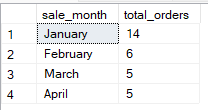

Kurs
PostgreSQL Summary Stats and Window Functions
4 sa
125.4K
Tek bir sütuna göre grupla(ma) yaygın olsa da, birden fazla sütuna göre gruplama, ortak değerlere sahip satırları bir araya getirerek büyük veri kümelerini özetlemenizi sağlar; bu da kalıpları, eğilimleri ve aykırı değerleri belirlemeyi kolaylaştırır.
Bu rehberde, GROUP BY ifadesinin nasıl çalıştığını, gelişmiş gruplama yöntemlerini ve en iyi uygulamaları açıklayacağım. SQL’e yeni başlıyorsanız, sağlam bir temel oluşturmak için Introduction to SQL veya Intermediate SQL kursumuzla başlamayı düşünebilirsiniz. Ayrıca indirilebilir SQL Basics Cheat Sheet belgesini, en yaygın SQL işlevlerinin tamamını içerdiği için yararlı bir referans olarak buluyorum.
SQL’de birden fazla sütuna göre nasıl gruplama yapıldığını açıklamadan önce, GROUP BY ifadesinin temel kavramlarını anlayalım.
SQL’de GROUP BY ifadesi, özdeş verileri gruplar halinde düzenler. Veritabanındaki satırları tarar ve belirtilen sütunlardaki aynı değerlere sahip satırları kümeler, böylece bu gruplar içinde veri toplulaştırmayı mümkün kılar.
GROUP BY ifadesini, her bir satır grubu için özet hesaplamaları yapmak amacıyla COUNT(), SUM(), AVG(), MIN() ve MAX() gibi toplu (aggregate) işlevlerle birlikte kullanabilirsiniz.
Diyelim ki satış verilerini analiz ediyor ve bölge başına toplam geliri bilmek istiyorsunuz. GROUP BY, satışları bölgeye göre gruplamanıza ve her biri için toplamı tek bir sorguda hesaplamanıza olanak tanır.
Veritabanı, tek sütunda GROUP BY ifadesini işlemden geçirirken satırlar arasında gezinir ve o sütundaki farklı değerlere göre segmentlere ayırır. Her farklı değer bir grup oluşturur ve toplu işlevler her grubun içinde sonuçları hesaplar.
Ancak birden fazla sütun eklediğinizde, SQL verileri bu sütunların her benzersiz birleşimine göre gruplar. Bu da veritabanının, tüm belirtilen sütun değerleriyle tanımlanan daha küçük ve daha rafine gruplara veriyi bölümlendirdiği anlamına gelir.
Bu bölümlendirme yaklaşımı çok boyutlu toplulaştırmaya olanak tanır. Bu, ayrıntılı iş zekâsı ve analitik için kullanışlıdır. Birden çok boyutun kesişiminde veriyi özetleyerek derinlemesine analiz sağlar. Örneğin, satışları bölge ve ürün kategorisine göre gruplayabilirsiniz.
Gördüğünüz gibi, veriyi birden fazla sütuna göre gruplamak daha fazla içgörü elde etmenizi sağlar. Şimdi SQL’in bu gruplamayı nasıl ele aldığına bakalım.
SQL’de birden fazla sütuna göre gruplama yaptığınızda, veritabanı motoru sütun kombinasyonunu bileşik anahtarlar olarak ele alır. Bu benzersiz kombinasyonların her biri ayrı bir grup oluşturur. Örneğin, satış verilerini region ve product_type ile gruplamak, ('West', 'Electronics'), ('East', 'Furniture') gibi her benzersiz ikili için ayrı bir grup üretir.
Bu durum, hiyerarşik bir alt gruplama düzenine yol açar: ilk sütun birincil grupları oluşturur, ikinci sütun bu birincil grupları alt gruplara böler ve böyle devam eder. Bu katmanlı gruplama, bilgiyi ayrıntılı kategorilere ayırarak veri ayrıntı düzeyini artırır.
Ayrıca hiyerarşik ve hiyerarşik olmayan gruplama arasında fark olduğunu da not etmelisiniz. Hiyerarşik gruplama, belirli bir sırayı izleyerek sütunların gruplama ve alt gruplamasını takip eder. Öte yandan, hiyerarşik olmayan gruplama her sütunu başka bir boyut olarak ele alır ve içkin bir hiyerarşiyi izlemez. Yine de, hiyerarşik olmayan gruplama analiz için faydalı kombinasyonlar oluşturur; örneğin ürün satışlarını mevsime göre gruplamak istediğinizde.
SQL’de, GROUP BY ifadesinde sütunları hangi sırayla listelediğiniz gerçekten önemlidir. Birden fazla sütuna göre grupladığınızda, SQL bu sütunları birlikte birleşik bir anahtar olarak ele alır; sanki her grubu benzersiz biçimde tanımlamak için birkaç parçayı bir araya getirmek gibidir.
SQL sütunları soldan sağa işler. Yani önce listede yer alan ilk sütuna göre gruplar, ardından her bir grubun içinde bir sonraki sütuna göre yeniden gruplar ve böyle devam eder. Bu sıra; özellikle büyük veri kümeleriyle çalışırken, veritabanının sorguyu ne kadar verimli işlediğini, indeksleri nasıl kullandığını ve ara gruplamaların nasıl oluşturulduğunu etkileyebilir.
Örneğin, verinizi bölge ve ürüne göre gruplamak istiyorsanız, veri önce bölgeye göre, sonra her bölge içinde ürüne göre gruplandırılır. Ancak sırayı (ürün, bölge) olarak değiştirirseniz, gruplama hiyerarşisini de değiştirmiş olursunuz; bu da raporlarınızda farklı sonuçlara ve yorumlara yol açabilir.
GROUP BY ifadesinin sözdizimini ve varyasyonlarını tam olarak anlamak için inceleyelim.
GROUP BY ifadesini birden fazla sütunda kullanmak için, her sütunu SELECT deyiminde virgüllerle ayırarak listelemelisiniz. Veritabanı daha sonra satırları bu sütun değerlerinin benzersiz kombinasyonlarına göre gruplar.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;SELECT deyiminde kullanılan ve toplu işlevlerin parçası olmayan tüm sütunların hatalardan kaçınmak ve okunabilir bir toplulaştırma sağlamak için mutlaka GROUP BY ifadesinde yer aldığından emin olun.
Diyelim ki aşağıdaki yapıya sahip bir Sales tablonuz var:
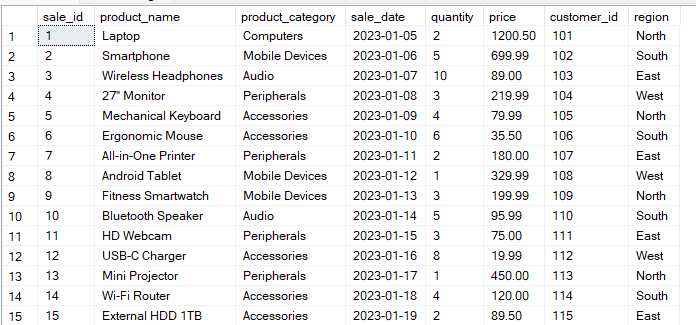
Aşağıdaki sorgu verileri region ve product_category sütunlarına göre gruplar. Ardından her grup kombinasyonu için total_sales değerini hesaplar.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;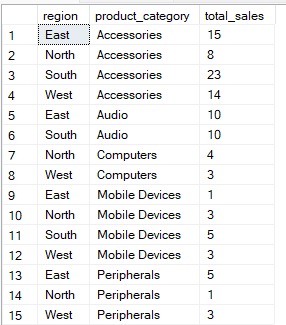
Aşağıda, SQL’de GROUP BY ifadesini birden fazla sütunda kullanmanın farklı yöntemleri yer alıyor:
SQL, sütun adları yerine GROUP BY ifadesinde sütunların konumunu belirtmenize de izin verir. Önceki örneğimizde 1 region sütununa, 2 ise product_category sütununa karşılık gelir. Bu yöntem MySQL ve PostgreSQL’de desteklenir, SQL Server’da desteklenmez.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Türetilmiş ifadeler veya hesaplanmış değerlere göre de gruplama yapabilirsiniz. Bu, örneğin bir tarihten yıl ya da alt dizeler gibi dönüştürülmüş veriye göre gruplamak için kullanışlıdır. Aşağıdaki sorgu, satışları sale_date’ten türetilen aya göre gruplar.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Birden çok sütun seçip yalnızca birine göre gruplama
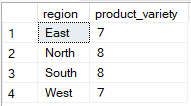
SQL, yalnızca bir sütuna göre gruplarken birden fazla sütun seçmenize izin verir; ancak ek sütunlar yalnızca toplu işlevlerin içinde kullanılıyorsa. Aşağıdaki örnekte, yalnızca region GROUP BY ifadesindedir, product_id ise bir toplu işlevde (COUNT(DISTINCT)) kullanıldığından sorgu geçerlidir.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
PostgreSQL’de veriyi nasıl işleyebileceğinizi anlamak için Analyzing and Formatting PostgreSQL Sales Data projemizi denemenizi öneririm. Ayrıca, MySQL Basics Cheat Sheet özellikle MySQL kullanmayı tercih ediyorsanız; temel sorgulama, veri filtreleme ve toplulaştırma için kullanışlı bir başvuru kılavuzu olacaktır.
SQL’de GROUP BY ifadesinin avantajı, gruplanmış verilerin özetini almak için toplu işlevlerle birlikte kullanılabilmesidir.
Birden fazla sütuna göre gruplarken toplu işlevler çeşitli veri kombinasyonları arasında çok boyutlu içgörüler sağlar. GROUP BY ile en yaygın kullanılan işlevler şunlardır:
SUM(): Her grup için sayısal bir sütundaki tüm değerleri toplar.
COUNT(): Her gruptaki satırların veya boş olmayan değerlerin sayısını verir.
AVG(): Her grup içindeki ortalama değeri hesaplar.
MIN(): Her gruptaki en küçük değeri bulur.
MAX(): Her gruptaki en büyük değeri bulur.
Örneğin, aşağıdaki sorgu her bölge ve ürün kategorisi kombinasyonu için toplam satışları ve satış kayıtlarının sayısını hesaplar
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;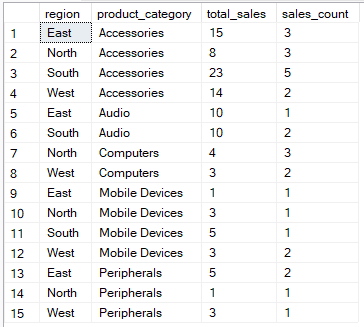
Yukarıdaki örneklerde GROUP BY ifadesinin toplu işlevlerle kullanıldığını gördünüz. Ancak, özetsiz olarak belirtilen sütunlara göre satırları gruplamak istediğinizde toplulaştırma yapmadan da kullanabilirsiniz.
Örneğin, aşağıdaki sorgu toplulaştırma olmadan bölge ve ürün kategorisinin benzersiz ikililerini döndürür. Bu yöntemi veri tutarlılığını kontrol etmek için kullanabilirsiniz.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;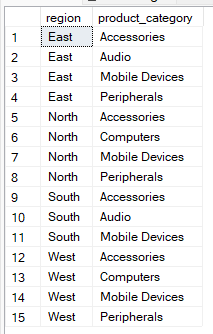
Artık birden fazla sütuna göre nasıl gruplama yapabileceğimizi gördüğümüze göre, GROUP BY ifadesiyle kullanılan farklı gelişmiş gruplama işlemlerine bakalım.
ROLLUP işlemi, belirtilen sütunlar boyunca yukarı doğru (roll up) özet düzeyleri oluşturarak standart GROUP BY ifadesini genişletir. Ayrıntılı grupları göstermenin yanı sıra, grupladığınız sütunlar üzerinden sağdan sola adım adım toplayarak ara toplamlar ve genel toplam da ekler.
Örneğin, aşağıdaki sorguda region ve product_category kombinasyonlarının her biri için total_quantity elde edersiniz. Sonuçlarda her bölge için ara toplamlar (product_category’nin NULL göründüğü yerler) ve tüm bölgeler ve kategoriler genelinde toplanan bir genel toplam bulunur.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);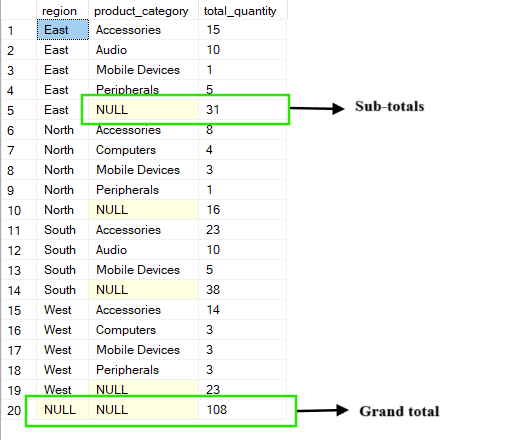
CUBE işlemi, gruplama sütunlarının tüm olası kombinasyonlarını üretir. Bir hiyerarşi oluşturan ROLLUP’ın aksine, CUBE tüm toplulaştırma kombinasyonlarından oluşan eksiksiz bir veri küpü üretir.
Belirtilen sütunların her alt kümesi için çapraz tablo şeklinde toplulaştırmalar sağlar. CUBE işleminin çıktısı, her sütun için özetleri, sütunların her kombinasyonunu ve genel toplamı içerir.
Örneğin, yukarıdaki tabloyu sorgulayıp (region, product_category) sütunlarına göre gruplarsak, CUBE işlemi şu kombinasyonları üretir:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL) genel toplamı ifade eder
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);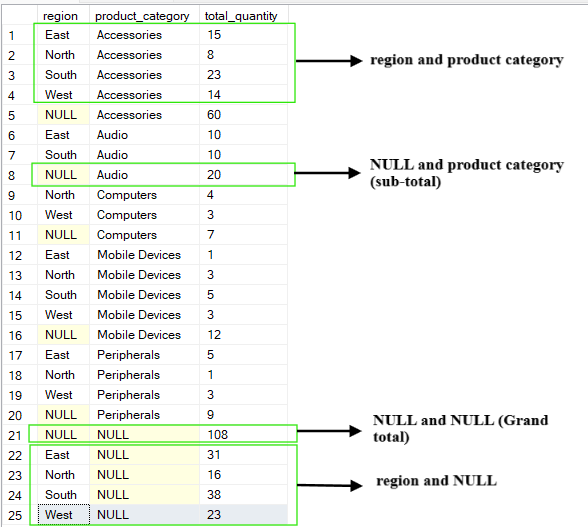
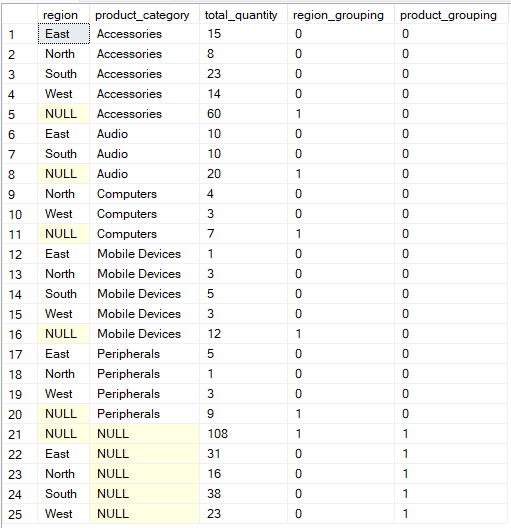
Verinizin nasıl gruplandığı üzerinde daha esnek bir kontrol istiyorsanız, GROUPING SETS işlemi tek bir sorguda birden fazla gruplamayı açıkça tanımlamanıza olanak tanır.
Bu durumda GROUPING() işlevi, sonuçtaki her satırda hangi sütunların toplulaştırıldığını belirten meta veriler sağlar; böylece gerçek eksik veri yerine alt toplam veya genel toplamı temsil eden NULL’ları ayırt eder.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Birden fazla sütuna göre gruplama yapan sorgular yazarken, bunları daha verimli ve genel veritabanı performansı açısından optimize etmek önemlidir. Aşağıda, sorgu optimizasyonu ve kaynak yönetimine yardımcı olmak için kullandığım bazı pratik ipuçları yer alıyor
Sorgularınızın sorunsuz çalışması ve minimum kaynak kullanması için:
Performans darboğazlarını belirleyin: Büyük veri kümeleriyle çalışırken GROUP BY sorguları; çok sayıda veriyi tarama, sıralama ve toplulaştırma nedeniyle yavaşlayabilir. Bunu önlemek için, her zaman WHERE ifadesiyle erken filtreleme yapın ve ihtiyaç duymadığınız verileri çekmekten kaçının.
İndekslemeyi etkin kullanın: Sütunları indekslemek GROUP BY performansını hızlandırır. GROUP BY ifadesinde kullanılan sütunlar üzerinde bileşik indeksler oluşturmak, veritabanı motorunun pahalı tam tablo taramaları veya sıralamalar olmadan satırları hızlıca bulup gruplamasına yardımcı olur.
Sütunları sınırlayın: Yalnızca gruplama ve analiz için gerekli sütunları ekleyin; bu, karmaşıklığı azaltır ve performansı artırır.
Sorgu planlarından yararlanın: Uygun olduğunda yürütme planlarını kontrol edin veya veritabanı iyileştiricisini en iyi stratejilere yönlendirmek için sorgu ipuçları (hints) kullanın.
Bellek, GROUP BY sorgularının ne kadar iyi performans gösterdiğinde büyük rol oynar. Veriyi sıralamak ve gruplamak çoğu zaman ara verilerin bellekte tutulmasını gerektirir. Yeterli bellek yoksa, işler ciddi şekilde yavaşlar.
Kaynakları daha iyi yönetmek için:
Ayrıca, veri boyutunun performans üzerinde büyük etkisi olduğunu unutmayın. Çok sayıda benzersiz grup kombinasyonuna sahip büyük veri kümeleri daha fazla bellek ve işlem gücü kullanır. Büyük tabloları bölümlemek (partitioning), özet tabloları önceden oluşturmak veya maddi görünümler (materialized view) kullanmak gibi teknikler işleri yönetilebilir kılar.
GROUP BY ifadesi diğer SQL ifadeleriyle iyi çalışır; sorgularınızı daha güçlü ve esnek hale getirir. Sırada, analizinizi geliştirmek için GROUP BY’ı farklı SQL ifadeleriyle nasıl birleştirebileceğinize dair pratik örnekler var.
WHERE ifadesi, gruplama gerçekleşmeden önce satırları filtreler. Böylece yalnızca gerekli satırlar toplulaştırma sürecine dahil edilir. Örneğin, aşağıdaki sorgu region and product_category` ile gruplar, ancak bölgenin ‘North’ olduğu kayıtları içerir.
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;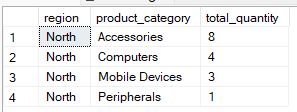
Öte yandan HAVING ifadesi, toplulaştırmadan sonra filtreler. Sonuçta hangi grupların görüneceğini toplu değerlere göre sınırlandırmak için kullanılır. Aşağıdaki sorgu region and product_category ile gruplar, ancak total_quantity` değeri 5’ten büyük olan kayıtları içerir.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;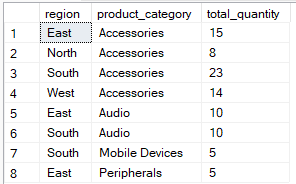
SQL’in çalışma sıralamasında, ORDER BY ifadesi GROUP BY ifadesinden sonra gelir ve gruplanmış sonuçları sıralamak için kullanılır; bu da okunabilirliği artırır veya sonraki işlemleri kolaylaştırır. Doğru indeksleri kullanarak ve ORDER BY ifadesindeki sütun sırasını dikkatle seçerek, veriyi sıralamak için gereken işi azaltıp sorgunuzu hızlandırabilirsiniz.
Örneğin, bu sorgu verileri region ve product_category’ye göre gruplar, ardından sonuçları en yüksek total_quantity değerine sahip gruplar en üstte görünecek şekilde sıralar.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;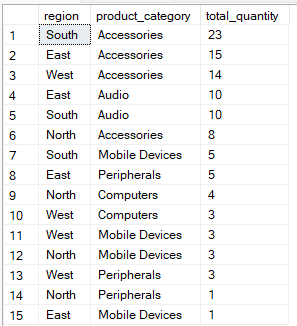
Ayrıca, GROUP BY ifadesiyle JOIN işlemlerini birleştirerek birden fazla ilişkili tablo genelinde gruplama yapabilirsiniz. Bu yöntemi kullanırken dikkatli olmalısınız; çünkü daha büyük boyutlu verileri birleştirmek karmaşıklık getirebilir.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Farklı join türlerini ve bunları iç içe sorgularda nasıl kullanacağınızı öğrenmek için Joining Data in SQL kursumuzu almanızı öneririm. SQL’de veri birleştirme hakkında daha fazla bilgi edinmek için referans olarak SQL Joins Cheat Sheet kılavuzumuzu indirebilirsiniz.
GROUP BY içinde CASE ifadesi, gruplama süreci sırasında sütun değerlerini dinamik olarak dönüştürerek özel gruplamalar yapmanıza olanak tanır.
Aşağıdaki sorgu, ürünleri fiyat aralığına göre kategorize eder ve bölge ile ürün kategorisi başına satılan toplam miktarı sayar.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;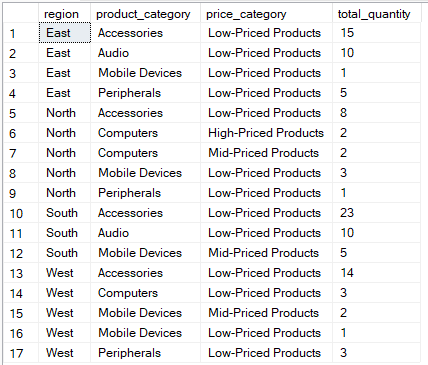
Birden fazla sütunu gruplamak için GROUP BY ifadesini kullanmaya devam ettikçe, kullanımınızı geliştirecek yinelenen kalıpları fark edeceksiniz. Bu yaygın durumları performans hususlarıyla birlikte ele alacağız.
Çoğu veri kümesinin kıta → ülke → şehir gibi coğrafya, ürün kategorileri veya organizasyon yapıları gibi doğal hiyerarşilere sahip olduğunu fark etmiş olabilirsiniz. Bu nedenle, GROUP BY ifadesi bu hiyerarşilerin farklı düzeylerinde verileri özetlemek için idealdir.
Verileriniz tarih ve zaman damgaları içerdiğinde, yıl, çeyrek, ay veya gün gibi tarih parçalarına göre gruplama yaparak eğilimleri, mevsimselliği ve zamana bağlı davranışları belirlemeye yardımcı olacak zamansal analiz yapabilirsiniz.
Daha önce iki tür gruplama kalıbından bahsetmiştik. Hiyerarşik gruplamalar, departmana göre grupladıktan sonra her departman içinde takıma göre gruplamak gibi doğal, iç içe geçmiş bir ilişkiye sahip sütunları içerir. Buna karşılık, hiyerarşik olmayan gruplamalar ürün türü ve ödeme yöntemi gibi ilgisiz boyutları karıştırır ve herhangi bir sıraya veya yapıya işaret etmeden kombinasyonları gösterir.
GROUP BY’ı birden fazla sütunla kullanırken, şu pratik ipuçlarıyla performansı artırabilirsiniz:
Gruplama sütunlarını sınırlayın: Analiz için gerekli sütunlara göre gruplama yaptığınızdan emin olun; bu, grupların hesaplama yükünü azaltır.
İndeks optimizasyonu: Gruplama yapılan sütunların indeksli olduğundan emin olun; bu, veritabanının sıralama işlemlerini daha verimli şekilde gerçekleştirmesine yardımcı olarak sorgu performansını hızlandırır.
Erken filtreleyin: WHERE ifadesini kullanarak, gruplamadan önce veri kümenizi sınırlayın; böylece işlenecek veri miktarını azaltın.
Sorgu planları ve ipuçlarını kullanın: Veritabanınız destekliyorsa yürütme planlarını inceleyin veya gruplama sürecini optimize etmeye yardımcı olmak için sorgu ipuçları ekleyin.
Gelişmiş SQL özelliklerinden yararlanın: ROLLUP veya GROUPING SETS gibi teknikleri kullanmayı düşünün; özellikle hiyerarşik ya da çok boyutlu verilerle çalışırken, özetleri daha verimli oluşturur ve tekrarlı sorgular çalıştırmaktan kaçınır.
GROUP BY, belirli alanlara göre yinelenenleri kaldırarak verinizi temizlemenin kullanışlı bir yolu da olabilir. Bu, veri kümeniz birden çok özdeş ya da kısmen yinelenen satır içerdiğinde faydalıdır.
Örneğin, yinelenen satış kayıtlarını kaldırmak için region, product_category ve product_name ile gruplar, ardından her grup için en yüksek fiyatı seçerek en ilgili kaydı korursunuz.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Birden fazla sütunda GROUP BY ile çalışırken, şu yaygın tuzakları aklınızda bulundurun:
GROUP BY sorgularındaki en sık hatalardan biri, yanlış sütun belirtiminden kaynaklanır. SQL, when selecting multiple columns not wrapped in an aggregate function, they must be included in the GROUP BY clause. Failing to do so results in an error. So, always include the non-aggregated columns in the GROUP BY clause if included in the SELECT statement.
Ayrıca, özellikle ifadelere göre gruplama yaparken, grupladığınız verilerde uyumsuzluklar varsa hatalarla karşılaşabilirsiniz. Diyelim ki verilerinizi biçimlendirilmiş bir tarihe göre grupluyorsunuz. Bu durumda, tarih değerlerinin farklı biçimlere veya duyarlılık düzeylerine sahip olması beklenmedik ya da yanlış sonuçlara yol açacağından hata alırsınız.
GROUP BY sorgularını kullanmak bazen veritabanınızı yavaşlatabilir; özellikle de çok sayıda benzersiz değere (yüksek kardinalite) sahip sütunlara göre grupluyorsanız veya bu sütunlar indeksli değilse. Büyük veri kümeleri ayrıca sıralama ve gruplama adımlarını karşılamak için yeterli belleğe ihtiyaç duyar; bu da yükü artırır.
Bu sorunlardan kaçınmak için, her zaman sütunları indeksleyin ve sorguladığınız veriyi sınırlamak için WHERE ile filtreleyin.
Ayrıca, SQL’in gruplamada NULL değerleri nasıl ele aldığını bilmek önemlidir: bir gruplama sütunundaki tüm NULL’lar, kaç tane olursa olsun, aynı grup olarak değerlendirilir. Ancak NULL hiçbir zaman gerçek (NULL olmayan) bir değere eşit kabul edilmez; dolayısıyla bu gruplar ayrı kalır.
GROUP BY ifadesini kullanarak SQL’de birden fazla sütunu gruplamak; alan kombinasyonları genelinde veriyi toplulaştırarak daha derin, çok boyutlu analiz yapmayı sağlayan güçlü bir tekniktir. Analistlerin temel özetlerin ötesine geçerek veri içindeki kalıplar ve ilişkiler hakkında daha fazla içgörü elde etmesine olanak tanır. Bu yetenek, modern iş ortamlarında raporlama, performans takibi ve karar alma için önemlidir..
Veri karmaşıklık ve hacim olarak büyüdükçe, SQL analitiklerde temel bir araç olmaya devam ediyor. Becerilerinizi daha da geliştirmek için, daha gelişmiş veri dönüşümleri ve raporlama iş akışlarının kapısını açan pencere işlevlerini (window functions), ortak tablo ifadelerini (CTE) ve maddi görünümleri keşfetmeyi düşünün.
Profesyonel düzeyde Pencere işlevleri kullanarak iş analitiği için sorgular yazmayı öğrenmek üzere PostgreSQL Summary Stats and Window Functions kursumuzu almanızı öneririm. Ayrıca, SQL becerilerinizi sınamak ve SQL’i iş problemlerini çözmek için kullanmadaki ustalığınızı göstermek üzere Analyzing Industry Carbon Emissions ve Analyzing Motorcycle Part Sales projelerimizi denemenizi tavsiye ederim.
DataCamp ile SQL öğrenin
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
