A mineração de regras de associação é uma técnica usada para descobrir relações ocultas entre variáveis em grandes conjuntos de dados. É um método popular em mineração de dados e aprendizado de máquina e tem uma ampla gama de aplicações em vários campos, como análise de cestas de mercado, segmentação de clientes e detecção de fraudes.
Neste artigo, exploraremos a mineração de regras de associação em Python, incluindo seus casos de uso, algoritmos e implementação. Começaremos com uma breve visão geral da mineração de regras de associação e suas aplicações e, em seguida, nos aprofundaremos nos detalhes dos algoritmos e de sua implementação em Python. Por fim, concluiremos com um resumo dos principais pontos abordados neste artigo.
O que é mineração de regras de associação?
A mineração de regras de associação é uma técnica usada para identificar padrões em grandes conjuntos de dados. Envolve encontrar relações entre variáveis nos dados e usar essas relações para fazer previsões ou tomar decisões. O objetivo da mineração de regras de associação é descobrir regras que descrevam as relações entre diferentes itens no conjunto de dados.
Por exemplo, considere um conjunto de dados de transações em uma mercearia. A mineração de regras de associação pode ser usada para identificar relacionamentos entre itens que são frequentemente comprados juntos. Por exemplo, a regra "Se um cliente compra pão, é provável que ele também compre leite" é uma regra de associação que pode ser extraída desse conjunto de dados. Podemos usar essas regras para informar decisões sobre o layout da loja, a colocação de produtos e os esforços de marketing.
Normalmente, a mineração de regras de associação envolve o uso de algoritmos para analisar os dados e identificar as relações. Esses algoritmos podem ser baseados em métodos estatísticos ou técnicas de aprendizado de máquina. As regras resultantes geralmente são expressas na forma de declarações "se-então", em que a parte "se" representa o antecedente (a condição que está sendo testada) e a parte "então" representa o consequente (o resultado que ocorre se a condição for atendida).
A mineração de regras de associação é uma técnica importante na análise de dados porque permite que os usuários descubram padrões ou relacionamentos dentro dos dados que podem não ser imediatamente aparentes. Ao identificar associações entre variáveis, a mineração de regras de associação pode ajudar os usuários a entender as relações entre diferentes variáveis e como essas variáveis podem estar relacionadas umas às outras.
Isso pode ser útil para várias finalidades, como a identificação de tendências de mercado, a detecção de atividades fraudulentas ou a compreensão do comportamento do cliente. A mineração de regras de associação também pode ser usada como um trampolim para outros tipos de análise de dados, como a previsão de resultados ou a identificação dos principais fatores de determinados fenômenos. Em geral, a mineração de regras de associação é uma ferramenta valiosa para extrair insights e compreender a estrutura subjacente dos dados.
Casos de uso da mineração de regras de associação:
A mineração de regras de associação é comumente usada em uma variedade de aplicativos, alguns dos quais são comuns:
Análise da cesta de mercado
Uma das aplicações mais conhecidas da mineração de regras de associação é a análise de cestas de mercado. Isso envolve a análise dos itens que os clientes compram juntos para entender seus hábitos e preferências de compra.
Por exemplo, um varejista pode usar a mineração de regras de associação para descobrir que os clientes que compram fraldas provavelmente também comprarão leite em pó para bebês. Podemos usar essas informações para otimizar a colocação de produtos e promoções para aumentar as vendas.
Para saber mais sobre a análise de cesta de mercado, confira nosso tutorial Análise de cesta de mercado em R.
Segmentação de clientes
A mineração de regras de associação também pode ser usada para segmentar clientes com base em seus hábitos de compra.
Por exemplo, uma empresa pode usar a mineração de regras de associação para descobrir que os clientes que compram determinados tipos de produtos têm maior probabilidade de serem mais jovens. Da mesma forma, eles poderiam saber que os clientes que compram determinadas combinações de produtos têm maior probabilidade de estar localizados em regiões geográficas específicas.
Podemos usar essas informações para adaptar campanhas de marketing e recomendações personalizadas a segmentos específicos de clientes. Saiba mais sobre esse tópico em nosso tutorial de introdução à segmentação de clientes em Python.
Detecção de fraudes
Você também pode usar a mineração de regras de associação para detectar atividades fraudulentas. Por exemplo, uma empresa de cartão de crédito pode usar a mineração de regras de associação para identificar padrões de transações fraudulentas, como várias compras do mesmo comerciante em um curto período de tempo.
Podemos então usar essas informações para sinalizar atividades potencialmente fraudulentas e tomar medidas preventivas para proteger os clientes. Em nosso site Data Science in Banking: Fraud Detection, você pode saber mais sobre como o processo funciona.
Análise de redes sociais
Várias empresas usam a mineração de regras de associação para identificar padrões em dados de mídia social que podem informar a análise de redes sociais.
Por exemplo, uma análise dos dados do Twitter pode revelar que os usuários que twittam sobre um determinado tópico provavelmente também twittam sobre outros tópicos relacionados, o que poderia informar a identificação de grupos ou comunidades dentro da rede.
Sistemas de recomendação
A mineração de regras de associação pode ser usada para sugerir itens nos quais um cliente pode estar interessado com base em suas compras anteriores ou histórico de navegação. Por exemplo, um serviço de streaming de música pode usar a mineração de regras de associação para recomendar novos artistas ou álbuns a um usuário com base em seu histórico de audição.
Com nosso tutorial sobre sistemas de recomendação em Python, você pode aprender mais sobre como criar vários modelos que executam essa função.
Algoritmos de mineração de regras de associação
Há vários algoritmos usados para a mineração de regras de associação. Alguns dos mais comuns são:
Algoritmo Apriori
O algoritmo Apriori é um dos algoritmos mais amplamente usados para mineração de regras de associação. Ele funciona identificando primeiro os conjuntos de itens frequentes no conjunto de dados (conjuntos de itens que aparecem em um determinado número de transações). Em seguida, ele usa esses conjuntos de itens frequentes para gerar regras de associação, que são declarações do tipo "se o item A for comprado, é provável que o item B também seja comprado". O algoritmo Apriori usa uma abordagem de baixo para cima, começando com itens individuais e aumentando gradualmente até chegar a conjuntos de itens mais complexos.
Algoritmo FP-Growth
O algoritmo FP-Growth (Frequent Pattern Growth) é outro algoritmo popular para mineração de regras de associação. Ele funciona por meio da construção de uma estrutura semelhante a uma árvore, chamada de árvore FP, que codifica os conjuntos de itens frequentes no conjunto de dados. A árvore FP é então usada para gerar regras de associação de maneira semelhante ao algoritmo Apriori. Em geral, o algoritmo FP-Growth é mais rápido do que o algoritmo Apriori, especialmente para grandes conjuntos de dados.
Algoritmo ECLAT
O algoritmo ECLAT (Equivalence Class Clustering and bottom-up Lattice Traversal) é uma variação do algoritmo Apriori que usa uma abordagem de cima para baixo em vez de uma abordagem de baixo para cima. Ele funciona dividindo os itens em classes de equivalência com base em seu suporte (o número de transações em que eles aparecem). As regras de associação são então geradas pela combinação dessas classes de equivalência em uma estrutura semelhante a uma rede. É uma versão mais eficiente e dimensionável do algoritmo Apriori.
Algoritmo Apriori
O algoritmo apriori se tornou um dos algoritmos mais amplamente usados para mineração de conjuntos de itens frequentes e aprendizado de regras de associação. Ele foi aplicado a uma variedade de aplicativos, incluindo análise de cestas de mercado, sistemas de recomendação e detecção de fraudes, e inspirou o desenvolvimento de muitos outros algoritmos para tarefas semelhantes.
Detalhes do algoritmo
O algoritmo apriori começa definindo o limite mínimo de suporte. Esse é o número mínimo de vezes que um item deve ocorrer no banco de dados para que ele seja considerado um conjunto de itens frequentes. Em seguida, o algoritmo filtra todos os conjuntos de itens candidatos que não atendem ao limite mínimo de suporte.
Em seguida, o algoritmo gera uma lista de todas as combinações possíveis de conjuntos de itens frequentes e conta o número de vezes que cada combinação aparece no banco de dados. Em seguida, o algoritmo gera uma lista de regras de associação com base nas combinações de conjuntos de itens frequentes.
Uma regra de associação é uma declaração do tipo "se o item A estiver presente em uma transação, então é provável que o item B também esteja presente". A força da associação é medida por meio da confiança da regra, que é a probabilidade de o item B estar presente se o item A estiver presente.
Em seguida, o algoritmo filtra todas as regras de associação que não atendem a um limite mínimo de confiança. Essas regras são chamadas de regras de associação fortes. Por fim, o algoritmo retorna a lista de regras de associação fortes como saída.
O Apriori usa uma abordagem "de baixo para cima", começando com itens individuais e combinando-os gradualmente em conjuntos de itens cada vez maiores à medida que busca padrões frequentes. Ele também usa uma abordagem de "exclusão de rótulo" para reduzir com eficiência o espaço de pesquisa, eliminando da consideração os conjuntos de itens pouco frequentes.
Prós:
- O Apriori é relativamente simples e fácil de entender.
- Ele identifica com eficácia padrões frequentes e regras de associação em grandes conjuntos de dados.
- Ele é eficiente na poda do espaço de pesquisa, eliminando conjuntos de itens infrequentes da consideração, reduzindo a complexidade computacional do algoritmo.
- Ele tem sido amplamente usado e testado em várias aplicações, o que o torna um algoritmo bem estabelecido e confiável.
Contras:
- O Apriori não é adequado para conjuntos de dados muito grandes, pois a complexidade computacional do algoritmo aumenta exponencialmente com o tamanho do conjunto de dados.
- Ele pode não ser tão eficaz na identificação de padrões em conjuntos de dados com muitos itens raros ou transações pouco frequentes.
- Ele é sensível aos limites de suporte mínimo e confiança mínima, o que pode afetar a qualidade dos resultados.
- Ele pode ser propenso a gerar um grande número de regras de associação, o que pode dificultar a interpretação dos resultados.
Para se aprofundar no algoritmo Apriori, confira este incrível tutorial de análise de cesta de mercado no DataCamp.
Métricas para avaliação de regras de associação
Na mineração de regras de associação, várias métricas são comumente usadas para avaliar a qualidade e a importância das regras de associação descobertas.
Essas métricas podem ser usadas para avaliar a qualidade e a importância das regras de associação e para selecionar as regras mais relevantes para um determinado aplicativo. É importante observar que a escolha apropriada da métrica dependerá dos objetivos e requisitos específicos do aplicativo.
Para interpretar os resultados das métricas de mineração de regras de associação, é necessário compreender o significado e as implicações de cada métrica, além de saber como usá-las para avaliar a qualidade e a importância das regras de associação descobertas. Aqui estão algumas diretrizes para interpretar os resultados das principais métricas de mineração de regras de associação:
Suporte
O suporte é uma medida da frequência com que um item ou conjunto de itens aparece no conjunto de dados. É calculado como o número de transações que contêm o(s) item(ns) dividido pelo número total de transações no conjunto de dados. O suporte alto indica que um item ou conjunto de itens é comum no conjunto de dados, enquanto o suporte baixo indica que ele é raro.
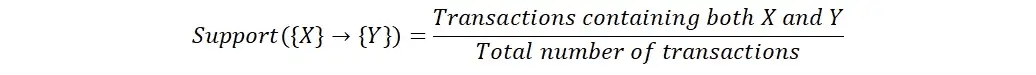
Confiança
A confiança é uma medida da força da associação entre dois itens. É calculado como o número de transações que contêm ambos os itens dividido pelo número de transações que contêm o primeiro item. A alta confiança indica que a presença do primeiro item é um forte indicador da presença do segundo item.
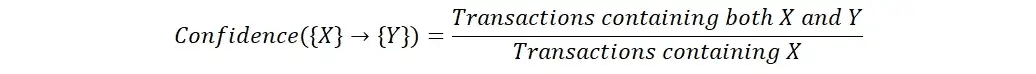
Elevador
Lift é uma medida da força da associação entre dois itens, levando em conta a frequência de ambos os itens no conjunto de dados. Ele é calculado como a confiança da associação dividida pelo suporte do segundo item. O Lift é usado para comparar a força da associação entre dois itens com a força esperada da associação se os itens fossem independentes.
Um valor de elevação maior que 1 indica que a associação entre dois itens é mais forte do que o esperado com base na frequência dos itens individuais. Isso sugere que a associação pode ser significativa e merece uma investigação mais aprofundada. Um valor de elevação menor que 1 indica que a associação é mais fraca do que o esperado e pode ser menos confiável ou menos significativa.

Bibliotecas Python e R para mineração de regras de associação
Há várias bibliotecas em R e Python que podem ser usadas para mineração de regras de associação:
Bibliotecas R
- Regras: Este é um pacote para minerar regras de associação e conjuntos de itens frequentes no R. Ele fornece funções para leitura e manipulação de dados transacionais, bem como para gerar regras de associação e avaliar sua qualidade.
- arulesViz: Este é um pacote para visualizar regras de associação e conjuntos de itens frequentes no R. Ele fornece funções para criar gráficos para ajudar a entender e interpretar os resultados da mineração de regras de associação.
- arulesSequences: Este é um pacote para minerar regras de associação a partir de dados sequenciais no R. Ele fornece funções para leitura e manipulação de dados sequenciais, bem como para gerar regras de associação e avaliar sua qualidade.
Bibliotecas Python
- apyori: Esta é uma biblioteca para implementar o algoritmo Apriori em Python. Ele fornece funções para leitura e manipulação de dados transacionais, bem como para geração de regras de associação e avaliação de sua qualidade.
- mlxtend: Esta é uma biblioteca para implementar vários algoritmos e ferramentas de aprendizado de máquina em Python, incluindo mineração de regras de associação. Ele fornece funções para leitura e manipulação de dados transacionais, bem como para geração de regras de associação e avaliação de sua qualidade.
- PyCaret: PyCaret é uma biblioteca de aprendizado de máquina de código aberto e de baixo código em Python para automatizar fluxos de trabalho de aprendizado de máquina. Ele fornece um wrapper sobre o mlxtend para facilitar a implementação do algoritmo Apriori.
Implementação de regras de associação em Python
Usaremos o PyCaret para implementar regras de associação em Python. Vamos começar instalando o PyCaret e, em seguida, importando o conjunto de dados de amostra.
Instalar o PyCaret
Você pode instalar o pycaret usando o pip.
```
# install pycaret
pip install pycaret
```Conjunto de dados
Começaremos carregando um conjunto de dados de amostra do repositório do pycaret. Trata-se de um conjunto de dados transacionais de uma das lojas de varejo da França. Ele tem o número da fatura para identificar a transação e a descrição do item. Essas são as duas únicas coisas com as quais nos preocupamos ao extrair regras desse conjunto de dados.
```
# load sample data
from pycaret.datasets import get_data
data = get_data('france')
```
Configuração
A primeira etapa é importar o módulo `arules` e inicializar a função `setup` definindo data, transaction_id e item_id.
```
# init setup
from pycaret.arules import *
s = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
```
Saída da função de configuração
Criar modelo
```
The `create_model` function runs the algorithm and return the rules in pandas DataFrame based on the selection parameters defined in the `create_model`. In this example we have used selection metric `confidence` with threshold and support of 0.5.
# train model
arules = create_model(metric='confidence', threshold=0.5, min_support=0.05)
```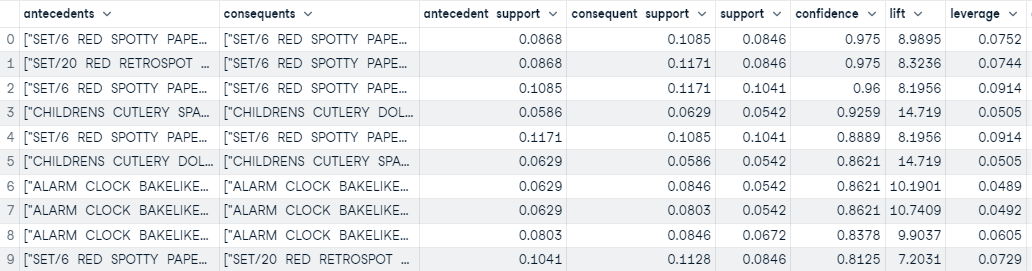
Saída da função create_model
Com base no limite definido nas funções `create_model`, criamos 45 regras. O resultado acima contém os 10 primeiros classificados com base na confiança (da maior para a menor).
Regras do enredo
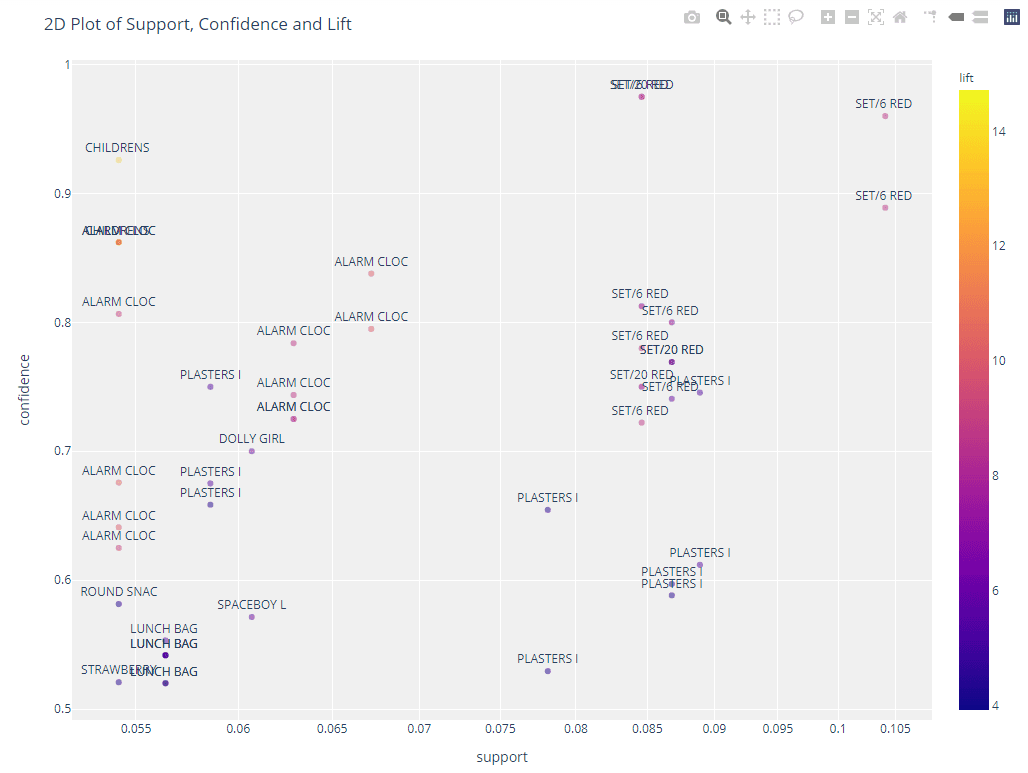
Visualize e analise regras usando a função `plot_model` no PyCaret.
```
# 2d plot
plot_model(arules, plot = '2d')
```
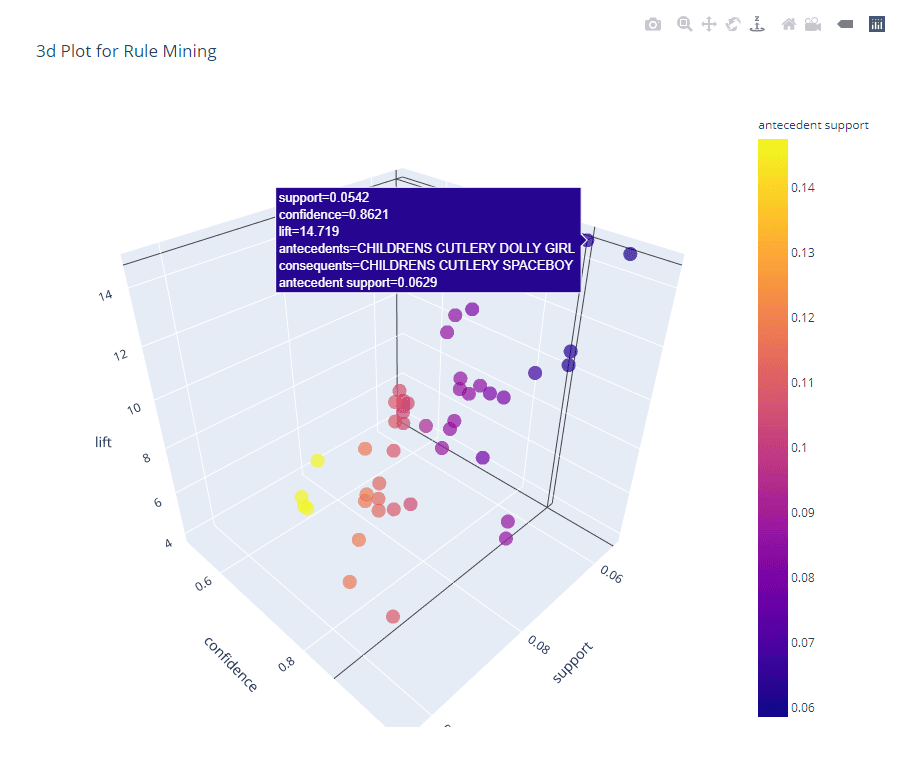
```
# 3d plot
plot_model(arules, plot = '3d')
```Confira o Notebook completo para acompanhar o processo.
Conclusão
A mineração de regras de associação é uma ferramenta valiosa para a análise de dados e uma técnica poderosa para descobrir padrões e relacionamentos nos dados. No Python e no R, há várias bibliotecas disponíveis para implementar a mineração de regras de associação, que fornecem uma implementação pronta para uso de vários algoritmos, bem como opções para visualizar os resultados.
Você pode usar a mineração de regras de associação em vários contextos para extrair insights e entender a estrutura subjacente dos dados. No entanto, é importante escolher o algoritmo adequado e definir os parâmetros corretos, como o suporte mínimo e os limites de confiança, para obter resultados significativos e precisos.
Se quiser se aprofundar nesse tópico e saber mais sobre mineração de regras de associação, você pode conferir os seguintes cursos:

