
Course
Intermediate R
6 hr
670.5K
The concept of regular expressions, usually referred to as regex, exists in many programming languages, such as R, Python, C, C++, Perl, Java, and JavaScript. You can access the functionality of regex either in the base version of those languages or via libraries. For most programming languages, the syntax of regex patterns is similar.
In this tutorial, we'll explore what regular expressions in R are, why they're important, what tools and functions allow us to work with them, which regex patterns are the most common ones, and how to use them. In the end, we'll overview some advanced applications of R regex.
A regular expression, regex, in R is a sequence of characters (or even one character) that describes a certain pattern found in a text. Regex patterns can be as short as ‘a’ or as long as the one mentioned in this StackOverflow thread.
Broadly speaking, the above definition of the regex is related not only to R but also to any other programming language supporting regular expressions.
Regex represents a very flexible and powerful tool widely used for processing and mining unstructured text data. For example, they find their application in search engines, lexical analysis, spam filtering, and text editors.
While regex patterns are similar for the majority of programming languages, the functions for working with them are different.
In R, we can use the functions of the base R to detect, match, locate, extract, and replace regex. Below are the main functions that search for regex matches in a character vector and then do the following:
grep(), grepl() – return the indices of strings containing a match (grep()) or a logical vector showing which strings contain a match (grepl()).
regexpr(), gregexpr() – return the index for each string where the match begins and the length of that match. While regexpr() provides this information only for the first match (from the left), gregexpr() does the same for all the matches.
sub(), gsub() – replace a detected match in each string with a specified string (sub() – only for the first match, gsub() – for all the matches).
regexec() – works like regexpr() but returns the same information also for a specified sub-expression inside the match.
regmatches() – works like regexec() but returns the exact strings detected for the overall match and a specified sub-expression.
However, instead of using the native R functions, a more convenient and consistent way to work with R regex is to use a specialized stringr package of the tidyverse collection. This library is built on top of the stringi package. In the stringr library, all the functions start with str_ and have much more intuitive names (as well as the names of their optional parameters) than those of the base R.
To install and load the stringr package, run the following:
install.packages('stringr')
library(stringr)The table below shows the correspondence between the stringr functions and those of the base R that we've discussed earlier in this section:
|
stringr |
Base R |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
You can find a full list of the stringr functions and regular expressions in these cheat sheets, but we'll discuss some of them further in this tutorial.
Note: in the stringr functions, we pass in first the data and then a regex, while in the base R functions – just the opposite.
Another note: This tutorial uses stringr 1.5.1, the current version as of 2026. If you're using an older version, some behavior may differ — particularly around str_view(), which was significantly updated in 1.5.0.
Now, we're going to overview the most popular R regex patterns and their usage and, at the same time, practice some of the stringr functions.
Before doing so, let's take a look at a very basic example. Namely, let's check if a unicorn has at least one corn 😉
str_detect('unicorn', 'corn')Output:
TRUEIn this example, we used the str_detect() stringr function to check the presence of the string corn in the string unicorn.
However, usually, we aren't looking for a certain literal string in a piece of text but rather for a certain pattern – a regular expression. Let's dive in and explore such patterns.
There are a few characters that have a special meaning when used in R regular expressions. More precisely, they don't match themselves, as all letters and digits do, but they do something different:
str_extract_all('unicorn', '.')Output:
1. 'u' 'n' 'i' 'c' 'o' 'r' 'n'We clearly see that there are no dots in our unicorn. However, the str_extract_all() function extracted every single character from this string. This is the exact mission of the . character – to match any single character except for a new line.
