.
Aqui estão alguns trechos de código que você pode usar para criar um modelo de classificação em Python usando a biblioteca Scikit-Learn:
1. Regressão logística
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. Vizinhos mais próximos K
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Os modelos baseados em árvore são algoritmos de aprendizado de máquina supervisionados que constroem uma estrutura semelhante a uma árvore para fazer previsões. Eles podem ser usados tanto para problemas de classificação quanto de regressão.
Nesta seção, exploraremos dois dos modelos de aprendizado de máquina baseados em árvores mais comumente usados: árvores de decisão e florestas aleatórias.
Uma árvore de decisão é o algoritmo de aprendizado de máquina baseado em árvore mais simples. Esse modelo nos permite dividir continuamente o conjunto de dados com base em parâmetros específicos até que uma decisão final seja tomada.
Aqui está um exemplo simples que demonstra como o algoritmo de árvore de decisão funciona:
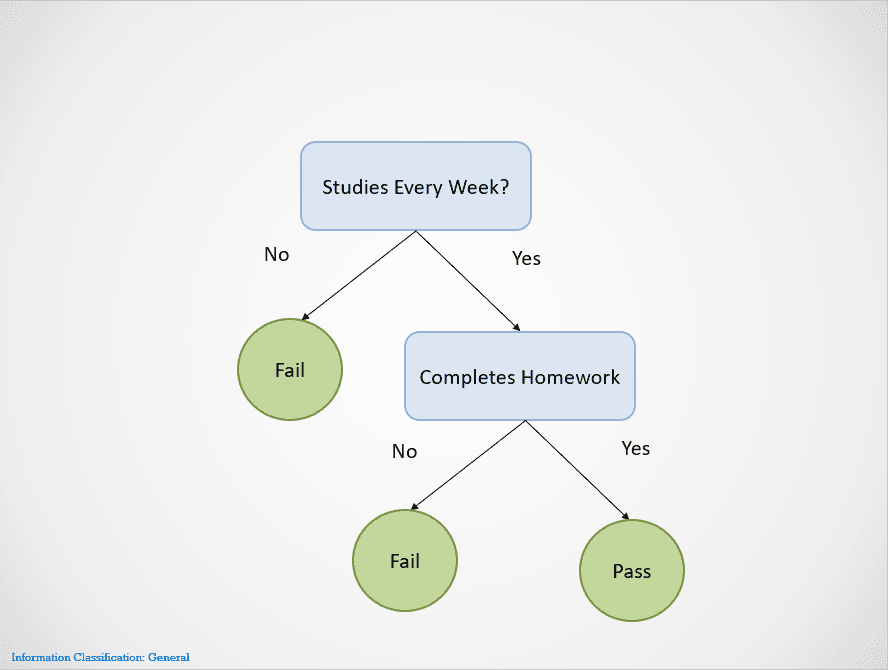
Imagem do autor
As árvores de decisão se dividem em nós diferentes até que um resultado seja obtido.
Nesse caso, se o aluno não estudar toda semana, ele será reprovado. Se eles estudarem toda semana, mas não fizerem a lição de casa, o resultado ainda será "Reprovado". Eles só serão aprovados se estudarem toda semana e fizerem todos os deveres de casa.
Observe que a árvore de decisão acima se divide primeiro na variável "Estuda toda semana?". Em seguida, ele interrompe a divisão se a resposta for "Não", dizendo que o aluno será reprovado.
A árvore de decisão escolherá uma variável para dividir primeiro com base em uma métrica chamada entropia. Ele interromperá a divisão quando for obtida uma "divisão pura", ou seja, quando todos os pontos de dados pertencerem a uma única classe.
Há muitas maneiras de criar uma árvore de decisão. A árvore precisa encontrar um recurso para se dividir em primeiro, segundo, terceiro, etc. Essa estrutura é criada com base em uma métrica chamada ganho de informações. A melhor árvore de decisão possível é aquela com o maior ganho de informações.
Para saber mais sobre como as árvores de decisão funcionam, juntamente com métricas como entropia e ganho de informações, este artigo sobre classificação de árvores de decisão em Python tem mais detalhes.
Uma das maiores vantagens das árvores de decisão é que elas são altamente interpretáveis. É fácil trabalhar de trás para frente e entender como uma árvore de decisão obteve seu resultado final com base no conjunto de dados de treinamento.
No entanto, as árvores de decisão também são altamente propensas ao superajuste se forem deixadas para crescer completamente. Isso ocorre porque eles são projetados para se dividir perfeitamente em todas as amostras do conjunto de dados de treinamento, o que os torna incapazes de generalizar bem para dados externos.
Essa desvantagem das árvores de decisão pode ser resolvida com o uso do algoritmo de floresta aleatória.
O modelo de floresta aleatória é um algoritmo baseado em árvore que nos ajuda a mitigar alguns dos problemas que surgem quando se usam árvores de decisão, um dos quais é o excesso de ajuste. As florestas aleatórias são criadas combinando as previsões feitas por vários modelos de árvore de decisão e retornando um único resultado.
Ele faz isso em duas etapas:
No caso de um problema de regressão, o resultado será a previsão média de todas as árvores de decisão.
Aqui está um visual simples para mostrar como o algoritmo de floresta aleatória funciona:
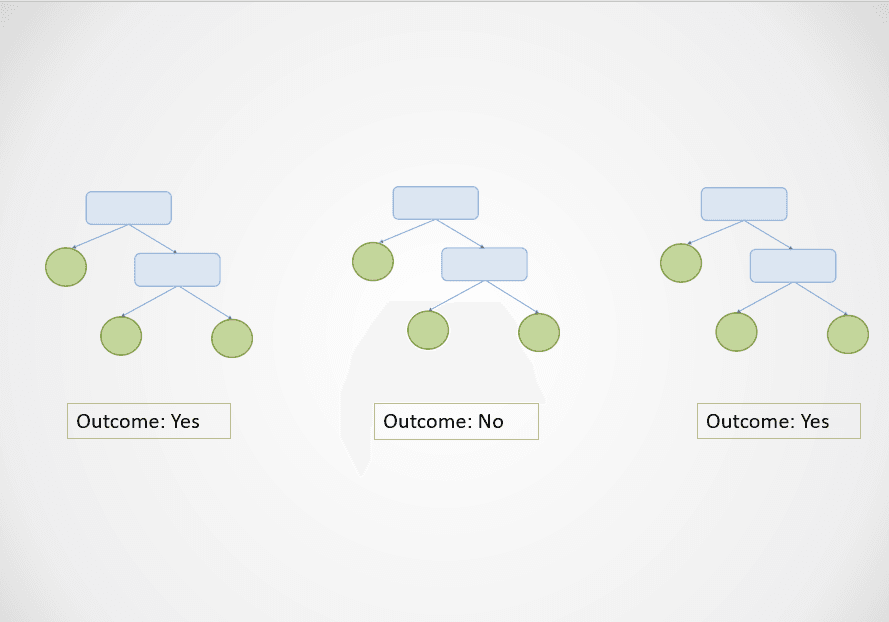
Imagem do autor
No diagrama acima, a primeira e a terceira árvores de decisão preveem "Sim", enquanto a segunda prevê "Não".
Como essa é uma tarefa de classificação, a classe majoritária é selecionada. Nesse caso, o algoritmo de floresta aleatória retornará um resultado final de "Sim" com base nas previsões feitas por 2 das 3 árvores de decisão.
Uma das maiores vantagens do algoritmo de floresta aleatória é que ele generaliza bem, pois combina a saída de várias árvores de decisão que são treinadas em um subconjunto de recursos.
Além disso, embora o resultado de uma única árvore de decisão possa variar drasticamente com base em uma pequena alteração no conjunto de dados de treinamento, esse problema não ocorre com o algoritmo de floresta aleatória, pois o conjunto de dados de treinamento é amostrado muitas vezes.
Execute as seguintes linhas de código para criar um algoritmo de aprendizado de máquina baseado em árvore com o Scikit-Learn:
1. Árvore de decisão
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Florestas aleatórias
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Até agora, exploramos modelos de aprendizado de máquina supervisionados para lidar com problemas de classificação e regressão. Agora, vamos nos aprofundar em uma abordagem popular de aprendizado não supervisionado chamada clustering.
Em palavras simples, o clustering é a tarefa de criar um grupo de objetos que são semelhantes entre si, mas diferentes dos outros. Essa técnica tem uma variedade de casos de uso comercial, como a recomendação de filmes para usuários com padrões de visualização semelhantes em um site de streaming de vídeo, detecção de anomalias e segmentação de clientes.
