Association Rule Mining ist eine Technik, die verwendet wird, um versteckte Beziehungen zwischen Variablen in großen Datensätzen aufzudecken. Sie ist eine beliebte Methode des Data Mining und des maschinellen Lernens und findet in vielen Bereichen Anwendung, z. B. bei der Warenkorbanalyse, der Kundensegmentierung und der Betrugserkennung.
In diesem Artikel werden wir uns mit dem Assoziationsregel-Mining in Python beschäftigen, einschließlich der Anwendungsfälle, Algorithmen und der Implementierung. Wir beginnen mit einem kurzen Überblick über das Assoziationsregel-Mining und seine Anwendungen und beschäftigen uns dann mit den Details der Algorithmen und ihrer Implementierung in Python. Zum Schluss fassen wir die wichtigsten Punkte aus diesem Artikel zusammen.
Was ist Association Rule Mining?
Association Rule Mining ist eine Technik, die verwendet wird, um Muster in großen Datensätzen zu erkennen. Es geht darum, Beziehungen zwischen den Variablen in den Daten zu finden und diese Beziehungen zu nutzen, um Vorhersagen oder Entscheidungen zu treffen. Das Ziel des Assoziationsregel-Minings ist es, Regeln aufzudecken, die die Beziehungen zwischen verschiedenen Elementen im Datensatz beschreiben.
Nehmen wir zum Beispiel einen Datensatz mit Transaktionen in einem Lebensmittelgeschäft. Mit Hilfe von Assoziationsregeln lassen sich Beziehungen zwischen Artikeln erkennen, die häufig zusammen gekauft werden. Die Regel "Wenn ein Kunde Brot kauft, kauft er wahrscheinlich auch Milch" ist zum Beispiel eine Assoziationsregel, die aus diesem Datensatz gewonnen werden könnte. Wir können solche Regeln nutzen, um Entscheidungen über das Ladenlayout, die Produktplatzierung und Marketingmaßnahmen zu treffen.
Beim Assoziationsregel-Mining werden in der Regel Algorithmen eingesetzt, um die Daten zu analysieren und die Beziehungen zu erkennen. Diese Algorithmen können auf statistischen Methoden oder maschinellen Lernverfahren beruhen. Die sich daraus ergebenden Regeln werden oft in Form von "Wenn-Dann"-Aussagen ausgedrückt, wobei der "Wenn"-Teil die Vorbedingung (die getestete Bedingung) und der "Dann"-Teil die Folge (das Ergebnis, das eintritt, wenn die Bedingung erfüllt ist) darstellt.
Die Suche nach Assoziationsregeln ist eine wichtige Technik in der Datenanalyse, weil sie es den Nutzern ermöglicht, Muster oder Beziehungen in Daten zu entdecken, die vielleicht nicht sofort ersichtlich sind. Durch die Identifizierung von Assoziationen zwischen Variablen kann das Assoziationsregel-Mining den Nutzern helfen, die Beziehungen zwischen verschiedenen Variablen zu verstehen und wie diese Variablen miteinander in Beziehung stehen können.
Dies kann für verschiedene Zwecke nützlich sein, z. B. um Markttrends zu erkennen, betrügerische Aktivitäten aufzudecken oder das Kundenverhalten zu verstehen. Association Rule Mining kann auch als Sprungbrett für andere Arten der Datenanalyse genutzt werden, z. B. für die Vorhersage von Ergebnissen oder die Identifizierung von Schlüsselfaktoren für bestimmte Phänomene. Insgesamt ist das Assoziationsregel-Mining ein wertvolles Instrument, um Erkenntnisse zu gewinnen und die zugrunde liegende Struktur von Daten zu verstehen.
Anwendungsfälle von Association Rule Mining:
Die Auswertung von Assoziationsregeln wird in einer Vielzahl von Anwendungen eingesetzt, darunter einige gängige:
Marktkorb-Analyse
Eine der bekanntesten Anwendungen von Association Rule Mining ist die Warenkorbanalyse. Dabei werden die Artikel analysiert, die die Kunden gemeinsam kaufen, um ihre Kaufgewohnheiten und Vorlieben zu verstehen.
Ein Einzelhändler könnte zum Beispiel mithilfe von Assoziationsregeln herausfinden, dass Kunden, die Windeln kaufen, wahrscheinlich auch Babynahrung kaufen. Wir können diese Informationen nutzen, um Produktplatzierungen und Werbeaktionen zu optimieren und den Umsatz zu steigern.
Um mehr über die Warenkorbanalyse zu erfahren, schau dir unser Tutorial zur Warenkorbanalyse in R an.
Kundensegmentierung
Association Rule Mining kann auch verwendet werden, um Kunden anhand ihrer Kaufgewohnheiten zu segmentieren.
Ein Unternehmen könnte zum Beispiel mithilfe von Assoziationsregeln herausfinden, dass Kunden, die bestimmte Produkte kaufen, eher jünger sind. Ebenso könnten sie erfahren, dass Kunden, die bestimmte Produktkombinationen kaufen, eher in bestimmten geografischen Regionen zu finden sind.
Wir können diese Informationen nutzen, um Marketingkampagnen und personalisierte Empfehlungen auf bestimmte Kundensegmente zuzuschneiden. Mehr zu diesem Thema erfährst du in unserem Tutorial Einführung in die Kundensegmentierung in Python.
Betrugsaufdeckung
Du kannst auch Assoziationsregeln verwenden, um betrügerische Aktivitäten aufzudecken. Ein Kreditkartenunternehmen könnte zum Beispiel Assoziationsregeln verwenden, um Muster von betrügerischen Transaktionen zu erkennen, wie z. B. mehrere Käufe beim selben Händler innerhalb eines kurzen Zeitraums.
Wir können diese Informationen dann nutzen, um potenziell betrügerische Aktivitäten zu erkennen und Präventivmaßnahmen zum Schutz der Kunden zu ergreifen. In unserem Data Sciece in Banking: Blog von Fraud Detection erfährst du mehr darüber, wie das Verfahren funktioniert.
Analyse sozialer Netzwerke
Verschiedene Unternehmen nutzen das Assoziationsregel-Mining, um Muster in Social-Media-Daten zu erkennen, die bei der Analyse von sozialen Netzwerken helfen können.
Eine Analyse von Twitter-Daten könnte zum Beispiel zeigen, dass Nutzer/innen, die über ein bestimmtes Thema twittern, wahrscheinlich auch über andere verwandte Themen twittern, was die Identifizierung von Gruppen oder Gemeinschaften innerhalb des Netzwerks ermöglichen könnte.
Empfehlungssysteme
Mit Hilfe von Assoziationsregeln können Artikel vorgeschlagen werden, für die sich ein Kunde aufgrund seiner früheren Einkäufe oder seines Surfverhaltens interessieren könnte. Ein Musikstreamingdienst könnte zum Beispiel Assoziationsregeln verwenden, um einem Nutzer auf der Grundlage seiner Hörgeschichte neue Künstler oder Alben zu empfehlen.
In unserem Tutorial über Empfehlungssysteme in Python erfährst du mehr darüber, wie du verschiedene Modelle erstellen kannst, die diese Funktion erfüllen.
Algorithmen für das Association Rule Mining
Es gibt verschiedene Algorithmen, die für das Assoziationsregel-Mining verwendet werden. Einige davon sind häufig:
Apriori-Algorithmus
Der Apriori-Algorithmus ist einer der am häufigsten verwendeten Algorithmen für das Assoziationsregel-Mining. Dabei werden zunächst die häufigen Itemsets im Datensatz identifiziert (Itemsets, die in einer bestimmten Anzahl von Transaktionen vorkommen). Anhand dieser häufigen Einträge werden dann Assoziationsregeln erstellt, also Aussagen der Form "Wenn Artikel A gekauft wird, wird wahrscheinlich auch Artikel B gekauft". Der Apriori-Algorithmus verwendet einen Bottom-up-Ansatz, bei dem er mit einzelnen Elementen beginnt und schrittweise zu komplexeren Elementen aufsteigt.
FP-Wachstumsalgorithmus
Der FP-Growth-Algorithmus (Frequent Pattern Growth) ist ein weiterer beliebter Algorithmus für das Assoziationsregel-Mining. Dabei wird eine baumähnliche Struktur, ein sogenannter FP-Baum, erstellt, der die häufigen Einträge im Datensatz kodiert. Der FP-Baum wird dann verwendet, um ähnlich wie beim Apriori-Algorithmus Assoziationsregeln zu erstellen. Der FP-Growth-Algorithmus ist im Allgemeinen schneller als der Apriori-Algorithmus, insbesondere bei großen Datensätzen.
ECLAT-Algorithmus
Der ECLAT-Algorithmus (Equivalence Class Clustering and Bottom-up Lattice Traversal) ist eine Variante des Apriori-Algorithmus, die einen Top-Down-Ansatz statt eines Bottom-Up-Ansatzes verwendet. Dabei werden die Artikel auf der Grundlage ihrer Unterstützung (der Anzahl der Transaktionen, in denen sie vorkommen) in Äquivalenzklassen eingeteilt. Die Assoziationsregeln werden dann durch die Kombination dieser Äquivalenzklassen in einer gitterartigen Struktur erstellt. Er ist eine effizientere und skalierbarere Version des Apriori-Algorithmus.
Apriori Algorithm
Der Apriori-Algorithmus hat sich zu einem der am weitesten verbreiteten Algorithmen für das Mining von Frequent Itemsets und das Lernen von Assoziationsregeln entwickelt. Er wurde für eine Vielzahl von Anwendungen eingesetzt, darunter die Analyse von Warenkörben, Empfehlungssysteme und die Betrugserkennung, und hat die Entwicklung vieler anderer Algorithmen für ähnliche Aufgaben inspiriert.
Algorithmus Details
Der Apriori-Algorithmus beginnt mit der Festlegung der minimalen Unterstützungsschwelle. Dies ist die Mindestanzahl, die ein Element in der Datenbank vorkommen muss, damit es als häufiges Item-Set gilt. Der Algorithmus filtert dann alle Kandidatensätze heraus, die die Mindestunterstützungsschwelle nicht erfüllen.
Der Algorithmus erstellt dann eine Liste mit allen möglichen Kombinationen von häufigen Mengen und zählt, wie oft jede Kombination in der Datenbank vorkommt. Der Algorithmus erstellt dann eine Liste von Assoziationsregeln, die auf den Kombinationen der häufigen Elemente basieren.
Eine Assoziationsregel ist eine Aussage der Form "Wenn Gegenstand A in einer Transaktion vorhanden ist, dann ist auch Gegenstand B wahrscheinlich vorhanden". Die Stärke der Assoziation wird anhand der Konfidenz der Regel gemessen, d. h. der Wahrscheinlichkeit, dass Element B vorhanden ist, wenn Element A vorhanden ist.
Der Algorithmus filtert dann alle Assoziationsregeln heraus, die eine Mindestkonfidenzschwelle nicht erreichen. Diese Regeln werden als starke Assoziationsregeln bezeichnet. Schließlich gibt der Algorithmus die Liste der starken Assoziationsregeln als Ausgabe zurück.
Apriori verwendet einen "Bottom-up"-Ansatz, bei dem es mit einzelnen Elementen beginnt und diese bei der Suche nach häufigen Mustern nach und nach zu immer größeren Elementmengen kombiniert. Außerdem wird ein "delete-relabel"-Ansatz verwendet, um den Suchraum effizient zu verkleinern, indem seltene Itemsets aus der Betrachtung ausgeschlossen werden.
Vorteile:
- Apriori ist relativ einfach und leicht zu verstehen.
- Sie identifiziert effektiv häufige Muster und Assoziationsregeln in großen Datensätzen.
- Er ist effizient beim Beschneiden des Suchraums, indem er seltene Itemsets aus der Betrachtung ausschließt und so den Rechenaufwand des Algorithmus reduziert.
- Der Algorithmus wurde bereits in vielen verschiedenen Anwendungen eingesetzt und getestet und ist somit ein bewährter und zuverlässiger Algorithmus.
Nachteile:
- Apriori ist nicht für sehr große Datensätze geeignet, da die Rechenkomplexität des Algorithmus exponentiell mit der Größe des Datensatzes steigt.
- Bei Datensätzen mit vielen seltenen Gegenständen oder seltenen Transaktionen ist es möglicherweise nicht so effektiv, Muster zu erkennen.
- Sie reagiert empfindlich auf die Schwellenwerte für die Mindestunterstützung und das Mindestvertrauen, was sich auf die Qualität der Ergebnisse auswirken kann.
- Es kann dazu neigen, eine große Anzahl von Assoziationsregeln zu erstellen, was die Interpretation der Ergebnisse erschweren kann.
Wenn du tiefer in den Apriori-Algorithmus eintauchen willst, schau dir dieses tolle Tutorial zur Warenkorbanalyse auf DataCamp an.
Metriken zur Bewertung von Assoziationsregeln
Beim Assoziationsregel-Mining werden üblicherweise verschiedene Metriken verwendet, um die Qualität und Bedeutung der entdeckten Assoziationsregeln zu bewerten.
Diese Metriken können verwendet werden, um die Qualität und Bedeutung von Assoziationsregeln zu bewerten und die relevantesten Regeln für eine bestimmte Anwendung auszuwählen. Es ist wichtig zu beachten, dass die Wahl der geeigneten Metrik von den spezifischen Zielen und Anforderungen der Anwendung abhängt.
Um die Ergebnisse der Assoziationsregel-Metriken zu interpretieren, muss man die Bedeutung und die Implikationen der einzelnen Metriken verstehen und wissen, wie man sie verwendet, um die Qualität und die Bedeutung der entdeckten Assoziationsregeln zu bewerten. Hier sind einige Richtlinien für die Interpretation der Ergebnisse der wichtigsten Assoziationsregel-Metriken:
Unterstütze
Die Unterstützung ist ein Maß dafür, wie häufig ein Item oder ein Item-Set im Datensatz vorkommt. Sie wird berechnet als die Anzahl der Transaktionen, die den/die Artikel enthalten, geteilt durch die Gesamtzahl der Transaktionen im Datensatz. Eine hohe Unterstützung zeigt an, dass ein Item oder ein Item-Set im Datensatz häufig vorkommt, während eine geringe Unterstützung bedeutet, dass es selten ist.
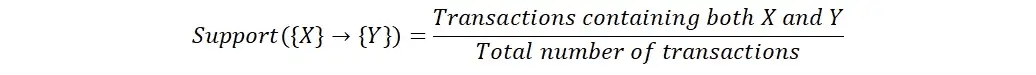
Zuversicht
Die Konfidenz ist ein Maß für die Stärke des Zusammenhangs zwischen zwei Items. Sie wird berechnet als die Anzahl der Vorgänge, die beide Posten enthalten, geteilt durch die Anzahl der Vorgänge, die den ersten Posten enthalten. Hohes Vertrauen bedeutet, dass das Vorhandensein des ersten Items ein starker Prädiktor für das Vorhandensein des zweiten Items ist.
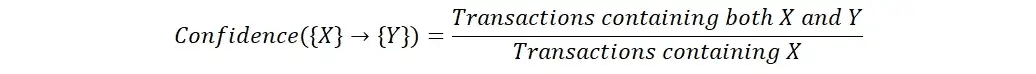
Aufzug
Der Lift ist ein Maß für die Stärke der Assoziation zwischen zwei Items, wobei die Häufigkeit beider Items im Datensatz berücksichtigt wird. Sie wird berechnet als die Konfidenz der Assoziation geteilt durch die Unterstützung des zweiten Items. Der Lift wird verwendet, um die Stärke des Zusammenhangs zwischen zwei Items mit der erwarteten Stärke des Zusammenhangs zu vergleichen, wenn die Items unabhängig wären.
Ein Lift-Wert größer als 1 zeigt an, dass der Zusammenhang zwischen zwei Items stärker ist als aufgrund der Häufigkeit der einzelnen Items erwartet. Das deutet darauf hin, dass der Zusammenhang bedeutsam und eine weitere Untersuchung wert sein könnte. Ein Lift-Wert von weniger als 1 bedeutet, dass der Zusammenhang schwächer als erwartet ist und möglicherweise weniger zuverlässig oder weniger signifikant ist.

Python- und R-Bibliotheken für Association Rule Mining
Es gibt verschiedene Bibliotheken in R und Python, die für das Assoziationsregel-Mining verwendet werden können:
R Bibliotheken
- arules: Dies ist ein Paket für das Mining von Assoziationsregeln und Frequent Itemsets in R. Es bietet Funktionen zum Lesen und Manipulieren von Transaktionsdaten sowie zum Erzeugen von Assoziationsregeln und zum Auswerten ihrer Qualität.
- arulesViz: Dies ist ein Paket zur Visualisierung von Assoziationsregeln und Frequent Itemsets in R. Es bietet Funktionen zur Erstellung von Plots und Diagrammen, die das Verständnis und die Interpretation der Ergebnisse des Assoziationsregel-Minings erleichtern.
- arulesSequences: Dies ist ein Paket für das Mining von Assoziationsregeln aus sequentiellen Daten in R. Es bietet Funktionen zum Lesen und Manipulieren sequentieller Daten sowie zum Generieren von Assoziationsregeln und zum Auswerten ihrer Qualität.
Python-Bibliotheken
- apyori: Dies ist eine Bibliothek zur Implementierung des Apriori-Algorithmus in Python. Es bietet Funktionen zum Lesen und Manipulieren von Transaktionsdaten sowie zum Erstellen von Assoziationsregeln und zur Bewertung ihrer Qualität.
- mlxtend: Dies ist eine Bibliothek, mit der du verschiedene Algorithmen und Werkzeuge des maschinellen Lernens in Python implementieren kannst, darunter auch das Assoziationsregel-Mining. Es bietet Funktionen zum Lesen und Manipulieren von Transaktionsdaten sowie zum Erstellen von Assoziationsregeln und zur Bewertung ihrer Qualität.
- PyCaret: PyCaret ist eine Open-Source-Bibliothek für maschinelles Lernen in Python, mit der sich maschinelle Lernabläufe automatisieren lassen. Es bietet einen Wrapper über mlxtend für die einfache Implementierung des Apriori-Algorithmus.
Assoziationsregeln in Python implementieren
Wir werden PyCaret verwenden, um Assoziationsregeln in Python zu implementieren. Wir beginnen mit der Installation von PyCaret und importieren dann den Beispieldatensatz.
PyCaret installieren
Du kannst pycaret mit pip installieren.
```
# install pycaret
pip install pycaret
```Dataset
Wir beginnen damit, einen Beispieldatensatz aus dem pycaret-Repository zu laden. Es handelt sich um einen Transaktionsdatensatz aus einem Einzelhandelsgeschäft in Frankreich. Sie enthält die Rechnungsnummer zur Identifizierung der Transaktion und die Beschreibung des Artikels. Das sind die einzigen beiden Dinge, die uns bei der Ermittlung von Regeln aus diesem Datensatz interessieren.
```
# load sample data
from pycaret.datasets import get_data
data = get_data('france')
```
Einrichtung
Im ersten Schritt importierst du das Modul `arules` und initialisierst die Funktion `setup`, indem du data, transaction_id und item_id definierst.
```
# init setup
from pycaret.arules import *
s = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
```
Ausgabe der Setup-Funktion
Modell erstellen
```
The `create_model` function runs the algorithm and return the rules in pandas DataFrame based on the selection parameters defined in the `create_model`. In this example we have used selection metric `confidence` with threshold and support of 0.5.
# train model
arules = create_model(metric='confidence', threshold=0.5, min_support=0.05)
```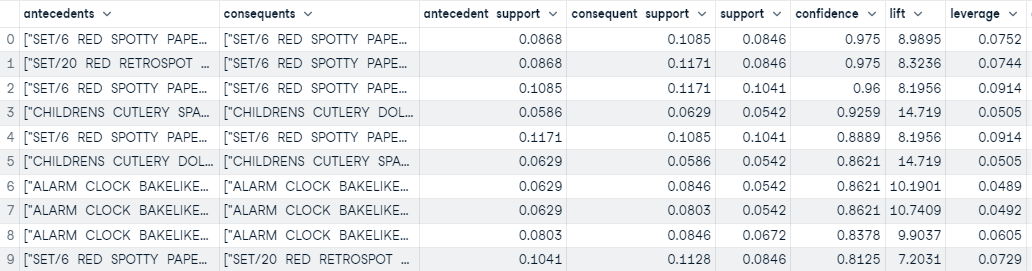
Ausgabe der Funktion create_model
Basierend auf dem Schwellenwert, der in den "create_model"-Funktionen definiert wurde, haben wir 45 Regeln erstellt. Die obige Ausgabe enthält die ersten 10, sortiert nach Konfidenz (höchste bis niedrigste).
Grundstücksregeln
Visualisiere und analysiere Regeln mit der Funktion `plot_model` in PyCaret.
```
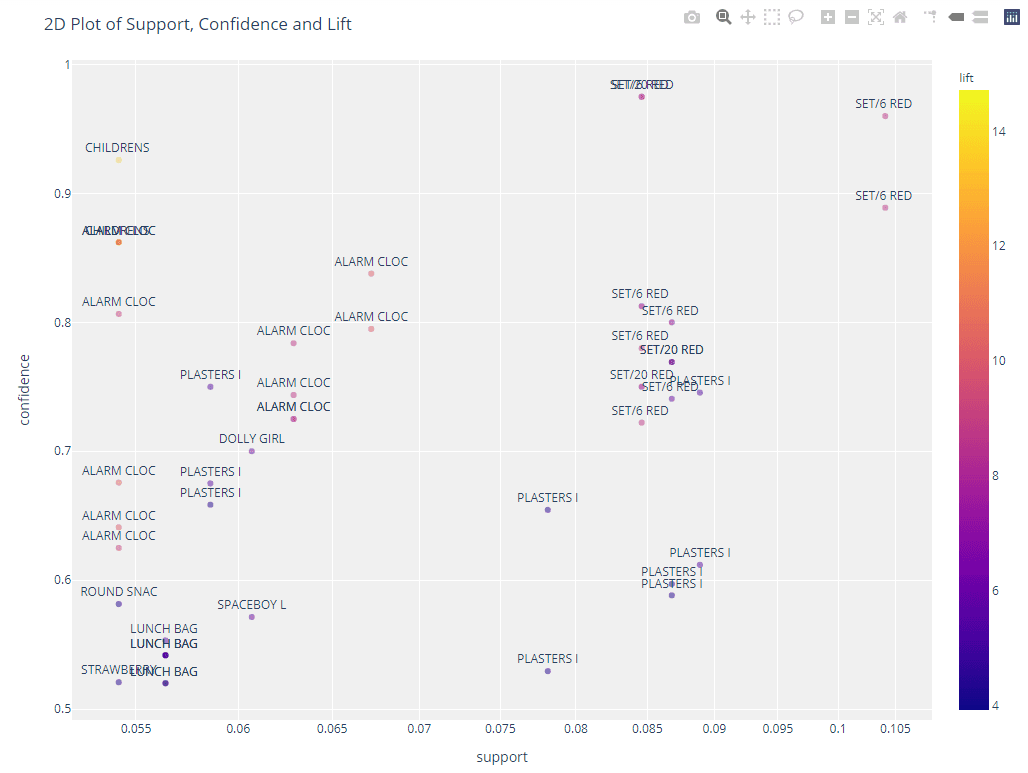
# 2d plot
plot_model(arules, plot = '2d')
```
```
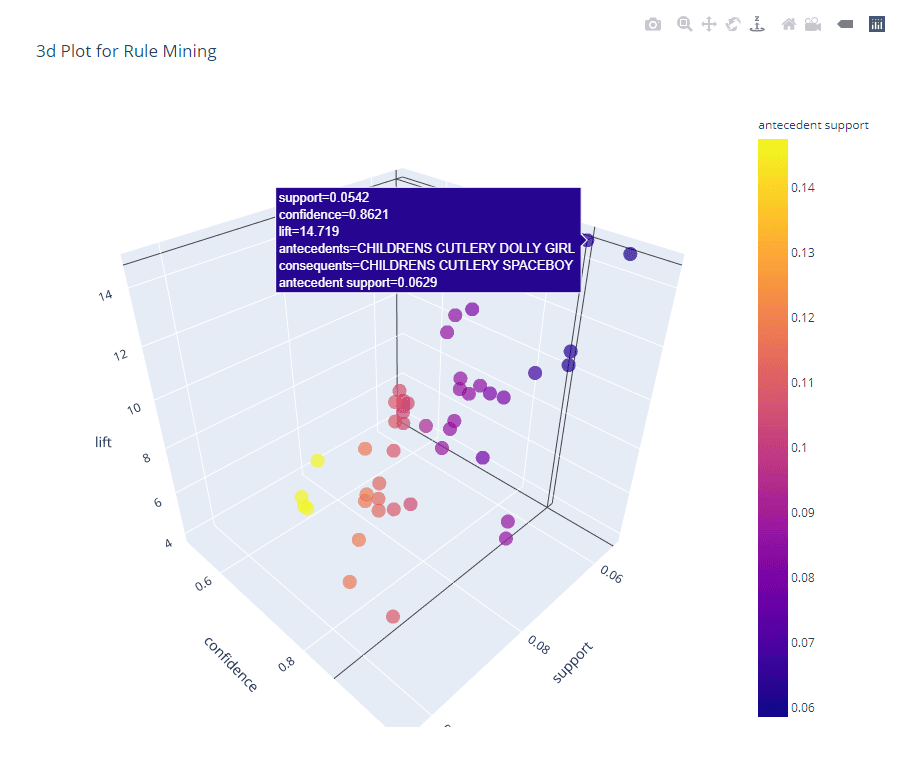
# 3d plot
plot_model(arules, plot = '3d')
```Schau dir das ganze Notizbuch an, um mitzukommen.
Fazit
Association Rule Mining ist ein wertvolles Werkzeug für die Datenanalyse und eine leistungsstarke Technik, um Muster und Beziehungen in Daten zu entdecken. In Python und R gibt es mehrere Bibliotheken für die Implementierung von Assoziationsregel-Mining, die eine Out-of-Box-Implementierung für verschiedene Algorithmen sowie Optionen zur Visualisierung der Ergebnisse bereitstellen.
Du kannst Assoziationsregeln in verschiedenen Kontexten nutzen, um Erkenntnisse zu gewinnen und die zugrunde liegende Struktur von Daten zu verstehen. Um aussagekräftige und genaue Ergebnisse zu erhalten, ist es jedoch wichtig, den passenden Algorithmus zu wählen und die richtigen Parameter wie die Mindestunterstützung und die Vertrauensschwellen festzulegen.
Wenn du tiefer in dieses Thema eintauchen und mehr über Assoziationsregeln lernen möchtest, kannst du dir die folgenden Kurse ansehen: