Programa
Fundamentos da IA
10 h
Imagine tentar ensinar a um computador a diferença entre uma maçã e uma laranja. Para nós, isso é fácil de entender, mas para uma máquina projetada para entender apenas números, é um desafio complexo.
É aqui que entramas incorporações de vetores. Esses truques de mágica matemática transformam palavras, imagens e outros dados em representações numéricas que os computadores podem entender e manipular facilmente.
As incorporações vetoriais abrem um universo de possibilidades ao mapear o mundo das informações no espaço numérico.
As incorporações de vetores são impressões digitais para palavras ou outras partes de dados. Em vez de usar letras ou imagens, eles usam números que são organizados em uma estrutura específica chamada vetor, que é como uma lista ordenada de valores.
Imagine cada vetor como um ponto em um espaço multidimensional, onde sua localização contém informações vitais sobre a palavra ou os dados representados.
Talvez você se lembre dos vetores das aulas de matemática como setas com direção e magnitude. Embora os embeddings vetoriais compartilhem esse conceito fundamental, eles operam em espaços com inúmeras dimensões.
Essa dimensionalidade extrema é essencial para capturar as nuances complicadas da linguagem humana, como tom, contexto e recursos gramaticais. Imagine um vetor que não apenas diferencie entre "feliz" e "triste", mas também variações sutis como "extático", "contente" ou "melancólico".
A incorporação de vetores é uma técnica valiosa para transformar dados complexos em um formato adequado para algoritmos de machine learning. Ao converter dados categóricos e de alta dimensão em representações contínuas e de baixa dimensão, os embeddings melhoram o desempenho do modelo e a eficiência computacional, preservando os padrões de dados subjacentes.
Para que você tenha uma visão simplificada de como um espaço vetorial multidimensional pode ser definido, aqui está uma tabela que mostra oito dimensões exemplares e o respectivo intervalo de valores:
|
Recurso |
Descrição |
Faixa |
|
Concretude |
Uma medida de quão tangível ou abstrata é uma palavra |
0 a 1 |
|
Valência emocional |
A positividade ou negatividade associada à palavra |
-1 para 1 |
|
Frequência |
A frequência com que a palavra aparece em um grande corpus de texto |
0 a 1 |
|
Comprimento |
O número de caracteres na palavra |
0 a 1 |
|
Parte do discurso |
Um conjunto de valores codificados com um único ponto representando substantivo, verbo, adjetivo e outros |
4x [0,1] |
|
Formalidade |
O nível de formalidade associado à palavra |
0 a 1 |
|
Especificidade |
Quão específica ou geral é a palavra |
0 a 1 |
|
Associação sensorial |
O grau em que a palavra está associada a experiências sensoriais |
0 a 1 |
Por exemplo, a palavra "cat" (gato) pode ter um vetor como este: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0, 0.4, 0.8, 0.9] e "liberdade" pode ser: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Cada vetor é como um identificador exclusivo que não apenas encapsula o significado de uma palavra, mas também reflete como essa palavra se relaciona com outras. Palavras com definições semelhantes geralmente têm vetores próximos nesse espaço numérico, assim como pontos vizinhos em um mapa. Essa proximidade revela as conexões semânticas entre as palavras.