Nesta seção, examinaremos um algoritmo chamado K-Means clustering - o modelo de aprendizado de máquina mais simples e mais popular usado para tarefas de aprendizado não supervisionado.
O K-Means clustering é uma técnica de aprendizado de máquina não supervisionada usada para agrupar objetos semelhantes nos dados.
Este é um exemplo de como o algoritmo de agrupamento K-Means funciona:

Imagem do autor
Etapa 1: A imagem acima consiste em observações não rotuladas que não foram agrupadas. Inicialmente, cada observação será atribuída a um cluster de forma aleatória. Em seguida, será calculado um centroide para cada cluster.
Eles são representados com o símbolo "+" no diagrama abaixo:
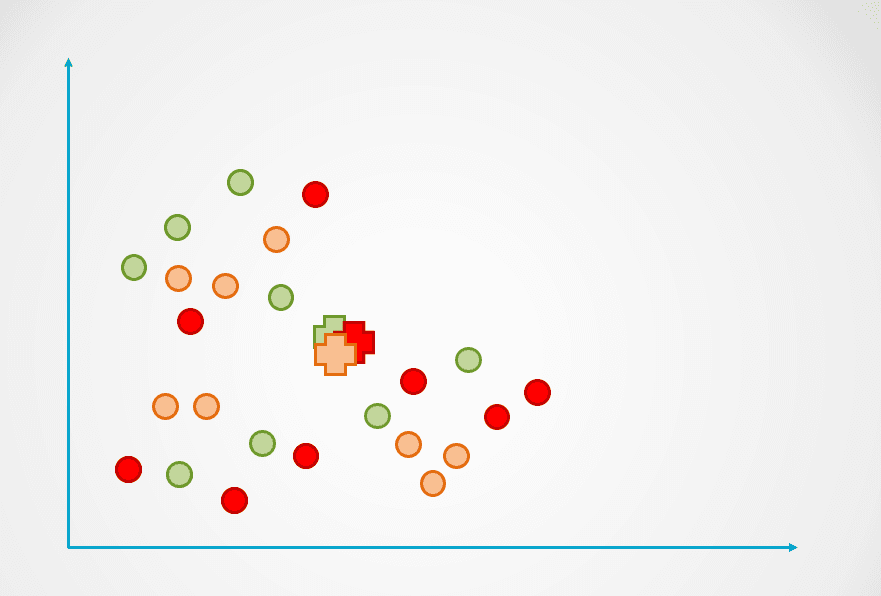
Imagem do autor
Etapa 2: Em seguida, a distância de cada ponto de dados até o centroide é medida, e cada ponto é atribuído ao centroide mais próximo:
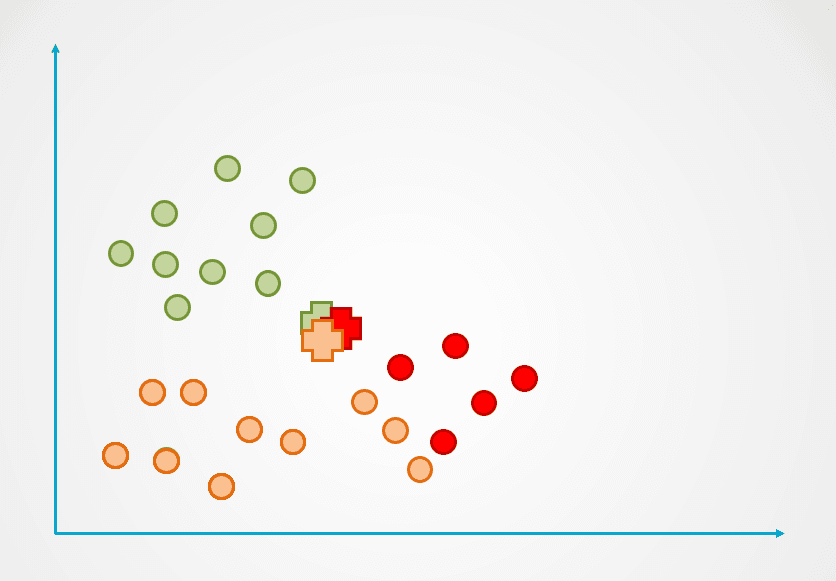
Imagem do autor
Etapa 3: O centroide do novo cluster é então recalculado, e os pontos de dados serão reatribuídos de acordo.
