Kursus
Machine Learning dengan Model Berbasis Pohon di Python
5 Hr
117.2K
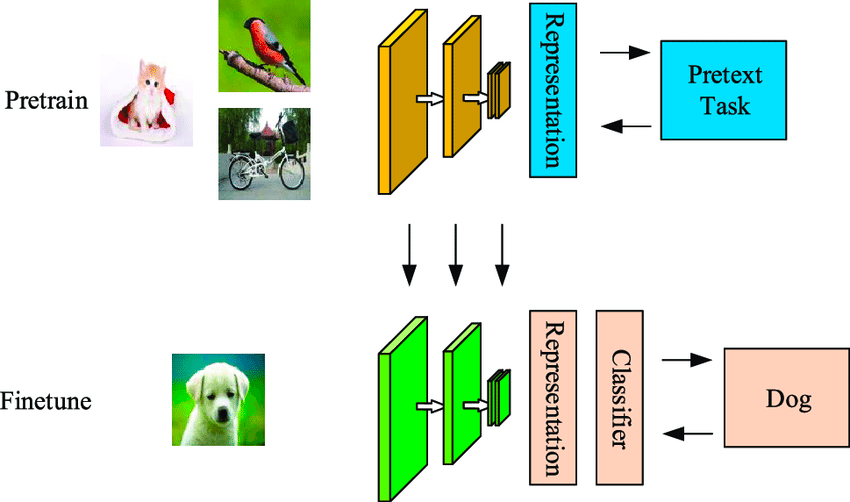
Machine learning dapat dibilang bertanggung jawab atas use case paling menonjol dan terlihat dari data science dan kecerdasan buatan. Dari mobil self-driving Tesla hingga algoritme AlphaFold milik DeepMind, solusi berbasis machine learning telah menghasilkan capaian yang menakjubkan dan memicu antusiasme besar. Namun, sebenarnya apa itu machine learning? Bagaimana cara kerjanya? Dan yang terpenting, benarkah hype-nya sepadan? Artikel ini memberikan definisi intuitif tentang algoritme machine learning utama, menguraikan beberapa penerapannya, dan menyediakan sumber daya untuk memulai machine learning.
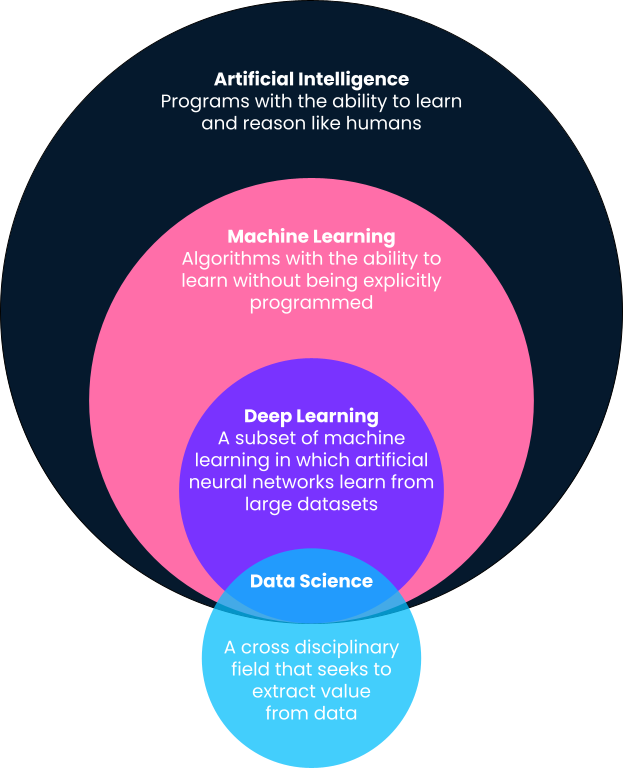
Singkatnya, machine learning adalah sub-bidang dari kecerdasan buatan di mana komputer memberikan prediksi berdasarkan pola yang dipelajari langsung dari data tanpa diprogram secara eksplisit untuk melakukannya. Anda akan melihat dalam definisi ini bahwa machine learning adalah sub-bidang dari kecerdasan buatan. Karena itu, mari kita uraikan definisinya lebih detail, karena sering kali istilah seperti machine learning, kecerdasan buatan, deep learning, dan bahkan data science digunakan secara bergantian.
Salah satu definisi terbaik tentang kecerdasan buatan datang dari Andrew Ng, salah satu pendiri Google Brain dan mantan Chief Scientist di Baidu. Menurut Andrew, kecerdasan buatan adalah “sekumpulan besar alat untuk membuat komputer berperilaku cerdas.” Ini dapat mencakup apa pun mulai dari sistem yang didefinisikan secara eksplisit seperti kalkulator hingga solusi berbasis machine learning seperti pendeteksi email spam.
Seperti diuraikan di atas, machine learning adalah sub-bidang kecerdasan buatan di mana algoritme mempelajari pola dari data historis dan memberikan prediksi berdasarkan pola yang dipelajari tersebut dengan menerapkannya pada data baru. Secara tradisional, sistem cerdas yang sederhana seperti kalkulator diprogram secara eksplisit oleh pengembang sebagai langkah dan prosedur yang jelas (mis., jika ini, maka itu). Namun, ini tidak dapat diskalakan atau dimungkinkan untuk masalah yang lebih maju.
Ambil contoh filter spam email. Pengembang dapat mencoba membuat filter spam dengan mendefinisikannya secara eksplisit. Misalnya, mereka dapat mendefinisikan program yang memicu filter spam jika email memiliki subjek tertentu atau berisi tautan tertentu. Namun, sistem ini akan menjadi tidak efektif segera setelah pelaku spam mengubah taktiknya.
Di sisi lain, solusi berbasis machine learning akan memasukkan jutaan email spam sebagai data masukan, mempelajari karakteristik paling umum dari email spam melalui asosiasi statistik, dan membuat prediksi pada email di masa depan berdasarkan karakteristik yang telah dipelajari.
Deep learning adalah sub-bidang dari machine learning dan mungkin bertanggung jawab atas use case machine learning yang paling terlihat di budaya populer. Algoritme deep learning terinspirasi oleh struktur otak manusia dan memerlukan jumlah data yang sangat besar untuk pelatihan. Algoritme ini sering digunakan untuk masalah “kognitif” yang paling kompleks, seperti deteksi ucapan, penerjemahan bahasa, mobil self-driving, dan banyak lagi. Lihat perbandingan kami tentang deep learning vs machine learning untuk konteks lebih lanjut.
Berbeda dengan machine learning, kecerdasan buatan, dan deep learning, data science memiliki definisi yang cukup luas. Singkatnya, data science adalah tentang mengekstrak nilai dan wawasan dari data. Nilai tersebut bisa berupa model prediktif yang menggunakan machine learning, tetapi juga bisa berarti menampilkan wawasan melalui dasbor atau laporan. Baca lebih lanjut tentang tugas harian data scientist dalam artikel ini.
Di luar deteksi spam email, beberapa aplikasi machine learning yang banyak dikenal antara lain segmentasi pelanggan berdasarkan data demografis (penjualan dan pemasaran), prediksi harga saham (keuangan), otomatisasi persetujuan klaim (asuransi), rekomendasi konten berdasarkan riwayat tontonan (media & hiburan), dan banyak lagi. Machine learning kini ada di mana-mana dan menemukan beragam penerapan dalam kehidupan sehari-hari kita.
Di akhir artikel ini, kami akan membagikan banyak sumber daya untuk memulai dengan machine learning.
Sekarang kami telah memberikan gambaran umum tentang machine learning dan posisinya di antara kata-kata populer lain yang mungkin Anda temui di bidang ini, mari kita melihat lebih dalam berbagai jenis algoritme machine learning. Algoritme machine learning secara umum dikategorikan menjadi supervised, unsupervised, reinforcement, dan self-supervised learning. Mari kita pahami lebih detail dan use case paling umum dari masing-masing.
Kebanyakan use case machine learning berkisar pada algoritme yang mempelajari pola dari data historis dan menerapkannya pada data baru dalam bentuk prediksi. Ini sering disebut sebagai supervised learning. Algoritme supervised learning ditunjukkan masukan dan keluaran historis pada suatu masalah tertentu yang ingin kita pecahkan, di mana masukan pada dasarnya adalah fitur atau dimensi dari observasi yang ingin kita prediksi, dan keluaran adalah hasil yang ingin kita prediksi. Mari kita ilustrasikan dengan contoh deteksi spam kita.
Dalam use case deteksi spam, algoritme supervised learning akan dilatih pada dataset email spam. Masukannya berupa fitur atau dimensi tentang email, seperti subjek email, alamat email pengirim, konten email, apakah email berisi tautan yang terlihat berbahaya, dan informasi relevan lain yang dapat memberi petunjuk apakah sebuah email spam.
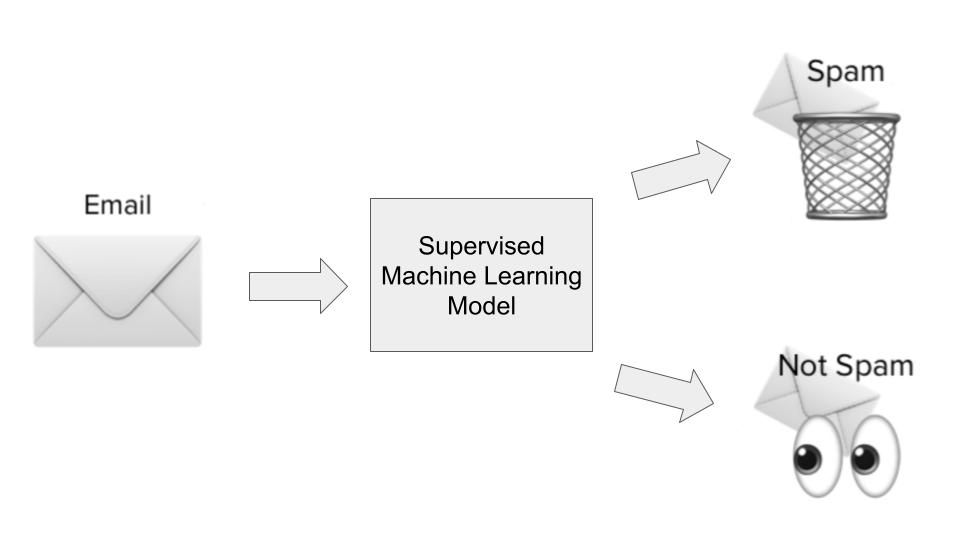
Keluaran yang diharapkan adalah apakah email tersebut benar-benar spam atau bukan. Selama fase pembelajaran model, algoritme mempelajari fungsi untuk memetakan hubungan statistik antara kumpulan variabel input (berbagai dimensi email spam) dan variabel output (apakah itu spam atau bukan). Pemetaan fungsional ini kemudian digunakan untuk memprediksi keluaran dari data yang sebelumnya belum pernah dilihat.
Secara umum ada dua jenis use case supervised learning:
Pada bagian berikutnya, kita akan melihat algoritme supervised learning tertentu dan beberapa use case-nya secara lebih rinci.
Alih-alih mempelajari pola yang memetakan masukan ke keluaran, algoritme unsupervised learning menemukan pola umum dalam data tanpa ditunjukkan keluaran secara eksplisit. Algoritme unsupervised learning biasanya digunakan untuk mengelompokkan dan mengklaster berbagai objek dan entitas. Contoh bagus dari unsupervised learning adalah segmentasi pelanggan. Perusahaan sering memiliki beragam persona pelanggan yang mereka layani. Organisasi sering kali menginginkan pendekatan berbasis fakta untuk mengidentifikasi segmen pelanggan agar dapat melayani mereka dengan lebih baik. Di sinilah unsupervised learning berperan.
Pada use case ini, algoritme unsupervised learning akan mempelajari pengelompokan pelanggan berdasarkan berbagai atribut, seperti seberapa sering mereka menggunakan produk, demografi, bagaimana mereka berinteraksi dengan produk, dan lainnya. Lalu, algoritme yang sama dapat memprediksi segmen mana yang kemungkinan menjadi milik pelanggan baru berdasarkan dimensi yang sama.
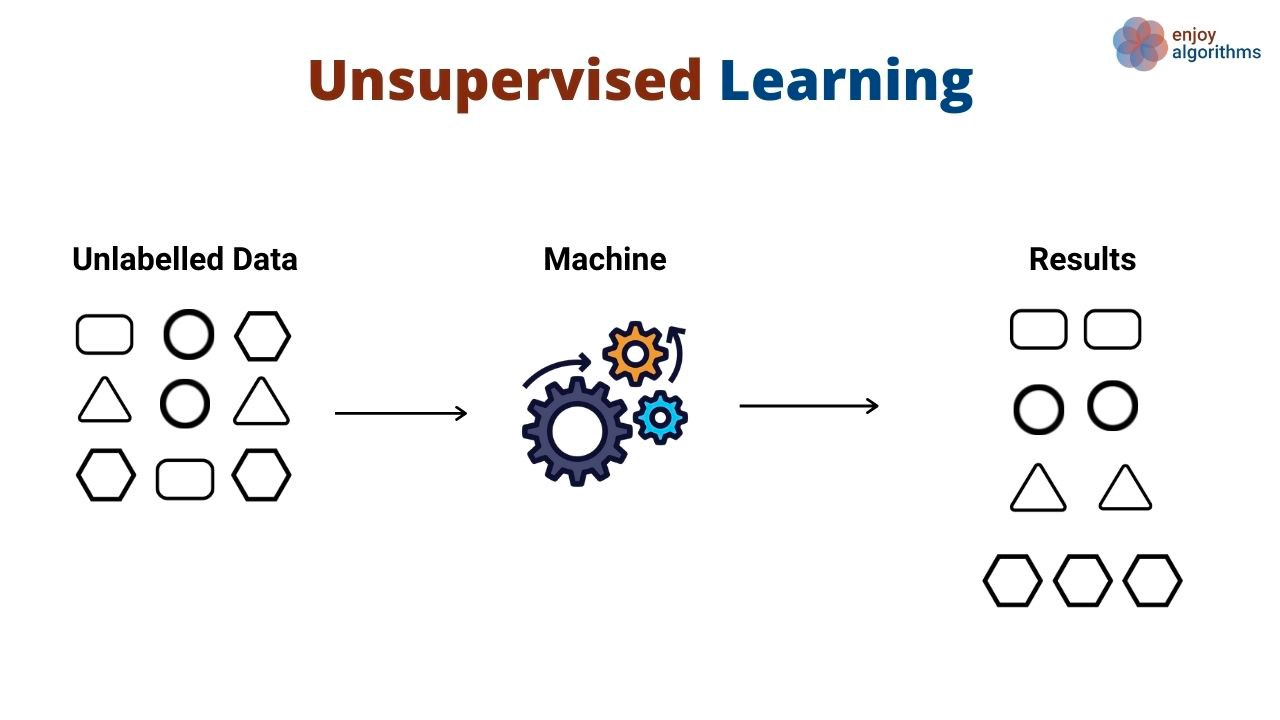
Algoritme unsupervised juga digunakan untuk mengurangi dimensi dalam sebuah dataset (yaitu jumlah fitur) dengan menggunakan teknik reduksi dimensi. Algoritme ini sering digunakan sebagai langkah perantara dalam melatih algoritme supervised learning.
Salah satu pertukaran besar yang sering dihadapi data scientist saat melatih algoritme machine learning adalah kinerja vs akurasi prediktif. Secara umum, semakin banyak informasi yang dimiliki tentang suatu masalah, semakin baik. Namun, itu juga dapat menyebabkan waktu pelatihan yang lambat dan kinerja yang menurun. Teknik reduksi dimensi membantu mengurangi jumlah fitur dalam sebuah dataset tanpa mengorbankan nilai prediktif.
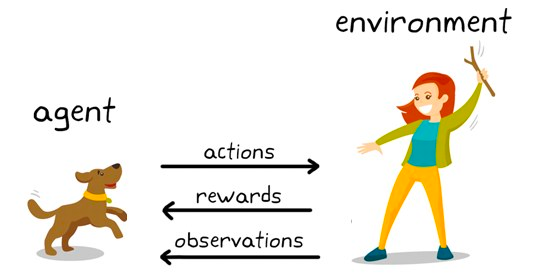
Reinforcement learning adalah subset algoritme machine learning yang memanfaatkan penghargaan untuk mendorong perilaku atau prediksi yang diinginkan dan penalti sebaliknya. Meskipun relatif masih menjadi area riset dalam machine learning, reinforcement learning bertanggung jawab atas algoritme yang melampaui kecerdasan tingkat manusia dalam permainan seperti Catur, Go, dan lainnya.
Ini adalah teknik pemodelan perilaku di mana model belajar melalui mekanisme coba-coba saat terus berinteraksi dengan lingkungan. Mari kita ilustrasikan dengan contoh catur. Pada tingkat tinggi, algoritme reinforcement learning (sering disebut agen) disediakan sebuah lingkungan (papan catur) di mana ia dapat membuat berbagai keputusan (melakukan langkah).
Setiap langkah memiliki seperangkat skor terkait, penghargaan untuk aksi yang membuat agen menang, dan penalti untuk langkah yang membuat agen kalah.
Agen terus berinteraksi dengan lingkungan untuk mempelajari tindakan yang menghasilkan penghargaan paling besar dan terus mengulang tindakan tersebut. Pengulangan perilaku yang dipromosikan ini disebut fase eksploitasi. Ketika agen mencari jalan baru untuk memperoleh penghargaan, ini disebut fase eksplorasi. Secara umum, ini disebut paradigma eksplorasi-eksploitasi.
Self-supervised learning adalah teknik machine learning yang efisien terhadap data, di mana model belajar dari sampel dataset tanpa label. Seperti ditunjukkan pada contoh di bawah, model pertama diberi masukan berupa beberapa gambar tanpa label, yang kemudian dikelompokkannya menggunakan fitur yang dihasilkan dari gambar-gambar tersebut.
Beberapa contoh ini akan memiliki keyakinan tinggi termasuk ke dalam klaster, sementara yang lain tidak. Langkah kedua menggunakan data berlabel berkepastian tinggi dari langkah pertama untuk melatih sebuah pengklasifikasi yang cenderung lebih kuat daripada pendekatan klastering satu langkah.
Perbedaan antara algoritme self-supervised dan supervised adalah bahwa keluaran yang diklasifikasikan pada yang pertama tetap tidak akan memiliki kelas yang dipetakan ke objek nyata. Ini berbeda dari supervised learning karena tidak bergantung pada kumpulan data berlabel secara manual dan menghasilkan labelnya sendiri, karenanya disebut pembelajaran mandiri.
Di bawah ini, kami menguraikan beberapa algoritme machine learning teratas dan use case paling umum dari masing-masing.
Algoritme sederhana yang memodelkan hubungan linear antara satu atau lebih variabel penjelas dan variabel keluaran numerik kontinu. Pelatihannya lebih cepat dibandingkan algoritme machine learning lainnya. Keuntungan terbesarnya terletak pada kemampuannya menjelaskan dan menafsirkan prediksi model. Ini adalah algoritme regresi yang digunakan untuk memprediksi hasil seperti nilai seumur hidup pelanggan, harga rumah, dan harga saham.
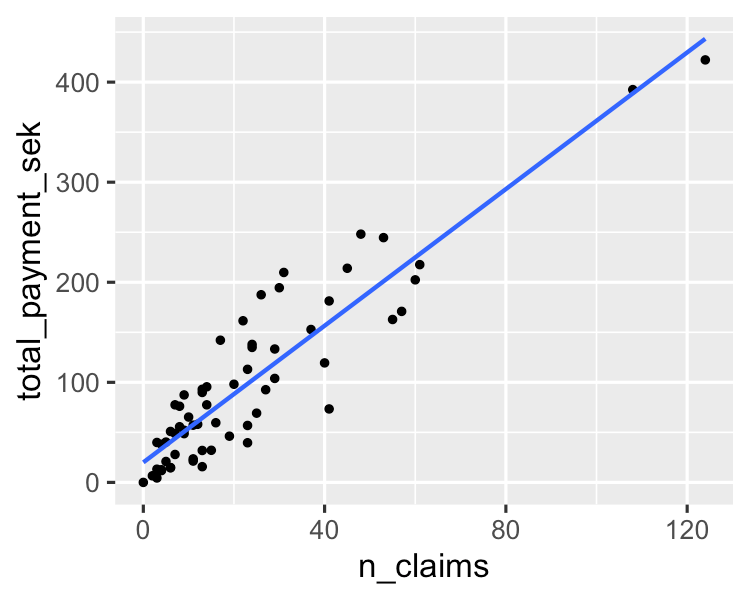
Anda dapat mempelajarinya lebih lanjut dalam tutorial esensial regresi linear di Python ini. Jika Anda tertarik untuk praktik langsung dengan analisis regresi, kursus yang sangat diminati di DataCamp ini adalah sumber yang tepat untuk Anda.
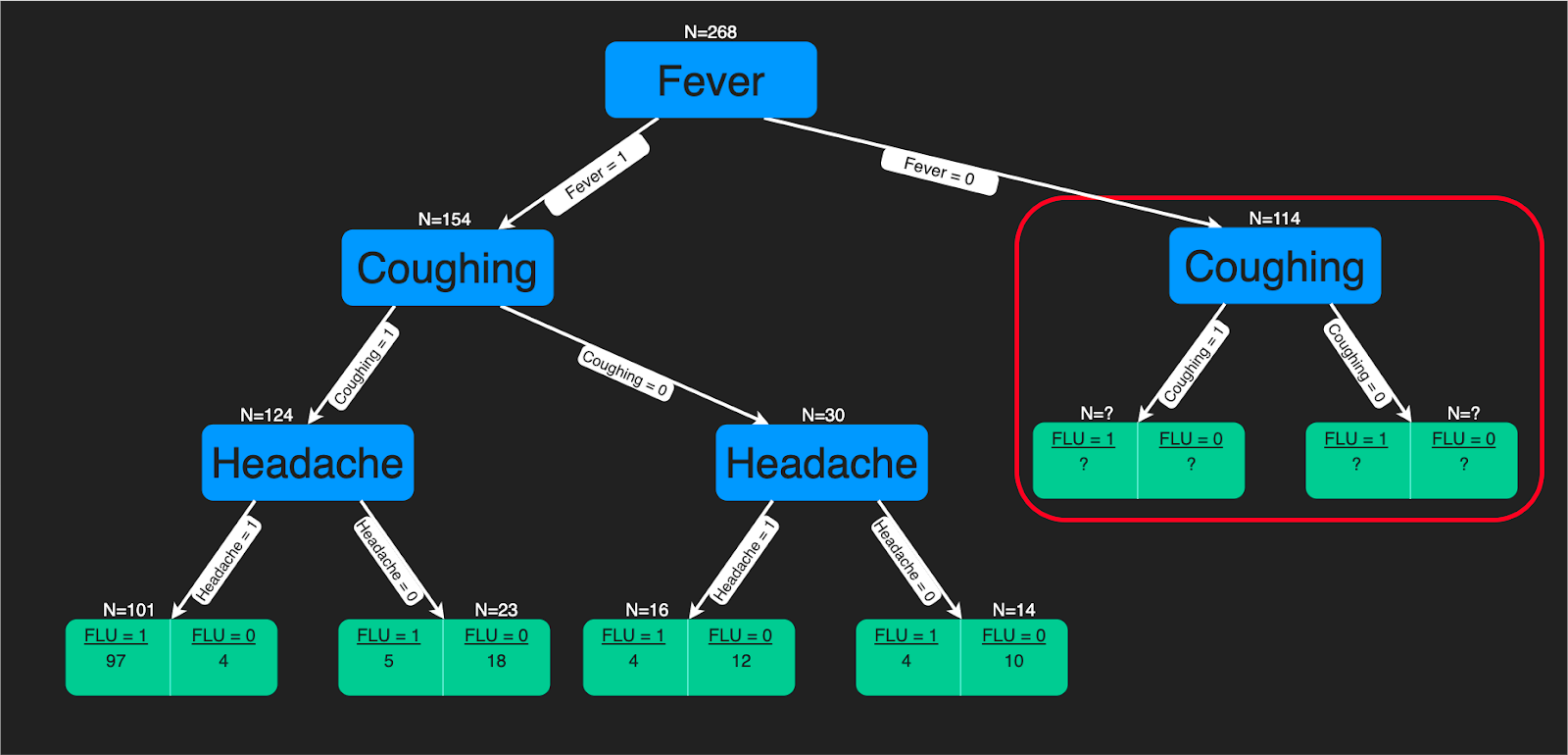
Algoritme decision tree adalah struktur seperti pohon dari aturan keputusan yang diterapkan pada fitur masukan untuk memprediksi kemungkinan hasil. Algoritme ini dapat digunakan untuk klasifikasi atau regresi. Prediksi decision tree sangat membantu pakar kesehatan karena cara pembuatannya mudah ditafsirkan.
Anda dapat merujuk ke tutorial ini jika tertarik mempelajari cara membangun pengklasifikasi decision tree menggunakan Python. Jika Anda lebih nyaman menggunakan R, Anda akan diuntungkan dengan tutorial ini. Tersedia juga kursus decision tree komprehensif di DataCamp.
Ini mungkin salah satu algoritme paling populer dan dibangun untuk mengatasi kelemahan overfitting yang menonjol pada model decision tree. Overfitting adalah ketika algoritme dilatih pada data pelatihan terlalu baik, sehingga gagal menggeneralisasi atau memberikan prediksi akurat pada data yang belum pernah dilihat. Random forest memecahkan masalah overfitting dengan membangun banyak decision tree pada sampel yang dipilih secara acak dari data. Hasil akhir berupa prediksi terbaik diturunkan dari pemungutan suara mayoritas dari semua pohon di hutan.
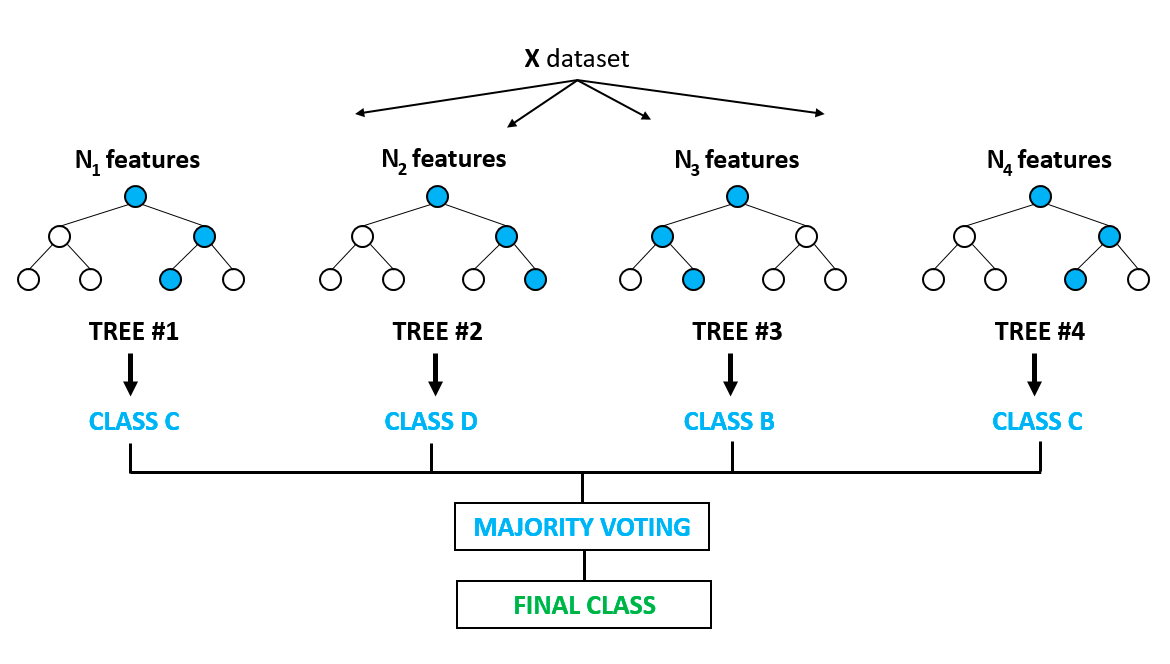
Algoritme ini digunakan untuk masalah klasifikasi dan regresi. Penerapannya mencakup pemilihan fitur, deteksi penyakit, dan lain-lain. Anda dapat mempelajari lebih lanjut tentang model berbasis pohon dan ensemble (menggabungkan berbagai model individual) dari kursus yang sangat populer di DataCamp ini. Anda juga dapat mempelajari lebih lanjut dalam tutorial berbasis Python tentang implementasi model random forest.
Support Vector Machines, yang biasa dikenal sebagai SVM, umumnya digunakan untuk masalah klasifikasi. Seperti ditunjukkan pada contoh di bawah, SVM menemukan sebuah hyperplane (garis pada kasus ini) yang memisahkan dua kelas (merah dan hijau) dan memaksimalkan margin (jarak antara garis putus-putus) di antara keduanya.
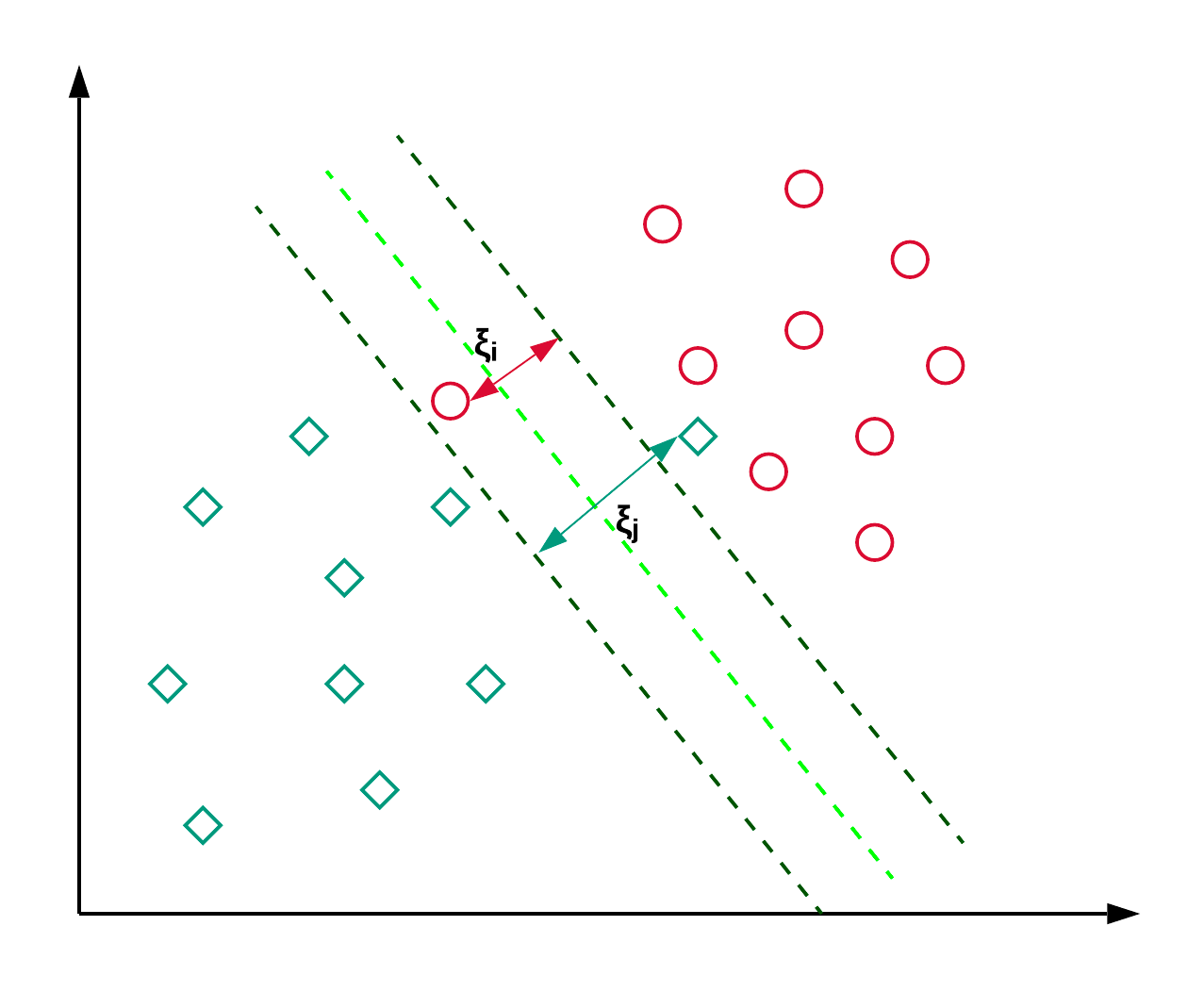
SVM umumnya digunakan untuk masalah klasifikasi tetapi juga dapat diterapkan pada masalah regresi. Algoritme ini digunakan untuk mengklasifikasikan artikel berita dan pengenalan tulisan tangan. Anda dapat membaca lebih lanjut tentang berbagai jenis trik kernel beserta implementasi python-nya dalam tutorial SVM scikit-learn ini. Anda juga dapat mengikuti tutorial ini, di mana Anda akan mereplikasi implementasi SVM di R
Gradient Boosting Regression adalah model ensemble yang menggabungkan beberapa weak learner untuk membuat model prediktif yang kuat. Model ini bagus dalam menangani non-linearitas pada data dan masalah multikolinearitas.
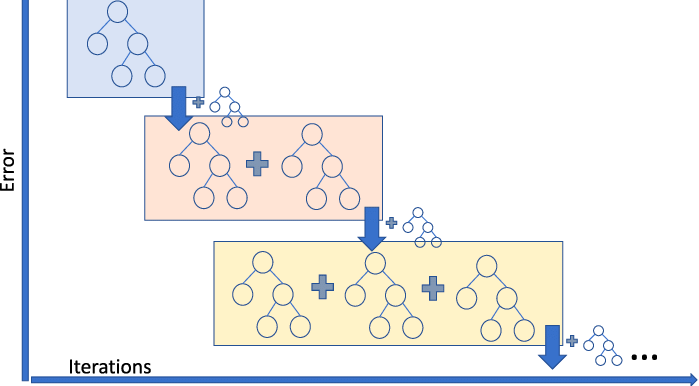
Jika Anda berada di bisnis ride sharing dan perlu memprediksi besaran tarif perjalanan, Anda dapat menggunakan gradient boosting regressor. Jika Anda ingin memahami ragam metode gradient boosting, Anda dapat menonton video ini di DataCamp.
K-Means adalah pendekatan klastering yang paling banyak digunakan—ia menentukan K klaster berdasarkan jarak Euclidean. Ini adalah algoritme yang sangat populer untuk segmentasi pelanggan dan sistem rekomendasi.
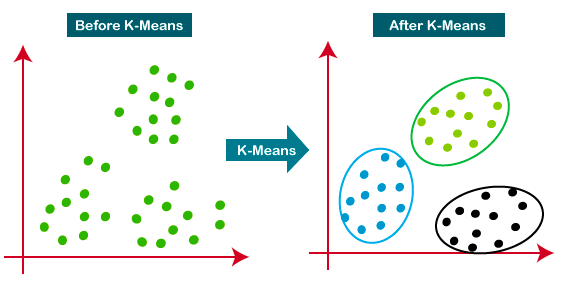
Tutorial ini adalah sumber yang bagus untuk mempelajari lebih lanjut tentang klastering K-means.
Principal component analysis (PCA) adalah prosedur statistik yang digunakan untuk merangkum informasi dari kumpulan data besar dengan memproyeksikannya ke subruang berdimensi lebih rendah. Ini juga disebut teknik reduksi dimensi yang memastikan bagian esensial dari data dengan informasi lebih tinggi tetap dipertahankan.
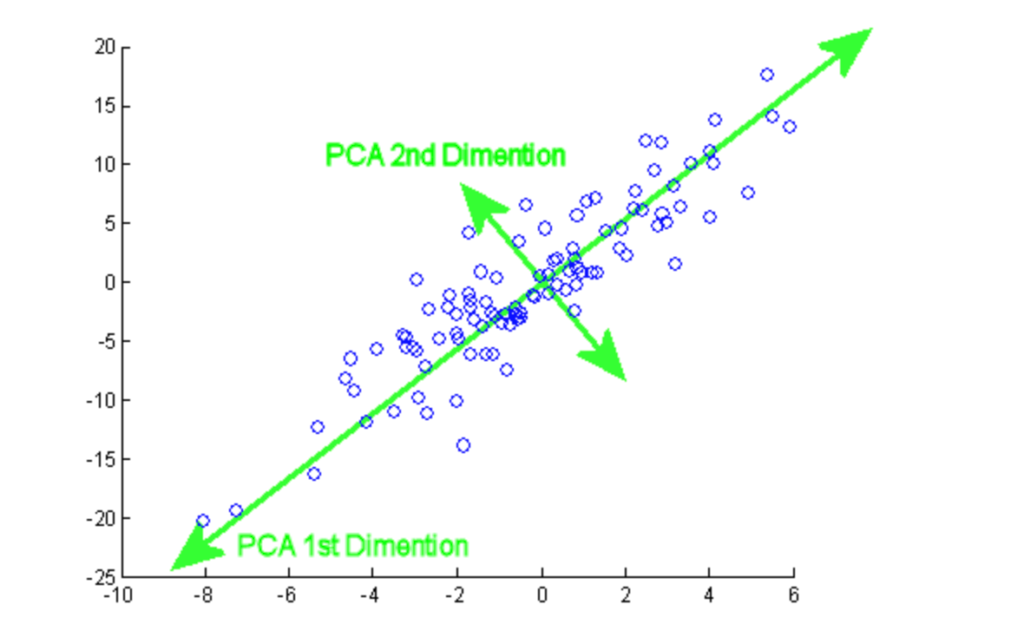
Dari tutorial ini, Anda dapat berlatih implementasi PCA secara langsung pada dua dataset populer, Breast Cancer dan CIFAR-10.
Ini adalah pendekatan bottom-up di mana setiap titik data diperlakukan sebagai klasternya sendiri, lalu dua klaster terdekat digabungkan secara iteratif. Keuntungan terbesarnya dibandingkan klastering K-means adalah tidak mengharuskan pengguna menentukan jumlah klaster yang diharapkan sejak awal. Algoritme ini diterapkan pada pengelompokan dokumen berdasarkan kesamaan.
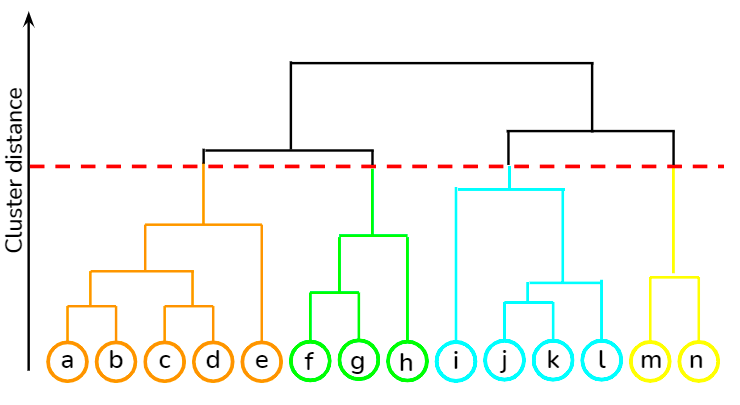
Anda dapat mempelajari berbagai teknik unsupervised learning, seperti hierarchical clustering dan K-means clustering, menggunakan pustaka scipy dari kursus di DataCamp. Selain itu, Anda juga dapat mempelajari cara menerapkan teknik klastering untuk menghasilkan wawasan dari data tanpa label menggunakan R dari kursus ini.
Ini adalah model probabilistik untuk memodelkan klaster yang berdistribusi normal dalam sebuah dataset. Ini berbeda dari algoritme klastering standar karena memperkirakan probabilitas sebuah observasi termasuk ke dalam klaster tertentu dan kemudian menelusuri pembuatan inferensi tentang subpopulasinya.
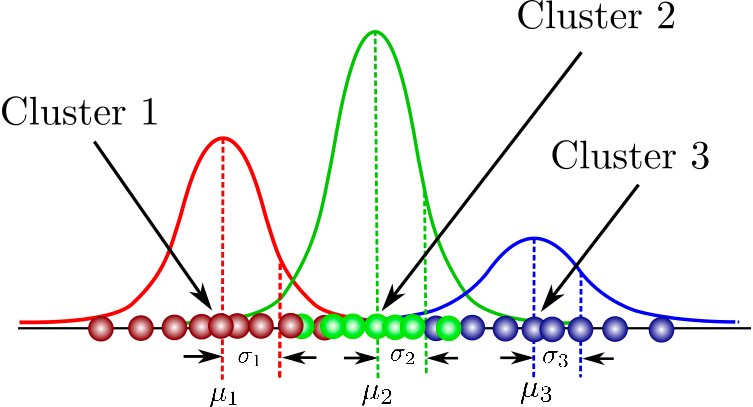
Anda dapat menemukan kumpulan kursus satu pintu di sini yang mencakup konsep fundamental dalam model-based clustering, struktur Mixture Models, dan seterusnya. Anda juga akan berlatih pemodelan gaussian mixture secara langsung menggunakan paket flexmix.
Pendekatan berbasis aturan yang mengidentifikasi itemset paling sering dalam sebuah dataset tertentu di mana pengetahuan awal tentang properti itemset yang sering digunakan. Analisis keranjang belanja menggunakan algoritme ini untuk membantu raksasa seperti Amazon dan Netflix menerjemahkan tumpukan informasi tentang penggunanya menjadi aturan sederhana rekomendasi produk. Algoritme ini menganalisis asosiasi antara jutaan produk dan mengungkap aturan yang berwawasan.
DataCamp menyediakan kursus komprehensif dalam kedua bahasa—Python dan R.
Machine learning bukan sekadar kata populer lagi. Banyak organisasi menerapkan model machine learning dan sudah merasakan manfaat dari wawasan prediktif. Tak perlu dikatakan, ada banyak permintaan bagi praktisi machine learning yang sangat terampil di pasar. Di bawah ini, Anda akan menemukan daftar sumber daya yang dapat dengan cepat membantu Anda mulai meningkatkan keterampilan konsep machine learning:
Mulai belajar machine learning
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
