
Tracks
Cơ bản về Trí tuệ Nhân tạo
10 giờ
Hãy tưởng tượng bạn cố gắng dạy máy tính phân biệt giữa một quả táo và một quả cam. Với chúng ta thì điều đó thật đơn giản, nhưng với một cỗ máy chỉ được thiết kế để hiểu các con số, đó là một thách thức phức tạp.
Đây chính là lúc vector embedding phát huy tác dụng. Những "mẹo" toán học này biến đổi từ ngữ, hình ảnh và dữ liệu khác thành các biểu diễn số mà máy tính có thể dễ dàng hiểu và xử lý.
Vector embedding mở ra cả một vũ trụ khả năng bằng cách ánh xạ thế giới thông tin vào không gian số.
Vector embedding giống như dấu vân tay số cho từ ngữ hoặc các mẩu dữ liệu khác. Thay vì dùng chữ cái hay hình ảnh, chúng sử dụng các con số được sắp xếp theo một cấu trúc cụ thể gọi là vector, tương tự như một danh sách các giá trị có thứ tự.
Hãy hình dung mỗi vector là một điểm trong không gian đa chiều, nơi vị trí của nó mang thông tin quan trọng về từ hoặc dữ liệu được biểu diễn.
Bạn có thể nhớ đến vector trong các lớp toán như những mũi tên có hướng và độ lớn. Vector embedding kế thừa khái niệm nền tảng này, nhưng hoạt động trong các không gian có vô số chiều.
Độ nhiều chiều cực lớn này là điều thiết yếu để nắm bắt những sắc thái phức tạp của ngôn ngữ tự nhiên, như giọng điệu, ngữ cảnh và đặc điểm ngữ pháp. Hãy tưởng tượng một vector không chỉ phân biệt "happy" và "sad" mà còn cả những biến thể tinh tế như "ecstatic", "content" hay "melancholic".
Vector embedding là kỹ thuật hữu ích để biến đổi dữ liệu phức tạp thành định dạng phù hợp với các thuật toán học máy. Bằng cách chuyển dữ liệu nhiều chiều và dạng phân loại thành các biểu diễn liên tục, ít chiều hơn, embedding vừa nâng cao hiệu năng mô hình vừa tăng hiệu quả tính toán, đồng thời vẫn giữ được các mẫu tiềm ẩn của dữ liệu.
Để bạn có cái nhìn giản lược về cách một không gian vector đa chiều có thể được xác định, dưới đây là bảng minh họa tám chiều mẫu và khoảng giá trị tương ứng:
|
Đặc trưng |
Mô tả |
Khoảng |
|
Tính cụ thể |
Mức độ một từ là hữu hình hay trừu tượng |
0 đến 1 |
|
Giá trị cảm xúc |
Mức độ tích cực hay tiêu cực gắn với từ |
-1 đến 1 |
|
Tần suất |
Tần suất xuất hiện của từ trong một kho văn bản lớn |
0 đến 1 |
|
Độ dài |
Số ký tự trong từ |
0 đến 1 |
|
Từ loại |
Tập giá trị one-hot đại diện cho danh từ, động từ, tính từ, khác |
4x [0,1] |
|
Mức độ trang trọng |
Mức trang trọng gắn với từ |
0 đến 1 |
|
Tính đặc hiệu |
Mức độ cụ thể hay khái quát của từ |
0 đến 1 |
|
Liên hệ giác quan |
Mức độ từ gắn với trải nghiệm giác quan |
0 đến 1 |
Ví dụ, từ "cat" có thể có một vector như sau: [0.9, 0.2, 0.7, 0.3, 1, 0, 0, 0, 0.4, 0.8, 0.9] và "freedom" có thể là: [0.1, 0.8, 0.6, 0.7, 1, 0, 0, 0, 0.7, 0.3, 0.2].
Mỗi vector giống như một định danh duy nhất không chỉ bao hàm ý nghĩa của từ mà còn phản ánh cách từ đó liên hệ với những từ khác. Các từ có định nghĩa tương tự thường có vector nằm gần nhau trong không gian số này, giống như các điểm lân cận trên bản đồ. Sự gần gũi đó hé lộ các kết nối ngữ nghĩa giữa các từ.
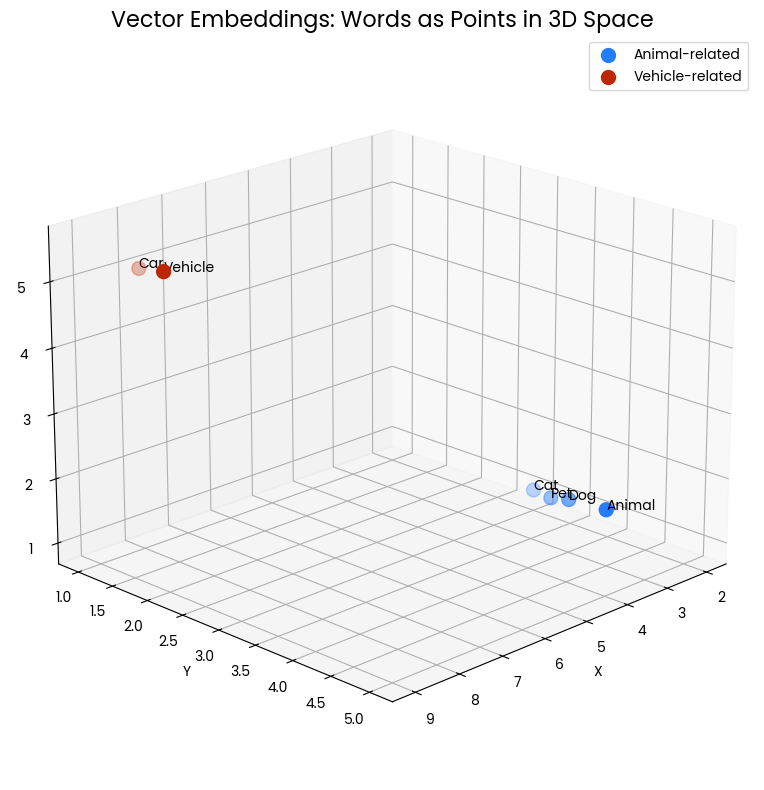
Biểu đồ phân tán 3D dưới đây trực quan hóa khái niệm vector embedding cho các từ. Mỗi điểm trong không gian đại diện cho một từ, với vị trí được xác định bởi vector embedding của nó. Các điểm màu xanh dương tụ lại thể hiện các từ liên quan đến động vật (“Cat,” “Dog,” “Pet,” “Animal”), trong khi các điểm màu đỏ thể hiện các từ liên quan đến phương tiện (“Car,” “Vehicle”). Khoảng cách giữa các điểm cho biết mức độ tương đồng ngữ nghĩa—các từ có ý nghĩa liên quan sẽ được đặt gần nhau hơn trong không gian vector này.
Hình 1: Hai cụm từ trong không gian 3 chiều. Mức độ gần nhau biểu thị sự tương đồng ngữ nghĩa.
Chẳng hạn, “Cat” và “Dog” nằm gần nhau, phản ánh đặc điểm chung là thú cưng phổ biến. Tương tự, “Car” và “Vehicle” gần nhau, thể hiện ý nghĩa liên quan. Tuy nhiên, cụm động vật lại cách xa cụm phương tiện, cho thấy các nhóm khái niệm này khác biệt về mặt ngữ nghĩa.
Cách biểu diễn theo không gian này giúp chúng ta trực quan nắm bắt cách vector embedding ghi nhận và thể hiện mối quan hệ giữa các từ. Nó biến ý nghĩa ngôn ngữ thành các quan hệ hình học có thể đo lường và phân tích bằng toán học.
Vector embedding đặc biệt phổ biến trong Xử lý ngôn ngữ tự nhiên (NLP), tập trung vào việc biểu diễn từng từ. Các biểu diễn số này không được gán ngẫu nhiên—chúng được học từ lượng dữ liệu văn bản khổng lồ. Hãy xem cách chúng hoạt động.
Một trong các kỹ thuật NLP để gán vector cho từ là Word2Vec. Đây là một mô hình học máy học cách liên hệ các từ dựa trên ngữ cảnh của chúng trong một kho văn bản lớn. Bạn có thể xem nó như một mô hình ngôn ngữ cố gắng dự đoán một từ dựa trên các từ xung quanh.
Bằng cách đó, mô hình ngầm học được các mối quan hệ giữa từ, nắm bắt thông tin ngữ nghĩa và cú pháp. Những mối quan hệ đã học này sau đó được mã hóa thành các vector số, có thể dùng cho nhiều tác vụ NLP. Cuối cùng, các từ thường xuất hiện cùng nhau hoặc trong ngữ cảnh tương tự sẽ có vector gần nhau trong không gian embedding.
Word2Vec sử dụng hai kiến trúc chính để nắm bắt quan hệ giữa các từ: Continuous Bag-of-Words (CBOW) và Skip-gram.
|
Kiến trúc |
Quy trình |
Hiệu quả tính toán |
Mối quan hệ nắm bắt |
Độ nhạy với từ xuất hiện thường xuyên |
|
CBOW |
Dự đoán từ mục tiêu dựa trên các từ ngữ cảnh xung quanh |
Huấn luyện nhanh hơn |
Tốt hơn trong việc nắm bắt quan hệ cú pháp (quy tắc ngữ pháp) |
Nhạy hơn với các từ xuất hiện thường xuyên |
|
Skip-gram |
Dự đoán các từ ngữ cảnh xung quanh dựa trên từ mục tiêu |
Huấn luyện chậm hơn |
Tốt hơn trong việc nắm bắt quan hệ ngữ nghĩa (ý nghĩa văn bản) |
Kém nhạy hơn với các từ xuất hiện thường xuyên |
Skip-gram có thể chậm huấn luyện hơn CBOW, nhưng cách tiếp cận sinh (generative) của nó thường được xem là tạo ra embedding chính xác hơn, đặc biệt với các từ hiếm.
Hãy xem một ví dụ: Hình dung một kho văn bản khổng lồ. Word2Vec bắt đầu bằng cách phân tích cách các từ đồng xuất hiện trong một cửa sổ văn bản nhất định. Chẳng hạn, xét câu "The king and queen ruled the kingdom." Ở đây, "king" và "queen" xuất hiện cùng nhau trong một cửa sổ nhỏ. Word2Vec ghi nhận thông tin đồng xuất hiện này.
Qua vô số câu, thuật toán xây dựng một mô hình thống kê. Nó học rằng các từ như "king" và "queen" thường xuất hiện trong ngữ cảnh tương tự và mã hóa thông tin này vào các vector số. Kết quả là, các vector của "king" và "queen" sẽ ở gần nhau trong không gian embedding so với vector của "apple", vốn hiếm khi xuất hiện trong cùng ngữ cảnh.
Sự gần nhau trong không gian vector này phản ánh mức độ tương đồng ngữ nghĩa giữa "king" và "queen", minh chứng sức mạnh của Word2Vec trong việc nắm bắt các mối quan hệ ngôn ngữ.
Giờ chúng ta đã hiểu vector embedding là gì và chúng nắm bắt ý nghĩa ra sao, hãy tiến thêm một bước để xem chúng hỗ trợ những tác vụ nào.
Như đã đề cập, vector embedding vượt trội trong việc định lượng mức độ tương đồng ngữ nghĩa. Bằng cách đo khoảng cách giữa các vector từ, chúng ta có thể xác định mức độ liên quan về ý nghĩa của các từ.
Khả năng này cho phép thực hiện các tác vụ như tìm từ đồng nghĩa và trái nghĩa. Những từ có định nghĩa tương tự sẽ có vector tụ lại thành cụm, trong khi từ trái nghĩa thường chia sẻ nhiều chiều nhưng cách xa nhau ở các chiều then chốt mô tả sự khác biệt của chúng.
"Phép màu" còn mở rộng sang việc giải các câu đố ngôn ngữ phức tạp. Vector embedding cho phép chúng ta thực hiện các phép toán trên vector từ để khám phá những mối quan hệ ẩn. Chẳng hạn, phép tương tự "king đối với queen như man đối với woman" có thể được giải bằng cách lấy vector của "king" trừ đi "man" rồi cộng với "woman". Vector thu được sẽ gần với vector của "queen", cho thấy sức mạnh của embedding trong việc nắm bắt các mẫu ngôn ngữ.
Tính linh hoạt của embedding vượt ra ngoài từng từ riêng lẻ. Embedding cho câu nắm bắt ý nghĩa tổng thể của cả câu. Bằng cách biểu diễn câu dưới dạng vector dày đặc, chúng ta có thể đo mức độ tương đồng ngữ nghĩa giữa các văn bản khác nhau.
Tương tự như embedding từ là các điểm trong không gian nhiều chiều, embedding câu cũng là các vector. Tuy nhiên, chúng thường có số chiều lớn hơn để phản ánh độ phức tạp tăng lên của thông tin cấp độ câu. Ta có thể thực hiện các phép toán trên các vector này để đo tương đồng ngữ nghĩa, từ đó cho phép các tác vụ phức tạp hơn như truy xuất thông tin, phân loại văn bản và phân tích cảm xúc.
Một phương pháp trực quan là lấy trung bình embedding của tất cả các từ trong câu. Dù đơn giản, cách này thường cho kết quả cơ bản khá ổn. Để nắm bắt thông tin ngữ nghĩa và cú pháp phức tạp hơn, các kỹ thuật tiên tiến như Mạng nơ-ron hồi quy (RNN) và các mô hình dựa trên transformer được sử dụng:
|
Kiến trúc |
Cách xử lý |
Hiểu ngữ cảnh |
Hiệu quả tính toán |
|
RNN |
Tuần tự |
Tập trung vào ngữ cảnh cục bộ |
Kém hiệu quả với chuỗi dài |
|
Mô hình dựa trên transformer |
Song song |
Có thể nắm bắt phụ thuộc xa |
Rất hiệu quả, kể cả với chuỗi dài |
Trong khi RNN từng là kiến trúc chủ đạo trong thời gian dài, Transformer đã vượt qua về hiệu năng và hiệu quả cho nhiều tác vụ NLP, bao gồm tạo embedding cho câu.
Tuy vậy, RNN vẫn có chỗ đứng trong những ứng dụng mà xử lý tuần tự là then chốt. Ngoài ra, có nhiều mô hình embedding câu được huấn luyện sẵn, cung cấp giải pháp sẵn dùng cho các tác vụ như tóm tắt văn bản, hỏi đáp dựa trên tri thức hoặc Nhận dạng thực thể có tên (NER).
Vector embedding không chỉ giới hạn ở văn bản. Các ứng dụng sau đây cho thấy ảnh hưởng rộng của embedding trên nhiều lĩnh vực:
Giờ khi đã xác định cách vector embedding hoạt động và những loại dữ liệu chúng có thể xử lý, chúng ta có thể xem các trường hợp sử dụng cụ thể. Hãy bắt đầu với một ví dụ nổi tiếng: các mô hình ngôn ngữ lớn (LLM).
Các LLM như ChatGPT, Claud hoặc Google Gemini phụ thuộc rất nhiều vào vector embedding như một thành phần nền tảng. Những mô hình này học cách biểu diễn từ, cụm từ và thậm chí cả câu dưới dạng các vector dày đặc trong không gian nhiều chiều. Về bản chất, embedding cung cấp cho mô hình ngôn ngữ khả năng hiểu ngữ nghĩa của từ và mối quan hệ giữa chúng, tạo thành xương sống cho các năng lực ấn tượng của mô hình.
Biểu diễn số của văn bản cho phép LLM hiểu và tạo văn bản giống con người, cho phép thực hiện các tác vụ như dịch thuật, tóm tắt và hỏi đáp. Điều này mở ra nhiều lĩnh vực ứng dụng tiềm năng, từ sáng tạo nội dung và chăm sóc khách hàng đến giáo dục và nghiên cứu.
Vector embedding cũng có thể mang lại cách tiếp cận thay thế cho các công cụ tìm kiếm truyền thống, vốn thường dựa vào khớp từ khóa. Bằng cách biểu diễn cả truy vấn tìm kiếm và trang web dưới dạng embedding, công cụ tìm kiếm có thể hiểu ý nghĩa ngữ nghĩa đằng sau truy vấn và các trang mục tiêu tiềm năng. Nhờ đó, chúng xác định các trang liên quan vượt ra ngoài khớp từ khóa chính xác, đem lại kết quả chính xác và hữu ích hơn.
Một thế mạnh khác của embedding là phát hiện các điểm dữ liệu hoặc mẫu bất thường. Thuật toán có thể tính khoảng cách giữa các điểm dữ liệu được biểu diễn dưới dạng vector và gắn cờ những điểm cách xa đáng kể so với chuẩn. Kỹ thuật này được ứng dụng trong phát hiện gian lận, an ninh mạng và giám sát quy trình công nghiệp.
Vector embedding cũng đóng vai trò quan trọng trong việc thu hẹp khoảng cách ngôn ngữ. Tương tự ví dụ với “king” và “queen,” các vector thể hiện mối quan hệ ngữ nghĩa và cú pháp giữa các từ có thể được học xuyên ngôn ngữ. Theo đó, có thể tìm các từ hoặc cụm từ tương ứng trong ngôn ngữ đích dựa trên độ tương đồng vector, giúp các hệ thống dịch máy như DeepL tạo ra bản dịch chính xác và trôi chảy hơn.
Cuối cùng, embedding là thành phần then chốt để xây dựng hệ thống gợi ý hiệu quả. Bằng cách biểu diễn người dùng và đối tượng dưới dạng embedding, hệ thống gợi ý có thể xác định người dùng hoặc đối tượng tương tự dựa trên độ gần về vector. Điều này cho phép gợi ý cá nhân hóa cho sản phẩm, phim, nhạc và nội dung khác. Ví dụ, một người dùng thích các bộ phim tương tự một bộ phim nhất định nhiều khả năng cũng sẽ thích những bộ phim có embedding tương tự.
Như bạn thấy, vector embedding đã nổi lên như một công cụ rất mạnh mẽ. Bằng cách biến đổi dữ liệu phức tạp thành định dạng mà các thuật toán học máy dễ dàng hiểu, chúng mở khóa vô vàn khả năng trong nhiều lĩnh vực.
Dưới đây là những điểm chính rút ra từ bài viết:
Bạn có thể tiếp tục tìm hiểu về vector embedding qua các tài nguyên sau:
Học AI từ con số 0!
Tracks
Tracks
Tracks