What if we want to extract a literal dot? For this purpose, we have to use a regex escape character before the dot – a backslash (\). However, there is a pitfall here to keep in mind: a backslash is also used in the strings themselves as an escape character. This means that we first need to "escape the escape character," by using a double backslash. Let's see how it works:
str_extract_all('Eat. Pray. Love.', '\\.')Output:
1. '.' '.' '.'Hence, the backslash helps neglect a special meaning of some symbols in R regular expressions and interpret them literally. It also has the opposite mission: to give a special meaning to some characters that otherwise would be interpreted literally. Below is a table of the most used character escape sequences:
|
R regex |
What matches |
|
|
A word boundary (a boundary between a |
|
|
A non-word boundary ( |
|
|
A new line |
|
|
A tab |
|
|
A vertical tab |
Let's take a look at some examples keeping in mind that also in such cases, we have to use a double backslash. At the same time, we'll introduce another stringr function: str_view() to view HTML rendering of the first match or all matches:
str_view('Unicorns are so cute!', 's\\b')
str_view('Unicorns are so cute!', 's\\B')Output:
Unicorns are so cute!
Unicorns are so cute!In the string Unicorns are so cute!, there are two instances of the letter s. Above, the first R regex pattern highlighted the first instance of the letter s (since it's followed by a space), while the second one – the second instance (since it's followed by another letter, not a word boundary).
A couple more examples:
cat('Unicorns are\nso cute!')
str_view('Unicorns are\nso cute!', '\\n')Output:
Unicorns are
so cute!Unicorns are_so cute!
cat('Unicorns are\tso cute!')
str_view('Unicorns are\tso cute!', '\\t')Output:
Unicorns are so cute!Unicorns are_so cute!
A character class matches any character of a predefined set of characters. Built-in character classes have the same syntax as the character escape sequences we saw in the previous section: a backslash followed by a letter to which it gives a special meaning rather than its literal one. The most popular of these constructions are given below:
|
R regex |
What matches |
|
|
Any word character (any letter, digit, or underscore) |
|
|
Any non-word character |
|
|
Any digit |
|
|
Any non-digit |
|
|
Any space character (a space, a tab, a new line, etc.) |
|
|
Any non-space character |
Let's take a look at some self-explanatory examples:
str_view('Unicorns are so cute!', '\\w')
str_view('Unicorns are so cute!', '\\W')Output:
[1] │ <U><n><i><c><o><r><n><s>< ><a><r><e>< ><s><o>< ><c><u><t><e>!
[1] │ Unicorns< >are< >so< >cute<!>str_view('Unicorns are\nso cute!', '\\s')
str_view('Unicorns are\nso cute!', '\\S')Output:
Unicorns are<\n>so cute!
str_detect('Unicorns are so cute!', '\\d')Output:
FALSEBuilt-in character classes can also appear in an alternative form – [:character_class_name:]. Some of these character classes have an equivalent among those with a backslash; others don't. The most common ones are:
|
R regex |
What matches |
|
|
Any letter |
|
|
Any lowercase letter |
|
|
Any uppercase letter |
|
|
Any digit (equivalent to |
|
|
Any letter or number |
|
|
Any hexadecimal digit |
|
|
Any punctuation character |
|
|
Any letter, number, or punctuation character |
|
|
A space, a tab, a new line, etc. (equivalent to |
Let's explore some examples keeping in mind that we have to put any of the above R regex patterns inside square brackets:
str_view('Unicorns are so cute!', '[[:upper:]]')
str_view('Unicorns are so cute!', '[[:lower:]]')Output:
Unicorns are so cute!
Unicorns are so cute!
str_detect('Unicorns are so cute!', '[[:digit:]]')Output:
FALSEstr_extract_all('Unicorns are so cute!', '[[:punct:]]')Output:
1. '!'str_view('Unicorns are so cute!', '[[:space:]]')Output:
Unicorns_are_so_cute!
It's also possible to create a user-defined character class putting inside square brackets any set of characters from which we want to match any one character. We can enclose in square brackets a range of letters or numbers (in Unicode order), several different ranges, or any sequential or nonsequential set of characters or groups of characters.
