Kurs
Python’a Giriş
4 sa
6.9M
Karar ağacı, bir iç düğümün bir özelliği (veya niteliği) temsil ettiği, dalın bir karar kuralını temsil ettiği ve her yaprak düğümün sonucu temsil ettiği akış şeması benzeri bir ağaç yapısıdır.
Karar ağacındaki en üst düğüme kök düğüm denir. Öznitelik değerine göre nasıl bölüneceğini öğrenir. Ağacı özyinelemeli bölümleme adı verilen yinelemeli bir şekilde böler. Bu akış şeması benzeri yapı karar vermede yardımcı olur. Görselleştirmesi, insan düzeyindeki düşünmeyi kolayca taklit eden bir akış şeması gibidir. Bu yüzden karar ağaçlarını anlamak ve yorumlamak kolaydır.
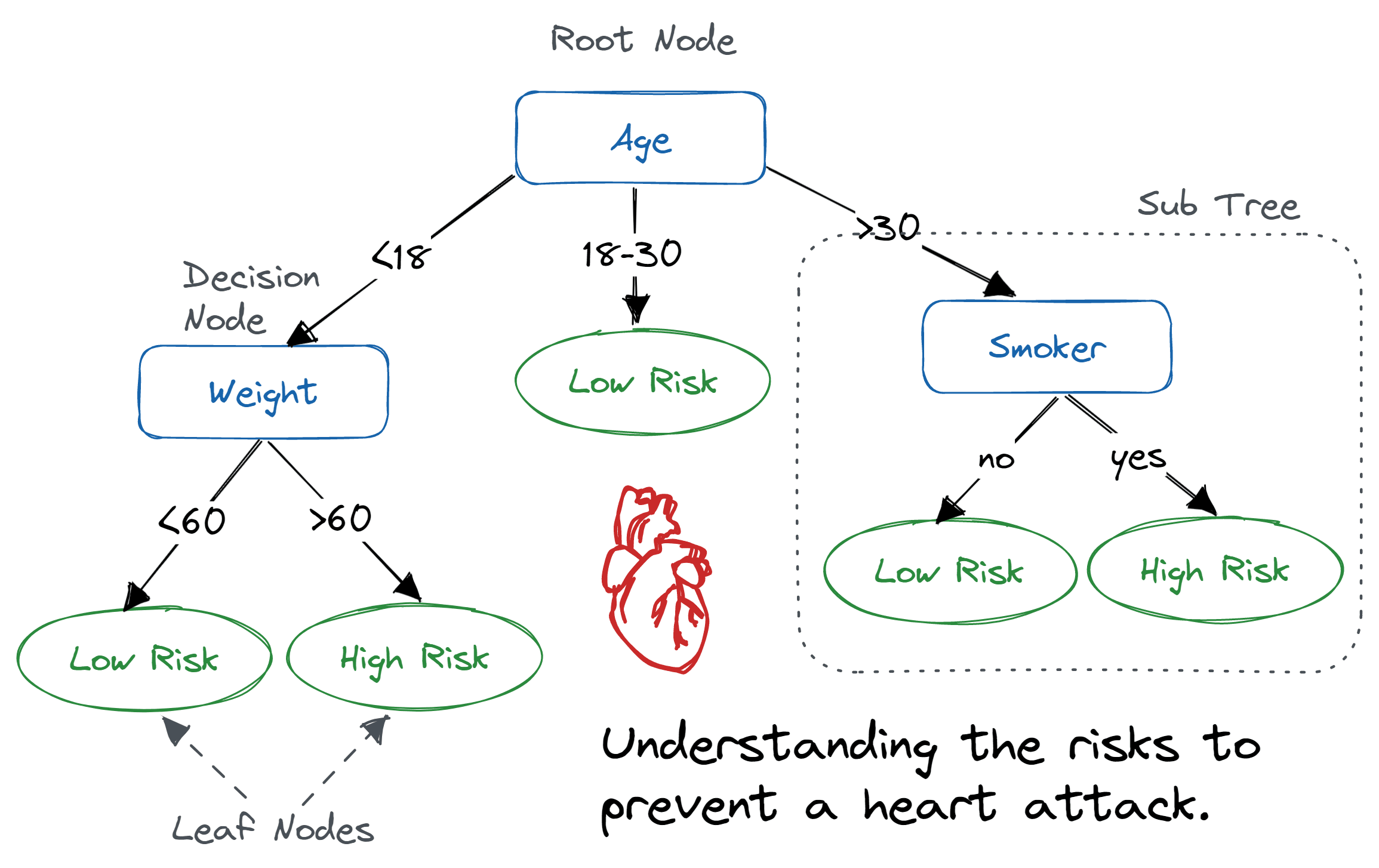
Karar ağacı algoritması. Görsel: Abid Ali Awan
Karar ağacı, beyaz kutu (white box) türü bir ML algoritmasıdır. yapay sinir ağı gibi siyah kutu türü algoritmalarda bulunmayan dahili karar verme mantığını paylaşır. Eğitimi, sinir ağı algoritmasına kıyasla daha hızlıdır.
Karar ağaçlarının zaman karmaşıklığı, verilen verilerdeki kayıt ve öznitelik sayısının bir fonksiyonudur. Karar ağacı, verilerin altta yatan olasılık dağılımına ilişkin varsayımlara bağlı olmayan dağılımdan bağımsız veya parametrik olmayan bir yöntemdir. Karar ağaçları, yüksek boyutlu verileri iyi bir doğrulukla işleyebilir.
Herhangi bir karar ağacı algoritmasının temel fikri şöyledir:
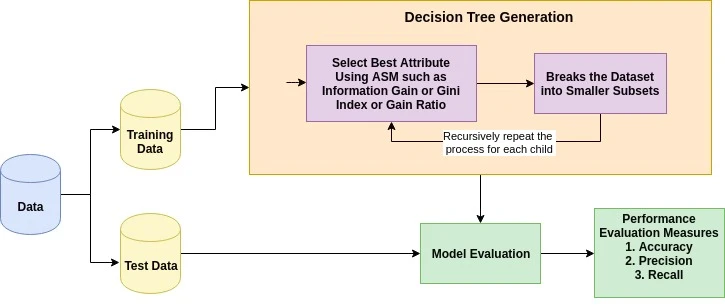
Öznitelik seçim ölçütü, verileri mümkün olan en iyi şekilde bölecek ayrım ölçütünü seçmeye yönelik sezgisel bir yöntemdir. Bir düğümde demetler için kırılma noktalarını belirlemeye yardımcı olduğu için bölme kuralları olarak da bilinir. ASM, verilen veri kümesini açıklayarak her özelliğe (veya özniteliğe) bir sıralama verir. En iyi skora sahip öznitelik, bölme özniteliği olarak seçilir (Kaynak). Sürekli değerli bir öznitelik söz konusu olduğunda, dallar için bölme noktalarının da tanımlanması gerekir. En popüler seçim ölçütleri Bilgi Kazancı (Information Gain), Kazanç Oranı (Gain Ratio) ve Gini İndeksi'dir.
Claude Shannon, girdi kümesinin safsızlığını ölçen entropi kavramını icat etti. Fizik ve matematikte entropi, bir sistemdeki rastgelelik veya safsızlık olarak ifade edilir. Bilgi kuramında ise örnekler grubundaki safsızlığı ifade eder. Bilgi kazancı, entropideki azalmadır. Bilgi kazancı, veri kümesi verilmiş öznitelik değerlerine göre bölünmeden önceki entropi ile bölünmeden sonraki ortalama entropi arasındaki farkı hesaplar. ID3 (Iterative Dichotomiser) karar ağacı algoritması bilgi kazancını kullanır.
Burada Pi, D içindeki rastgele bir demetin Ci sınıfına ait olma olasılığıdır.
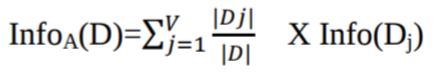
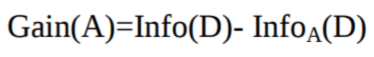
Burada:
Info(D), D içindeki bir demetin sınıf etiketini belirlemek için gereken ortalama bilgi miktarıdır.
|Dj|/|D|, jinci bölümün ağırlığı olarak işlev görür.
InfoA(D), D'den bir demeti, A tarafından yapılan bölümlemeye göre sınıflandırmak için gereken beklenen bilgidir.
En yüksek bilgi kazancına sahip A özniteliği, düğüm N() için bölme özniteliği olarak seçilir.
Bilgi kazancı, çok sayıda çıktıya sahip özniteliklere karşı önyargılıdır. Yani çok sayıda farklı değeri olan öznitelikleri tercih eder. Örneğin, müşteri_kimliği gibi benzersiz tanımlayıcıya sahip bir özniteliği düşünün; saf bölme nedeniyle info(D)'si sıfırdır. Bu, bilgi kazancını en üst düzeye çıkarır ve işe yaramaz bölmelere yol açar.
ID3'ün bir iyileştirmesi olan C4.5, bilgi kazancının bir uzantısı olan kazanç oranını kullanır. Kazanç oranı, Bölme Bilgisi (Split Info) kullanarak bilgi kazancını normalize ederek önyargı sorununu ele alır. C4.5 algoritmasının Java uygulaması, WEKA veri madenciliği aracında bulunan J48 olarak bilinir.
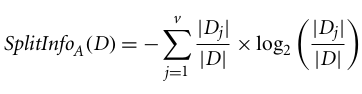
Burada:
Kazanç oranı şöyle tanımlanabilir
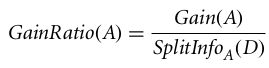
En yüksek kazanç oranına sahip öznitelik, bölme özniteliği olarak seçilir (Kaynak).
Başka bir karar ağacı algoritması olan CART (Classification and Regression Tree), bölme noktaları oluşturmak için Gini yöntemini kullanır.
Burada pi, D içindeki bir demetin Ci sınıfına ait olma olasılığıdır.
Gini İndeksi her öznitelik için ikili bir bölmeyi dikkate alır. Her bölümün safsızlığının ağırlıklı toplamını hesaplayabilirsiniz. A özniteliği üzerindeki ikili bir bölme, D verisini D1 ve D2'ye ayırıyorsa, D'nin Gini indeksi şöyledir:
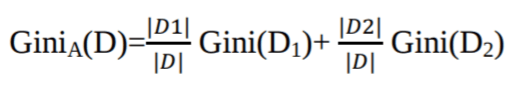
Ayrık değerli bir öznitelik söz konusu olduğunda, seçilen için minimum gini indeksini veren alt küme bölme özniteliği olarak seçilir. Sürekli değerli öznitelikler için strateji, bitişik her değer çiftini olası bir bölme noktası olarak seçmektir ve daha küçük gini indeksine sahip nokta bölme noktası olarak seçilir.
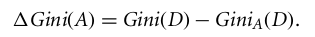
En düşük Gini indeksine sahip öznitelik, bölme özniteliği olarak seçilir.
Bu eğitimdeki kodu çevrimiçi olarak çalıştırın ve düzenleyin
Kodu çalıştırÖnce gerekli kütüphaneleri yükleyelim.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Önce pandas'ın CSV okuma fonksiyonunu kullanarak gerekli Pima Indian Diabetes veri setini yükleyelim. Takip edebilmek için Kaggle veri setini indirebilirsiniz.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
Burada, verilen sütunları bağımlı (veya hedef değişken) ve bağımsız değişken (veya özellik değişkenleri) olmak üzere iki türe ayırmanız gerekir.
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Model performansını anlamak için veri kümesini eğitim ve test seti olarak bölmek iyi bir stratejidir.
train_test_split() fonksiyonunu kullanarak veri kümesini bölelim. Üç parametre geçirmeniz gerekir: özellikler, hedef ve test seti boyutu.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Scikit-learn kullanarak bir karar ağacı modeli oluşturalım.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Sınıflandırıcının veya modelin, kültivar türünü ne kadar doğru tahmin edebildiğini tahmin edelim.
Doğruluk, gerçek test seti değerleri ile tahmin edilen değerler karşılaştırılarak hesaplanabilir.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
%67,53'lük bir sınıflandırma oranı elde ettik; bu iyi bir doğruluk olarak kabul edilir. Karar ağacı algoritmasındaki parametreleri ayarlayarak bu doğruluğu artırabilirsiniz.
Ağacı bir Jupyter not defterinde görüntülemek için Scikit-learn'ün export_graphviz() fonksiyonunu kullanabilirsiniz. Ağacı çizdirmek için ayrıca graphviz ve pydotplus kurmanız gerekir.
pip install graphviz
pip install pydotplusexport_graphviz() fonksiyonu karar ağacı sınıflandırıcısını bir dot dosyasına dönüştürür ve pydotplus bu dot dosyasını PNG'ye veya Jupyter'da görüntülenebilir bir biçime çevirir.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())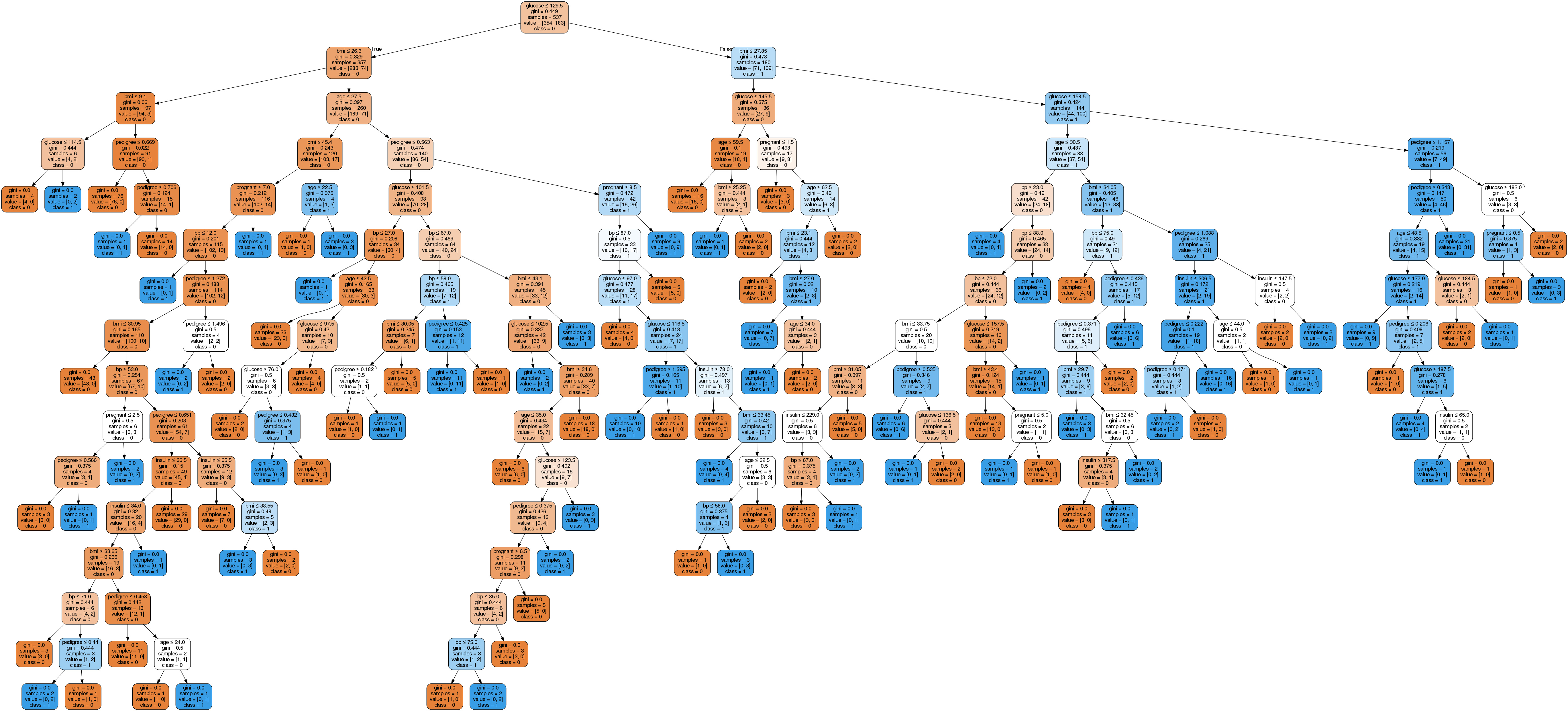
Karar ağacı grafiğinde, her iç düğüm veriyi bölen bir karar kuralına sahiptir. Gini (Gini oranı olarak anılır), düğümün safsızlığını ölçer. Tüm kayıtları aynı sınıfa ait olduğunda bir düğümün saf olduğunu söyleyebilirsiniz; bu tür düğümler yaprak düğümü olarak bilinir.
Burada, ortaya çıkan ağaç budanmamıştır. Bu budanmamış ağaç açıklanabilir değildir ve anlaması kolay değildir. Bir sonraki bölümde budama yaparak optimize edelim.
criterion: isteğe bağlı (varsayılan=”gini”) veya Öznitelik seçim ölçütü seçimi. Bu parametre, farklı öznitelik seçim ölçütlerini kullanmamıza olanak tanır. Desteklenen ölçütler Gini indeksi için “gini” ve bilgi kazancı için “entropy”dir.
splitter: string, isteğe bağlı (varsayılan=”best”) veya Bölme stratejisi. Bu parametre, bölme stratejisini seçmemize olanak tanır. Desteklenen stratejiler en iyi bölmeyi seçmek için “best” ve rastgele en iyi bölmeyi seçmek için “random”dır.
max_depth: int veya None, isteğe bağlı (varsayılan=None) veya Ağacın azami derinliği. Ağacın maksimum derinliğidir. None ise, tüm yapraklar min_samples_split örnekten daha azını içerecek şekilde düğümler genişletilir. Maksimum derinliğin yüksek değeri aşırı öğrenmeye, düşük değeri ise yetersiz öğrenmeye neden olur (Kaynak).
Scikit-learn'de karar ağacı sınıflandırıcısının optimizasyonu yalnızca ön budama ile gerçekleştirilir. Ağacın maksimum derinliği, ön budama için bir kontrol değişkeni olarak kullanılabilir. Aşağıdaki örnekte, aynı veriler üzerinde max_depth=3 ile bir karar ağacı çizebilirsiniz. Ön budama parametrelerinin yanı sıra, bilgi ölçütü olarak entropy gibi diğer seçim ölçütlerini de deneyebilirsiniz.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Görüldüğü gibi, sınıflandırma oranı %77,05'e yükseldi; bu, önceki modelden daha iyi bir doğruluktur.
Karar ağacımızı aşağıdaki kodu kullanarak biraz daha anlaşılır hale getirelim:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Burada şu adımları tamamladık:
Gerekli kütüphaneleri içe aktardık.
Karar ağacının metin temsiliyi tutmak için dot_data adlı bir StringIO nesnesi oluşturduk.
export_graphviz fonksiyonunu kullanarak karar ağacını dot formatına aktardık ve çıktıyı dot_data arabelleğine yazdık.
dot_data arabelleğinde saklanan karar ağacının dot formatı temsilinden bir pydotplus grafik nesnesi oluşturduk.
Oluşturulan grafiği "diabetes.png" adlı bir PNG dosyasına yazdık.
IPython.display modülündeki Image nesnesini kullanarak karar ağacının oluşturulan PNG görüntüsünü görüntüledik.
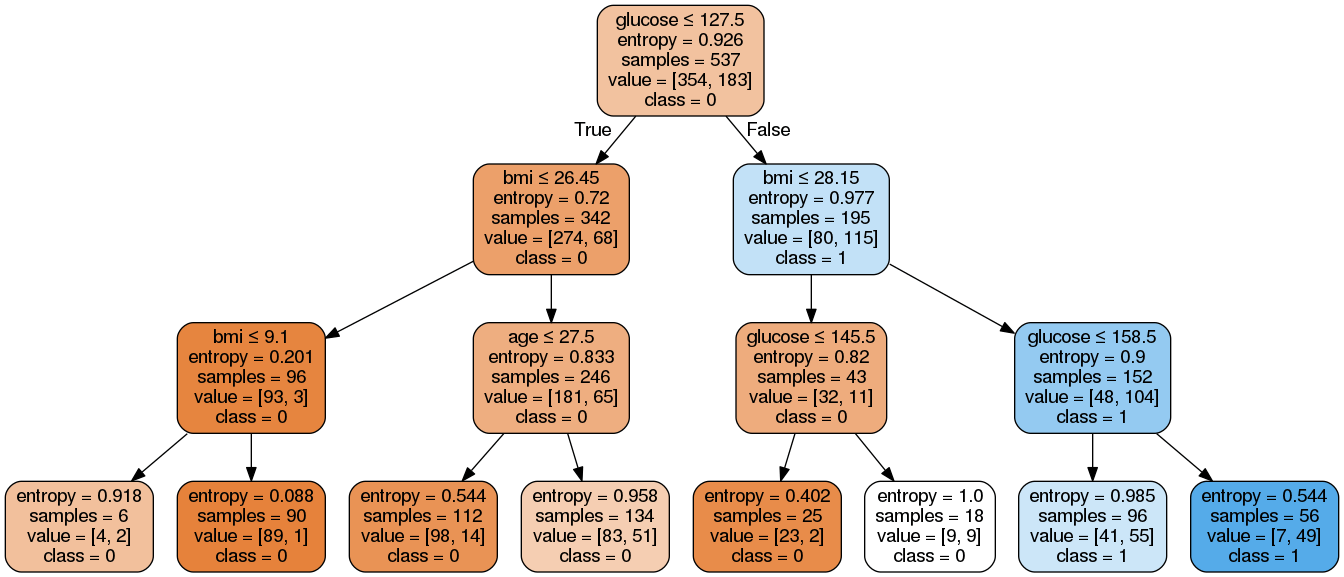
Görüldüğü gibi, bu budanmış model önceki karar ağacı görselleştirmesine göre daha az karmaşık, daha açıklanabilir ve anlaması daha kolaydır.
Artık bir karar ağacı sınıflandırıcısı oluşturup optimize ettiğinize göre, algoritmanın genel olarak bazı güçlü ve sınırlı yönlerini değerlendirelim. Değiş tokuşları anlamak, karar ağaçlarının ne zaman doğru tercih olduğuna karar vermenize yardımcı olur.
| Avantajlar | Dezavantajlar |
|---|---|
| Yorumlaması ve görselleştirmesi kolay | Gürültülü veriye duyarlıdır ve aşırı uyum gösterebilir |
| Doğrusal olmayan desenleri kolayca yakalayabilir | Verideki küçük değişiklikler çok farklı ağaçlara yol açabilir |
| Asgari veri ön işleme gerektirir (sütunları normalize etmeye gerek yok) | Dengesiz veri kümelerinde önyargılıdır (dengelenmesi önerilir) |
| Özellik mühendisliği için faydalıdır (eksik değerleri tahmin etme, değişken seçimi) | |
| Veri dağılımına ilişkin hiçbir varsayım yoktur (parametrik olmayan) |
Varyans kararsızlığı gibi bazı dezavantajların, bagging ve boosting gibi topluluk (ensemble) yöntemleriyle hafifletilebileceğini unutmayın.
Bu eğitim boyunca tam karar ağaçlarıyla çalışmış olsak da, decision stump adı verilen daha basit bir varyantı anlamaya değer. Decision stump, maksimum derinliği bir olan—yani kök düğümde tek bir bölmeye ve iki yaprak düğüme sahip—bir karar ağacıdır.
| Boyut | Karar Ağacı | Decision Stump |
|---|---|---|
| Derinlik | Herhangi bir derinlikte olabilir (max_depth parametresiyle kontrol edilir) |
Daima derinlik 1'dir (yalnızca bir bölme) |
| Karmaşıklık | Karmaşık, doğrusal olmayan ilişkileri modelleyebilir | Yalnızca basit, doğrusal karar sınırlarını modeller |
| Kullanım Amacı | Karmaşık problemler için tek başına sınıflandırıcı | Esas olarak topluluk yöntemlerinde zayıf öğrenici olarak kullanılır |
| Doğruluk | Genellikle tek başına model olarak daha yüksek doğruluk | Daha düşük doğruluk, ancak birleştirildiğinde etkilidir |
| Yorumlanabilirlik | Derinlikle birlikte azalır (budanmamış ağacımızda gördüğümüz gibi) | Aşırı derecede basit ve yorumlanabilir |
Decision stump'lar basitlikleri nedeniyle nadiren tek başına sınıflandırıcı olarak kullanılır. Ancak topluluk yöntemlerinde rol oynayabilir; özellikle AdaBoost decision stump'ları güçlü bir sınıflandırıcı oluşturmak için birleştirilen zayıf öğreniciler olarak kullanır ya da gradient boosting sürecinde stump'lar temel öğreniciler olarak kullanılabilir.
Scikit-learn'de max_depth=1 ayarlayarak kolayca bir decision stump oluşturabilirsiniz:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Tebrikler, bu eğitimin sonuna ulaştınız!
Bu eğitimde, karar ağaçlarıyla ilgili pek çok detayı ele aldınız; nasıl çalıştıkları, Bilgi Kazancı, Kazanç Oranı ve Gini İndeksi gibi öznitelik seçim ölçütleri, karar ağacı modeli oluşturma, görselleştirme ve Python'un Scikit-learn paketiyle diyabet veri setinin değerlendirilmesi. Ayrıca artılarını, eksilerini ve parametre ayarlama yoluyla karar ağacı performansını nasıl optimize edeceğinizi tartıştık.
Umarız artık karar ağacı algoritmasını kendi veri kümelerinizi analiz etmek için kullanabilirsiniz.
Python'da Makine Öğrenmesi hakkında daha fazla bilgi edinmek isterseniz, Machine Learning with Tree-Based Models in Python kursumuzu alın. Ayrıca Kaggle Eğitimi: İlk Makine Öğrenmesi Modeliniz yazımıza da göz atın.
Python Kursları
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
