Cursus
Machine Learning met boomgebaseerde modellen in Python
5 Hr
117.2K
Machine learning is waarschijnlijk verantwoordelijk voor de meest prominente en zichtbare use-cases van data science en kunstmatige intelligentie. Van de zelfrijdende auto’s van Tesla tot DeepMinds AlphaFold-algoritme: op machine learning gebaseerde oplossingen hebben adembenemende resultaten opgeleverd en veel buzz gegenereerd. Maar wat is machine learning nu precies? Hoe werkt het? En misschien wel het belangrijkst: is het die hype waard? Dit artikel geeft een intuïtieve definitie van belangrijke machinelearning-algoritmen, zet hun belangrijkste toepassingen uiteen en biedt bronnen om te starten met machine learning.
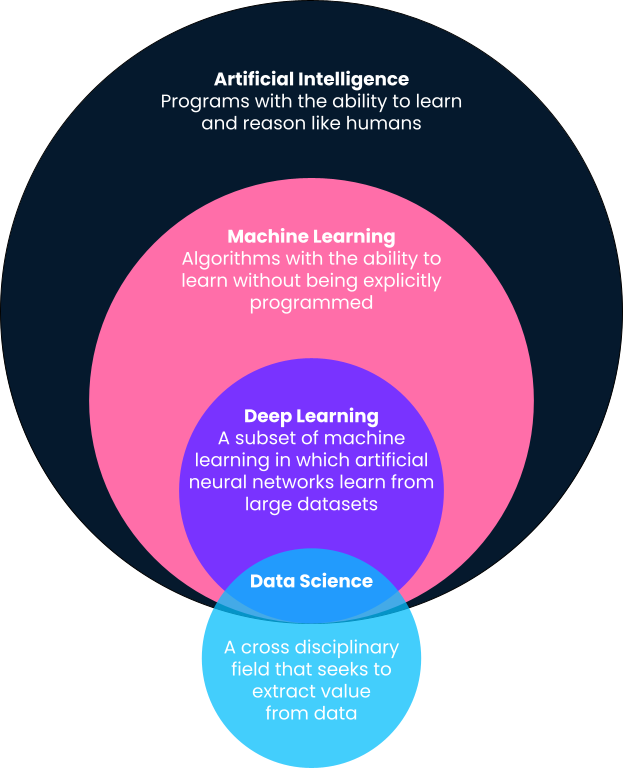
Kort gezegd is machine learning een subveld van kunstmatige intelligentie waarin computers voorspellingen doen op basis van patronen die ze rechtstreeks uit data leren, zonder daar expliciet voor te zijn geprogrammeerd. Je ziet in deze definitie dat machine learning een subveld is van kunstmatige intelligentie. Laten we de definities daarom verder uitsplitsen, want termen als machine learning, kunstmatige intelligentie, deep learning en zelfs data science worden vaak door elkaar gebruikt.
Een van de beste definities van kunstmatige intelligentie komt van Andrew Ng, medeoprichter van Google Brain en voormalig Chief Scientist bij Baidu. Volgens Andrew is kunstmatige intelligentie een “enorme set tools om computers zich intelligent te laten gedragen.” Dat kan variëren van expliciet gedefinieerde systemen zoals rekenmachines tot machinelearning-oplossingen zoals spamfilters voor e-mail.
Zoals hierboven beschreven, is machine learning een subveld van kunstmatige intelligentie waarin algoritmen patronen leren uit historische data en op basis van die patronen voorspellingen doen door ze toe te passen op nieuwe data. Traditioneel worden eenvoudige, intelligente systemen zoals rekenmachines expliciet geprogrammeerd door ontwikkelaars als duidelijk gedefinieerde stappen en procedures (if this, then that). Voor geavanceerdere problemen is dat echter niet schaalbaar of haalbaar.
Neem het voorbeeld van spamfilters voor e-mail. Ontwikkelaars kunnen proberen spamfilters expliciet te definiëren. Zo kunnen ze een programma maken dat een spamfilter activeert als een e-mail een bepaald onderwerp heeft of bepaalde links bevat. Maar dit systeem blijkt ineffectief zodra spammers van tactiek veranderen.
Een machinelearning-oplossing daarentegen neemt miljoenen spammails als invoerdata, leert via statistische associatie de meest voorkomende kenmerken van spamachtige e-mails, en doet vervolgens voorspellingen voor toekomstige e-mails op basis van die geleerde kenmerken.
Deep learning is een subveld van machine learning en is waarschijnlijk verantwoordelijk voor de meest zichtbare machinelearning-use-cases in de populaire cultuur. Deep-learningalgoritmen zijn geïnspireerd op de structuur van het menselijk brein en vereisen enorme hoeveelheden data voor training. Ze worden vaak ingezet voor de meest complexe “cognitieve” problemen, zoals spraakherkenning, taalvertaling, zelfrijdende auto’s en meer. Bekijk onze vergelijking van deep learning vs. machine learning voor meer context.
In tegenstelling tot machine learning, kunstmatige intelligentie en deep learning heeft data science een vrij brede definitie. Kort gezegd draait data science om het halen van waarde en inzichten uit data. Die waarde kan de vorm aannemen van voorspellende modellen die machine learning gebruiken, maar kan ook betekenen dat je inzichten zichtbaar maakt met een dashboard of rapport. Lees meer over de dagelijkse taken van data scientists in dit artikel.
Naast spamdetectie voor e-mail zijn enkele veelvoorkomende machinelearning-toepassingen: klantsegmentatie op basis van demografische data (sales en marketing), voorspelling van aandelenkoersen (financiën), automatische afhandeling van schades (verzekeringen), contentaanbevelingen op basis van kijkgeschiedenis (media & entertainment), en nog veel meer. Machine learning is alomtegenwoordig geworden en kent uiteenlopende toepassingen in ons dagelijks leven.
Aan het einde van dit artikel delen we veel bronnen om je op weg te helpen met machine learning.
Nu we een overzicht hebben gegeven van machine learning en hoe het zich verhoudt tot andere buzzwords die je in dit domein kunt tegenkomen, kijken we dieper naar de verschillende soorten machinelearning-algoritmen. Machinelearning-algoritmen worden grofweg ingedeeld in supervised, unsupervised, reinforcement en self-supervised learning. Laten we ze in meer detail bekijken en hun meest voorkomende use-cases bespreken.
De meeste machinelearning-use-cases draaien om algoritmen die patronen leren uit historische data en die toepassen op nieuwe data in de vorm van voorspellingen. Dit wordt vaak supervised learning genoemd. Supervised-learningalgoritmen krijgen zowel historische inputs als outputs te zien voor een specifiek probleem dat we willen oplossen, waarbij inputs in wezen features of dimensies zijn van de observatie die we willen voorspellen, en outputs de uitkomsten zijn die we willen voorspellen. Laten we dit illustreren met ons spamdetectievoorbeeld.
In de spamdetectie-use-case wordt een supervised-learningalgoritme getraind op een dataset met spamachtige e-mails. De inputs zijn features of dimensies van de e-mails, zoals de onderwerpregel, het e-mailadres van de afzender, de inhoud van de e-mail, of de e-mail gevaarlijk ogende links bevatte, en andere relevante informatie die aanwijzingen kan geven of een e-mail spamachtig is.
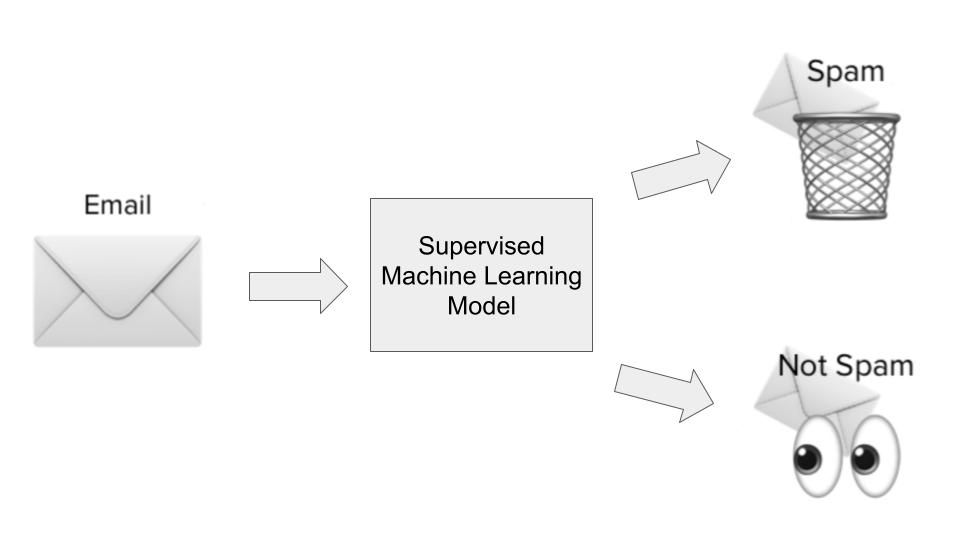
De output is of die e-mail inderdaad spam was of niet. Tijdens de leercyclus van het model leert het algoritme een functie die de statistische relatie in kaart brengt tussen de set inputvariabelen (de verschillende dimensies van spamachtige e-mail) en de outputvariabele (of het spam was of niet). Deze functionele mapping wordt vervolgens gebruikt om de output van niet eerder geziene data te voorspellen.
Er zijn grofweg twee soorten supervised-learning-use-cases:
In een volgende sectie bekijken we specifieke supervised-learningalgoritmen en enkele van hun use-cases in meer detail.
In plaats van patronen te leren die inputs aan outputs koppelen, ontdekken unsupervised-learningalgoritmen algemene patronen in data zonder dat outputs expliciet worden getoond. Unsupervised-learningalgoritmen worden vaak gebruikt om verschillende objecten en entiteiten te groeperen en clusteren. Een goed voorbeeld van unsupervised learning is klantsegmentatie. Bedrijven bedienen vaak verschillende klantpersona’s. Organisaties willen vaak een fact-based aanpak om hun klantsegmenten te identificeren, zodat ze die beter kunnen bedienen. Daar komt unsupervised learning om de hoek kijken.
In deze use-case leert een unsupervised-learningalgoritme klanten te groeperen op basis van verschillende kenmerken, zoals hoe vaak ze een product hebben gebruikt, hun demografie, hoe ze met producten omgaan, en meer. Vervolgens kan hetzelfde algoritme voorspellen tot welk segment nieuwe klanten waarschijnlijk behoren op basis van dezelfde dimensies.
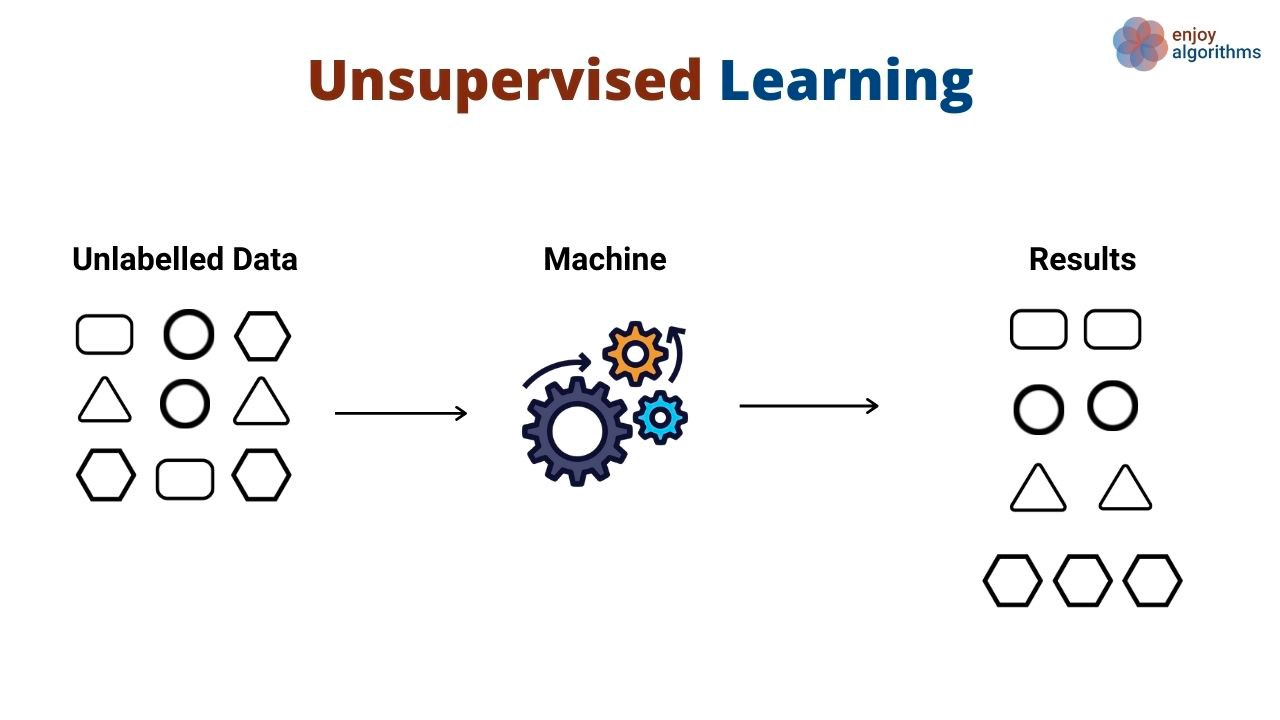
Unsupervised-algoritmen worden ook gebruikt om het aantal dimensies in een dataset te verminderen (dus het aantal features) met technieken voor dimensionaliteitsreductie. Deze algoritmen worden vaak gebruikt als tussenstap bij het trainen van een supervised-learningalgoritme.
Een grote afweging waar data scientists vaak voor staan bij het trainen van machinelearning-algoritmen is performance versus voorspellende nauwkeurigheid. Over het algemeen geldt: hoe meer informatie ze hebben over een bepaald probleem, hoe beter. Maar dat kan ook leiden tot trage trainingstijden en mindere performance. Technieken voor dimensionaliteitsreductie helpen het aantal features in een dataset te verminderen zonder voorspellende waarde op te offeren.
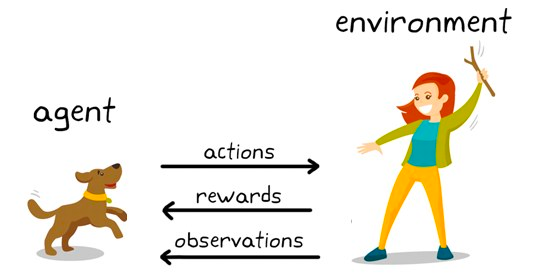
Reinforcement learning is een subset van machinelearning-algoritmen die beloningen gebruiken om gewenst gedrag of gewenste voorspellingen te stimuleren en anders een straf. Hoewel het relatief nog een onderzoeksgebied binnen machine learning is, is reinforcement learning verantwoordelijk voor algoritmen die de menselijke intelligentie overtreffen in spellen zoals schaken, Go en meer.
Het is een techniek voor gedragsmodellering waarbij het model leert via trial-and-error terwijl het blijft interacteren met de omgeving. Laten we dat illustreren met het schaakvoorbeeld. Op hoofdlijnen krijgt een reinforcement-learningalgoritme (vaak agent genoemd) een omgeving (schaakbord) waarin het verschillende beslissingen kan nemen (zetten spelen).
Elke zet heeft een set bijbehorende scores: een beloning voor acties die de agent naar winst leiden, en een straf voor zetten die tot verlies leiden.
De agent blijft met de omgeving interacteren om de acties te leren die de meeste beloningen opleveren en blijft die acties herhalen. Deze herhaling van gestimuleerd gedrag heet de exploitatie-fase. Wanneer de agent zoekt naar nieuwe manieren om beloningen te verdienen, heet dit de exploratie-fase. Algemeen wordt dit het exploratie-exploitatieparadigma genoemd.
Self-supervised learning is een data-efficiënte machinelearningtechniek waarbij het model leert van een ongelabelde steekproefdataset. Zoals in het onderstaande voorbeeld te zien is, krijgt het eerste model ongelabelde invoerafbeeldingen, die het clustert met behulp van features die uit deze afbeeldingen zijn gegenereerd.
Sommige van deze voorbeelden zullen met hoge zekerheid tot de clusters behoren, terwijl dat voor andere niet zo is. De tweede stap gebruikt de met hoge zekerheid gelabelde data uit de eerste stap om een classifier te trainen die vaak krachtiger is dan een eenstaps-clusteringaanpak.
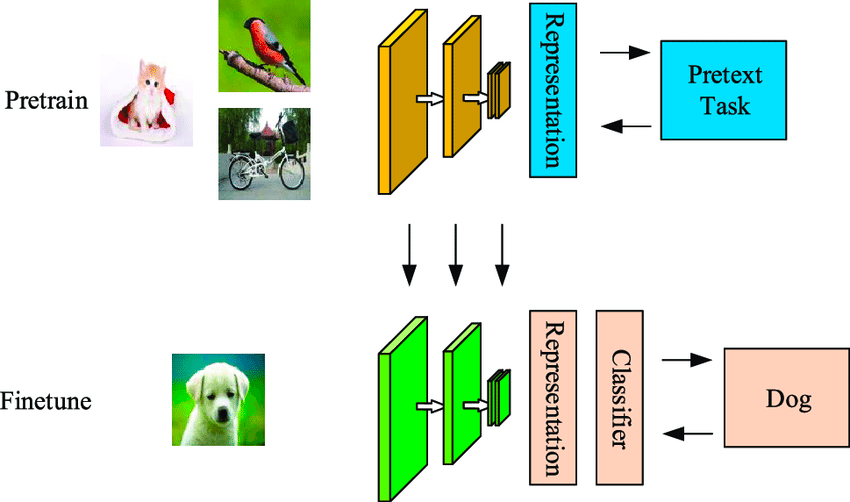
Het verschil tussen self-supervised en supervised algoritmen is dat de geclassificeerde output in het eerste geval nog steeds geen klassen heeft die aan echte objecten zijn gekoppeld. Het verschilt van supervised learning doordat het niet afhankelijk is van handmatig gelabelde sets en zelf labels genereert — vandaar de naam self-learning.
Hieronder zetten we enkele van de top machinelearning-algoritmen en hun meest voorkomende use-cases op een rij.
Een eenvoudig algoritme dat een lineaire relatie modelleert tussen een of meer verklarende variabelen en een continue numerieke outputvariabele. Het is sneller te trainen dan veel andere machinelearning-algoritmen. Het grootste voordeel zit in het kunnen verklaren en interpreteren van de modelvoorspellingen. Het is een regressie-algoritme dat wordt gebruikt om uitkomsten te voorspellen zoals customer lifetime value, huizenprijzen en aandelenkoersen.
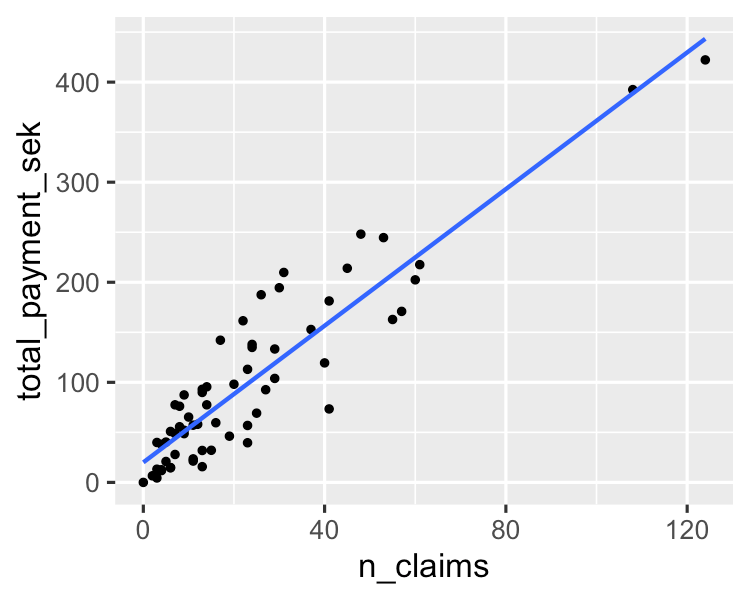
Je kunt er meer over leren in deze tutorial over de basis van lineaire regressie in Python. Als je praktisch aan de slag wilt met regressieanalyse, is deze zeer populaire cursus op DataCamp de juiste bron voor jou.
Een decision-tree-algoritme is een boomachtige structuur van beslisregels die worden toegepast op de inputfeatures om mogelijke uitkomsten te voorspellen. Het kan worden gebruikt voor classificatie of regressie. Voorspellingen van beslissingsbomen zijn een goed hulpmiddel voor zorgexperts, omdat het eenvoudig te interpreteren is hoe die voorspellingen tot stand komen.
Raadpleeg deze tutorial als je wilt leren hoe je een decision-tree-classifier bouwt met Python. Ben je meer thuis in R, dan heb je baat bij deze tutorial. Er is ook een uitgebreide cursus over beslissingsbomen op DataCamp.
Dit is waarschijnlijk een van de populairste algoritmen en bouwt voort op het nadeel van overfitting dat prominent voorkomt bij decision-treemodellen. Overfitting treedt op wanneer algoritmen net iets te goed worden getraind op de trainingsdata en ze niet in staat zijn te generaliseren of nauwkeurige voorspellingen te doen op ongeziene data. Random forest lost het probleem van overfitting op door meerdere beslissingsbomen te bouwen op willekeurig geselecteerde steekproeven uit de data. De uiteindelijke uitkomst in de vorm van de beste voorspelling wordt afgeleid uit de meerderheid van de stemmen van alle bomen in het forest.
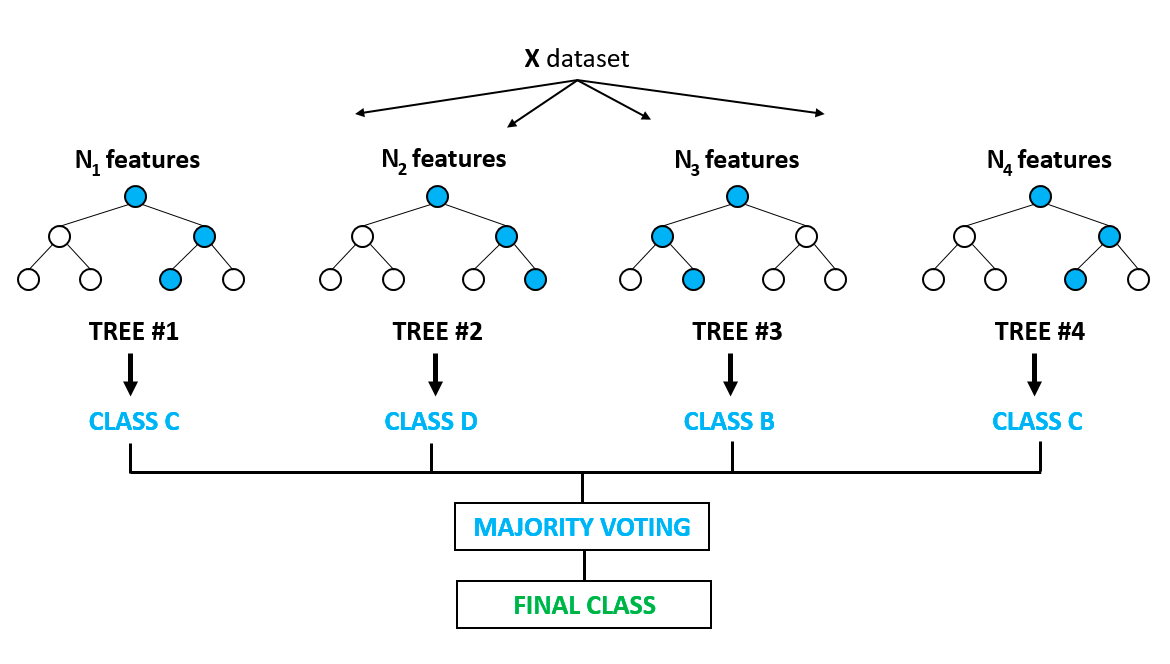
Het wordt gebruikt voor zowel classificatie- als regressieproblemen. Het vindt toepassing in featureselectie, ziekte-detectie, enzovoort. Je kunt meer leren over boomgebaseerde modellen en ensembles (het combineren van verschillende individuele modellen) in deze zeer populaire cursus op DataCamp. Je kunt ook meer leren in deze Python-tutorial over het implementeren van het random-forestmodel.
Support Vector Machines, meestal SVM genoemd, worden doorgaans gebruikt voor classificatieproblemen. Zoals in het onderstaande voorbeeld te zien is, vindt een SVM een hypervlak (hier een lijn) dat de twee klassen (rood en groen) scheidt en de marge (afstand tussen de gestippelde lijnen) ertussen maximaliseert.
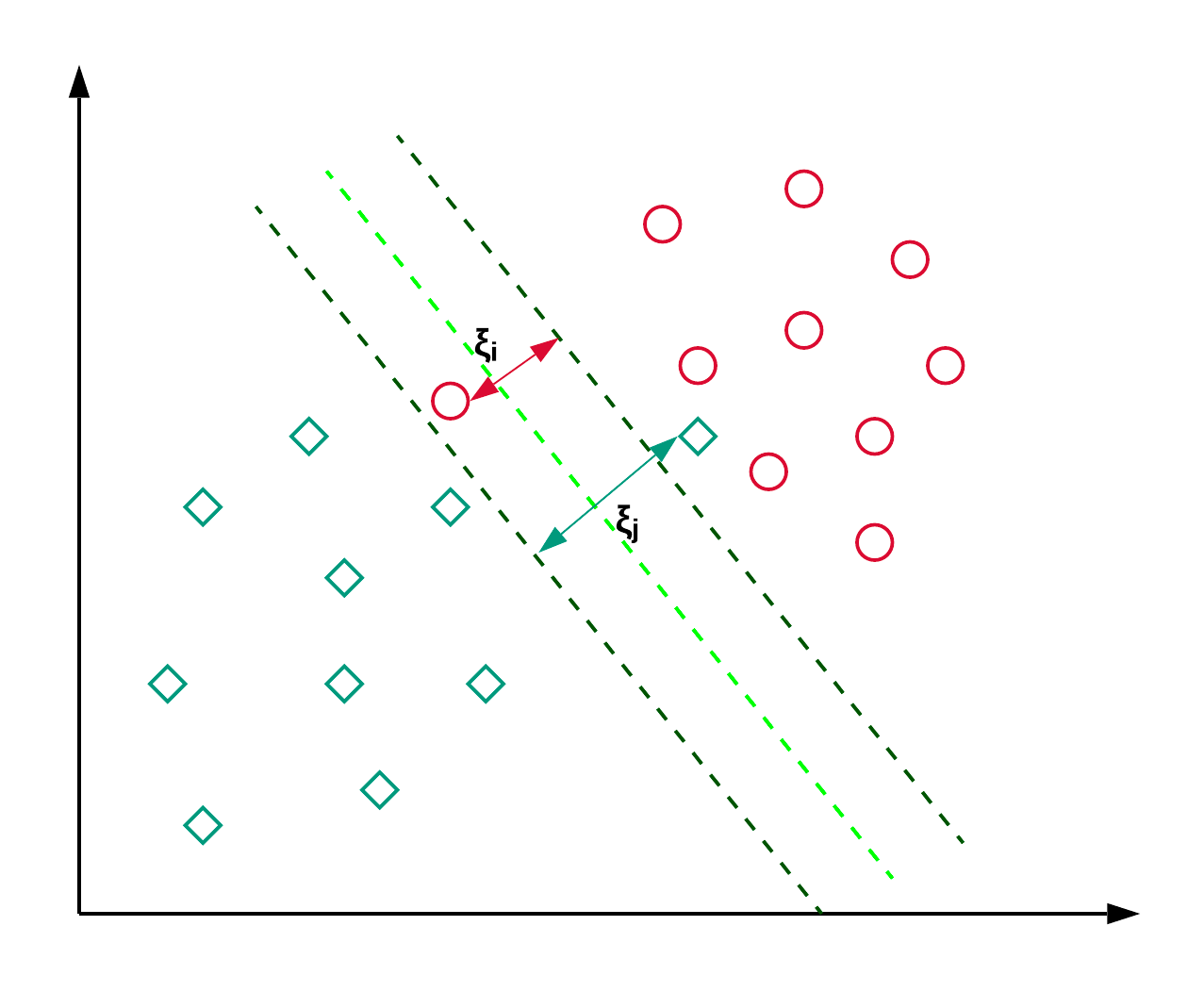
SVM wordt doorgaans gebruikt voor classificatieproblemen, maar kan ook worden ingezet bij regressieproblemen. Het wordt gebruikt om nieuwsartikelen te classificeren en voor handschriftherkenning. Je kunt meer lezen over de verschillende soorten kernel-tricks en de Python-implementatie in deze scikit-learn SVM-tutorial. Je kunt ook deze tutorial volgen, waar je de SVM-implementatie in R nabouwt
Gradient Boosting Regression is een ensemblemodel dat meerdere zwakke learners combineert om een robuust voorspellend model te maken. Het is goed in het omgaan met non-lineariteiten in de data en problemen met multicollineariteit.
Als je in de ride-sharingbranche zit en de ritprijs wilt voorspellen, kun je een gradient boosting regressor gebruiken. Wil je de verschillende varianten van gradient boosting begrijpen, bekijk dan deze video op DataCamp.
K-means is de meest gebruikte clusteringaanpak — het bepaalt K clusters op basis van de Euclidische afstand. Het is een zeer populair algoritme voor klantsegmentatie en aanbevelingssystemen.
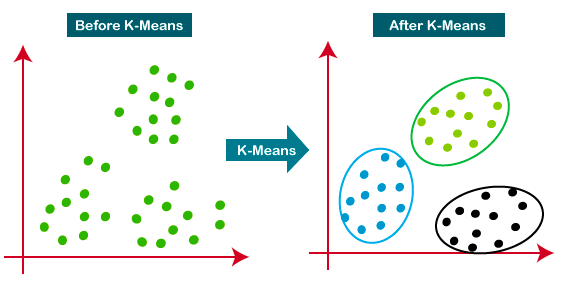
Deze tutorial is een geweldige bron om meer te leren over K-means clustering.
Principal component analysis (PCA) is een statistische procedure die wordt gebruikt om informatie uit een grote dataset samen te vatten door deze te projecteren naar een subruimte met lagere dimensie. Het is ook een techniek voor dimensionaliteitsreductie die ervoor zorgt dat de essentiële delen van de data met veel informatie behouden blijven.
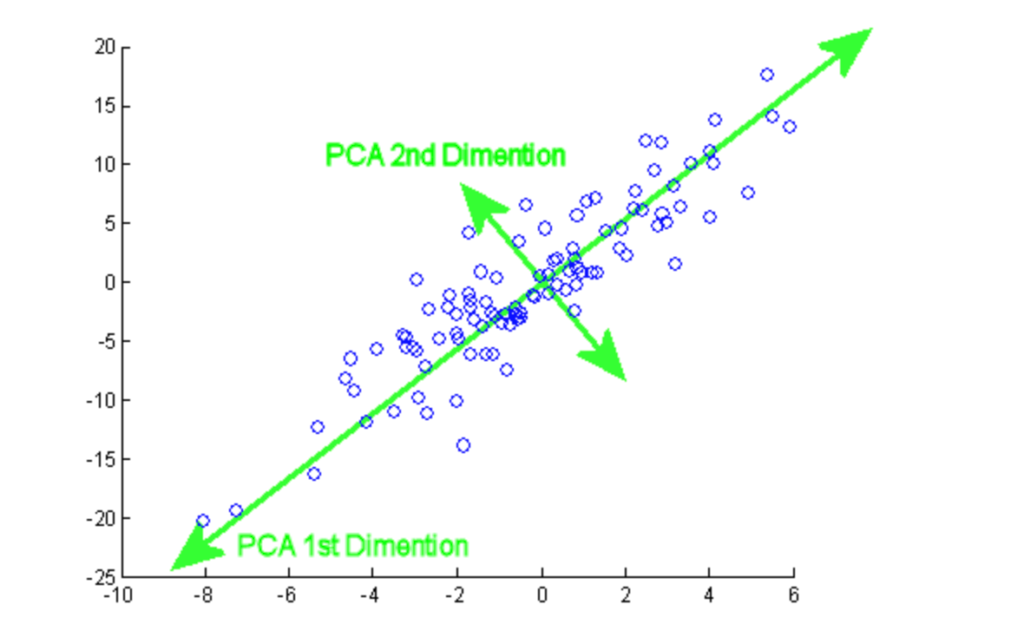
In deze tutorial kun je hands-on PCA implementeren op twee populaire datasets: Breast Cancer en CIFAR-10.
Dit is een bottom-upbenadering waarbij elk datapunt als eigen cluster wordt beschouwd, waarna de dichtstbijzijnde twee clusters iteratief worden samengevoegd. Het grootste voordeel ten opzichte van K-means clustering is dat de gebruiker niet vooraf het verwachte aantal clusters hoeft op te geven. Het vindt toepassing in documentclustering op basis van gelijkenis.
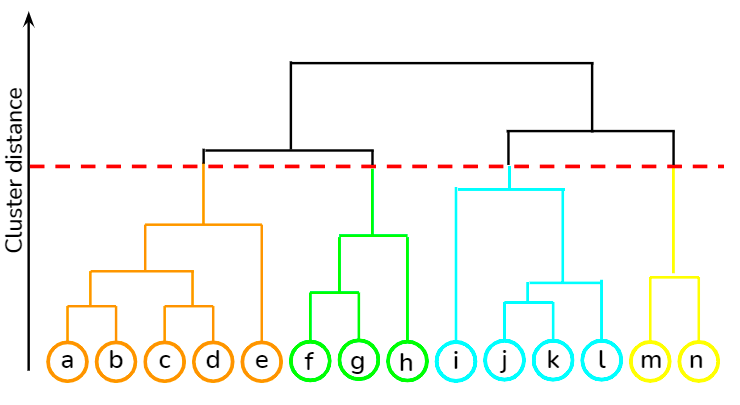
Je kunt verschillende unsupervised-learningtechnieken, zoals hiërarchisch clusteren en K-means clusteren, leren met de scipy-bibliotheek in deze cursus op DataCamp. Daarnaast leer je in deze cursus hoe je clusteringtechnieken toepast om inzichten te genereren uit ongelabelde data met R.
Dit is een probabilistisch model voor het modelleren van normaal verdeelde clusters binnen een dataset. Het verschilt van standaard clusteringalgoritmen doordat het de kans schat dat een observatie tot een bepaald cluster behoort en vervolgens inferenties doet over de subpopulatie.
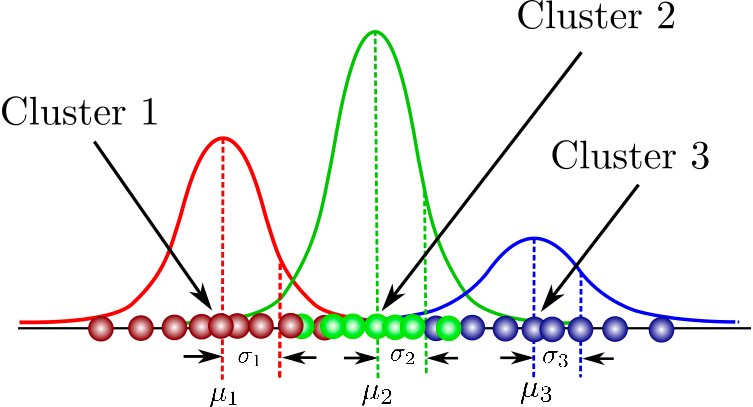
Je vindt hier een complete verzameling cursussen die fundamentele concepten in modelgebaseerd clusteren, de structuur van Mixture Models en meer behandelen. Je gaat ook hands-on aan de slag met gaussiaanse mengmodellen met het flexmix-pakket.
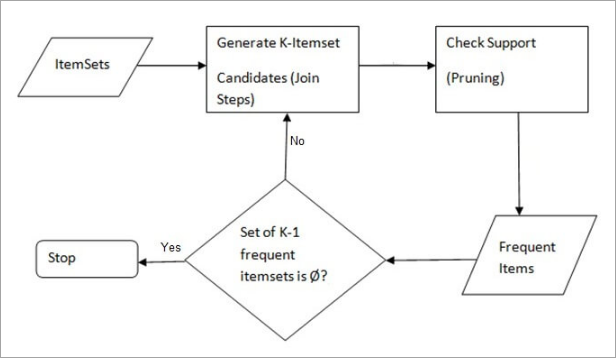
Een regelgebaseerde aanpak die de meest frequente itemsets in een gegeven dataset identificeert, waarbij voorafgaande kennis van eigenschappen van frequente itemsets wordt gebruikt. Marktmandanalyse gebruikt dit algoritme om giganten als Amazon en Netflix te helpen de bergen aan informatie over hun gebruikers te vertalen naar eenvoudige regels voor productaanbevelingen. Het analyseert de associaties tussen miljoenen producten en ontdekt waardevolle regels.
DataCamp biedt een uitgebreide cursus in beide talen — Python en R.
Machine learning is allang niet meer alleen een buzzword. Veel organisaties zetten machinelearningmodellen in en realiseren al winst door voorspellende inzichten. Er is dan ook veel vraag naar hooggekwalificeerde machinelearning-specialisten. Hieronder vind je een lijst met bronnen die je snel op weg helpen om je machinelearning-kennis bij te spijkeren:
Aan de slag met machine learning
Cursus
Cursus
blog
Adel Nehme
15 min
