Association rule mining is a technique used to uncover hidden relationships between variables in large datasets. It is a popular method in data mining and machine learning and has a wide range of applications in various fields, such as market basket analysis, customer segmentation, and fraud detection.
In this article, we will explore association rule mining in Python, including its use cases, algorithms, and implementation. We will start with a brief overview of association rule mining and its applications and then delve into the details of the algorithms and their implementation in Python. Finally, we will conclude with a summary of the key points covered in this article.
What is Association Rule Mining?
Association rule mining is a technique used to identify patterns in large data sets. It involves finding relationships between variables in the data and using those relationships to make predictions or decisions. The goal of association rule mining is to uncover rules that describe the relationships between different items in the data set.
For example, consider a dataset of transactions at a grocery store. Association rule mining could be used to identify relationships between items that are frequently purchased together. For example, the rule "If a customer buys bread, they are also likely to buy milk" is an association rule that could be mined from this data set. We can use such rules to inform decisions about store layout, product placement, and marketing efforts.
Association rule mining typically involves using algorithms to analyze the data and identify the relationships. These algorithms can be based on statistical methods or machine learning techniques. The resulting rules are often expressed in the form of "if-then" statements, where the "if" part represents the antecedent (the condition being tested) and the "then" part represents the consequent (the outcome that occurs if the condition is met).
Association rule mining is an important technique in data analysis because it allows users to discover patterns or relationships within data that may not be immediately apparent. By identifying associations between variables, association rule mining can help users understand the relationships between different variables and how those variables may be related to one another.
This can be useful for various purposes, such as identifying market trends, detecting fraudulent activity, or understanding customer behavior. Association rule mining can also be used as a stepping stone for other types of data analysis, such as predicting outcomes or identifying key drivers of certain phenomena. Overall, association rule mining is a valuable tool for extracting insights and understanding the underlying structure of data.
Use Cases of Association Rule Mining:
Association rule mining is commonly used in a variety of applications, some common ones are:
Market Basket Analysis
One of the most well-known applications of association rule mining is in market basket analysis. This involves analyzing the items customers purchase together to understand their purchasing habits and preferences.
For example, a retailer might use association rule mining to discover that customers who purchase diapers are also likely to purchase baby formula. We can use this information to optimize product placements and promotions to increase sales.
To learn more about Market Basket Analysis, check out our Market Basket Analysis in R tutorial.
Customer Segmentation
Association rule mining can also be used to segment customers based on their purchasing habits.
For example, a company might use association rule mining to discover that customers who purchase certain types of products are more likely to be younger. Similarly, they could learn that customers who purchase certain combinations of products are more likely to be located in specific geographic regions.
We can use this information to tailor marketing campaigns and personalized recommendations to specific customer segments. Discover more about this topic in our introduction to customer segmentation in Python tutorial.
Fraud Detection
You can also use association rule mining to detect fraudulent activity. For example, a credit card company might use association rule mining to identify patterns of fraudulent transactions, such as multiple purchases from the same merchant within a short period of time.
We can then use this information can to flag potentially fraudulent activity and take preventative measures to protect customers. In our Data Sciece in Banking: Fraud Detection blog, you can learn more about how the process works.
Social network analysis
Various companies use association rule mining to identify patterns in social media data that can inform the analysis of social networks.
For example, an analysis of Twitter data might reveal that users who tweet about a particular topic are also likely to tweet about other related topics, which could inform the identification of groups or communities within the network.
Recommendation systems
Association rule mining can be used to suggest items that a customer might be interested in based on their past purchases or browsing history. For example, a music streaming service might use association rule mining to recommend new artists or albums to a user based on their listening history.
With our recommendation systems in Python tutorial, you can learn more about how to build various models that perform this function.
Association Rule Mining Algorithms
There are several algorithms used for association rule mining. Some common ones are:
Apriori algorithm
The Apriori algorithm is one of the most widely used algorithms for association rule mining. It works by first identifying the frequent itemsets in the dataset (itemsets that appear in a certain number of transactions). It then uses these frequent itemsets to generate association rules, which are statements of the form "if item A is purchased, then item B is also likely to be purchased." The Apriori algorithm uses a bottom-up approach, starting with individual items and gradually building up to more complex itemsets.
FP-Growth algorithm
The FP-Growth (Frequent Pattern Growth) algorithm is another popular algorithm for association rule mining. It works by constructing a tree-like structure called a FP-tree, which encodes the frequent itemsets in the dataset. The FP-tree is then used to generate association rules in a similar manner to the Apriori algorithm. The FP-Growth algorithm is generally faster than the Apriori algorithm, especially for large datasets.
ECLAT algorithm
The ECLAT (Equivalence Class Clustering and bottom-up Lattice Traversal) algorithm is a variation of the Apriori algorithm that uses a top-down approach rather than a bottom-up approach. It works by dividing the items into equivalence classes based on their support (the number of transactions in which they appear). The association rules are then generated by combining these equivalence classes in a lattice-like structure. It is a more efficient and scalable version of the Apriori algorithm.
Apriori Algorithm
The apriori algorithm has become one of the most widely used algorithms for frequent itemset mining and association rule learning. It has been applied to a variety of applications, including market basket analysis, recommendation systems, and fraud detection, and has inspired the development of many other algorithms for similar tasks.
Algorithm Details
The apriori algorithm starts by setting the minimum support threshold. This is the minimum number of times an item must occur in the database in order for it to be considered a frequent itemset. The algorithm then filters out any candidate itemsets that do not meet the minimum support threshold.
The algorithm then generates a list of all possible combinations of frequent itemsets and counts the number of times each combination appears in the database. The algorithm then generates a list of association rules based on the frequent itemset combinations.
An association rule is a statement of the form "if item A is present in a transaction, then item B is also likely to be present". The strength of the association is measured using the confidence of the rule, which is the probability that item B is present given that item A is present.
The algorithm then filters out any association rules that do not meet a minimum confidence threshold. These rules are referred to as strong association rules. Finally, the algorithm then returns the list of strong association rules as output.
Apriori uses a "bottom-up" approach, starting with individual items and gradually combining them into larger and larger itemsets as it searches for frequent patterns. It also uses a "delete-relabel" approach to efficiently prune the search space by eliminating infrequent itemsets from consideration.
Pros:
- Apriori is relatively simple and easy to understand.
- It effectively identifies frequent patterns and association rules in large datasets.
- It is efficient at pruning the search space by eliminating infrequent itemsets from consideration, reducing the algorithm's computational complexity.
- It has been widely used and tested in various applications, making it a well-established and reliable algorithm.
Cons:
- Apriori is not suitable for very large datasets, as the computational complexity of the algorithm increases exponentially with the size of the dataset.
- It may not be as effective at identifying patterns in datasets with many rare items or infrequent transactions.
- It is sensitive to the minimum support and minimum confidence thresholds, which can affect the quality of the results.
- It may be prone to generating a large number of association rules, which can make it difficult to interpret the results.
To take a deeper dive into the Apriori algorithm, check out this amazing Market Basket Analysis tutorial on DataCamp.
Metrics for Evaluating Association Rules
In association rule mining, several metrics are commonly used to evaluate the quality and importance of the discovered association rules.
These metrics can be used to evaluate the quality and importance of association rules and to select the most relevant rules for a given application. It is important to note that the appropriate choice of metric will depend on the specific goals and requirements of the application.
Interpreting the results of association rule mining metrics requires understanding the meaning and implications of each metric, as well as how to use them to evaluate the quality and importance of the discovered association rules. Here are some guidelines for interpreting the results of the main association rule mining metrics:
Support
Support is a measure of how frequently an item or itemset appears in the dataset. It is calculated as the number of transactions containing the item(s) divided by the total number of transactions in the dataset. High support indicates that an item or itemset is common in the dataset, while low support indicates that it is rare.
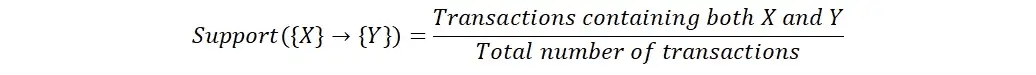
Confidence
Confidence is a measure of the strength of the association between two items. It is calculated as the number of transactions containing both items divided by the number of transactions containing the first item. High confidence indicates that the presence of the first item is a strong predictor of the presence of the second item.
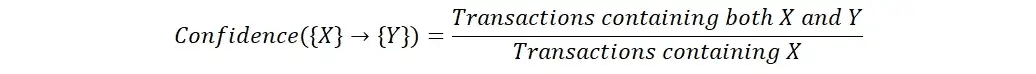
Lift
Lift is a measure of the strength of the association between two items, taking into account the frequency of both items in the dataset. It is calculated as the confidence of the association divided by the support of the second item. Lift is used to compare the strength of the association between two items to the expected strength of the association if the items were independent.
A lift value greater than 1 indicates that the association between two items is stronger than expected based on the frequency of the individual items. This suggests that the association may be meaningful and worth further investigation. A lift value less than 1 indicates that the association is weaker than expected and may be less reliable or less significant.

Python and R Libraries for Association Rule Mining
There are several libraries in R and Python that can be used for association rule mining:
R libraries
- arules: This is a package for mining association rules and frequent itemsets in R. It provides functions for reading and manipulating transactional data, as well as for generating association rules and evaluating their quality.
- arulesViz: This is a package for visualizing association rules and frequent itemsets in R. It provides functions for creating plots and charts to help understand and interpret the results of association rule mining.
- arulesSequences: This is a package for mining association rules from sequential data in R. It provides functions for reading and manipulating sequential data, as well as for generating association rules and evaluating their quality.
Python libraries
- apyori: This is a library for implementing the Apriori algorithm in Python. It provides functions for reading and manipulating transactional data, as well as for generating association rules and evaluating their quality.
- mlxtend: This is a library for implementing various machine learning algorithms and tools in Python, including association rule mining. It provides functions for reading and manipulating transactional data, as well as for generating association rules and evaluating their quality.
- PyCaret: PyCaret is an open-source, low-code machine learning library in Python for automating machine learning workflows. It provides a wrapper on top of mlxtend for easy implementation of the Apriori algorithm.
Implementing Association Rules in Python
We will use PyCaret for implementing association rules in Python. Let’s begin by installing PyCaret and then importing the sample dataset.
Install PyCaret
You can install pycaret using pip.
```
# install pycaret
pip install pycaret
```Dataset
We will start by loading sample dataset from pycaret’s repository. It is a transactional dataset from one of the Retail store in France. It has Invoice number to identify transaction and Description of item. These are the only two things we care about when mining rules from this dataset.
```
# load sample data
from pycaret.datasets import get_data
data = get_data('france')
```
Setup
The first step is to import `arules` module and initialize the `setup` function by defining data, transaction_id, and item_id.
```
# init setup
from pycaret.arules import *
s = setup(data = data, transaction_id = 'InvoiceNo', item_id = 'Description')
```
Output from the setup function
Create Model
```
The `create_model` function runs the algorithm and return the rules in pandas DataFrame based on the selection parameters defined in the `create_model`. In this example we have used selection metric `confidence` with threshold and support of 0.5.
# train model
arules = create_model(metric='confidence', threshold=0.5, min_support=0.05)
```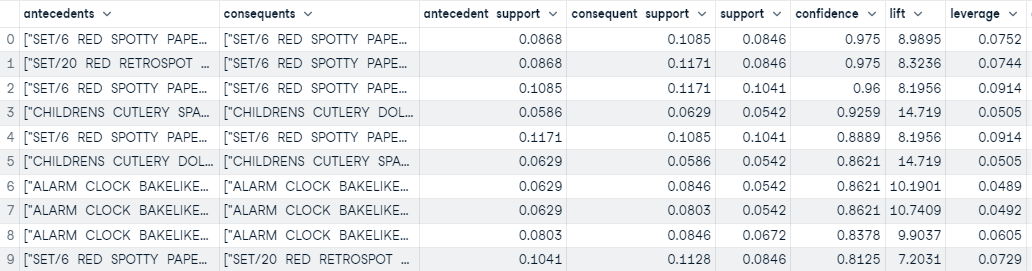
Output from the create_model function
Based on the threshold defined in the `create_model` functions, we have created 45 rules. The output above contains the first 10 sorted based on confidence (highest to lowest).
Plot Rules
Visualize and analyze rules using the `plot_model` function in PyCaret.
```
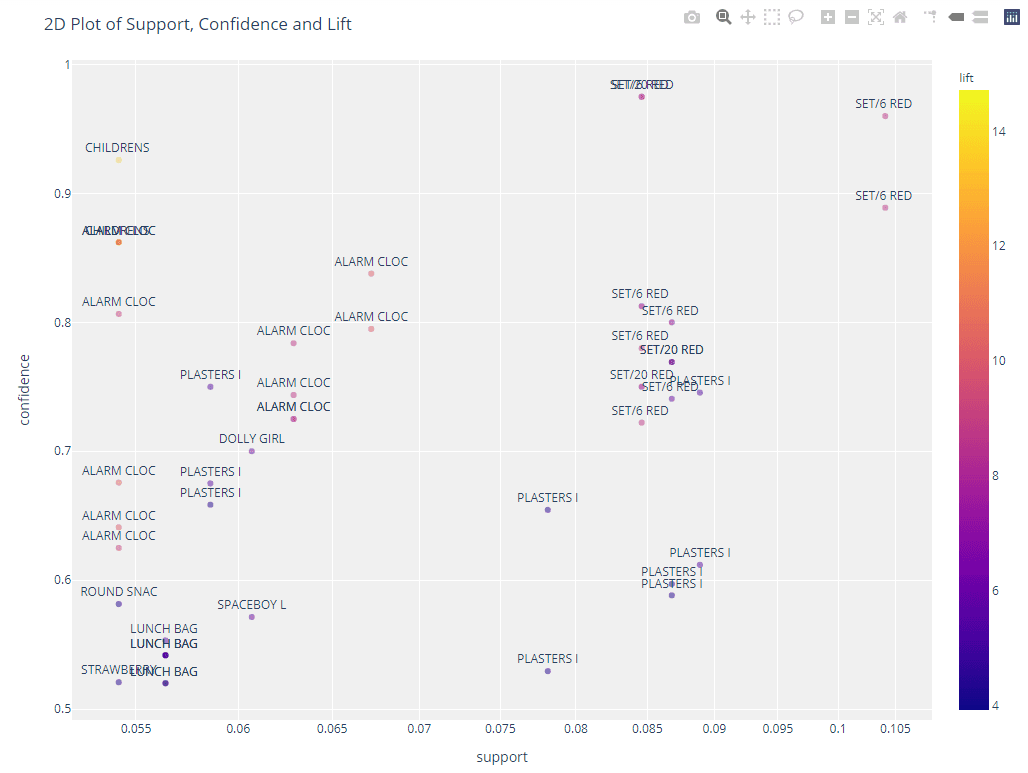
# 2d plot
plot_model(arules, plot = '2d')
```
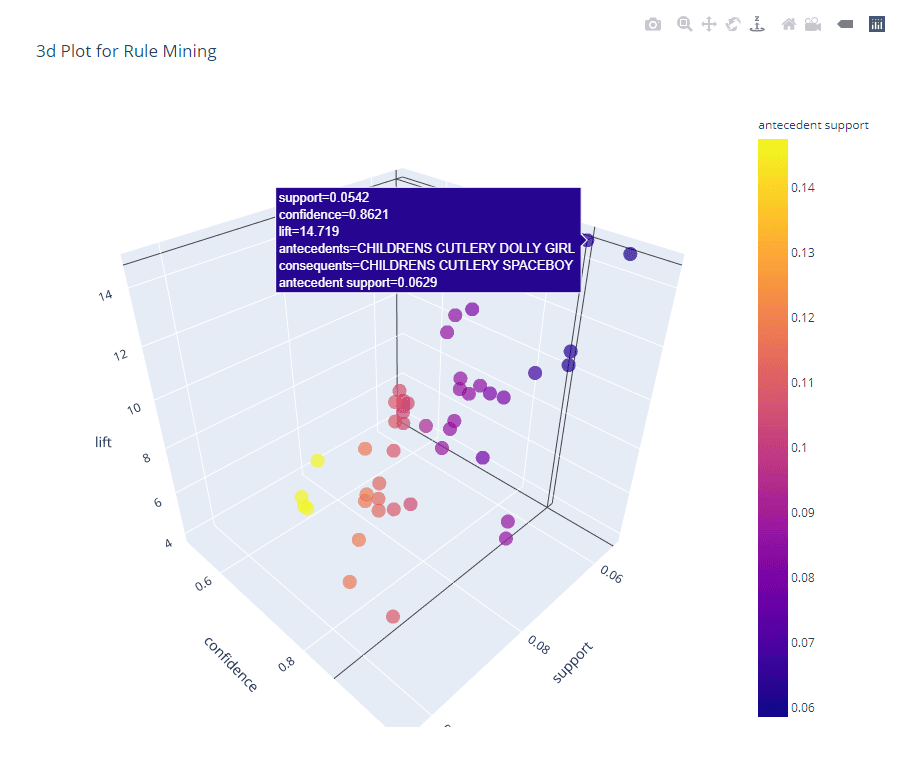
```
# 3d plot
plot_model(arules, plot = '3d')
```Check out the full Notebook to follow along.
Conclusion
Association rule mining is a valuable tool for data analysis and a powerful technique for discovering patterns and relationships within data. In Python and R, there are several libraries available for implementing association rule mining which provides an out-of-box implementation for various algorithms as well as options for visualizing the results.
You can use association rule mining in multiple contexts to extract insights and understand the underlying structure of data. However, it is important to choose the appropriate algorithm and set the right parameters, such as the minimum support and confidence thresholds, to obtain meaningful and accurate results.
If you would like to deep dive into this topic and learn more about association rule mining, you can check out the following courses:

