
Track
AI Fundamentals
10 hr
Imagine trying to teach a computer the difference between an apple and an orange. It’s easy for us to grasp, but for a machine that is designed to understand only numbers, it’s a complex challenge.
This is where vector embeddings come in. These mathematical magic tricks transform words, images, and other data into numerical representations that computers can easily understand and manipulate.
Vector embeddings open up a universe of possibilities by mapping the world of information into numerical space.
Vector embeddings are digital fingerprints for words or other pieces of data. Instead of using letters or images, they use numbers that are arranged in a specific structure called a vector, which is like an ordered list of values.
Imagine each vector as a point in a multi-dimensional space, where its location carries vital information about the represented word or data.
You might remember vectors from your math classes as arrows with direction and magnitude. While vector embeddings share this fundamental concept, they operate in spaces with countless dimensions.
This extreme dimensionality is essential for capturing the complicated nuances of human language, such as tone, context, and grammatical features. Imagine a vector that not only differentiates between "happy" and "sad" but also subtle variations like "ecstatic," "content," or "melancholic."
Vector embeddings are a valuable technique for transforming complex data into a format suitable for machine learning algorithms. By converting high-dimensional and categorical data into lower-dimensional, continuous representations, embeddings enhance model performance and computational efficiency while preserving underlying data patterns.
To give you a simplified look into how a multi-dimensional vector space could be defined, here is a table showing eight exemplary dimensions and the respective value range:
|
Feature |
Description |
Range |
|
Concreteness |
A measure of how tangible or abstract a word is |
0 to 1 |
|
Emotional valence |
The positivity or negativity associated with the word |
-1 to 1 |
|
Frequency |
How often the word appears in a large corpus of text |
0 to 1 |
|
Length |
The number of characters in the word |
0 to 1 |
|
Part of speech |
A set of one-hot encoded values representing noun, verb, adjective, other |
4x [0,1] |
|
Formality |
The level of formality associated with the word |
0 to 1 |
|
Specificity |
How specific or general the word is |
0 to 1 |
|
Sensory association |
The degree to which the word is associated with sensory experiences |
0 to 1 |
For example, the word "cat" might have a vector like this: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] and "freedom" might be: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Each vector is like a unique identifier that not only encapsulates a word's meaning but also reflects how this word relates to others. Words with similar definitions often have vectors close together in this numerical space, just like neighboring points on a map. This proximity reveals the semantic connections between words.
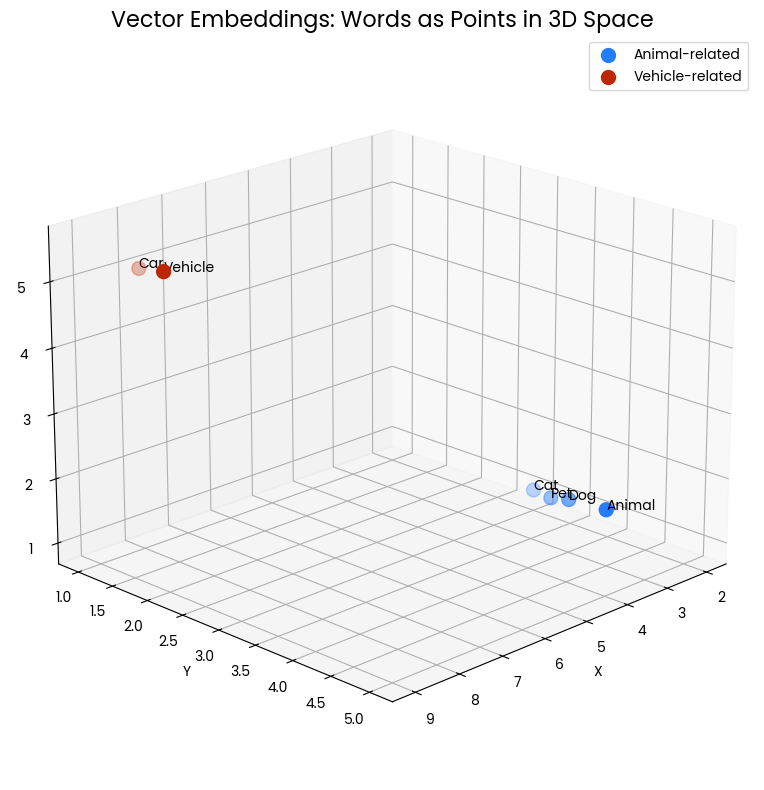
The following 3D scatter plot visualizes the concept of vector embeddings for words. Each point in the space represents a word, with its position determined by its vector embedding. The blue points clustered together represent animal-related words (“Cat,” “Dog,” “Pet,” “Animal”), while the red points represent vehicle-related words (“Car,” “Vehicle”). The proximity of points indicates semantic similarity—words with related meanings are positioned closer together in this vector space.
Figure 1: Two clusters of words within a 3-dimensional space. Proximity indicates semantic similarity.
For instance, “Cat” and “Dog” are near each other, reflecting their shared characteristics as common pets. Similarly, “Car” and “Vehicle” are close, showing their related meanings. However, the animal cluster is far from the vehicle cluster, illustrating that these concept groups are semantically distinct.
This spatial representation allows us to visually grasp how vector embeddings capture and represent the relationships between words. It transforms linguistic meaning into geometric relationships that can be measured and analyzed mathematically.
Vector embeddings are particularly common in Natural Language Processing (NLP), focusing on representing individual words. These numerical representations aren't randomly assigned—they're learned from vast amounts of text data. Let’s see how it works.
One of the NLP techniques to assign vectors to words is Word2Vec. It's a machine learning model that learns to associate words based on their context within a large corpus of text. You can think of it as a language model that tries to predict a word based on its surrounding words.
By doing this, it implicitly learns the relationships between words, capturing semantic and syntactic information. These learned relationships are then encoded into numerical vectors, which can be used for various NLP tasks. Finally, words that frequently appear together or in similar contexts will have vectors that are closer in the embedding space.
Word2Vec employs two primary architectures to capture word relationships: Continuous Bag-of-Words (CBOW) and Skip-gram.
|
Architecture |
Procedure |
Computational Efficiency |
Captured Relationships |
Sensitivity to Frequent Words |
|
CBOW |
Predicts target word based on surrounding context words |
Faster training |
Better at capturing syntactic relationships (grammatical rules) |
More sensitive to frequent words |
|
Skip-gram |
Predicts surrounding context words based on target word |
Slower training |
Better at capturing semantic relationships (text meaning) |
Less sensitive to frequent words |
Skip-gram might be slower to train than CBOW, but its generative approach is generally considered to produce more accurate embeddings, especially for rare words.
Let’s take a look at an example: Imagine a vast corpus of text. Word2Vec starts by analyzing how words co-occur within a specific window of text. For instance, consider the sentence "The king and queen ruled the kingdom." Here, "king" and "queen" appear together within a small window. Word2Vec captures this co-occurrence information.
Over countless sentences, the algorithm builds a statistical model. It learns that words like "king" and "queen" frequently appear in similar contexts and encodes this information into numerical vectors. As a result, the vectors for "king" and "queen" will be positioned closer together in the embedding space compared to the vector for "apple," which rarely appears in the same context.
This proximity in the vector space reflects the semantic similarity between "king" and "queen," demonstrating the power of Word2Vec in capturing linguistic relationships.
Now that we have found out what vector embeddings are and how they capture meaning, it is time to go one step further and see which tasks they enable.
As we have already covered, vector embeddings excel at quantifying semantic similarity. By measuring the distance between word vectors, we can determine how closely related words are in meaning.
This capability empowers tasks like finding synonyms and antonyms. Words with similar definitions have vectors clustered together, while antonyms often share many dimensions but are far apart in the key dimensions describing their difference.
The magic extends to solving complex linguistic puzzles. Vector embeddings allow us to perform arithmetic operations on word vectors, uncovering hidden relationships. For instance, the analogy "king is to queen as man is to woman" can be solved by subtracting the vector for "man" from "king" and adding it to "woman." The resulting vector should closely match the vector for "queen," demonstrating the power of vector embeddings in capturing linguistic patterns.
The versatility of embeddings extends beyond the realm of individual words. Sentence embeddings capture the overall meaning of entire sentences. By representing sentences as dense vectors, we can measure semantic similarity between different texts.
Just as word embeddings are points in a high-dimensional space, sentence embeddings are also vectors. However, they are typically of higher dimensionality to account for the increased complexity of sentence-level information. We can perform mathematical operations on the resulting vectors to measure semantic similarity, enabling more complex tasks like information retrieval, text classification, and sentiment analysis.
A straightforward method is to average the word embeddings of all words in a sentence. While simple, it often provides a decent baseline. To capture more complex semantic and syntactic information, more advanced techniques like Recurrent Neural Networks (RNNs) and transformer-based models are employed:
|
Architecture |
Processing |
Contextual Understanding |
Computational Efficiency |
|
RNNs |
Sequential |
Focus on local context |
Less efficient for long sequences |
|
Transformer-based models |
Parallel |
Can capture long-range dependencies |
Highly efficient, also for long sequences |
While RNNs were the dominant architecture for a long time, Transformers have surpassed them in terms of performance and efficiency for many NLP tasks, including sentence embedding generation.
However, RNNs still have their place in specific applications where sequential processing is crucial. Additionally, many pre-trained sentence embedding models are available, offering out-of-the-box solutions for various tasks like text summarization, knowledge-based question answering or Named Entity Recognition (NER).
Vector embeddings are not limited to text. The following applications highlight the broad impact of embeddings across various domains:
Now that we have established how vector embeddings work and which kinds of data they can handle, we can examine specific use cases. Let’s start with one of the most famous examples: large language models (LLMs).
LLMs like ChatGPT, Claud, or Google Gemini rely heavily on vector embeddings as a foundational component. These models learn to represent words, phrases, and even entire sentences as dense vectors in a high-dimensional space. Essentially, vector embeddings provide the language models with a semantic understanding of words and their relationships, forming the backbone for their impressive capabilities.
The numerical representation of text allows LLMs to understand and generate human-like text, enabling tasks such as translation, summarization, and question-answering. This opens a wide array of fields with potential applications, from content creation and customer service to education and research.
Vector embeddings also can provide an alternative approach to traditional search engines, which often rely on keyword matching. Its limitations can be overcome by representing both search queries and web pages as embeddings, helping search engines with understanding the semantic meaning behind queries and potential target pages. This enables them to identify relevant pages beyond exact keyword matches, delivering more accurate and informative results.
Another strength of vector embeddings lies in the identification of unusual data points or patterns. Algorithms can calculate distances between data points represented as vectors and flag those that are significantly distant from the norm. This technique finds applications in fraud detection, network security, and industrial process monitoring.
Vector embeddings also play a crucial role in bridging the language gap. Similarly to our example with “king” and “queen,” vectors representing semantic and syntactic relationships between words can be captured across languages. Accordingly, finding corresponding words or phrases in the target language based on their vector similarity is possible, helping machine translation systems like DeepL to generate more accurate and fluent translations.
Finally, vector embeddings are instrumental in building effective recommendation systems. By representing users and items as embeddings, recommendation systems can identify similar users or items based on their vector proximity. This enables personalized recommendations for products, movies, music, and other content. For example, a user who enjoys similar movies to a given movie will likely enjoy other movies with similar embeddings.
As you can see, vector embeddings have emerged as a very powerful tool. By transforming complex data into a format readily understood by machine learning algorithms, they unlock a vast array of possibilities in various fields.
Here are the key takeaways from this article:
You can continue learning more about vector embeddings with these resources:
Learn AI from scratch!
Track
Track
Track
blog
Chisom Uma
10 min
Tutorial
Lars Hulstaert
Tutorial
Gary Alway
Tutorial
Nilesh Soni
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita