
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
Bayangkan Anda mencoba mengajari komputer perbedaan antara apel dan jeruk. Bagi kita itu mudah dipahami, tetapi bagi mesin yang dirancang hanya untuk memahami angka, ini merupakan tantangan yang kompleks.
Di sinilah vector embedding berperan. Jurus matematika ini mengubah kata, gambar, dan data lain menjadi representasi numerik yang mudah dipahami dan dimanipulasi oleh komputer.
Vector embedding membuka semesta kemungkinan dengan memetakan dunia informasi ke dalam ruang numerik.
Vector embedding adalah sidik jari digital untuk kata atau potongan data lainnya. Alih-alih menggunakan huruf atau gambar, embedding menggunakan angka yang disusun dalam struktur khusus yang disebut vektor, mirip dengan daftar nilai yang terurut.
Bayangkan setiap vektor sebagai titik dalam ruang multi-dimensi, di mana lokasinya membawa informasi penting tentang kata atau data yang direpresentasikan.
Anda mungkin ingat vektor dari pelajaran matematika sebagai panah dengan arah dan besar. Meskipun vector embedding berbagi konsep dasar ini, embedding beroperasi dalam ruang dengan tak terhitung dimensi.
Dimensionalitas ekstrem ini penting untuk menangkap nuansa rumit bahasa manusia, seperti nada, konteks, dan ciri gramatikal. Bayangkan sebuah vektor yang bukan hanya membedakan antara "happy" dan "sad" tetapi juga variasi halus seperti "ecstatic", "content", atau "melancholic".
Vector embedding adalah teknik berharga untuk mengubah data kompleks menjadi format yang sesuai bagi algoritme pembelajaran mesin. Dengan mengonversi data berdimensi tinggi dan kategorikal menjadi representasi berdimensi lebih rendah yang kontinu, embedding meningkatkan kinerja model dan efisiensi komputasi sambil tetap mempertahankan pola data yang mendasarinya.
Untuk memberi gambaran sederhana tentang bagaimana ruang vektor multi-dimensi dapat ditentukan, berikut tabel yang menampilkan delapan dimensi contoh dan rentang nilainya:
|
Fitur |
Deskripsi |
Rentang |
|
Kekonkretan |
Ukuran seberapa nyata atau abstrak sebuah kata |
0 hingga 1 |
|
Valensi emosional |
Tingkat positivitas atau negativitas yang terkait dengan kata tersebut |
-1 hingga 1 |
|
Frekuensi |
Seberapa sering kata tersebut muncul dalam korpus teks besar |
0 hingga 1 |
|
Panjang |
Jumlah karakter dalam kata |
0 hingga 1 |
|
Kelas kata |
Sekumpulan nilai one-hot yang merepresentasikan nomina, verba, adjektiva, lainnya |
4x [0,1] |
|
Tingkat formalitas |
Tingkat formalitas yang terkait dengan kata tersebut |
0 hingga 1 |
|
Spesifisitas |
Seberapa spesifik atau umum suatu kata |
0 hingga 1 |
|
Asosiasi sensorik |
Sejauh mana kata tersebut diasosiasikan dengan pengalaman sensorik |
0 hingga 1 |
Sebagai contoh, kata "cat" mungkin memiliki vektor seperti ini: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] dan "freedom" mungkin: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Setiap vektor ibarat pengenal unik yang tidak hanya merangkum makna suatu kata, tetapi juga mencerminkan bagaimana kata itu berhubungan dengan kata lain. Kata-kata dengan definisi serupa sering kali memiliki vektor yang berdekatan dalam ruang numerik ini, seperti titik-titik yang bertetangga pada peta. Kedekatan ini mengungkap koneksi semantik antar kata.
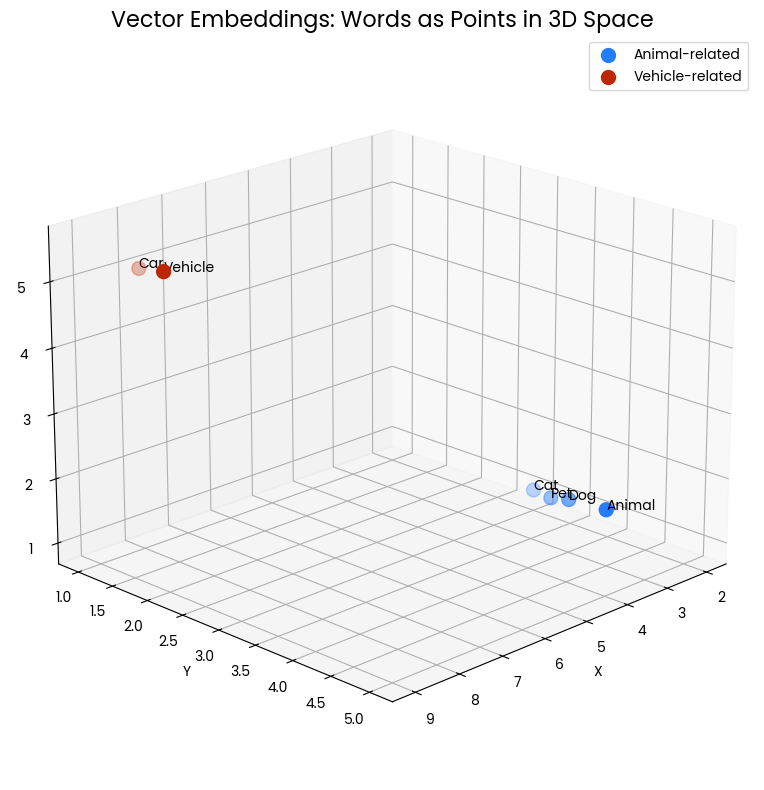
Plot sebar 3D berikut memvisualisasikan konsep vector embedding untuk kata. Setiap titik dalam ruang merepresentasikan sebuah kata, dengan posisinya ditentukan oleh vector embedding-nya. Titik-titik biru yang berkerumun merepresentasikan kata-kata terkait hewan (“Cat,” “Dog,” “Pet,” “Animal”), sedangkan titik-titik merah merepresentasikan kata-kata terkait kendaraan (“Car,” “Vehicle”). Kedekatan titik menunjukkan kemiripan semantik—kata dengan makna terkait ditempatkan lebih dekat satu sama lain dalam ruang vektor ini.
Gambar 1: Dua kluster kata dalam ruang 3 dimensi. Kedekatan menunjukkan kemiripan semantik.
Sebagai contoh, “Cat” dan “Dog” berdekatan, mencerminkan sifatnya yang sama-sama hewan peliharaan umum. Demikian pula, “Car” dan “Vehicle” saling dekat, menunjukkan makna yang terkait. Namun, kluster hewan jauh dari kluster kendaraan, menggambarkan bahwa kelompok konsep ini berbeda secara semantik.
Representasi spasial ini memungkinkan kita menangkap secara visual bagaimana vector embedding merekam dan merepresentasikan hubungan antarkata. Ini mengubah makna linguistik menjadi relasi geometris yang dapat diukur dan dianalisis secara matematis.
Vector embedding sangat umum digunakan dalam Natural Language Processing (NLP), dengan fokus merepresentasikan kata secara individual. Representasi numerik ini tidak ditetapkan secara acak—melainkan dipelajari dari sejumlah besar data teks. Mari kita lihat cara kerjanya.
Salah satu teknik NLP untuk menetapkan vektor pada kata adalah Word2Vec. Ini adalah model pembelajaran mesin yang belajar mengasosiasikan kata berdasarkan konteksnya dalam korpus teks yang besar. Anda dapat menganggapnya sebagai model bahasa yang mencoba memprediksi sebuah kata berdasarkan kata-kata di sekitarnya.
Dengan melakukan itu, model secara implisit mempelajari hubungan antarkata, menangkap informasi semantik dan sintaktis. Hubungan yang dipelajari ini kemudian dikodekan menjadi vektor numerik, yang dapat digunakan untuk berbagai tugas NLP. Pada akhirnya, kata-kata yang sering muncul bersama atau dalam konteks serupa akan memiliki vektor yang lebih berdekatan dalam ruang embedding.
Word2Vec menggunakan dua arsitektur utama untuk menangkap relasi kata: Continuous Bag-of-Words (CBOW) dan Skip-gram.
|
Arsitektur |
Prosedur |
Efisiensi Komputasi |
Relasi yang Ditangkap |
Sensitivitas terhadap Kata Sering |
|
CBOW |
Memprediksi kata target berdasarkan kata-kata konteks di sekitarnya |
Pelatihan lebih cepat |
Lebih baik menangkap relasi sintaktis (aturan tata bahasa) |
Lebih sensitif terhadap kata yang sering muncul |
|
Skip-gram |
Memprediksi kata-kata konteks di sekitar berdasarkan kata target |
Pelatihan lebih lambat |
Lebih baik menangkap relasi semantik (makna teks) |
Kurang sensitif terhadap kata yang sering muncul |
Skip-gram mungkin lebih lambat dilatih dibanding CBOW, tetapi pendekatannya yang generatif umumnya dianggap menghasilkan embedding yang lebih akurat, terutama untuk kata-kata langka.
Mari lihat sebuah contoh: Bayangkan korpus teks yang sangat besar. Word2Vec mulai dengan menganalisis ko-kemunculan kata dalam jendela teks tertentu. Misalnya, pertimbangkan kalimat "The king and queen ruled the kingdom." Di sini, "king" dan "queen" muncul bersama dalam jendela kecil. Word2Vec menangkap informasi ko-kemunculan ini.
Lewat tak terhitung kalimat, algoritme membangun model statistik. Ia mempelajari bahwa kata seperti "king" dan "queen" sering muncul dalam konteks yang serupa dan mengodekan informasi ini ke dalam vektor numerik. Akibatnya, vektor untuk "king" dan "queen" akan ditempatkan lebih berdekatan dalam ruang embedding dibanding vektor untuk "apple", yang jarang muncul dalam konteks yang sama.
Kedekatan dalam ruang vektor ini mencerminkan kemiripan semantik antara "king" dan "queen", yang menunjukkan kekuatan Word2Vec dalam menangkap relasi linguistik.
Kini setelah kita mengetahui apa itu vector embedding dan bagaimana embedding menangkap makna, saatnya melangkah lebih jauh untuk melihat tugas apa saja yang dimungkinkan olehnya.
Seperti telah dibahas, vector embedding unggul dalam mengukur kemiripan semantik. Dengan mengukur jarak antar vektor kata, kita dapat menentukan seberapa erat hubungan makna antar kata.
Kemampuan ini mendukung tugas seperti menemukan sinonim dan antonim. Kata dengan definisi serupa memiliki vektor yang berkerumun, sementara antonim sering berbagi banyak dimensi tetapi berjauhan pada dimensi kunci yang menggambarkan perbedaannya.
Keajaiban ini meluas ke pemecahan teka-teki linguistik yang kompleks. Vector embedding memungkinkan kita melakukan operasi aritmetika pada vektor kata untuk mengungkap hubungan tersembunyi. Misalnya, analogi "king berbanding queen seperti man berbanding woman" dapat dipecahkan dengan mengurangkan vektor "man" dari "king" dan menambahkannya ke "woman". Vektor yang dihasilkan seharusnya mendekati vektor "queen", menunjukkan kekuatan vector embedding dalam menangkap pola linguistik.
Fleksibilitas embedding melampaui ranah kata per kata. Embedding kalimat menangkap makna keseluruhan dari satu kalimat utuh. Dengan merepresentasikan kalimat sebagai vektor padat, kita dapat mengukur kemiripan semantik antar teks.
Sama seperti embedding kata adalah titik dalam ruang berdimensi tinggi, embedding kalimat juga merupakan vektor. Namun, dimensinya biasanya lebih tinggi untuk mengakomodasi kompleksitas informasi tingkat kalimat. Kita dapat melakukan operasi matematis pada vektor yang dihasilkan untuk mengukur kemiripan semantik, sehingga memungkinkan tugas yang lebih kompleks seperti penelusuran informasi, klasifikasi teks, dan analisis sentimen.
Metode langsung adalah merata-ratakan embedding kata dari semua kata dalam satu kalimat. Meski sederhana, ini sering memberikan baseline yang cukup baik. Untuk menangkap informasi semantik dan sintaktis yang lebih kompleks, teknik yang lebih maju seperti Recurrent Neural Networks (RNN) dan model berbasis transformer digunakan:
|
Arsitektur |
Pemrosesan |
Pemahaman Kontekstual |
Efisiensi Komputasi |
|
RNN |
Sekuensial |
Fokus pada konteks lokal |
Kurang efisien untuk sekuens panjang |
|
Model berbasis transformer |
Paralel |
Dapat menangkap ketergantungan jarak jauh |
Sangat efisien, juga untuk sekuens panjang |
Walau RNN lama menjadi arsitektur dominan, transformer telah melampauinya dalam hal performa dan efisiensi untuk banyak tugas NLP, termasuk pembuatan embedding kalimat.
Namun, RNN masih memiliki peran pada aplikasi tertentu di mana pemrosesan sekuensial sangat penting. Selain itu, banyak model embedding kalimat pra-latih tersedia, menawarkan solusi siap pakai untuk berbagai tugas seperti peringkasan teks, tanya jawab berbasis pengetahuan, atau Named Entity Recognition (NER).
Vector embedding tidak terbatas pada teks. Aplikasi berikut menyoroti dampak luas embedding di berbagai domain:
Sekarang setelah kita menetapkan bagaimana vector embedding bekerja dan jenis data apa yang dapat ditanganinya, kita bisa menelaah kasus penggunaan spesifik. Mari mulai dengan salah satu contoh paling terkenal: large language model (LLM).
LLM seperti ChatGPT, Claud, atau Google Gemini sangat bergantung pada vector embedding sebagai komponen fondasional. Model-model ini belajar merepresentasikan kata, frasa, dan bahkan seluruh kalimat sebagai vektor padat dalam ruang berdimensi tinggi. Intinya, vector embedding memberikan pemahaman semantik tentang kata dan relasinya pada model bahasa, membentuk tulang punggung bagi kemampuan mereka yang mengesankan.
Representasi numerik teks memungkinkan LLM memahami dan menghasilkan teks menyerupai manusia, sehingga memungkinkan tugas seperti penerjemahan, peringkasan, dan tanya jawab. Ini membuka berbagai bidang dengan potensi aplikasi, mulai dari pembuatan konten dan layanan pelanggan hingga pendidikan dan riset.
Vector embedding juga dapat menyediakan pendekatan alternatif terhadap mesin pencari tradisional, yang sering mengandalkan pencocokan kata kunci. Keterbatasannya dapat diatasi dengan merepresentasikan kueri pencarian dan halaman web sebagai embedding, membantu mesin pencari memahami makna semantik di balik kueri dan halaman target potensial. Ini memungkinkan mereka mengidentifikasi halaman relevan melampaui kecocokan kata kunci persis, sehingga memberikan hasil yang lebih akurat dan informatif.
Kekuatan lain dari vector embedding terletak pada identifikasi titik data atau pola yang tidak biasa. Algoritme dapat menghitung jarak antar titik data yang direpresentasikan sebagai vektor dan menandai titik yang secara signifikan jauh dari norma. Teknik ini dimanfaatkan dalam deteksi penipuan, keamanan jaringan, dan pemantauan proses industri.
Vector embedding juga berperan penting dalam menjembatani kesenjangan bahasa. Serupa dengan contoh kita tentang “king” dan “queen,” vektor yang merepresentasikan relasi semantik dan sintaktis antar kata dapat ditangkap lintas bahasa. Dengan demikian, menemukan kata atau frasa padanan dalam bahasa target berdasarkan kemiripan vektornya dimungkinkan, membantu sistem penerjemahan mesin seperti DeepL menghasilkan terjemahan yang lebih akurat dan fasih.
Terakhir, vector embedding sangat penting dalam membangun sistem rekomendasi yang efektif. Dengan merepresentasikan pengguna dan item sebagai embedding, sistem rekomendasi dapat mengidentifikasi pengguna atau item serupa berdasarkan kedekatan vektor. Ini memungkinkan rekomendasi yang dipersonalisasi untuk produk, film, musik, dan konten lainnya. Misalnya, pengguna yang menyukai film serupa dengan sebuah film tertentu kemungkinan besar juga akan menyukai film lain dengan embedding yang serupa.
Seperti yang Anda lihat, vector embedding telah muncul sebagai alat yang sangat kuat. Dengan mengubah data kompleks ke dalam format yang mudah dipahami oleh algoritme pembelajaran mesin, embedding membuka berbagai kemungkinan di berbagai bidang.
Berikut hal-hal utama yang perlu diingat dari artikel ini:
Anda dapat terus mempelajari lebih lanjut tentang vector embedding melalui sumber berikut:
Pelajari AI dari nol!
Program
Program
Program
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
