Lernpfad
Grundlagen der KI
10 Std.
Den Beispielen von Meta zufolge können die Modelle in Dokumente eingebettete Diagramme analysieren und wichtige Trends zusammenfassen. Sie können auch Karten interpretieren, bestimmen, welcher Teil eines Wanderweges am steilsten ist, oder die Entfernung zwischen zwei Punkten berechnen.
Diese Integration von Text und Bild bietet eine Vielzahl von Anwendungsmöglichkeiten, z. B:
Die Sichtmodelle von Llama 3.2 sind offen und anpassbar. Entwickler können feinabstimmen. und angepasste Versionen dieser Modelle mit Meta's Torchtune Torchtune Framework von Meta.
Außerdem können diese Modelle lokal über Torchchateingesetzt werden, wodurch die Abhängigkeit von Cloud Cloud-Infrastruktur und bietet eine Lösung für Entwickler, die KI-Systeme einsetzen vor Ort oder in ressourcenbeschränkten Umgebungen einsetzen wollen.
Die Visionsmodelle können auch über Meta AI, den intelligenten Assistenten von Meta, getestet werden.
Damit die Llama 3.2-Vision-Modelle sowohl Text als auch Bilder verstehen können, hat Meta einen vortrainierten Bild-Encoder mit Hilfe von speziellen Adaptern in das bestehende Sprachmodell. Diese Adapter verknüpfen die Bilddaten mit den Textverarbeitungsteilen des Modells, so dass es beide Arten von Eingaben verarbeiten kann.
Der Trainingsprozess begann mit dem Sprachmodell Llama 3.1. Zunächst trainierte das Team das Modell mit einer großen Anzahl von Bildern, die mit Textbeschreibungen gepaart waren, um dem Modell beizubringen, wie es die beiden miteinander verbinden kann. Dann haben sie es mit saubereren, spezifischeren Daten verfeinert, um die Fähigkeit zu verbessern, visuelle Inhalte zu verstehen und zu interpretieren.
In der Endphase verwendete Meta Techniken wie Feinabstimmung und synthetische Daten um sicherzustellen, dass das Modell hilfreiche Antworten gibt und sich sicher verhält.
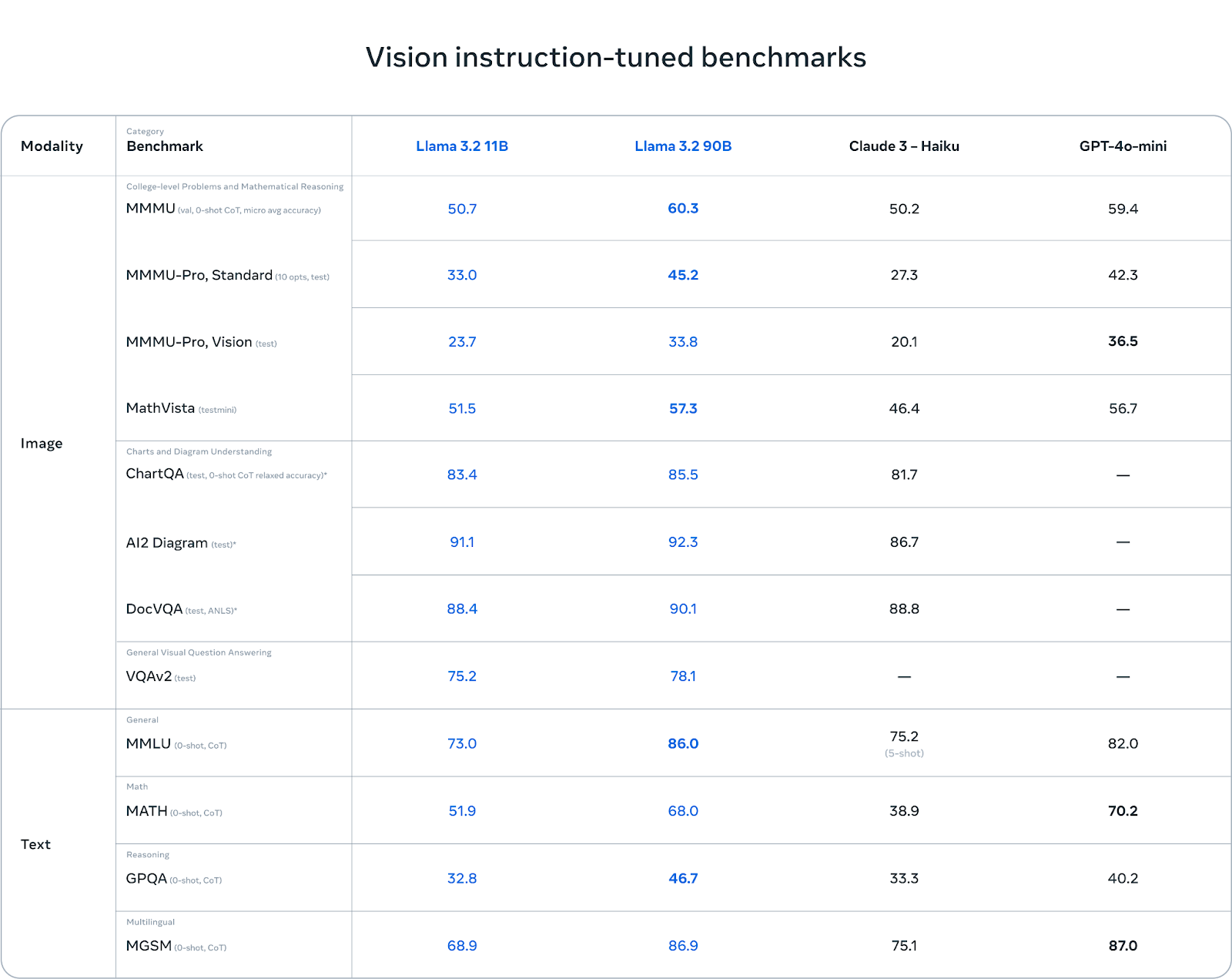
Die Llama 3.2 Visionsmodelle glänzen beim Verstehen von Tabellen und Diagrammen. In Benchmarks wie AI2 Diagram (92,3) und DocVQA (90,1) schneidet Llama 3.2 besser ab als Claude 3 Haiku. Das macht sie zu einer ausgezeichneten Wahl für Aufgaben, bei denen es um das Verstehen von Dokumenten, die Beantwortung visueller Fragen und die Datenextraktion aus Diagrammen geht.
Bei mehrsprachigen Aufgaben (MGSM) schneidet Llama 3.2 ebenfalls gut ab und erreicht mit 86,9 Punkten fast die gleiche Punktzahl wie GPT-4o-mini, was es zu einer soliden Option für Entwickler macht, die mit mehreren Sprachen arbeiten.
Quelle: Meta AI
Während Llama 3.2 bei sehkraftbasierten Aufgaben gut abschneidet, gibt es in anderen Bereichen Herausforderungen. Bei MMMU-Pro Vision, einem Test zum mathematischen Denken anhand visueller Daten, übertrifft GPT-4o-mini Llama 3.2 mit 36,5 Punkten im Vergleich zu 33,8 Punkten bei Llama.
Auch im MATH-Benchmark übertrifft die Leistung von GPT-4o-mini (70,2) Llama 3.2 (51,9) deutlich, was zeigt, dass Llama bei mathematischen Denkaufgaben noch Verbesserungspotenzial hat.
Eine weitere wichtige Neuerung in Llama 3.2 ist die Einführung von leichtgewichtigen Modellen, die für Edge- und Mobilgeräte entwickelt wurden. Diese Modelle mit 1 Milliarde und 3 Milliarden Parametern sind so optimiert, dass sie auf kleinerer Hardware laufen und gleichzeitig einen vernünftigen Kompromiss bei der Leistung darstellen.
Diese Modelle sind so konzipiert, dass sie auf mobilen Geräten laufen und eine schnelle, lokale Verarbeitung ermöglichen, ohne dass die Daten in die Cloud gesendet werden müssen. Die lokale Ausführung von Modellen auf Edge-Geräten bietet zwei wesentliche Vorteile:
Die leichtgewichtigen Modelle von Llama 3.2 sind für Arm-Prozessoren optimiert und können auf Qualcomm- und MediaTek-Hardware eingesetzt werden, die heute viele mobile und Edge-Geräte antreiben.
Die leichten Modelle sind für eine Vielzahl praktischer Anwendungen auf dem Gerät konzipiert, wie z. B.:
1. Zusammenfassung: Die Nutzer/innen können große Textmengen, wie E-Mails oder Besprechungsnotizen, direkt auf ihrem Gerät zusammenfassen, ohne auf Cloud-Dienste angewiesen zu sein.
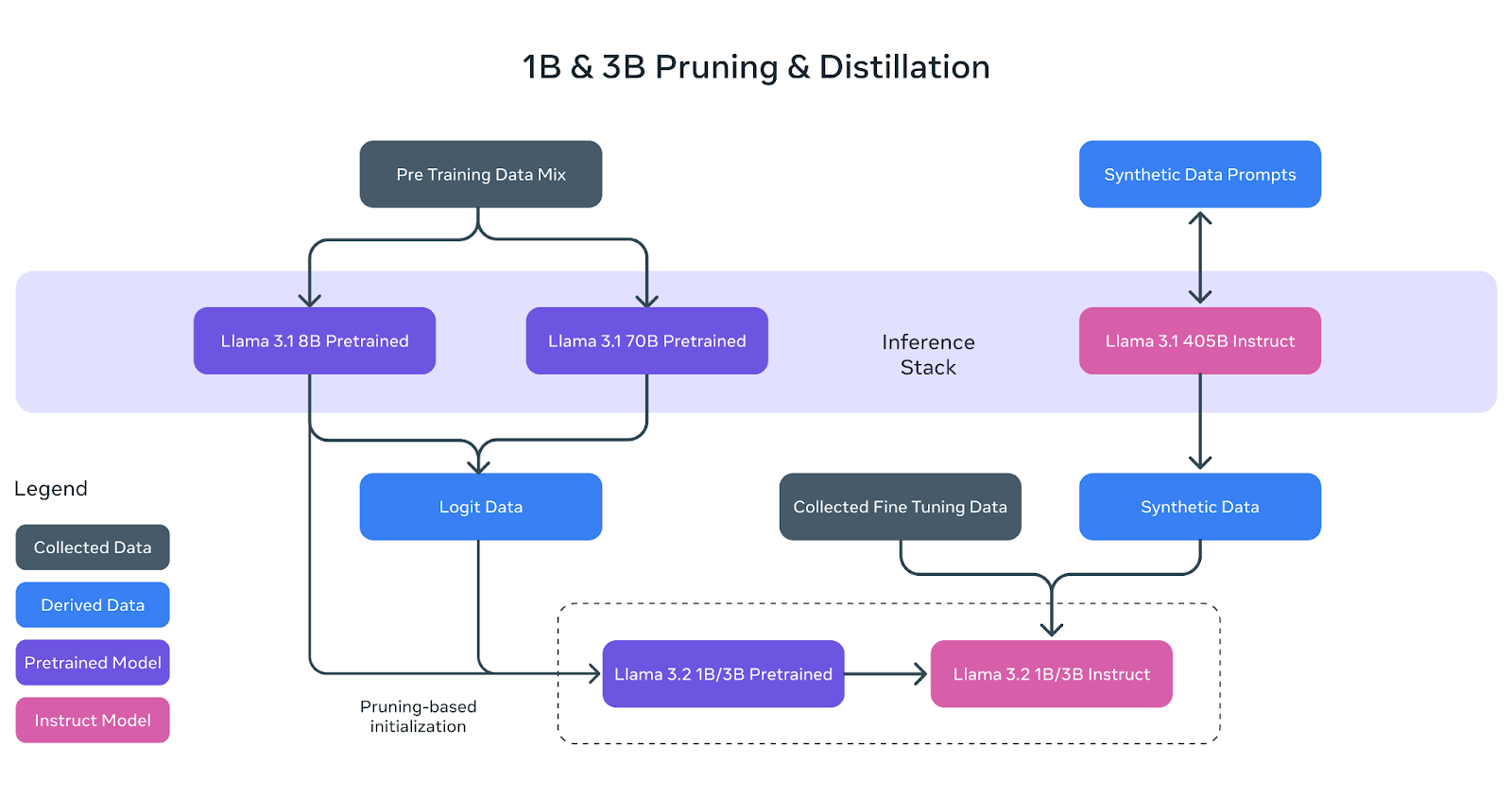
Die leichten Llama 3.2-Modelle (1B und 3B) wurden so gebaut, dass sie effizient auf Mobil- und Edge-Geräte passen und gleichzeitig eine starke Leistung bieten. Um dies zu erreichen, setzte Meta zwei Schlüsseltechniken ein: Pruning und Destillation.
Quelle: Meta AI
Pruning hilft, die Größe der ursprünglichen Llama-Modelle zu reduzieren, indem weniger kritische Teile des Netzwerks entfernt werden, während so viel Wissen wie möglich erhalten bleibt. Im Fall der 1B- und 3B-Modelle von Llama 3.2 begann dieser Prozess mit dem größeren, vortrainierten 8B-Modell von Llama 3.1.
Durch systematisches Beschneiden konnte das Meta AI-Team kleinere, effizientere Versionen des Modells erstellen, ohne dass die Leistung signifikant abnahm. Dies wird im obigen Diagramm dargestellt, in dem das 8B-Modell (lila Kasten) beschnitten und verfeinert wird, um die Basis für die kleineren Llama 3.2 1B/3B-Modelle zu bilden.
Destillation ist der Prozess der Wissensübertragung von einem größeren, leistungsfähigeren Modell (dem "Lehrer") auf ein kleineres Modell (den "Schüler"). In Llama 3.2 wurden die Logits (Vorhersagen) der größeren Modelle Llama 3.1 8B und Llama 3.1 70B verwendet, um die kleineren Modelle zu lernen.
Auf diese Weise konnten die kleineren 1B- und 3B-Modelle lernen, Aufgaben trotz ihrer geringeren Größe effektiver auszuführen. Das obige Diagramm zeigt, wie dieser Prozess die Logit-Daten der größeren Modelle nutzt, um die 1B- und 3B-Modelle während des Pre-Trainings zu steuern.
Nach dem Pruning und der Destillation wurden die Modelle 1B und 3B einem Post-Training unterzogen, ähnlich wie die früheren Llama-Modelle. Dazu gehörten Techniken wie überwachte Feinabstimmung, Rejection Sampling und direkte Präferenzoptimierung, um die Ergebnisse der Modelle mit den Erwartungen der Nutzerinnen und Nutzer in Einklang zu bringen.
Es wurden auch synthetische Daten erstellt, um sicherzustellen, dass die Modelle eine breite Palette von Aufgaben bewältigen können, wie z.B. Zusammenfassen, Umschreiben und Befolgen von Anweisungen.
Wie im Diagramm zu sehen ist, sind die endgültigen Llama 3.2 1B/3B Lehrermodelle das Ergebnis von Pruning, Destillation und umfangreichem Post-Training.
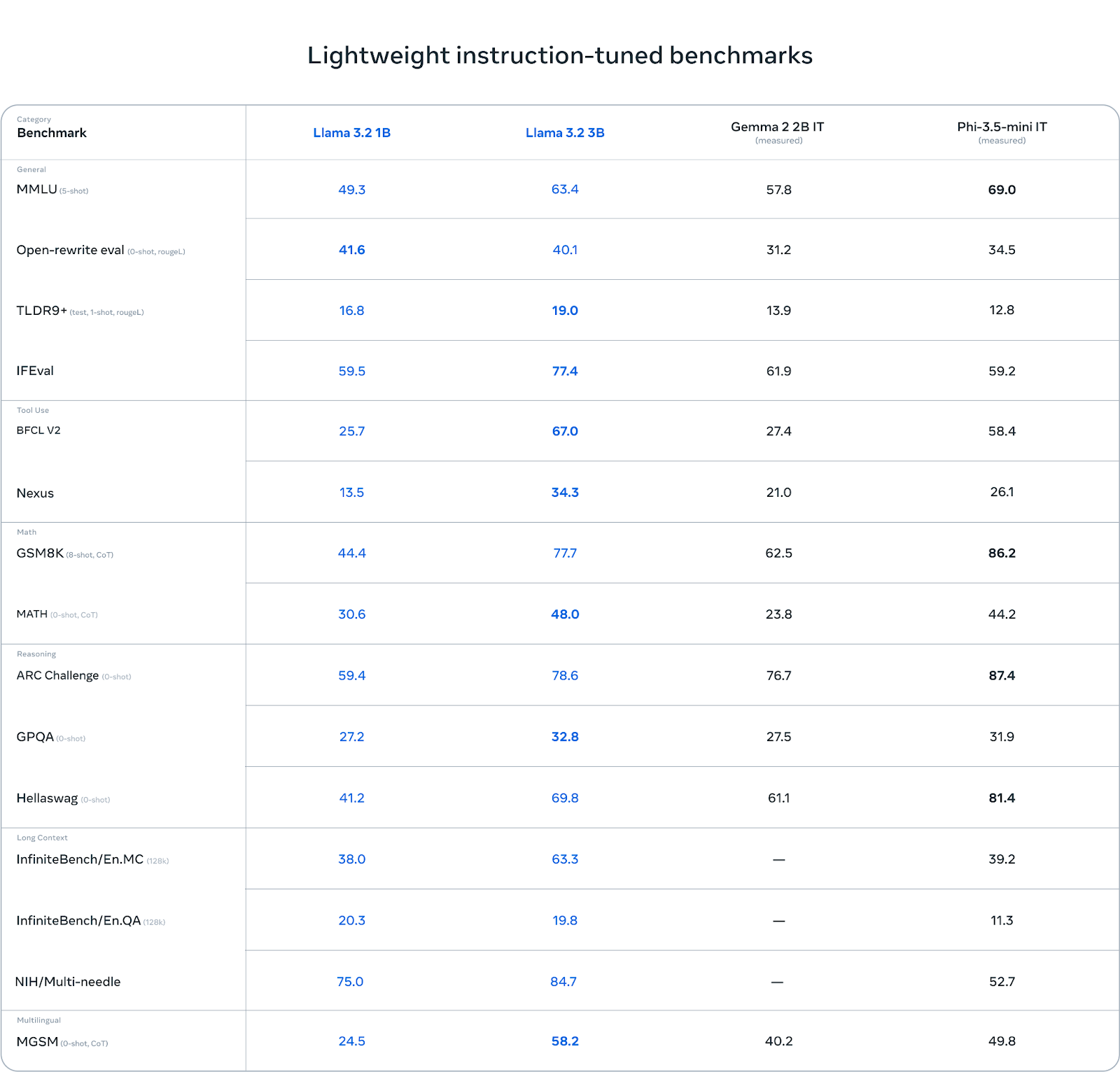
Llama 3.2 3B sticht in bestimmten Kategorien hervor, vor allem bei Aufgaben, die logisches Denken erfordern. In der ARC-Challenge erreicht er zum Beispiel 78,6 Punkte und übertrifft damit sowohl Gemma (76,7) als auch Phi-3.5-mini (87,4) knapp. Auch im Hellawag-Benchmark schneidet er mit 69,8 gut ab, schlägt Gemma und bleibt konkurrenzfähig mit Phi.
Bei Aufgaben zur Werkzeugnutzung wie BFCL V2 glänzt Llama 3.2 3B ebenfalls mit einer Punktzahl von 67,0 und liegt damit vor den beiden Konkurrenten. Das zeigt, dass das 3B-Modell das Befolgen von Anweisungen und werkzeugbezogene Aufgaben effektiv bewältigt.
Quelle: Meta AI
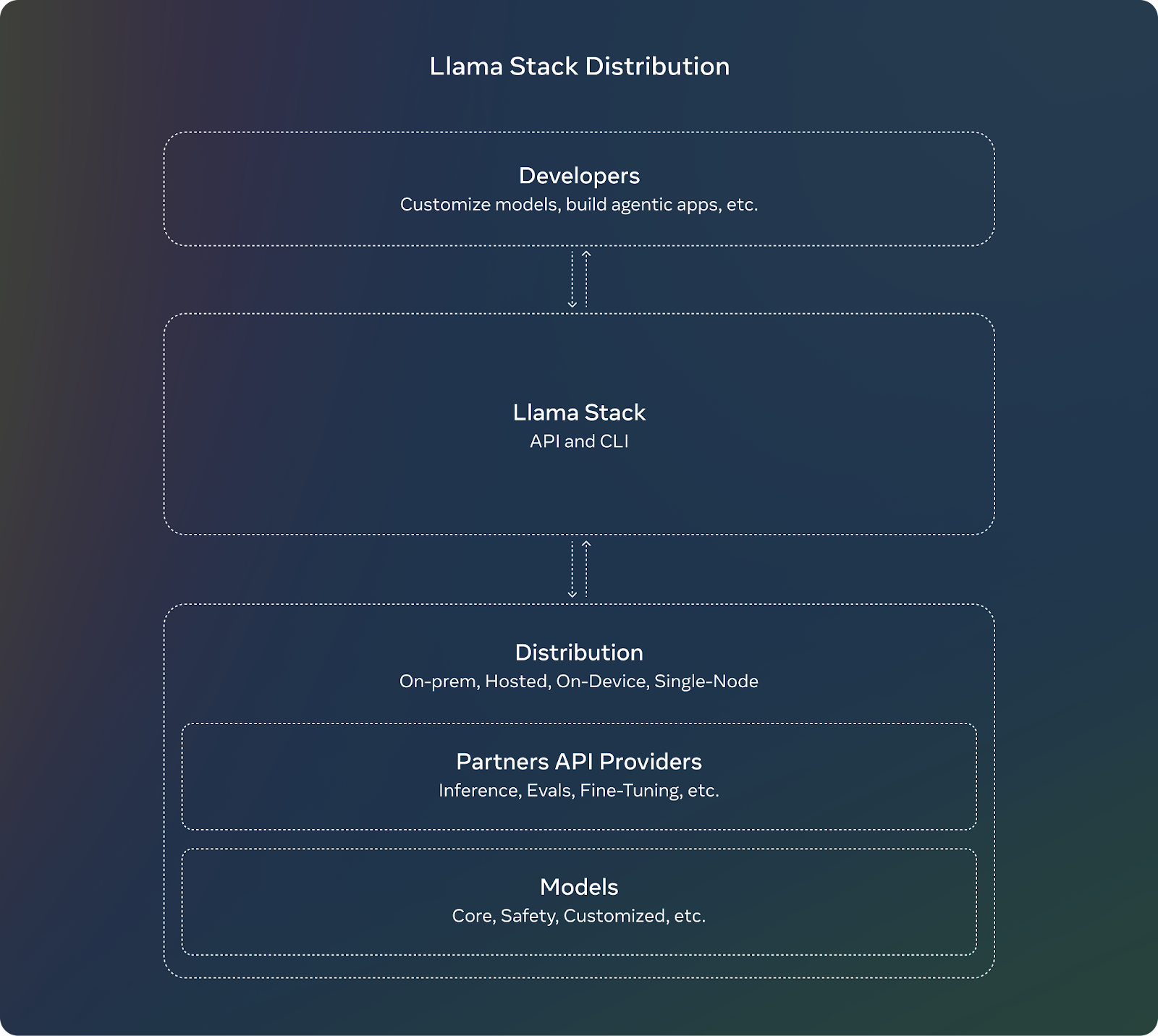
Als Ergänzung zur Veröffentlichung von Llama 3.2 stellt Meta den Llama Stack vor. Für Entwickler/innen bedeutet die Verwendung des Llama Stack, dass sie sich nicht um die komplexen Details der Einrichtung oder des Einsatzes von großen Modellen kümmern müssen. Sie können sich auf die Entwicklung ihrer Anwendungen konzentrieren und darauf vertrauen, dass der Llama Stack einen Großteil der schweren Arbeit übernimmt.
Dies sind die wichtigsten Merkmale des Llama Stack:
Quelle: Meta AI
Meta setzt seinen Fokus auf verantwortungsvolle KI mit Llama 3.2. Llama Guard 3 wurde aktualisiert und enthält jetzt eine Version mit Sehfunktion, die die neuen multimodalen Fähigkeiten von Llama 3.2 unterstützt. So wird sichergestellt, dass Anwendungen, die die neuen Bildverstehensfunktionen nutzen, sicher und konform mit den ethischen Richtlinien.
Außerdem wurde Llama Guard 3 1B für den Einsatz in ressourcenbeschränkten Umgebungen optimiert und ist nun kleiner und effizienter als die Vorgängerversionen.
Der Zugang und das Herunterladen der Llama 3.2 Modelle ist ziemlich einfach. Meta hat diese Modelle auf mehreren Plattformen zur Verfügung gestellt, darunter die eigene Website und Hugging Face, eine beliebte Plattform zum Hosten und Teilen von KI-Modellen.
Du kannst die Llama 3.2 Modelle direkt von der offiziellen Llama-Website. Meta bietet sowohl die kleineren, leichten Modelle (1B und 3B) als auch die größeren Vision-fähigen Modelle (11B und 90B) für Entwickler an.
Hugging Face ist eine weitere Plattform, auf der Llama 3.2 Modelle verfügbar sind. Es bietet einen einfachen Zugang und wird häufig von Entwicklern in der KI-Community verwendet.
Die Llama 3.2-Modelle sind für die sofortige Entwicklung auf unserem breiten Ökosystem von Partnerplattformen verfügbar, darunter AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud, Snowflake und andere.
Mit der Veröffentlichung von Llama 3.2 stellt Meta die ersten multimodalen Modelle der Serie vor, die sich auf zwei Schlüsselbereiche konzentrieren: Vision-fähige Modelle und leichtgewichtige Modelle für Edge- und Mobilgeräte.
Die multimodalen Modelle 11B und 90B können jetzt sowohl Text als auch Bilder verarbeiten, während die Modelle 1B und 3B für die effiziente lokale Nutzung auf kleineren Geräten optimiert sind.
In diesem Artikel erkläre ich dir das Wichtigste - wie diese Modelle funktionieren, wie sie in der Praxis angewendet werden und wie du sie nutzen kannst.
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs