Cours
Machine learning avec des modèles arborescents en Python
5 h
116.4K
L'apprentissage automatique est sans doute à l'origine des cas d'utilisation les plus importants et les plus visibles de la science des données et de l'intelligence artificielle. Des voitures autonomes de Tesla à l'algorithme AlphaFold de DeepMind, les solutions basées sur l'apprentissage automatique ont produit des résultats impressionnants et suscité un engouement considérable. Mais qu'est-ce que l'apprentissage automatique ? Comment cela fonctionne-t-il ? Et surtout, cela vaut-il la peine d'en faire tout un plat ? Cet article propose une définition intuitive des principaux algorithmes d'apprentissage automatique, décrit quelques-unes de leurs applications clés et fournit des ressources pour commencer à utiliser l'apprentissage automatique.
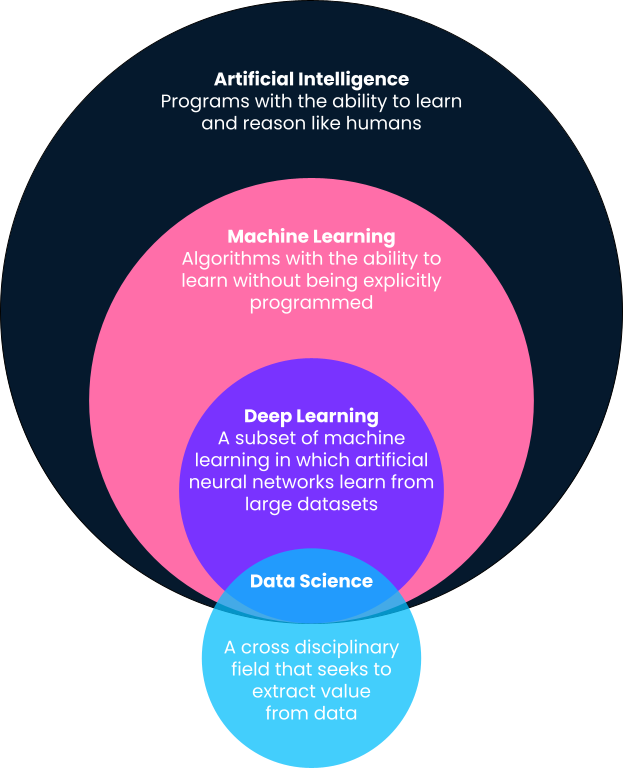
En bref, l'apprentissage automatique est un sous-domaine de l'intelligence artificielle dans lequel les ordinateurs fournissent des prédictions basées sur des modèles appris directement à partir de données sans être explicitement programmés pour le faire. Vous remarquerez dans cette définition que l'apprentissage automatique est un sous-domaine de l'intelligence artificielle. C'est pourquoi nous allons détailler les définitions, car les termes apprentissage automatique, intelligence artificielle, apprentissage profond et même science des données sont souvent utilisés de manière interchangeable.
L'une des meilleures définitions de l'intelligence artificielle est celle d'Andrew Ng, cofondateur de Google Brain et ancien scientifique en chef de Baidu. Selon Andrew, l'intelligence artificielle est un "vaste ensemble d'outils permettant aux ordinateurs de se comporter de manière intelligente". Il peut s'agir de systèmes explicitement définis, comme les calculatrices, ou de solutions basées sur l'apprentissage automatique, comme les détecteurs de courrier électronique indésirable.
Comme indiqué ci-dessus, l'apprentissage automatique est un sous-domaine de l'intelligence artificielle dans lequel les algorithmes apprennent des modèles à partir de données historiques et fournissent des prédictions basées sur ces modèles appris en les appliquant à de nouvelles données. Traditionnellement, les systèmes simples et intelligents tels que les calculatrices sont explicitement programmés par les développeurs sous la forme d'étapes et de procédures clairement définies (par exemple, si ceci, alors cela). Cependant, cette méthode n'est pas extensible ou possible pour les problèmes plus avancés.
Prenons l'exemple des filtres anti-spam. Les développeurs peuvent essayer de créer des filtres anti-spam en les définissant explicitement. Par exemple, ils peuvent définir un programme qui déclenche un filtre anti-spam si un courriel a un certain objet ou contient certains liens. Toutefois, ce système s'avérera inefficace dès que les spammeurs changeront de tactique.
En revanche, une solution basée sur l'apprentissage automatique prendra en compte des millions de spams comme données d'entrée, apprendra les caractéristiques les plus courantes des spams par association statistique et fera des prédictions sur les futurs spams sur la base des caractéristiques apprises.
L'apprentissage profond est un sous-domaine de l'apprentissage automatique et est probablement à l'origine des cas d'utilisation de l'apprentissage automatique les plus visibles dans la culture populaire. Les algorithmes d'apprentissage profond s'inspirent de la structure du cerveau humain et nécessitent d'incroyables quantités de données pour l'apprentissage. Ils sont souvent utilisés pour les problèmes "cognitifs" les plus complexes, tels que la détection de la parole, la traduction linguistique, les voitures autonomes, etc. Pour en savoir plus, consultez notre comparaison entre l'apprentissage profond et l'apprentissage automatique.
Contrairement à l'apprentissage automatique, à l'intelligence artificielle et à l'apprentissage profond, la science des données a une définition assez large. En résumé, la science des données consiste à extraire de la valeur et des informations des données. Cette valeur peut prendre la forme de modèles prédictifs utilisant l'apprentissage automatique, mais elle peut aussi se traduire par la présentation d'informations sous la forme d'un tableau de bord ou d'un rapport. Pour en savoir plus sur les tâches quotidiennes des data scientists, consultez cet article.
En dehors de la détection des spams dans les courriers électroniques, les applications d'apprentissage automatique les plus connues sont la segmentation de la clientèle sur la base de données démographiques (ventes et marketing), la prédiction du cours des actions (finance), l'automatisation de l'approbation des demandes d'indemnisation (assurance), les recommandations de contenu basées sur l'historique de visionnage (médias et divertissements), et bien d'autres encore. L'apprentissage automatique est devenu omniprésent et trouve des applications variées dans notre vie quotidienne.
À la fin de cet article, nous partagerons avec vous de nombreuses ressources pour vous aider à démarrer avec l'apprentissage automatique.
Maintenant que nous avons donné un aperçu de l'apprentissage automatique et de sa place dans les autres termes à la mode que vous pouvez rencontrer dans ce domaine, examinons plus en détail les différents types d'algorithmes d'apprentissage automatique. Les algorithmes d'apprentissage automatique sont généralement classés dans les catégories suivantes : apprentissage supervisé, apprentissage non supervisé, apprentissage par renforcement et apprentissage auto-supervisé. Nous allons les comprendre plus en détail ainsi que leurs cas d'utilisation les plus courants.
La plupart des cas d'utilisation de l'apprentissage automatique tournent autour d'algorithmes qui apprennent des modèles à partir de données historiques et les appliquent à de nouvelles données sous la forme de prédictions. On parle souvent d'apprentissage supervisé. Les algorithmes d'apprentissage supervisé se voient présenter à la fois des entrées et des sorties historiques sur un problème particulier que nous essayons de résoudre, où les entrées sont essentiellement des caractéristiques ou des dimensions de l'observation que nous essayons de prédire, et où les sorties sont les résultats que nous voulons prédire. Illustrons cela avec notre exemple de détection de spam.
Dans le cas de la détection du spam, un algorithme d'apprentissage supervisé serait entraîné sur un ensemble de données de courriels spammés. Les données d'entrée seraient des caractéristiques ou des dimensions des courriels, telles que l'objet du courriel, l'adresse électronique de l'expéditeur, le contenu du courriel, le fait que le courriel contienne ou non des liens dangereux, et d'autres informations pertinentes qui pourraient donner des indices sur le caractère spammeur d'un courriel.
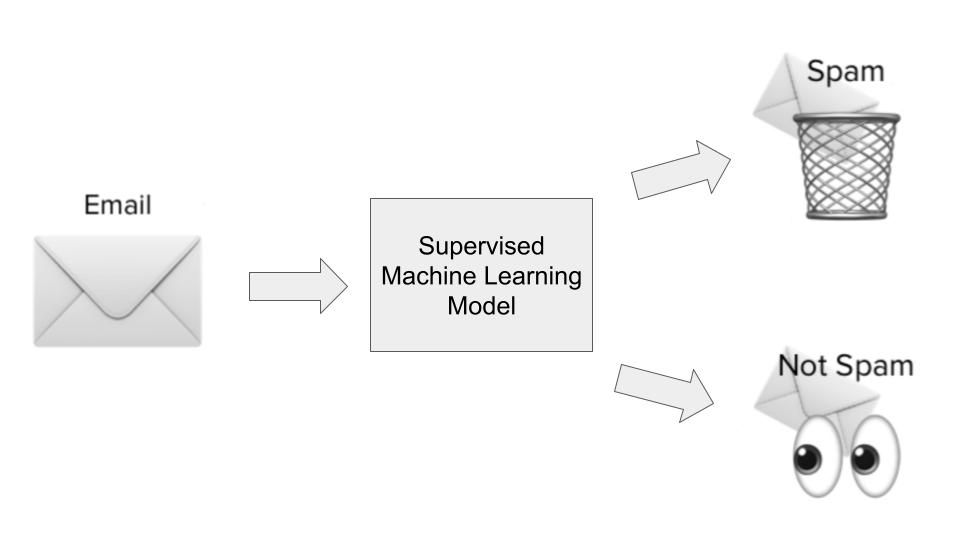
Le résultat serait de savoir si, en fait, ce courriel était du spam ou non. Au cours de la phase d'apprentissage du modèle, l'algorithme apprend une fonction pour cartographier la relation statistique entre l'ensemble des variables d'entrée (les différentes dimensions du courrier électronique indésirable) et la variable de sortie (le fait qu'il s'agisse d'un courrier indésirable ou non). Cette cartographie fonctionnelle est ensuite utilisée pour prédire la sortie des données inédites.
Il existe globalement deux types de cas d'utilisation de l'apprentissage supervisé :
Dans une prochaine section, nous examinerons plus en détail des algorithmes d'apprentissage supervisé spécifiques et certains de leurs cas d'utilisation.
Au lieu d'apprendre des modèles qui mettent en correspondance les entrées et les sorties, les algorithmes d'apprentissage non supervisé découvrent des modèles généraux dans les données sans qu'on leur montre explicitement les sorties. Les algorithmes d'apprentissage non supervisés sont couramment utilisés pour grouper et regrouper différents objets et entités. La segmentation de la clientèle est un excellent exemple d'apprentissage non supervisé. Les entreprises ont souvent plusieurs profils de clients qu'elles servent. Les entreprises souhaitent souvent adopter une approche factuelle pour identifier leurs segments de clientèle afin de mieux les servir. C'est là qu'intervient l'apprentissage non supervisé.
Dans ce cas d'utilisation, un algorithme d'apprentissage non supervisé apprendrait à regrouper les clients en fonction de divers attributs, tels que le nombre de fois qu'ils ont utilisé un produit, leurs données démographiques, la façon dont ils interagissent avec les produits, etc. Ensuite, le même algorithme peut prédire le segment probable auquel appartiennent les nouveaux clients sur la base des mêmes dimensions.
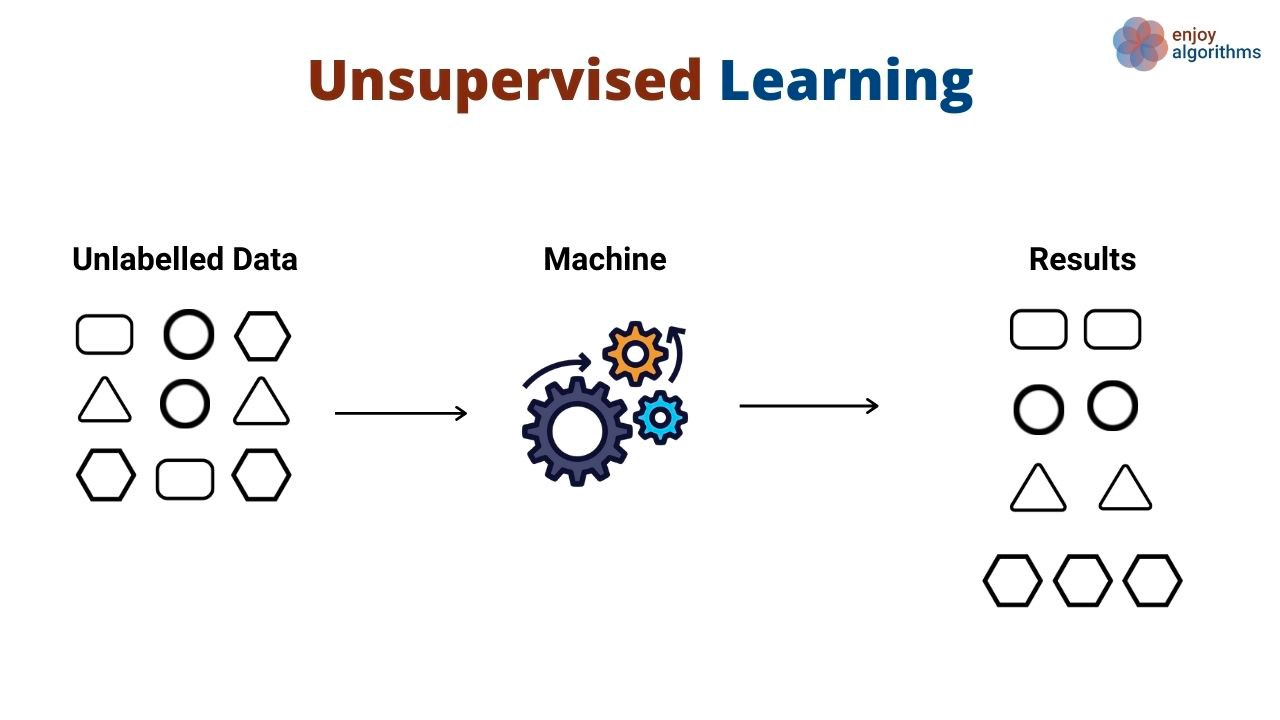
Les algorithmes non supervisés sont également utilisés pour réduire les dimensions d'un ensemble de données (c'est-à-dire le nombre de caractéristiques) en utilisant des techniques de réduction de la dimensionnalité. Ces algorithmes sont souvent utilisés comme étape intermédiaire dans la formation d'un algorithme d'apprentissage supervisé.
Lors de la formation des algorithmes d'apprentissage automatique, les scientifiques des données sont souvent confrontés à un compromis important : la performance par rapport à la précision prédictive. En règle générale, plus ils disposent d'informations sur un problème particulier, mieux c'est. Cependant, cela peut également entraîner des temps d'entraînement et des performances plus lents. Les techniques de réduction de la dimensionnalité permettent de réduire le nombre de caractéristiques présentes dans un ensemble de données sans sacrifier la valeur prédictive.
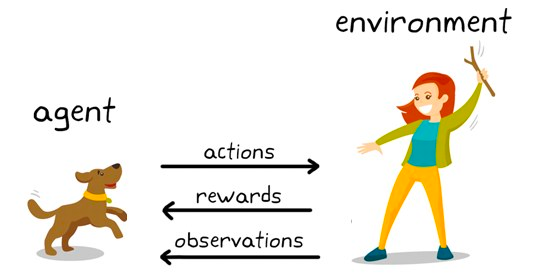
L'apprentissage par renforcement est un sous-ensemble d'algorithmes d'apprentissage automatique qui utilisent des récompenses pour favoriser un comportement ou une prédiction souhaités et une pénalité dans le cas contraire. Bien qu'il s'agisse encore d'un domaine de recherche au sein de l'apprentissage automatique, l'apprentissage par renforcement est à l'origine d'algorithmes qui dépassent l'intelligence humaine dans des jeux tels que les échecs, le jeu de go et bien d'autres.
Il s'agit d'une technique de modélisation comportementale dans laquelle le modèle apprend par le biais d'un mécanisme d'essais et d'erreurs au fur et à mesure qu'il interagit avec l'environnement. Illustrons cela par l'exemple des échecs. À un niveau élevé, un algorithme d'apprentissage par renforcement (souvent appelé agent) dispose d'un environnement (échiquier) dans lequel il peut prendre diverses décisions (coups).
Chaque mouvement est associé à un ensemble de scores, une récompense pour les actions qui conduisent l'agent à gagner, et une pénalité pour les mouvements qui conduisent l'agent à perdre.
L'agent continue d'interagir avec l'environnement pour apprendre les actions qui rapportent le plus et répète ces actions. Cette répétition du comportement promu est appelée la phase d'exploitation. Lorsque l'agent cherche de nouvelles voies pour obtenir des récompenses, on parle de phase d'exploration. Plus généralement, on parle de paradigme d'exploration-exploitation.
L'apprentissage auto-supervisé est une technique d'apprentissage automatique peu gourmande en données, dans laquelle le modèle apprend à partir d'un ensemble de données non étiquetées. Comme le montre l'exemple ci-dessous, le premier modèle est alimenté par des images d'entrée non étiquetées, qu'il regroupe en utilisant les caractéristiques générées à partir de ces images.
Certains de ces exemples ont une forte probabilité d'appartenir aux groupes, d'autres non. La deuxième étape utilise les données étiquetées à haute fiabilité de la première étape pour former un classificateur qui tend à être plus puissant qu'une approche de regroupement en une seule étape.
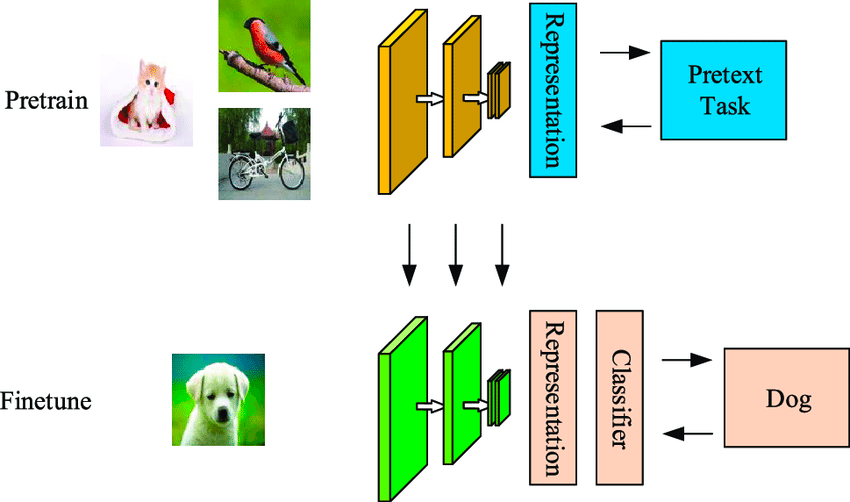
La différence entre les algorithmes auto-supervisés et supervisés réside dans le fait que les résultats classifiés dans le premier cas ne sont toujours pas associés à des objets réels. Il diffère de l'apprentissage supervisé car il ne dépend pas de l'ensemble étiqueté manuellement et génère des étiquettes par lui-même, d'où le nom d'auto-apprentissage.
Vous trouverez ci-dessous un aperçu des principaux algorithmes d'apprentissage automatique et de leurs cas d'utilisation les plus courants.
Un algorithme simple modélise une relation linéaire entre une ou plusieurs variables explicatives et une variable de sortie numérique continue. Il est plus rapide à former que les autres algorithmes d'apprentissage automatique. Son principal avantage réside dans sa capacité à expliquer et à interpréter les prédictions du modèle. Il s'agit d'un algorithme de régression utilisé pour prédire des résultats tels que la valeur du cycle de vie des clients, les prix de l'immobilier et les cours boursiers.
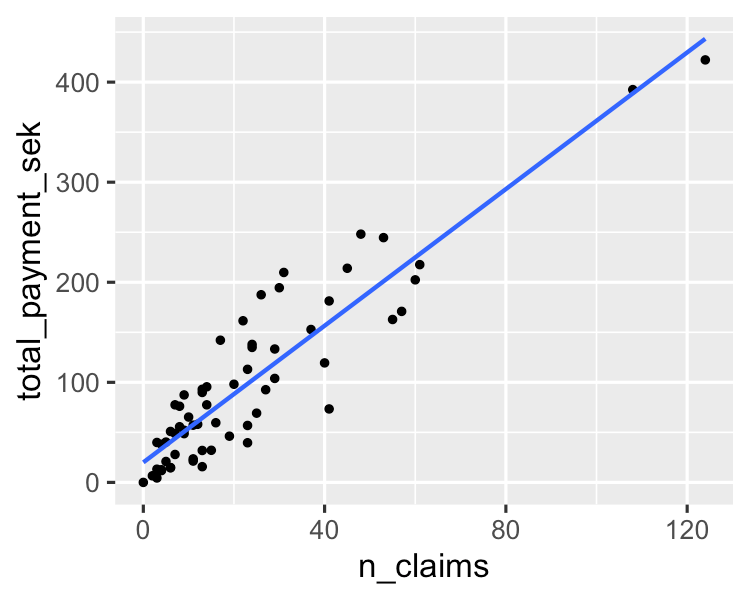
Vous pouvez en apprendre davantage à ce sujet dans ce tutoriel L'essentiel de la régression linéaire en Python. Si vous souhaitez mettre la main à la pâte en matière d'analyse de régression, ce cours très recherché sur DataCamp est la ressource qu'il vous faut.
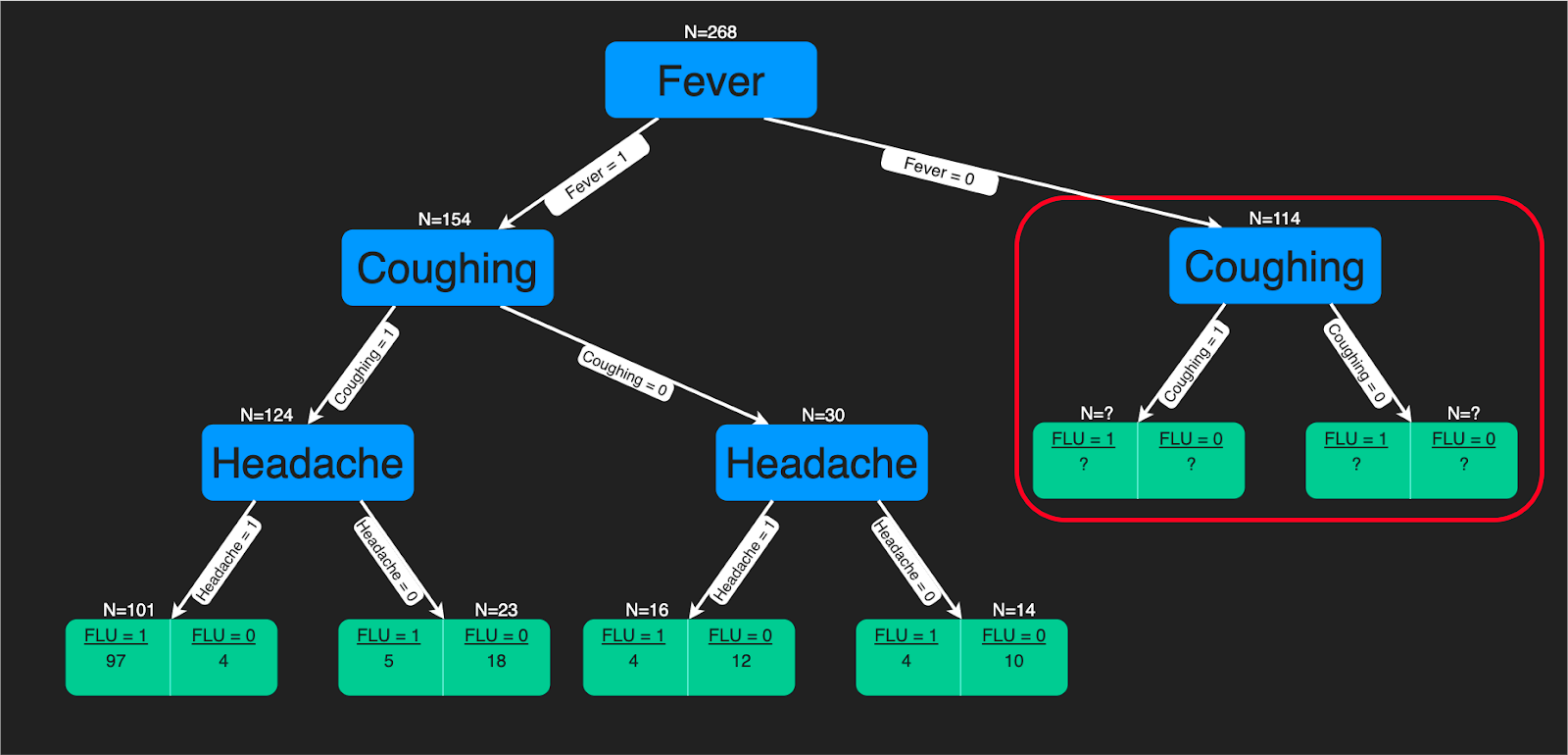
Un algorithme d'arbre de décision est une structure arborescente de règles de décision qui sont appliquées aux caractéristiques d'entrée pour prédire les résultats possibles. Il peut être utilisé pour la classification ou la régression. Les prédictions des arbres de décision constituent une aide précieuse pour les experts en soins de santé, car il est facile d'interpréter la manière dont ces prédictions sont faites.
Vous pouvez vous référer à ce tutoriel si vous souhaitez apprendre à construire un classificateur d'arbre de décision à l'aide de Python. De plus, si vous êtes plus à l'aise avec R, ce tutoriel vous sera utile. Il existe également un cours complet sur les arbres décisionnels sur DataCamp.
Il s'agit sans doute de l'un des algorithmes les plus populaires, qui s'appuie sur les inconvénients de l'ajustement excessif (overfitting) que l'on observe fréquemment dans les modèles d'arbres de décision. Il y a surajustement lorsque les algorithmes sont formés sur les données d'apprentissage un peu trop bien, et qu'ils ne parviennent pas à généraliser ou à fournir des prédictions précises sur des données inédites. La forêt aléatoire résout le problème de l'ajustement excessif en construisant plusieurs arbres de décision sur des échantillons de données sélectionnés de manière aléatoire. Le résultat final, sous la forme de la meilleure prédiction, est obtenu par le vote majoritaire de tous les arbres de la forêt.
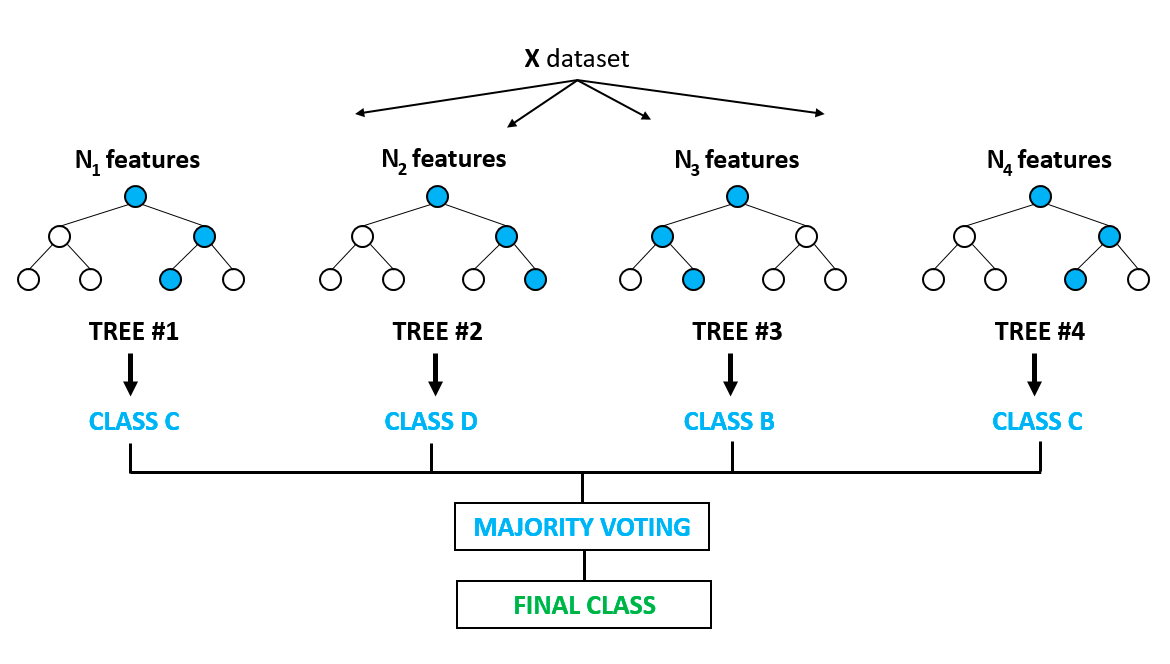
Il est utilisé pour les problèmes de classification et de régression. Il trouve des applications dans la sélection des caractéristiques, la détection des maladies, etc. Vous pouvez en apprendre davantage sur les modèles basés sur les arbres et les ensembles (combinant différents modèles individuels) grâce à ce cours très populaire sur DataCamp. Vous pouvez également en savoir plus dans ce tutoriel en Python sur la mise en œuvre du modèle de forêt aléatoire.
Les machines à vecteurs de support, communément appelées SVM, sont généralement utilisées pour les problèmes de classification. Comme le montre l'exemple ci-dessous, un SVM trouve un hyperplan (une ligne dans ce cas) qui sépare les deux classes (rouge et verte) et maximise la marge (distance entre les lignes pointillées) entre elles.
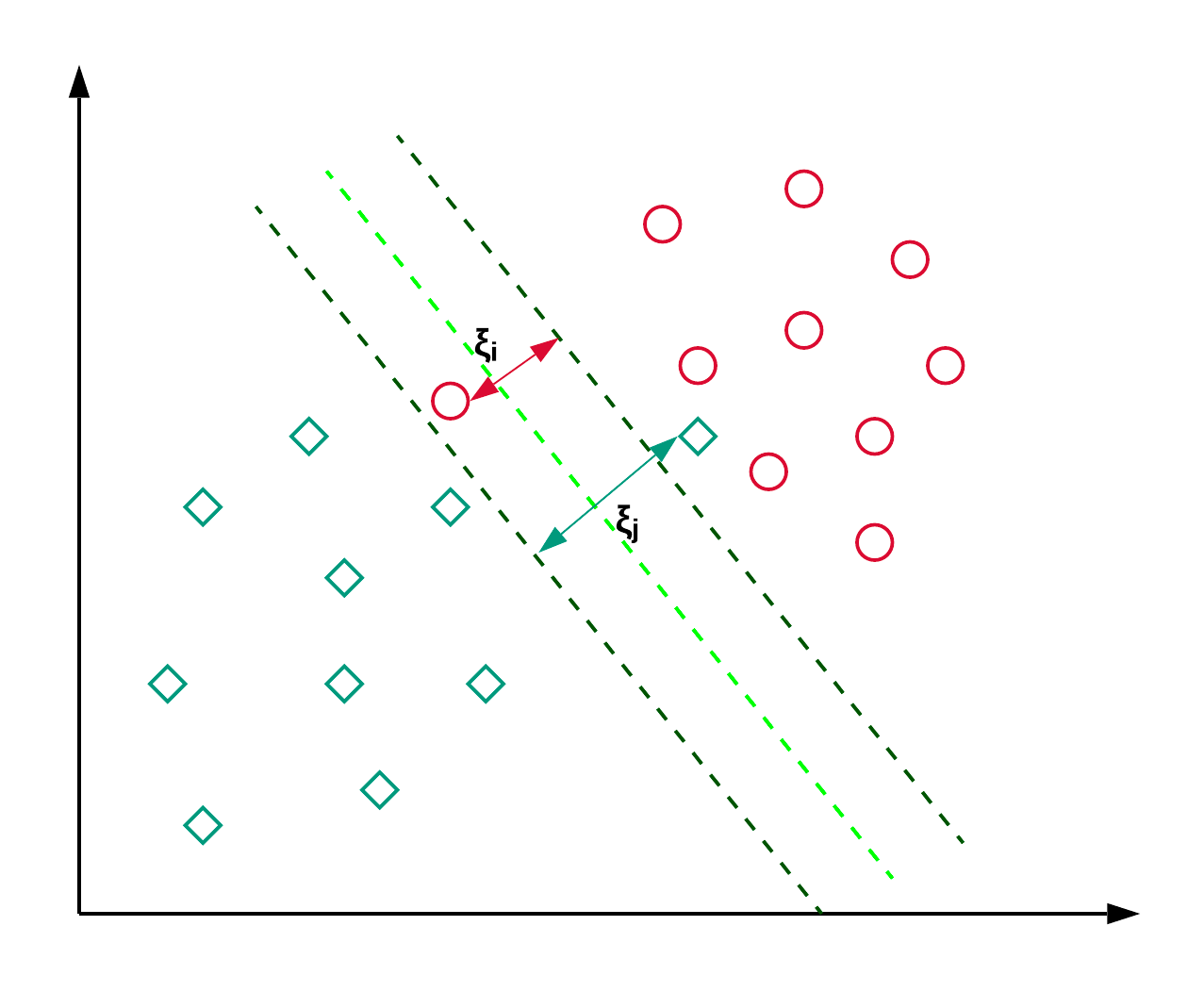
Les SVM sont généralement utilisés pour les problèmes de classification, mais ils peuvent également être employés pour les problèmes de régression. Il est utilisé pour classer les articles de presse et pour la reconnaissance de l'écriture manuscrite. Vous pouvez en savoir plus sur les différents types de noyaux ainsi que sur l'implémentation en python dans ce tutoriel scikit-learn sur les SVM. Vous pouvez également suivre ce tutoriel, qui vous permettra de reproduire l'implémentation du SVM dans R
La régression par amplification de gradient est un modèle d'ensemble qui combine plusieurs apprenants faibles pour créer un modèle prédictif robuste. Il permet de gérer les non-linéarités dans les données et les problèmes de multicolinéarité.
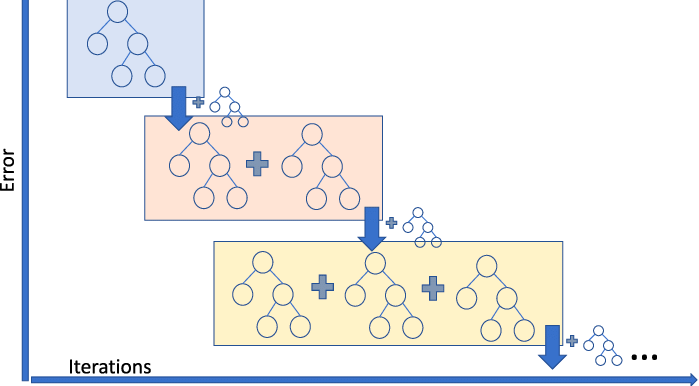
Si vous travaillez dans une entreprise de covoiturage et que vous devez prédire le montant de la course, vous pouvez utiliser un régresseur de renforcement du gradient. Si vous voulez comprendre les différentes saveurs du gradient boosting, alors vous pouvez regarder cette vidéo sur DataCamp.
K-Means est l'approche de regroupement la plus répandue. Elle détermine K groupes sur la base de la distance euclidienne. Il s'agit d'un algorithme très populaire pour la segmentation de la clientèle et les systèmes de recommandation.
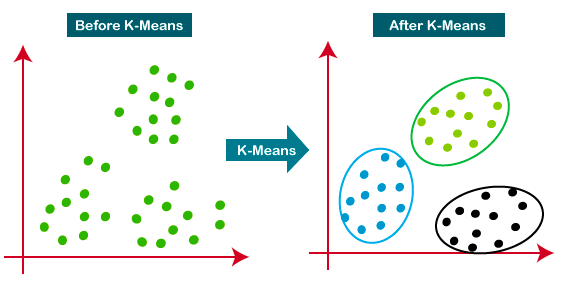
Ce tutoriel est une excellente ressource pour en savoir plus sur le regroupement K-means.
L'analyse en composantes principales (ACP) est une procédure statistique utilisée pour résumer les informations d'un grand ensemble de données en les projetant dans un sous-espace de dimension inférieure. Il s'agit également d'une technique de réduction de la dimensionnalité qui permet de conserver les parties essentielles des données contenant le plus d'informations.
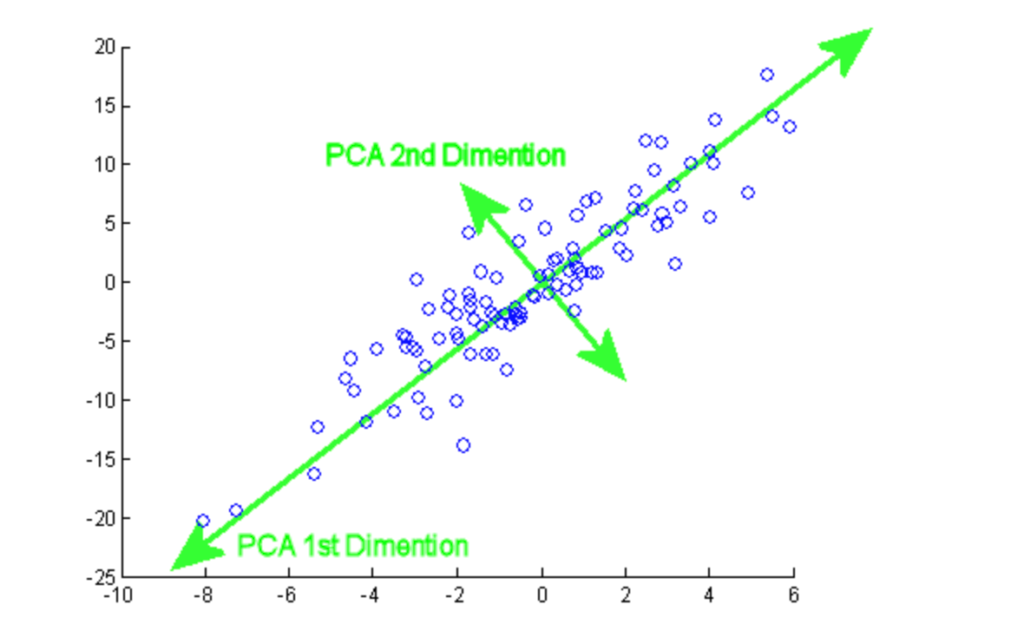
Ce tutoriel vous permettra de vous exercer à la mise en œuvre pratique de l'ACP sur deux ensembles de données populaires, Breast Cancer et CIFAR-10.
Il s'agit d'une approche ascendante dans laquelle chaque point de données est traité comme sa propre grappe, puis les deux grappes les plus proches sont fusionnées de manière itérative. Son principal avantage par rapport à la classification par K-moyennes est qu'elle n'exige pas que l'utilisateur spécifie le nombre prévu de grappes dès le départ. Il trouve son application dans le regroupement de documents basé sur la similarité.
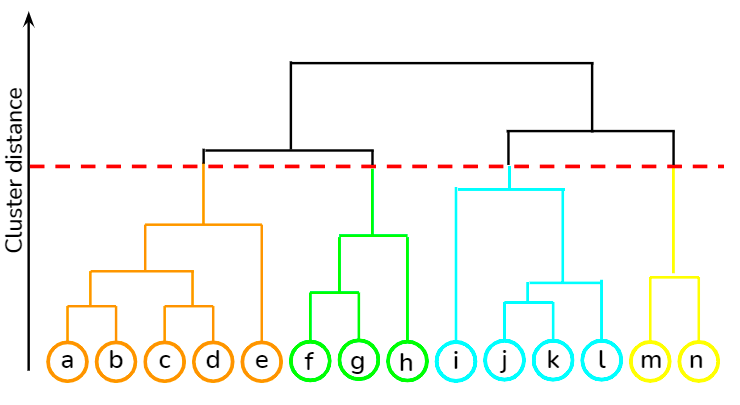
Vous pouvez apprendre diverses techniques d'apprentissage non supervisé, telles que le clustering hiérarchique et le clustering K-means, en utilisant la bibliothèque scipy à partir de ce cours à DataCamp. En outre, vous pouvez également apprendre à appliquer des techniques de clustering pour générer des informations à partir de données non étiquetées en utilisant R dans ce cours.
Il s'agit d'un modèle probabiliste permettant de modéliser des grappes normalement distribuées au sein d'un ensemble de données. Il diffère des algorithmes de regroupement standard en ce sens qu'il estime la probabilité qu'une observation appartienne à un regroupement particulier et qu'il se lance ensuite dans la réalisation d'inférences sur sa sous-population.
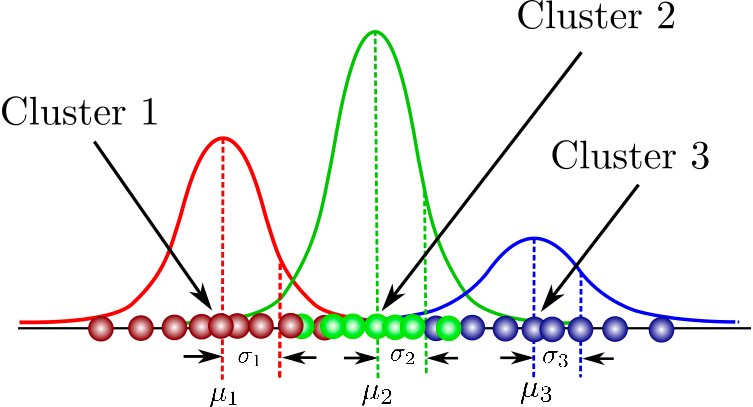
Vous trouverez ici une liste de cours couvrant les concepts fondamentaux du regroupement basé sur un modèle, la structure des modèles de mélange et bien d'autres choses encore. Vous aurez également l'occasion de vous exercer à la modélisation de mélanges gaussiens à l'aide du progiciel flexmix.
Une approche basée sur des règles qui identifie l'ensemble d'éléments le plus fréquent dans un ensemble de données donné, où la connaissance préalable des propriétés des ensembles d'éléments fréquents est utilisée. L'analyse du panier de marché utilise cet algorithme pour aider des géants tels qu'Amazon et Netflix à traduire les masses d'informations sur leurs utilisateurs en règles simples de recommandations de produits. Il analyse les associations entre des millions de produits et découvre des règles pertinentes.
DataCamp propose un cours complet sur les deux langages - Python et R.
L'apprentissage automatique n'est plus un simple mot à la mode. De nombreuses organisations déploient des modèles d'apprentissage automatique et réalisent déjà des gains grâce aux informations prédictives. Il va sans dire que le marché est très demandeur de praticiens hautement qualifiés dans le domaine de l'apprentissage automatique. Vous trouverez ci-dessous une liste de ressources qui peuvent vous aider à vous familiariser rapidement avec les concepts de l'apprentissage automatique :
Lancez-vous dans l'apprentissage automatique
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree

