La minería de reglas de asociación es una técnica utilizada para descubrir relaciones ocultas entre variables en grandes conjuntos de datos. Es un método popular en la minería de datos y el aprendizaje automático y tiene una amplia gama de aplicaciones en diversos campos, como el análisis de cestas de mercado, la segmentación de clientes y la detección de fraudes.
En este artículo, exploraremos la minería de reglas de asociación en Python, incluyendo sus casos de uso, algoritmos e implementación. Comenzaremos con una breve visión general de la minería de reglas de asociación y sus aplicaciones, para después profundizar en los detalles de los algoritmos y su implementación en Python. Por último, concluiremos con un resumen de los puntos clave tratados en este artículo.
¿Qué es la minería de reglas de asociación?
La minería de reglas de asociación es una técnica utilizada para identificar patrones en grandes conjuntos de datos. Consiste en encontrar relaciones entre las variables de los datos y utilizar esas relaciones para hacer predicciones o tomar decisiones. El objetivo de la minería de reglas de asociación es descubrir reglas que describan las relaciones entre los distintos elementos del conjunto de datos.
Por ejemplo, consideremos un conjunto de datos de transacciones en una tienda de comestibles. La minería de reglas de asociación podría utilizarse para identificar relaciones entre artículos que se compran juntos con frecuencia. Por ejemplo, la regla "Si un cliente compra pan, es probable que también compre leche" es una regla de asociación que podría extraerse de este conjunto de datos. Podemos utilizar estas reglas para tomar decisiones sobre la distribución de las tiendas, la colocación de los productos y las acciones de marketing.
La minería de reglas de asociación suele implicar el uso de algoritmos para analizar los datos e identificar las relaciones. Estos algoritmos pueden basarse en métodos estadísticos o técnicas de aprendizaje automático. Las reglas resultantes suelen expresarse en forma de sentencias "si-entonces", en las que la parte "si" representa el antecedente (la condición que se comprueba) y la parte "entonces" representa el consecuente (el resultado que se produce si se cumple la condición).
La minería de reglas de asociación es una técnica importante en el análisis de datos porque permite descubrir patrones o relaciones en los datos que pueden no ser evidentes de inmediato. Al identificar asociaciones entre variables, la minería de reglas de asociación puede ayudar a los usuarios a comprender las relaciones entre distintas variables y cómo esas variables pueden estar relacionadas entre sí.
Esto puede ser útil para diversos fines, como identificar tendencias de mercado, detectar actividades fraudulentas o comprender el comportamiento de los clientes. La minería de reglas de asociación también puede utilizarse como trampolín para otros tipos de análisis de datos, como la predicción de resultados o la identificación de impulsores clave de determinados fenómenos. En general, la minería de reglas de asociación es una herramienta valiosa para extraer información y comprender la estructura subyacente de los datos.
Casos prácticos de minería de reglas de asociación:
La minería de reglas de asociación se utiliza comúnmente en una variedad de aplicaciones, algunas comunes son:
Análisis de la cesta de la compra
Una de las aplicaciones más conocidas de la minería de reglas de asociación es el análisis de la cesta de la compra. Se trata de analizar conjuntamente los artículos que compran los clientes para conocer sus hábitos de compra y sus preferencias.
Por ejemplo, un minorista podría utilizar la minería de reglas de asociación para descubrir que es probable que los clientes que compran pañales también compren leche de fórmula para bebés. Podemos utilizar esta información para optimizar la colocación de los productos y las promociones para aumentar las ventas.
Para obtener más información sobre el análisis de la cesta de la compra, consulte nuestro tutorial Análisis de la cesta de la compra en R.
Segmentación de clientes
La minería de reglas de asociación también puede utilizarse para segmentar a los clientes en función de sus hábitos de compra.
Por ejemplo, una empresa puede utilizar la minería de reglas de asociación para descubrir que los clientes que compran determinados tipos de productos tienen más probabilidades de ser más jóvenes. Del mismo modo, podrían saber que los clientes que compran determinadas combinaciones de productos tienen más probabilidades de estar ubicados en regiones geográficas concretas.
Podemos utilizar esta información para adaptar campañas de marketing y recomendaciones personalizadas a segmentos específicos de clientes. Descubra más sobre este tema en nuestro tutorial de introducción a la segmentación de clientes en Python.
Detección de fraudes
También puede utilizar la minería de reglas de asociación para detectar actividades fraudulentas. Por ejemplo, una empresa de tarjetas de crédito podría utilizar la minería de reglas de asociación para identificar patrones de transacciones fraudulentas, como múltiples compras al mismo comerciante en un breve periodo de tiempo.
Podemos utilizar esta información para detectar actividades potencialmente fraudulentas y tomar medidas preventivas para proteger a los clientes. En nuestro sitio Data Sciece in Banking: Fraud Detection blog, puede obtener más información sobre cómo funciona el proceso.
Análisis de redes sociales
Varias empresas utilizan la minería de reglas de asociación para identificar patrones en los datos de los medios sociales que puedan informar el análisis de las redes sociales.
Por ejemplo, un análisis de los datos de Twitter podría revelar que los usuarios que tuitean sobre un tema concreto también suelen tuitear sobre otros temas relacionados, lo que podría informar sobre la identificación de grupos o comunidades dentro de la red.
Sistemas de recomendación
La minería de reglas de asociación puede utilizarse para sugerir artículos que podrían interesar a un cliente basándose en sus compras anteriores o en su historial de navegación. Por ejemplo, un servicio de streaming de música puede utilizar la minería de reglas de asociación para recomendar nuevos artistas o álbumes a un usuario basándose en su historial de escuchas.
Con nuestro tutorial sobre sistemas de recomendación en Python, podrá aprender más sobre cómo construir varios modelos que realizan esta función.
Algoritmos de minería de reglas de asociación
Existen varios algoritmos utilizados para la minería de reglas de asociación. Algunas de las más comunes son:
Algoritmo Apriori
El algoritmo Apriori es uno de los más utilizados para la minería de reglas de asociación. En primer lugar, identifica los conjuntos de elementos frecuentes en el conjunto de datos (conjuntos de elementos que aparecen en un determinado número de transacciones). A continuación, utiliza estos conjuntos de elementos frecuentes para generar reglas de asociación, que son afirmaciones del tipo "si se compra el artículo A, es probable que también se compre el artículo B". El algoritmo Apriori utiliza un enfoque ascendente, comenzando con elementos individuales y construyendo gradualmente conjuntos de elementos más complejos.
Algoritmo FP-Growth
El algoritmo FP-Growth (Frequent Pattern Growth) es otro algoritmo popular para la minería de reglas de asociación. Funciona mediante la construcción de una estructura arborescente denominada árbol FP, que codifica los conjuntos de elementos frecuentes del conjunto de datos. A continuación, el árbol FP se utiliza para generar reglas de asociación de forma similar al algoritmo Apriori. El algoritmo FP-Growth es generalmente más rápido que el algoritmo Apriori, especialmente para grandes conjuntos de datos.
Algoritmo ECLAT
El algoritmo ECLAT (Equivalence Class Clustering and bottom-up Lattice Traversal) es una variación del algoritmo Apriori que utiliza un enfoque descendente en lugar de ascendente. Funciona dividiendo los artículos en clases de equivalencia en función de su soporte (el número de transacciones en las que aparecen). A continuación, las reglas de asociación se generan combinando estas clases de equivalencia en una estructura similar a una celosía. Se trata de una versión más eficiente y escalable del algoritmo Apriori.
Algoritmo Apriori
El algoritmo apriori se ha convertido en uno de los más utilizados para la minería de conjuntos de elementos frecuentes y el aprendizaje de reglas de asociación. Se ha aplicado a diversas aplicaciones, como el análisis de cestas de mercado, los sistemas de recomendación y la detección de fraudes, y ha inspirado el desarrollo de muchos otros algoritmos para tareas similares.
Detalles del algoritmo
El algoritmo apriori comienza estableciendo el umbral de soporte mínimo. Es el número mínimo de veces que un elemento debe aparecer en la base de datos para que se considere un conjunto de elementos frecuentes. A continuación, el algoritmo filtra los itemsets candidatos que no alcanzan el umbral mínimo de apoyo.
A continuación, el algoritmo genera una lista de todas las combinaciones posibles de conjuntos frecuentes y cuenta el número de veces que aparece cada combinación en la base de datos. A continuación, el algoritmo genera una lista de reglas de asociación basadas en las combinaciones de ítems frecuentes.
Una regla de asociación es una afirmación del tipo "si el elemento A está presente en una transacción, es probable que el elemento B también lo esté". La fuerza de la asociación se mide utilizando la confianza de la regla, que es la probabilidad de que el elemento B esté presente dado que el elemento A está presente.
A continuación, el algoritmo filtra las reglas de asociación que no alcanzan un umbral mínimo de confianza. Estas reglas se denominan reglas de asociación fuertes. Por último, el algoritmo devuelve como resultado la lista de reglas de asociación sólidas.
Apriori utiliza un enfoque "ascendente", empezando con elementos individuales y combinándolos gradualmente en conjuntos de elementos cada vez mayores a medida que busca patrones frecuentes. También utiliza un método de "eliminación de etiquetas" para recortar eficazmente el espacio de búsqueda eliminando los conjuntos de elementos poco frecuentes.
Pros:
- Apriori es relativamente sencillo y fácil de entender.
- Identifica eficazmente patrones frecuentes y reglas de asociación en grandes conjuntos de datos.
- Es eficaz a la hora de podar el espacio de búsqueda eliminando los conjuntos de elementos poco frecuentes, lo que reduce la complejidad computacional del algoritmo.
- Ha sido ampliamente utilizado y probado en diversas aplicaciones, lo que lo convierte en un algoritmo consolidado y fiable.
Contras:
- Apriori no es adecuado para conjuntos de datos muy grandes, ya que la complejidad computacional del algoritmo aumenta exponencialmente con el tamaño del conjunto de datos.
- Puede que no sea tan eficaz a la hora de identificar patrones en conjuntos de datos con muchos artículos raros o transacciones poco frecuentes.
- Es sensible a los umbrales mínimo de apoyo y mínimo de confianza, que pueden afectar a la calidad de los resultados.
- Puede ser propenso a generar un gran número de reglas de asociación, lo que puede dificultar la interpretación de los resultados.
Para profundizar en el algoritmo Apriori, echa un vistazo a este increíble tutorial de Análisis de la Cesta de Mercado en DataCamp.
Métricas para evaluar las reglas de asociación
En la minería de reglas de asociación, se suelen utilizar varias métricas para evaluar la calidad y la importancia de las reglas de asociación descubiertas.
Estas métricas pueden utilizarse para evaluar la calidad e importancia de las reglas de asociación y seleccionar las más relevantes para una aplicación determinada. Es importante señalar que la elección de la métrica adecuada dependerá de los objetivos y requisitos específicos de la aplicación.
La interpretación de los resultados de las métricas de minería de reglas de asociación requiere comprender el significado y las implicaciones de cada métrica, así como la forma de utilizarlas para evaluar la calidad y la importancia de las reglas de asociación descubiertas. A continuación se ofrecen algunas pautas para interpretar los resultados de las principales métricas de minería de reglas de asociación:
Ayuda
El apoyo es una medida de la frecuencia con la que un elemento o conjunto de elementos aparece en el conjunto de datos. Se calcula como el número de transacciones que contienen el artículo o artículos dividido por el número total de transacciones del conjunto de datos. Un apoyo alto indica que un elemento o conjunto de elementos es común en el conjunto de datos, mientras que un apoyo bajo indica que es raro.
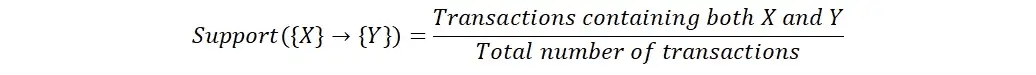
Confianza
La confianza es una medida de la fuerza de la asociación entre dos elementos. Se calcula como el número de transacciones que contienen ambos elementos dividido por el número de transacciones que contienen el primer elemento. Una confianza alta indica que la presencia del primer elemento es un fuerte predictor de la presencia del segundo elemento.
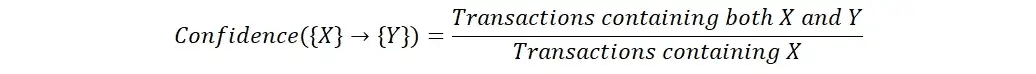
Ascensor
La elevación es una medida de la fuerza de la asociación entre dos elementos, teniendo en cuenta la frecuencia de ambos en el conjunto de datos. Se calcula como la confianza de la asociación dividida por el apoyo del segundo elemento. La elevación se utiliza para comparar la fuerza de la asociación entre dos elementos con la fuerza esperada de la asociación si los elementos fueran independientes.
Un valor de elevación superior a 1 indica que la asociación entre dos elementos es mayor de lo esperado en función de la frecuencia de los elementos individuales. Esto sugiere que la asociación puede ser significativa y que merece la pena seguir investigándola. Un valor de elevación inferior a 1 indica que la asociación es más débil de lo esperado y puede ser menos fiable o menos significativa.

Bibliotecas Python y R para minería de reglas de asociación
Existen varias bibliotecas en R y Python que pueden utilizarse para la minería de reglas de asociación:
Bibliotecas R
- arules: Se trata de un paquete para la minería de reglas de asociación y conjuntos de elementos frecuentes en R. Proporciona funciones para leer y manipular datos transaccionales, así como para generar reglas de asociación y evaluar su calidad.
- arulesViz: Se trata de un paquete para visualizar reglas de asociación y conjuntos de elementos frecuentes en R. Proporciona funciones para crear gráficos y diagramas que ayudan a comprender e interpretar los resultados de la minería de reglas de asociación.
- arulesSequences: Se trata de un paquete para la minería de reglas de asociación a partir de datos secuenciales en R. Proporciona funciones para leer y manipular datos secuenciales, así como para generar reglas de asociación y evaluar su calidad.
Bibliotecas Python
- apyori: Se trata de una biblioteca para implementar el algoritmo Apriori en Python. Proporciona funciones para leer y manipular datos transaccionales, así como para generar reglas de asociación y evaluar su calidad.
- mlxtend: Se trata de una biblioteca para implementar diversos algoritmos y herramientas de aprendizaje automático en Python, incluida la minería de reglas de asociación. Proporciona funciones para leer y manipular datos transaccionales, así como para generar reglas de asociación y evaluar su calidad.
- PyCaret: PyCaret es una biblioteca de aprendizaje automático de código abierto y bajo nivel de código en Python para automatizar los flujos de trabajo de aprendizaje automático. Proporciona una envoltura sobre mlxtend para una fácil implementación del algoritmo Apriori.
Implementación de reglas de asociación en Python
Utilizaremos PyCaret para implementar reglas de asociación en Python. Comencemos instalando PyCaret e importando el conjunto de datos de ejemplo.
Instalar PyCaret
Puedes instalar pycaret usando pip.
```
# install pycaret
pip install pycaret
```Conjunto de datos
Empezaremos cargando un conjunto de datos de ejemplo del repositorio de pycaret. Se trata de un conjunto de datos transaccionales de uno de los comercios minoristas de Francia. Contiene el número de factura para identificar la transacción y la descripción del artículo. Éstas son las dos únicas cosas que nos importan a la hora de extraer reglas de este conjunto de datos.
```
# load sample data
from pycaret.datasets import get_data
data = get_data('france')
```
Configurar
El primer paso es importar el módulo `arules` e inicializar la función `setup` definiendo data, transaction_id, y item_id.
```
# init setup
from pycaret.arules import *
s = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
```
Salida de la función de configuración
Crear modelo
```
The `create_model` function runs the algorithm and return the rules in pandas DataFrame based on the selection parameters defined in the `create_model`. In this example we have used selection metric `confidence` with threshold and support of 0.5.
# train model
arules = create_model(metric='confidence', threshold=0.5, min_support=0.05)
```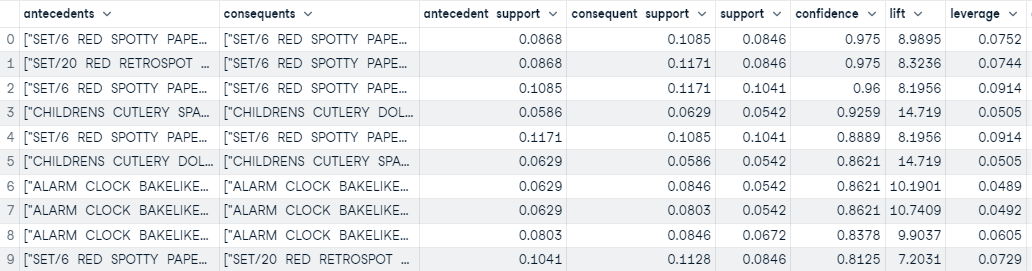
Salida de la función create_model
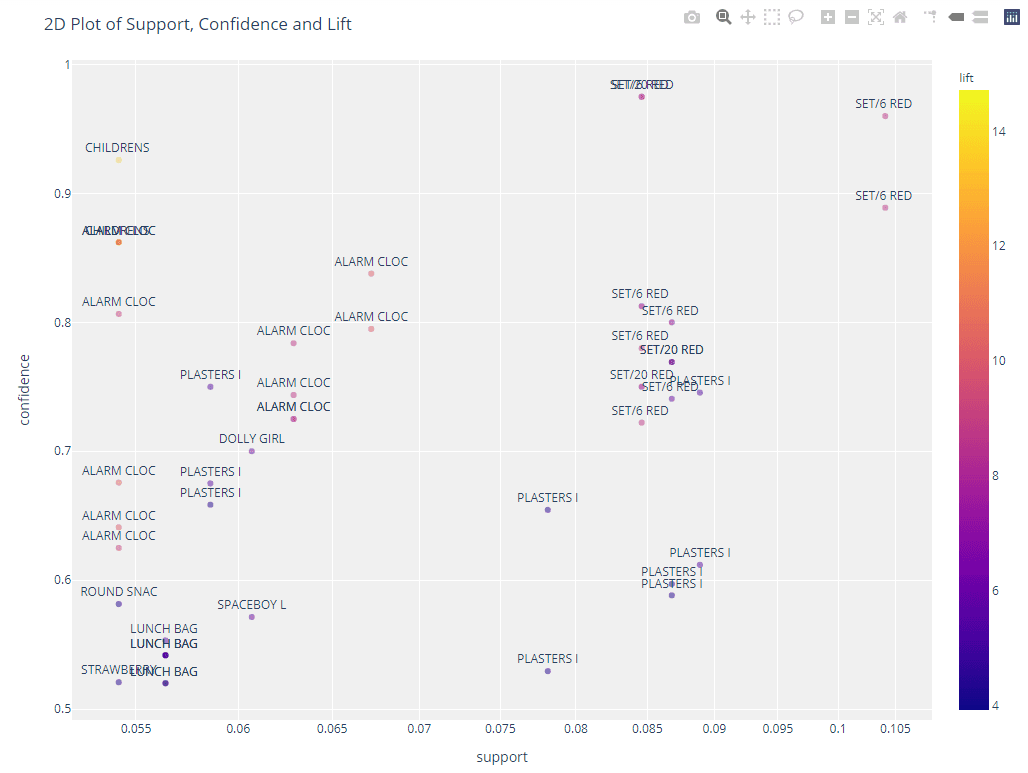
A partir del umbral definido en las funciones `create_model`, hemos creado 45 reglas. La salida anterior contiene los 10 primeros ordenados en función de la confianza (de mayor a menor).
Reglas de la trama
Visualice y analice reglas utilizando la función `plot_model` de PyCaret.
```
# 2d plot
plot_model(arules, plot = '2d')
```
```
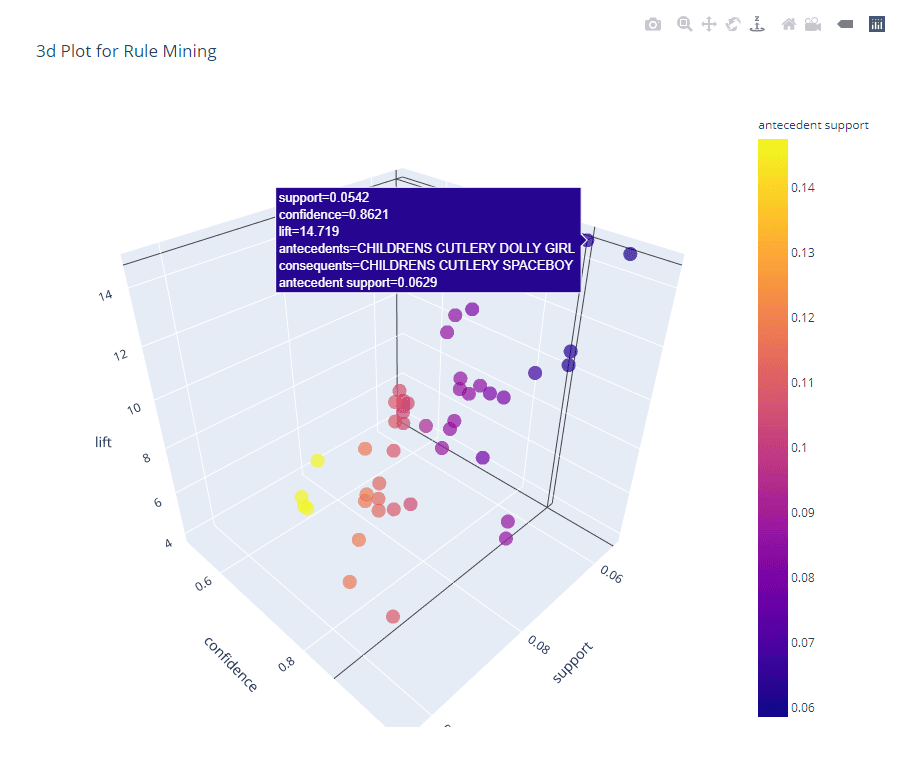
# 3d plot
plot_model(arules, plot = '3d')
```Consulte el Cuaderno completo para seguirnos.
Conclusión
La minería de reglas de asociación es una valiosa herramienta para el análisis de datos y una potente técnica para descubrir patrones y relaciones en los datos. En Python y R, hay varias bibliotecas disponibles para implementar la minería de reglas de asociación que proporcionan una implementación lista para usar de varios algoritmos, así como opciones para visualizar los resultados.
Puede utilizar la minería de reglas de asociación en múltiples contextos para extraer información y comprender la estructura subyacente de los datos. Sin embargo, es importante elegir el algoritmo adecuado y establecer los parámetros correctos, como los umbrales mínimos de apoyo y confianza, para obtener resultados significativos y precisos.
Si desea profundizar en este tema y aprender más sobre minería de reglas de asociación, puede consultar los siguientes cursos:
