L'extraction de règles d'association est une technique utilisée pour découvrir des relations cachées entre des variables dans de grands ensembles de données. Il s'agit d'une méthode populaire dans le domaine de l'exploration de données et de l'apprentissage automatique, qui trouve un large éventail d'applications dans divers domaines, tels que l'analyse du panier de la ménagère, la segmentation de la clientèle et la détection des fraudes.
Dans cet article, nous allons explorer l'exploration des règles d'association en Python, notamment ses cas d'utilisation, ses algorithmes et sa mise en œuvre. Nous commencerons par un bref aperçu de l'extraction de règles d'association et de ses applications, puis nous nous plongerons dans les détails des algorithmes et de leur implémentation en Python. Enfin, nous conclurons par un résumé des points clés abordés dans cet article.
Qu'est-ce que l'extraction de règles d'association ?
L'extraction de règles d'association est une technique utilisée pour identifier des modèles dans de grands ensembles de données. Il s'agit de trouver des relations entre les variables des données et d'utiliser ces relations pour faire des prédictions ou prendre des décisions. L'objectif de l'extraction de règles d'association est de découvrir les règles qui décrivent les relations entre les différents éléments de l'ensemble de données.
Prenons l'exemple d'un ensemble de données relatives à des transactions effectuées dans une épicerie. L'extraction de règles d'association pourrait être utilisée pour identifier les relations entre les articles qui sont fréquemment achetés ensemble. Par exemple, la règle "Si un client achète du pain, il est également susceptible d'acheter du lait" est une règle d'association qui pourrait être extraite de cet ensemble de données. Nous pouvons utiliser ces règles pour prendre des décisions concernant l'agencement des magasins, l'emplacement des produits et les efforts de marketing.
L'extraction de règles d'association implique généralement l'utilisation d'algorithmes pour analyser les données et identifier les relations. Ces algorithmes peuvent être basés sur des méthodes statistiques ou des techniques d'apprentissage automatique. Les règles qui en résultent sont souvent exprimées sous la forme d'énoncés "si-alors", où la partie "si" représente l'antécédent (la condition testée) et la partie "alors" représente le conséquent (le résultat qui se produit si la condition est remplie).
L'extraction de règles d'association est une technique importante dans l'analyse des données car elle permet aux utilisateurs de découvrir des schémas ou des relations dans les données qui ne sont pas toujours immédiatement apparents. En identifiant les associations entre les variables, l'extraction de règles d'association peut aider les utilisateurs à comprendre les relations entre différentes variables et la manière dont ces variables peuvent être liées les unes aux autres.
Cela peut être utile à diverses fins, telles que l'identification des tendances du marché, la détection des activités frauduleuses ou la compréhension du comportement des clients. L'extraction de règles d'association peut également servir de tremplin pour d'autres types d'analyse de données, comme la prédiction de résultats ou l'identification des facteurs clés de certains phénomènes. Dans l'ensemble, l'extraction de règles d'association est un outil précieux pour extraire des informations et comprendre la structure sous-jacente des données.
Cas d'utilisation de l'extraction de règles d'association :
L'extraction de règles d'association est couramment utilisée dans une variété d'applications, dont certaines sont courantes :
Analyse du panier de la ménagère
L'une des applications les plus connues de l'extraction de règles d'association est l'analyse du panier de la ménagère. Il s'agit d'analyser les articles que les clients achètent ensemble pour comprendre leurs habitudes d'achat et leurs préférences.
Par exemple, un détaillant peut utiliser l'extraction de règles d'association pour découvrir que les clients qui achètent des couches sont également susceptibles d'acheter du lait maternisé. Nous pouvons utiliser ces informations pour optimiser le placement des produits et les promotions afin d'augmenter les ventes.
Pour en savoir plus sur l'analyse de panier de marché, consultez notre tutoriel sur l'analyse de panier de marché dans R.
Segmentation de la clientèle
L'extraction de règles d'association peut également être utilisée pour segmenter les clients en fonction de leurs habitudes d'achat.
Par exemple, une entreprise peut utiliser l'extraction de règles d'association pour découvrir que les clients qui achètent certains types de produits sont plus susceptibles d'être jeunes. De même, ils pourraient apprendre que les clients qui achètent certaines combinaisons de produits sont plus susceptibles d'être situés dans des régions géographiques spécifiques.
Nous pouvons utiliser ces informations pour adapter les campagnes de marketing et les recommandations personnalisées à des segments de clientèle spécifiques. Découvrez plus d'informations sur ce sujet dans notre tutoriel d'introduction à la segmentation des clients en Python.
Détection de la fraude
Vous pouvez également utiliser l'extraction de règles d'association pour détecter les activités frauduleuses. Par exemple, une société de cartes de crédit peut utiliser l'extraction de règles d'association pour identifier des schémas de transactions frauduleuses, tels que des achats multiples auprès du même commerçant dans un court laps de temps.
Nous pouvons alors utiliser ces informations pour signaler des activités potentiellement frauduleuses et prendre des mesures préventives pour protéger les clients. Dans notre site Data Sciece in Banking : Le blog Fraud Detection vous permet d'en savoir plus sur le fonctionnement du processus.
Analyse des réseaux sociaux
Plusieurs entreprises utilisent l'extraction de règles d'association pour identifier des modèles dans les données des médias sociaux qui peuvent servir à l'analyse des réseaux sociaux.
Par exemple, une analyse des données de Twitter pourrait révéler que les utilisateurs qui tweetent sur un sujet particulier sont également susceptibles de tweeter sur d'autres sujets connexes, ce qui pourrait permettre d'identifier des groupes ou des communautés au sein du réseau.
Systèmes de recommandation
L'extraction de règles d'association peut être utilisée pour suggérer des articles susceptibles d'intéresser un client en fonction de ses achats antérieurs ou de son historique de navigation. Par exemple, un service de streaming musical peut utiliser l'extraction de règles d'association pour recommander de nouveaux artistes ou albums à un utilisateur en fonction de son historique d'écoute.
Grâce à notre tutoriel sur les systèmes de recommandation en Python, vous pouvez en savoir plus sur la façon de construire différents modèles qui remplissent cette fonction.
Algorithmes d'extraction de règles d'association
Plusieurs algorithmes sont utilisés pour l'extraction de règles d'association. Parmi les plus courantes, citons
Algorithme Apriori
L'algorithme Apriori est l'un des algorithmes les plus utilisés pour l'extraction de règles d'association. Pour ce faire, il faut d'abord identifier les éléments fréquents de l'ensemble de données (éléments qui apparaissent dans un certain nombre de transactions). Il utilise ensuite ces ensembles fréquents pour générer des règles d'association, qui sont des énoncés de la forme "si l'article A est acheté, alors l'article B est également susceptible d'être acheté". L'algorithme Apriori utilise une approche ascendante, en commençant par des éléments individuels et en construisant progressivement des ensembles plus complexes.
Algorithme FP-Growth
L'algorithme FP-Growth (Frequent Pattern Growth) est un autre algorithme populaire pour l'extraction de règles d'association. Il s'agit de construire une structure arborescente appelée FP-tree, qui codifie les éléments fréquents de l'ensemble de données. L'arbre FP est ensuite utilisé pour générer des règles d'association de manière similaire à l'algorithme Apriori. L'algorithme FP-Growth est généralement plus rapide que l'algorithme Apriori, en particulier pour les grands ensembles de données.
Algorithme ECLAT
L'algorithme ECLAT (Equivalence Class Clustering and bottom-up Lattice Traversal) est une variante de l'algorithme Apriori qui utilise une approche descendante plutôt qu'une approche ascendante. Il divise les éléments en classes d'équivalence sur la base de leur support (le nombre de transactions dans lesquelles ils apparaissent). Les règles d'association sont ensuite générées en combinant ces classes d'équivalence dans une structure en treillis. Il s'agit d'une version plus efficace et plus évolutive de l'algorithme Apriori.
Algorithme Apriori
L'algorithme apriori est devenu l'un des algorithmes les plus utilisés pour l'extraction d'objets fréquents et l'apprentissage de règles d'association. Il a été appliqué à une variété d'applications, y compris l'analyse du panier de la ménagère, les systèmes de recommandation et la détection de la fraude, et a inspiré le développement de nombreux autres algorithmes pour des tâches similaires.
Détails de l'algorithme
L'algorithme apriori commence par fixer le seuil minimal de soutien. Il s'agit du nombre minimum de fois qu'un élément doit apparaître dans la base de données pour qu'il soit considéré comme un ensemble fréquent. L'algorithme filtre ensuite tous les ensembles candidats qui n'atteignent pas le seuil minimal de soutien.
L'algorithme génère ensuite une liste de toutes les combinaisons possibles d'ensembles fréquents et compte le nombre de fois que chaque combinaison apparaît dans la base de données. L'algorithme génère ensuite une liste de règles d'association basées sur les combinaisons d'items fréquents.
Une règle d'association est une déclaration du type "si l'élément A est présent dans une transaction, alors l'élément B est également susceptible d'y être présent". La force de l'association est mesurée à l'aide de la confiance de la règle, qui est la probabilité que l'élément B soit présent étant donné que l'élément A est présent.
L'algorithme filtre ensuite toutes les règles d'association qui n'atteignent pas un seuil de confiance minimal. Ces règles sont appelées règles d'association fortes. Enfin, l'algorithme renvoie la liste des règles d'association fortes en sortie.
Apriori utilise une approche "ascendante", en commençant par des éléments individuels et en les combinant progressivement pour former des ensembles de plus en plus importants au fur et à mesure qu'il recherche des modèles fréquents. Il utilise également une approche de "suppression-relabel" pour élaguer efficacement l'espace de recherche en éliminant les ensembles d'éléments peu fréquents.
Pour :
- Apriori est relativement simple et facile à comprendre.
- Il identifie efficacement les motifs fréquents et les règles d'association dans les grands ensembles de données.
- Il permet d'élaguer efficacement l'espace de recherche en éliminant les ensembles peu fréquents, ce qui réduit la complexité informatique de l'algorithme.
- Il a été largement utilisé et testé dans diverses applications, ce qui en fait un algorithme bien établi et fiable.
Cons :
- Apriori n'est pas adapté aux très grands ensembles de données, car la complexité informatique de l'algorithme augmente de manière exponentielle avec la taille de l'ensemble de données.
- Il peut ne pas être aussi efficace pour identifier des modèles dans des ensembles de données contenant de nombreux articles rares ou des transactions peu fréquentes.
- Il est sensible aux seuils de soutien minimum et de confiance minimum, ce qui peut affecter la qualité des résultats.
- Il peut être enclin à générer un grand nombre de règles d'association, ce qui peut rendre difficile l'interprétation des résultats.
Pour en savoir plus sur l'algorithme Apriori, consultez ce tutoriel sur l'analyse des paniers de marché sur DataCamp.
Mesures d'évaluation des règles d'association
Dans l'extraction de règles d'association, plusieurs mesures sont couramment utilisées pour évaluer la qualité et l'importance des règles d'association découvertes.
Ces mesures peuvent être utilisées pour évaluer la qualité et l'importance des règles d'association et pour sélectionner les règles les plus pertinentes pour une application donnée. Il est important de noter que le choix approprié de la métrique dépendra des objectifs et des exigences spécifiques de l'application.
L'interprétation des résultats des métriques d'extraction de règles d'association nécessite de comprendre la signification et les implications de chaque métrique, ainsi que la manière de les utiliser pour évaluer la qualité et l'importance des règles d'association découvertes. Voici quelques conseils pour interpréter les résultats des principales métriques d'extraction de règles d'association :
Soutien
Le soutien est une mesure de la fréquence d'apparition d'un élément ou d'un ensemble d'éléments dans l'ensemble de données. Il est calculé comme le nombre de transactions contenant le(s) article(s) divisé par le nombre total de transactions dans l'ensemble de données. Un soutien élevé indique qu'un élément ou un ensemble d'éléments est courant dans l'ensemble de données, tandis qu'un soutien faible indique qu'il est rare.
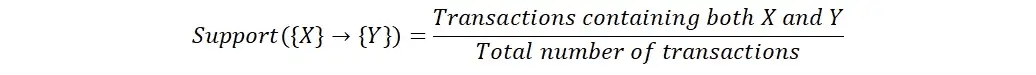
Confiance
La confiance est une mesure de la force de l'association entre deux éléments. Il est calculé comme le nombre de transactions contenant les deux éléments divisé par le nombre de transactions contenant le premier élément. Un niveau de confiance élevé indique que la présence du premier élément est un facteur prédictif important de la présence du second élément.
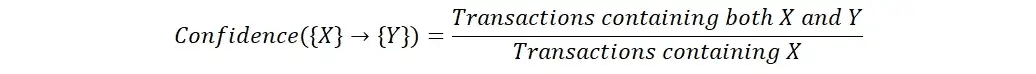
Ascenseur
Lift est une mesure de la force de l'association entre deux éléments, qui tient compte de la fréquence des deux éléments dans l'ensemble de données. Il est calculé comme la confiance de l'association divisée par le soutien du deuxième élément. Lift est utilisé pour comparer la force de l'association entre deux éléments à la force attendue de l'association si les éléments étaient indépendants.
Une valeur de lift supérieure à 1 indique que l'association entre deux éléments est plus forte que prévu sur la base de la fréquence des éléments individuels. Cela suggère que l'association peut être significative et qu'elle mérite d'être étudiée plus en détail. Une valeur de lift inférieure à 1 indique que l'association est plus faible que prévu et peut être moins fiable ou moins significative.

Bibliothèques Python et R pour l'extraction de règles d'association
Il existe plusieurs bibliothèques dans R et Python qui peuvent être utilisées pour l'exploration des règles d'association :
Bibliothèques R
- arules: Il s'agit d'un paquetage pour l'extraction de règles d'association et d'ensembles d'éléments fréquents dans R. Il fournit des fonctions pour lire et manipuler des données transactionnelles, ainsi que pour générer des règles d'association et évaluer leur qualité.
- arulesViz: Il s'agit d'un paquetage permettant de visualiser les règles d'association et les ensembles d'éléments fréquents dans R. Il fournit des fonctions permettant de créer des graphiques et des diagrammes pour aider à comprendre et à interpréter les résultats de l'exploration des règles d'association.
- arulesSequences: Il s'agit d'un paquetage pour l'extraction de règles d'association à partir de données séquentielles dans R. Il fournit des fonctions pour lire et manipuler des données séquentielles, ainsi que pour générer des règles d'association et évaluer leur qualité.
Bibliothèques Python
- apyori: Il s'agit d'une bibliothèque permettant d'implémenter l'algorithme Apriori en Python. Il fournit des fonctions de lecture et de manipulation des données transactionnelles, ainsi que de génération de règles d'association et d'évaluation de leur qualité.
- mlxtend: Il s'agit d'une bibliothèque permettant de mettre en œuvre divers algorithmes et outils d'apprentissage automatique en Python, notamment l'extraction de règles d'association. Il fournit des fonctions de lecture et de manipulation des données transactionnelles, ainsi que de génération de règles d'association et d'évaluation de leur qualité.
- PyCaret: PyCaret est une bibliothèque d'apprentissage automatique open-source et low-code en Python pour automatiser les flux de travail d'apprentissage automatique. Il fournit une enveloppe au-dessus de mlxtend pour faciliter la mise en œuvre de l'algorithme Apriori.
Implémentation de règles d'association en Python
Nous utiliserons PyCaret pour mettre en œuvre les règles d'association en Python. Commençons par installer PyCaret et par importer l'échantillon de données.
Installez PyCaret
Vous pouvez installer pycaret en utilisant pip.
```
# install pycaret
pip install pycaret
```Ensemble de données
Nous commencerons par charger un échantillon de données à partir du dépôt de pycaret. Il s'agit d'un ensemble de données transactionnelles provenant d'un magasin de détail en France. Il comporte un numéro de facture permettant d'identifier la transaction et une description de l'article. Ce sont les deux seules choses qui nous intéressent lors de l'extraction de règles à partir de cet ensemble de données.
```
# load sample data
from pycaret.datasets import get_data
data = get_data('france')
```
Mise en place
La première étape consiste à importer le module `arules` et à initialiser la fonction `setup` en définissant data, transaction_id et item_id.
```
# init setup
from pycaret.arules import *
s = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
```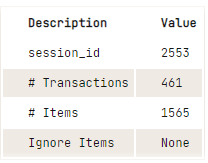
Sortie de la fonction Setup
Créer un modèle
```
The `create_model` function runs the algorithm and return the rules in pandas DataFrame based on the selection parameters defined in the `create_model`. In this example we have used selection metric `confidence` with threshold and support of 0.5.
# train model
arules = create_model(metric='confidence', threshold=0.5, min_support=0.05)
```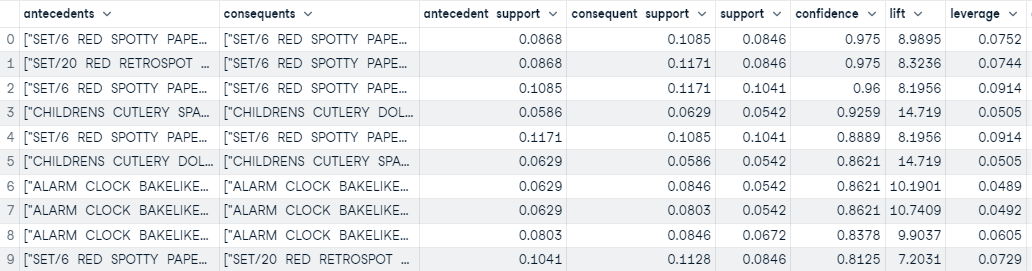
Résultat de la fonction create_model
Sur la base du seuil défini dans les fonctions `create_model`, nous avons créé 45 règles. Le résultat ci-dessus contient les 10 premiers triés en fonction de la confiance (de la plus élevée à la plus faible).
Règles d'intrigue
Visualisez et analysez les règles en utilisant la fonction `plot_model` de PyCaret.
```
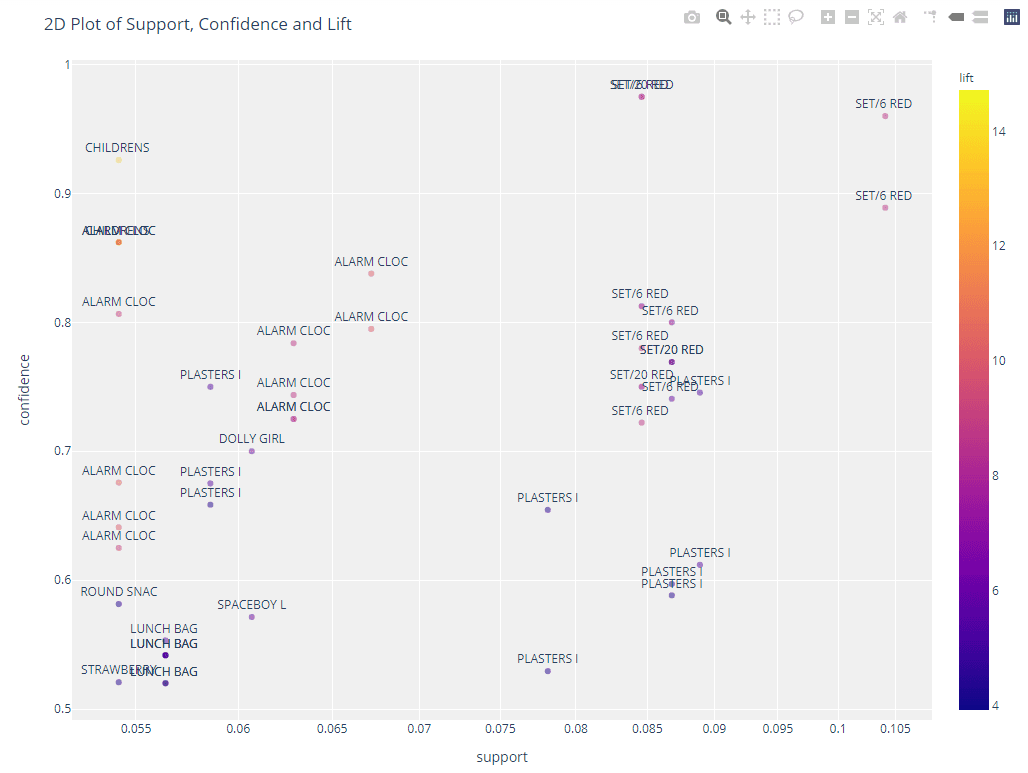
# 2d plot
plot_model(arules, plot = '2d')
```
```
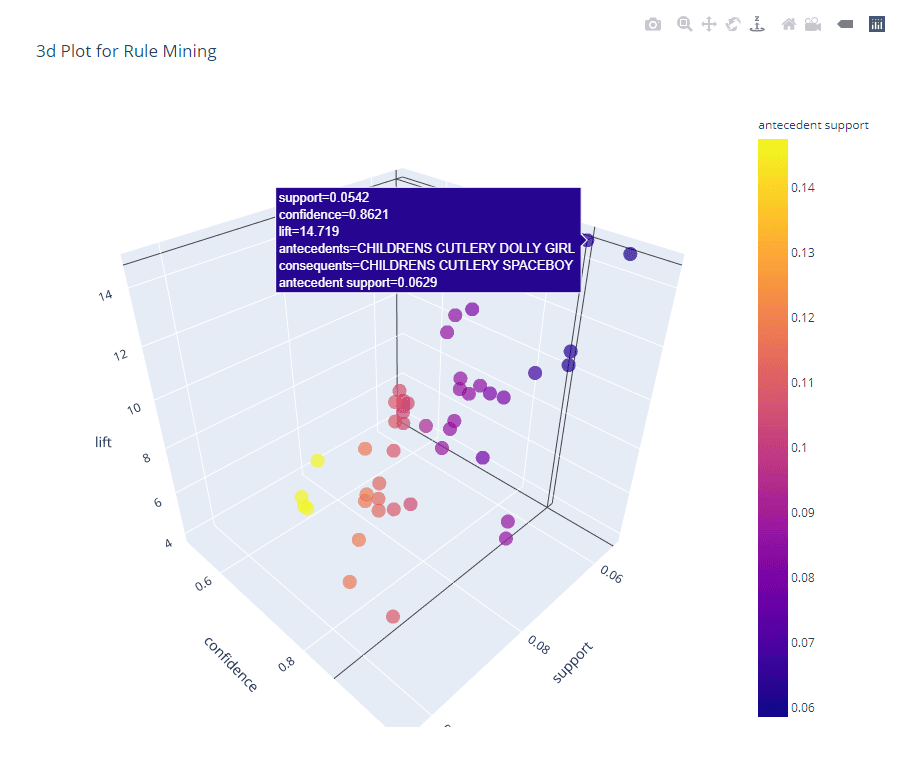
# 3d plot
plot_model(arules, plot = '3d')
```Consultez l'intégralité du carnet de notes pour suivre l'évolution de la situation.
Conclusion
L'extraction de règles d'association est un outil précieux pour l'analyse des données et une technique puissante pour découvrir des modèles et des relations dans les données. Dans Python et R, il existe plusieurs bibliothèques disponibles pour la mise en œuvre de l'exploration des règles d'association qui fournit une implémentation prête à l'emploi pour divers algorithmes ainsi que des options pour la visualisation des résultats.
Vous pouvez utiliser l'extraction de règles d'association dans de multiples contextes pour extraire des informations et comprendre la structure sous-jacente des données. Toutefois, il est important de choisir l'algorithme approprié et de définir les bons paramètres, tels que les seuils minimum de soutien et de confiance, afin d'obtenir des résultats significatifs et précis.
Si vous souhaitez approfondir ce sujet et en savoir plus sur l'extraction de règles d'association, vous pouvez consulter les cours suivants :