For example, [A-D] will match any uppercase letter from A to D inclusive, [k-r] – any lowercase letter from k to r inclusive,[0-7] – any digit from 0 to 7 inclusive, and [aou14%9] – any of the characters given inside square brackets. If we put the caret (^) as the first character inside square brackets, our R regex pattern will match anything but the provided characters. Note that the above matching mechanisms are case-sensitive.
str_view('Unicorns Are SOOO Cute!', '[O-V]')
str_view('Unicorns Are SOOO Cute!', '[^O-V]')Output:
Unicorns Are SOOO Cute!
Unicorns Are SOOO Cute!
str_view('3.14159265359', '[0-2]')Output:
3.14159265359
str_view('The number pi is equal to 3.14159265359', '[n2e9&]')Output:
The number pi is equal to 3.14159265359
Often, we need to match a certain R regex pattern repetitively, instead of strictly once. For this purpose, we use quantifiers. A quantifier always goes after the regex pattern to which it's related. The most common quantifiers are given in the table below:
|
R regex |
Number of pattern repetitions |
|
|
0 or more |
|
|
at least 1 |
|
|
at most 1 |
|
|
exactly n |
|
|
at least n |
|
|
at least n and at most m |
Let's try all of them:
str_extract('dog', 'dog\\d*')Output:
'dog'We got the initial string dog: there are no digits at the end of that string, but we're ok with it (0 or more instances of digits).
str_extract('12345', '\\d+')Output:
'12345'str_extract('12345', '\\d?')Output:
'1'str_extract('12345', '\\d{3}')Output:
'123'str_extract('12345', '\\d{7,}')Output:
NAWe got NA because we don't have at least 7 digits in the string, only 5 of them.
str_extract('12345', '\\d{2,4}')Output:
'1234'By default, R regex will match any part of a provided string. We can change this behavior by specifying a certain position of an R regex pattern inside the string. Most often, we may want to impose the match from the start or end of the string. For this purpose, we use the two main anchors in R regular expressions:
^ – matches from the beginning of the string (for multiline strings – the beginning of each line)
$ – matches from the end of the string (for multiline strings – the end of each line)
Let's see how they work on the example of a palindrome stella won no wallets:
str_view('stella won no wallets', '^s')
str_view('stella won no wallets', 's$')Output:
<s>tella won no wallets
stella won no wallet<s>If we want to match the characters ^ or $ themselves, we need to precede the character of interest with a backslash (doubling it):
str_view('Do not have 100$, have 100 friends', '\\$')Output:
Do not have 100$, have 100 friendsIt's also possible to anchor matches to word or non-word boundaries inside the string (\b and \B respectively):
str_view('road cocoa oasis oak boa coach', '\\boa')
str_view('road cocoa oasis oak boa coach', 'oa\\b')
str_view('road cocoa oasis oak boa coach', 'oa\\B')Output:
road cocoa oasis oak boa coach
road cocoa oasis oak boa coach
road cocoa oasis oak boa coach
Above, we matched the combination of letters oa:
Applying the alternation operator (|), we can match more than one R regex pattern in the same string. Note that if we use this operator as a part of a user-defined character class, it's interpreted literally, hence doesn't perform any alternation.
str_view('coach koala board oak cocoa road boa load coat oasis boat', 'boa|coa')Output:
coach koala board oak cocoa road boa load coat oasis boat
In the above example, we matched all the instances of either boa or coa.
R regex patterns follow certain precedence rules. For example, repetition (using quantifiers) is prioritized over anchoring, while anchoring takes precedence over alternation. To override these rules and increase the precedence of a certain operation, we should use grouping. This can be performed by enclosing a subexpression of interest into round brackets.
Grouping works best in combination with the alternation operator. The examples below clearly demonstrate the effect of such a combination:
str_view('code rat coat cot cat', 'co|at')
str_view('code rat coat cot cat', 'c(o|a)t')Output:
code rat coat cot cat
code rat coat cot cat
Everything we've discussed so far gives us a good basis for starting working with R regular expressions. However, there are many more things we can do with this powerful tool. Without getting into detail, let's just mention some advanced operations that we can perform with R regex:
Lear more in our course Intermediate Regular Expressions in R.
Now it's your turn to practice the R regex patterns we've discussed in this tutorial. To do so, use our Dataset: Internet News and Consumer Engagement, and try to do the following: extract the top-level domains (TLDs) from all the URLs. Some examples of TLDs are com, net, uk, etc.
There is more than one approach to complete this task, including elegant and compact one-line solutions (hint: you can learn more about lookarounds in R regex mentioned in the previous section and use them to solve this problem). Consider the following very loose guidance for a relatively "rookie" approach:
To solve the problem using the above algorithm, you don't need to do or learn anything additional. Just refresh everything that we've discussed in this tutorial and put your knowledge into practice. In particular, you'll need the stringr functions, character escapes, character classes, quantifiers, and grouping.
If you want more practice, this time without any hints, try to do the following: using the same dataset from the previous challenge, extract the domain names from all the URLs. An example of a domain name is google in the URL www.google.com.
To conclude, in this tutorial, we learned plenty of things about R regular expressions. In particular, we discussed:
These skills and notions will help you working in R and in many other programming languages since the concept of regular expressions is the same for all those languages and also the syntax of the regex is rather similar for the majority of them.
If you're interested in mastering your R skills, consider exploring the following courses, skill tracks, and articles of DataCamp:
IBM Certified Data Scientist (2020), previously Petroleum Geologist/Geomodeler of oil and gas fields worldwide with 12+ years of international work experience. Proficient in Python, R, and SQL. Areas of expertise: data cleaning, data manipulation, data visualization, data analysis, data modeling, statistics, storytelling, machine learning. Extensive experience in managing data science communities and writing/reviewing articles and tutorials on data science and career topics.
Run this in your R console:
packageVersion('stringr')
If it shows anything below 1.5.0, update with:
install.packages('stringr')
It still works in the current version of stringr and will continue to for a while — deprecation in R doesn't mean immediate removal. However, every call will produce a warning message, which gets noisy fast. More importantly, deprecated functions do eventually get removed in future major releases, so any code relying on str_view_all() will eventually break. It takes about 30 seconds to fix, so it's worth doing now rather than later.
A: Because R processes the string before passing it to the regex engine. A single \ gets consumed by R's string parser, so you need \\ to ensure a single \ actually reaches the regex engine. Write \\d and R converts it to \d for the regex — write \d and it breaks before the regex ever sees it.
grep() returns the indices of matching elements; grepl() returns a TRUE/FALSE vector the same length as your input. Use grep() when you need positions, grepl() when you want to filter or test. In practice, the stringr equivalents str_subset() and str_detect() are cleaner for most use cases.
For single characters, always use a character class — it's faster and cleaner. Use alternation with | when any of your options have more than one character, like cat|dog, since those can't go inside [].
* = zero or more (pattern is optional and can repeat). + = one or more (at least one required). ? = zero or one (optional, won't repeat). Memory trick: + adds (requires at least one), ? asks (maybe it's there, maybe not), * means anything goes.
sub() replaces only the first match; gsub() replaces all matches. Their stringr equivalents are str_replace() and str_replace_all(). The stringr versions are preferred since they follow tidyverse argument order — data first, pattern second, replacement third.
regexpr() finds the position of the first match in each string; gregexpr() finds all matches. Most R users prefer stringr's str_locate() and str_locate_all() instead — they return results as clean data frames with start and end columns rather than base R's awkward named integer format.
Outside [], it anchors to the start of a string: ^Hello matches strings beginning with "Hello". Inside [] as the first character, it negates the set: [^aeiou] matches anything that isn't a vowel. Anywhere else inside [], it's treated as a literal caret.
Use \b when you want to match a whole word anywhere in a string, not just at the start or end. Searching for cat matches "concatenated" too — \bcat\b matches only the standalone word. It's especially useful in text analysis when partial matches would skew your results.
