Courses
Machine Learning với mô hình dựa trên cây trong Python
5 giờ
117.2K
Machine learning có lẽ là nền tảng của những trường hợp sử dụng nổi bật và dễ thấy nhất trong khoa học dữ liệu và trí tuệ nhân tạo. Từ xe tự lái của Tesla đến thuật toán AlphaFold của DeepMind, các giải pháp dựa trên machine learning đã tạo ra những kết quả ấn tượng và thu hút rất nhiều sự quan tâm. Nhưng chính xác thì machine learning là gì? Nó hoạt động như thế nào? Và quan trọng hơn cả, liệu nó có xứng đáng với sự kỳ vọng? Bài viết này đưa ra định nghĩa trực quan về các thuật toán machine learning chủ chốt, phác thảo một số ứng dụng tiêu biểu của chúng, và cung cấp tài nguyên để bạn bắt đầu với machine learning.
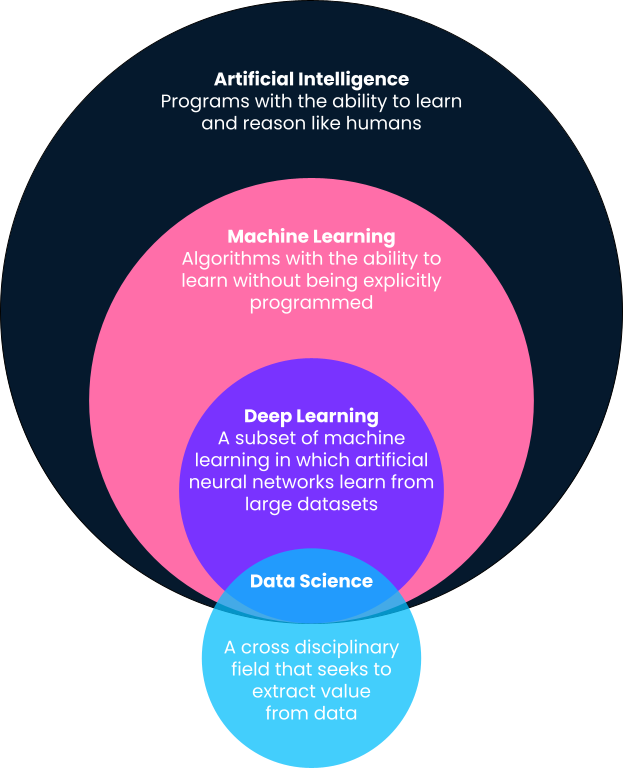
Tóm lại, machine learning là một phân ngành của trí tuệ nhân tạo trong đó máy tính đưa ra dự đoán dựa trên các mẫu học trực tiếp từ dữ liệu mà không cần được lập trình tường minh để làm điều đó. Bạn sẽ nhận thấy trong định nghĩa này rằng machine learning là một phân ngành của trí tuệ nhân tạo. Do vậy, hãy đi sâu hơn vào các định nghĩa, vì nhiều khi các thuật ngữ như machine learning, trí tuệ nhân tạo, deep learning, và thậm chí khoa học dữ liệu thường được dùng thay thế cho nhau.
Một trong những định nghĩa hay nhất về trí tuệ nhân tạo đến từ Andrew Ng, đồng sáng lập Google Brain và cựu Giám đốc Khoa học tại Baidu. Theo Andrew, trí tuệ nhân tạo là một “tập hợp khổng lồ các công cụ giúp máy tính hành xử một cách thông minh.” Điều này có thể bao gồm mọi thứ từ các hệ thống được định nghĩa tường minh như máy tính bỏ túi đến các giải pháp dựa trên machine learning như bộ lọc email rác.
Như đã nêu ở trên, machine learning là một phân ngành của trí tuệ nhân tạo, trong đó các thuật toán học các mẫu từ dữ liệu lịch sử và đưa ra dự đoán dựa trên những mẫu đã học này bằng cách áp dụng chúng lên dữ liệu mới. Truyền thống, các hệ thống thông minh đơn giản như máy tính bỏ túi được lập trình tường minh bởi các nhà phát triển theo các bước và thủ tục rõ ràng (ví dụ: nếu thế này thì làm thế kia). Tuy nhiên, điều này không thể mở rộng hoặc khả thi với các bài toán phức tạp hơn.
Lấy ví dụ bộ lọc email rác. Các nhà phát triển có thể cố gắng tạo bộ lọc rác bằng cách định nghĩa tường minh. Chẳng hạn, họ có thể viết một chương trình kích hoạt bộ lọc rác nếu email có một số dòng tiêu đề nhất định hoặc chứa một số liên kết cụ thể. Tuy nhiên, hệ thống này sẽ trở nên kém hiệu quả ngay khi kẻ gửi thư rác thay đổi chiến thuật.
Ngược lại, một giải pháp dựa trên machine learning sẽ đưa vào hàng triệu email rác làm dữ liệu đầu vào, học các đặc điểm phổ biến nhất của email rác thông qua liên kết thống kê, và dự đoán về các email trong tương lai dựa trên những đặc điểm đã học được.
Deep learning là một phân ngành của machine learning và có lẽ là tác nhân tạo ra những ứng dụng machine learning dễ thấy nhất trong văn hóa đại chúng. Các thuật toán deep learning lấy cảm hứng từ cấu trúc não bộ con người và cần lượng dữ liệu khổng lồ để huấn luyện. Chúng thường được dùng cho các bài toán “nhận thức” phức tạp nhất như nhận diện giọng nói, dịch ngôn ngữ, xe tự lái, v.v. Xem thêm so sánh deep learning và machine learning để có thêm ngữ cảnh.
Trái với machine learning, trí tuệ nhân tạo và deep learning, khoa học dữ liệu có định nghĩa khá rộng. Tóm lại, khoa học dữ liệu là việc khai thác giá trị và hiểu biết từ dữ liệu. Giá trị đó có thể ở dạng các mô hình dự đoán sử dụng machine learning, nhưng cũng có thể là việc đưa ra insight qua bảng điều khiển hoặc báo cáo. Đọc thêm về các công việc hằng ngày của nhà khoa học dữ liệu trong bài viết này.
Ngoài phát hiện email rác, một số ứng dụng machine learning thường gặp gồm phân khúc khách hàng dựa trên dữ liệu nhân khẩu học (bán hàng và tiếp thị), dự đoán giá cổ phiếu (tài chính), tự động phê duyệt yêu cầu bồi thường (bảo hiểm), đề xuất nội dung dựa trên lịch sử xem (truyền thông & giải trí), và còn nhiều nữa. Machine learning đã trở nên phổ biến khắp nơi và có nhiều ứng dụng trong đời sống hằng ngày của chúng ta.
Cuối bài viết, chúng tôi sẽ chia sẻ nhiều tài nguyên để bạn bắt đầu với machine learning.
Sau khi đã có cái nhìn tổng quan về machine learning và cách nó liên hệ với các thuật ngữ thịnh hành khác trong lĩnh vực này, hãy đi sâu hơn vào các loại thuật toán machine learning khác nhau. Các thuật toán machine learning được phân loại rộng thành học có giám sát, không giám sát, tăng cường, và tự giám sát. Hãy tìm hiểu chi tiết hơn và các trường hợp sử dụng phổ biến nhất của chúng.
Phần lớn các trường hợp sử dụng machine learning xoay quanh việc các thuật toán học các mẫu từ dữ liệu lịch sử và áp dụng chúng vào dữ liệu mới dưới dạng dự đoán. Điều này thường được gọi là học có giám sát. Thuật toán học có giám sát được cung cấp cả đầu vào và đầu ra lịch sử cho một vấn đề cụ thể cần giải, trong đó đầu vào về cơ bản là các đặc trưng hoặc chiều của quan sát cần dự đoán, và đầu ra là các kết quả ta muốn dự đoán. Hãy minh họa bằng ví dụ phát hiện thư rác.
Trong trường hợp phát hiện thư rác, một thuật toán học có giám sát sẽ được huấn luyện trên một tập dữ liệu gồm các email rác. Đầu vào sẽ là các đặc trưng hoặc chiều về email, chẳng hạn dòng tiêu đề, địa chỉ email người gửi, nội dung email, liệu email có chứa các liên kết có vẻ nguy hiểm hay không, và các thông tin liên quan khác có thể gợi ý email là rác.
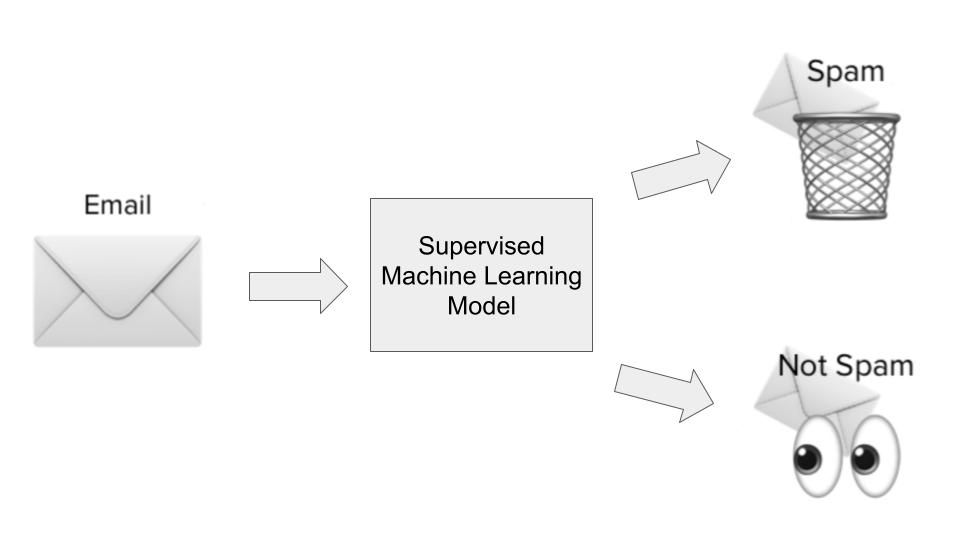
Đầu ra sẽ là liệu email đó thực sự là rác hay không. Trong giai đoạn học của mô hình, thuật toán học một hàm để ánh xạ mối quan hệ thống kê giữa tập biến đầu vào (các chiều khác nhau của email rác) và biến đầu ra (có là rác hay không). Ánh xạ hàm này sau đó được dùng để dự đoán đầu ra cho dữ liệu chưa từng thấy trước đó.
Có hai loại trường hợp sử dụng học có giám sát chính:
Trong phần tiếp theo, chúng ta sẽ xem xét chi tiết hơn các thuật toán học có giám sát cụ thể và một số trường hợp sử dụng của chúng.
Thay vì học các mẫu ánh xạ đầu vào tới đầu ra, thuật toán học không giám sát khám phá các mẫu tổng quát trong dữ liệu mà không được cung cấp đầu ra tường minh. Thuật toán học không giám sát thường được dùng để gom nhóm và phân cụm các đối tượng và thực thể khác nhau. Ví dụ điển hình của học không giám sát là phân khúc khách hàng. Các công ty thường có nhiều chân dung khách hàng khác nhau mà họ phục vụ. Tổ chức thường muốn có cách tiếp cận dựa trên dữ liệu để xác định các phân khúc khách hàng nhằm phục vụ tốt hơn. Khi đó học không giám sát phát huy tác dụng.