Etapa 4: Esse processo é repetido até que os pontos de dados não estejam mais sendo reatribuídos:
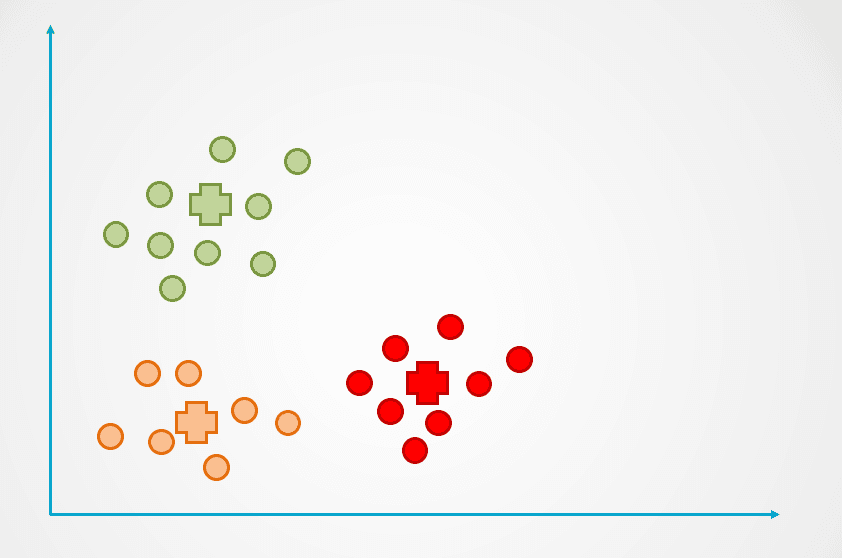
Imagem do autor
Observe que foram criados três clusters no exemplo acima. O número de clusters é chamado de "k" no algoritmo de clustering K-Means, e deve ser determinado por nós.
Há algumas maneiras diferentes de selecionar "k" no K-Means, a mais popular delas é o método do cotovelo. Essa técnica consiste em plotar o erro para um número diferente de clusters em um gráfico e escolher o ponto de inflexão da curva como "k".
Saiba mais em nosso tutorial sobre clustering K-Means em Python para descobrir o método elbow e o funcionamento interno do clustering K-Means.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')O argumento n_clusters indica o número de clusters "k" que você precisa definir ao criar o algoritmo.
Se você conseguiu acompanhar todo este artigo, parabéns! Agora você conhece alguns dos modelos e algoritmos mais populares de aprendizado de máquina supervisionado e não supervisionado e sabe como eles podem ser aplicados para resolver uma variedade de problemas de modelagem preditiva.
Para se tornar um cientista de dados, você precisa entender como funcionam os diferentes tipos de modelos de aprendizado de máquina para aplicá-los na solução de um problema. Por exemplo, se você quiser criar um modelo que seja interpretável e tenha pouco tempo de computação, pode fazer sentido criar uma árvore de decisão. No entanto, se o seu objetivo for criar um modelo que generalize bem, você poderá optar por criar um algoritmo de floresta aleatória.
Também é importante entender como avaliar os modelos de aprendizado de máquina. Um modelo "bom" é subjetivo e depende muito de seu caso de uso. Em problemas de classificação, por exemplo, a alta precisão por si só não é indicativa de um bom modelo. Como cientista de dados, você precisa analisar métricas como precisão, recall e F1-Score para ter uma ideia melhor do desempenho do seu modelo.
Se você quiser obter uma compreensão mais profunda dos modelos de aprendizado de máquina do que os conceitos abordados neste artigo, faça o curso Machine Learning Scientist with Python. Esse curso de carreira ensinará a você a teoria por trás do funcionamento dos modelos de aprendizado de máquina e como eles podem ser implementados em Python. No curso, você também aprenderá técnicas de preparação de dados, como normalização, descorrelação e seleção de recursos.
Cursos de aprendizado de máquina
Curso
Curso
Curso
blog
Matt Crabtree
14 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
11 min
blog
Moez Ali
15 min
blog
Kurtis Pykes
8 min
blog
Abid Ali Awan
15 min