Corso
Introduzione a Python
4 h
6.9M
Un albero decisionale è una struttura ad albero simile a un diagramma di flusso in cui un nodo interno rappresenta una caratteristica (o attributo), il ramo rappresenta una regola decisionale e ogni foglia rappresenta l'esito.
Il nodo più in alto in un albero decisionale è detto nodo radice. Impara a effettuare partizioni in base al valore dell'attributo. Partiziona l'albero in modo ricorsivo, processo chiamato partizionamento ricorsivo. Questa struttura simile a un diagramma di flusso ti aiuta nel processo decisionale. La sua visualizzazione ricorda un diagramma di flusso che imita facilmente il pensiero umano. Ecco perché gli alberi decisionali sono facili da capire e interpretare.
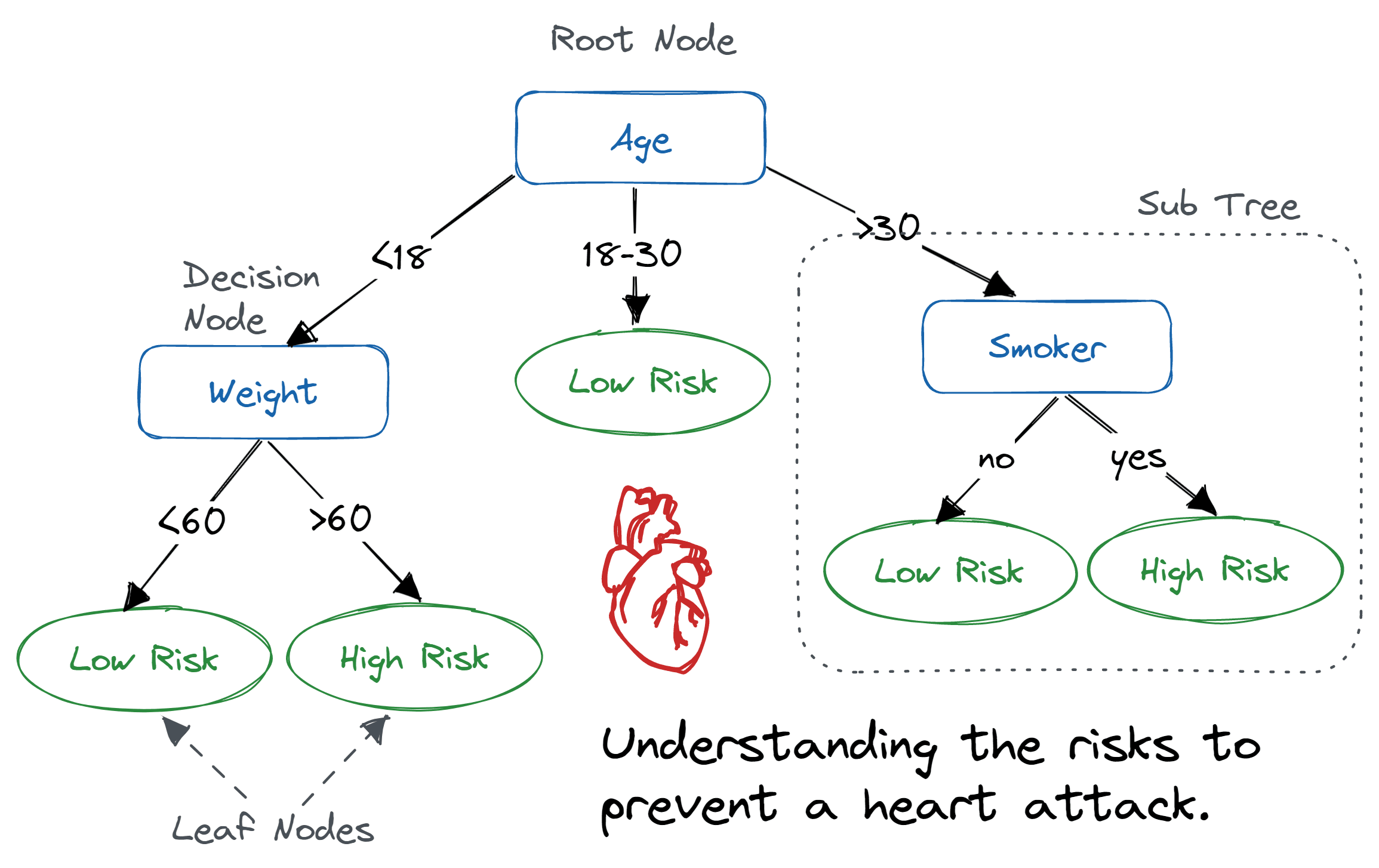
Algoritmo ad albero decisionale. Immagine di Abid Ali Awan
Un albero decisionale è un algoritmo di ML di tipo "scatola bianca". Condivide la logica decisionale interna, cosa che non avviene con gli algoritmi di tipo "scatola nera" come una rete neurale. Il tempo di training è più rapido rispetto a quello di una rete neurale.
La complessità temporale degli alberi decisionali è funzione del numero di record e di attributi nei dati forniti. L'albero decisionale è un metodo non parametrico e privo di ipotesi sulla distribuzione di probabilità sottostante dei dati. Gli alberi decisionali possono gestire dati ad alta dimensionalità con buona accuratezza.
L'idea di base dietro qualsiasi algoritmo ad albero decisionale è la seguente:
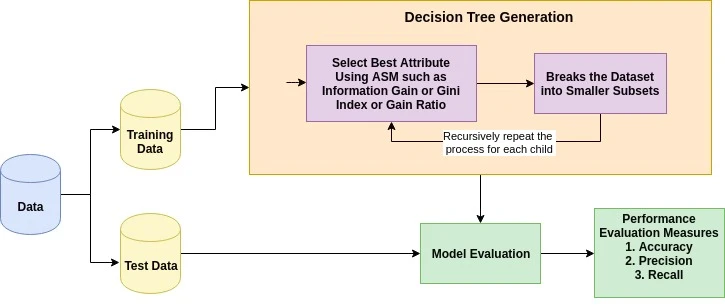
La misura di selezione degli attributi è un euristico per scegliere il criterio di split che partiziona i dati nel modo migliore possibile. È anche nota come regola di suddivisione perché ci aiuta a determinare i punti di rottura per le tuple in un dato nodo. Le ASM forniscono un punteggio a ogni caratteristica (o attributo) spiegando il dataset fornito. L'attributo con il punteggio migliore verrà selezionato come attributo di suddivisione (Fonte). Nel caso di un attributo a valori continui, è necessario definire anche i punti di split per i rami. Le misure di selezione più popolari sono Information Gain, Gain Ratio e Indice di Gini.
Claude Shannon ha inventato il concetto di entropia, che misura l'impurità dell'insieme di input. In fisica e matematica, l'entropia si riferisce alla casualità o all'impurità in un sistema. Nella teoria dell'informazione, si riferisce all'impurità in un gruppo di esempi. L'information gain è la diminuzione di entropia. L'information gain calcola la differenza tra l'entropia prima dello split e l'entropia media dopo lo split del dataset in base ai valori dell'attributo considerato. L'algoritmo ad albero decisionale ID3 (Iterative Dichotomiser) utilizza l'information gain.
Dove Pi è la probabilità che una tupla arbitraria in D appartenga alla classe Ci.
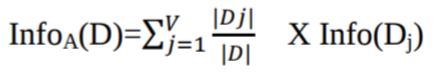
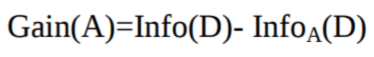
Dove:
Info(D) è la quantità media di informazione necessaria per identificare l'etichetta di classe di una tupla in D.
|Dj|/|D| funge da peso per la jesima partizione.
InfoA(D) è l'informazione attesa necessaria per classificare una tupla da D in base alla partizione determinata da A.
L'attributo A con il maggior information gain, Gain(A), è scelto come attributo di suddivisione nel nodo N().
L'information gain è distorto a favore degli attributi con molti esiti. Significa che preferisce l'attributo con un gran numero di valori distinti. Per esempio, considera un attributo con un identificatore univoco, come customer_ID, che ha info(D) pari a zero a causa di una partizione pura. Questo massimizza l'information gain e crea suddivisioni inutili.
C4.5, un miglioramento di ID3, utilizza un'estensione dell'information gain nota come gain ratio. Il gain ratio gestisce il problema del bias normalizzando l'information gain tramite Split Info. L'implementazione Java dell'algoritmo C4.5 è nota come J48, disponibile nello strumento di data mining WEKA.
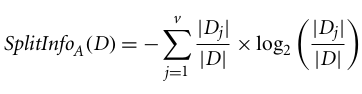
Dove:
Il gain ratio può essere definito come
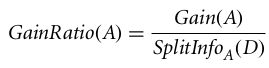
L'attributo con il gain ratio più alto è scelto come attributo di suddivisione (Fonte).
Un altro algoritmo ad albero decisionale, CART (Classification and Regression Tree), utilizza il metodo di Gini per creare i punti di split.
Dove pi è la probabilità che una tupla in D appartenga alla classe Ci.
L'indice di Gini considera uno split binario per ciascun attributo. Puoi calcolare una somma pesata dell'impurità di ciascuna partizione. Se uno split binario sull'attributo A partiziona i dati D in D1 e D2, l'indice di Gini di D è:
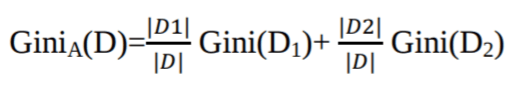
Nel caso di un attributo a valori discreti, viene selezionato come attributo di suddivisione il sottoinsieme che fornisce l'indice di Gini minimo. Nel caso di attributi a valori continui, la strategia consiste nel selezionare ogni coppia di valori adiacenti come possibile punto di split, e viene scelto come punto di suddivisione quello con indice di Gini minore.
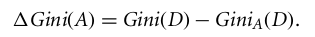
L'attributo con l'indice di Gini minimo è scelto come attributo di suddivisione.
Esegui e modifica il codice da questo tutorial online
Esegui codicePer prima cosa carichiamo le librerie richieste.
# Load libraries
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
Per prima cosa carichiamo il dataset Pima Indian Diabetes utilizzando la funzione read CSV di pandas. Puoi scaricare il dataset su Kaggle per seguire passo passo.
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("diabetes.csv", header=None, names=col_names)
pima.head()
| pregnant | glucose | bp | skin | insulin | bmi | pedigree | age | label | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
Qui devi dividere le colonne fornite in due tipi di variabili: dipendente (o variabile target) e indipendente (o variabili di input).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variable
Per comprendere le prestazioni del modello, è buona norma dividere il dataset in un set di training e uno di test.
Suddividiamo il dataset usando la funzione train_test_split(). Devi passare tre parametri: caratteristiche, target e dimensione del set di test.
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) # 70% training and 30% test
Creiamo un modello ad albero decisionale usando Scikit-learn.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier()
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
Stimiamo con quanta accuratezza il classificatore o modello può predire il tipo di cultivar.
L'accuratezza può essere calcolata confrontando i valori reali del set di test con i valori predetti.
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.6753246753246753
Abbiamo ottenuto un tasso di classificazione del 67,53%, considerato una buona accuratezza. Puoi migliorare questa accuratezza regolando i parametri dell'algoritmo dell'albero decisionale.
Puoi usare la funzione export_graphviz() di Scikit-learn per visualizzare l'albero in un notebook Jupyter. Per tracciare l'albero, devi anche installare graphviz e pydotplus.
pip install graphviz
pip install pydotplusLa funzione export_graphviz() converte il classificatore ad albero decisionale in un file dot, e pydotplus converte questo file dot in PNG o in una forma visualizzabile su Jupyter.
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from IPython.display import Image
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True, rounded=True,
special_characters=True,feature_names = feature_cols,class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())
Nel grafico dell'albero decisionale, ogni nodo interno ha una regola decisionale che suddivide i dati. Gini, indicato come indice di Gini, misura l'impurità del nodo. Si può dire che un nodo è puro quando tutti i suoi record appartengono alla stessa classe; tali nodi sono detti nodi foglia.
Qui, l'albero risultante non è potato. Questo albero non potato è poco spiegabile e non facile da comprendere. Nella prossima sezione, ottimizziamolo con il pruning.
criterion: opzionale (default=”gini”) ovvero scelta della misura di selezione degli attributi. Questo parametro permette di usare diverse misure di selezione degli attributi. I criteri supportati sono “gini” per l'indice di Gini ed “entropy” per l'information gain.
splitter: stringa, opzionale (default=”best”) ovvero strategia di split. Questo parametro consente di scegliere la strategia di split. Le strategie supportate sono “best” per scegliere lo split migliore e “random” per scegliere il miglior split casuale.
max_depth: int o None, opzionale (default=None) ovvero profondità massima dell'albero. La profondità massima dell'albero. Se None, i nodi vengono espansi finché tutte le foglie contengono meno di min_samples_split campioni. Un valore elevato della profondità massima provoca overfitting, mentre un valore basso causa underfitting (Fonte).
In Scikit-learn, l'ottimizzazione del classificatore ad albero decisionale viene effettuata solo tramite pre-pruning. La profondità massima dell'albero può essere utilizzata come variabile di controllo per il pre-pruning. Nel seguente esempio, puoi tracciare un albero decisionale sugli stessi dati con max_depth=3. Oltre ai parametri di pre-pruning, puoi anche provare altre misure di selezione degli attributi come entropy.
# Create Decision Tree classifer object
clf = DecisionTreeClassifier(criterion="entropy", max_depth=3)
# Train Decision Tree Classifer
clf = clf.fit(X_train,y_train)
#Predict the response for test dataset
y_pred = clf.predict(X_test)
# Model Accuracy, how often is the classifier correct?
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
Accuracy: 0.7705627705627706Il tasso di classificazione è salito al 77,05%, un'accuratezza migliore rispetto al modello precedente.
Rendiamo il nostro albero decisionale un po' più facile da capire usando il seguente codice:
from six import StringIO
from IPython.display import Image
from sklearn.tree import export_graphviz
import pydotplus
dot_data = StringIO()
export_graphviz(clf, out_file=dot_data,
filled=True,
rounded=True,
special_characters=True,
feature_names=feature_cols,
class_names=['0','1'])
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('diabetes.png')
Image(graph.create_png())Qui abbiamo completato i passaggi seguenti:
Importato le librerie necessarie.
Creato un oggetto StringIO chiamato dot_data per contenere la rappresentazione testuale dell'albero decisionale.
Esportato l'albero decisionale nel formato dot usando la funzione export_graphviz e scritto l'output nel buffer dot_data.
Creato un oggetto grafico pydotplus dalla rappresentazione in formato dot dell'albero decisionale memorizzata nel buffer dot_data.
Scritto il grafico generato in un file PNG chiamato "diabetes.png".
Visualizzata l'immagine PNG generata dell'albero decisionale utilizzando l'oggetto Image dal modulo IPython.display.
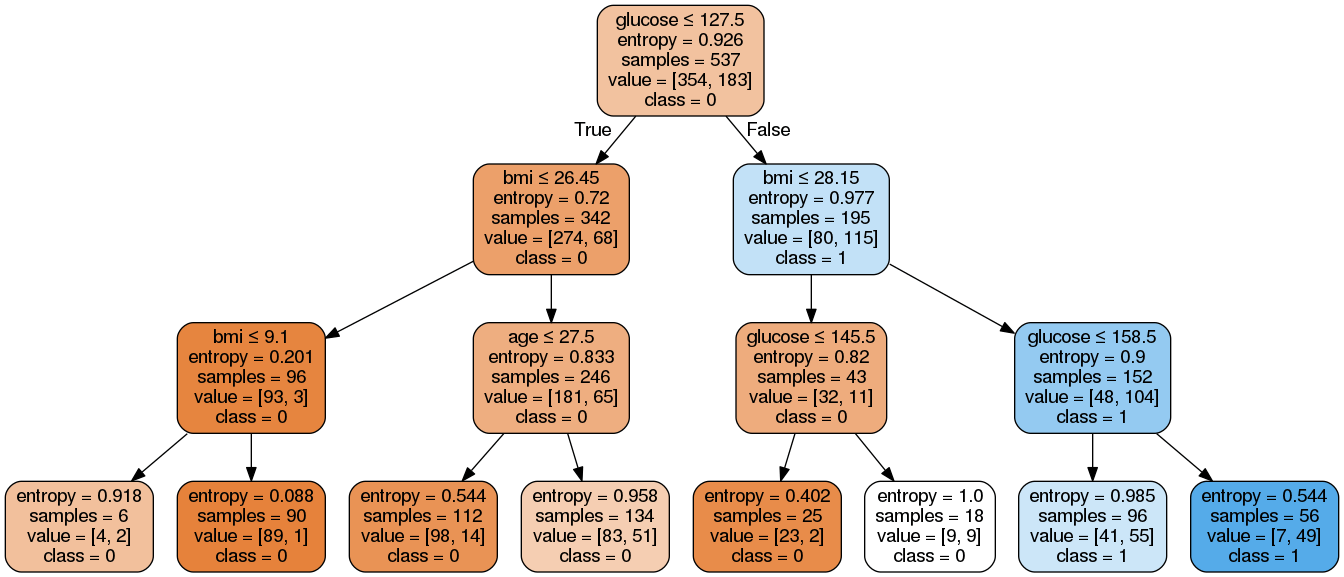
Come puoi vedere, questo modello potato è meno complesso, più spiegabile e più facile da comprendere rispetto al grafico del modello precedente.
Ora che hai costruito e ottimizzato un classificatore ad albero decisionale, prendiamoci un momento per valutarne in generale punti di forza e limiti. Capire i trade-off ti aiuta a decidere quando gli alberi decisionali sono la scelta giusta.
| Vantaggi | Svantaggi |
|---|---|
| Facili da interpretare e visualizzare | Sensibili al rumore nei dati e soggetti a overfitting |
| Captano facilmente pattern non lineari | Piccole variazioni nei dati possono produrre alberi molto diversi |
| Richiedono preprocessing minimo dei dati (niente normalizzazione delle colonne) | Bias con dataset sbilanciati (si consiglia di bilanciare) |
| Utili per feature engineering (predire valori mancanti, selezione di variabili) | |
| Nessuna assunzione sulla distribuzione dei dati (non parametrico) |
Nota che alcuni svantaggi, come l'instabilità della varianza, possono essere mitigati con metodi ensemble come bagging e boosting.
Anche se in questo tutorial abbiamo lavorato con alberi decisionali completi, vale la pena conoscere una variante più semplice chiamata decision stump. Un decision stump è essenzialmente un albero decisionale con profondità massima pari a uno—cioè ha un solo split al nodo radice e due nodi foglia.
| Aspetto | Decision Tree | Decision Stump |
|---|---|---|
| Profondità | Può avere qualsiasi profondità (controllata dal parametro max_depth) |
Sempre profondità 1 (un solo split) |
| Complessità | Può modellare relazioni complesse e non lineari | Modella solo confini decisionali semplici e lineari |
| Caso d'uso | Classificatore standalone per problemi complessi | Usato principalmente come weak learner nei metodi ensemble |
| Accuratezza | In genere più alta come modello standalone | Più bassa, ma efficace quando combinato |
| Interpretabilità | Diminuisce con la profondità (come visto con l'albero non potato) | Estremamente semplice e interpretabile |
I decision stump sono raramente utilizzati come classificatori standalone a causa della loro semplicità. Ma possono avere un ruolo nei metodi ensemble: in particolare AdaBoost utilizza i decision stump come weak learner combinati per creare un classificatore forte, oppure il gradient boosting perché gli stump possono essere usati come base learner nel processo di boosting.
Puoi creare un decision stump in Scikit-learn semplicemente impostando max_depth=1:
# Create a Decision Stump
stump = DecisionTreeClassifier(max_depth=1)
stump = stump.fit(X_train, y_train)Congratulazioni, sei arrivato alla fine di questo tutorial!
In questo tutorial hai visto molti dettagli sugli alberi decisionali: come funzionano, le misure di selezione degli attributi come Information Gain, Gain Ratio e Indice di Gini, la costruzione del modello ad albero decisionale, la visualizzazione e la valutazione di un dataset sul diabete usando il pacchetto Scikit-learn di Python. Abbiamo anche discusso pro, contro e come ottimizzare le prestazioni di un albero decisionale regolando i parametri.
Si spera che ora tu possa utilizzare l'algoritmo dell'albero decisionale per analizzare i tuoi dataset.
Se vuoi imparare di più sul Machine Learning in Python, segui il nostro corso Machine Learning con modelli ad albero in Python. Dai anche un'occhiata al nostro Tutorial Kaggle: Il tuo primo modello di Machine Learning.
Corsi Python
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

