Corso
Machine Learning con modelli ad alberi in Python
5 h
117.2K
Il machine learning è probabilmente alla base dei casi d’uso più importanti e visibili della data science e dell’intelligenza artificiale. Dalle auto a guida autonoma di Tesla all’algoritmo AlphaFold di DeepMind, le soluzioni basate sul machine learning hanno prodotto risultati sorprendenti e generato molto clamore. Ma che cos’è esattamente il machine learning? Come funziona? E, soprattutto, merita davvero tutto questo interesse? Questo articolo fornisce una definizione intuitiva dei principali algoritmi di machine learning, ne illustra alcune applicazioni chiave e offre risorse per iniziare con il machine learning.
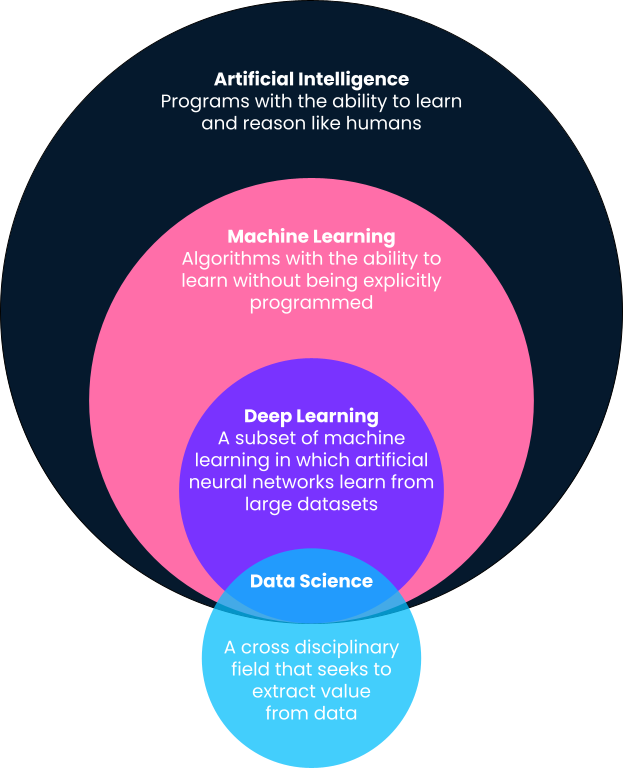
In poche parole, il machine learning è un sottoinsieme dell’intelligenza artificiale in cui i computer forniscono previsioni basate su schemi appresi direttamente dai dati, senza essere programmati in modo esplicito per farlo. Noterai in questa definizione che il machine learning è un sottoinsieme dell’intelligenza artificiale. Perciò, scomponiamo meglio le definizioni, dato che spesso termini come machine learning, intelligenza artificiale, deep learning e persino data science vengono usati in modo intercambiabile.
Una delle migliori definizioni di intelligenza artificiale viene da Andrew Ng, cofondatore di Google Brain ed ex Chief Scientist di Baidu. Secondo Andrew, l’intelligenza artificiale è un “insieme vastissimo di strumenti per far sì che i computer si comportino in modo intelligente”. Questo può includere qualsiasi cosa, dai sistemi definiti in modo esplicito come le calcolatrici, alle soluzioni basate sul machine learning come i rilevatori di email spam.
Come descritto sopra, il machine learning è un sottoinsieme dell’intelligenza artificiale in cui gli algoritmi apprendono schemi dai dati storici e forniscono previsioni basate su questi schemi appresi applicandoli a nuovi dati. Tradizionalmente, i sistemi intelligenti semplici come le calcolatrici sono programmati in modo esplicito dagli sviluppatori come passaggi e procedure chiaramente definiti (cioè, se questo, allora quello). Tuttavia, questo non è scalabile o possibile per problemi più complessi.
Prendiamo l’esempio dei filtri antispam per email. Gli sviluppatori possono provare a creare filtri antispam definendoli in modo esplicito. Ad esempio, possono definire un programma che attivi un filtro antispam se un’email ha un certo oggetto o contiene certi link. Tuttavia, questo sistema si rivelerà inefficace non appena gli spammer cambiano tattica.
Invece, una soluzione basata sul machine learning prenderà in input milioni di email spam, imparerà le caratteristiche più comuni delle email sospette tramite associazioni statistiche e formulerà previsioni sulle email future sulla base delle caratteristiche apprese.
Il deep learning è un sottoinsieme del machine learning ed è probabilmente responsabile dei casi d’uso più visibili nella cultura pop. Gli algoritmi di deep learning si ispirano alla struttura del cervello umano e richiedono enormi quantità di dati per l’addestramento. Sono spesso usati per i problemi “cognitivi” più complessi, come il riconoscimento vocale, la traduzione linguistica, le auto a guida autonoma e altro ancora. Dai un’occhiata al nostro confronto tra deep learning e machine learning per maggior contesto.
A differenza di machine learning, intelligenza artificiale e deep learning, la data science ha una definizione piuttosto ampia. In sintesi, la data science riguarda l’estrazione di valore e insight dai dati. Quel valore può assumere la forma di modelli predittivi che utilizzano il machine learning, ma può anche significare mettere in evidenza insight con una dashboard o un report. Leggi di più sulle attività quotidiane dei data scientist in questo articolo.
Oltre al rilevamento dello spam nelle email, alcune applicazioni comuni del machine learning includono la segmentazione dei clienti in base ai dati demografici (vendite e marketing), la previsione dei prezzi azionari (finanza), l’automazione dell’approvazione dei sinistri (assicurazioni), i consigli sui contenuti basati sulla cronologia di visualizzazione (media e intrattenimento) e molto altro. Il machine learning è ormai ubiquo e trova applicazioni diverse nella nostra vita quotidiana.
Alla fine di questo articolo condivideremo molte risorse per iniziare con il machine learning.
Ora che abbiamo fornito una panoramica del machine learning e di come si colloca rispetto ad altri termini che potresti incontrare in questo ambito, diamo uno sguardo più approfondito ai diversi tipi di algoritmi di machine learning. Gli algoritmi di machine learning sono ampiamente categorizzati in apprendimento supervisionato, non supervisionato, per rinforzo e auto-supervisionato. Vediamoli nel dettaglio insieme ai loro casi d’uso più comuni.
La maggior parte dei casi d’uso del machine learning ruota attorno ad algoritmi che apprendono schemi dai dati storici e li applicano a nuovi dati sotto forma di previsioni. Questo è spesso chiamato apprendimento supervisionato. Agli algoritmi supervisionati vengono mostrati sia gli input sia gli output storici su un particolare problema che stiamo cercando di risolvere, dove gli input sono in sostanza le caratteristiche o dimensioni dell’osservazione che vogliamo predire, e gli output sono gli esiti che vogliamo predire. Illustriamo il tutto con il nostro esempio del rilevamento dello spam.
Nel caso d’uso del rilevamento spam, un algoritmo supervisionato verrebbe addestrato su un dataset di email sospette. Gli input sarebbero caratteristiche o dimensioni relative alle email, come l’oggetto, l’indirizzo email del mittente, il contenuto dell’email, la presenza di link dall’aspetto pericoloso e altre informazioni rilevanti che possano fornire indizi sul fatto che un’email sia spam.
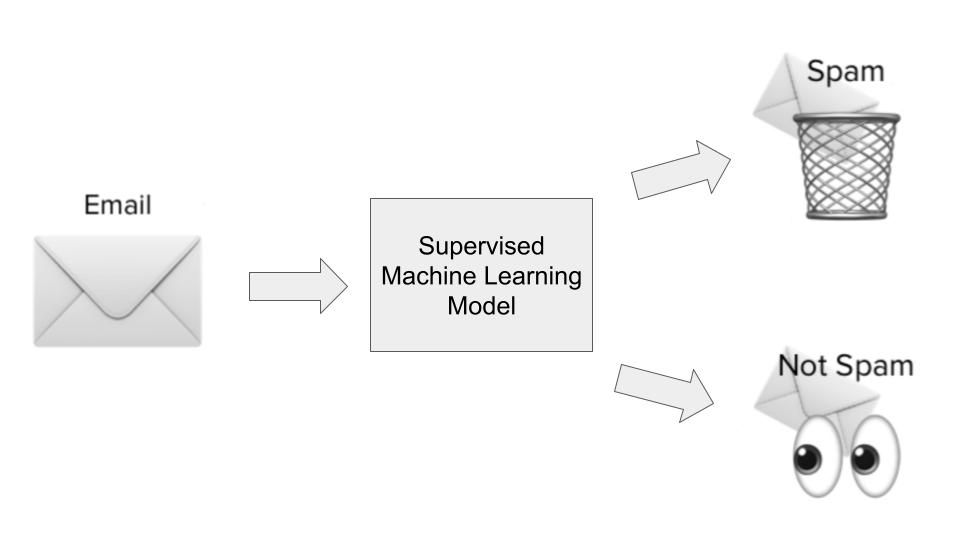
L’output sarebbe se quell’email fosse effettivamente spam oppure no. Durante la fase di apprendimento del modello, l’algoritmo impara una funzione che mappa la relazione statistica tra l’insieme delle variabili in input (le diverse dimensioni di un’email sospetta) e la variabile in output (se era spam o no). Questa mappatura funzionale viene poi usata per predire l’output di dati mai visti prima.
Esistono due grandi tipi di casi d’uso nell’apprendimento supervisionato:
In una sezione successiva, esamineremo nel dettaglio alcuni specifici algoritmi supervisionati e i loro casi d’uso.
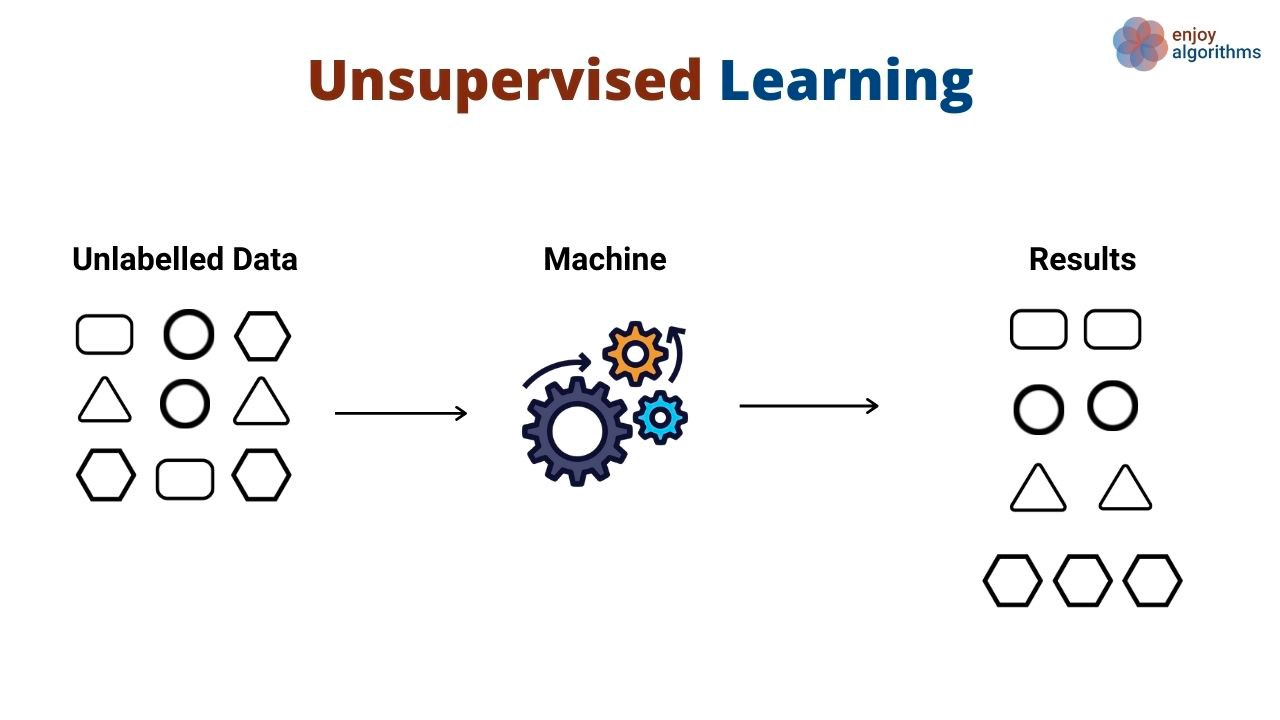
Invece di apprendere schemi che mappano input a output, gli algoritmi non supervisionati scoprono schemi generali nei dati senza che vengano mostrati output in modo esplicito. Sono comunemente usati per raggruppare e clusterizzare diversi oggetti ed entità. Un ottimo esempio di apprendimento non supervisionato è la segmentazione dei clienti. Le aziende spesso servono una varietà di personas di clienti. Le organizzazioni vogliono spesso adottare un approccio basato sui dati per identificare i propri segmenti di clientela e servirli meglio. Entra in gioco l’apprendimento non supervisionato.
In questo caso d’uso, un algoritmo non supervisionato raggrupperebbe i clienti in base a varie caratteristiche, come il numero di volte in cui hanno usato un prodotto, i loro dati demografici, come interagiscono con i prodotti e altro ancora. Poi, lo stesso algoritmo può prevedere a quale segmento è probabile che appartengano i nuovi clienti sulla base delle stesse dimensioni.
Gli algoritmi non supervisionati vengono anche usati per ridurre le dimensioni in un dataset (cioè il numero di variabili) tramite tecniche di riduzione della dimensionalità. Questi algoritmi sono spesso usati come passaggio intermedio nell’addestramento di un algoritmo supervisionato.
Un grande compromesso con cui i data scientist si confrontano spesso quando addestrano algoritmi di machine learning è prestazioni vs. accuratezza predittiva. In generale, più informazioni hanno su un determinato problema, meglio è. Tuttavia, ciò può portare anche a tempi di addestramento lenti e a problemi di performance. Le tecniche di riduzione della dimensionalità aiutano a ridurre il numero di caratteristiche presenti in un dataset senza sacrificare il valore predittivo.
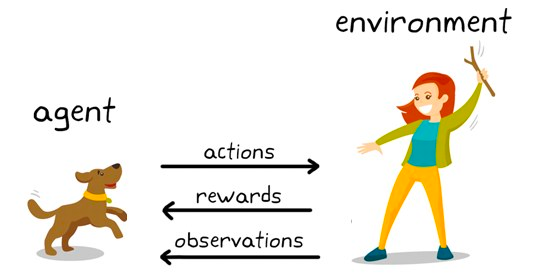
Il reinforcement learning è un sottoinsieme di algoritmi di machine learning che utilizza ricompense per promuovere un comportamento o una previsione desiderati e penalità in caso contrario. Sebbene sia ancora relativamente un’area di ricerca all’interno del machine learning, il reinforcement learning è responsabile di algoritmi che superano l’intelligenza umana in giochi come gli scacchi, il Go e altri.
È una tecnica di modellazione comportamentale in cui il modello apprende attraverso un meccanismo di prova ed errore mentre continua a interagire con l’ambiente. Illustriamolo con l’esempio degli scacchi. A un livello alto, a un algoritmo di reinforcement learning (spesso chiamato agente) viene fornito un ambiente (la scacchiera) in cui può prendere varie decisioni (giocare mosse).
Ogni mossa ha un insieme di punteggi associati, una ricompensa per le azioni che portano l’agente a vincere e una penalità per le mosse che portano a perdere.
L’agente continua a interagire con l’ambiente per imparare le azioni che fruttano le maggiori ricompense e continua a ripetere tali azioni. Questa ripetizione del comportamento promosso è chiamata fase di sfruttamento. Quando l’agente cerca nuove strade per ottenere ricompense, si parla di fase di esplorazione. Più in generale, questo è noto come paradigma esplorazione–sfruttamento.
L’apprendimento auto-supervisionato è una tecnica di machine learning data-efficient in cui il modello apprende da un campione di dati non etichettati. Come mostrato nell’esempio seguente, al primo modello vengono fornite alcune immagini di input non etichettate, che vengono raggruppate utilizzando caratteristiche generate da queste immagini.
Alcuni di questi esempi avranno un’alta confidenza di appartenenza ai cluster mentre altri no. Il secondo passaggio utilizza i dati etichettati ad alta confidenza del primo per addestrare un classificatore che tende a essere più potente di un approccio di clustering a uno step.
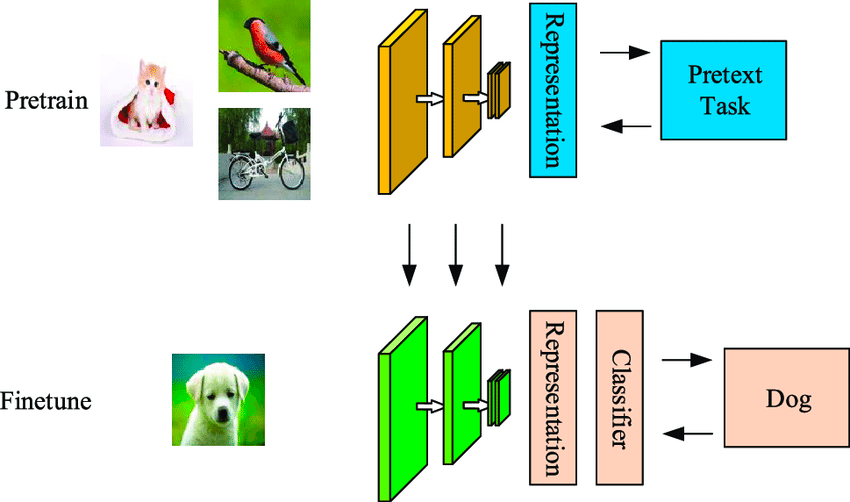
La differenza tra algoritmi auto-supervisionati e supervisionati è che, nei primi, l’output classificato non avrà ancora le classi mappate a oggetti reali. Differisce dall’apprendimento supervisionato perché non dipende da un set etichettato manualmente e genera etichette da sé, da cui il nome auto-apprendimento.
Di seguito abbiamo delineato alcuni dei principali algoritmi di machine learning e i loro casi d’uso più comuni.
Un algoritmo semplice che modella una relazione lineare tra una o più variabili esplicative e una variabile di output numerica continua. È più veloce da addestrare rispetto ad altri algoritmi di machine learning. Il suo maggiore vantaggio risiede nella capacità di spiegare e interpretare le previsioni del modello. È un algoritmo di regressione usato per prevedere risultati come il valore del ciclo di vita del cliente, i prezzi delle case e i prezzi azionari.
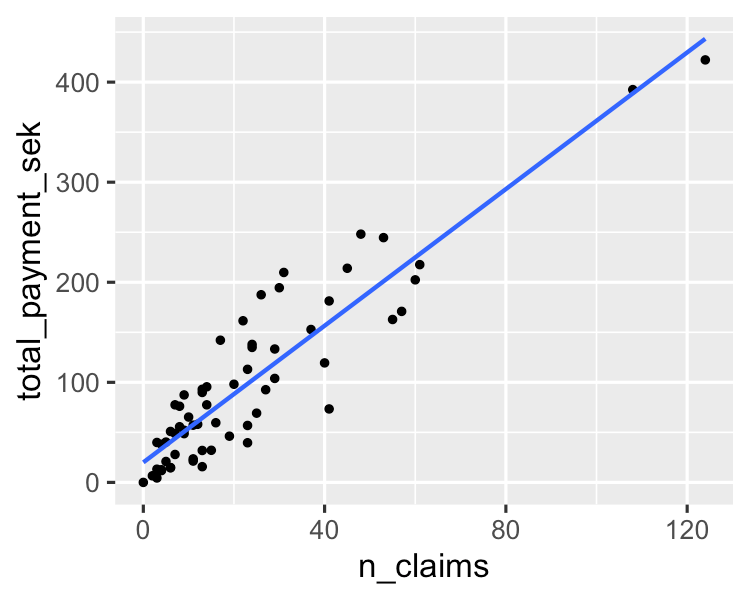
Puoi saperne di più in questo tutorial sugli elementi essenziali della regressione lineare in Python. Se vuoi mettere mano alla regressione, questo corso molto richiesto su DataCamp è la risorsa giusta per te.
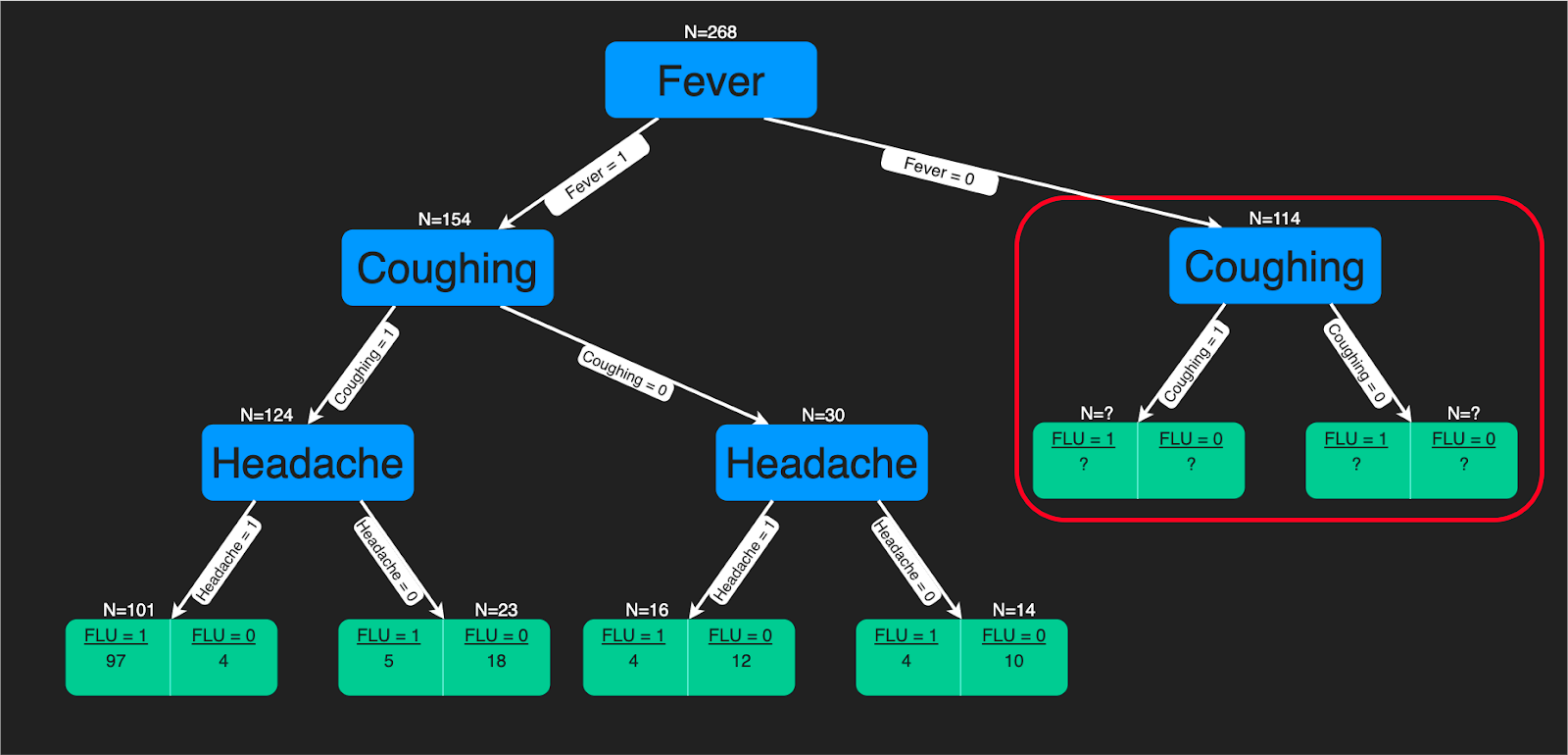
Un algoritmo ad albero decisionale è una struttura ad albero di regole decisionali che vengono applicate alle caratteristiche in input per prevedere i possibili risultati. Può essere usato per classificazione o regressione. Le previsioni degli alberi decisionali sono un valido aiuto per gli esperti in ambito sanitario, perché è semplice interpretare come vengono generate.
Puoi fare riferimento a questo tutorial se vuoi imparare come costruire un classificatore ad albero decisionale usando Python. Inoltre, se ti trovi meglio con R, ti sarà utile questo tutorial. È disponibile anche un completo corso sugli alberi decisionali su DataCamp.
È probabilmente uno degli algoritmi più popolari e supera il problema dell’overfitting, molto evidente nei modelli ad albero decisionale. L’overfitting si verifica quando gli algoritmi sono addestrati fin troppo bene sui dati di training e non riescono a generalizzare o a fornire previsioni accurate su dati mai visti. La random forest risolve il problema dell’overfitting costruendo più alberi decisionali su campioni selezionati casualmente dai dati. Il risultato finale, sotto forma della migliore previsione, è ricavato dal voto di maggioranza di tutti gli alberi nella foresta.
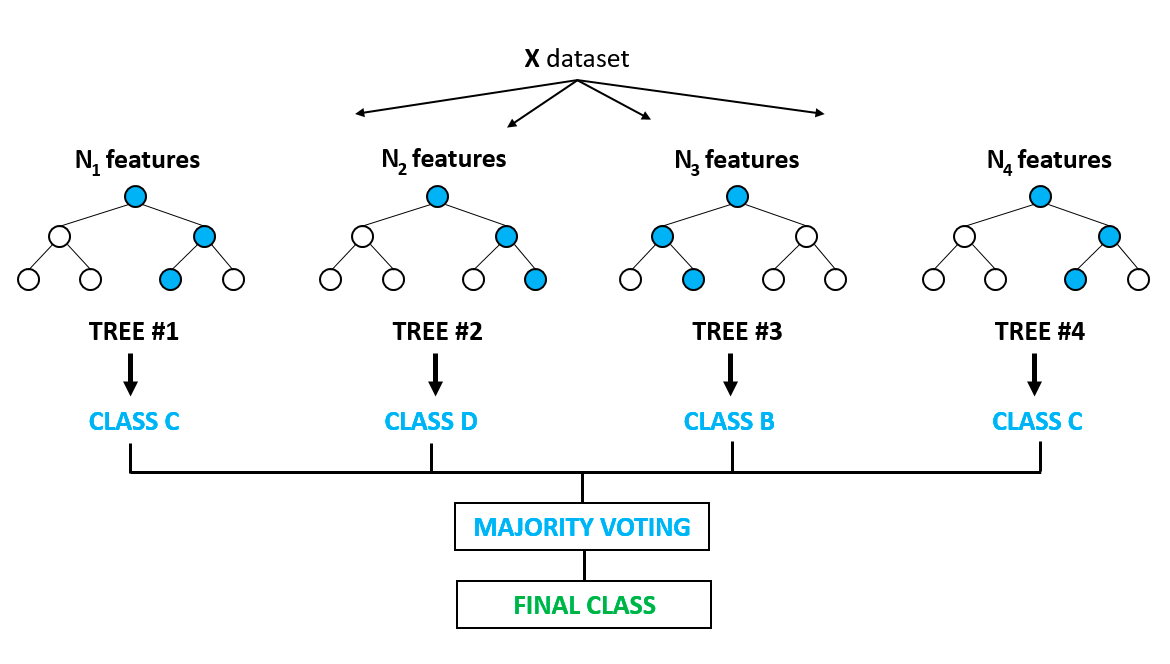
È usata sia per problemi di classificazione sia di regressione. Trova applicazione nella selezione delle variabili, nel rilevamento di malattie, ecc. Puoi approfondire i modelli ad albero e gli ensemble (combinazione di modelli individuali) con questo corso molto popolare su DataCamp. Puoi anche saperne di più in questo tutorial in Python sull’implementazione della random forest.
Le Support Vector Machines, comunemente note come SVM, sono generalmente usate per problemi di classificazione. Come mostrato nell’esempio qui sotto, una SVM trova un iperpiano (in questo caso, una retta) che separa le due classi (rosso e verde) e massimizza il margine (la distanza tra le linee tratteggiate) tra di esse.
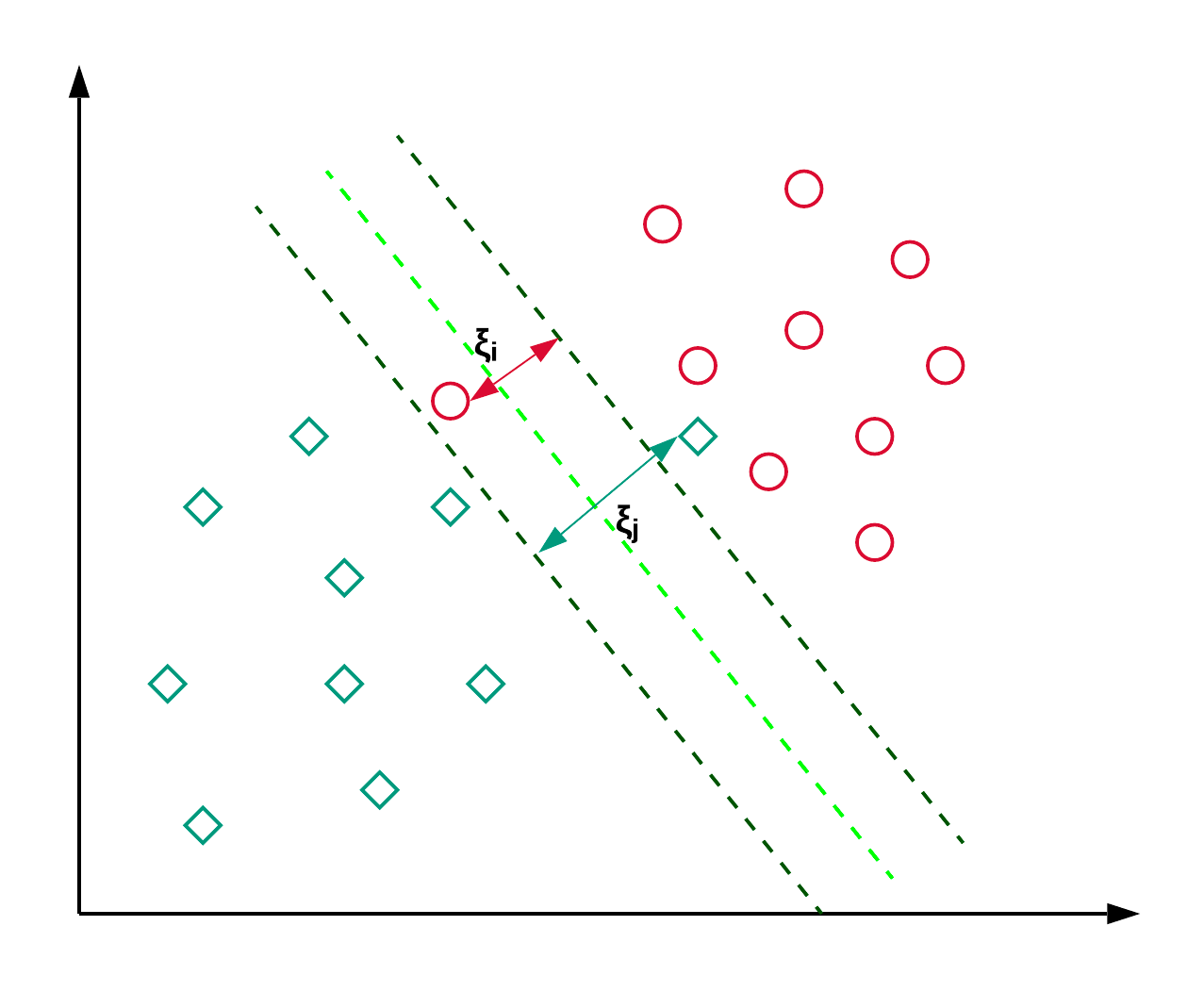
Le SVM sono in genere usate per problemi di classificazione ma possono essere impiegate anche nella regressione. Sono usate per classificare articoli di news e nel riconoscimento della scrittura a mano. Puoi leggere di più sui diversi tipi di kernel trick insieme all’implementazione in Python in questo tutorial su SVM con scikit-learn. Puoi seguire anche questo tutorial, in cui replicherai l’implementazione SVM in R
La Gradient Boosting Regression è un modello ensemble che combina diversi weak learner per creare un modello predittivo solido. Gestisce bene le non linearità nei dati e i problemi di multicollinearità.
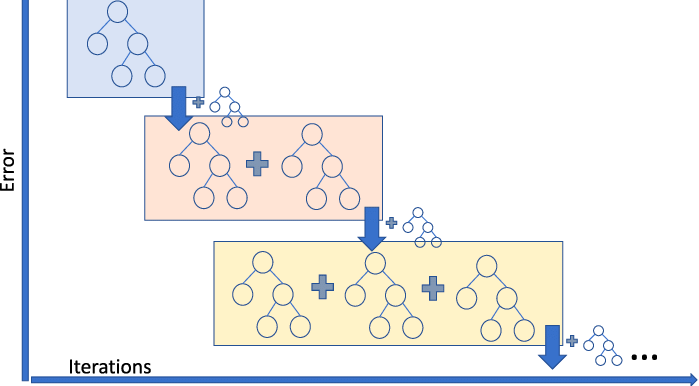
Se lavori in un servizio di ride sharing e devi prevedere l’importo della corsa, puoi usare un gradient boosting regressor. Se vuoi capire le diverse varianti del gradient boosting, puoi guardare questo video su DataCamp.
K-Means è l’approccio di clustering più diffuso — determina K cluster in base alla distanza euclidea. È un algoritmo molto popolare per la segmentazione dei clienti e i sistemi di raccomandazione.
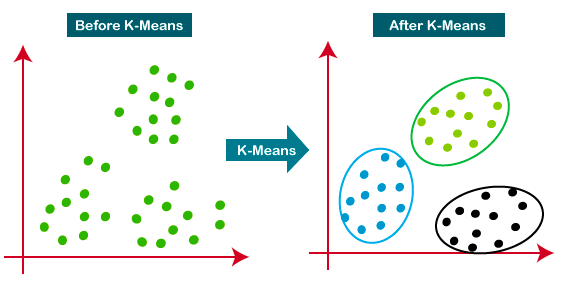
Questo tutorial è un’ottima risorsa per imparare di più sul clustering K-means.
La principal component analysis (PCA) è una procedura statistica usata per riassumere le informazioni di un grande set di dati proiettandolo in uno spazio a dimensionalità inferiore. È anche chiamata tecnica di riduzione della dimensionalità e garantisce il mantenimento delle parti essenziali dei dati con maggiore informazione.
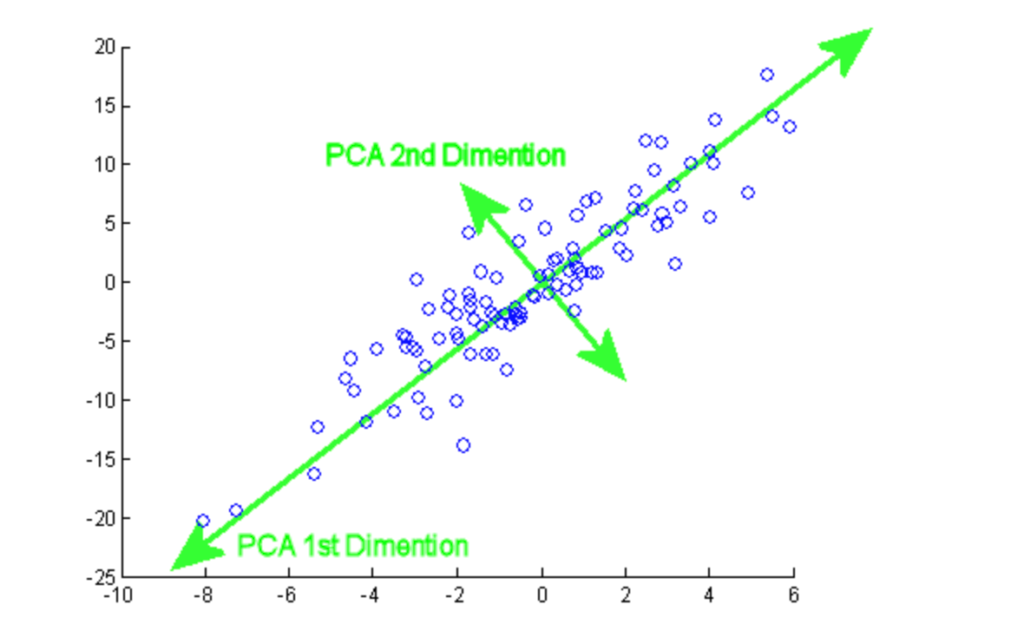
Da questo tutorial puoi praticare l’implementazione pratica della PCA su due dataset popolari, Breast Cancer e CIFAR-10.
È un approccio bottom-up in cui ogni punto dati è trattato come un proprio cluster e poi i due cluster più vicini vengono uniti iterativamente. Il suo maggiore vantaggio rispetto al clustering K-means è che non richiede all’utente di specificare il numero atteso di cluster all’inizio. Trova applicazione nel clustering di documenti in base alla similarità.
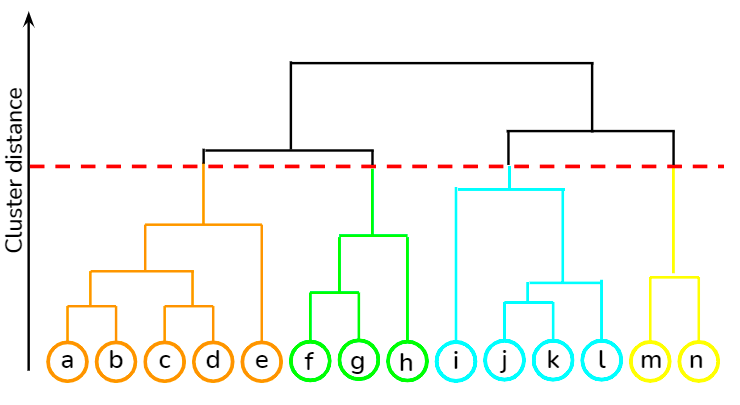
Puoi imparare varie tecniche di apprendimento non supervisionato, come il clustering gerarchico e il K-means, usando la libreria scipy in questo corso su DataCamp. Inoltre, puoi anche imparare ad applicare tecniche di clustering per generare insight da dati non etichettati usando R con questo corso.
È un modello probabilistico per modellare cluster distribuiti normalmente all’interno di un dataset. Differisce dagli algoritmi di clustering standard nel senso che stima la probabilità che un’osservazione appartenga a un particolare cluster e quindi procede a trarre inferenze sulla sua sotto-popolazione.
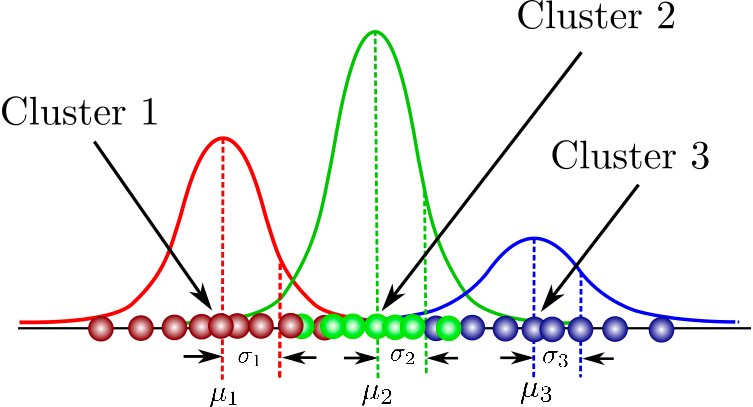
Puoi trovare qui una raccolta completa di corsi che copre i concetti fondamentali del clustering basato su modelli, la struttura dei Mixture Models e oltre. Potrai anche esercitarti con la modellazione a gaussiane miste utilizzando il pacchetto flexmix.
Un approccio basato su regole che identifica i set di item più frequenti in un determinato dataset, in cui si utilizza la conoscenza a priori delle proprietà degli itemset frequenti. La market basket analysis impiega questo algoritmo per aiutare colossi come Amazon e Netflix a tradurre le enormi quantità di informazioni sui loro utenti in semplici regole di raccomandazione dei prodotti. Analizza le associazioni tra milioni di prodotti e scopre regole ricche di insight.
DataCamp offre un corso completo in entrambe le lingue — Python e R.
Il machine learning non è più solo una parola di moda. Molte organizzazioni stanno distribuendo modelli di machine learning e stanno già ottenendo benefici dagli insight predittivi. Inutile dirlo, c’è molta domanda di professionisti del machine learning altamente qualificati. Qui sotto trovi un elenco di risorse che possono aiutarti a iniziare rapidamente a sviluppare competenze di machine learning:
Inizia con il machine learning
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

