Curso
Aprendizado de máquina com modelos baseados em árvores em Python
5 h
116.4K
O aprendizado de máquina é indiscutivelmente responsável pelos casos de uso mais proeminentes e visíveis da ciência de dados e da inteligência artificial. Desde os carros autônomos da Tesla até o algoritmo AlphaFold da DeepMind, as soluções baseadas em aprendizado de máquina produziram resultados impressionantes e geraram um entusiasmo considerável. Mas o que exatamente é aprendizado de máquina? Como isso funciona? E, o mais importante, será que vale a pena a propaganda? Este artigo fornece uma definição intuitiva dos principais algoritmos de aprendizado de máquina, descreve algumas de suas principais aplicações e fornece recursos para que você possa começar a usar o aprendizado de máquina.
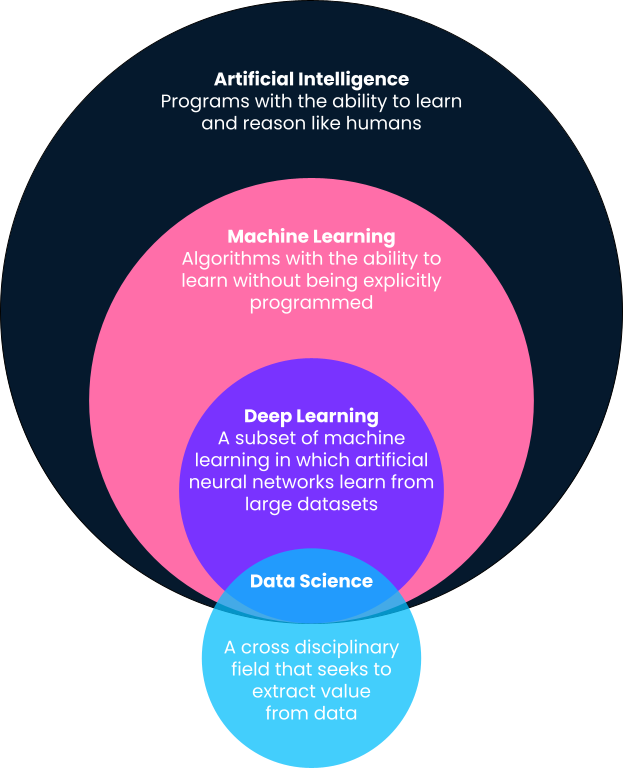
Em resumo, o aprendizado de máquina é um subcampo da inteligência artificial no qual os computadores fornecem previsões com base em padrões aprendidos diretamente dos dados sem serem explicitamente programados para isso. Você perceberá nessa definição que o aprendizado de máquina é um subcampo da inteligência artificial. Por isso, vamos detalhar melhor as definições, pois, muitas vezes, termos como aprendizado de máquina, inteligência artificial, aprendizado profundo e até mesmo ciência de dados são usados de forma intercambiável.
Uma das melhores definições de inteligência artificial vem de Andrew Ng, cofundador do Google Brain e ex-cientista-chefe do Baidu. De acordo com Andrew, a inteligência artificial é um "enorme conjunto de ferramentas para fazer com que os computadores se comportem de forma inteligente". Isso pode incluir qualquer coisa, desde sistemas explicitamente definidos, como calculadoras, até soluções baseadas em aprendizado de máquina, como detectores de e-mail de spam.
Conforme descrito acima, o aprendizado de máquina é um subcampo da inteligência artificial no qual os algoritmos aprendem padrões a partir de dados históricos e fornecem previsões com base nesses padrões aprendidos, aplicando-os a novos dados. Tradicionalmente, os sistemas simples e inteligentes, como as calculadoras, são explicitamente programados pelos desenvolvedores como etapas e procedimentos claramente definidos (ou seja, se isso, então aquilo). No entanto, isso não é dimensionável nem possível para problemas mais avançados.
Vejamos o exemplo dos filtros de spam de e-mail. Os desenvolvedores podem tentar criar filtros de spam definindo-os explicitamente. Por exemplo, eles podem definir um programa que aciona um filtro de spam se um e-mail tiver uma determinada linha de assunto ou contiver determinados links. No entanto, esse sistema se mostrará ineficaz assim que os remetentes de spam mudarem de tática.
Por outro lado, uma solução baseada em aprendizado de máquina receberá milhões de e-mails de spam como dados de entrada, aprenderá as características mais comuns de e-mails com spam por meio de associação estatística e fará previsões sobre e-mails futuros com base nas características aprendidas.
A aprendizagem profunda é um subcampo da aprendizagem automática e provavelmente é responsável pelos casos de uso de aprendizagem automática mais visíveis da cultura popular. Os algoritmos de aprendizagem profunda são inspirados na estrutura do cérebro humano e exigem quantidades incríveis de dados para treinamento. Eles são usados com frequência para os problemas "cognitivos" mais complexos, como detecção de fala, tradução de idiomas, carros autônomos e muito mais. Confira nossa comparação entre aprendizagem profunda e aprendizagem automática para obter mais contexto.
Em contraste com o aprendizado de máquina, a inteligência artificial e o aprendizado profundo, a ciência de dados tem uma definição bastante ampla. Em resumo, a ciência de dados trata de extrair valor e insights dos dados. Esse valor pode estar na forma de modelos preditivos que usam o aprendizado de máquina, mas também pode significar a apresentação de insights em um painel ou relatório. Leia mais sobre as tarefas diárias dos cientistas de dados neste artigo.
Além da detecção de spam por e-mail, alguns aplicativos de aprendizado de máquina comumente conhecidos incluem a segmentação de clientes com base em dados demográficos (vendas e marketing), previsão de preços de ações (finanças), automação de aprovação de sinistros (seguros), recomendações de conteúdo com base no histórico de visualização (mídia e entretenimento) e muito mais. O aprendizado de máquina tornou-se onipresente e encontra diversas aplicações em nosso dia a dia.
No final deste artigo, compartilharemos muitos recursos para você começar a usar o aprendizado de máquina.
Agora que apresentamos uma visão geral do aprendizado de máquina e onde ele se encaixa em outras palavras-chave que você pode encontrar nesse espaço, vamos analisar mais profundamente os diferentes tipos de algoritmos de aprendizado de máquina. Os algoritmos de aprendizado de máquina são amplamente categorizados em aprendizado supervisionado, não supervisionado, por reforço e autossupervisionado. Vamos entendê-los em mais detalhes e seus casos de uso mais comuns.
A maioria dos casos de uso de aprendizado de máquina gira em torno de algoritmos que aprendem padrões a partir de dados históricos e os aplicam a novos dados na forma de previsões. Isso geralmente é chamado de aprendizado supervisionado. Os algoritmos de aprendizado supervisionado apresentam entradas e saídas históricas em um problema específico que estamos tentando resolver, onde as entradas são essencialmente recursos ou dimensões da observação que estamos tentando prever e onde as saídas são os resultados que queremos prever. Vamos ilustrar isso com nosso exemplo de detecção de spam.
No caso de uso de detecção de spam, um algoritmo de aprendizado supervisionado seria treinado em um conjunto de dados de e-mails com spam. As entradas seriam recursos ou dimensões sobre os e-mails, como a linha de assunto do e-mail, o endereço de e-mail do remetente, o conteúdo do e-mail, se o e-mail continha links com aparência perigosa e outras informações relevantes que poderiam dar pistas sobre se um e-mail é spam.
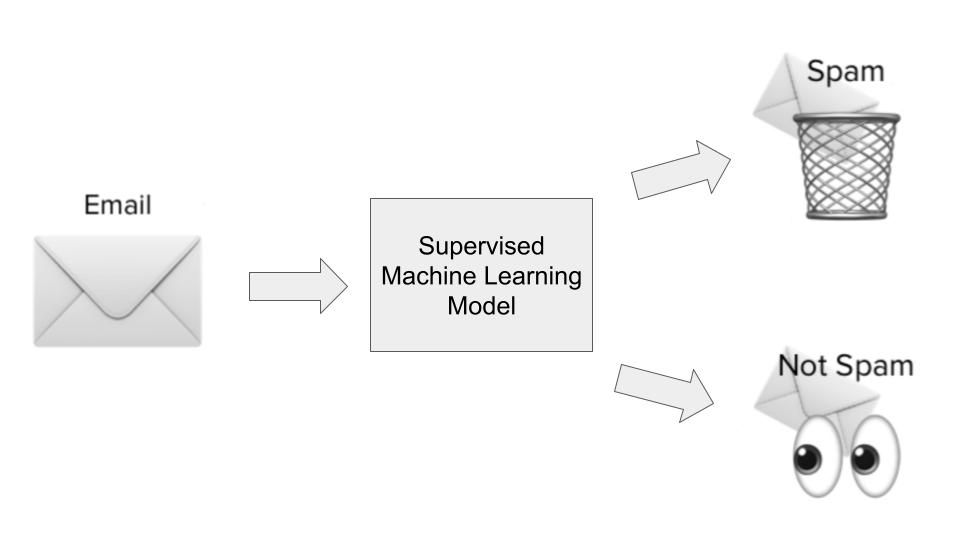
O resultado seria se, de fato, o e-mail era spam ou não. Durante a fase de aprendizado do modelo, o algoritmo aprende uma função para mapear a relação estatística entre o conjunto de variáveis de entrada (as diferentes dimensões do e-mail com spam) e a variável de saída (se era spam ou não). Esse mapeamento funcional é então usado para prever o resultado dos dados não vistos anteriormente.
Em geral, há dois tipos de casos de uso de aprendizado supervisionado:
Em uma próxima seção, analisaremos algoritmos específicos de aprendizagem supervisionada e alguns de seus casos de uso com mais detalhes.
Em vez de aprender padrões que mapeiam entradas para saídas, os algoritmos de aprendizado não supervisionado descobrem padrões gerais nos dados sem que as saídas sejam explicitamente mostradas. Os algoritmos de aprendizado não supervisionado são comumente usados para agrupar e agrupar diferentes objetos e entidades. Um ótimo exemplo de aprendizado não supervisionado é a segmentação de clientes. As empresas geralmente têm uma variedade de personas de clientes que atendem. As organizações geralmente querem ter uma abordagem baseada em fatos para identificar seus segmentos de clientes e atendê-los melhor. Você pode usar o aprendizado não supervisionado.
Nesse caso de uso, um algoritmo de aprendizado não supervisionado aprenderia a agrupar os clientes com base em vários atributos, como o número de vezes que eles usaram um produto, seus dados demográficos, como eles interagem com os produtos e muito mais. Em seguida, o mesmo algoritmo pode prever a qual segmento provável os novos clientes pertencem com base nas mesmas dimensões.
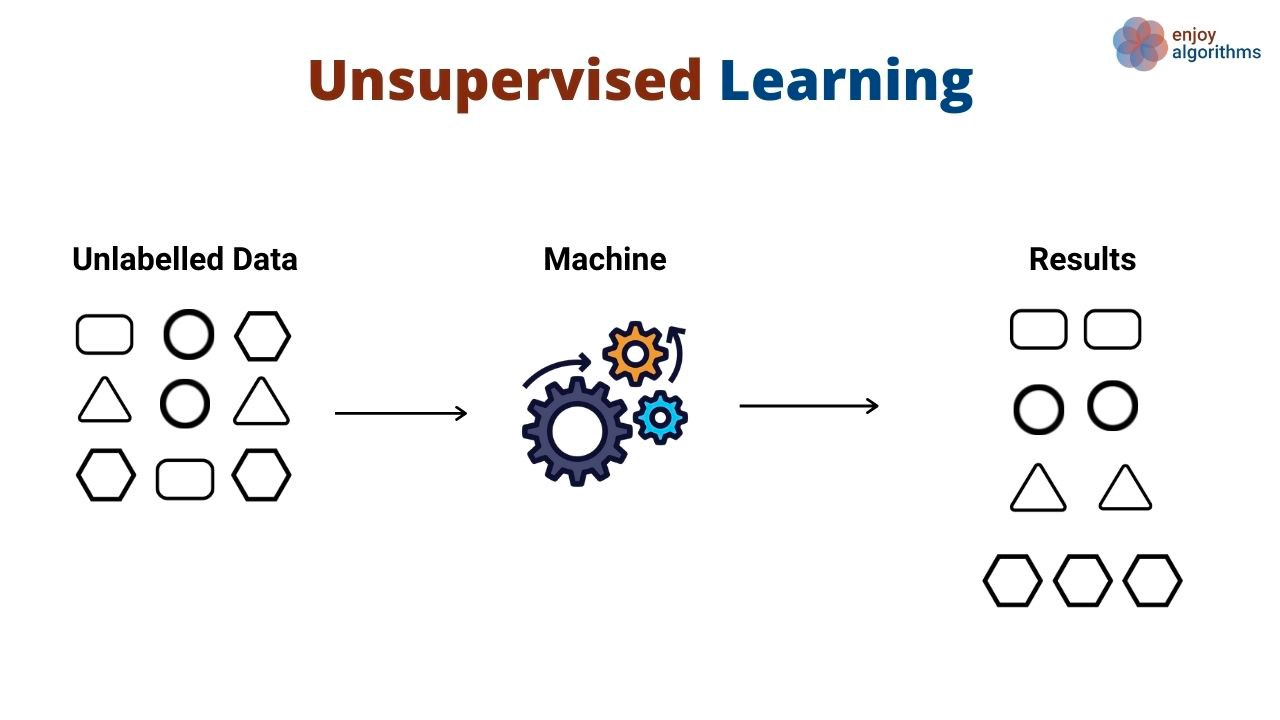
Os algoritmos não supervisionados também são usados para reduzir as dimensões em um conjunto de dados (ou seja, o número de recursos) usando técnicas de redução de dimensionalidade. Esses algoritmos são frequentemente usados como uma etapa intermediária no treinamento de um algoritmo de aprendizado supervisionado.
Uma grande troca que os cientistas de dados geralmente enfrentam ao treinar algoritmos de aprendizado de máquina é o desempenho versus a precisão da previsão. Em geral, quanto mais informações você tiver sobre um determinado problema, melhor. No entanto, isso também pode levar a tempos de treinamento e desempenho lentos. As técnicas de redução de dimensionalidade ajudam a reduzir o número de recursos presentes em um conjunto de dados sem sacrificar o valor preditivo.
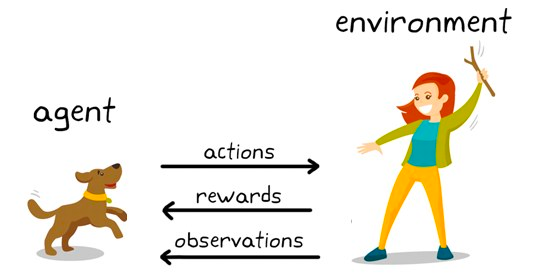
O aprendizado por reforço é um subconjunto de algoritmos de aprendizado de máquina que utiliza recompensas para promover um comportamento ou uma previsão desejada e uma penalidade caso contrário. Embora ainda seja relativamente uma área de pesquisa dentro do aprendizado de máquina, o aprendizado por reforço é responsável por algoritmos que superam a inteligência humana em jogos como xadrez, Go e outros.
É uma técnica de modelagem comportamental em que o modelo aprende por meio de um mecanismo de tentativa e erro à medida que continua interagindo com o ambiente. Vamos ilustrar isso com o exemplo do xadrez. Em um nível mais alto, um algoritmo de aprendizagem por reforço (geralmente chamado de agente) recebe um ambiente (tabuleiro de xadrez) no qual pode tomar várias decisões (jogadas).
Cada movimento tem um conjunto de pontuações associadas, uma recompensa para ações que levam o agente a vencer e uma penalidade para movimentos que levam o agente a perder.
O agente continua interagindo com o ambiente para aprender as ações que geram mais recompensas e continua repetindo essas ações. Essa repetição do comportamento promovido é chamada de fase de exploração. Quando o agente procura novos caminhos para ganhar recompensas, isso é chamado de fase de exploração. Em termos mais gerais, isso é chamado de paradigma de exploração-exploração.
O aprendizado autossupervisionado é uma técnica de aprendizado de máquina eficiente em termos de dados, em que o modelo aprende com um conjunto de dados de amostra não rotulado. Conforme mostrado no exemplo abaixo, o primeiro modelo é alimentado com algumas imagens de entrada não rotuladas, que são agrupadas por ele usando recursos gerados a partir dessas imagens.
Alguns desses exemplos teriam uma alta confiança de pertencer aos clusters, enquanto outros não. A segunda etapa usa os dados rotulados de alta confiança da primeira etapa para treinar um classificador que tende a ser mais eficiente do que uma abordagem de agrupamento em uma etapa.
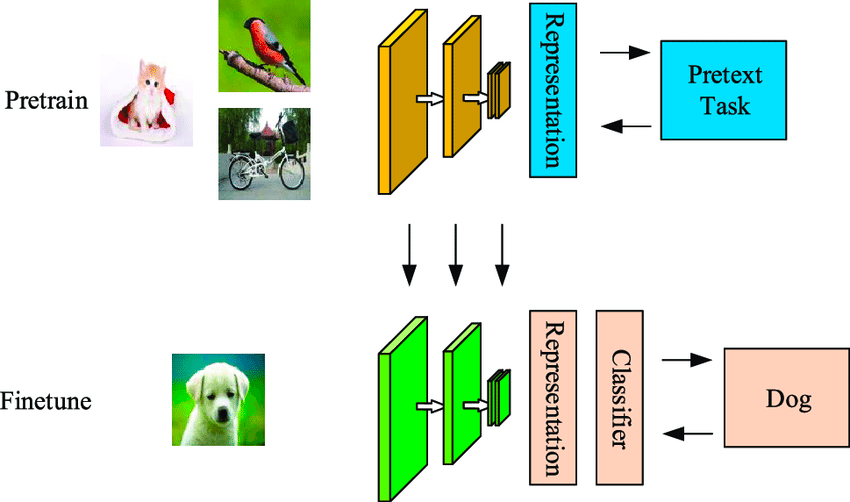
A diferença entre os algoritmos autossupervisionados e supervisionados é que a saída classificada no primeiro ainda não terá as classes mapeadas para objetos reais. Ele difere do aprendizado supervisionado porque não depende do conjunto rotulado manualmente e gera rótulos por si só, daí o nome autoaprendizado.
A seguir, descrevemos alguns dos principais algoritmos de aprendizado de máquina e seus casos de uso mais comuns.
Um algoritmo simples modela uma relação linear entre uma ou mais variáveis explicativas e uma variável de saída numérica contínua. Seu treinamento é mais rápido do que o de outros algoritmos de aprendizado de máquina. Sua maior vantagem está na capacidade de explicar e interpretar as previsões do modelo. É um algoritmo de regressão usado para prever resultados como o valor do ciclo de vida do cliente, preços de imóveis e preços de ações.
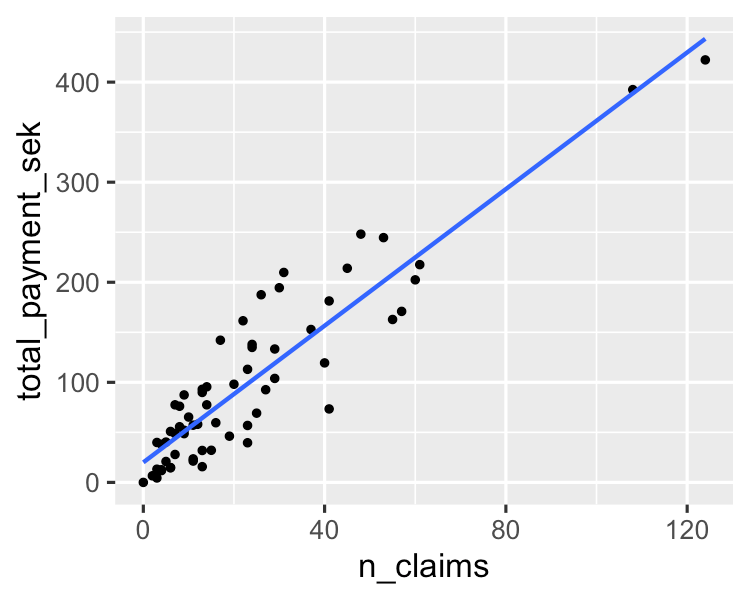
Você pode aprender mais sobre isso neste tutorial sobre os fundamentos da regressão linear em Python. Se você estiver interessado em colocar a mão na massa com a análise de regressão, esse curso muito procurado no DataCamp é o recurso certo para você.
Um algoritmo de árvore de decisão é uma estrutura em forma de árvore de regras de decisão que são aplicadas aos recursos de entrada para prever os possíveis resultados. Ele pode ser usado para classificação ou regressão. As previsões da árvore de decisão são uma boa ajuda para os especialistas em saúde, pois é fácil interpretar como essas previsões são feitas.
Você pode consultar este tutorial se estiver interessado em aprender como criar um classificador de árvore de decisão usando Python. Além disso, se você se sentir mais confortável com o uso do R, será beneficiado por este tutorial. Há também um curso abrangente sobre árvores de decisão no DataCamp.
Esse é, sem dúvida, um dos algoritmos mais populares e se baseia nas desvantagens do ajuste excessivo, que são vistas com destaque nos modelos de árvore de decisão. Overfitting é quando os algoritmos são treinados nos dados de treinamento um pouco bem demais e não conseguem generalizar ou fornecer previsões precisas sobre dados não vistos. A floresta aleatória resolve o problema do excesso de ajuste criando várias árvores de decisão em amostras selecionadas aleatoriamente dos dados. O resultado final na forma da melhor previsão é derivado da votação majoritária de todas as árvores da floresta.
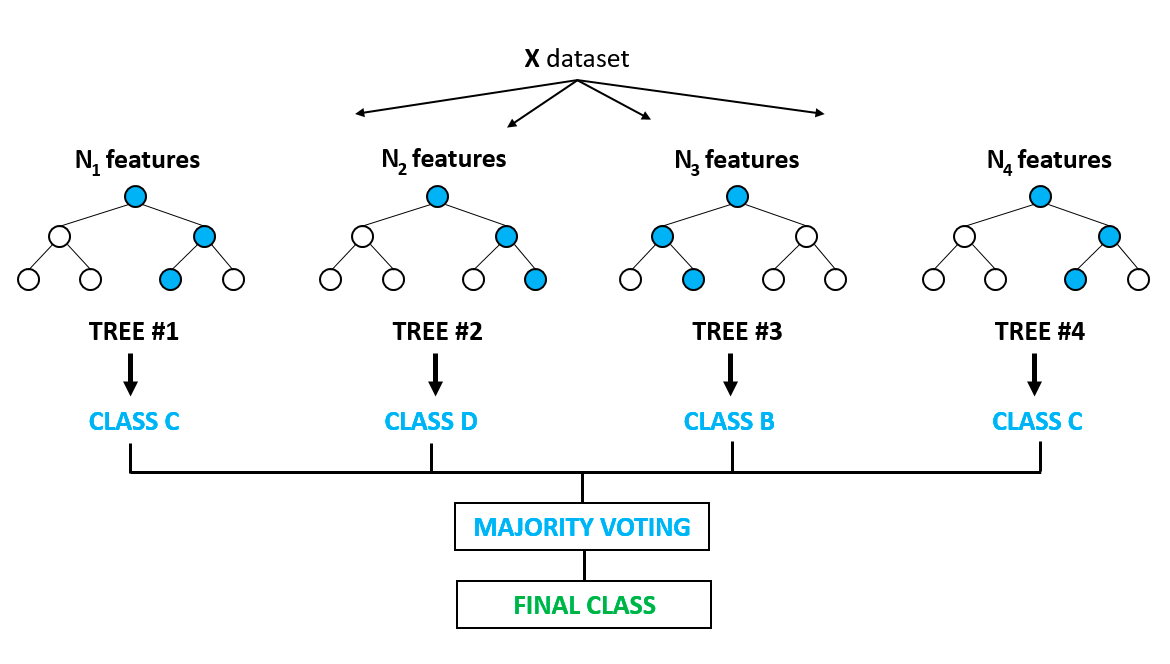
Ele é usado para problemas de classificação e regressão. Ele encontra aplicação na seleção de recursos, detecção de doenças etc. Você pode saber mais sobre modelos baseados em árvores e conjuntos (combinando diferentes modelos individuais) neste curso muito popular no DataCamp. Você também pode saber mais neste tutorial baseado em Python sobre a implementação do modelo de floresta aleatória.
As Support Vector Machines, comumente conhecidas como SVM, são geralmente usadas para problemas de classificação. Conforme mostrado no exemplo abaixo, um SVM encontra um hiperplano (linha, nesse caso) que segrega as duas classes (vermelha e verde) e maximiza a margem (distância entre as linhas pontilhadas) entre elas.
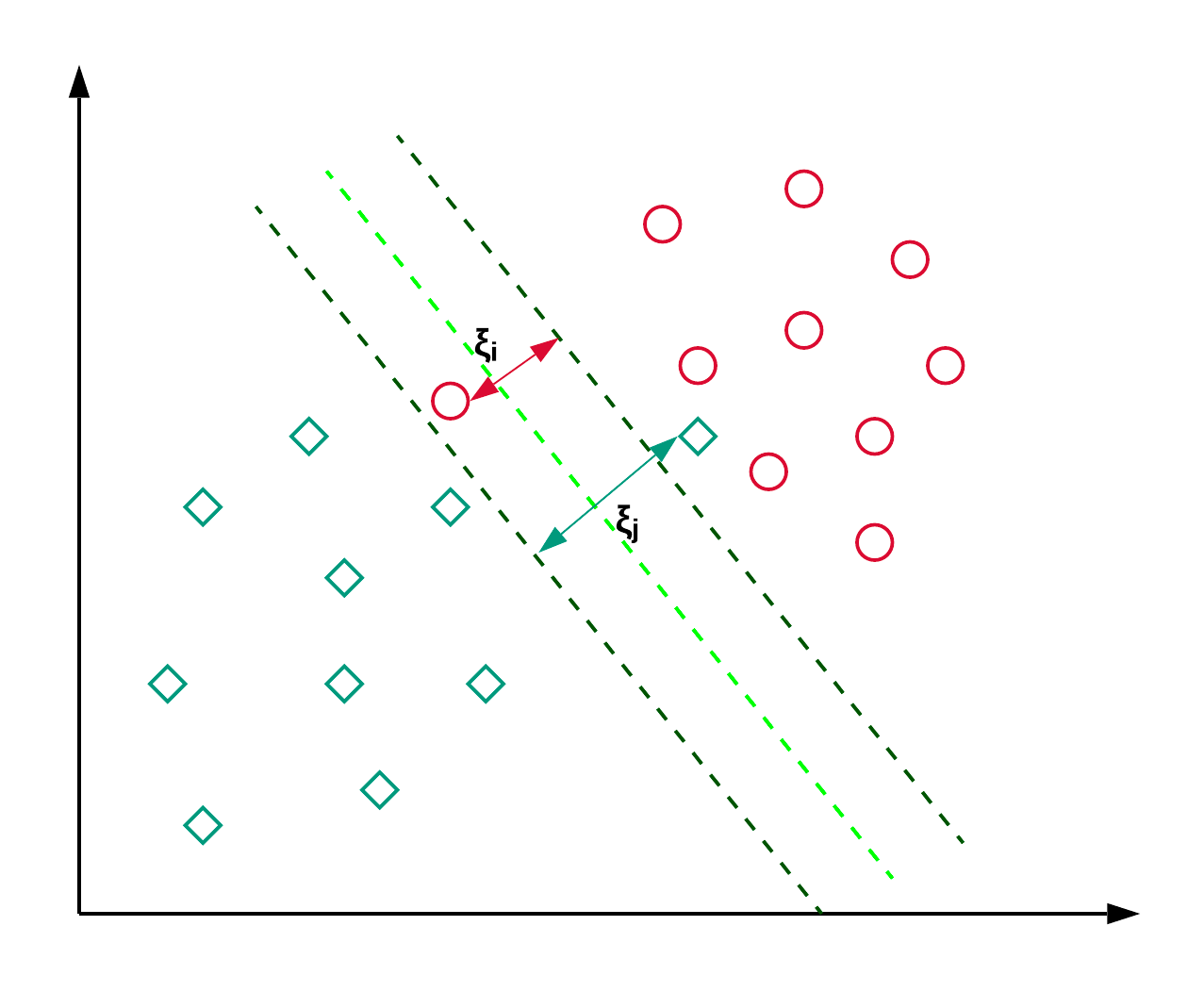
O SVM é geralmente usado para problemas de classificação, mas também pode ser empregado em problemas de regressão. Ele é usado para classificar artigos de notícias e reconhecimento de escrita à mão. Você pode ler mais sobre os diferentes tipos de truques de kernel, juntamente com a implementação em python , neste tutorial do scikit-learn SVM. Você também pode seguir este tutorial, no qual replicará a implementação do SVM no R
O Gradient Boosting Regression é um modelo de conjunto que combina vários alunos fracos para criar um modelo preditivo robusto. Ele é bom para lidar com não linearidades nos dados e problemas de multicolinearidade.
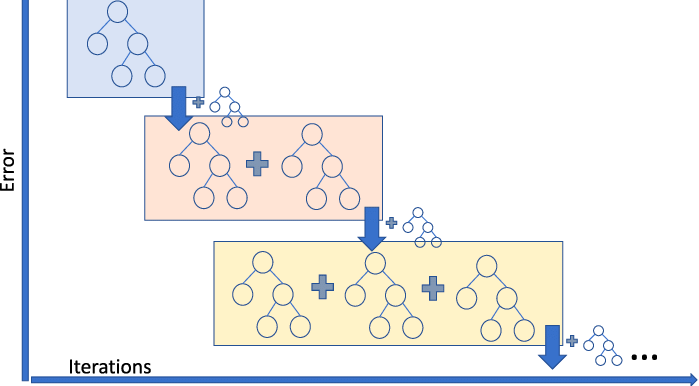
Se você estiver em um negócio de compartilhamento de carona e precisar prever o valor da tarifa da carona, poderá usar um regressor de aumento de gradiente. Se quiser entender os diferentes tipos de gradient boosting, você pode assistir a este vídeo no DataCamp.
O K-Means é a abordagem de agrupamento mais usada - ele determina K clusters com base na distância euclidiana. É um algoritmo muito popular para segmentação de clientes e sistemas de recomendação.
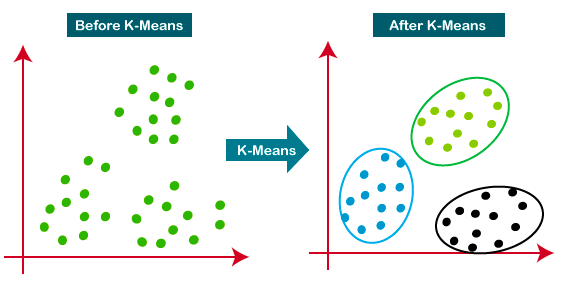
Este tutorial é um ótimo recurso para você aprender mais sobre o agrupamento K-means.
A análise de componentes principais (PCA) é um procedimento estatístico usado para resumir as informações de um grande conjunto de dados, projetando-as em um subespaço de dimensão inferior. Também é chamada de técnica de redução de dimensionalidade que garante a retenção das partes essenciais dos dados com mais informações.
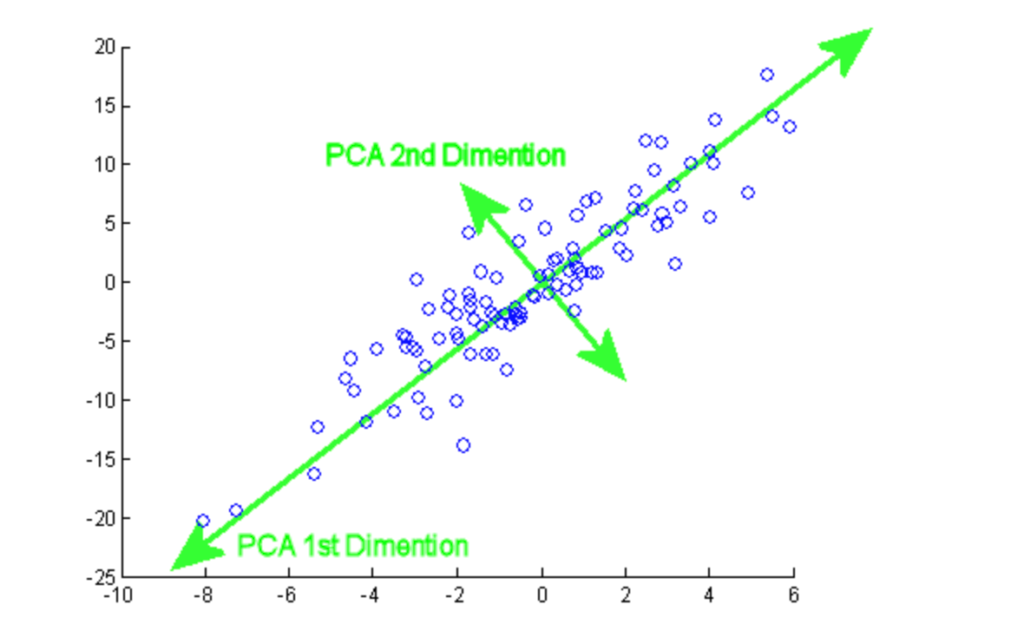
Com este tutorial, você pode praticar a implementação prática de PCA em dois conjuntos de dados populares, Breast Cancer e CIFAR-10.
É uma abordagem de baixo para cima em que cada ponto de dados é tratado como seu próprio cluster e, em seguida, os dois clusters mais próximos são mesclados iterativamente. Sua maior vantagem sobre o clustering K-means é que ele não exige que o usuário especifique o número esperado de clusters no início. Ele encontra aplicação no agrupamento de documentos com base na similaridade.
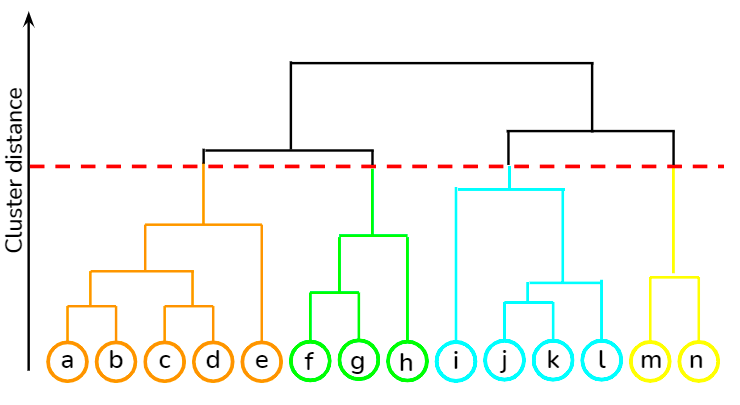
Você pode aprender várias técnicas de aprendizado não supervisionado, como clustering hierárquico e clustering K-means, usando a biblioteca scipy neste curso do DataCamp. Além disso, você também pode aprender a aplicar técnicas de agrupamento para gerar insights a partir de dados não rotulados usando o R neste curso.
É um modelo probabilístico para modelar clusters normalmente distribuídos em um conjunto de dados. Ele é diferente dos algoritmos de agrupamento padrão no sentido de que estima a probabilidade de uma observação pertencer a um determinado agrupamento e, em seguida, se dedica a fazer inferências sobre sua subpopulação.
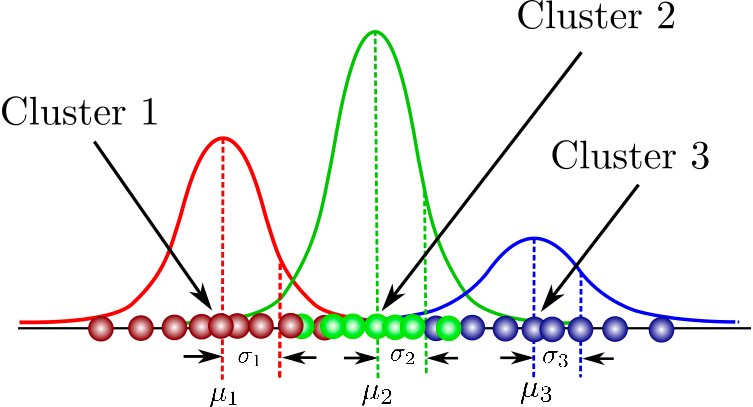
Você pode encontrar aqui um conjunto completo de cursos que abrangem conceitos fundamentais de agrupamento baseado em modelos, a estrutura de modelos de mistura e muito mais. Você também terá a oportunidade de praticar a modelagem de mistura gaussiana usando o pacote flexmix.
Uma abordagem baseada em regras que identifica o conjunto de itens mais frequente em um determinado conjunto de dados em que é usado o conhecimento prévio das propriedades do conjunto de itens frequente. A análise de cesta de mercado emprega esse algoritmo para ajudar gigantes como a Amazon e a Netflix a traduzir os montes de informações sobre seus usuários em regras simples de recomendações de produtos. Ele analisa as associações entre milhões de produtos e revela regras perspicazes.
O DataCamp oferece um curso abrangente em ambas as linguagens - Python e R.
O aprendizado de máquina não é mais apenas uma palavra da moda. Muitas organizações estão implantando modelos de aprendizado de máquina e já estão obtendo ganhos com insights preditivos. Não é preciso dizer que há uma grande demanda por profissionais altamente qualificados em aprendizado de máquina no mercado. A seguir, você encontrará uma lista de recursos que podem ajudá-lo a começar rapidamente a aprimorar os conceitos de aprendizado de máquina:
Comece a usar o aprendizado de máquina
Curso
Curso
blog
DataCamp Team
11 min
blog
Moez Ali
15 min
blog
Matt Crabtree
14 min
blog
Elena Kosourova
15 min
blog
Abid Ali Awan
15 min
blog
Natassha Selvaraj
15 min