Top R Courses
Course
Course
Course
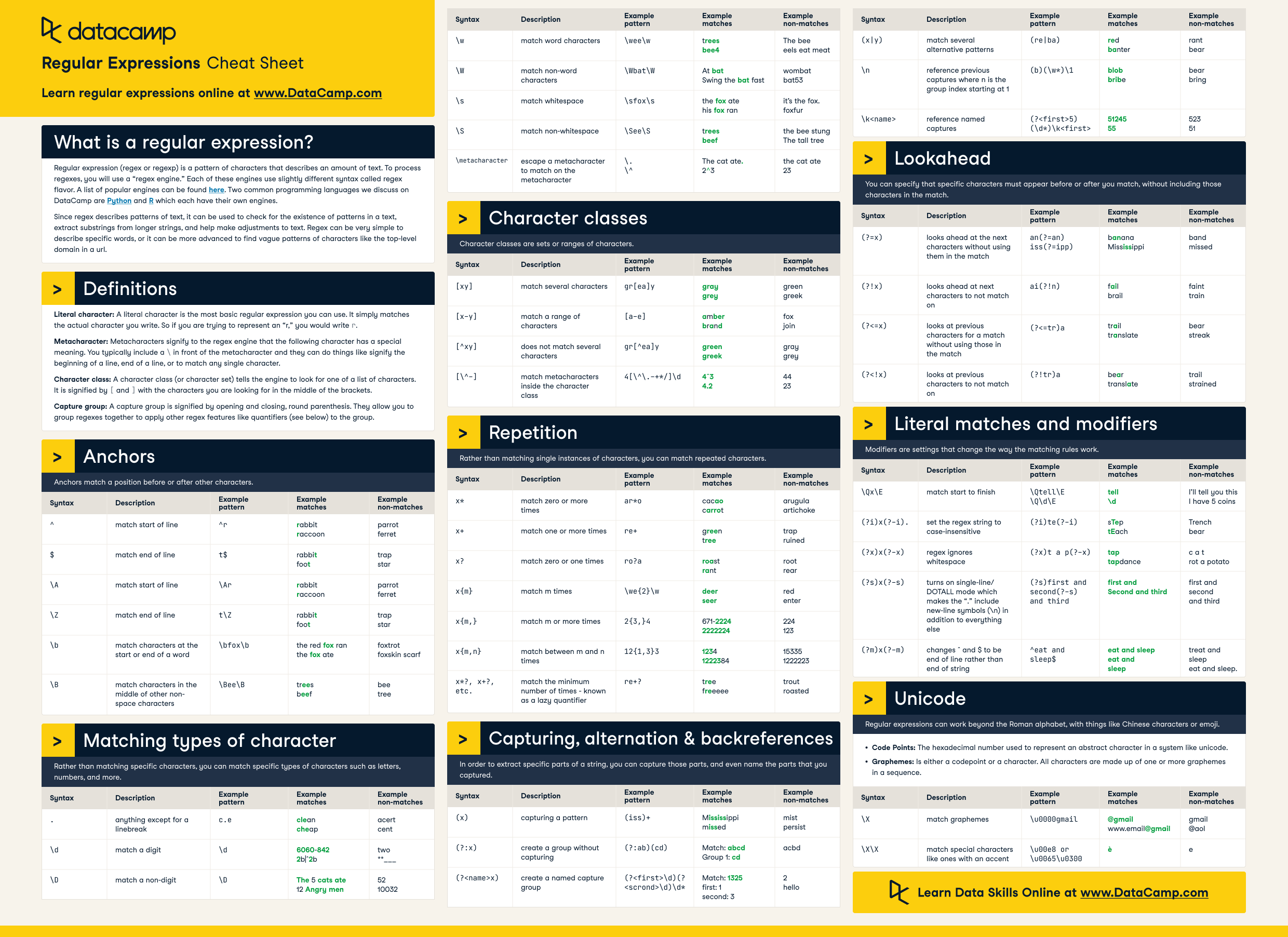
cheat-sheet
Richie Cotton
Tutorial
Aditya Sharma
Tutorial
Sejal Jaiswal

Tutorial
Chloe Lubin
Tutorial
Karlijn Willems
Tutorial
Olivia Smith