Kurs
Python ile Ağaç Tabanlı Modellerle Machine Learning
5 sa
117.2K
Makine öğrenimi, veri bilimi ve yapay zekânın en öne çıkan ve görünür kullanım alanlarının büyük kısmından sorumludur. Tesla’nın otonom araçlarından DeepMind’in AlphaFold algoritmasına kadar makine öğrenimine dayalı çözümler hayranlık uyandıran sonuçlar üretmiş ve ciddi bir ilgi yaratmıştır. Peki makine öğrenimi tam olarak nedir? Nasıl çalışır? Ve en önemlisi, bu ilgiyi hak ediyor mu? Bu makale, temel makine öğrenimi algoritmalarına sezgisel bir tanım getirir, başlıca uygulama alanlarını özetler ve makine öğrenimine nasıl başlayacağınıza dair kaynaklar sunar.
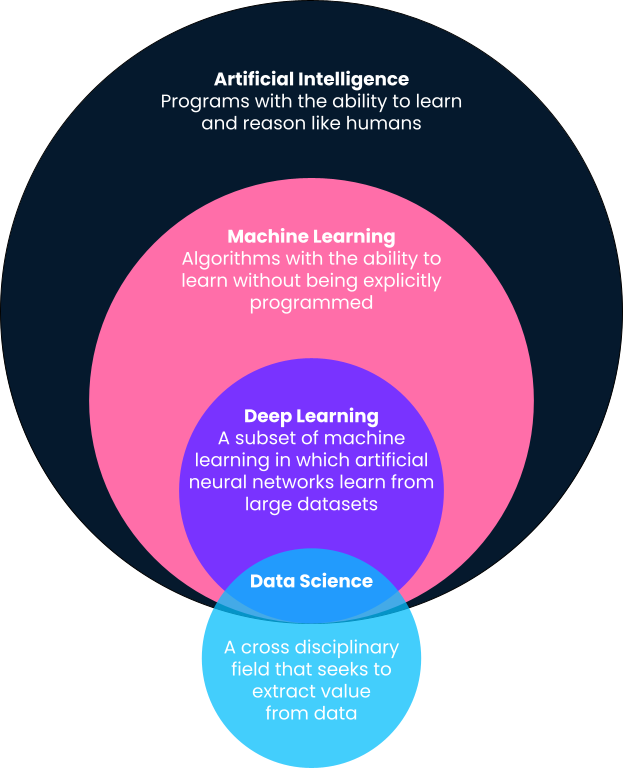
Kısaca, makine öğrenimi, bilgisayarların veriden doğrudan öğrendiği örüntülere dayanarak, bunu yapmak üzere açıkça programlanmadan tahminler ürettiği bir yapay zekâ alt dalıdır. Bu tanımda da göreceğiniz üzere makine öğrenimi, yapay zekânın bir alt alanıdır. Bu nedenle tanımları biraz daha açalım; zira çoğu zaman makine öğrenimi, yapay zekâ, derin öğrenme ve hatta veri bilimi gibi terimler birbirlerinin yerine kullanılır.
Yapay zekânın en iyi tanımlarından biri Google Brain’in kurucu ortağı ve Baidu’nun eski Baş Bilimcisi Andrew Ng’den gelir. Andrew’a göre yapay zekâ, “bilgisayarları akıllıca davranır hâle getirmeye yarayan çok büyük bir araç setidir.” Buna hesap makineleri gibi açıkça tanımlanmış sistemlerden, istenmeyen e-postaları algılayan makine öğrenimi tabanlı çözümlere kadar pek çok şey dâhil olabilir.
Yukarıda belirtildiği gibi, makine öğrenimi; algoritmaların geçmiş verilerden örüntüler öğrenip bu öğrendiklerini yeni verilere uygulayarak tahminler sunduğu yapay zekâ alt alanıdır. Geleneksel olarak, hesap makineleri gibi basit ve akıllı sistemler geliştiriciler tarafından açıkça tanımlanmış adımlar ve prosedürlerle (örn. şu olursa bunu yap) programlanır. Ancak bu yaklaşım daha gelişmiş problemler için ölçeklenebilir veya mümkün değildir.
Örneğin e-posta spam filtrelerini ele alalım. Geliştiriciler, filtreleri açıkça tanımlayarak oluşturmaya çalışabilir. Örneğin, belirli bir konu satırı olan ya da belirli bağlantılar içeren e-postalarda spam filtresini tetikleyen bir program yazabilirler. Ancak spam gönderenler taktik değiştirdiği anda bu sistem etkisiz kalacaktır.
Öte yandan, makine öğrenimi tabanlı bir çözüm, girdi verisi olarak milyonlarca spam e-postayı alır, istatistiksel ilişkilendirme yoluyla spam e-postaların en yaygın özelliklerini öğrenir ve bu öğrenilen özelliklere dayanarak gelecekteki e-postalar hakkında tahminlerde bulunur.
Derin öğrenme, makine öğreniminin bir alt dalıdır ve popüler kültürde en görünür makine öğrenimi kullanım alanlarının muhtemelen baş sorumlusudur. Derin öğrenme algoritmaları insan beyninin yapısından esinlenmiştir ve eğitilmek için çok büyük miktarda veriye ihtiyaç duyar. Çoğunlukla konuşma algılama, dil çevirisi, otonom araçlar gibi en karmaşık “bilişsel” problemlerde kullanılır. Daha fazla bağlam için derin öğrenme ve makine öğrenimi karşılaştırmamıza göz atın.
Makine öğrenimi, yapay zekâ ve derin öğrenmeden farklı olarak, veri biliminin tanımı oldukça geniştir. Kısaca, veri bilimi veriden değer ve içgörü elde etmektir. Bu değer, makine öğrenimi kullanan tahminleyici modeller şeklinde olabilir; ancak bir gösterge paneli veya raporla içgörü sunmak da bu kapsama girer. Veri bilimcilerin günlük görevleri hakkında bu yazıdan daha fazlasını okuyun.
E-posta spam tespitinin ötesinde, yaygın bilinen makine öğrenimi uygulamaları arasında demografik verilere dayalı müşteri segmentasyonu (satış ve pazarlama), hisse senedi fiyat tahmini (finans), hasar onayı otomasyonu (sigorta), izleme geçmişine dayalı içerik önerileri (medya ve eğlence) ve çok daha fazlası yer alır. Makine öğrenimi artık her yerde karşımıza çıkıyor ve günlük hayatımızda farklı şekillerde uygulanıyor.
Bu makalenin sonunda, makine öğrenimine başlamanıza yardımcı olacak pek çok kaynağı paylaşacağız.
Artık makine öğrenimine ve bu alanda karşılaşabileceğiniz diğer moda terimler arasında nereye oturduğuna dair genel bir bakış sunduğumuza göre, farklı makine öğrenimi algoritması türlerine daha yakından bakalım. Makine öğrenimi algoritmaları genel olarak denetimli, denetimsiz, pekiştirmeli ve öz-denetimli öğrenme olarak sınıflandırılır. Bunları ve en yaygın kullanım alanlarını daha ayrıntılı olarak anlayalım.
Makine öğrenimi kullanım alanlarının çoğu, algoritmaların geçmiş verilerden örüntüler öğrenip bu öğrendiklerini tahminler şeklinde yeni verilere uygulaması etrafında döner. Bu sıkça denetimli öğrenme olarak anılır. Denetimli öğrenme algoritmalarına, çözmeye çalıştığımız belirli bir problemde hem geçmiş girdiler hem de çıktılar gösterilir; burada girdiler, tahmin etmeye çalıştığımız gözlemin özellikleri veya boyutları; çıktılar ise tahmin etmek istediğimiz sonuçlardır. Bunu spam tespit örneğimizle açıklayalım.
Spam tespit kullanımında, denetimli bir öğrenme algoritması spam e-postalardan oluşan bir veri kümesi üzerinde eğitilir. Girdiler; e-postaların konu satırı, gönderenin e-posta adresi, e-posta içeriği, tehlikeli görünen bağlantılar içerip içermediği ve bir e-postanın spam olup olmadığına dair ipucu verebilecek diğer ilgili bilgiler gibi e-postalara ilişkin özellikler veya boyutlar olur.
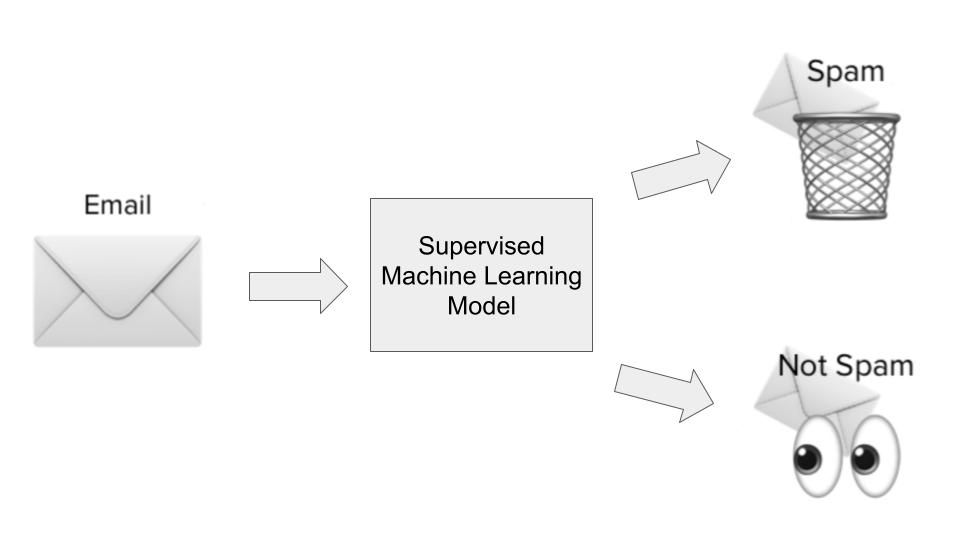
Çıktı ise o e-postanın gerçekten spam olup olmadığıdır. Model öğrenme aşamasında algoritma, girdi değişkenleri kümesi (spam e-postanın farklı boyutları) ile çıktı değişkeni (spam olup olmadığı) arasındaki istatistiksel ilişkiyi haritalayan bir fonksiyon öğrenir. Bu fonksiyonel eşleme daha sonra daha önce görülmemiş verilerin çıktısını tahmin etmek için kullanılır.
Denetimli öğrenmede genel olarak iki tür kullanım vardır:
Bir sonraki bölümde, belirli denetimli öğrenme algoritmalarını ve bazı kullanım alanlarını daha ayrıntılı inceleyeceğiz.
Girdileri çıktılara eşleyen örüntüler öğrenmek yerine, denetimsiz öğrenme algoritmaları çıktıların açıkça gösterilmesine gerek duymadan veride genel örüntüler keşfeder. Denetimsiz öğrenme algoritmaları genellikle farklı nesneleri ve varlıkları gruplamak ve kümelemek için kullanılır. Denetimsiz öğrenmeye güzel bir örnek müşteri segmentasyonudur. Şirketler sıklıkla hizmet verdikleri çeşitli müşteri personalarına sahiptir. Kuruluşlar, müşterilerini daha iyi hizmet verebilmek için olgulara dayalı bir yaklaşımla segmentlerine ayırmak ister. İşte denetimsiz öğrenme burada devreye girer.
Bu kullanımda, denetimsiz bir öğrenme algoritması müşterileri bir ürünü kullanma sıklıkları, demografik özellikleri, ürünlerle nasıl etkileşim kurdukları ve daha fazlası gibi çeşitli özniteliklere göre gruplamayı öğrenir. Ardından aynı algoritma, aynı boyutlara dayanarak yeni müşterilerin büyük olasılıkla hangi segmente ait olduğunu da tahmin edebilir.
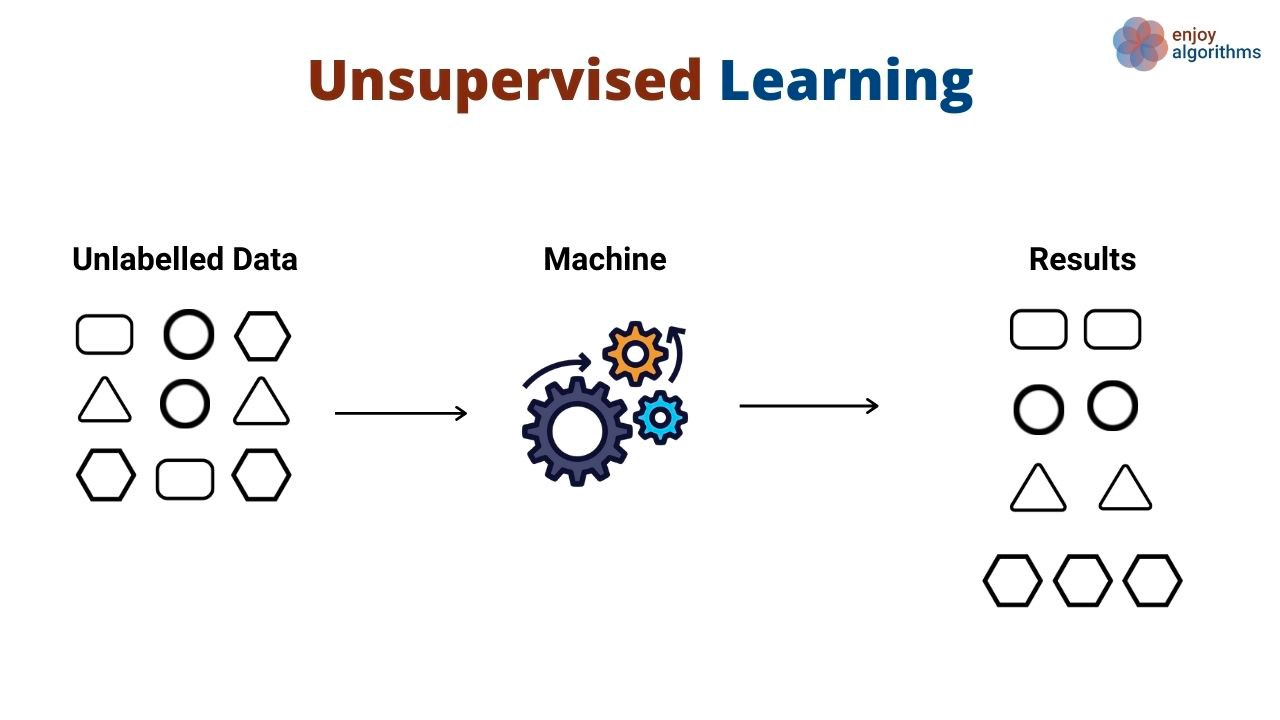
Denetimsiz algoritmalar, boyut indirgeme tekniklerini kullanarak bir veri kümesindeki boyutları (yani öznitelik sayısını) azaltmak için de kullanılır. Bu algoritmalar sıklıkla bir denetimli öğrenme algoritması eğitmede ara adım olarak kullanılır.
Veri bilimcilerin makine öğrenimi algoritmalarını eğitirken sıklıkla karşılaştığı büyük bir ödünleşim, performans ile tahmin doğruluğu arasındadır. Genel olarak bir problem hakkında ne kadar çok bilgi varsa o kadar iyidir. Ancak bu durum eğitim sürelerinin ve performansın düşmesine de yol açabilir. Boyut indirgeme teknikleri, bir veri kümesinde bulunan öznitelik sayısını tahmin gücünden ödün vermeden azaltmaya yardımcı olur.
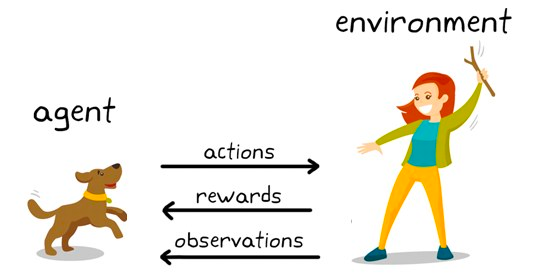
Pekiştirmeli öğrenme, arzu edilen bir davranışı veya tahmini ödüllerle teşvik eden, aksi hâlde cezalandıran bir alt makine öğrenimi algoritmaları kümesidir. Makine öğrenimi içinde görece hâlâ araştırma alanı olsa da satranç, Go ve daha başka oyunlarda insan düzeyini aşan zekâ sergileyen algoritmalardan pekiştirmeli öğrenme sorumludur.
Bu, modelin çevreyle etkileşimde bulunmaya devam ettikçe deneme-yanılma yoluyla öğrendiği bir davranış modelleme tekniğidir. Bunu satranç örneğiyle açıklayalım. Yüksek seviyede, pekiştirmeli bir öğrenme algoritmasına (genellikle ajan denir) kararlar verebileceği bir çevre (satranç tahtası) sağlanır (hamleler oynama).
Her hamlenin ilişkili bir puanı vardır; ajanın kazanmasına yol açan eylemler için ödül, kaybetmesine yol açan hamleler için ceza verilir.
Ajan, en fazla ödül getiren eylemleri öğrenmek için çevreyle etkileşimini sürdürür ve bu eylemleri tekrarlar. Bu teşvik edilen davranışın tekrarlanmasına sömürü (exploitation) aşaması denir. Ajan yeni ödül yolları aradığında ise buna keşif (exploration) aşaması denir. Genel olarak buna keşif-sömürü paradigması denir.
Öz-denetimli öğrenme, modelin etiketlenmemiş bir örnek veri kümesinden öğrendiği, veri açısından verimli bir makine öğrenimi tekniğidir. Aşağıdaki örnekte gösterildiği gibi, ilk modele etiketlenmemiş bazı girdi görüntüleri verilir ve model bu görüntülerden üretilen özellikleri kullanarak bunları kümeler.
Bu örneklerden bazılarının kümelere ait olma güveni yüksekken bazılarınınki düşüktür. İkinci adımda, bir adımdaki kümelemeye göre daha güçlü olma eğilimindeki bir sınıflandırıcıyı eğitmek için ilk adımdan gelen yüksek güvenli etiketli veriler kullanılır.
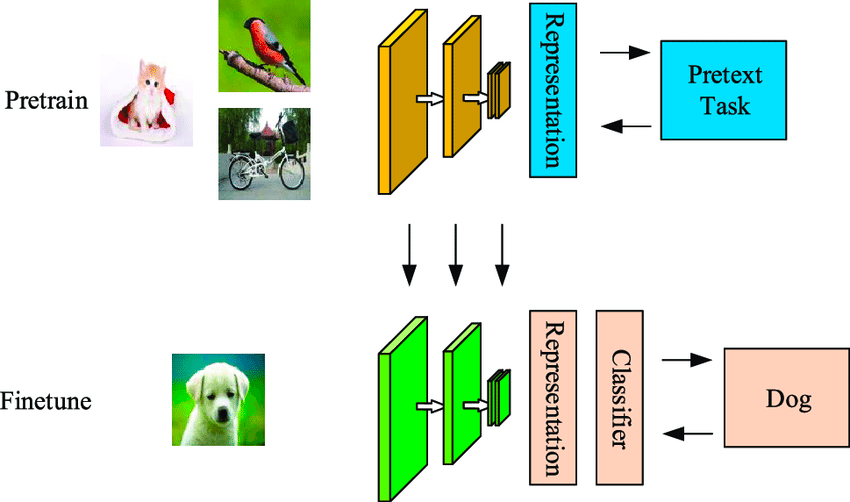
Öz-denetimli ve denetimli algoritmalar arasındaki fark, ilkinde sınıflandırılan çıktının yine de gerçek nesnelere karşılık gelen sınıflarla eşlenmemiş olmasıdır. El ile etiketlenmiş bir kümeye dayanmadığı ve etiketleri kendi ürettiği için denetimli öğrenmeden ayrılır; adını da buradan alır.
Aşağıda, en önde gelen makine öğrenimi algoritmalarını ve en yaygın kullanım alanlarını özetledik.
Bir veya daha fazla açıklayıcı değişken ile sürekli bir sayısal çıktı değişkeni arasında doğrusal bir ilişkiyi modelleyen basit bir algoritmadır. Diğer makine öğrenimi algoritmalarına kıyasla daha hızlı eğitilir. En büyük avantajı, model tahminlerini açıklama ve yorumlama becerisidir. Müşteri yaşam döngüsü değeri, konut fiyatları ve hisse senedi fiyatları gibi sonuçları tahmin etmek için kullanılan bir regresyon algoritmasıdır.
Bu Python ile doğrusal regresyonun temelleri başlıklı eğitimde daha fazlasını öğrenebilirsiniz. Regresyon analizini uygulamalı olarak öğrenmekle ilgileniyorsanız, DataCamp’teki çok rağbet gören bu kurs sizin için doğru kaynaktır.
Karar ağacı algoritması, olası sonuçları tahmin etmek için girdi özniteliklerine uygulanan karar kurallarından oluşan ağaç benzeri bir yapıdır. Sınıflandırma veya regresyon için kullanılabilir. Karar ağacı tahminleri, nasıl üretildiğinin anlaşılması kolay olduğundan, sağlık uzmanları için iyi bir destek sağlar.
Python kullanarak karar ağacı sınıflandırıcısı nasıl oluşturulur öğrenmek istiyorsanız bu eğitime bakabilirsiniz. Ayrıca R kullanmayı tercih ediyorsanız bu eğitimden faydalanabilirsiniz. DataCamp’te kapsamlı bir karar ağaçları kursu da mevcuttur.
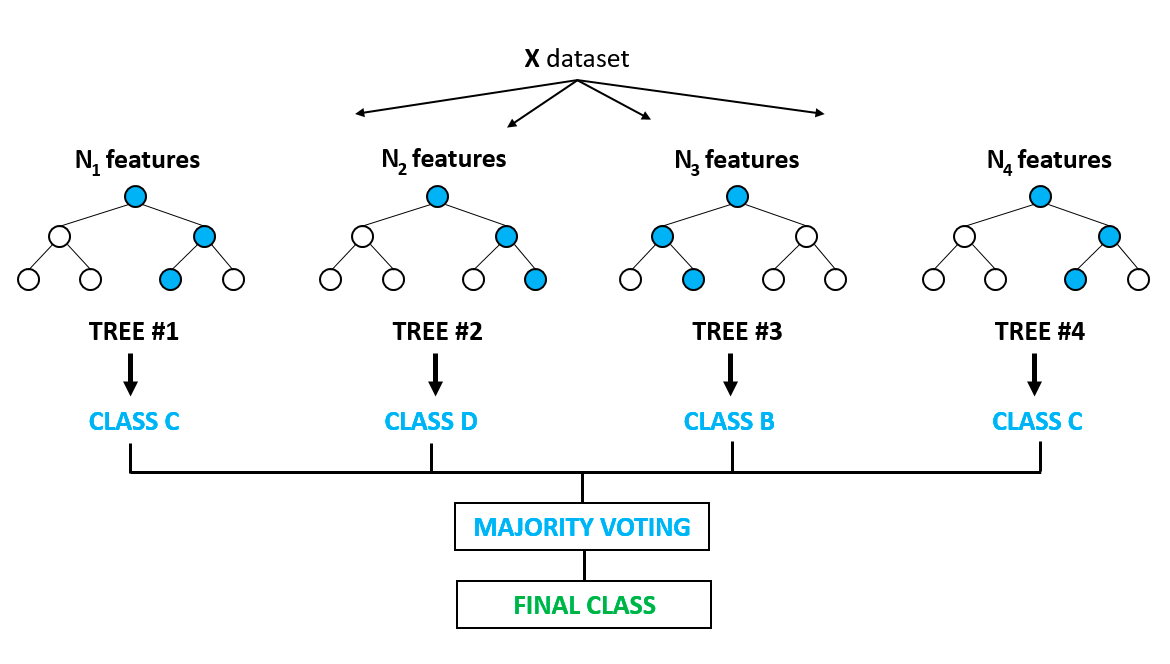
Muhtemelen en popüler algoritmalardan biridir ve karar ağaçlarında belirgin şekilde görülen aşırı öğrenme (overfitting) dezavantajını giderir. Aşırı öğrenme, algoritmaların eğitim verisine fazlasıyla uyum sağlaması ve daha önce görülmemiş verilerde genellemede başarısız olması veya doğru tahminler üretememesi durumudur. Rastgele orman, veriden rastgele seçilmiş örnekler üzerinde birden çok karar ağacı oluşturarak aşırı öğrenme sorununu çözer. Nihai sonuç, ormandaki tüm ağaçların çoğunluk oylamasından elde edilen en iyi tahmindir.
Hem sınıflandırma hem de regresyon problemlerinde kullanılır. Öznitelik seçimi, hastalık tespiti gibi alanlarda uygulama bulur. Ağaç tabanlı modeller ve ansambllar (farklı bireysel modelleri birleştirme) hakkında daha fazla bilgiyi DataCamp’teki bu popüler kurstan edinebilirsiniz. Ayrıca rastgele orman modelinin Python ile uygulanmasına dair bu eğitimde de daha fazlasını öğrenebilirsiniz.
Yaygın olarak SVM olarak bilinen Destek Vektör Makineleri genellikle sınıflandırma problemleri için kullanılır. Aşağıdaki örnekte gösterildiği gibi, bir SVM iki sınıfı (kırmızı ve yeşil) ayıran ve aralarındaki marjı (noktalı çizgiler arası mesafe) maksimize eden bir hiper düzlem (bu durumda bir doğru) bulur.
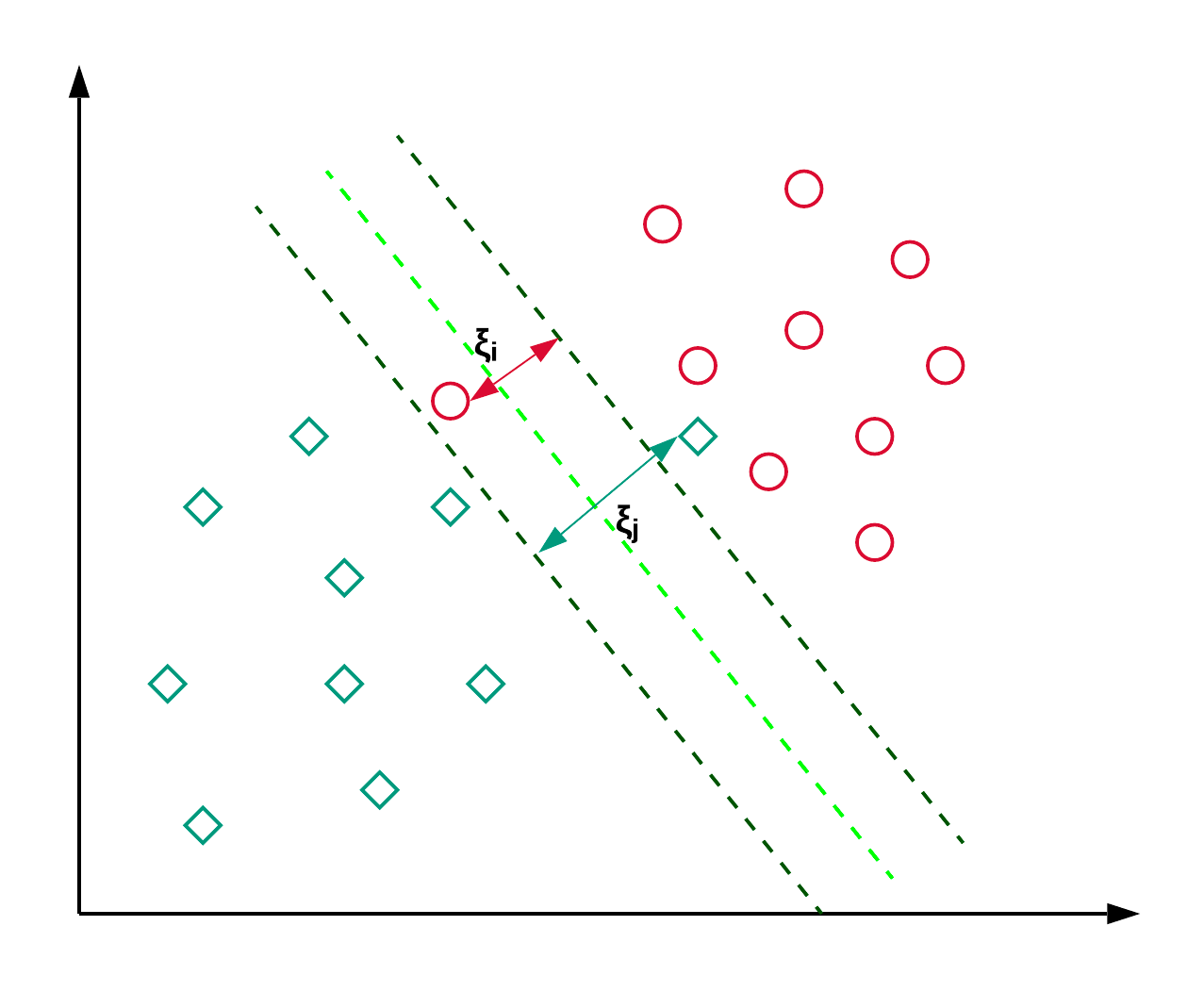
SVM genellikle sınıflandırmada kullanılır ancak regresyon problemlerinde de uygulanabilir. Haber makalelerini sınıflandırmak ve el yazısı tanıma için kullanılır. Farklı çekirdek (kernel) hileleri ve Python uygulaması hakkında daha fazlasını bu scikit-learn SVM eğitiminde okuyabilirsiniz. Ayrıca R ile SVM uygulamasını çoğaltacağınız bu eğitimi de takip edebilirsiniz
Gradyan Artırmalı Regresyon (Gradient Boosting), birkaç zayıf öğreneni birleştirerek güçlü bir tahmin modeli oluşturan bir ansambl modelidir. Verideki doğrusal olmayanlıkları ve çoklu doğrusal bağlantı sorunlarını iyi ele alır.
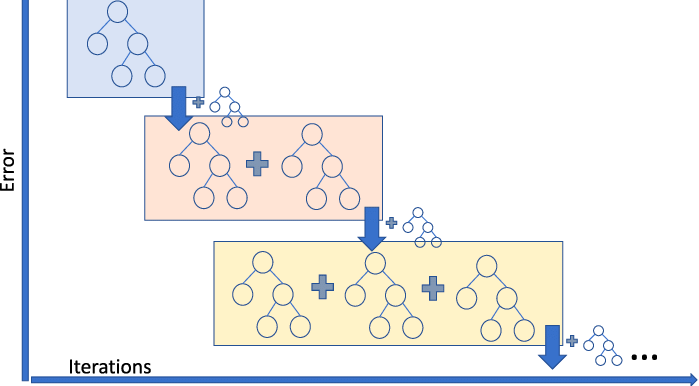
Bir araç paylaşım işletmesindeyseniz ve yolculuk ücretini tahmin etmeniz gerekiyorsa, gradyan artırmalı bir regresör kullanabilirsiniz. Gradyan artırmanın farklı türlerini anlamak istiyorsanız DataCamp’teki bu videoyu izleyebilirsiniz.
K-ortalamalar, Öklidyen mesafeye dayalı olarak K küme belirleyen en yaygın kullanılan kümeleme yaklaşımıdır. Müşteri segmentasyonu ve öneri sistemleri için çok popüler bir algoritmadır.
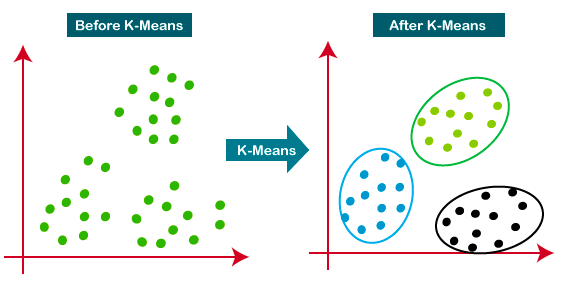
K-ortalamalar kümeleme hakkında daha fazla bilgi edinmek için bu eğitim harika bir kaynaktır.
Temel bileşenler analizi (PCA), büyük bir veri setindeki bilgiyi daha düşük boyutlu bir alt uzaya yansıtarak özetlemek için kullanılan istatistiksel bir prosedürdür. Yüksek bilgi içeren temel kısımları koruyarak veri boyutunu azaltan bir teknik olarak da adlandırılır.
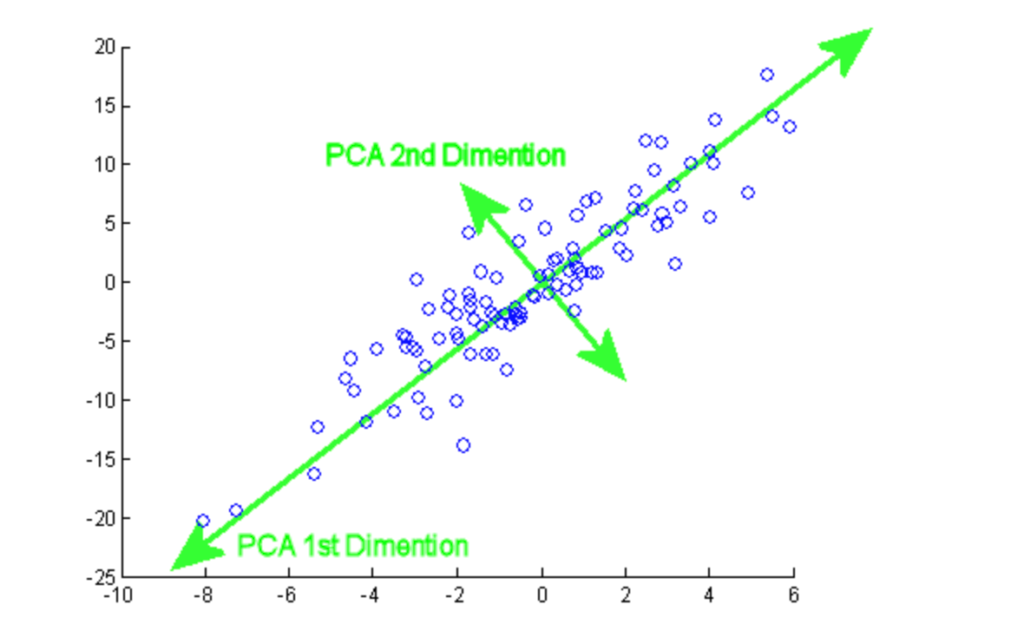
Bu eğitimde, Meme Kanseri ve CIFAR-10 gibi iki popüler veri seti üzerinde uygulamalı PCA pratiği yapabilirsiniz.
Her veri noktasının kendi kümesi olarak alındığı ve ardından en yakın iki kümenin yinelemeli olarak birleştirildiği aşağıdan yukarıya bir yaklaşımdır. K-ortalamalara göre en büyük avantajı, beklenen küme sayısının baştan kullanıcı tarafından belirtilmesini gerektirmemesidir. Benzerliğe dayalı belge kümelemede uygulama bulur.
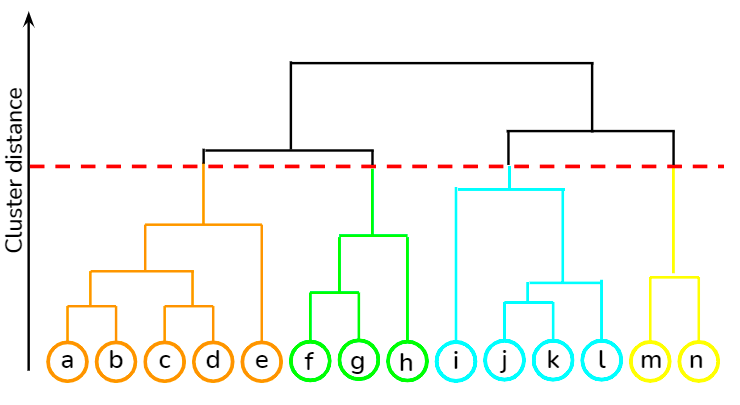
scipy kütüphanesini kullanarak hiyerarşik kümeleme ve K-ortalamalar gibi çeşitli denetimsiz öğrenme tekniklerini DataCamp’teki bu dersten öğrenebilirsiniz. Ayrıca, bu kurstan R kullanarak etiketlenmemiş verilerden içgörü üretmek için kümeleme tekniklerini nasıl uygulayacağınızı da öğrenebilirsiniz.
Bir veri setindeki normal dağılımlı kümeleri modellemek için olasılıksal bir modeldir. Standart kümeleme algoritmalarından farklı olarak, bir gözlemin belirli bir kümeye ait olma olasılığını tahmin eder ve ardından alt popülasyonu hakkında çıkarımlara girer.
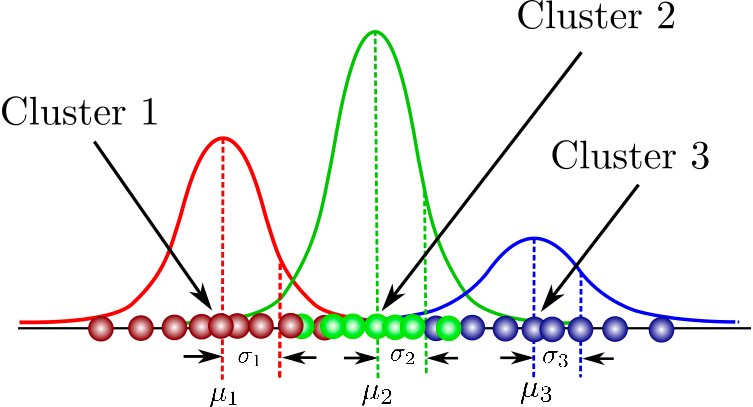
Model tabanlı kümelemede temel kavramları, Karışım Modellerinin yapısını ve ötesini kapsayan tek noktadan ders derlemesini burada bulabilirsiniz. Ayrıca flexmix paketiyle uygulamalı Gauss karışım modellemesi pratiği de yapacaksınız.
Verilen bir veri kümesinde en sık öğe kümelerini belirleyen, sık öğe kümesi özelliklerine dair ön bilgiden yararlanan kural tabanlı bir yaklaşımdır. Pazar sepeti analizi, Amazon ve Netflix gibi devlerin kullanıcıları hakkındaki yığınla bilgiyi basit ürün öneri kurallarına dönüştürmesine yardımcı olmak için bu algoritmayı kullanır. Milyonlarca ürün arasındaki ilişkileri analiz eder ve anlamlı kurallar ortaya çıkarır.
DataCamp hem Python hem de R dillerinde kapsamlı bir kurs sunar.
Makine öğrenimi artık sadece bir moda sözcük değil. Pek çok kuruluş makine öğrenimi modellerini devreye alıyor ve tahmine dayalı içgörülerden şimdiden fayda sağlıyor. Dolayısıyla piyasada yüksek vasıflı makine öğrenimi uygulayıcılarına büyük talep var. Aşağıda, makine öğrenimi kavramlarında hızlıca kendinizi geliştirmenize yardımcı olacak kaynakların bir listesi yer alıyor:
Makine öğrenimine başlayın
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
