
Leerpad
AI-basisprincipes
10 Hr
Stel je voor dat je een computer het verschil wilt leren tussen een appel en een sinaasappel. Voor ons is dat eenvoudig te begrijpen, maar voor een machine die alleen getallen begrijpt, is het een complexe uitdaging.
Daar komen vector-embeddings om de hoek kijken. Deze wiskundige trucjes zetten woorden, afbeeldingen en andere gegevens om in numerieke representaties die computers gemakkelijk kunnen begrijpen en bewerken.
Vector-embeddings openen een universum aan mogelijkheden door de informatiewereld in een numerieke ruimte te projecteren.
Vector-embeddings zijn digitale vingerafdrukken voor woorden of andere gegevens. In plaats van letters of afbeeldingen gebruiken ze getallen die zijn gerangschikt in een specifieke structuur, een vector genaamd, vergelijkbaar met een geordende lijst met waarden.
Zie elke vector als een punt in een multidimensionale ruimte, waarbij de locatie belangrijke informatie draagt over het gerepresenteerde woord of de data.
Misschien herinner je je vectoren uit de wiskundeles als pijlen met richting en grootte. Hoewel vector-embeddings dit basisidee delen, werken ze in ruimten met ontelbare dimensies.
Die extreme dimensionaliteit is essentieel om de fijne nuances van menselijke taal vast te leggen, zoals toon, context en grammaticale kenmerken. Stel je een vector voor die niet alleen onderscheid maakt tussen "happy" en "sad", maar ook subtiele variaties als "ecstatic", "content" of "melancholic".
Vector-embeddings zijn een waardevolle techniek om complexe data om te zetten in een formaat dat geschikt is voor machinelearningalgoritmen. Door hoog-dimensionale en categorische data te converteren naar lager-dimensionale, continue representaties verbeteren embeddings zowel de modelprestaties als de rekenefficiëntie, terwijl onderliggende patronen behouden blijven.
Om je een vereenvoudigd beeld te geven van hoe een multidimensionale vectorruimte gedefinieerd zou kunnen worden, zie je hieronder een tabel met acht voorbeelddimensies en de bijbehorende waardebereiken:
|
Kenmerk |
Beschrijving |
Bereik |
|
Concreetheid |
Een maat voor hoe tastbaar of abstract een woord is |
0 tot 1 |
|
Emotionele valentie |
De positiviteit of negativiteit die met het woord geassocieerd is |
-1 tot 1 |
|
Frequentie |
Hoe vaak het woord voorkomt in een groot tekstcorpus |
0 tot 1 |
|
Lengte |
Het aantal tekens in het woord |
0 tot 1 |
|
Woordsoort |
Een set one-hot-gecodeerde waarden voor zelfstandig naamwoord, werkwoord, bijvoeglijk naamwoord, anders |
4x [0,1] |
|
Formaliteit |
Het niveau van formaliteit dat met het woord geassocieerd is |
0 tot 1 |
|
Specificiteit |
Hoe specifiek of algemeen het woord is |
0 tot 1 |
|
Zintuiglijke associatie |
De mate waarin het woord met zintuiglijke ervaringen wordt geassocieerd |
0 tot 1 |
Zo zou het woord "cat" bijvoorbeeld een vector kunnen hebben als: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] en "freedom" zou kunnen zijn: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Elke vector is als een unieke identifier die niet alleen de betekenis van een woord omvat, maar ook weerspiegelt hoe dat woord zich verhoudt tot andere woorden. Woorden met vergelijkbare definities hebben vaak vectors die dicht bij elkaar liggen in deze numerieke ruimte, net als buurpunten op een kaart. Die nabijheid onthult de semantische verbanden tussen woorden.
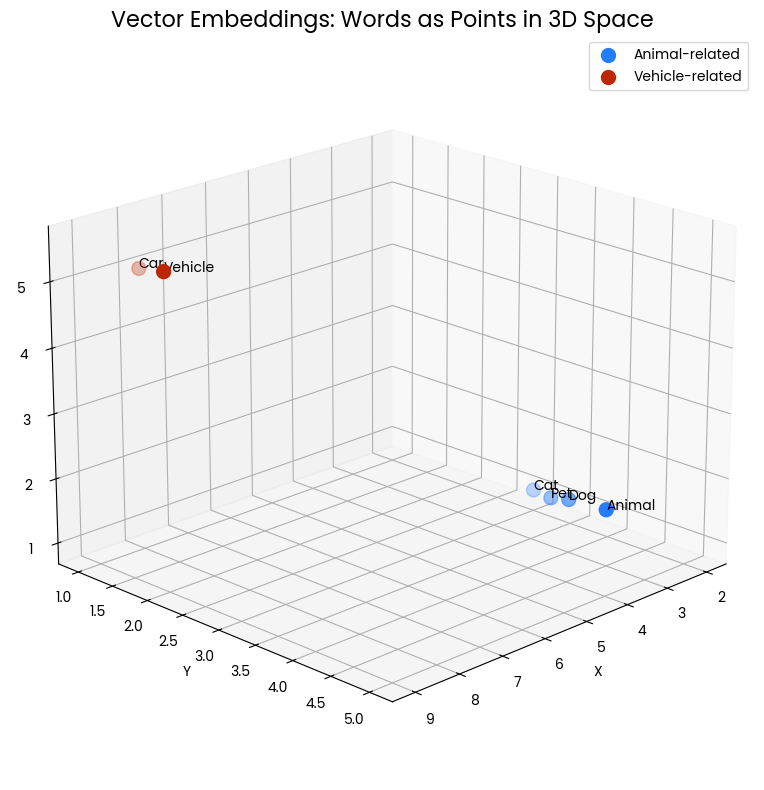
De volgende 3D-strooigrafiek visualiseert het concept van vector-embeddings voor woorden. Elk punt in de ruimte stelt een woord voor, met een positie die wordt bepaald door zijn vector-embedding. De blauwe punten die bij elkaar clusteren, vertegenwoordigen diergerelateerde woorden (“Cat,” “Dog,” “Pet,” “Animal”), terwijl de rode punten voertuiggerelateerde woorden (“Car,” “Vehicle”) voorstellen. De nabijheid van punten geeft semantische overeenkomst aan—woorden met verwante betekenissen staan dichter bij elkaar in deze vectorruimte.
Figuur 1: Twee clusters van woorden in een driedimensionale ruimte. Nabijheid duidt op semantische overeenkomst.
Zo liggen “Cat” en “Dog” dicht bij elkaar, wat hun gedeelde kenmerken als veelvoorkomende huisdieren weerspiegelt. Evenzo liggen “Car” en “Vehicle” dicht bij elkaar, wat hun verwante betekenissen laat zien. Het dierencluster ligt echter ver van het voertuigencluster, wat illustreert dat deze begrippengroepen semantisch verschillend zijn.
Deze ruimtelijke weergave helpt ons visueel te begrijpen hoe vector-embeddings de relaties tussen woorden vastleggen en representeren. Het zet linguïstische betekenis om in geometrische relaties die wiskundig zijn te meten en te analyseren.
Vector-embeddings komen vooral veel voor in de Natural Language Processing (NLP), waarbij de focus ligt op de representatie van individuele woorden. Deze numerieke representaties worden niet willekeurig toegewezen—ze worden geleerd uit enorme hoeveelheden tekstdata. Laten we kijken hoe dat werkt.
Een van de NLP-technieken om vectors aan woorden toe te kennen is Word2Vec. Het is een machinelearningmodel dat leert woorden te associëren op basis van hun context binnen een groot tekstcorpus. Je kunt het zien als een taalmodel dat probeert een woord te voorspellen op basis van de omliggende woorden.
Daarmee leert het impliciet de relaties tussen woorden en legt het semantische en syntactische informatie vast. Deze geleerde relaties worden vervolgens gecodeerd in numerieke vectors, die kunnen worden gebruikt voor uiteenlopende NLP-taken. Uiteindelijk zullen woorden die vaak samen voorkomen of in vergelijkbare contexten verschijnen, vectors hebben die dichter bij elkaar liggen in de embeddingruimte.
Word2Vec gebruikt twee primaire architecturen om woordrelaties vast te leggen: Continuous Bag-of-Words (CBOW) en Skip-gram.
|
Architectuur |
Procedure |
Rekenefficiëntie |
Vastgelegde relaties |
Gevoeligheid voor frequente woorden |
|
CBOW |
Voorspelt doelwoord op basis van omliggende contextwoorden |
Snellere training |
Beter in het vastleggen van syntactische relaties (grammaticale regels) |
Gevoeliger voor frequente woorden |
|
Skip-gram |
Voorspelt omliggende contextwoorden op basis van het doelwoord |
Langzamere training |
Beter in het vastleggen van semantische relaties (tekstbetekenis) |
Minder gevoelig voor frequente woorden |
Skip-gram is mogelijk trager te trainen dan CBOW, maar de generatieve aanpak staat over het algemeen bekend om nauwkeurigere embeddings op te leveren, vooral voor zeldzame woorden.
Laten we een voorbeeld bekijken: stel je een enorm tekstcorpus voor. Word2Vec begint met het analyseren van hoe woorden samen voorkomen binnen een specifiek tekstvenster. Neem bijvoorbeeld de zin "The king and queen ruled the kingdom." Hier komen "king" en "queen" samen voor binnen een klein venster. Word2Vec legt deze co-occurrence-informatie vast.
Over ontelbare zinnen bouwt het algoritme een statistisch model op. Het leert dat woorden als "king" en "queen" vaak in vergelijkbare contexten voorkomen en codeert deze informatie in numerieke vectors. Daardoor zullen de vectors voor "king" en "queen" dichter bij elkaar liggen in de embeddingruimte dan de vector voor "apple", dat zelden in dezelfde context voorkomt.
Die nabijheid in de vectorruimte weerspiegelt de semantische gelijkenis tussen "king" en "queen" en toont de kracht van Word2Vec in het vastleggen van taalkundige relaties.
Nu we weten wat vector-embeddings zijn en hoe ze betekenis vastleggen, is het tijd voor de volgende stap: welke taken maken ze mogelijk?
Zoals we al bespraken, blinken vector-embeddings uit in het kwantificeren van semantische gelijkenis. Door de afstand tussen woordvectors te meten, kunnen we bepalen hoe nauw betekenissen aan elkaar verwant zijn.
Deze mogelijkheid maakt taken als het vinden van synoniemen en antoniemen mogelijk. Woorden met vergelijkbare definities clusteren in de vectorruimte, terwijl antoniemen vaak veel dimensies delen maar ver uit elkaar liggen in de sleuteldimensies die hun verschil beschrijven.
De magie strekt zich ook uit tot het oplossen van complexe taalpuzzels. Vector-embeddings maken rekenkundige bewerkingen op woordvectors mogelijk, waarmee verborgen relaties zichtbaar worden. De analogie "king verhoudt zich tot queen zoals man tot vrouw" kun je bijvoorbeeld oplossen door de vector voor "man" van "king" af te trekken en die op te tellen bij "vrouw". De resulterende vector zal dicht in de buurt komen van de vector voor "queen", wat de kracht van vector-embeddings in het vastleggen van taalkundige patronen laat zien.
De veelzijdigheid van embeddings gaat verder dan losse woorden. Zin-embeddings leggen de algehele betekenis van volledige zinnen vast. Door zinnen als dichte vectors te representeren, kunnen we semantische gelijkenis tussen verschillende teksten meten.
Net zoals woord-embeddings punten zijn in een hoog-dimensionale ruimte, zijn zin-embeddings ook vectors. Ze hebben echter doorgaans een hogere dimensionaliteit om de grotere complexiteit van informatie op zinsniveau te dekken. We kunnen wiskundige bewerkingen uitvoeren op de resulterende vectors om semantische gelijkenis te meten, wat complexere taken mogelijk maakt zoals informatieopzoeking, tekstonderverdeling en sentimentanalyse.
Een eenvoudige methode is het middelen van de woord-embeddings van alle woorden in een zin. Simpel, maar vaak een redelijk vertrekpunt. Om complexere semantische en syntactische informatie vast te leggen, worden geavanceerdere technieken zoals Recurrent Neural Networks (RNN's) en transformer-gebaseerde modellen ingezet:
|
Architectuur |
Verwerking |
Contextueel begrip |
Rekenefficiëntie |
|
RNN's |
Sequentieel |
Focus op lokale context |
Minder efficiënt voor lange reeksen |
|
Transformer-gebaseerde modellen |
Parallel |
Kunnen langeafstandsafhankelijkheden vastleggen |
Zeer efficiënt, ook voor lange reeksen |
Hoewel RNN's lange tijd de dominante architectuur waren, hebben transformers ze op veel NLP-taken ingehaald qua prestaties en efficiëntie, waaronder het genereren van zin-embeddings.
Toch hebben RNN's nog steeds hun plek in specifieke toepassingen waar sequentiële verwerking cruciaal is. Bovendien zijn er veel voorgetrainde modellen voor zin-embeddings beschikbaar, die kant-en-klare oplossingen bieden voor taken als samenvatten, kennisgestuurde vraagbeantwoording of Named Entity Recognition (NER).
Vector-embeddings beperken zich niet tot tekst. De volgende toepassingen laten de brede impact van embeddings in verschillende domeinen zien:
Nu we hebben vastgesteld hoe vector-embeddings werken en welke soorten data ze aankunnen, kunnen we specifieke use-cases bekijken. Laten we beginnen met een van de bekendste voorbeelden: large language models (LLM's).
LLM's zoals ChatGPT, Claud of Google Gemini leunen zwaar op vector-embeddings als fundament. Deze modellen leren woorden, zinnen en zelfs volledige zinnen te representeren als dichte vectors in een hoog-dimensionale ruimte. In wezen geven vector-embeddings taalmodellen een semantisch begrip van woorden en hun relaties en vormen ze de ruggengraat van hun indrukwekkende mogelijkheden.
De numerieke representatie van tekst stelt LLM's in staat om mensachtige tekst te begrijpen en te genereren, wat taken mogelijk maakt zoals vertalen, samenvatten en vraagbeantwoording. Dit opent talloze toepassingsgebieden, van contentcreatie en klantenservice tot onderwijs en onderzoek.
Vector-embeddings kunnen ook een alternatief bieden voor traditionele zoekmachines, die vaak op keywordmatching vertrouwen. Die beperkingen zijn te omzeilen door zowel zoekopdrachten als webpagina's als embeddings te representeren, zodat zoekmachines de semantische betekenis achter zoekopdrachten en potentiële doelpagina's beter begrijpen. Zo kunnen ze relevante pagina's vinden buiten exacte keywordovereenkomsten om en accuratere, informatievere resultaten leveren.
Een andere kracht van vector-embeddings zit in het identificeren van ongebruikelijke datapunten of patronen. Algoritmen kunnen afstanden tussen als vectors weergegeven datapunten berekenen en die markeren die significant afwijken van de norm. Deze techniek wordt toegepast in fraudedetectie, netwerkbeveiliging en monitoring van industriële processen.
Vector-embeddings spelen ook een cruciale rol bij het overbruggen van taalbarrières. Net als in ons voorbeeld met “king” en “queen” kunnen vectors die semantische en syntactische relaties tussen woorden vastleggen, over talen heen worden geleerd. Zo kun je overeenkomstige woorden of zinnen in de doeltaal vinden op basis van vectorsimilariteit, wat vertaalssystemen zoals DeepL helpt om nauwkeurigere en vloeiendere vertalingen te genereren.
Tot slot zijn vector-embeddings onmisbaar bij het bouwen van effectieve aanbevelingssystemen. Door gebruikers en items als embeddings te representeren, kunnen aanbevelingssystemen vergelijkbare gebruikers of items identificeren op basis van vectornabijheid. Dit maakt gepersonaliseerde aanbevelingen mogelijk voor producten, films, muziek en andere content. Iemand die geniet van films die lijken op een bepaalde film, vindt waarschijnlijk ook andere films met vergelijkbare embeddings leuk.
Zoals je ziet, zijn vector-embeddings uitgegroeid tot een zeer krachtig hulpmiddel. Door complexe data om te zetten in een formaat dat machinelearningalgoritmen direct begrijpen, ontsluiten ze een enorme reeks mogelijkheden in uiteenlopende velden.
Dit zijn de belangrijkste punten uit dit artikel:
Je kunt meer leren over vector-embeddings met deze bronnen:
Leer AI vanaf nul!
Leerpad
Leerpad
Leerpad
blog
Adel Nehme
15 min
