Corso
Machine Learning con modelli ad alberi in Python
5 h
117.2K
Oggi, molte grandi organizzazioni utilizzano forme di modellazione predittiva per massimizzare i ricavi e favorire la crescita.
Il machine learning ha una varietà di casi d’uso in domini diversi. Le piattaforme in abbonamento come Netflix e Spotify, per esempio, usano il machine learning per raccomandare contenuti in base all’attività dell’utente sull’applicazione.
I sistemi di raccomandazione generano valore diretto per queste aziende, perché una migliore esperienza d’uso rende più probabile che i clienti continuino a sottoscrivere l’abbonamento. Questo è un esempio di modello di machine learning non supervisionato.
Allo stesso modo, un operatore di telefonia mobile potrebbe usare il machine learning per analizzare il sentiment degli utenti e adattare l’offerta di prodotto in base alla domanda di mercato. Questo è un esempio di modello di machine learning supervisionato.
Tutti i modelli di machine learning possono essere classificati come supervisionati o non supervisionati. La differenza principale è che un algoritmo supervisionato richiede dati di addestramento etichettati in input e output, mentre un modello non supervisionato può elaborare dataset grezzi, non etichettati.
I modelli supervisionati possono poi essere ulteriormente classificati in algoritmi di regressione e classificazione, che spiegheremo più avanti in questo articolo.
Gli algoritmi di regressione vengono usati per prevedere un risultato continuo (y) usando variabili indipendenti (x).
Per esempio, guarda la tabella qui sotto:
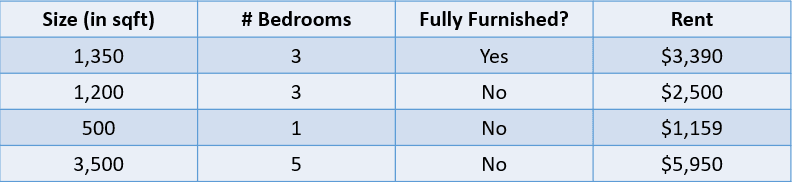
Immagine dell’autore
In questo caso, vogliamo prevedere l’affitto di una casa in base alla metratura, al numero di camere da letto e al fatto che sia completamente arredata. La variabile dipendente, “Affitto”, è numerica: questo rende il problema una regressione.
Un problema con molte variabili in input come quello sopra è chiamato problema di regressione multivariata.
Un errore comune dei principianti in data science è pensare che un modello di regressione possa essere valutato con una metrica come l’accuratezza. L’accuratezza è una metrica usata per valutare le prestazioni dei modelli di classificazione, come spiegheremo più avanti.
I modelli di regressione, invece, si valutano con metriche come MAE (Mean Absolute Error), MSE (Mean Squared Error) e RMSE (Root Mean Squared Error).
Aggiungiamo ora un valore predetto al problema del prezzo della casa sopra e valutiamo queste previsioni con alcune metriche di regressione:

Immagine dell’autore
Il mean absolute error calcola la somma delle differenze tra tutti i valori reali e quelli predetti e la divide per il numero totale di osservazioni. Ecco la formula per calcolare il MAE:
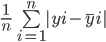
Calcoliamo il Mean Absolute Error dei valori sopra usando questa formula:
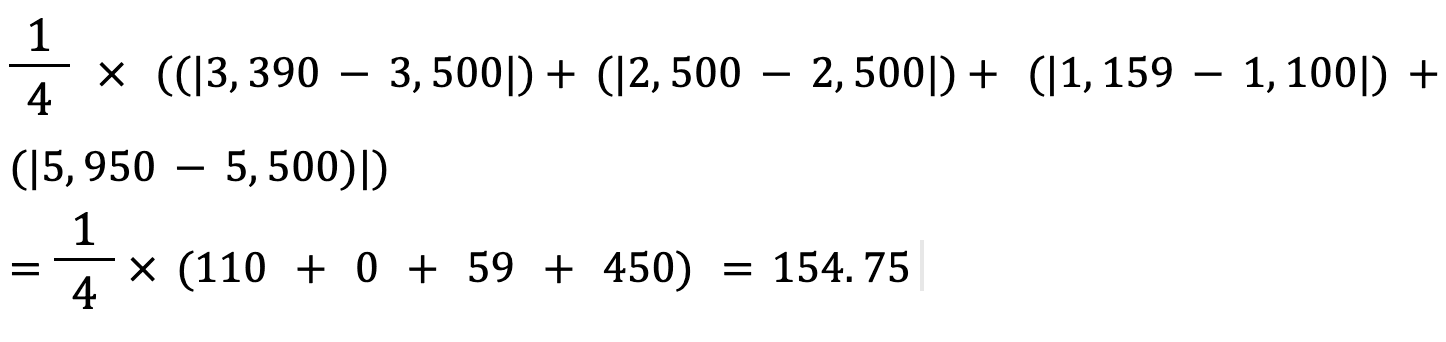
Il mean absolute error tra il prezzo reale e quello predetto della casa è di circa 155 $.
La formula per calcolare il mean squared error di un modello è simile a quella del mean absolute error:
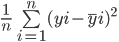
Nota che mentre il mean absolute error calcola la distanza assoluta media tra valore reale e predetto, il mean squared error trova la distanza quadratica media tra valori reali e predetti.
Calcoliamo l’MSE tra i valori reali e predetti sopra:
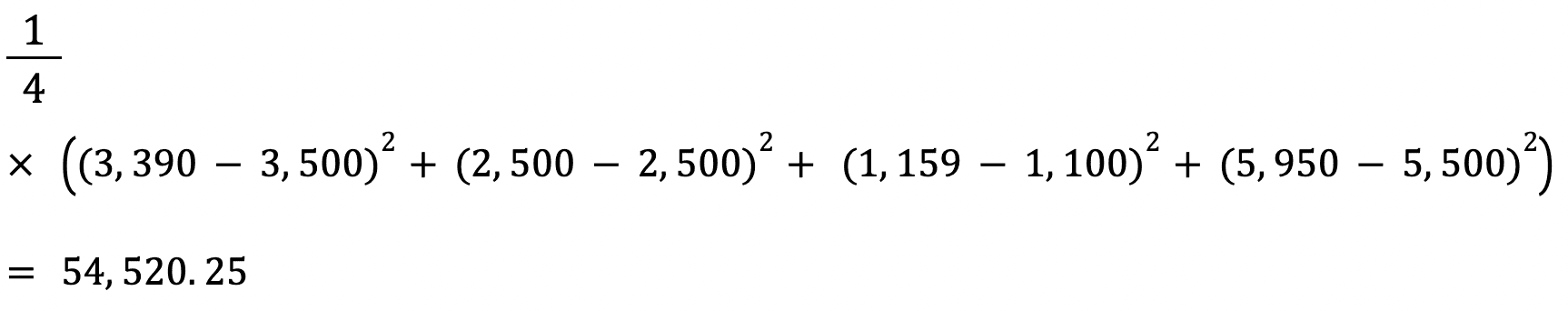
L’RMSE di uno stimatore si calcola estraendo la radice quadrata del suo mean squared error. Un vantaggio dell’RMSE rispetto all’MSE è che l’errore è restituito nella stessa unità della variabile che stiamo prevedendo.
In questo caso, per esempio, l’RMSE è √54.520,25 = 233,5. Questo valore è interpretabile perché è espresso in termini di prezzo della casa, mentre il Mean Squared Error no.
Ora che hai compreso il concetto di regressione, vediamo i diversi tipi di modelli di regressione:
La regressione lineare è un approccio lineare per modellare la relazione tra una variabile dipendente e una o più variabili indipendenti. L’algoritmo consiste nel trovare una retta che si adatti al meglio ai dati disponibili.
Ecco una rappresentazione visiva di come funziona una regressione lineare semplice:
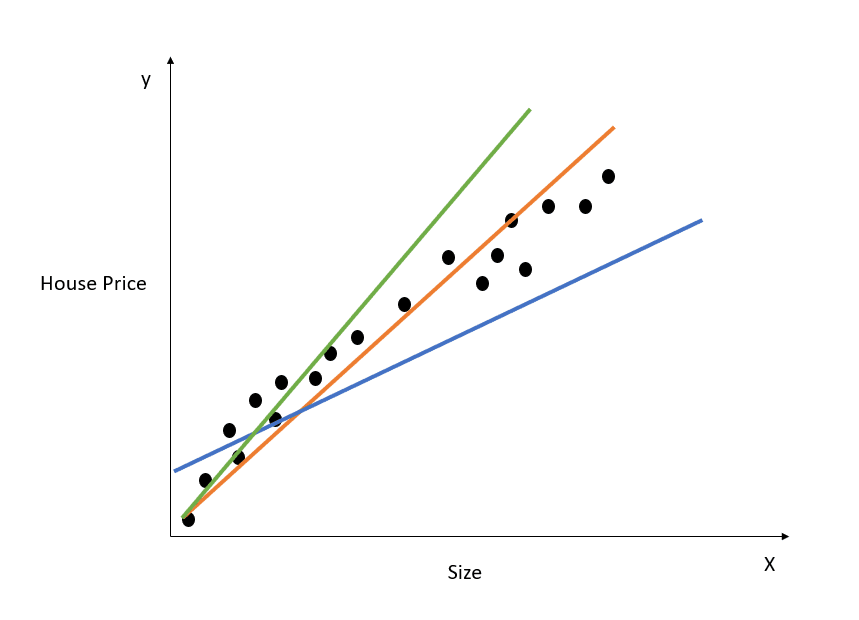
Immagine dell’autore
Il grafico sopra mostra la relazione tra prezzo e metratura della casa. Il modello di regressione lineare creerà una retta che modella al meglio questa relazione. Tutte le previsioni del prezzo in funzione di diversi valori di metratura giaceranno sulla retta di best fit.
Osserva che nel diagramma sono tracciate tre linee. Quale di queste è la “retta di best fit”?
A colpo d’occhio, si vede che la linea arancione è la più vicina a tutti i punti dati mostrati. Quindi possiamo dire intuitivamente che rappresenta la “retta di best fit”.
Ecco una spiegazione più formale di come si trova la retta di best fit nella regressione lineare:
L’equazione di una retta è y = mx + c. Qui, m rappresenta la pendenza della retta e c rappresenta l’intercetta y. Ci sono infiniti modi per tracciare questa retta, perché esistono infiniti possibili valori di m e c.
La retta di best fit, anche detta retta di regressione ai minimi quadrati, si ottiene minimizzando la somma delle distanze quadre tra valori reali e predetti:
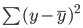
Puoi leggere il tutorial Essentials of Linear Regression in Python per capire più a fondo il modello di regressione lineare e la sua implementazione.
La ridge regression è un’estensione del modello di regressione lineare descritto sopra. È una tecnica usata per mantenere i coefficienti di un modello di regressione il più bassi possibile.
Un problema della regressione lineare semplice è che i suoi coefficienti possono diventare grandi, rendendo il modello più sensibile agli input. Questo può portare a overfitting.
Prendiamo un semplice esempio per capire il concetto di overfitting:
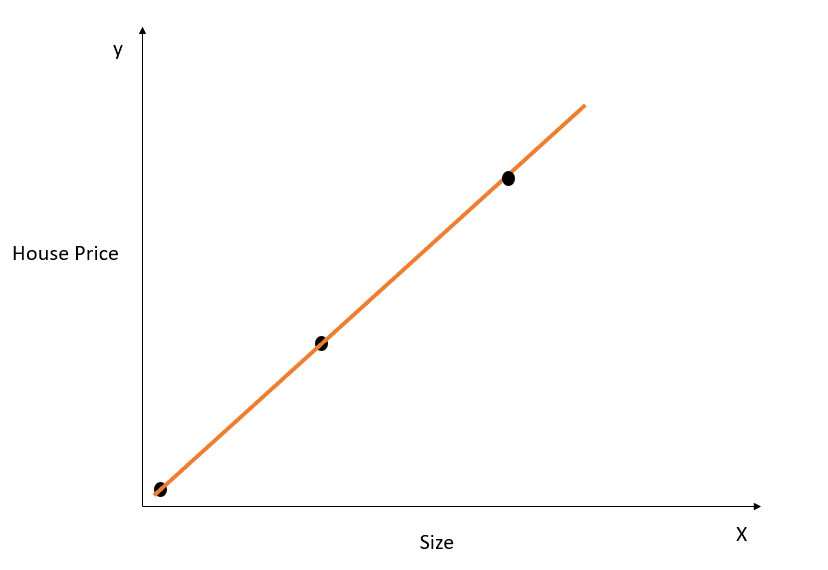
Immagine dell’autore
Nella figura sopra, la retta di best fit modella perfettamente la relazione tra X e y, e la somma delle distanze quadre tra valori reali e predetti è 0. Ricorda che l’equazione di questa retta è y = mx + c.