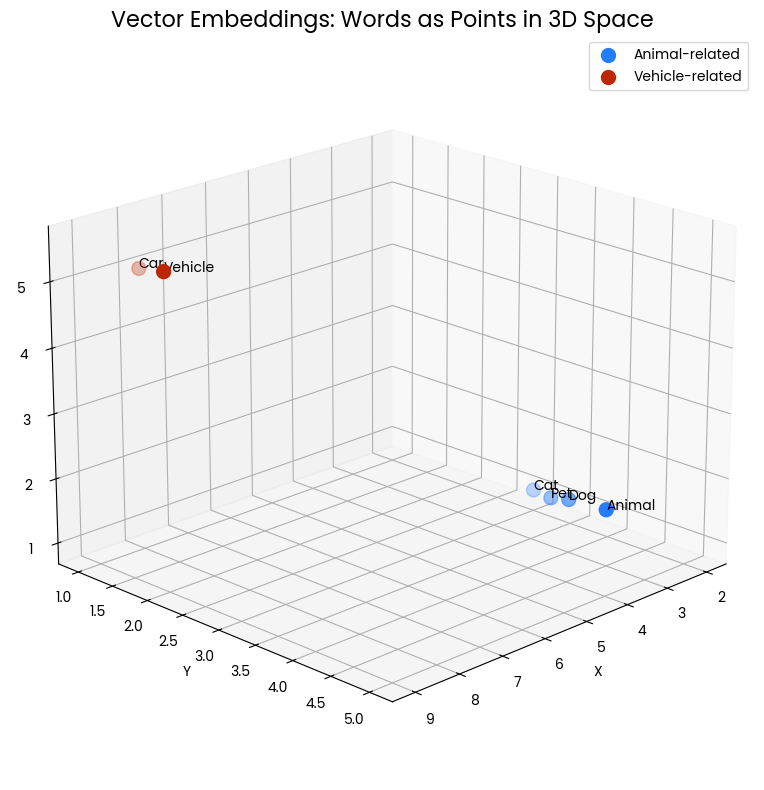
O gráfico de dispersão 3D a seguir visualiza o conceito de incorporação de vetores para palavras. Cada ponto no espaço representa uma palavra, com sua posição determinada pela incorporação do vetor. Os pontos azuis agrupados representam palavras relacionadas a animais ("Cat", "Dog", "Pet", "Animal"), enquanto os pontos vermelhos representam palavras relacionadas a veículos ("Car", "Vehicle"). A proximidade dos pontos indica similaridade semântica - palavras com significados relacionados são posicionadas mais próximas umas das outras nesse espaço vetorial.
Figura 1: Dois grupos de palavras em um espaço tridimensional. A proximidade indica similaridade semântica.
Por exemplo, "Cat" (gato) e "Dog" (cachorro) estão próximos um do outro, refletindo suas características compartilhadas como animais de estimação comuns. Da mesma forma, "Car" e "Vehicle" estão próximos, mostrando seus significados relacionados. No entanto, o grupo de animais está longe do grupo de veículos, o que mostra que esses grupos de conceitos são semanticamente distintos.
Essa representação espacial nos permite compreender visualmente como os embeddings de vetores capturam e representam as relações entre as palavras. Ele transforma o significado linguístico em relações geométricas que podem ser medidas e analisadas matematicamente.
Os embeddings de vetores são particularmente comuns no Processamento de linguagem natural (NLP)com foco na representação de palavras individuais. Essas representações numéricas não são atribuídas aleatoriamente - elas são aprendidas a partir de grandes quantidades de dados de texto. Vamos ver como isso funciona.
Uma das técnicas de PNL para atribuir vetores a palavras é a Word2Vec. É um modelo de machine learning que aprende a associar palavras com base em seu contexto em um grande corpus de texto. Você pode pensar nisso como um modelo de linguagem que tenta prever uma palavra com base nas palavras que a cercam.
Ao fazer isso, ele aprende implicitamente as relações entre as palavras, capturando informações semânticas e sintáticas. Essas relações aprendidas são então codificadas em vetores numéricos, que podem ser usados para várias tarefas de PNL. Por fim, as palavras que aparecem frequentemente juntas ou em contextos semelhantes terão vetores mais próximos no espaço de incorporação.
O Word2Vec utiliza duas arquiteturas principais para capturar as relações entre as palavras: Saco de palavras contínuo (CBOW) e Skip-gram.
|
Arquitetura |
Procedimento |
Eficiência computacional |
Relacionamentos capturados |
Sensibilidade a palavras frequentes |
|
CBOW |
Prevê a palavra-alvo com base nas palavras do contexto ao redor |
Treinamento mais rápido |
Melhor captura de relações sintáticas (regras gramaticais) |
Mais sensível a palavras frequentes |
|
Skip-gram |
Prevê as palavras do contexto ao redor com base na palavra-alvo |
Treinamento mais lento |
Melhor captura de relações semânticas (significado do texto) |
Menos sensível a palavras frequentes |
O treinamento do Skip-gram pode ser mais lento do que o do CBOW, mas sua abordagem generativa é geralmente considerada como a que produz incorporações mais precisas, especialmente para palavras raras.
