
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Der AWS Multi-Agent Orchestrator ist ein flexibles, werkzeugreiches Framework zur Verwaltung von KI-Agenten und zur Erleichterung komplexer Multi-Turn-Konversationen. Die vorgefertigten Komponenten ermöglichen eine schnelle Entwicklung und Bereitstellung, sodass wir uns auf unsere Anwendung konzentrieren können, ohne diese Komponenten von Grund auf neu erstellen zu müssen.
Der AWS Multi-Agent Orchestrator bietet die folgenden Funktionen:
Das Framework ist so implementiert, dass es sowohl Python als auch TypeScript unterstützt.
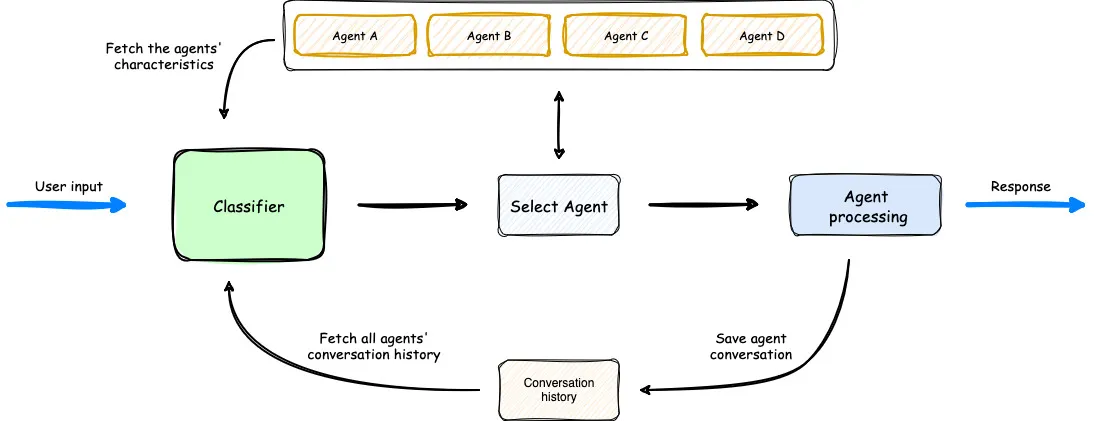
Ein Überblick darüber, wie der Multi-Agent Orchestrator funktioniert. (Quelle)
Im obigen Diagramm sehen wir, dass der Klassifikator die verfügbaren Agenten, die Eingabeaufforderung des Benutzers und den bisherigen Gesprächsverlauf berücksichtigt, um den optimalen Agenten für die Benutzereingabe auszuwählen. Dann bearbeitet der Agent die Anfrage. Der Arbeitsablauf ist einfach, aber effektiv.
Um die Umgebung schnell einzurichten, kannst du die Anweisungen in der Dokumentation folgen.
Zuerst erstellen wir einen neuen Ordner und eine neue Python-Umgebung, um die benötigten Bibliotheken zu installieren.
mkdir test_multi_agent_orchestrator
cd test_multi_agent_orchestrator
python -m venv venv
source venv/bin/activate # On Windows use venv\\Scripts\\activateWenn die neue virtuelle Umgebung aktiviert ist, installiere die Bibliothek
pip install multi-agent-orchestratorAls Nächstes müssen wir unser AWS-Konto konfigurieren. Wenn du noch kein AWS-Konto hast, melde dich kostenlos für ein Free Tier-Konto. Nachdem du dich angemeldet hast, herunterladen. die AWS CLI herunter.
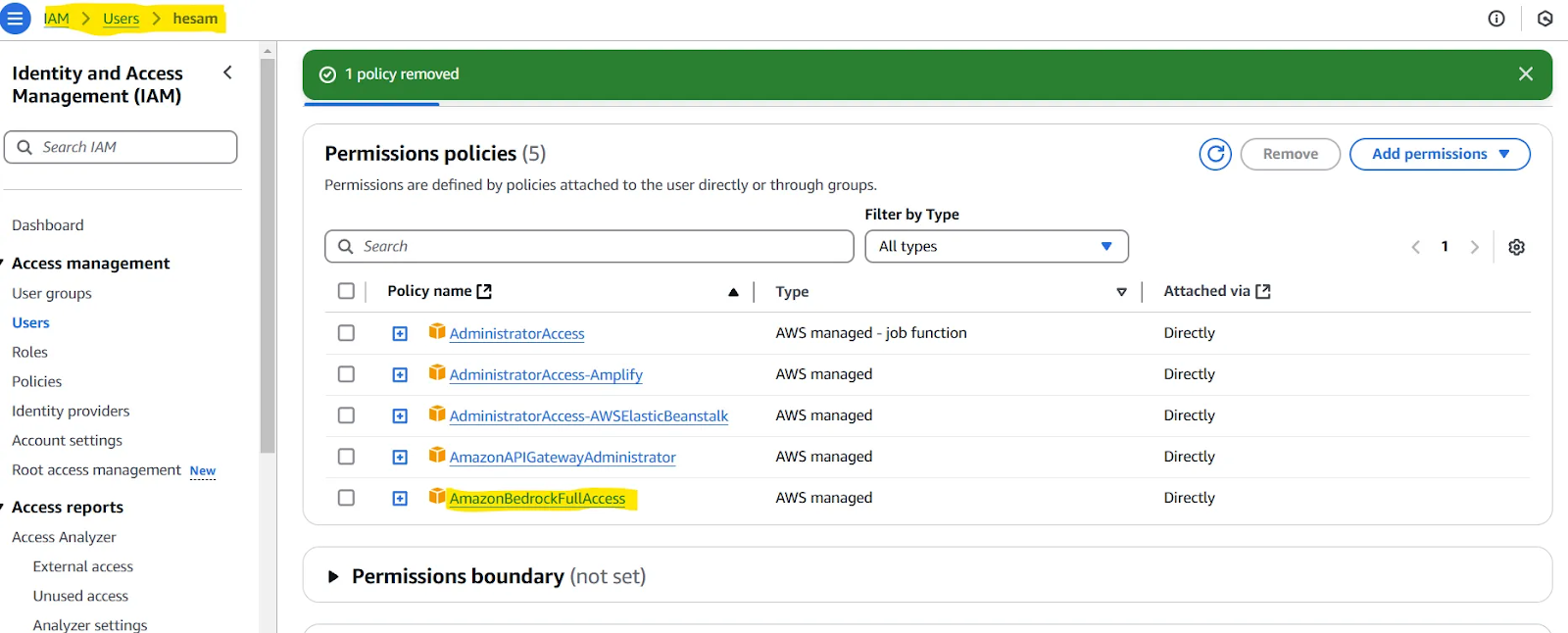
Die AWS CLI muss ebenfalls konfiguriert werden. Detaillierte Anweisungen finden Sie unter Einrichten der AWS CLIaber du kannst es dir auch einfacher machen, indem du den Befehl aws configure verwendest und die AWS-Zugangsschlüssel-ID und den geheimen Zugangsschlüssel angibst. Du erhältst diese Schlüssel, nachdem du einen neuen Benutzer in deinem Dashboard angelegt hast.
Bereitstellung von Zugangsschlüsseln bei der Erstellung eines neuen Benutzers.
Wenn du die Zugangsschlüssel zur Hand hast, führe aws configure aus, gib die Schlüssel ein und wähle den Namen der Region (eine vollständige Liste findest du hier), die dir am nächsten liegt, und setze das Standardausgabeformat auf json.

Wenn deine CLI richtig konfiguriert ist, sollte der Befehl aws sts get-caller-identity deine AWS-Konto-ID, Benutzer-ID und ARN anzeigen.
Jetzt, wo wir die AWS CLI einsatzbereit haben, müssen wir AWS Bedrock so konfigurieren, dass wir Zugriff auf die LLMs haben, die wir brauchen. Amazon Bedrock ist ein Service, mit dem du Basismodelle testen und aufrufen kannst (wie z.B. Llama 3.2 oder Claude 3.5 Sonnet) über eine API aufrufen kannst. Der Multi-Agent Orchestrator nutzt diesen Dienst, um standardmäßig zwei Modelle aufzurufen:
Natürlich können diese Modelle geändert werden, aber lass uns mit der Standardauswahl weitermachen.
Um Zugriff auf diese beiden Modelle zu erhalten, gehe zu Amazon Bedrock > Modellzugriff und wähle "Modify model access". Wähle die beiden Modelle aus (und andere, wenn du möchtest) und gib alle erforderlichen Informationen ein. Dieser Teil wird wie folgt aussehen:
Nach Abschluss der Anfrage sind die Modelle in 1-2 Minuten verfügbar. Wenn der Zugang für die angeforderten Modelle gewährt wird, musst du "Zugang gewährt" vor ihnen sehen.
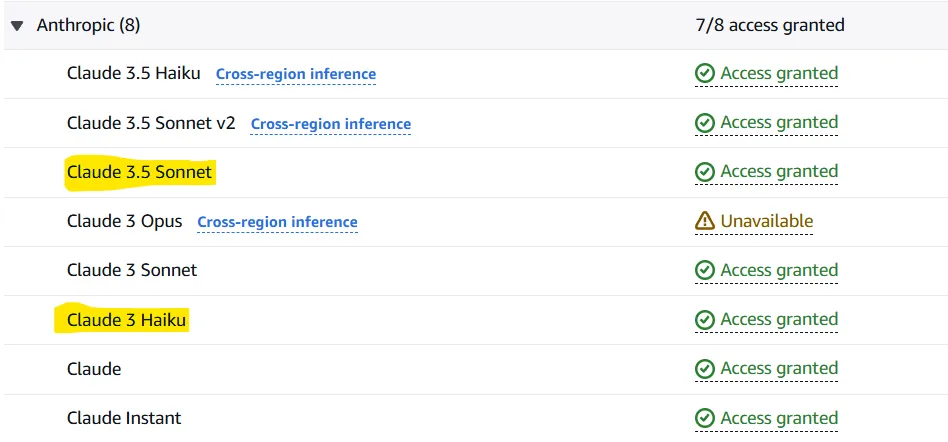
Hinweis: Möglicherweise musst du dem von dir erstellten Benutzer eine Richtlinie zuweisen. Wenn du Probleme hast, kannst du das im nächsten Abschnitt unseres Artikels testen (Teste deine Einrichtung). Wenn ja, dann schau dir diese Seite. Zusammengefasst müsstest du dem Benutzer, den du definiert hast, Zugriff auf AmazonBedrockFullAccess geben.
Um zu überprüfen, ob alle vorherigen Schritte richtig ausgeführt wurden, verwende diesen Code:
import uuid
import asyncio
import json
import sys
from typing import Optional, List, Dict, Any
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.agents import (
BedrockLLMAgent,
BedrockLLMAgentOptions,
AgentResponse,
AgentCallbacks,
)
from multi_agent_orchestrator.types import ConversationMessage, ParticipantRole
orchestrator = MultiAgentOrchestrator(
options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=True,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
)
)
class BedrockLLMAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
# handle response streaming here
print(token, end="", flush=True)
tech_agent = BedrockLLMAgent(
BedrockLLMAgentOptions(
name="Tech Agent",
streaming=True,
description=(
"Specializes in technology areas including software development, hardware, AI, "
"cybersecurity, blockchain, cloud computing, emerging tech innovations, and pricing/costs "
"related to technology products and services."
),
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks(),
)
)
orchestrator.add_agent(tech_agent)
async def handle_request(
_orchestrator: MultiAgentOrchestrator, _user_input: str, _user_id: str, _session_id: str
):
response: AgentResponse = await _orchestrator.route_request(
_user_input, _user_id, _session_id
)
# Print metadata
print("\nMetadata:")
print(f"Selected Agent: {response.metadata.agent_name}")
if response.streaming:
print("Response:", response.output.content[0]["text"])
else:
print("Response:", response.output.content[0]["text"])
if __name__ == "__main__":
USER_ID = "user123"
SESSION_ID = str(uuid.uuid4())
print("Welcome to the interactive Multi-Agent system. Type 'quit' to exit.")
while True:
# Get user input
user_input = input("\nYou: ").strip()
if user_input.lower() == "quit":
print("Exiting the program. Goodbye!")
sys.exit()
# Run the async function
asyncio.run(handle_request(orchestrator, user_input, USER_ID, SESSION_ID))Wenn du eine Anfrage stellen kannst und eine Antwort erhältst, funktioniert alles gut.
Das AWS Multi-Agent Orchestrator Repository bietet mehrere Beispielprojekte in TypeScript und Python. Wir werden nun eine vereinfachte Python-Anwendung schreiben, die aus zwei Agenten besteht: Python Developer Agent und ML Expert Agent.
Wir werden auch Chainlit, ein Open-Source-Paket für Python, verwenden, um eine einfache Benutzeroberfläche für die Anwendung zu implementieren. Installiere zunächst die erforderlichen Bibliotheken:
chainlit==1.2.0
multi_agent_orchestrator==0.0.18Wir verwenden den unten stehenden Code für unsere Demoanwendung, aber lass ihn uns erst einmal erklären:
“anthropic.claude-3-haiku-20240307-v1:0” als Modell für unseren Klassifikator. Dieser Klassifikator wählt aus, welcher Agent verwendet werden soll, wenn eine neue Benutzereingabe eingeht.MultiAgentOrchestrator und definieren einige Konfigurationen.BedrockLLMAgent wird verwendet, um unsere Agenten zu erstellen. Für jedes Mittel gibt es eine name und eine description. Für einen Agenten kannst du eines der zugänglichen Modelle wählen oder sogar Ollama verwenden, um sie lokal zu betreiben. Wenn du streaming=True einstellst und ChainlitAgentCallbacks() als callback übergibst, werden die Agenten die Antworten nicht vollständig, sondern gestreamt zurückgeben. Schließlich fügen wir jeden Agenten zum Orchestrator hinzu.user_session wird eingestellt und der Hauptabschnitt zur Bearbeitung von Benutzer- und Agentennachrichten wird definiert.### 1
import uuid
import chainlit as cl
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.classifiers import BedrockClassifier, BedrockClassifierOptions
from multi_agent_orchestrator.agents import AgentResponse
from multi_agent_orchestrator.agents import BedrockLLMAgent, BedrockLLMAgentOptions, AgentCallbacks
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator
from multi_agent_orchestrator.types import ConversationMessage
import asyncio
import chainlit as cl
class ChainlitAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
asyncio.run(cl.user_session.get("current_msg").stream_token(token))
### 2
# Initialize the orchestrator & classifier
custom_bedrock_classifier = BedrockClassifier(BedrockClassifierOptions(
model_id='anthropic.claude-3-haiku-20240307-v1:0',
inference_config={
'maxTokens': 500,
'temperature': 0.7,
'topP': 0.9
}
))
### 3
orchestrator = MultiAgentOrchestrator(options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=False,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
),
classifier=custom_bedrock_classifier
)
### 4
def create_python_dev():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Python Developer Agent",
streaming=True,
description="Experienced Python developer specialized in writing, debugging, and evaluating only Python code.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
def create_ml_expert():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Machine Learning Expert",
streaming=True,
description="Expert in areas related to machine learning including deep learning, pytorch, tensorflow, scikit-learn, and large language models.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
# Add agents to the orchestrator
orchestrator.add_agent(create_python_dev())
orchestrator.add_agent(create_ml_expert())
### 5
@cl.on_chat_start
async def start():
cl.user_session.set("user_id", str(uuid.uuid4()))
cl.user_session.set("session_id", str(uuid.uuid4()))
cl.user_session.set("chat_history", [])
@cl.on_message
async def main(message: cl.Message):
user_id = cl.user_session.get("user_id")
session_id = cl.user_session.get("session_id")
msg = cl.Message(content="")
await msg.send() # Send the message immediately to start streaming
cl.user_session.set("current_msg", msg)
response:AgentResponse = await orchestrator.route_request(message.content, user_id, session_id, {})
# Handle non-streaming or problematic responses
if isinstance(response, AgentResponse) and response.streaming is False:
# Handle regular response
if isinstance(response.output, str):
await msg.stream_token(response.output)
elif isinstance(response.output, ConversationMessage):
await msg.stream_token(response.output.content[0].get('text'))
await msg.update()
if __name__ == "__main__":
cl.run()Jetzt ist es an der Zeit, die Anwendung zu starten. Um dies zu tun, führe zuerst chainlit run [app.py](<http://app.py/>) -w aus. Du kannst deine Anwendung jetzt in dem neuen Tab in deinem Browser testen.
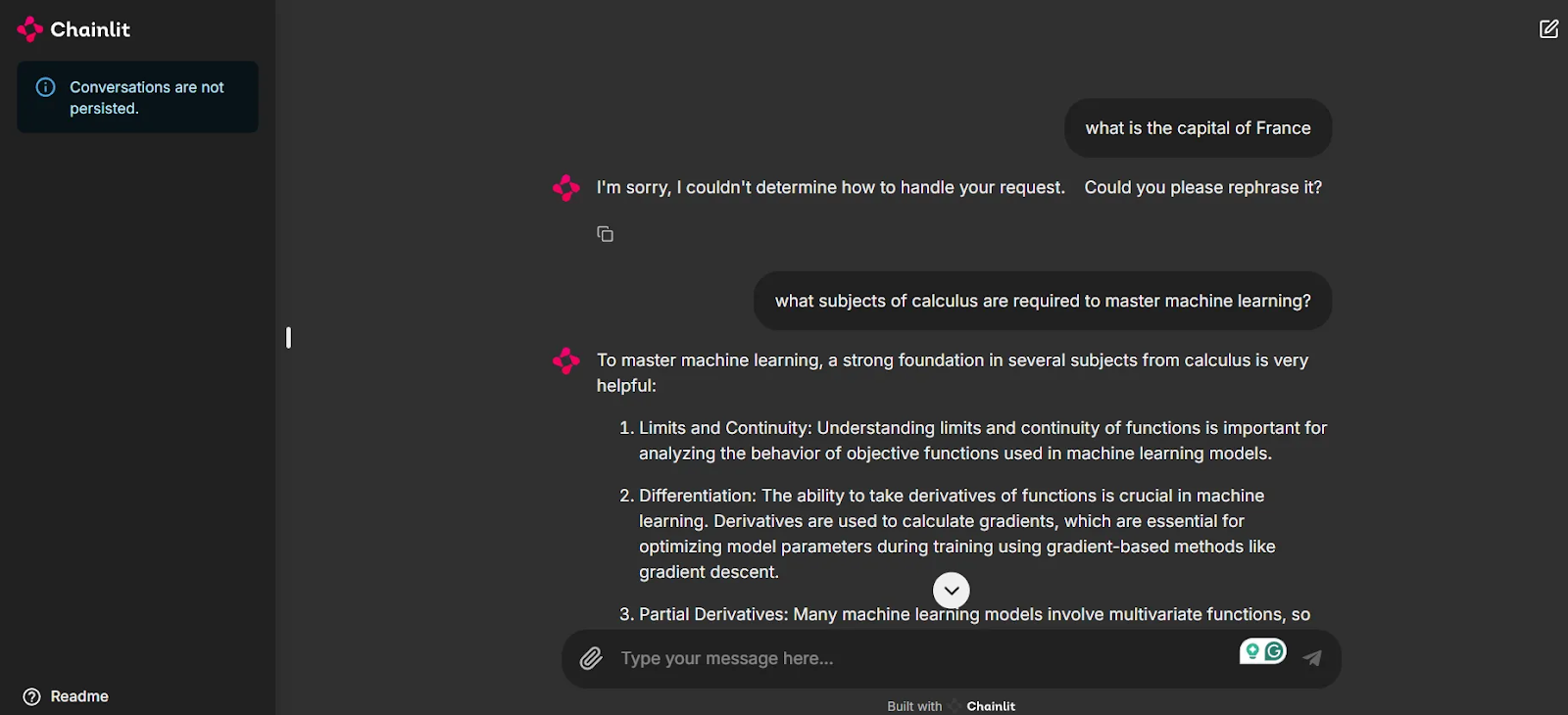
Wie du auf dem Screenshot sehen kannst, steht uns jetzt eine Benutzeroberfläche zur Verfügung, mit der wir unsere Anwendung testen und mit den Agenten chatten können.
Beachte, dass die erste Frage "Was ist die Hauptstadt von Frankreich?" keinen Bezug zu einem unserer Agenten hat und das System keine Antwort gibt. Das ist der Schlüssel dazu, dass die Chats relevant bleiben und du bei diesen Modellen keine unnötigen Credits ausgibst. Wenn jedoch eine verwandte Frage gestellt wird,kommt unser Machine Learning Expert Agent ins Spiel und gibt dank der intelligenten Weiterleitung des Multi-Agent Orchestrator eine Antwort.
In diesem Blog haben wir das neue AWS Multi-Agent Orchestrator-Framework vorgestellt, einige seiner einzigartigen Funktionen hervorgehoben, die Schritte zum Einrichten der Umgebung beschrieben, die grundlegenden Modelle von Amazon Bedrock untersucht und ein Demoprojekt implementiert.
Zum Zeitpunkt des Verfassens dieses Artikels fehlt dem Framework eine umfassende und detaillierte Dokumentation. Um von anderen Funktionen zu profitieren, wie z.B. der Speicher- und Werkzeugnutzung, musst du die Codebasis lesen und einen Blick auf die mitgelieferten Beispielprojekte werfen.
Ein neugieriges Auge auf agentenbasierte KI-Frameworks zu werfen, ist eine kluge Entscheidung, um in diesem schnelllebigen Bereich auf dem Laufenden zu bleiben. Der AWS Multi-Agent Orchestrator ist eine vielversprechende Option, die auf den Infrastrukturen der AWS-Dienste aufbaut und deren Entwicklung es sich lohnt, zu beobachten.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