Anche se questa retta è un fit perfetto sul dataset di training, probabilmente non generalizzerà bene sui dati di test. Questo fenomeno è chiamato overfitting; puoi leggere questo articolo sull’overfitting per saperne di più.
In parole semplici, un modello molto complesso coglierà sfumature inutili del dataset di training che non si riflettono nel mondo reale. Questo modello andrà molto bene sui dati di training ma avrà prestazioni scarse su dataset esterni a quelli su cui è stato addestrato.
Un modello di regressione lineare con coefficienti grandi è incline all’overfitting.
La ridge regression è una tecnica di regolarizzazione che costringe l’algoritmo a scegliere coefficienti più piccoli penalizzando la funzione di perdita con un costo aggiuntivo.
Come mostrato nella sezione precedente, ecco l’errore che vogliamo minimizzare nella regressione lineare semplice:
Nella ridge regression, questa equazione cambia leggermente e si aggiunge un termine di penalità all’errore sopra:
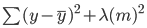
Nota che c’è un valore (lambda) moltiplicato per i coefficienti del modello. Poiché questo modello ha una sola variabile, c’è un singolo coefficiente con un termine di penalità aggiunto. Se ci sono più variabili indipendenti, lambda verrà moltiplicato per la somma dei quadrati dei coefficienti.
Questo termine penalizza il modello per la scelta di coefficienti più grandi. L’obiettivo è ridurre i coefficienti in modo che le variabili con un contributo minimo all’output abbiano coefficienti vicini a 0. Questo riduce la varianza del modello e aiuta a mitigare l’overfitting.
Nota che un valore di lambda pari a 0 non ha alcun effetto e il termine di penalità è eliminato. Un valore di lambda più alto aggiungerà una penalità di shrinkage maggiore e i coefficienti del modello si avvicineranno allo zero.
Quando scegli un valore di lambda, cerca un equilibrio tra semplicità e buon fit sui dati di training. Un lambda elevato produce un modello semplice e generalizzato, ma scegliere un valore troppo alto comporta il rischio di underfitting. D’altra parte, un lambda molto vicino a zero può portare a un modello molto complesso.
La lasso regression è un’altra estensione della regressione lineare che riduce i coefficienti del modello aggiungendo un termine di penalità alla sua funzione di costo.
Ecco l’errore da minimizzare nella lasso regression:
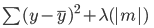
Nota che questa equazione è simile a quella della ridge regression, tranne per il fatto che, invece di moltiplicare lambda per il quadrato del coefficiente, lo moltiplichiamo per il valore assoluto del coefficiente.
La differenza più grande tra ridge e lasso è che nella ridge regression, sebbene i coefficienti possano avvicinarsi a zero, non diventano mai effettivamente zero. Nella lasso regression è possibile che i coefficienti diventino zero.
Se il coefficiente di una variabile indipendente arriva a zero, la feature può essere eliminata dal modello. Questo riduce lo spazio delle feature e rende l’algoritmo più interpretabile, che è il vantaggio principale della lasso regression.
Per questo motivo, la lasso può essere usata anche come tecnica di selezione delle feature, dato che le variabili di bassa importanza possono avere coefficienti che arrivano a zero e verranno rimosse completamente dal modello.
Puoi costruire modelli di regressione lineare, ridge e lasso usando la libreria Scikit-Learn:
1. Regressione lineare
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Per effettuare il fit del modello sul dataset di training, esegui:
lr_model.fit(X_train,y_train)2. Ridge Regression
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)Il termine lambda può essere configurato tramite il parametro “alpha” quando definisci il modello.
3. Lasso Regression
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Se vuoi saperne di più sui modelli lineari e su come costruirli in Python, segui il corso Introduction to Linear Modeling in Python.
Usiamo gli algoritmi di classificazione per prevedere un risultato discreto (y) usando variabili indipendenti (x). La variabile dipendente, in questo caso, è sempre una classe o categoria.
Per esempio, prevedere se un paziente è probabile che sviluppi una cardiopatia in base ai suoi fattori di rischio è un problema di classificazione:
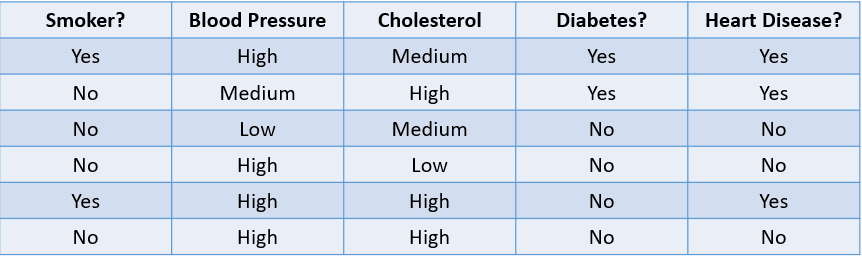
Immagine dell’autore
La tabella sopra mostra un problema di classificazione con quattro variabili indipendenti e una variabile dipendente, la cardiopatia. Poiché ci sono solo due possibili esiti (Sì e No), si parla di classificazione binaria.
Altri esempi di classificazione binaria includono classificare se un’email è spam o legittima, la previsione del churn dei clienti e la decisione se concedere o meno un prestito.
Un problema di classificazione multiclasse ha tre o più possibili esiti, come le previsioni meteo o la distinzione tra diverse specie animali.
Ci sono molti modi per valutare un modello di classificazione. Sebbene l’accuratezza sia la metrica più usata, non è sempre la più affidabile.
Vediamo alcuni metodi comuni per valutare un algoritmo di classificazione sulla base del dataset seguente:
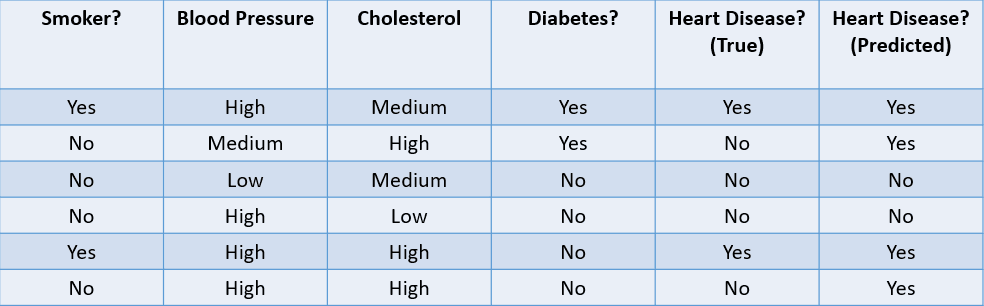
Immagine dell’autore
1. Accuratezza: l’accuratezza è la frazione di previsioni corrette fatte dal modello di machine learning.
La formula per calcolare l’accuratezza è:

In questo caso, l’accuratezza è 4/6, ovvero 0,67.
2. Precision: la precision misura la qualità delle previsioni positive fatte dal modello. È definita come:
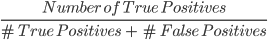
Il modello sopra ha una precision di 2/4, cioè 0,5.
3. Recall: il recall è usato per calcolare la qualità delle previsioni negative fatte dal modello. È definito come:
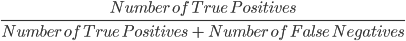
Il modello sopra ha un recall di 2/2, cioè 1.
Vediamo un semplice esempio per capire la differenza tra precision e recall:
C’è una malattia rara e fatale che colpisce una frazione della popolazione. Il 95% dei pazienti nel database di un ospedale non ha la malattia, mentre solo il 5% sì. Se costruiamo un algoritmo di machine learning che predice che nessuno ha la malattia, l’accuratezza di training di questo modello sarà del 95%. Nonostante l’alta accuratezza, sappiamo che non è un buon modello perché non riesce a identificare i pazienti con la malattia.
Qui entrano in gioco metriche come precision e recall. La precision, o specificità, indica la capacità del modello di identificare correttamente le persone senza la malattia. Il recall, o sensibilità, indica quanto bene il modello identifica le persone con la malattia.
Un “buon” valore di precision e recall è soggettivo e dipende dal caso d’uso.
In questo scenario di previsione della malattia, vogliamo sempre identificare le persone malate, anche a rischio di un falso positivo. Qui costruiremo il modello per avere un recall più alto della precision.
D’altra parte, se dovessimo costruire un modello che impedisce ad attori malevoli di entrare in un sito e-commerce, potremmo volere una precision più alta, perché bloccare utenti legittimi porterebbe a un calo delle vendite.
Spesso usiamo una metrica chiamata F1-Score per trovare la media armonica di precision e recall di un classificatore. In poche parole, l’F1-Score combina precision e recall in un’unica metrica calcolandone la media.
L’AUC, o Area Under the Curve, è un’altra metrica popolare usata per misurare le prestazioni di un modello di classificazione. L’AUC di un algoritmo ci dice la sua capacità di distinguere tra classi positive e negative.
Per saperne di più su misure come l’AUC e su come si calcolano, segui il corso Supervised Learning in R di Datacamp.
Ora vediamo i diversi tipi di modelli di classificazione e come funzionano:
La regressione logistica è un semplice modello di classificazione che predice la probabilità che un evento avvenga.
Ecco un esempio di come funziona il modello di regressione logistica:
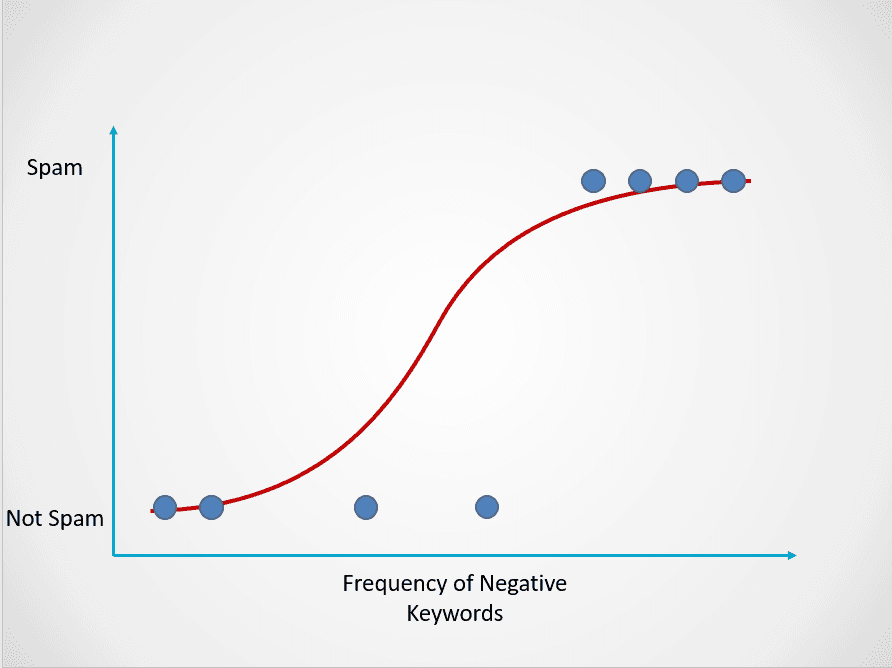
Immagine dell’autore
Il grafico sopra mostra una funzione logistica che mappa i dati delle email in due categorie: “Spam” e “Non Spam” in base alla frequenza di parole chiave negative nel testo.
Osserva che, a differenza dell’algoritmo di regressione lineare, la regressione logistica è modellata con una curva a S. Questa è la funzione logistica e ha la formula seguente:
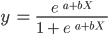
Mentre la funzione lineare non ha limiti superiore e inferiore, la funzione logistica varia tra 0 e 1. Il modello predice una probabilità compresa tra 0 e 1, che determina la classe cui appartiene il punto dati.
Nel nostro esempio di spam, se il testo contiene poche o nessuna parola sospetta, la probabilità che sia spam sarà bassa e vicina a 0. Al contrario, un’email con molte parole sospette avrà un’alta probabilità di essere spam, vicina a 1.
Questa probabilità viene poi trasformata in un esito di classificazione:
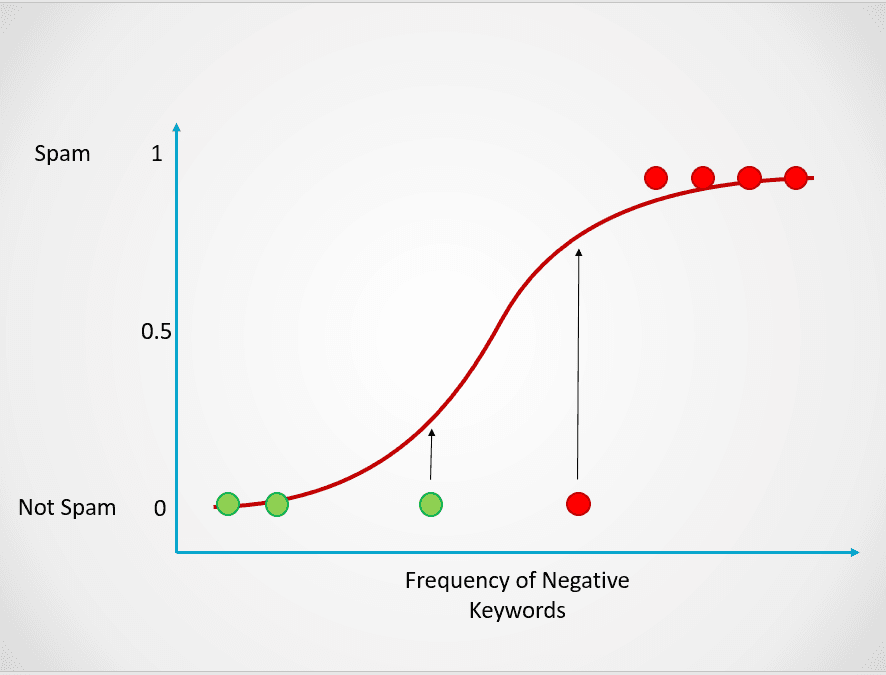
Immagine dell’autore
Tutti i punti in rosso hanno una probabilità >= 0,5 di essere spam. Quindi, vengono classificati come spam e il modello di regressione logistica restituisce un esito di classificazione pari a 1. I punti in verde hanno una probabilità < 0,5 di essere spam, quindi sono classificati come “Non Spam” e restituiscono un esito pari a 0.
Per problemi di classificazione binaria come questo, la soglia predefinita di un modello di regressione logistica è 0,5, il che significa che i punti dati con probabilità superiore a 0,5 saranno automaticamente etichettati come 1. Questa soglia può essere modificata manualmente in base al caso d’uso per ottenere risultati migliori.
Ricorda ora che nella regressione lineare trovavamo la retta di best fit minimizzando la somma degli errori quadri tra predetto e reale. Nella regressione logistica, invece, i coefficienti sono stimati con una tecnica chiamata massima verosimiglianza (maximum likelihood estimation) invece dei minimi quadrati.
Leggi il tutorial Python logistic regression per saperne di più sul concetto di massima verosimiglianza e sul funzionamento della regressione logistica.
KNN è un algoritmo di classificazione che classifica un punto dati in base al gruppo cui appartengono i punti a lui più vicini.
Ecco un semplice esempio per mostrare come funziona il modello K-Nearest Neighbors:
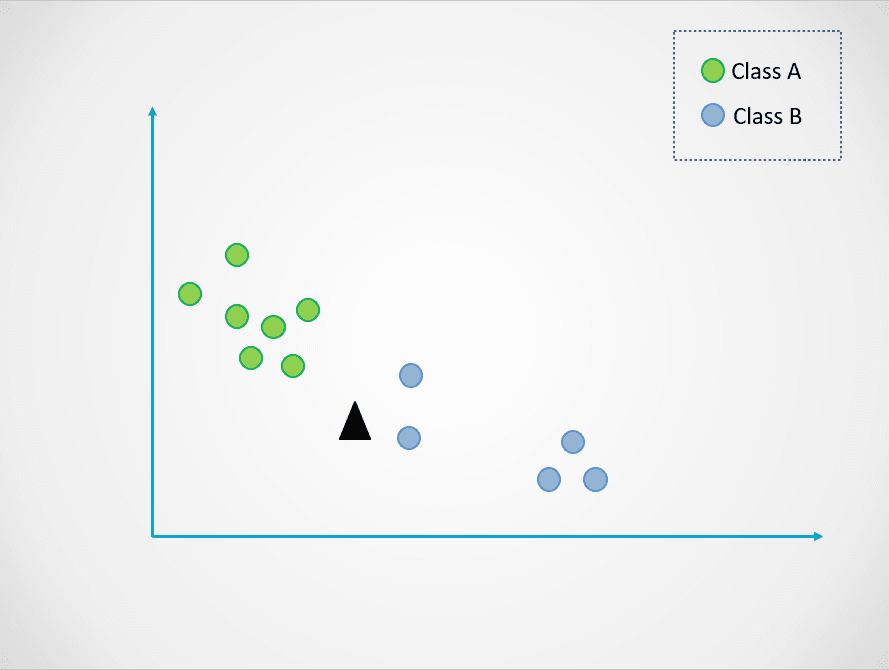
Immagine dell’autore
Nel diagramma sopra, ci sono due classi di punti dati - A e B. Il triangolo nero rappresenta un nuovo punto dati da classificare in una di queste due classi.
L’algoritmo K-Nearest Neighbors funziona così:
Nella figura sopra, il valore di k è 1. Significa che guardiamo un solo vicino più prossimo al triangolo nero e assegniamo il punto a quella classe. Il nuovo punto è più vicino al punto blu, quindi lo assegniamo alla classe B.
Ora modifichiamo il valore di k. Proviamo due valori possibili, 3 e 7:
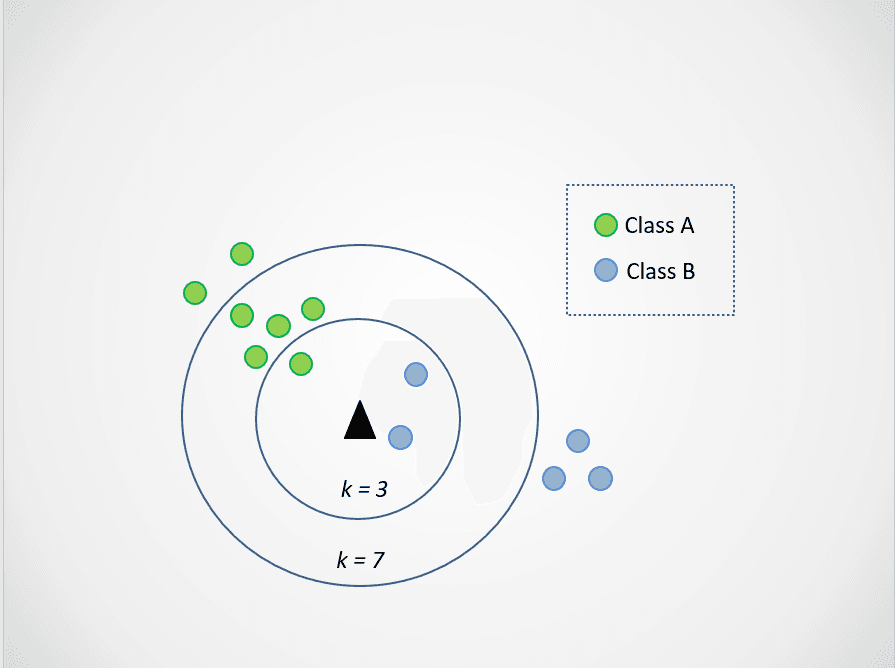
Immagine dell’autore
Nota ora che quando scegliamo k=3, il nuovo punto è tra due categorie. Scegliamo quindi la classe di maggioranza. Due vicini più prossimi sono blu e uno è verde, quindi il punto sarà nuovamente assegnato alla classe dei punti blu, classe B.
Quando k=7, però, le cose cambiano. Ora due vicini sono blu e sette sono verdi. In questo caso, il punto sarà assegnato alla classe verde, classe A.
Scegliere valori diversi di k influenzerà la classe assegnata al nuovo punto.
Selezionare un valore troppo piccolo può essere rumoroso e sensibile agli outlier, mentre un valore troppo grande potrebbe farti trascurare categorie con meno punti dati.
Se vuoi saperne di più sull’algoritmo K-Nearest Neighbors e su come selezionare un valore di “k” ottimale, leggi questo tutorial su KNN.
Ecco alcuni snippet di codice per costruire un modello di classificazione in Python usando Scikit-Learn:
1. Regressione logistica
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-Nearest Neighbors
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()I modelli basati su alberi sono algoritmi di machine learning supervisionato che costruiscono una struttura ad albero per fare previsioni. Possono essere usati sia per problemi di classificazione che di regressione.
In questa sezione, esploreremo due dei modelli basati su alberi più usati: decision tree e random forest.
Un decision tree è l’algoritmo più semplice tra i modelli ad albero. Questo modello consente di dividere ripetutamente il dataset in base a parametri specifici fino a prendere una decisione finale.
Ecco un semplice esempio che mostra come funziona l’algoritmo dei decision tree:
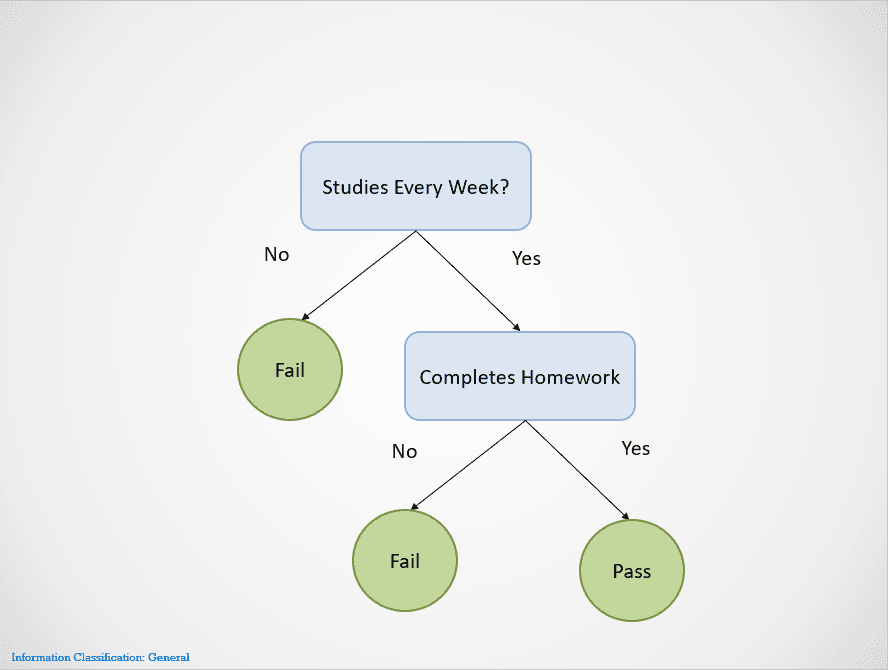
Immagine dell’autore
I decision tree effettuano split su diversi nodi fino a ottenere un esito.
In questo caso, se uno studente non studia ogni settimana, fallirà. Se studia ogni settimana ma non fa i compiti, l’esito è ancora “Fail”. Passerà solo se studia ogni settimana e completa tutti i compiti.
Nota che il decision tree sopra effettua il primo split sulla variabile “Studies Every Week?”. Poi smette di dividere se la risposta è “No”, indicando che lo studente fallirà.
Il decision tree sceglierà su quale variabile effettuare lo split per prima in base a una metrica chiamata entropia. Smetterà di dividere quando si ottiene uno “split puro”, cioè quando tutti i punti dati appartengono a una singola classe.
Ci sono molti modi per costruire un decision tree. L’albero deve trovare una feature su cui dividere per prima, poi la seconda, la terza, ecc. Questa struttura è creata in base a una metrica chiamata information gain. Il miglior decision tree possibile è quello con il maggiore information gain.
Per approfondire il funzionamento dei decision tree, insieme a metriche come entropia e information gain, questo articolo sulla classificazione con decision tree in Python offre più dettagli.
Uno dei maggiori vantaggi dei decision tree è l’elevata interpretabilità. È facile risalire a ritroso e capire come un albero abbia ottenuto l’esito finale in base al dataset di training.
Tuttavia, i decision tree sono anche molto inclini all’overfitting se lasciati crescere senza controllo. Questo perché sono progettati per dividere perfettamente su tutti i campioni del dataset di training, il che li rende incapaci di generalizzare bene su dati esterni.
Questo limite dei decision tree può essere risolto usando l’algoritmo random forest.
Il modello random forest è un algoritmo basato su alberi che aiuta a mitigare alcuni problemi che sorgono con i decision tree, tra cui l’overfitting. Le random forest sono create combinando le previsioni di più modelli di decision tree e restituendo un unico output.
Funziona in due passaggi:
In caso di un problema di regressione, l’esito sarà la media delle previsioni di tutti gli alberi.
Ecco una semplice visualizzazione di come funziona l’algoritmo random forest:
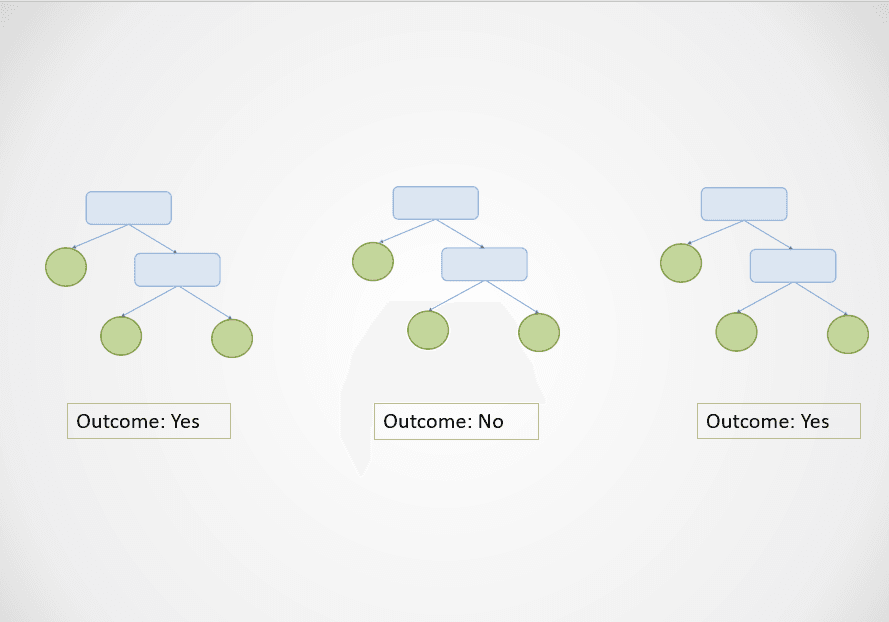
Immagine dell’autore
Nel diagramma sopra, il primo e il terzo decision tree predicono “Sì” mentre il secondo predice “No”.
Poiché si tratta di un compito di classificazione, si seleziona la classe di maggioranza. In questo caso, l’algoritmo random forest restituirà un esito finale di “Sì” sulla base delle previsioni di 2 alberi su 3.
Uno dei maggiori vantaggi dell’algoritmo random forest è che generalizza bene, poiché combina l’output di più alberi addestrati su un sottoinsieme di feature.
Inoltre, mentre l’output di un singolo decision tree può variare drasticamente in base a una piccola modifica del dataset di training, questo problema non si presenta con la random forest perché il dataset di training viene campionato molte volte.
Esegui le seguenti righe di codice per costruire un algoritmo di machine learning basato su alberi con Scikit-Learn:
1. Decision tree
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Random forest
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Finora abbiamo esplorato modelli di machine learning supervisionato per affrontare problemi di classificazione e regressione. Ora vedremo un popolare approccio di apprendimento non supervisionato chiamato clustering.
In parole semplici, il clustering consiste nel creare gruppi di oggetti simili tra loro ma diversi dagli altri. Questa tecnica ha vari casi d’uso di business, come raccomandare film a utenti con schemi di visione simili su una piattaforma di streaming, il rilevamento di anomalie e la segmentazione della clientela.
In questa sezione esamineremo un algoritmo chiamato K-Means clustering: il modello di machine learning più semplice e popolare per compiti di apprendimento non supervisionato.
Il K-Means clustering è una tecnica di machine learning non supervisionato usata per raggruppare tra loro oggetti simili nei dati.
Ecco un esempio di come funziona l’algoritmo K-Means:

Immagine dell’autore
Passo 1: l’immagine sopra consiste in osservazioni non etichettate che non sono state raggruppate. Inizialmente, ogni osservazione sarà assegnata a un cluster in modo casuale. Verrà poi calcolato un centroide per ogni cluster.
Questi sono rappresentati dal simbolo “+” nel diagramma seguente:
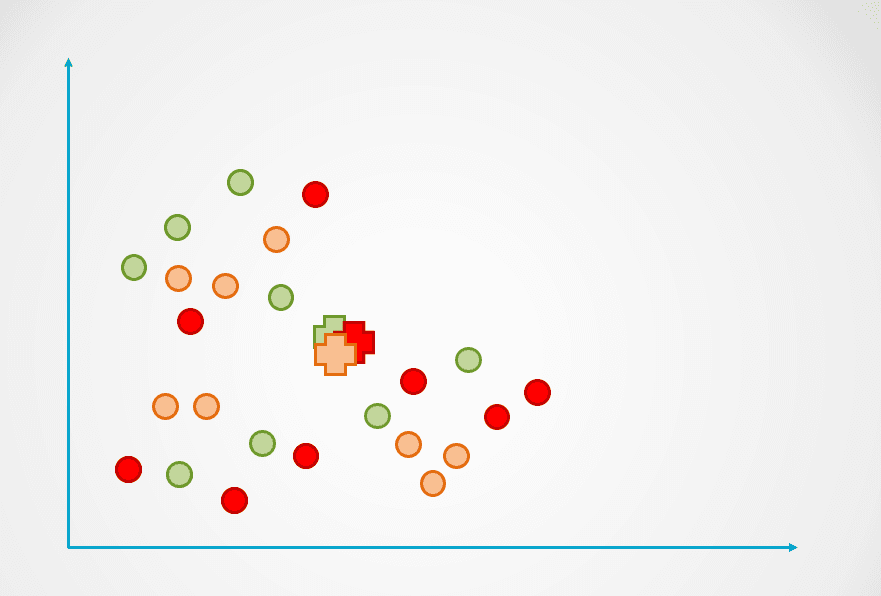
Immagine dell’autore
Passo 2: successivamente, si misura la distanza di ogni punto dati dal centroide e ogni punto viene assegnato al centroide più vicino:
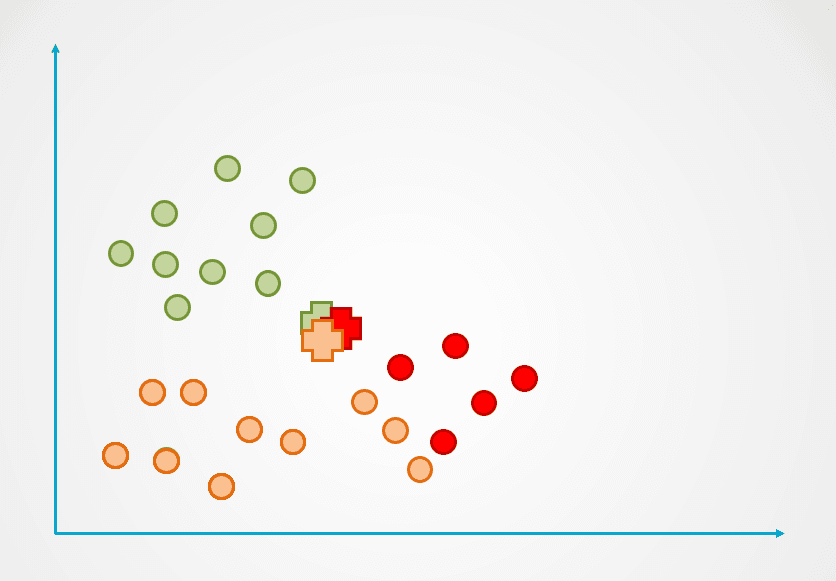
Immagine dell’autore
Passo 3: quindi si ricalcola il centroide del nuovo cluster e i punti verranno riassegnati di conseguenza.
Passo 4: questo processo si ripete finché i punti dati non vengono più riassegnati:
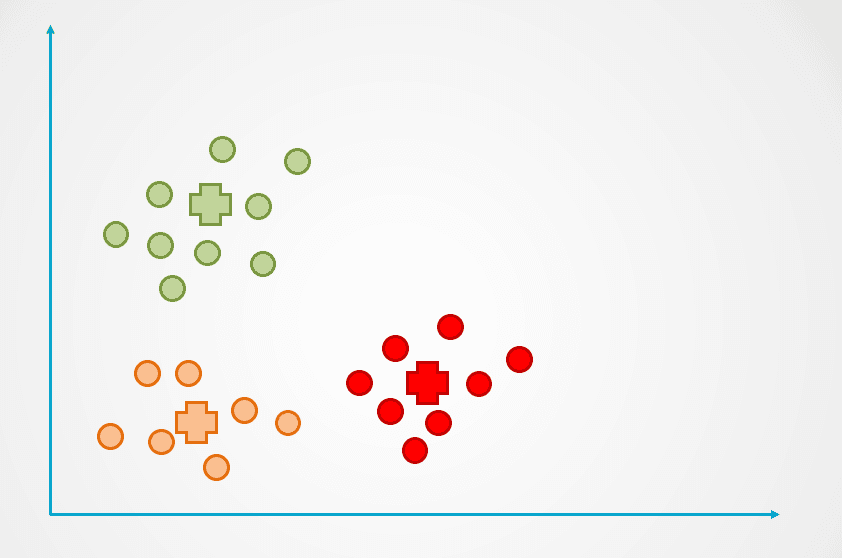
Immagine dell’autore
Osserva che nell’esempio sopra sono stati creati tre cluster. Il numero di cluster è indicato con “k” nell’algoritmo K-Means, e deve essere determinato da noi.
Ci sono diversi modi per selezionare “k” in K-Means, il più popolare è il metodo del gomito (elbow method). Questa tecnica consiste nel tracciare su un grafico l’errore per un diverso numero di cluster e scegliere come “k” il punto di inflessione della curva.
Scopri di più nel nostro tutorial sul K-Means clustering in Python, per conoscere l’elbow method e il funzionamento interno del K-Means clustering.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')L’argomento n_clusters indica il numero di cluster “k” che devi definire quando costruisci l’algoritmo.
Se sei riuscito a seguire tutto l’articolo, congratulazioni! Ora conosci alcuni dei modelli e algoritmi di machine learning supervisionato e non supervisionato più popolari e come applicarli per risolvere vari problemi di modellazione predittiva.
Per diventare data scientist, devi capire come funzionano i diversi tipi di modelli di machine learning per applicarli alla soluzione di un problema. Per esempio, se vuoi costruire un modello interpretabile e con basso tempo di calcolo, potrebbe avere senso creare un decision tree. Se invece il tuo obiettivo è creare un modello che generalizzi bene, puoi scegliere di costruire una random forest.
È anche importante sapere come valutare i modelli di machine learning. Un modello “buono” è soggettivo e dipende molto dal caso d’uso. Nei problemi di classificazione, per esempio, un’alta accuratezza da sola non indica un buon modello. Come data scientist, devi analizzare metriche come precision, recall e F1-Score per avere un’idea migliore delle prestazioni del modello.
Se vuoi approfondire i modelli di machine learning oltre i concetti trattati in questo articolo, segui il corso Machine Learning Scientist with Python. Questo career track ti insegnerà la teoria del funzionamento dei modelli di machine learning e come implementarli in Python. Imparerai anche tecniche di preparazione dei dati come normalizzazione, decorrelazione e selezione delle feature.
Corsi di Machine Learning
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