Trong trường hợp này, một thuật toán học không giám sát sẽ học cách nhóm khách hàng dựa trên nhiều thuộc tính, như số lần họ sử dụng sản phẩm, nhân khẩu học, cách họ tương tác với sản phẩm, và hơn thế nữa. Sau đó, cùng thuật toán có thể dự đoán khách hàng mới nhiều khả năng thuộc phân khúc nào dựa trên các chiều tương tự.
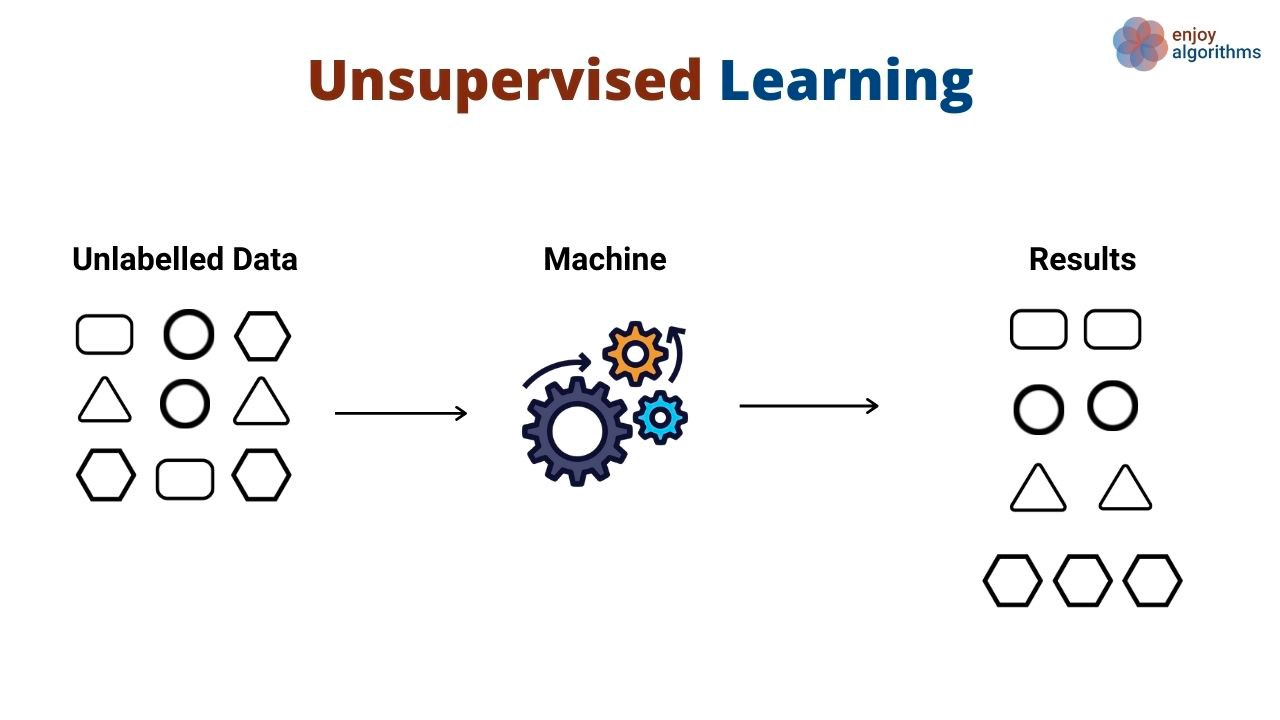
Các thuật toán không giám sát cũng được dùng để giảm số chiều trong tập dữ liệu (tức số đặc trưng) bằng các kỹ thuật giảm chiều. Những thuật toán này thường được dùng như một bước trung gian khi huấn luyện thuật toán học có giám sát.
Một đánh đổi lớn mà các nhà khoa học dữ liệu thường gặp khi huấn luyện thuật toán machine learning là hiệu năng so với độ chính xác dự đoán. Nói chung, họ có càng nhiều thông tin về một vấn đề cụ thể thì càng tốt. Tuy nhiên, điều đó cũng có thể dẫn đến thời gian huấn luyện chậm và hiệu năng kém. Các kỹ thuật giảm chiều giúp giảm số đặc trưng trong tập dữ liệu mà không làm mất giá trị dự đoán.
Học tăng cường là một tập hợp con của các thuật toán machine learning sử dụng phần thưởng để khuyến khích hành vi hoặc dự đoán mong muốn và hình phạt nếu ngược lại. Dù vẫn còn tương đối là lĩnh vực nghiên cứu trong machine learning, học tăng cường là nền tảng cho các thuật toán vượt qua trí tuệ con người trong các trò chơi như Cờ vua, Go, v.v.
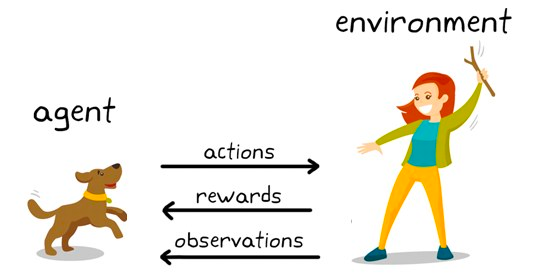
Đây là một kỹ thuật mô hình hóa hành vi, trong đó mô hình học qua cơ chế thử và sai khi liên tục tương tác với môi trường. Hãy minh họa bằng ví dụ cờ vua. Ở mức cao, một thuật toán học tăng cường (thường gọi là agent/tác tử) được cung cấp một môi trường (bàn cờ) nơi nó có thể đưa ra nhiều quyết định (đánh nước đi).
Mỗi nước đi có một tập điểm số liên kết, phần thưởng cho các hành động dẫn tác tử đến chiến thắng, và hình phạt cho các nước đi dẫn đến thua cuộc.
Tác tử liên tục tương tác với môi trường để học các hành động đem lại nhiều phần thưởng nhất và lặp lại các hành động đó. Việc lặp lại hành vi được khuyến khích này được gọi là giai đoạn khai thác (exploitation). Khi tác tử tìm kiếm các hướng mới để giành phần thưởng, đó là giai đoạn thăm dò (exploration). Tổng quát hơn, đây được gọi là mô hình thăm dò–khai thác.
Học tự giám sát là một kỹ thuật machine learning hiệu quả về dữ liệu, trong đó mô hình học từ một tập mẫu không gán nhãn. Như minh họa dưới đây, mô hình đầu tiên được đưa vào một số ảnh đầu vào không gán nhãn, sau đó nó phân cụm các ảnh này bằng cách sử dụng các đặc trưng sinh ra từ chính các ảnh.
Một số ví dụ trong đó sẽ có mức tự tin cao thuộc về các cụm, trong khi số khác thì không. Bước thứ hai sử dụng dữ liệu gán nhãn có độ tin cậy cao từ bước đầu để huấn luyện một bộ phân loại, thường mạnh mẽ hơn cách phân cụm một bước.
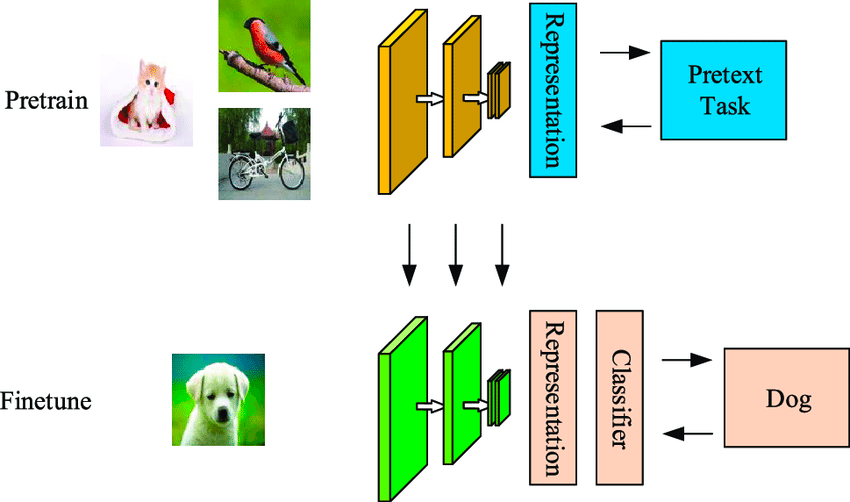
Điểm khác biệt giữa thuật toán tự giám sát và có giám sát là đầu ra được phân loại trong phương pháp trước vẫn sẽ chưa có các lớp được ánh xạ tới các đối tượng thực. Nó khác với học có giám sát ở chỗ không phụ thuộc vào tập được gán nhãn thủ công và tự sinh nhãn, vì thế có tên là tự học.
Bên dưới, chúng tôi tổng hợp một số thuật toán machine learning hàng đầu và các trường hợp sử dụng thường gặp của chúng.
Một thuật toán đơn giản mô hình hóa mối quan hệ tuyến tính giữa một hoặc nhiều biến giải thích và một biến đầu ra số liên tục. Nó có tốc độ huấn luyện nhanh hơn so với các thuật toán machine learning khác. Ưu điểm lớn nhất nằm ở khả năng giải thích và diễn giải các dự đoán của mô hình. Đây là thuật toán hồi quy dùng để dự đoán các kết quả như giá trị vòng đời khách hàng, giá nhà và giá cổ phiếu.
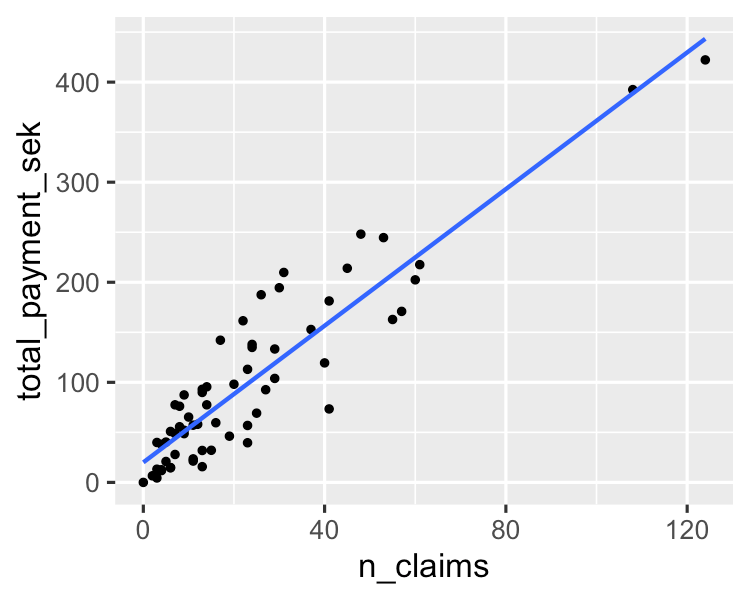
Bạn có thể tìm hiểu thêm trong hướng dẫn các yếu tố cốt lõi của hồi quy tuyến tính bằng Python. Nếu bạn muốn trực tiếp thực hành phân tích hồi quy, khóa học rất được quan tâm trên DataCamp này là tài nguyên phù hợp.
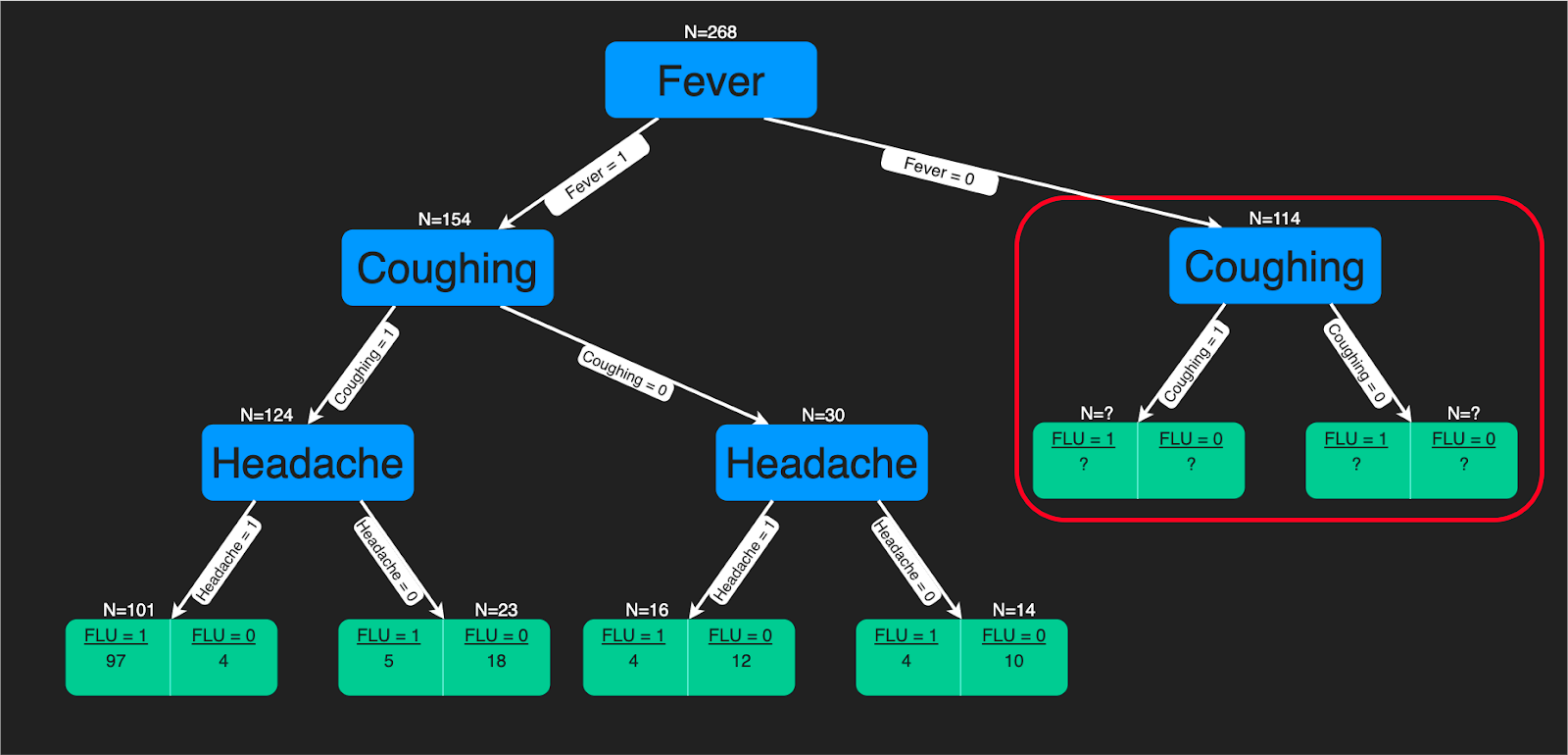
Thuật toán cây quyết định là một cấu trúc dạng cây gồm các quy tắc quyết định được áp dụng lên các đặc trưng đầu vào để dự đoán kết quả có thể. Nó có thể dùng cho cả phân loại hoặc hồi quy. Dự đoán của cây quyết định hỗ trợ tốt cho chuyên gia y tế vì cách mô hình đưa ra dự đoán rất dễ diễn giải.
Bạn có thể tham khảo hướng dẫn này nếu muốn học cách xây dựng bộ phân loại cây quyết định bằng Python. Ngoài ra, nếu bạn quen dùng R hơn, bạn sẽ thấy hữu ích với hướng dẫn này. DataCamp cũng có một khóa học về cây quyết định toàn diện.
Đây có lẽ là một trong những thuật toán phổ biến nhất và khắc phục nhược điểm quá khớp thường thấy ở mô hình cây quyết định. Quá khớp là khi thuật toán học quá kỹ trên dữ liệu huấn luyện và không tổng quát hóa tốt hay dự đoán chính xác trên dữ liệu chưa thấy. Rừng ngẫu nhiên giải quyết vấn đề quá khớp bằng cách xây dựng nhiều cây quyết định trên các mẫu được chọn ngẫu nhiên từ dữ liệu. Kết quả cuối cùng dưới dạng dự đoán tốt nhất được suy ra từ bỏ phiếu đa số của tất cả các cây trong rừng.
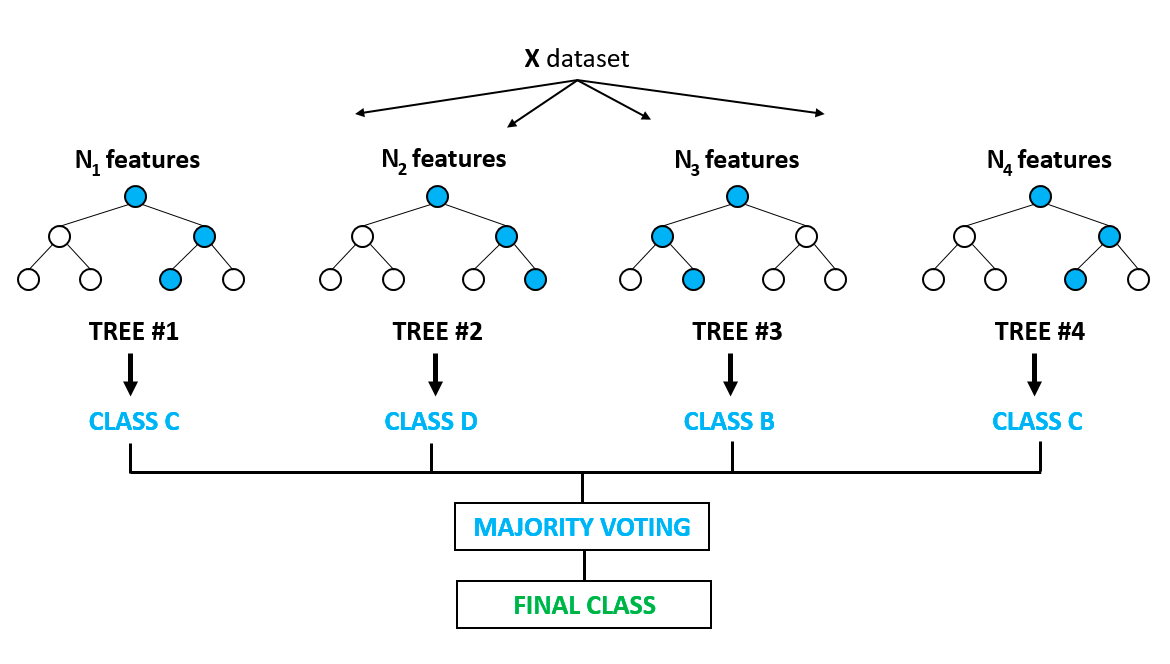
Nó được dùng cho cả bài toán phân loại và hồi quy. Ứng dụng gồm lựa chọn đặc trưng, phát hiện bệnh, v.v. Bạn có thể học thêm về các mô hình dựa trên cây và mô hình tổ hợp (kết hợp nhiều mô hình đơn lẻ) từ khóa học rất phổ biến trên DataCamp. Bạn cũng có thể tìm hiểu thêm trong hướng dẫn Python này về triển khai mô hình rừng ngẫu nhiên.
Support Vector Machines, thường gọi là SVM, thường được dùng cho các bài toán phân loại. Như ví dụ bên dưới, một SVM tìm một siêu phẳng (trong trường hợp này là đường thẳng) phân tách hai lớp (đỏ và xanh lá) và đồng thời tối đa hóa biên (khoảng cách giữa các đường nét đứt) giữa chúng.
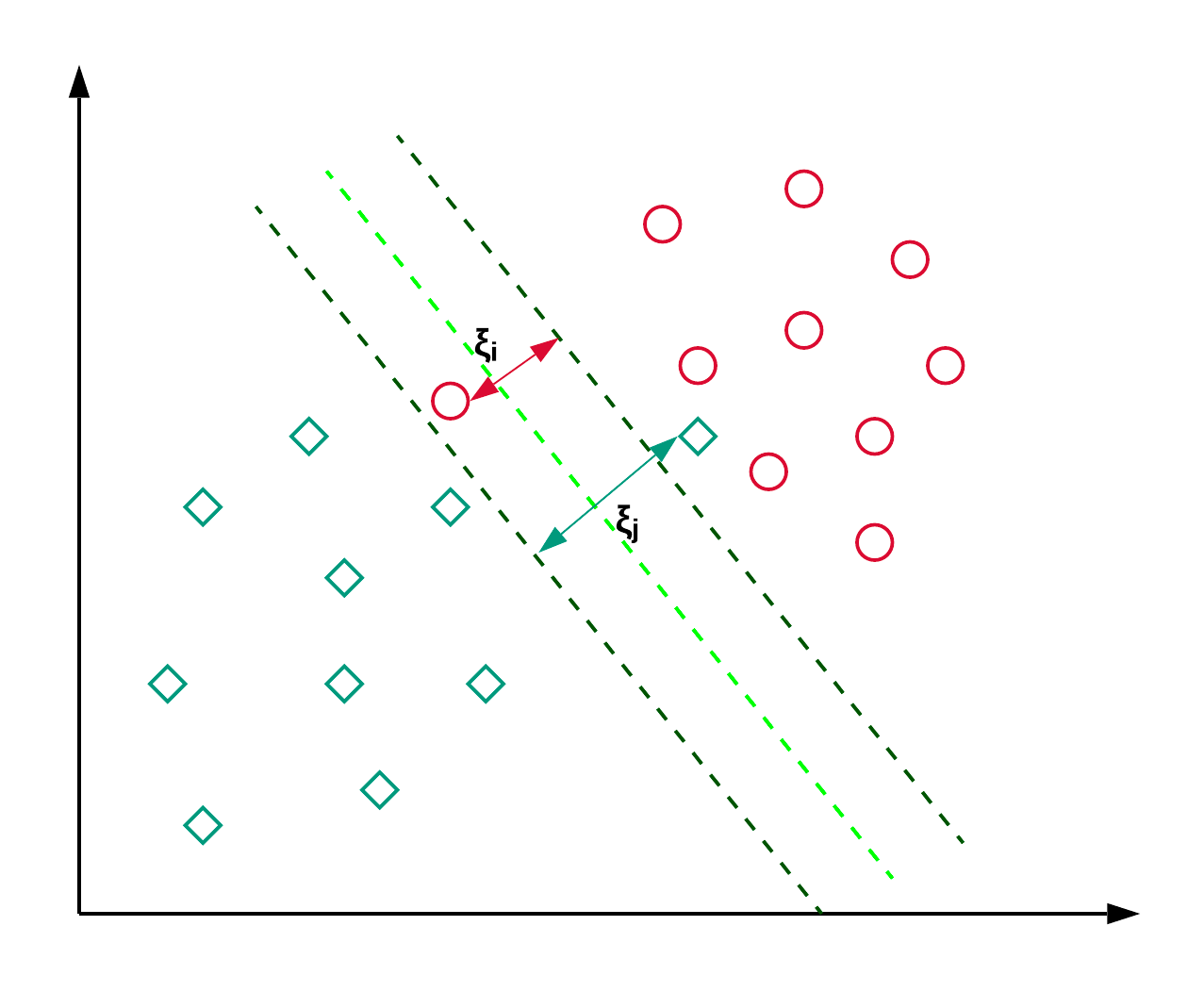
SVM thường dùng cho phân loại nhưng cũng có thể sử dụng trong hồi quy. Nó được dùng để phân loại bài báo và nhận dạng chữ viết tay. Bạn có thể đọc thêm về các loại kernel trick khác nhau cùng với triển khai bằng Python trong hướng dẫn SVM của scikit-learn này. Bạn cũng có thể theo dõi hướng dẫn này, nơi bạn sẽ tái tạo triển khai SVM trong R
Gradient Boosting Regression là một mô hình tổ hợp kết hợp nhiều bộ học yếu để tạo thành một mô hình dự đoán vững chắc. Nó xử lý tốt tính phi tuyến trong dữ liệu và các vấn đề đa cộng tuyến.
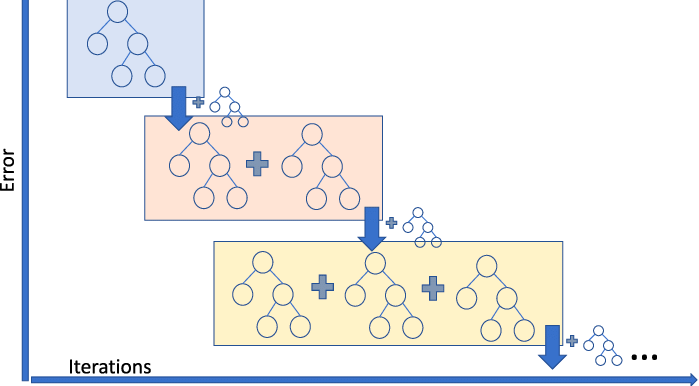
Nếu bạn làm trong lĩnh vực gọi xe và cần dự đoán giá cước chuyến đi, bạn có thể dùng bộ hồi quy tăng cường theo gradient. Nếu bạn muốn hiểu các biến thể của tăng cường theo gradient, bạn có thể xem video này trên DataCamp.
K-Means là phương pháp phân cụm được dùng rộng rãi nhất — nó xác định K cụm dựa trên khoảng cách Euclid. Đây là thuật toán rất phổ biến cho phân khúc khách hàng và hệ thống gợi ý.
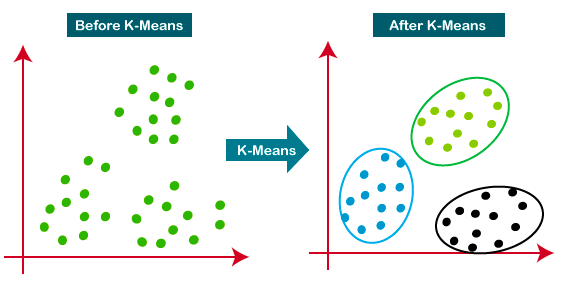
Hướng dẫn này là tài nguyên tuyệt vời để học thêm về phân cụm K-means.
Phân tích thành phần chính (PCA) là một thủ tục thống kê dùng để tóm tắt thông tin từ một tập dữ liệu lớn bằng cách chiếu nó xuống một không gian con có số chiều thấp hơn. Nó còn gọi là kỹ thuật giảm chiều, đảm bảo giữ lại những phần cốt lõi của dữ liệu với lượng thông tin cao.
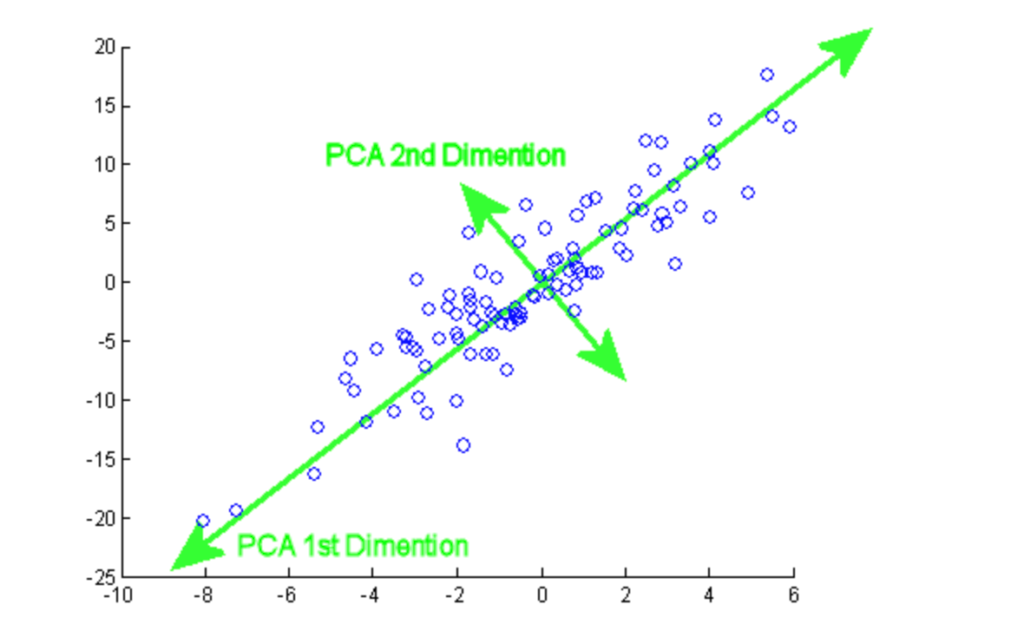
Từ hướng dẫn này, bạn có thể thực hành triển khai PCA thực tế trên hai bộ dữ liệu phổ biến, Breast Cancer và CIFAR-10.
Đây là cách tiếp cận từ dưới lên, trong đó mỗi điểm dữ liệu ban đầu được coi là một cụm riêng, sau đó hai cụm gần nhau nhất được gộp lại lặp đi lặp lại. Ưu điểm lớn nhất so với K-means là không yêu cầu người dùng chỉ định trước số cụm kỳ vọng. Nó được dùng trong phân cụm tài liệu dựa trên độ tương đồng.
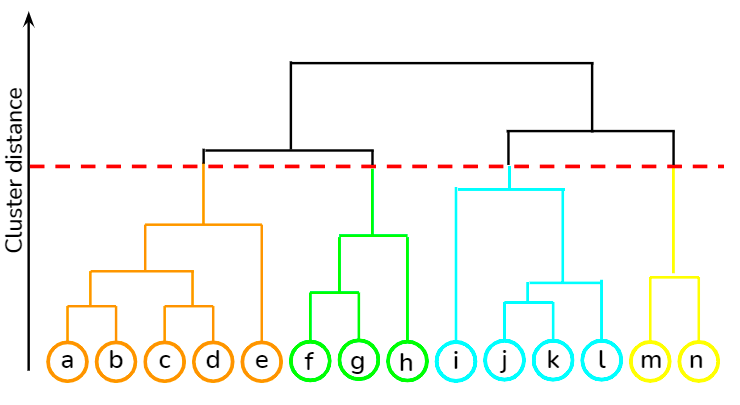
Bạn có thể học các kỹ thuật học không giám sát như phân cụm phân cấp và K-means bằng thư viện scipy qua khóa học tại DataCamp. Ngoài ra, bạn cũng có thể học cách áp dụng kỹ thuật phân cụm để tạo insight từ dữ liệu không gán nhãn bằng R từ khóa học này.
Đây là một mô hình xác suất để mô hình hóa các cụm phân phối chuẩn trong một tập dữ liệu. Nó khác với các thuật toán phân cụm tiêu chuẩn ở chỗ nó ước lượng xác suất một quan sát thuộc về một cụm cụ thể, rồi từ đó đưa ra suy luận về các quần thể con của nó.
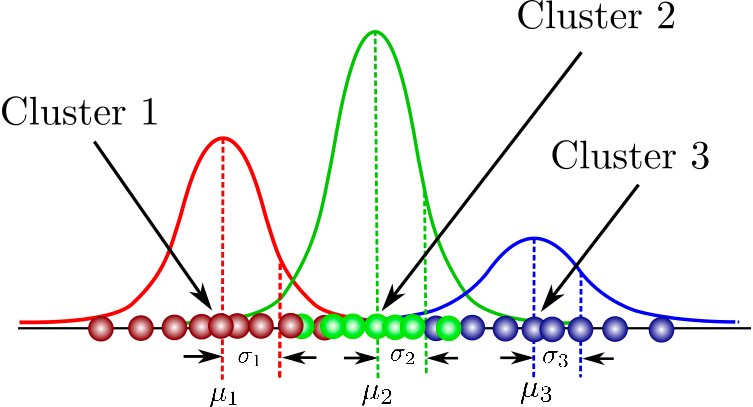
Bạn có thể tìm thấy bộ sưu tập khóa học tổng hợp tại đây bao quát các khái niệm nền tảng trong phân cụm dựa trên mô hình, cấu trúc của Mixture Models và nhiều hơn nữa. Bạn cũng sẽ được thực hành mô hình hỗn hợp Gaussian bằng gói flexmix.
Một cách tiếp cận dựa trên luật nhằm xác định tập mục thường xuyên nhất trong một tập dữ liệu, nơi kiến thức trước về đặc tính của các tập mục thường xuyên được sử dụng. Phân tích giỏ hàng sử dụng thuật toán này để giúp những “gã khổng lồ” như Amazon và Netflix chuyển khối thông tin khổng lồ về người dùng thành các quy tắc đơn giản cho gợi ý sản phẩm. Nó phân tích mối liên hệ giữa hàng triệu sản phẩm và khai mở các quy tắc hữu ích.
DataCamp cung cấp một khóa học toàn diện ở cả hai ngôn ngữ — Python và R.
Machine learning không còn chỉ là một từ thông dụng. Nhiều tổ chức đang triển khai các mô hình machine learning và đã thu được lợi ích từ insight dự đoán. Không cần nói, thị trường hiện đang có nhu cầu lớn đối với các chuyên gia machine learning có kỹ năng cao. Bên dưới là danh sách tài nguyên có thể nhanh chóng giúp bạn bắt đầu nâng cao kiến thức machine learning:
Bắt đầu với machine learning
Courses
Courses
blogs
Matt Crabtree
10 phút