
Programma
Nozioni di base sull'intelligenza artificiale
10 h
Immagina di dover insegnare a un computer la differenza tra una mela e un'arancia. Per noi è semplice, ma per una macchina progettata per comprendere solo numeri è una sfida complessa.
È qui che entrano in gioco le vector embeddings. Questi “trucchi” matematici trasformano parole, immagini e altri dati in rappresentazioni numeriche che i computer possono comprendere e manipolare con facilità.
Le vector embeddings aprono un universo di possibilità mappando il mondo dell'informazione in uno spazio numerico.
Le vector embeddings sono impronte digitali per parole o altri tipi di dati. Invece di usare lettere o immagini, usano numeri disposti in una struttura specifica chiamata vettore, simile a un elenco ordinato di valori.
Immagina ogni vettore come un punto in uno spazio multidimensionale, dove la sua posizione racchiude informazioni cruciali sulla parola o sul dato rappresentato.
Forse ricordi i vettori dalle lezioni di matematica come frecce con direzione e magnitudine. Pur condividendo questo concetto fondamentale, le vector embeddings operano in spazi con innumerevoli dimensioni.
Questa estrema dimensionalità è essenziale per cogliere le sfumature complesse del linguaggio umano, come tono, contesto e tratti grammaticali. Immagina un vettore che non solo distingue tra "happy" e "sad", ma anche sfumature come "ecstatic", "content" o "melancholic".
Le vector embeddings sono una tecnica preziosa per trasformare dati complessi in un formato adatto agli algoritmi di machine learning. Convertendo dati ad alta dimensionalità e categoriali in rappresentazioni continue a dimensionalità inferiore, le embedding migliorano le prestazioni dei modelli e l'efficienza computazionale preservando al contempo i pattern sottostanti dei dati.
Per darti una visione semplificata di come potrebbe essere definito uno spazio vettoriale multidimensionale, ecco una tabella che mostra otto dimensioni esemplificative e il relativo intervallo di valori:
|
Caratteristica |
Descrizione |
Intervallo |
|
Concretezza |
Una misura di quanto una parola sia tangibile o astratta |
0 a 1 |
|
Valenza emotiva |
La positività o negatività associata alla parola |
-1 a 1 |
|
Frequenza |
Quanto spesso la parola appare in un ampio corpus testuale |
0 a 1 |
|
Lunghezza |
Il numero di caratteri della parola |
0 a 1 |
|
Parte del discorso |
Un set di valori one-hot che rappresentano nome, verbo, aggettivo, altro |
4x [0,1] |
|
Formalità |
Il livello di formalità associato alla parola |
0 a 1 |
|
Specificità |
Quanto la parola sia specifica o generale |
0 a 1 |
|
Associazione sensoriale |
Il grado in cui la parola è associata a esperienze sensoriali |
0 a 1 |
Per esempio, la parola "cat" potrebbe avere un vettore come questo: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] e "freedom" potrebbe essere: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Ogni vettore è come un identificatore unico che non solo racchiude il significato di una parola, ma riflette anche come questa parola si relaziona alle altre. Parole con definizioni simili hanno spesso vettori vicini in questo spazio numerico, proprio come punti adiacenti su una mappa. Questa prossimità rivela le connessioni semantiche tra le parole.
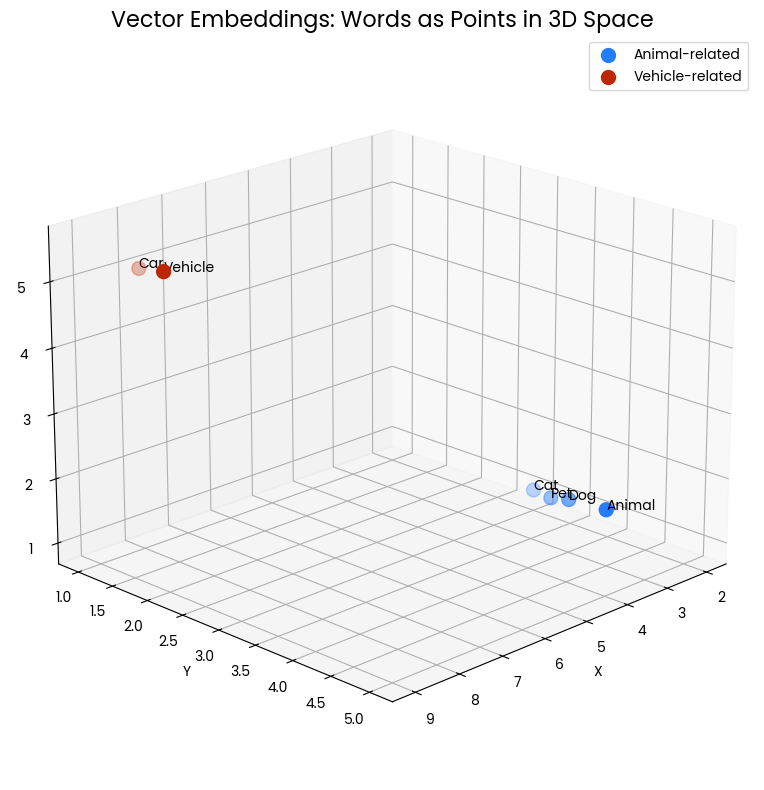
Il seguente grafico a dispersione 3D visualizza il concetto di vector embeddings per le parole. Ogni punto nello spazio rappresenta una parola, con la sua posizione determinata dalla relativa embedding vettoriale. I punti blu raggruppati rappresentano parole legate agli animali (“Cat,” “Dog,” “Pet,” “Animal”), mentre i punti rossi rappresentano parole legate ai veicoli (“Car,” “Vehicle”). La prossimità dei punti indica somiglianza semantica: parole con significati correlati sono posizionate più vicine tra loro in questo spazio vettoriale.
Figura 1: Due cluster di parole in uno spazio tridimensionale. La prossimità indica somiglianza semantica.
Per esempio, “Cat” e “Dog” sono vicine tra loro, a riflettere le caratteristiche comuni come animali domestici. Allo stesso modo, “Car” e “Vehicle” sono vicine, a mostrare i loro significati correlati. Tuttavia, il cluster degli animali è distante da quello dei veicoli, a indicare che questi gruppi di concetti sono semanticamente distinti.
Questa rappresentazione spaziale ci permette di cogliere visivamente come le vector embeddings catturino e rappresentino le relazioni tra parole. Trasforma il significato linguistico in relazioni geometriche misurabili e analizzabili matematicamente.
Le vector embeddings sono particolarmente comuni nell'ambito del Natural Language Processing (NLP), con il focus sulla rappresentazione di singole parole. Queste rappresentazioni numeriche non sono assegnate casualmente: vengono apprese da enormi quantità di testo. Vediamo come funziona.
Una delle tecniche NLP per assegnare vettori alle parole è Word2Vec. È un modello di machine learning che impara ad associare le parole in base al loro contesto all'interno di un ampio corpus di testo. Puoi pensarla come un modello linguistico che cerca di prevedere una parola a partire dalle parole circostanti.
Facendo questo, apprende implicitamente le relazioni tra parole, catturando informazioni semantiche e sintattiche. Queste relazioni apprese vengono poi codificate in vettori numerici, utilizzabili per vari compiti NLP. In definitiva, parole che compaiono spesso insieme o in contesti simili avranno vettori più vicini nello spazio delle embedding.
Word2Vec impiega due architetture principali per catturare le relazioni tra parole: Continuous Bag-of-Words (CBOW) e Skip-gram.
|
Architettura |
Procedura |
Efficienza computazionale |
Relazioni catturate |
Sensibilità alle parole frequenti |
|
CBOW |
Prevede la parola target in base alle parole di contesto circostanti |
Addestramento più rapido |
Migliore nel catturare relazioni sintattiche (regole grammaticali) |
Più sensibile alle parole frequenti |
|
Skip-gram |
Prevede le parole di contesto circostanti in base alla parola target |
Addestramento più lento |
Migliore nel catturare relazioni semantiche (significato del testo) |
Meno sensibile alle parole frequenti |
Skip-gram può essere più lento da addestrare rispetto a CBOW, ma il suo approccio generativo è generalmente considerato in grado di produrre embedding più accurate, soprattutto per le parole rare.
Diamo un'occhiata a un esempio: immagina un vasto corpus di testo. Word2Vec inizia analizzando come le parole co-occorrono all'interno di una specifica finestra di testo. Per esempio, considera la frase "The king and queen ruled the kingdom." Qui, "king" e "queen" compaiono insieme in una piccola finestra. Word2Vec cattura queste informazioni di co-occorrenza.
Su innumerevoli frasi, l'algoritmo costruisce un modello statistico. Impara che parole come "king" e "queen" appaiono frequentemente in contesti simili e codifica queste informazioni in vettori numerici. Di conseguenza, i vettori di "king" e "queen" saranno posizionati più vicini nello spazio delle embedding rispetto al vettore di "apple", che raramente appare nello stesso contesto.
Questa prossimità nello spazio vettoriale riflette la somiglianza semantica tra "king" e "queen", dimostrando la potenza di Word2Vec nel catturare le relazioni linguistiche.
Ora che abbiamo visto cosa sono le vector embeddings e come catturano il significato, è il momento di fare un passo avanti e vedere quali compiti rendono possibili.
Come abbiamo già detto, le vector embeddings eccellono nel quantificare la somiglianza semantica. Misurando la distanza tra vettori di parole, possiamo determinare quanto siano vicini i significati delle parole.
Questa capacità abilita compiti come trovare sinonimi e contrari. Parole con definizioni simili hanno vettori raggruppati, mentre i contrari spesso condividono molte dimensioni ma sono lontani nelle dimensioni chiave che descrivono la loro differenza.
La magia si estende alla soluzione di rompicapi linguistici complessi. Le vector embeddings permettono di eseguire operazioni aritmetiche sui vettori di parole, svelando relazioni nascoste. Per esempio, l'analogia "king sta a queen come man sta a woman" può essere risolta sottraendo il vettore di "man" da quello di "king" e aggiungendolo a quello di "woman". Il vettore risultante dovrebbe corrispondere da vicino al vettore di "queen", a dimostrazione della capacità delle embedding di catturare pattern linguistici.
La versatilità delle embedding va oltre le singole parole. Le sentence embeddings catturano il significato complessivo di intere frasi. Rappresentando le frasi come vettori densi, possiamo misurare la somiglianza semantica tra testi diversi.
Così come le word embeddings sono punti in uno spazio ad alta dimensionalità, anche le sentence embeddings sono vettori. Tuttavia, hanno tipicamente una dimensionalità maggiore per tener conto della complessità delle informazioni a livello di frase. Possiamo eseguire operazioni matematiche sui vettori risultanti per misurare la somiglianza semantica, abilitando compiti più complessi come information retrieval, classificazione del testo e sentiment analysis.
Un metodo semplice consiste nel fare la media delle embedding delle parole presenti in una frase. Pur essendo basilare, spesso fornisce un buon punto di partenza. Per catturare informazioni semantiche e sintattiche più complesse, si impiegano tecniche più avanzate come le Recurrent Neural Networks (RNN) e i modelli basati su transformer :
|
Architettura |
Elaborazione |
Comprensione contestuale |
Efficienza computazionale |
|
RNN |
Sequenziale |
Focus sul contesto locale |
Meno efficienti per sequenze lunghe |
|
Modelli basati su transformer |
Parallela |
Possono catturare dipendenze a lungo raggio |
Altamente efficienti, anche per sequenze lunghe |
Sebbene le RNN siano state a lungo l'architettura dominante, i Transformer le hanno superate in termini di prestazioni ed efficienza per molti compiti NLP, inclusa la generazione di sentence embedding.
Tuttavia, le RNN hanno ancora il loro spazio in applicazioni specifiche in cui l'elaborazione sequenziale è cruciale. Inoltre, sono disponibili molti modelli pre-addestrati di sentence embedding, che offrono soluzioni pronte all'uso per vari compiti come il riassunto testuale, il question answering su basi di conoscenza o Named Entity Recognition (NER).
Le vector embeddings non si limitano al testo. Le applicazioni seguenti evidenziano l'ampio impatto delle embedding in vari domini:
Ora che abbiamo chiarito come funzionano le vector embeddings e quali tipi di dati possono gestire, possiamo esaminare casi d'uso specifici. Iniziamo con uno degli esempi più celebri: i large language model (LLM).
LLM come ChatGPT, Claud o Google Gemini si basano fortemente sulle vector embeddings come componente fondamentale. Questi modelli imparano a rappresentare parole, frasi e persino intere frasi come vettori densi in uno spazio ad alta dimensionalità. In sostanza, le embedding forniscono ai modelli linguistici una comprensione semantica delle parole e delle loro relazioni, formando l'ossatura delle loro impressionanti capacità.
La rappresentazione numerica del testo consente agli LLM di comprendere e generare testo simile a quello umano, abilitando compiti come traduzione, riassunto e question answering. Questo apre un'ampia gamma di campi d'applicazione, dalla creazione di contenuti e assistenza clienti fino all'istruzione e alla ricerca.
Le vector embeddings possono anche offrire un approccio alternativo ai motori di ricerca tradizionali, che spesso si basano sul matching di parole chiave. Le sue limitazioni possono essere superate rappresentando sia le query di ricerca sia le pagine web come embedding, aiutando i motori di ricerca a comprendere il significato semantico dietro le query e le possibili pagine di destinazione. Questo consente di individuare pagine rilevanti oltre le corrispondenze esatte di keyword, fornendo risultati più accurati e informativi.
Un altro punto di forza delle vector embeddings sta nell'identificazione di dati o pattern anomali. Gli algoritmi possono calcolare le distanze tra punti dati rappresentati come vettori e segnalare quelli significativamente distanti dalla norma. Questa tecnica trova applicazione nella rilevazione delle frodi, nella sicurezza di rete e nel monitoraggio dei processi industriali.
Le vector embeddings svolgono anche un ruolo cruciale nel colmare i gap linguistici. Analogamente al nostro esempio con “king” e “queen,” vettori che rappresentano relazioni semantiche e sintattiche tra parole possono essere catturati tra lingue diverse. Di conseguenza, è possibile trovare parole o frasi corrispondenti nella lingua di destinazione in base alla similarità vettoriale, aiutando sistemi di traduzione automatica come DeepL a generare traduzioni più accurate e fluide.
Infine, le vector embeddings sono fondamentali per costruire sistemi di raccomandazione efficaci. Rappresentando utenti e oggetti come embedding, i sistemi di raccomandazione possono identificare utenti o oggetti simili in base alla loro prossimità vettoriale. Questo abilita raccomandazioni personalizzate per prodotti, film, musica e altri contenuti. Per esempio, un utente a cui piacciono film simili a un dato film probabilmente apprezzerà altri film con embedding simili.
Come vedi, le vector embeddings sono emerse come uno strumento molto potente. Trasformando dati complessi in un formato facilmente interpretabile dagli algoritmi di machine learning, sbloccano un'ampia gamma di possibilità in diversi campi.
Ecco i punti chiave da ricordare:
Puoi continuare ad approfondire le vector embeddings con queste risorse:
Impara l'AI da zero!
Programma
Programma
Programma
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

