Cursus
Machine Learning met boomgebaseerde modellen in Python
5 Hr
117.2K
Tegenwoordig gebruiken veel grote organisaties een vorm van voorspellende modellering om de omzet te maximaliseren en de groei te stimuleren.
Machine learning kent uiteenlopende use-cases in verschillende domeinen. Abonnementsplatforms zoals Netflix en Spotify gebruiken bijvoorbeeld machine learning om content aan te bevelen op basis van gebruikersactiviteit in de app.
Aanbevelingssystemen leveren deze bedrijven directe bedrijfswaarde op, omdat een betere gebruikerservaring de kans vergroot dat klanten geabonneerd blijven. Dit is een voorbeeld van een ongecontroleerd (unsupervised) machine learning-model.
Op vergelijkbare wijze kan een mobiele serviceprovider machine learning gebruiken om gebruikerssentiment te analyseren en zijn aanbod af te stemmen op de marktvraag. Dit is een voorbeeld van een gecontroleerd (supervised) machine learning-model.
Alle machine learning-modellen zijn te classificeren als supervised of unsupervised. Het grootste verschil is dat een supervised algoritme gelabelde input- en output-trainingsdata vereist, terwijl een unsupervised model ruwe, ongelabelde datasets kan verwerken.
Supervised machine learning-modellen zijn vervolgens verder te verdelen in regressie- en classificatie-algoritmen, die later in dit artikel in meer detail worden uitgelegd.
Regressie-algoritmen worden gebruikt om een continue uitkomst (y) te voorspellen met behulp van onafhankelijke variabelen (x).
Kijk bijvoorbeeld naar de onderstaande tabel:
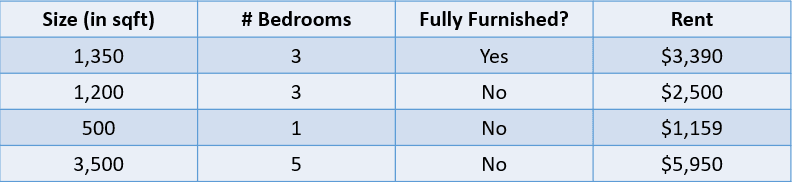
Afbeelding door auteur
In dit geval willen we de huurprijs van een huis voorspellen op basis van de grootte, het aantal slaapkamers en of het volledig gemeubileerd is. De afhankelijke variabele, “Rent”, is numeriek, wat dit tot een regressieprobleem maakt.
Een probleem met veel inputvariabelen zoals hierboven heet een multivariate regressie.
Een veelvoorkomend misverstand bij beginnende data scientists is dat je een regressiemodel kunt evalueren met een metriek als accuratesse (accuracy). Accuratesse is een metriek om de prestaties van classificatiemodellen te beoordelen, zoals later in dit artikel wordt uitgelegd.
Regressiemodellen worden daarentegen geëvalueerd met metrieken zoals MAE (Mean Absolute Error), MSE (Mean Squared Error) en RMSE (Root Mean Squared Error).
Voegen we een voorspelde waarde toe aan het bovenstaande huisprijsprobleem en evalueren we deze voorspellingen met een paar regressiemetrieken:

Afbeelding door auteur
De mean absolute error berekent de som van de verschillen tussen alle werkelijke en voorspelde waarden en deelt dit door het totale aantal observaties. Hier is de formule om MAE te berekenen:
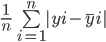
Laten we de Mean Absolute Error van de bovenstaande waarden berekenen met deze formule:
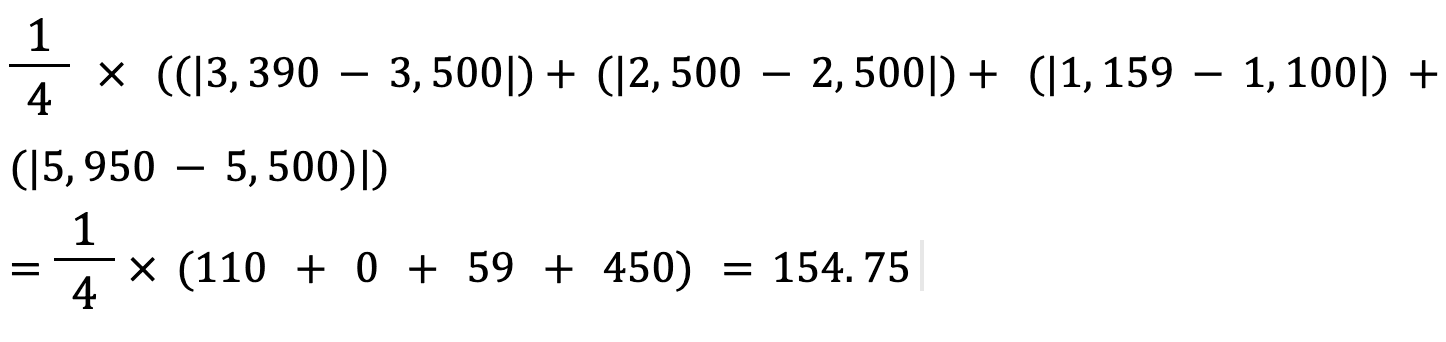
De mean absolute error tussen de werkelijke en voorspelde huisprijs is ongeveer $155.
De formule om de mean squared error van een model te berekenen lijkt op die van de mean absolute error:
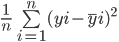
Let op: terwijl de mean absolute error de gemiddelde absolute afstand tussen de werkelijke en voorspelde waarde berekent, vindt de mean squared error de gemiddelde gekwadrateerde afstand tussen werkelijke en voorspelde waarden.
Laten we de MSE berekenen tussen de bovenstaande werkelijke en voorspelde waarden:
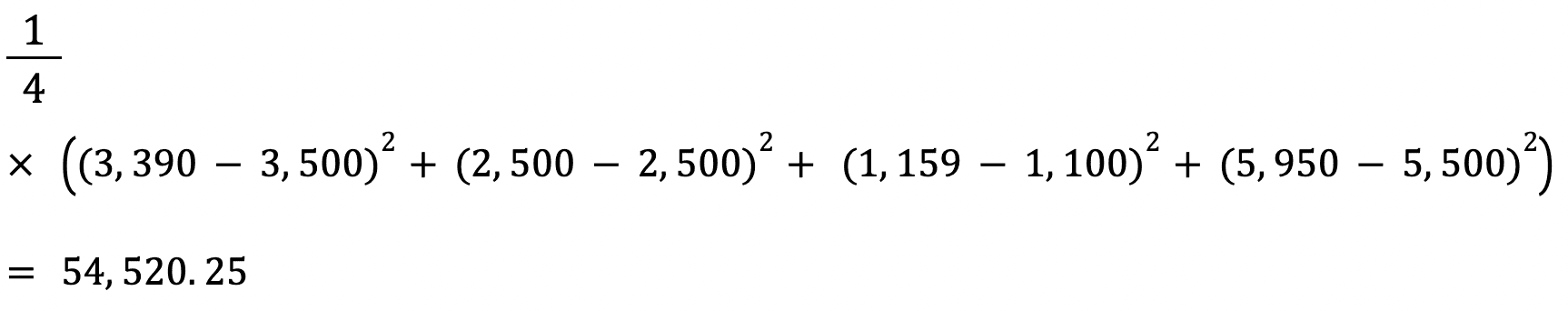
De RMSE van een schatter wordt berekend door de vierkantswortel te nemen van de mean squared error. Een voordeel van het berekenen van de RMSE boven de MSE is dat de fout wordt gerapporteerd in dezelfde eenheid als de variabele die we voorspellen.
In dit geval is de RMSE bijvoorbeeld √54.520,25 = 233,5. Deze waarde is interpreteerbaar omdat hij uitgedrukt is in termen van huisprijs, terwijl de Mean Squared Error dat niet was.
Nu je het concept van regressie begrijpt, kijken we naar de verschillende soorten regressiemodellen:
Lineaire regressie is een lineaire benadering om de relatie te modelleren tussen een afhankelijke en één of meer onafhankelijke variabelen. Dit algoritme zoekt naar een lijn die het beste past bij de beschikbare data.
Hier is een visuele weergave van hoe een eenvoudige lineaire regressie werkt:
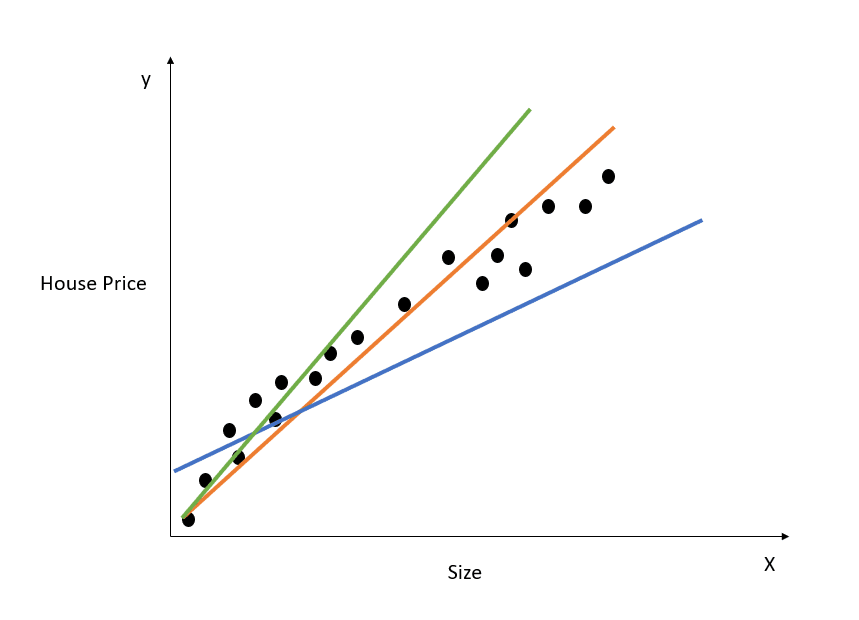
Afbeelding door auteur
De grafiek hierboven toont de relatie tussen huisprijs en grootte. Het lineaire regressiemodel zal een lijn creëren die deze relatie het beste modelleert. Alle huisprijsvoorspellingen voor verschillende waardes van grootte liggen op de best-fit-lijn.
Let op dat er drie lijnen zijn getekend in het diagram hierboven. Welke van deze lijnen is de “best-fit-lijn”?
Alleen al door naar het diagram te kijken, zien we dat de oranje lijn het dichtst bij alle datapunten ligt. We kunnen dus intuïtief zeggen dat dit de “best-fit-lijn” is.
Hier is een formelere uitleg hoe de best-fit-lijn wordt gevonden in lineaire regressie:
De vergelijking van een rechte lijn is y = mx + c. Hier staat m voor de helling van de lijn en c voor het y-snijpunt. Er zijn oneindig veel manieren om deze lijn te tekenen, omdat er oneindig veel mogelijke waarden zijn voor m en c.
De best-fit-lijn, ook bekend als de kleinste-kwadraten-regressielijn, wordt gevonden door de som van de gekwadrateerde afstanden tussen de werkelijke en voorspelde waarden te minimaliseren:
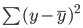
Je kunt de tutorial Essentials of Linear Regression in Python lezen voor een diepgaander begrip van het lineaire regressiemodel en de implementatie ervan.
Ridge-regressie is een uitbreiding op het hierboven uitgelegde lineaire regressiemodel. Het is een techniek om de coëfficiënten van een regressiemodel zo klein mogelijk te houden.
Een probleem bij eenvoudige lineaire regressie is dat de coëfficiënten groot kunnen worden, waardoor het model gevoeliger wordt voor inputs. Dit kan leiden tot overfitting.
Laten we een eenvoudig voorbeeld nemen om het concept van overfitting te begrijpen:
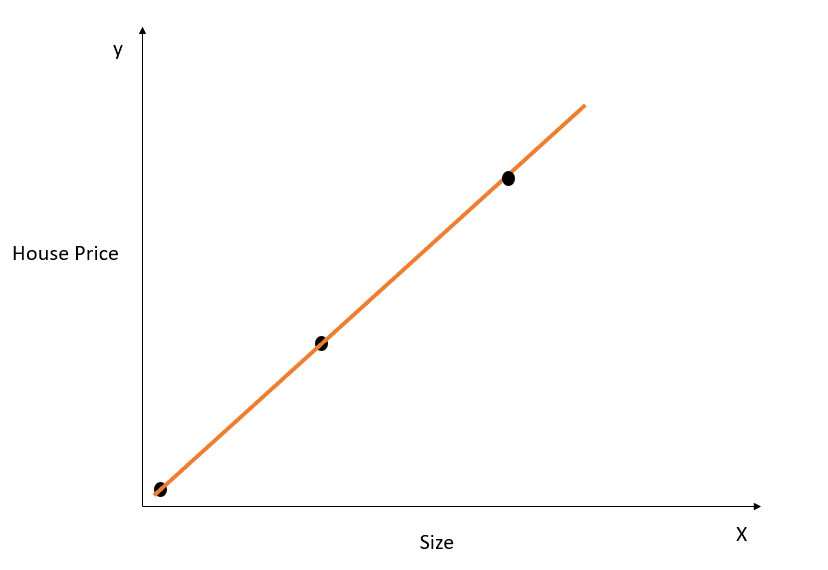
Afbeelding door auteur
In de bovenstaande figuur modelleert de best-fit-lijn de relatie tussen X en y perfect, en is de som van de gekwadrateerde afstanden tussen de werkelijke en voorspelde waarden 0. Denk eraan dat de vergelijking voor deze lijn y = mx + c is.
Hoewel deze lijn perfect past op de trainingsdataset, zal hij waarschijnlijk niet goed generaliseren naar testdata. Dit fenomeen heet overfitting, en je kunt dit artikel over overfitting lezen om er meer over te leren.
Simpel gezegd: een zeer complex model pikt onnodige nuances op in de trainingsdata die niet in de echte wereld voorkomen. Dit model presteert extreem goed op trainingsdata, maar minder goed op data buiten wat het heeft gezien.
Een lineair regressiemodel met grote coëfficiënten is gevoelig voor overfitting.
Ridge-regressie is een regularisatietechniek die het algoritme dwingt kleinere coëfficiënten te kiezen door de verliesfunctie te straffen met een extra kostenterm.
Zoals in de vorige sectie getoond, is dit de fout die we willen minimaliseren in eenvoudige lineaire regressie:
Bij ridge-regressie verandert deze vergelijking iets en wordt er een strafterm aan de bovenstaande fout toegevoegd:
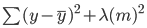
Merk op dat er een waarde (lambda) wordt vermenigvuldigd met de modelcoëfficiënten. Omdat dit model slechts één variabele heeft, is er één coëfficiënt met een strafterm. Als er meerdere onafhankelijke variabelen zijn, wordt lambda vermenigvuldigd met de som van de gekwadrateerde coëfficiënten.
Deze strafterm bestraft het model voor het kiezen van grotere coëfficiënten. Het doel is om de coëfficiëntwaarden te verkleinen, zodat variabelen met een geringe bijdrage aan de uitkomst coëfficiënten dicht bij 0 krijgen. Dit vermindert de variantie van het model en helpt overfitting te beperken.
Let op dat een lambda-waarde van 0 geen enkel effect heeft en de strafterm verdwijnt. Een hogere lambda voegt een grotere krimpstraf toe en de modelcoëfficiënten naderen nul.
Kies bij het selecteren van een lambda-waarde een balans tussen eenvoud en een goede fit op de trainingsdata. Een hogere lambda levert een eenvoudig, gegeneraliseerd model op, maar een te hoge waarde brengt het risico op underfitting mee. Aan de andere kant kan een lambda die heel dicht bij nul ligt leiden tot een zeer complex model.
Lasso-regressie is een andere uitbreiding op lineaire regressie die modelcoëfficiënten verkleint door een strafterm aan de kostenfunctie toe te voegen.
Hier is de fout die in lasso-regressie moet worden geminimaliseerd:
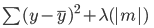
Merk op dat deze vergelijking lijkt op die van een ridge-regressiemodel, behalve dat we in plaats van lambda te vermenigvuldigen met het kwadraat van de coëfficiënt, lambda vermenigvuldigen met de absolute waarde van de coëfficiënt.
Het grootste verschil tussen ridge en lasso is dat bij ridge-regressie de modelcoëfficiënten wel naar nul kunnen krimpen, maar nooit echt nul worden. Bij lasso-regressie kunnen modelcoëfficiënten wél nul worden.
Als de coëfficiënt van een onafhankelijke variabele nul wordt, kan deze feature uit het model worden verwijderd. Dit verkleint de feature space en maakt het algoritme makkelijker te interpreteren, wat het grootste voordeel van lasso-regressie is.
Daardoor kan lasso-regressie ook worden gebruikt als featureselectietechniek, omdat variabelen met lage belangrijkheid coëfficiënten kunnen hebben die nul worden en volledig uit het model verdwijnen.
Je kunt lineaire, ridge- en lasso-regressiemodellen bouwen met de Scikit-Learn-bibliotheek:
1. Lineaire regressie
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression()Om het model te fitten op je trainingsdataset, voer je uit:
lr_model.fit(X_train,y_train)2. Ridge-regressie
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)De lambda-term kun je instellen via de “alpha”-parameter bij het definiëren van het model.
3. Lasso-regressie
from sklearn.linear_model import Lasso
model = Lasso(alpha=1.0)Als je meer wilt leren over lineaire modellen en hoe je ze in Python bouwt, volg dan onze cursus Introduction to Linear Modeling in Python.
We gebruiken classificatie-algoritmen om een discrete uitkomst (y) te voorspellen met behulp van onafhankelijke variabelen (x). De afhankelijke variabele is in dit geval altijd een klasse of categorie.
Het voorspellen of een patiënt waarschijnlijk hartziekte ontwikkelt op basis van risicofactoren is bijvoorbeeld een classificatieprobleem:
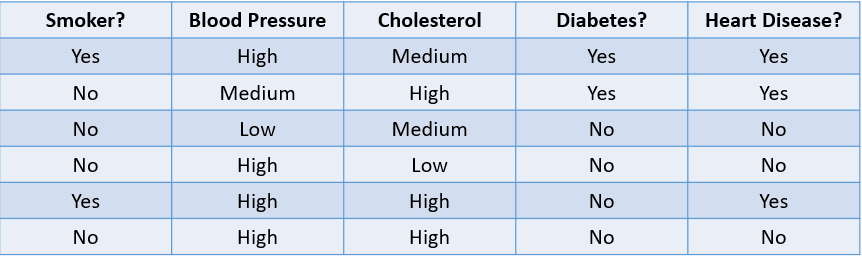
Afbeelding door auteur
De bovenstaande tabel toont een classificatieprobleem met vier onafhankelijke variabelen en één afhankelijke variabele, hartziekte. Omdat er slechts twee mogelijke uitkomsten zijn (Yes en No), heet dit een binaire classificatie.
Andere voorbeelden van binaire classificatie zijn bepalen of een e-mail spam of legitiem is, klantverloop (churn) voorspellen, en beslissen of iemand een lening krijgt.
Een multiclass-classificatieprobleem heeft drie of meer mogelijke uitkomsten, zoals weersvoorspelling of het onderscheiden van verschillende diersoorten.
Er zijn veel manieren om een classificatiemodel te evalueren. Hoewel accuratesse de meest gebruikte metriek is, is deze niet altijd het meest betrouwbaar.
Laten we enkele gangbare methoden bekijken om een classificatie-algoritme te evalueren op basis van de onderstaande dataset:
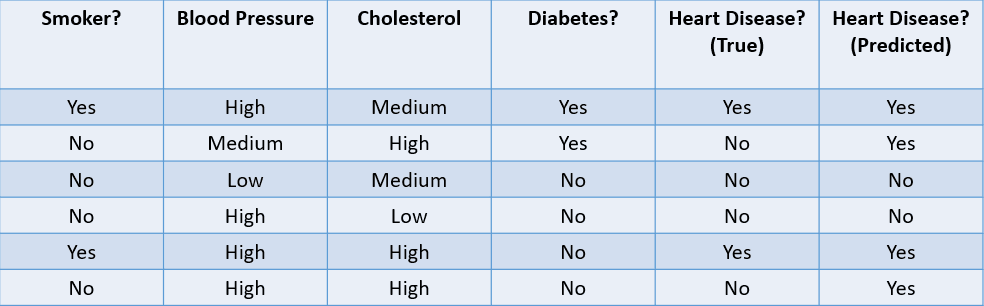
Afbeelding door auteur
1. Accuratesse: Accuratesse is het aandeel correcte voorspellingen dat het machine learning-model maakt.
De formule om accuratesse te berekenen is:

In dit geval is de accuratesse 4/6, ofwel 0,67.
2. Precisie: Precisie is een metriek om de kwaliteit van de positieve voorspellingen van het model te berekenen. Ze is gedefinieerd als:
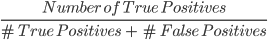
Het bovenstaande model heeft een precisie van 2/4, ofwel 0,5.
3. Recall: Recall wordt gebruikt om de kwaliteit van de negatieve voorspellingen te berekenen. Ze is gedefinieerd als:
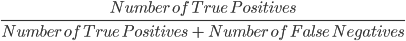
Het bovenstaande model heeft een recall van 2/2 ofwel 1.
Laten we een eenvoudig voorbeeld bekijken om het verschil tussen precisie en recall te begrijpen:
Er is een zeldzame, dodelijke ziekte die een fractie van de bevolking treft. 95% van de patiënten in de database van een ziekenhuis heeft de ziekte niet, terwijl slechts 5% die wel heeft. Als we een machine learning-algoritme bouwen dat voorspelt dat niemand de ziekte heeft, dan is de trainingsaccuratesse 95%. Ondanks de hoge accuratesse weten we dat dit geen goed model is, omdat het geen patiënten met de ziekte identificeert.
Hier komen metrieken als precisie en recall in beeld. Precisie, of specificiteit, vertelt ons hoe goed het model mensen zonder de ziekte correct identificeert. Recall, of sensitiviteit, vertelt ons hoe goed het model mensen met de ziekte identificeert.
Een “goede” precisie- en recallwaarde is subjectief en hangt af van je use-case.
In dit ziektedetectiescenario willen we altijd mensen met de ziekte identificeren, zelfs als dat het risico op een vals-positieve uitslag met zich meebrengt. We bouwen het model hier dus met een hogere recall dan precisie.
Anderzijds, als we een model bouwen dat kwaadwillenden van een e-commercewebsite moet weren, dan willen we misschien een hogere precisie, omdat het blokkeren van legitieme gebruikers tot omzetdaling leidt.
We gebruiken vaak een metriek genaamd de F1-score om het harmonisch gemiddelde van de precisie en recall van een classifier te vinden. Simpel gezegd combineert de F1-score precisie en recall in één metriek door hun gemiddelde te berekenen.
AUC, of Area Under the Curve, is een andere populaire metriek om de prestaties van een classificatiemodel te meten. De AUC van een algoritme vertelt ons iets over het vermogen om positieve en negatieve klassen te onderscheiden.
Wil je meer leren over metrieken zoals AUC en hoe ze worden berekend, volg dan de cursus Supervised Learning in R van Datacamp.
Nu bekijken we de verschillende soorten classificatiemodellen en hoe ze werken:
Logistische regressie is een eenvoudig classificatiemodel dat de kans voorspelt dat een gebeurtenis plaatsvindt.
Hier is een voorbeeld van hoe het logistische regressiemodel werkt:
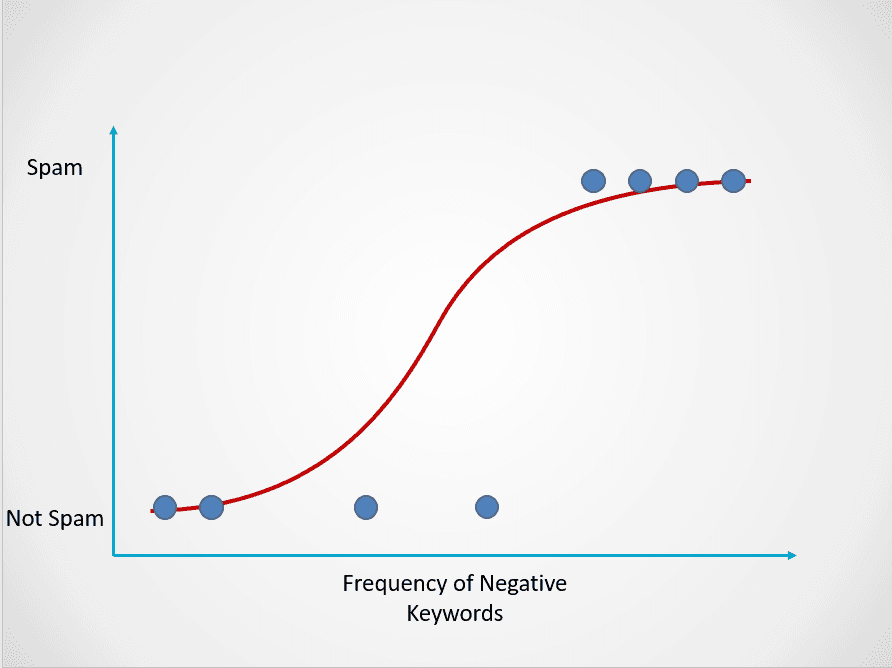
Afbeelding door auteur
De bovenstaande grafiek toont een logistische functie die e-maildata indeelt in twee categorieën: “Spam” en “Geen spam” op basis van de frequentie van negatieve trefwoorden in de tekst.
Merk op dat, in tegenstelling tot het lineaire regressie-algoritme, logistische regressie wordt gemodelleerd met een S-vormige curve. Dit staat bekend als de logistische functie en heeft de volgende formule:
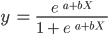
Terwijl de lineaire functie geen bovengrens en ondergrens heeft, varieert de logistische functie tussen 0 en 1. Het model voorspelt een waarschijnlijkheid tussen 0 en 1, die bepaalt tot welke klasse het datapunt behoort.
In dit spam-e-mailexample zal, als de tekst weinig tot geen verdachte trefwoorden bevat, de kans dat het spam is laag en dicht bij 0 zijn. Een e-mail met veel verdachte trefwoorden zal daarentegen een hoge kans op spam hebben, dicht bij 1.
Deze waarschijnlijkheid wordt vervolgens omgezet in een classificatie-uitkomst:
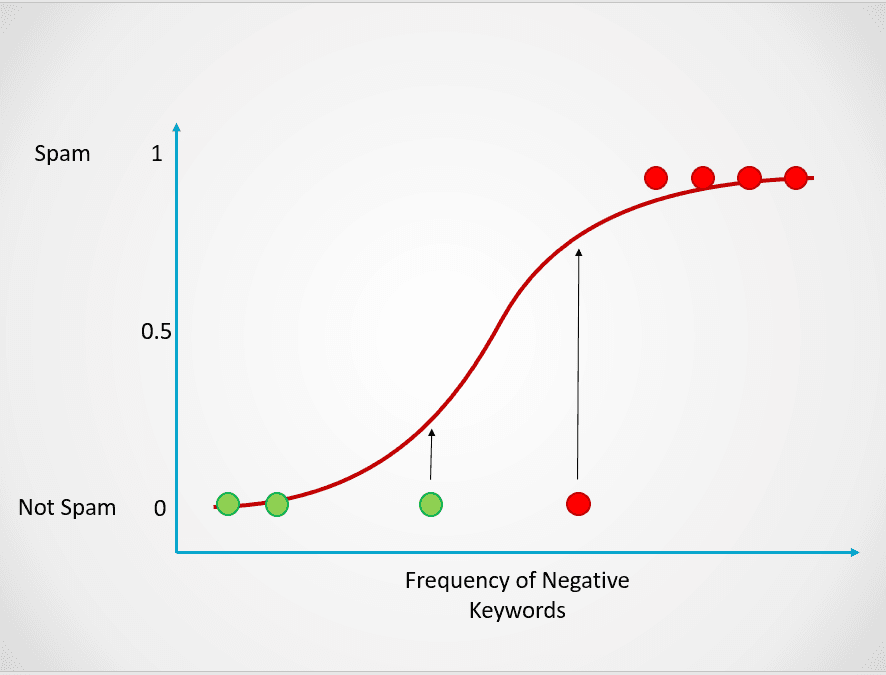
Afbeelding door auteur
Alle punten in het rood hebben een kans van >= 0,5 om spam te zijn. Daarom worden ze geclassificeerd als spam en geeft het logistische regressiemodel een classificatie-uitkomst van 1. De punten in het groen hebben een kans van < 0,5 om spam te zijn, dus worden door het model geclassificeerd als “Geen spam” en is de uitkomst 0.
Bij binaire classificatieproblemen zoals hierboven is de standaarddrempel van een logistisch regressiemodel 0,5, wat betekent dat datapunten met een hogere kans dan 0,5 automatisch een label 1 krijgen. Deze drempelwaarde kan handmatig worden aangepast, afhankelijk van je use-case, om betere resultaten te behalen.
Herinner je dat we bij lineaire regressie de best-fit-lijn vonden door de som van gekwadrateerde fouten tussen voorspelde en werkelijke waarden te minimaliseren. Bij logistische regressie worden de coëfficiënten echter geschat met een techniek die maximum likelihood estimation heet, in plaats van kleinste kwadraten.
Lees de tutorial Python logistic regression om meer te leren over het concept van maximum likelihood estimation en hoe logistische regressie werkt.
KNN is een classificatie-algoritme dat een datapunt classificeert op basis van de groep waar de dichtstbijzijnde datapunten toe behoren.
Hier is een eenvoudig voorbeeld om te laten zien hoe K-nearest neighbors werkt:
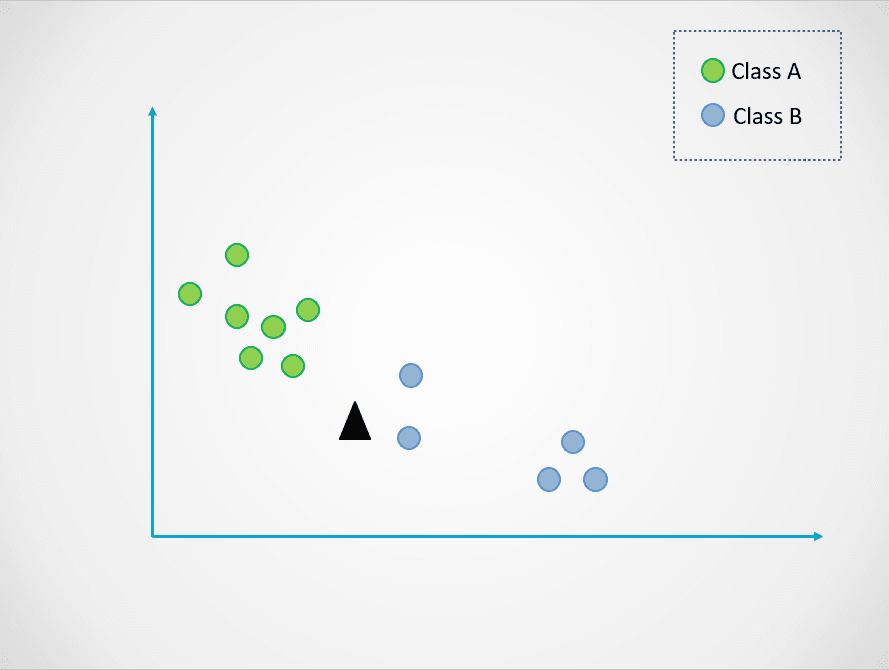
Afbeelding door auteur
In het diagram hierboven zijn er twee klassen datapunten – A en B. De zwarte driehoek vertegenwoordigt een nieuw datapunt dat in een van deze twee klassen moet worden ingedeeld.
Het K-nearest neighbors-algoritme werkt als volgt:
In de visual hierboven is de waarde van k 1. Dit betekent dat we alleen naar de één dichtstbijzijnde buur van de zwarte driehoek kijken en het datapunt aan die klasse toewijzen. Het nieuwe datapunt ligt het dichtst bij het blauwe punt, dus wijzen we het toe aan klasse B.
Laten we nu de waarde van k aanpassen. We proberen twee mogelijke waarden van k, 3 en 7:
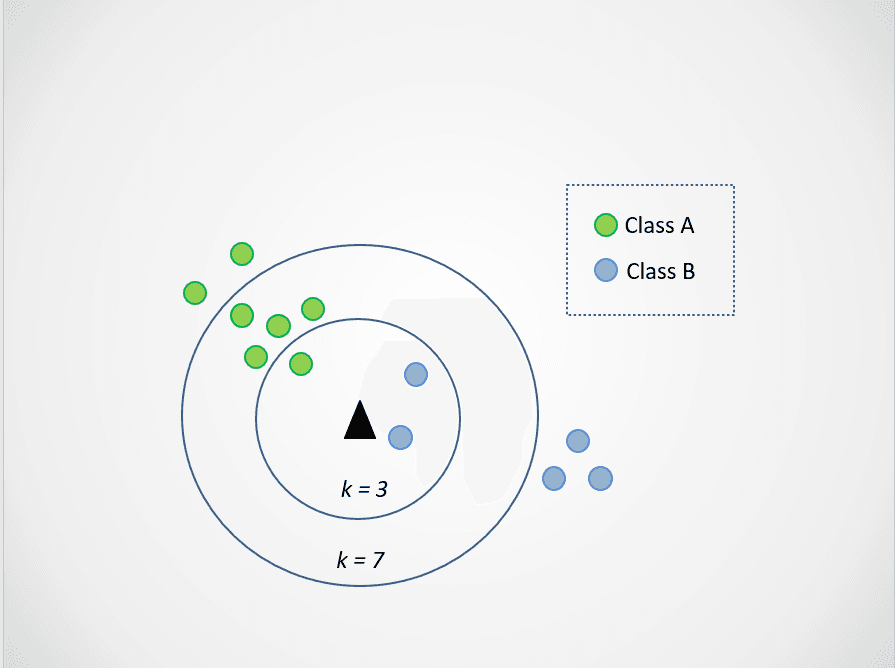
Afbeelding door auteur
Merk nu op dat wanneer we k = 3 kiezen, het nieuwe datapunt tussen twee categorieën in ligt. We kiezen dan de meerderheid. Twee dichtstbijzijnde buren zijn blauw en één is groen, dus wordt het datapunt opnieuw toegewezen aan de klasse met blauwe punten, klasse B.
Bij k = 7 veranderen de zaken. Nu zijn twee dichtstbijzijnde buren blauw en zeven groen. In dit geval wordt het datapunt toegewezen aan de groene klasse, klasse A.
Verschillende waarden van k beïnvloeden aan welke klasse het nieuwe punt wordt toegewezen.
Een te kleine waarde kiezen kan ruisgevoelig zijn en gevoelig voor uitschieters, terwijl een te grote waarde ertoe kan leiden dat je categorieën met minder datapunten over het hoofd ziet.
Wil je meer leren over K-nearest neighbors en hoe je een optimale “k”-waarde kiest, lees dan deze KNN-tutorial.
Hier zijn enkele codefragmenten om een classificatiemodel in Python te bouwen met de Scikit-Learn-bibliotheek:
1. Logistische regressie
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()2. K-nearest neighbors
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()Boomgebaseerde modellen zijn supervised machine learning-algoritmen die een boomstructuur opbouwen om voorspellingen te doen. Ze kunnen worden gebruikt voor zowel classificatie- als regressieproblemen.
In deze sectie bekijken we twee van de meest gebruikte boomgebaseerde machine learning-modellen: beslissingsbomen en random forests.
Een beslissingsboom is het eenvoudigste boomgebaseerde machine learning-algoritme. Dit model stelt ons in staat de dataset continu te splitsen op basis van specifieke parameters totdat er een definitieve beslissing is genomen.
Hier is een simpel voorbeeld dat laat zien hoe het beslissingsboom-algoritme werkt:
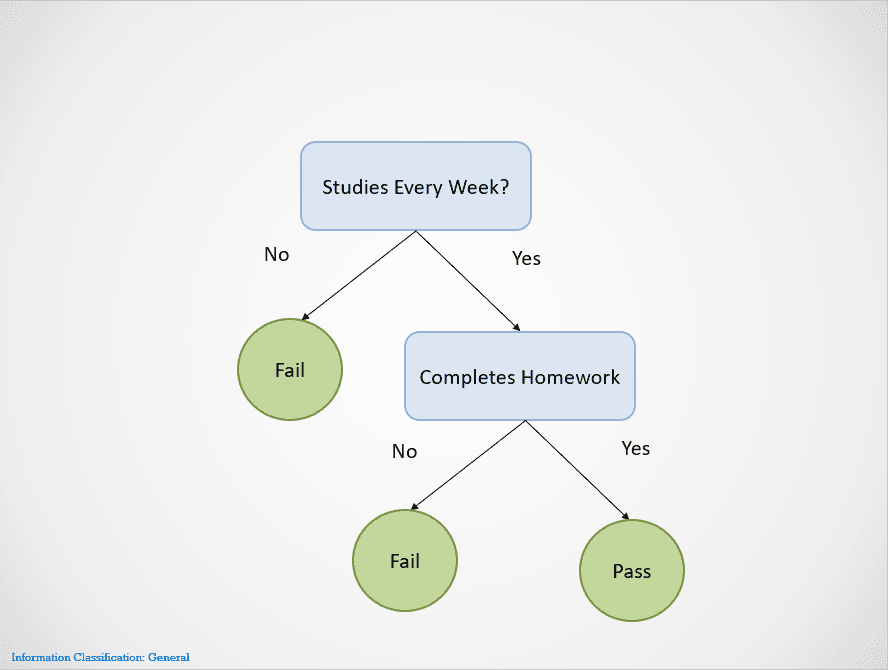
Afbeelding door auteur
Beslissingsbomen splitsen op verschillende knooppunten totdat een uitkomst wordt verkregen.
In dit geval, als een student niet elke week studeert, zakt die. Als ze elke week studeren maar hun huiswerk niet afmaken, is de uitkomst nog steeds “Gezakt”. Ze slagen alleen als ze elke week studeren en al hun huiswerk afmaken.
Merk op dat de beslissingsboom hierboven eerst splitst op de variabele “Studie elke week?”. Vervolgens stopt hij met splitsen als het antwoord “Nee” is, en zegt dat de student zakt.
De beslissingsboom kiest eerst een variabele om op te splitsen op basis van een metriek die entropie heet. Hij stopt met splitsen wanneer er een “pure split” is, d.w.z. wanneer alle datapunten tot één klasse behoren.
Er zijn veel manieren om een beslissingsboom te bouwen. De boom moet een feature vinden om eerst, tweede, derde, enz. op te splitsen. Deze structuur wordt gecreëerd op basis van een metriek die information gain heet. De best mogelijke beslissingsboom is degene met de hoogste information gain.
Wil je meer leren over hoe beslissingsbomen werken, samen met metrieken als entropie en information gain, lees dan dit artikel over decision tree-classificatie in Python.
Een van de grootste voordelen van beslissingsbomen is dat ze zeer goed te interpreteren zijn. Het is eenvoudig om terug te redeneren en te begrijpen hoe een beslissingsboom tot zijn einduitkomst is gekomen op basis van de trainingsdata.
Maar beslissingsbomen zijn ook erg gevoelig voor overfitting als ze onbeperkt mogen groeien. Dat komt omdat ze zo zijn ontworpen dat ze perfect splitsen op alle voorbeelden in de trainingsdata, waardoor ze niet goed generaliseren naar externe data.
Dit nadeel van beslissingsbomen kan worden opgelost met het random forest-algoritme.
Het random forest-model is een boomgebaseerd algoritme dat helpt enkele problemen te mitigeren die ontstaan bij het gebruik van beslissingsbomen, waaronder overfitting. Random forests worden gecreëerd door de voorspellingen van meerdere beslissingsbomen te combineren en één enkele output terug te geven.
Dat gebeurt in twee stappen:
Bij een regressieprobleem is de uitkomst de gemiddelde voorspelling van alle beslissingsbomen.
Hier is een eenvoudige visual die laat zien hoe het random forest-algoritme werkt:
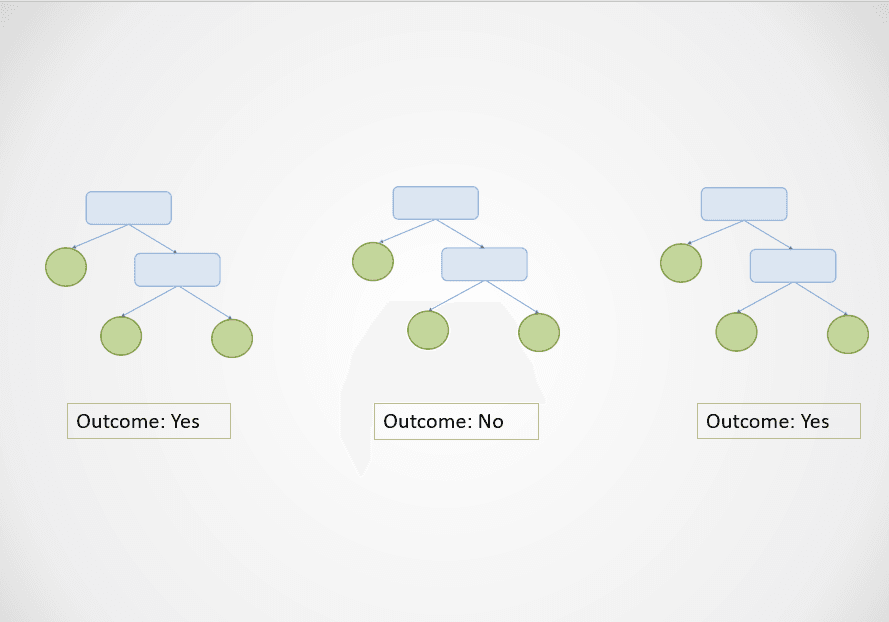
Afbeelding door auteur
In het diagram hierboven voorspellen de eerste en derde beslissingsboom “Ja”, terwijl de tweede “Nee” voorspelt.
Omdat dit een classificatietaak is, wordt de meerderheid gekozen. In dit geval geeft het random forest-algoritme een uiteindelijke uitkomst “Ja” op basis van de voorspellingen van 2 van de 3 beslissingsbomen.
Een van de grootste voordelen van het random forest-algoritme is dat het goed generaliseert, omdat het de output combineert van meerdere beslissingsbomen die zijn getraind op een subset van features.
Bovendien kan de output van één enkele beslissingsboom sterk variëren door een kleine wijziging in de trainingsdata; dit probleem doet zich minder voor bij het random forest-algoritme omdat de trainingsdata meerdere keren wordt bemonsterd.
Voer de volgende code uit om een boomgebaseerd machine learning-algoritme te bouwen met Scikit-Learn:
1. Beslissingsboom
# classification
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# regression
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()2. Random forests
# classification
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier()
# regression
from sklearn.ensemble import RandomForestRegressor
rf_reg = RandomForestRegressor()Tot nu toe hebben we supervised machine learning-modellen verkend om classificatie- en regressieproblemen aan te pakken. Nu duiken we in een populaire unsupervised benadering genaamd clustering.
Simpel gezegd is clustering het groeperen van objecten die op elkaar lijken, maar verschillen van andere objecten. Deze techniek kent diverse zakelijke toepassingen, zoals het aanbevelen van films aan gebruikers met vergelijkbare kijkpatronen op een videoplatform, anomaliedetectie en klantsegmentatie.
In deze sectie bekijken we een algoritme genaamd K-means clustering – het eenvoudigste en populairste machine learning-model voor unsupervised taken.
K-means clustering is een unsupervised machine learning-techniek die wordt gebruikt om vergelijkbare objecten in data te groeperen.
Hier is een voorbeeld van hoe het K-means clustering-algoritme werkt:

Afbeelding door auteur
Stap 1: De bovenstaande afbeelding bestaat uit ongelabelde observaties die nog niet gegroepeerd zijn. Aanvankelijk wordt elke observatie willekeurig aan een cluster toegewezen. Vervolgens wordt een centroid berekend voor elk cluster.
Deze worden weergegeven met het “+”-symbool in het onderstaande diagram:
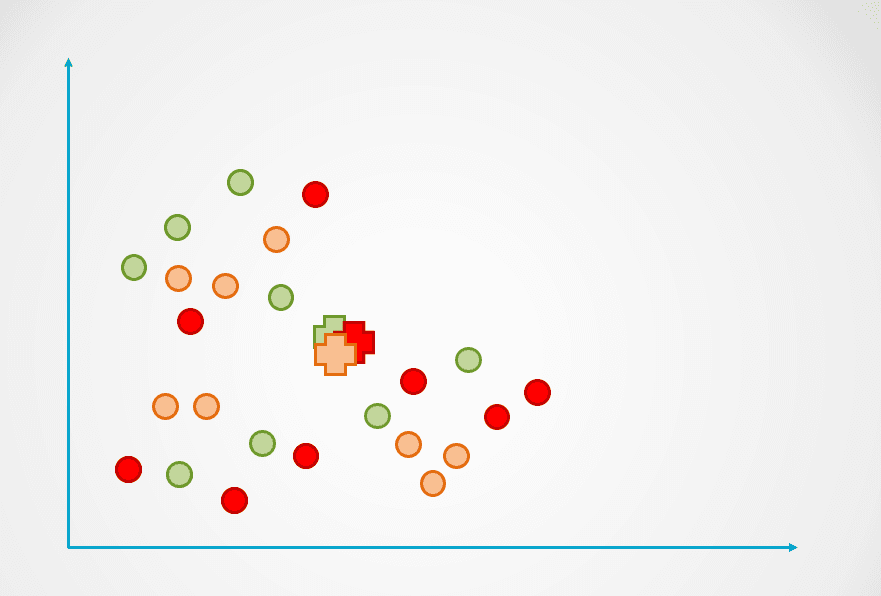
Afbeelding door auteur
Stap 2: Vervolgens wordt de afstand van elk datapunt tot het centroid gemeten en wordt elk punt toegewezen aan het dichtstbijzijnde centroid:
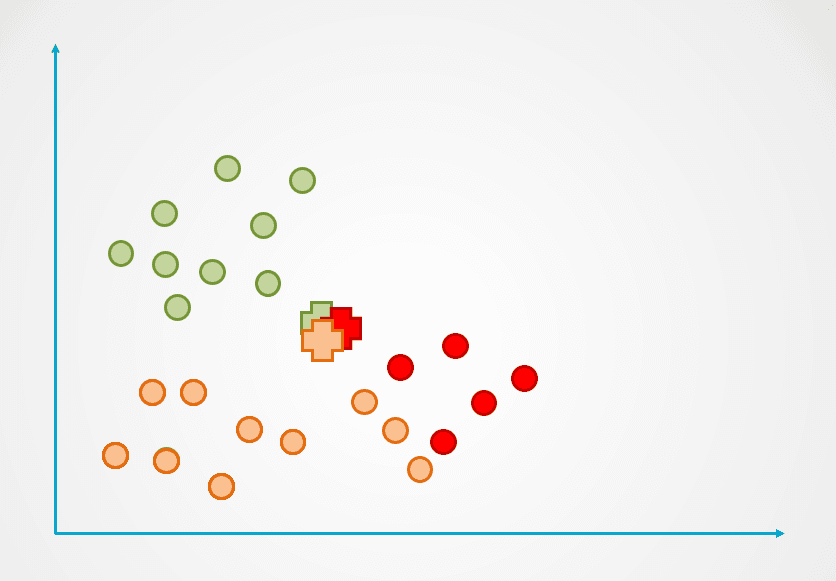
Afbeelding door auteur
Stap 3: Het centroid van het nieuwe cluster wordt vervolgens herberekend en datapunten worden dienovereenkomstig opnieuw toegewezen.
Stap 4: Dit proces wordt herhaald totdat datapunten niet langer worden herverdeeld:
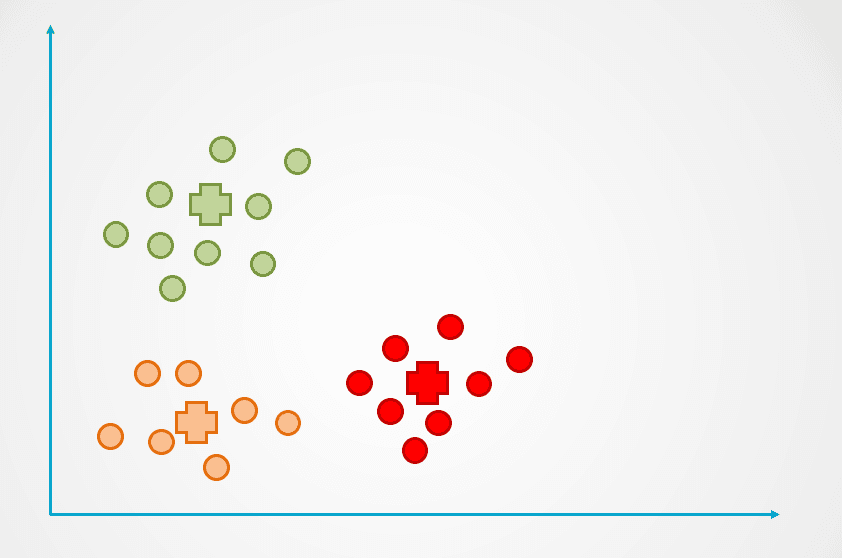
Afbeelding door auteur
Merk op dat er in het bovenstaande voorbeeld drie clusters zijn gemaakt. Het aantal clusters wordt aangeduid als “k” in het K-means-algoritme, en dit moeten we zelf bepalen.
Er zijn verschillende manieren om “k” te kiezen in K-means, waarvan de elbow-methode de populairste is. Deze techniek houdt in dat je de fout voor een verschillend aantal clusters uitzet in een grafiek en het knikpunt van de curve kiest als “k”.
Leer meer in onze K-means clustering in Python-tutorial om de elbow-methode en de werking van K-means te ontdekken.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3, init='k-means++')Het argument n_clusters geeft het aantal clusters “k” aan dat je moet definiëren bij het bouwen van het algoritme.
Als je het hele artikel hebt kunnen volgen: gefeliciteerd! Je kent nu enkele van de populairste supervised en unsupervised machine learning-modellen en -algoritmen en hoe je ze kunt toepassen om diverse voorspellende modelleringstaken op te lossen.
Om data scientist te worden, moet je begrijpen hoe verschillende soorten machine learning-modellen werken, zodat je ze kunt toepassen om een probleem op te lossen. Als je bijvoorbeeld een model wilt bouwen dat goed te interpreteren is en weinig rekentijd vraagt, kan een beslissingsboom logisch zijn. Wil je daarentegen een model dat goed generaliseert, dan kun je beter een random forest bouwen.
Het is ook belangrijk om te begrijpen hoe je machine learning-modellen evalueert. Een “goed” model is subjectief en sterk afhankelijk van je use-case. Bij classificatieproblemen is hoge accuratesse bijvoorbeeld niet op zichzelf al een indicatie van een goed model. Als data scientist moet je metrieken als precisie, recall en F1-score bekijken om een beter beeld te krijgen van de prestaties van je model.
Als je dieper begrip wilt krijgen van machine learning-modellen dan in dit artikel is behandeld, volg dan de cursus Machine Learning Scientist with Python. Deze career track leert je de theorie achter de werking van machine learning-modellen en hoe je ze in Python implementeert. Je leert in de cursus ook datavoorbereidingstechnieken zoals normalisatie, decorrelatie en featureselectie.
Machine learning-cursussen
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
