
Programa
Desenvolvimento de aplicativos de IA
21 h
O Orquestrador multiagente da AWS é uma estrutura flexível e repleta de ferramentas, projetada para gerenciar agentes de IA e facilitar conversas complexas com vários turnos. Seus componentes pré-construídos permitem desenvolvimento e implementação rápidos, para que possamos nos concentrar em nosso aplicativo sem a necessidade de reconstruir esses componentes do zero.
O AWS Multi-Agent Orchestrator oferece os seguintes recursos:
A estrutura é implementada para oferecer suporte a Python e TypeScript.
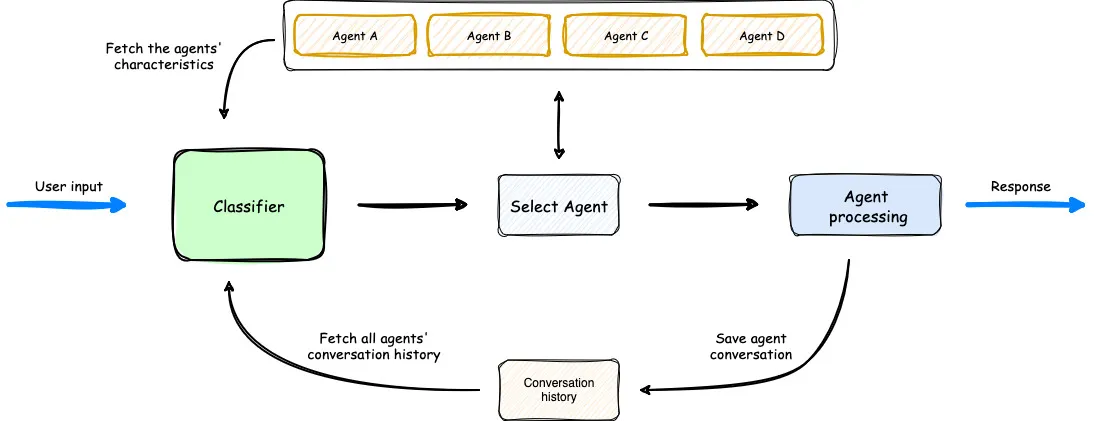
Uma visão geral de como o Multi-Agent Orchestrator funciona. (Fonte)
No diagrama acima, vemos que o classificador considera os agentes disponíveis, o prompt do usuário e o histórico de conversas anteriores para selecionar o agente ideal para a entrada do usuário. Em seguida, o agente processa a solicitação. O fluxo de trabalho é simples, mas eficaz.
Para uma configuração rápida do ambiente, você pode seguir as instruções na documentação.
Primeiro, criamos uma nova pasta e um novo ambiente Python para instalar as bibliotecas necessárias.
mkdir test_multi_agent_orchestrator
cd test_multi_agent_orchestrator
python -m venv venv
source venv/bin/activate # On Windows use venv\\Scripts\\activateCom o novo ambiente virtual ativado, instale a biblioteca
pip install multi-agent-orchestratorEm seguida, precisamos configurar nossa conta do AWS. Se você não tiver uma conta da AWS, inscreva-se gratuitamente em uma conta conta de nível gratuito. Depois de se registrar, faça o download a CLI do AWS.
A CLI do AWS também precisa ser configurada. Para obter instruções detalhadas, siga Configurando a CLI do AWSmas você pode adotar uma abordagem mais fácil usando o comando aws configure e fornecendo o ID da chave de acesso do AWS e a chave de acesso secreta. Você pode obter essas chaves depois de criar um novo usuário em seu painel.
Chaves de acesso fornecidas ao criar um novo usuário.
Com as chaves de acesso em mãos, execute aws configure e forneça as chaves, selecione o nome da região (uma lista completa é fornecida aqui) mais próxima de você e defina o formato de saída padrão como json.

Se a sua CLI estiver configurada corretamente, a execução do comando aws sts get-caller-identity deverá mostrar o ID da sua conta AWS, o ID do usuário e o ARN.