Vamos dar uma olhada em um exemplo: Imagine um vasto corpus de texto. O Word2Vec começa analisando como as palavras ocorrem simultaneamente em uma janela específica do texto. Por exemplo, considere a frase "O rei e a rainha governavam o reino". Aqui, "rei" e "rainha" aparecem juntos em uma pequena janela. O Word2Vec captura essas informações de co-ocorrência.
Ao longo de inúmeras frases, o algoritmo cria um modelo estatístico. Ele aprende que palavras como "rei" e "rainha" aparecem com frequência em contextos semelhantes e codifica essas informações em vetores numéricos. Como resultado, os vetores para "rei" e "rainha" serão posicionados mais próximos no espaço de incorporação em comparação com o vetor para "maçã", que raramente aparece no mesmo contexto.
Essa proximidade no espaço vetorial reflete a semelhança semântica entre "king" e "queen", demonstrando o poder do Word2Vec em capturar relações linguísticas.
Agora que descobrimos o que são embeddings vetoriais e como eles capturam o significado, é hora de dar um passo adiante e ver quais tarefas eles possibilitam.
Como já abordamos, as incorporações de vetores são excelentes para quantificar a similaridade semântica. Ao medir a distância entre os vetores de palavras, podemos determinar o grau de proximidade do significado das palavras.
Esse recurso possibilita tarefas como encontrar sinônimos e antônimos. As palavras com definições semelhantes têm vetores agrupados, enquanto os antônimos geralmente compartilham muitas dimensões, mas estão distantes nas principais dimensões que descrevem sua diferença.
A magia se estende à solução de quebra-cabeças linguísticos complexos. A incorporação de vetores nos permite realizar operações aritméticas em vetores de palavras, revelando relações ocultas. Por exemplo, a analogia "o rei está para a rainha assim como o homem está para a mulher" pode ser resolvida subtraindo o vetor de "homem" de "rei" e adicionando-o a "mulher". O vetor resultante deve ser muito parecido com o vetor de "queen", demonstrando o poder da incorporação de vetores na captura de padrões linguísticos.
A versatilidade dos embeddings vai além do domínio de palavras individuais. Os embeddings de frases capturam o significado geral de frases inteiras. Ao representar frases como vetores densos, podemos medir a semelhança semântica entre textos diferentes.
Assim como os embeddings de palavras são pontos em um espaço de alta dimensão, os embeddings de frases também são vetores. No entanto, eles geralmente têm uma dimensionalidade maior para levar em conta a maior complexidade das informações no nível da frase. Podemos realizar operações matemáticas nos vetores resultantes para medir a similaridade semântica, possibilitando tarefas mais complexas, como recuperação de informações, classificação de textos e análise de sentimentos.
Um método simples é calcular a média das palavras incorporadas de todas as palavras em uma frase. Embora seja simples, ele geralmente fornece uma linha de base decente. Para capturar informações semânticas e sintáticas mais complexas, técnicas mais avançadas, como Redes Neurais Recorrentes (RNNs) e modelos baseados em transformadores são empregadas:
|
Arquitetura |
Processamento |
Compreensão contextual |
Eficiência computacional |
|
RNNs |
Sequencial |
Foco no contexto local |
Menos eficiente para sequências longas |
|
Modelos baseados em transformadores |
Paralelo |
Pode capturar dependências de longo alcance |
Altamente eficiente, também para sequências longas |
Embora as RNNs tenham sido a arquitetura dominante por muito tempo,as Transformers as superaram em termos de desempenho e eficiência para muitas tarefas de PNL, incluindo a geração de incorporação de frases.
No entanto, as RNNs ainda têm seu lugar em aplicações específicas em que o processamento sequencial é fundamental. Além disso, muitos modelos de incorporação de frases pré-treinados estão disponíveis, oferecendo soluções prontas para várias tarefas, como resumo de texto, resposta a perguntas baseadas em conhecimento ou Reconhecimento de entidades nomeadas (NER).
As incorporações de vetores não se limitam ao texto. Os aplicativos a seguir destacam o amplo impacto dos embeddings em vários domínios:
Agora que já estabelecemos como funcionam as incorporações de vetores e com quais tipos de dados elas podem lidar, podemos examinar casos de uso específicos. Vamos começar com um dos exemplos mais famosos: modelos de linguagem grandes (LLMs).
LLMs como ChatGPT, Claudou Google Gemini dependem muito de embeddings de vetores como um componente fundamental. Esses modelos aprendem a representar palavras, frases e até mesmo sentenças inteiras como vetores densos em um espaço de alta dimensão. Essencialmente, as incorporações de vetores fornecem aos modelos de linguagem uma compreensão semântica das palavras e de seus relacionamentos, formando a espinha dorsal de seus impressionantes recursos.
A representação numérica do texto permite que os LLMs entendam e gerem textos semelhantes aos humanospermitindo tarefas como tradução, resumo e resposta a perguntas. Isso abre uma ampla gama de campos com possíveis aplicações, desde a criação de conteúdo e atendimento ao cliente até a educação e a pesquisa.
As incorporações de vetores também podem oferecer uma abordagem alternativa aos mecanismos de pesquisa tradicionais, que geralmente dependem da correspondência de palavras-chave. Suas limitações podem ser superadas com a representação das consultas de pesquisa e das páginas da Web como embeddings, ajudando os mecanismos de pesquisa a entender o significado semântico por trás das consultas e das possíveis páginas de destino. Isso permite que eles identifiquem páginas relevantes além das correspondências exatas de palavras-chave, fornecendo resultados mais precisos e informativos.
Outro ponto forte da incorporação de vetores é a identificação de padrões ou pontos de dados incomuns. Os algoritmos podem calcular as distâncias entre os pontos de dados representados como vetores e sinalizar aqueles que estão significativamente distantes da norma. Essa técnica encontra aplicações em detecção de fraudessegurança de rede e monitoramento de processos industriais.
As incorporações de vetores também desempenham um papel fundamental na redução da lacuna de idioma. Da mesma forma que em nosso exemplo com "rei" e "rainha", os vetores que representam as relações semânticas e sintáticas entre as palavras podem ser capturados em vários idiomas. Dessa forma, é possível encontrar palavras ou frases correspondentes no idioma de destino com base em sua similaridade vetorial, o que ajuda os sistemas de tradução automática, como DeepL a gerar traduções mais precisas e fluentes.
Por fim, a incorporação de vetores é fundamental para a criação de sistemas de recomendação eficazes. Ao representar usuários e itens como embeddings, os sistemas de recomendação podem identificar usuários ou itens semelhantes com base em sua proximidade vetorial. Isso permite recomendações personalizadas de produtos, filmes, músicas e outros conteúdos. Por exemplo, um usuário que gosta de filmes semelhantes a um determinado filme provavelmente gostará de outros filmes com embeddings semelhantes.
Como você pode ver, as incorporações vetoriais surgiram como uma ferramenta muito poderosa. Ao transformar dados complexos em um formato prontamente compreendido pelos algoritmos de machine learning, você tem acesso a uma vasta gama de possibilidades em vários campos.
Aqui estão as principais conclusões desse artigo:
Você pode continuar aprendendo mais sobre embeddings vetoriais com estes recursos:
Aprenda IA do zero!
Programa
Programa
Programa
blog
Moez Ali
14 min
blog
Bhavishya Pandit
8 min
blog
Abid Ali Awan
7 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
11 min
Tutorial
Zoumana Keita



