
Program
AI Temelleri
10 sa
Bir bilgisayara elma ile portakal arasındaki farkı öğretmeye çalıştığınızı hayal edin. Bizim için kavraması kolaydır, ancak yalnızca sayıları anlamak üzere tasarlanmış bir makine için bu karmaşık bir zorluktur.
İşte vektör gömlemeleri devreye girer. Bu matematiksel hileler, kelimeleri, görselleri ve diğer verileri bilgisayarların kolayca anlayıp işleyebileceği sayısal temsillere dönüştürür.
Vektör gömlemeleri, bilgi dünyasını sayısal bir uzaya haritalayarak olasılıkların bir evrenini açar.
Vektör gömlemeleri, kelimeler veya diğer veri parçaları için dijital parmak izleridir. Harfler veya görseller yerine, vektör adı verilen belirli bir yapıda düzenlenmiş sayıları kullanırlar; bu, değerlerin sıralı bir listesi gibidir.
Her vektörü, konumunun temsil edilen kelime veya veri hakkında hayati bilgiler taşıdığı çok boyutlu bir uzaydaki bir nokta olarak hayal edin.
Matematik derslerinizden vektörleri yönü ve büyüklüğü olan oklar olarak hatırlıyor olabilirsiniz. Vektör gömlemeleri bu temel kavramı paylaşsa da sayısız boyuta sahip uzaylarda çalışırlar.
Bu aşırı boyutluluk, ton, bağlam ve dilbilgisel özellikler gibi insan dilinin karmaşık nüanslarını yakalamak için gereklidir. "Happy" ve "sad" arasındaki farkı değil, aynı zamanda "ecstatic", "content" veya "melancholic" gibi ince varyasyonları da ayırt edebilen bir vektörü hayal edin.
Vektör gömlemeleri, karmaşık verileri makine öğrenimi algoritmaları için uygun bir formata dönüştürmekte değerli bir tekniktir. Yüksek boyutlu ve kategorik verileri daha düşük boyutlu, sürekli temsillere çevirerek, gömlemeler temel veri örüntülerini korurken model performansını ve hesaplama verimliliğini artırır.
Çok boyutlu bir vektör uzayının nasıl tanımlanabileceğine basitleştirilmiş bir bakış sunmak için, aşağıda sekiz örnek boyut ve ilgili değer aralığını gösteren bir tablo yer almaktadır:
|
Özellik |
Açıklama |
Aralık |
|
Somutluk |
Bir kelimenin ne kadar somut ya da soyut olduğunun ölçüsü |
0 ile 1 |
|
Duygusal değerlik |
Kelimede çağrışan olumlu ya da olumsuzluk |
-1 ile 1 |
|
Frekans |
Kelimenin büyük bir metin külliyatında ne sıklıkla göründüğü |
0 ile 1 |
|
Uzunluk |
Kelimedeki karakter sayısı |
0 ile 1 |
|
Sözcük türü |
İsim, fiil, sıfat, diğerini temsil eden one-hot kodlu değerler kümesi |
4x [0,1] |
|
Resmiyet düzeyi |
Kelimeyle ilişkilendirilen resmiyet seviyesi |
0 ile 1 |
|
Özgüllük |
Kelimenin ne kadar spesifik ya da genel olduğu |
0 ile 1 |
|
Duyusal çağrışım |
Kelimenin duyusal deneyimlerle ilişkilendirilme derecesi |
0 ile 1 |
Örneğin, "cat" kelimesinin vektörü şu şekilde olabilir: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] ve "freedom" şöyle olabilir: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Her vektör, yalnızca bir kelimenin anlamını kapsamakla kalmayıp bu kelimenin diğerleriyle nasıl ilişkili olduğunu da yansıtan benzersiz bir tanımlayıcı gibidir. Benzer tanımlara sahip kelimelerin, tıpkı bir haritadaki komşu noktalar gibi bu sayısal uzayda vektörleri genellikle birbirine yakındır. Bu yakınlık, kelimeler arasındaki anlamsal bağlantıları ortaya çıkarır.
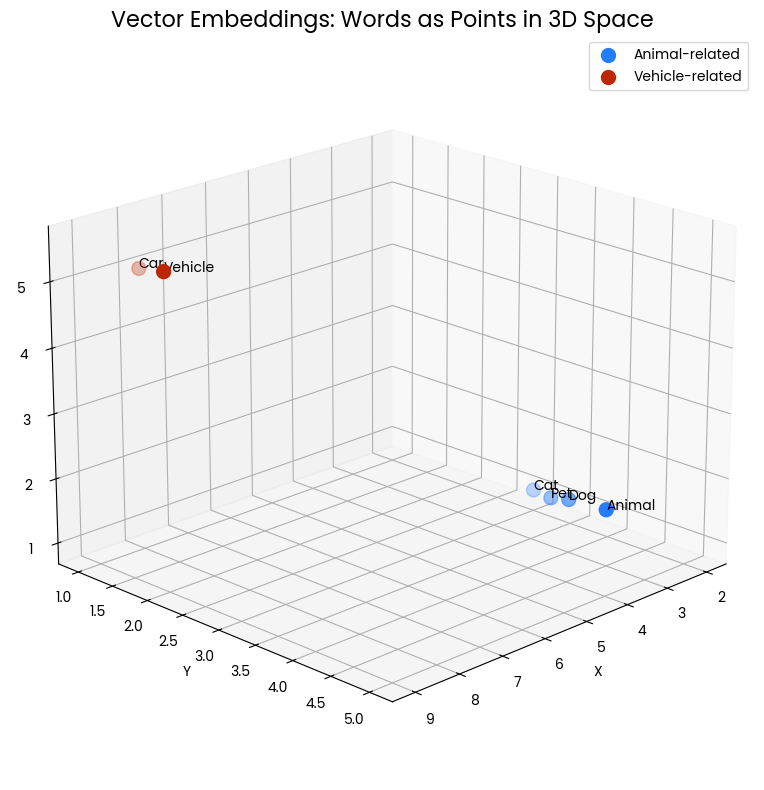
Aşağıdaki 3B saçılım grafiği, kelimeler için vektör gömleme kavramını görselleştirir. Uzaydaki her nokta bir kelimeyi temsil eder ve konumu, o kelimenin vektör gömlemesi tarafından belirlenir. Birbirine kümelenmiş mavi noktalar hayvanlarla ilgili kelimeleri (“Cat”, “Dog”, “Pet”, “Animal”) temsil ederken, kırmızı noktalar araçlarla ilgili kelimeleri (“Car”, “Vehicle”) temsil eder. Noktaların yakınlığı anlamsal benzerliği gösterir—ilgili anlamlara sahip kelimeler bu vektör uzayında birbirine daha yakın konumlanır.
Şekil 1: Üç boyutlu bir uzayda iki kelime kümesi. Yakınlık anlamsal benzerliği gösterir.
Örneğin, “Cat” ve “Dog” birbirine yakındır; bu, yaygın evcil hayvanlar olarak paylaştıkları özellikleri yansıtır. Benzer şekilde “Car” ve “Vehicle” de yakındır; ilişkili anlamlarını gösterir. Ancak, hayvan kümesi araç kümesinden uzaktadır; bu da bu kavram gruplarının anlamsal olarak farklı olduğunu ortaya koyar.
Bu uzamsal gösterim, vektör gömlemelerinin kelimeler arasındaki ilişkileri nasıl yakalayıp temsil ettiğini görsel olarak kavramamızı sağlar. Dilsel anlamı, matematiksel olarak ölçülebilen ve analiz edilebilen geometrik ilişkilere dönüştürür.
Vektör gömlemeleri özellikle Doğal Dil İşleme (NLP) alanında, bireysel kelimeleri temsil etmeye odaklanarak yaygındır. Bu sayısal temsiller rastgele atanmaz—çok büyük metin verilerinden öğrenilir. Nasıl çalıştığına bakalım.
Kelimelere vektör atamak için kullanılan NLP tekniklerinden biri Word2Vec’tir. Bu, büyük bir metin külliyatında kelimelerin bağlamlarına göre ilişkilendirmeyi öğrenen bir makine öğrenimi modelidir. Bunu, çevresindeki kelimelere bakarak bir kelimeyi tahmin etmeye çalışan bir dil modeli olarak düşünebilirsiniz.
Bunu yaparken, kelimeler arasındaki ilişkileri örtük olarak öğrenir; anlamsal ve sözdizimsel bilgileri yakalar. Öğrenilen bu ilişkiler daha sonra çeşitli NLP görevlerinde kullanılabilecek sayısal vektörlere kodlanır. Sonuç olarak, birlikte ya da benzer bağlamlarda sık görünen kelimelerin, gömme uzayında birbirine daha yakın vektörleri olur.
Word2Vec, kelime ilişkilerini yakalamak için iki temel mimari kullanır: Continuous Bag-of-Words (CBOW) ve Skip-gram.
|
Mimari |
Yöntem |
Hesaplama Verimliliği |
Yakalanan İlişkiler |
Sık Kelimelere Duyarlılık |
|
CBOW |
Hedef kelimeyi çevresindeki bağlam kelimelerine göre tahmin eder |
Daha hızlı eğitim |
Sözdizimsel ilişkileri (dilbilgisi kuralları) yakalamada daha iyi |
Sık geçen kelimelere daha duyarlı |
|
Skip-gram |
Hedef kelimeye göre çevredeki bağlam kelimelerini tahmin eder |
Daha yavaş eğitim |
Anlamsal ilişkileri (metin anlamı) yakalamada daha iyi |
Sık geçen kelimelere daha az duyarlı |
Skip-gram, CBOW’a göre eğitimi daha yavaş olabilir; ancak üretici yaklaşımı, özellikle nadir kelimeler için genellikle daha doğru gömlemeler üretir.
Bir örneğe bakalım: Çok büyük bir metin külliyatı hayal edin. Word2Vec, belirli bir metin penceresi içinde kelimelerin birlikte oluşumunu analiz ederek başlar. Örneğin, "The king and queen ruled the kingdom." cümlesinde “king” ve “queen” küçük bir pencere içinde birlikte görünür. Word2Vec bu birlikte oluşum bilgisini yakalar.
Sayısız cümle boyunca algoritma istatistiksel bir model kurar. “King” ve “queen” gibi kelimelerin benzer bağlamlarda sık göründüğünü öğrenir ve bu bilgiyi sayısal vektörlere kodlar. Sonuç olarak, “king” ve “queen” vektörleri, aynı bağlamda nadiren görünen “apple” vektörüne kıyasla gömme uzayında birbirine daha yakın konumlanır.
Vektör uzayındaki bu yakınlık, “king” ve “queen” arasındaki anlamsal benzerliği yansıtarak Word2Vec’in dilsel ilişkileri yakalamadaki gücünü gösterir.
Artık vektör gömlemelerinin ne olduğunu ve anlamı nasıl yakaladıklarını öğrendiğimize göre, bir adım ileri gidip hangi görevleri mümkün kıldıklarına bakalım.
Daha önce değindiğimiz gibi, vektör gömlemeleri anlamsal benzerliği nicelleştirmede mükemmeldir. Kelime vektörleri arasındaki mesafeyi ölçerek kelimelerin anlam bakımından ne kadar ilişkili olduğunu belirleyebiliriz.
Bu yetenek, eş anlamlı ve zıt anlamlı kelimeleri bulma gibi görevleri mümkün kılar. Benzer tanımlara sahip kelimelerin vektörleri birlikte kümelenirken, zıt anlamlılar çoğu boyutta ortak özellik taşısa da farklarını tanımlayan kilit boyutlarda birbirinden uzaktır.
Büyü, karmaşık dilbilimsel bilmeceleri çözmeye de uzanır. Vektör gömlemeleri, kelime vektörleri üzerinde aritmetik işlemler yaparak gizli ilişkileri açığa çıkarmamıza olanak tanır. Örneğin, "king is to queen as man is to woman" benzetmesi, “king” vektöründen “man” vektörünü çıkarıp “woman”a ekleyerek çözülebilir. Ortaya çıkan vektör “queen” vektörüne çok yakın olmalıdır; bu da vektör gömlemelerinin dilsel örüntüleri yakalamadaki gücünü gösterir.
Gömlemelerin çok yönlülüğü, tek tek kelimelerin ötesine uzanır. Cümle gömlemeleri, tüm cümlelerin genel anlamını yakalar. Cümleleri yoğun vektörler olarak temsil ederek farklı metinler arasındaki anlamsal benzerliği ölçebiliriz.
Kelime gömlemeleri nasıl yüksek boyutlu bir uzaydaki noktalar ise, cümle gömlemeleri de vektörlerdir. Ancak, cümle düzeyindeki bilginin artan karmaşıklığını karşılamak için genellikle daha yüksek boyutludurlar. Ortaya çıkan vektörler üzerinde matematiksel işlemler yaparak anlamsal benzerliği ölçebilir; bilgi erişimi, metin sınıflandırma ve duygu analizi gibi daha karmaşık görevleri mümkün kılabiliriz.
Basit bir yöntem, bir cümledeki tüm kelimelerin gömlemelerinin ortalamasını almaktır. Basit olsa da çoğu zaman makul bir başlangıç sunar. Daha karmaşık anlamsal ve sözdizimsel bilgileri yakalamak için, daha gelişmiş teknikler olan Tekrarlayan Sinir Ağları (RNN) ve dönüştürücü tabanlı modeller kullanılır:
|
Mimari |
İşleme |
Bağlamsal Anlama |
Hesaplama Verimliliği |
|
RNN'ler |
Sıralı |
Yerel bağlama odaklanır |
Uzun diziler için daha az verimli |
|
Dönüştürücü tabanlı modeller |
Paralel |
Uzun menzilli bağımlılıkları yakalayabilir |
Uzun dizilerde de son derece verimli |
RNN’ler uzun süre baskın mimari olsa da, Transformer’lar, cümle gömme üretimi de dahil olmak üzere birçok NLP görevi için performans ve verimlilik açısından onları geride bırakmıştır.
Bununla birlikte, RNN’lerin sıralı işlemenin kritik olduğu belirli uygulamalarda hâlâ yeri vardır. Ayrıca, metin özetleme, bilgi tabanlı soru yanıtlama veya Varlık Adı Tanıma (NER) gibi çeşitli görevler için kutudan çıktığı gibi çözümler sunan birçok önceden eğitilmiş cümle gömme modeli mevcuttur.
Vektör gömlemeleri metinle sınırlı değildir. Aşağıdaki uygulamalar, gömlemelerin çeşitli alanlardaki geniş etkisini vurgular:
Artık vektör gömlemelerinin nasıl çalıştığını ve hangi tür verileri işleyebildiklerini belirlediğimize göre, belirli kullanım senaryolarını inceleyebiliriz. En bilinen örneklerden biriyle başlayalım: büyük dil modelleri (LLM’ler).
ChatGPT, Claud veya Google Gemini gibi LLM’ler, temel bir bileşen olarak vektör gömlemelerine büyük ölçüde dayanır. Bu modeller, kelimeleri, ifadeleri ve hatta tüm cümleleri yüksek boyutlu bir uzayda yoğun vektörler olarak temsil etmeyi öğrenir. Özünde, vektör gömlemeleri dil modellerine kelimelerin ve aralarındaki ilişkilerin anlamsal bir anlayışını sağlar ve etkileyici yeteneklerinin belkemiğini oluşturur.
Metnin sayısal temsili, LLM’lerin insana benzer metinleri anlamasını ve üretmesini sağlar; çeviri, özetleme ve soru yanıtlama gibi görevleri mümkün kılar. Bu da içerik üretiminden müşteri hizmetlerine, eğitimden araştırmaya kadar geniş bir uygulama alanı açar.
Vektör gömlemeleri, sıklıkla anahtar kelime eşleştirmesine dayanan geleneksel arama motorlarına da alternatif bir yaklaşım sağlayabilir. Arama sorgularını ve web sayfalarını gömlemeler olarak temsil ederek, arama motorlarının sorguların ve potansiyel hedef sayfaların ardındaki anlamsal anlamı kavramasına yardımcı olarak bu kısıtları aşmak mümkündür. Bu sayede, tam anahtar kelime eşleşmelerinin ötesinde ilgili sayfaları tespit edebilir ve daha doğru, daha bilgilendirici sonuçlar sunabilirler.
Vektör gömlemelerinin bir diğer gücü, olağandışı veri noktalarının veya örüntülerin belirlenmesinde yatar. Algoritmalar, vektörler olarak temsil edilen veri noktaları arasındaki mesafeleri hesaplayıp normdan önemli ölçüde uzak olanları işaretleyebilir. Bu teknik, dolandırıcılık tespiti, ağ güvenliği ve endüstriyel süreç izleme gibi alanlarda uygulama bulur.
Vektör gömlemeleri ayrıca dil bariyerini aşmada da kritik bir rol oynar. “King” ve “queen” örneğimizde olduğu gibi, kelimeler arasındaki anlamsal ve sözdizimsel ilişkileri temsil eden vektörler diller arasında da yakalanabilir. Buna bağlı olarak, hedef dildeki karşılık gelen kelime veya ifadeleri vektör benzerliğine göre bulmak mümkün olur; bu da DeepL gibi makine çevirisi sistemlerinin daha doğru ve akıcı çeviriler üretmesine yardımcı olur.
Son olarak, vektör gömlemeleri etkili öneri sistemleri kurmada önemli rol oynar. Kullanıcıları ve öğeleri gömlemeler olarak temsil ederek öneri sistemleri, vektör yakınlığına göre benzer kullanıcıları veya öğeleri tanımlayabilir. Bu da ürünler, filmler, müzik ve diğer içerikler için kişiselleştirilmiş önerileri mümkün kılar. Örneğin, belirli bir filmi seven bir kullanıcı, gömlemeleri benzer olan diğer filmlerden de muhtemelen hoşlanacaktır.
Gördüğünüz gibi, vektör gömlemeleri son derece güçlü bir araç olarak ortaya çıkmıştır. Karmaşık verileri makine öğrenimi algoritmalarının kolayca anlayacağı bir formata dönüştürerek, çeşitli alanlarda çok geniş bir olasılık yelpazesinin kapılarını aralar.
Bu yazıdan çıkarılacak başlıca noktalar şunlardır:
Vektör gömlemeleri hakkında daha fazla bilgi edinmeye şu kaynaklarla devam edebilirsiniz:
Yapay zekâyı sıfırdan öğrenin!
Program
Program
Program
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