Agora que temos a CLI do AWS pronta para uso, precisamos configurar o AWS Bedrock para dar acesso aos LLMs de que precisaremos. O Amazon Bedrock é um serviço que permite que você teste e chame modelos básicos (como o Llama 3.2 ou Claude 3.5 Sonnet) por meio de uma API. O Multi-Agent Orchestrator usa esse serviço para chamar dois modelos por padrão:
É claro que esses modelos podem ser alterados, mas vamos continuar com a opção padrão.
Para dar acesso a esses dois modelos, vá para Amazon Bedrock > Acesso ao modelo e selecione "Modificar acesso ao modelo". Selecione os dois modelos (e outros, se você quiser) e preencha todas as informações necessárias. Essa parte terá a seguinte aparência:
Após concluir a solicitação, os modelos estarão disponíveis em um ou dois minutos. Quando o acesso for concedido para os modelos solicitados, você deverá ver "Acesso concedido" na frente deles.
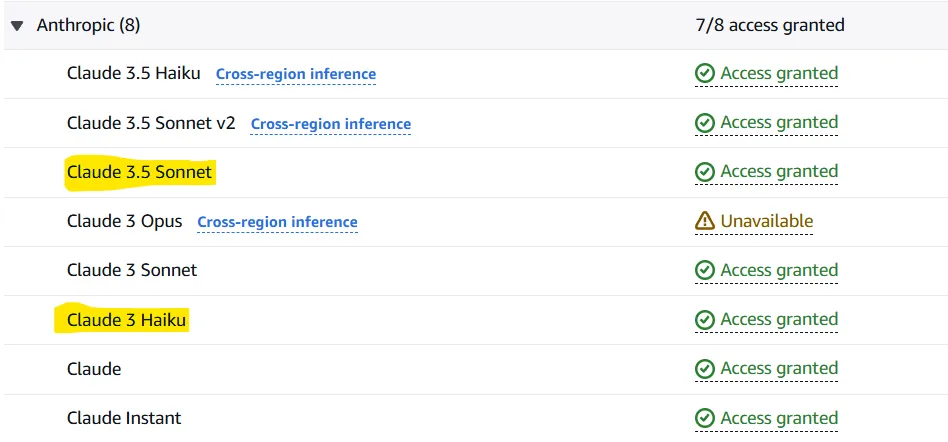
Observação: Pode ser necessário atribuir uma política ao usuário que você criou. Você pode testar isso se encontrar problemas na próxima subseção do nosso artigo (Teste sua configuração). Se for o caso, dê uma olhada em esta página. Em resumo, você precisaria conceder ao usuário que definiu acesso a AmazonBedrockFullAccess.
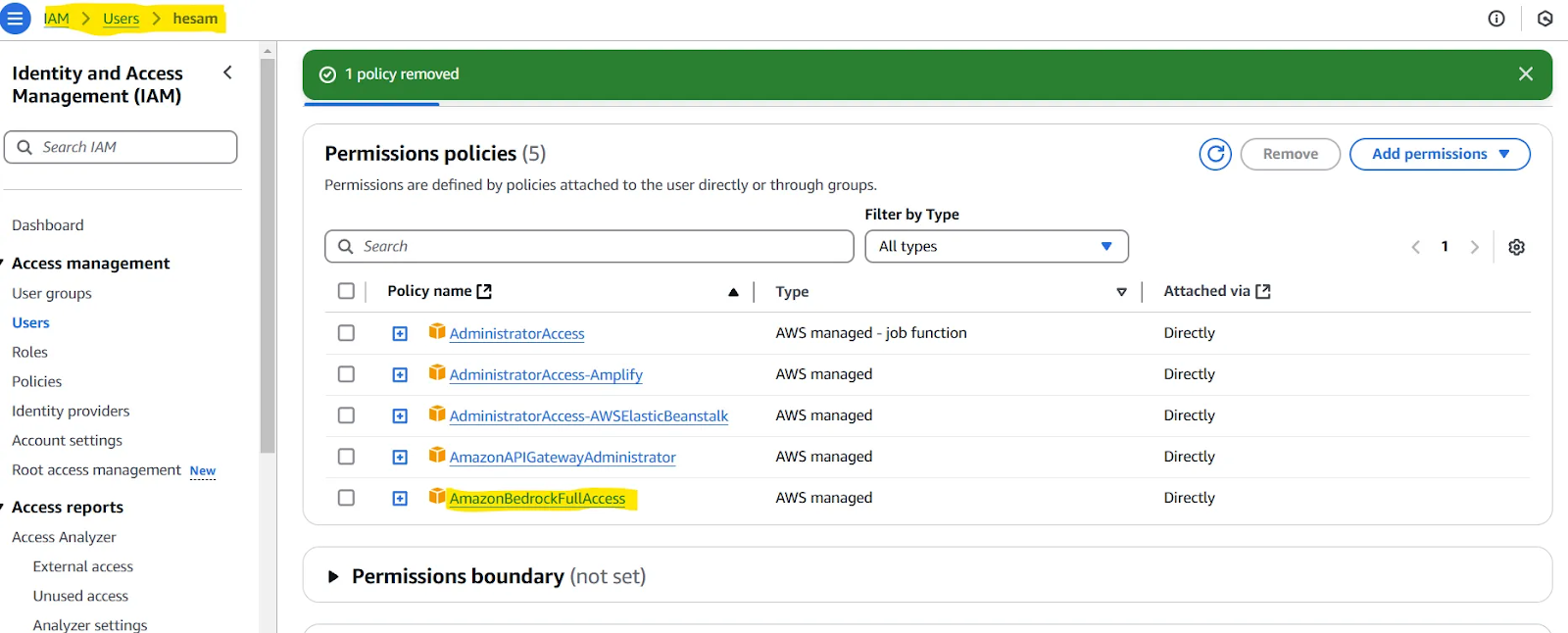
Para verificar se todas as etapas anteriores foram configuradas corretamente, use este código:
import uuid
import asyncio
import json
import sys
from typing import Optional, List, Dict, Any
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.agents import (
BedrockLLMAgent,
BedrockLLMAgentOptions,
AgentResponse,
AgentCallbacks,
)
from multi_agent_orchestrator.types import ConversationMessage, ParticipantRole
orchestrator = MultiAgentOrchestrator(
options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=True,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
)
)
class BedrockLLMAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
# handle response streaming here
print(token, end="", flush=True)
tech_agent = BedrockLLMAgent(
BedrockLLMAgentOptions(
name="Tech Agent",
streaming=True,
description=(
"Specializes in technology areas including software development, hardware, AI, "
"cybersecurity, blockchain, cloud computing, emerging tech innovations, and pricing/costs "
"related to technology products and services."
),
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks(),
)
)
orchestrator.add_agent(tech_agent)
async def handle_request(
_orchestrator: MultiAgentOrchestrator, _user_input: str, _user_id: str, _session_id: str
):
response: AgentResponse = await _orchestrator.route_request(
_user_input, _user_id, _session_id
)
# Print metadata
print("\nMetadata:")
print(f"Selected Agent: {response.metadata.agent_name}")
if response.streaming:
print("Response:", response.output.content[0]["text"])
else:
print("Response:", response.output.content[0]["text"])
if __name__ == "__main__":
USER_ID = "user123"
SESSION_ID = str(uuid.uuid4())
print("Welcome to the interactive Multi-Agent system. Type 'quit' to exit.")
while True:
# Get user input
user_input = input("\nYou: ").strip()
if user_input.lower() == "quit":
print("Exiting the program. Goodbye!")
sys.exit()
# Run the async function
asyncio.run(handle_request(orchestrator, user_input, USER_ID, SESSION_ID))Se você puder solicitar e receber uma resposta, tudo funcionará bem.
O repositório do AWS Multi-Agent Orchestrator fornece vários projetos de exemplo em TypeScript e Python. Agora escreveremos um aplicativo Python simplificado que consiste em dois agentes: Agente desenvolvedor Python e agente especialista em ML.
Também usaremos o Chainlit, um pacote Python de código aberto, para implementar uma interface de usuário simples para o aplicativo. Para começar, instale as bibliotecas necessárias:
chainlit==1.2.0
multi_agent_orchestrator==0.0.18Usamos o código abaixo em nosso aplicativo de demonstração, mas primeiro vamos explicá-lo:
“anthropic.claude-3-haiku-20240307-v1:0” como modelo para nosso classificador. Esse classificador escolherá qual agente usar quando chegar uma nova entrada de usuário.MultiAgentOrchestrator e definimos algumas configurações.BedrockLLMAgent é usada para criar nossos agentes. São fornecidos um name e um description para cada agente. Para um agente, você pode escolher qualquer um dos modelos acessíveis ou até mesmo usar o Ollama para executá-los localmente. Ao definir streaming=True e passar ChainlitAgentCallbacks() como callback, você fará com que os agentes retornem respostas em fluxo contínuo em vez de respostas completas. Por fim, adicionamos cada agente ao orquestrador.user_session é definido e a seção principal para tratar as mensagens do usuário e do agente é definida.### 1
import uuid
import chainlit as cl
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.classifiers import BedrockClassifier, BedrockClassifierOptions
from multi_agent_orchestrator.agents import AgentResponse
from multi_agent_orchestrator.agents import BedrockLLMAgent, BedrockLLMAgentOptions, AgentCallbacks
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator
from multi_agent_orchestrator.types import ConversationMessage
import asyncio
import chainlit as cl
class ChainlitAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
asyncio.run(cl.user_session.get("current_msg").stream_token(token))
### 2
# Initialize the orchestrator & classifier
custom_bedrock_classifier = BedrockClassifier(BedrockClassifierOptions(
model_id='anthropic.claude-3-haiku-20240307-v1:0',
inference_config={
'maxTokens': 500,
'temperature': 0.7,
'topP': 0.9
}
))
### 3
orchestrator = MultiAgentOrchestrator(options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=False,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
),
classifier=custom_bedrock_classifier
)
### 4
def create_python_dev():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Python Developer Agent",
streaming=True,
description="Experienced Python developer specialized in writing, debugging, and evaluating only Python code.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
def create_ml_expert():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Machine Learning Expert",
streaming=True,
description="Expert in areas related to machine learning including deep learning, pytorch, tensorflow, scikit-learn, and large language models.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
# Add agents to the orchestrator
orchestrator.add_agent(create_python_dev())
orchestrator.add_agent(create_ml_expert())
### 5
@cl.on_chat_start
async def start():
cl.user_session.set("user_id", str(uuid.uuid4()))
cl.user_session.set("session_id", str(uuid.uuid4()))
cl.user_session.set("chat_history", [])
@cl.on_message
async def main(message: cl.Message):
user_id = cl.user_session.get("user_id")
session_id = cl.user_session.get("session_id")
msg = cl.Message(content="")
await msg.send() # Send the message immediately to start streaming
cl.user_session.set("current_msg", msg)
response:AgentResponse = await orchestrator.route_request(message.content, user_id, session_id, {})
# Handle non-streaming or problematic responses
if isinstance(response, AgentResponse) and response.streaming is False:
# Handle regular response
if isinstance(response.output, str):
await msg.stream_token(response.output)
elif isinstance(response.output, ConversationMessage):
await msg.stream_token(response.output.content[0].get('text'))
await msg.update()
if __name__ == "__main__":
cl.run()Agora é hora de executar o aplicativo. Para fazer isso, primeiro execute chainlit run [app.py](<http://app.py/>) -w. Agora você pode testar o aplicativo na nova guia aberta no navegador.
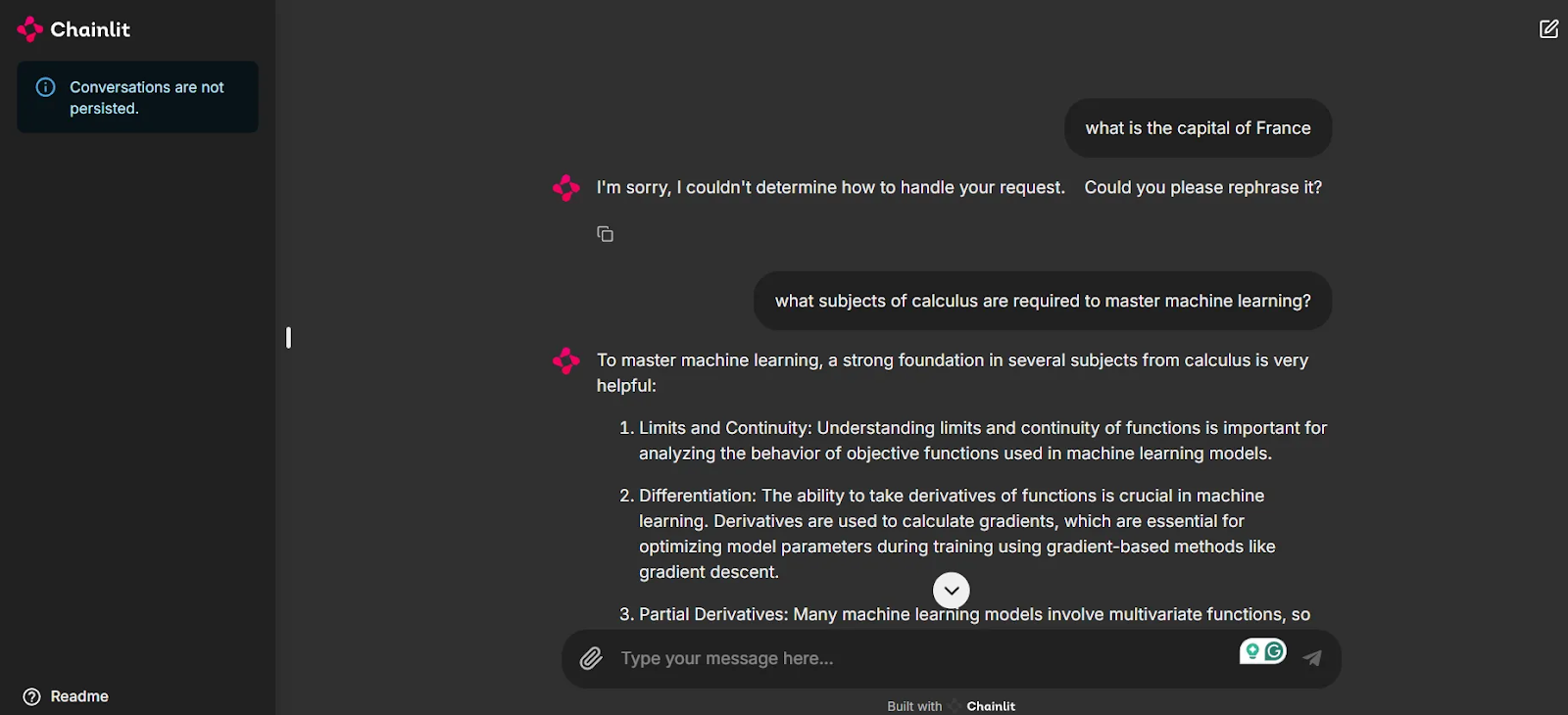
Como você pode ver na captura de tela, agora temos uma interface do usuário para testar nosso aplicativo e conversar com os agentes.
Observe que, como o primeiro prompt "Qual é a capital da França?" não está relacionado a nenhum dos nossos agentes, o sistema não fornece uma resposta. Isso é fundamental para que você mantenha os bate-papos relevantes e evite gastar créditos desnecessários ao usar esses modelos. No entanto, quando você recebe uma pergunta relacionada, nossoagente Machine Learning Expert entra em ação para dar uma resposta, graças ao roteamento inteligente do Multi-Agent Orchestrator.
Neste blog, apresentamos a recente estrutura do AWS Multi-Agent Orchestrator, destacamos alguns de seus recursos exclusivos, delineamos as etapas para configurar o ambiente, exploramos os modelos fundamentais atendidos pelo Amazon Bedrock e implementamos um projeto de demonstração.
No momento em que este artigo foi escrito, a estrutura carecia de documentação abrangente e detalhada. Para se beneficiar de outros recursos, como memória e uso de ferramentas, você deve ler a base de código e dar uma olhada nos projetos de exemplo fornecidos.
Manter um olhar curioso sobre as estruturas de IA agêntica é uma escolha inteligente para acompanhar esse campo em ritmo acelerado. O AWS Multi-Agent Orchestrator é uma opção promissora criada com base nas infraestruturas dos serviços da AWS, e vale a pena acompanhar seu desenvolvimento.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Srujana Maddula
13 min
blog
Yuliya Melnik
15 min
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Zoumana Keita

