
Cursus
Développer des applications d'IA
21 h
L'Orchestrateur AWS Multi-Agent Orchestrator est un cadre flexible et riche en outils, conçu pour gérer les agents d'intelligence artificielle et faciliter les conversations complexes à plusieurs tours. Ses composants préconstruits permettent un développement et un déploiement rapides, de sorte que nous pouvons nous concentrer sur notre application sans avoir à reconstruire ces composants à partir de zéro.
L'AWS Multi-Agent Orchestrator offre les fonctionnalités suivantes :
Le cadre est mis en œuvre pour prendre en charge à la fois Python et TypeScript.
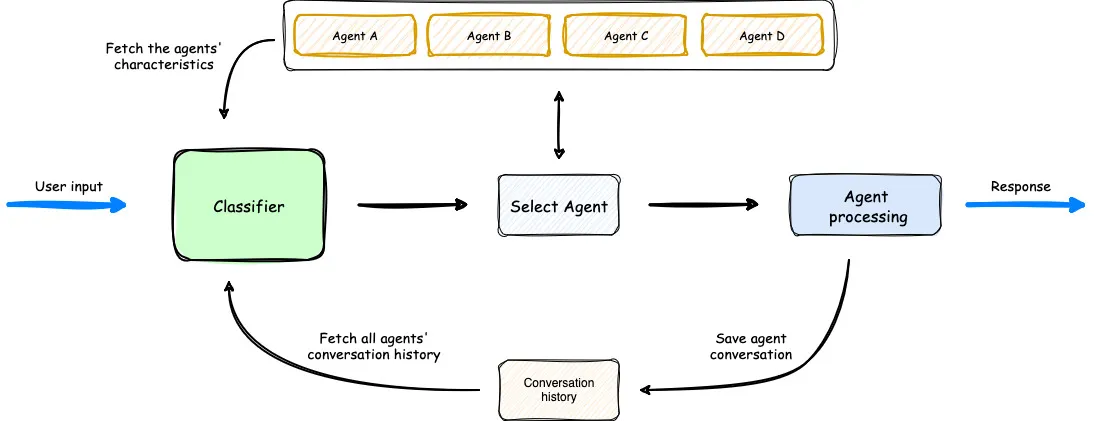
Aperçu du fonctionnement de Multi-Agent Orchestrator. (Source)
Dans le diagramme ci-dessus, nous voyons que le classificateur prend en compte les agents disponibles, l'invite de l'utilisateur et l'historique des conversations précédentes pour sélectionner l'agent optimal pour l'entrée de l'utilisateur. Ensuite, l'agent traite la demande. Le flux de travail est simple mais efficace.
Pour une installation rapide de l'environnement, vous pouvez suivre les instructions dans la documentation.
Tout d'abord, nous créons un nouveau dossier et un nouvel environnement Python pour installer les bibliothèques nécessaires.
mkdir test_multi_agent_orchestrator
cd test_multi_agent_orchestrator
python -m venv venv
source venv/bin/activate # On Windows use venv\\Scripts\\activateUne fois le nouvel environnement virtuel activé, installez la bibliothèque
pip install multi-agent-orchestratorEnsuite, nous devons configurer notre compte AWS. Si vous n'avez pas de compte AWS, inscrivez-vous gratuitement à un compte gratuit. Après l'inscription, téléchargez le CLI AWS.
Le CLI AWS doit également être configuré. Pour obtenir des instructions détaillées, suivez les instructions suivantes Configuration de la CLI AWSmais vous pouvez adopter une approche plus simple en utilisant la commande aws configure et en fournissant l'ID de la clé d'accès AWS et la clé d'accès secrète. Vous pouvez obtenir ces clés après avoir créé un nouvel utilisateur dans votre tableau de bord.
Clés d'accès fournies lors de la création d'un nouvel utilisateur.
Avec les clés d'accès en main, lancez aws configure et fournissez les clés, sélectionnez le nom de la région (une liste complète est fournie ici) le plus proche de chez vous et définissez le format de sortie par défaut sur json.

Si votre CLI est correctement configuré, la commande aws sts get-caller-identity devrait afficher votre identifiant de compte AWS, votre identifiant d'utilisateur et votre ARN.
Maintenant que le CLI AWS est prêt à fonctionner, nous devons configurer AWS Bedrock pour qu'il donne accès aux LLM dont nous aurons besoin. Amazon Bedrock est un service qui vous permet de tester et d'appeler des modèles fondamentaux (tels que Llama 3.2 ou Claude 3.5 Sonnet) à travers une API. L'orchestrateur multi-agents utilise ce service pour appeler deux modèles par défaut :
Bien sûr, ces modèles peuvent être modifiés, mais continuons avec le choix par défaut.
Pour donner accès à ces deux modèles, rendez-vous sur Amazon Bedrock > Accès au modèle et sélectionnez "Modifier l'accès au modèle". Sélectionnez les deux modèles (et d'autres si vous le souhaitez) et complétez les informations requises. Cette partie se présente comme suit :
Une fois la demande terminée, les modèles seront disponibles dans 1 à 2 minutes. Lorsque l'accès est accordé pour les modèles demandés, vous devez voir "Accès accordé" en face de ceux-ci.
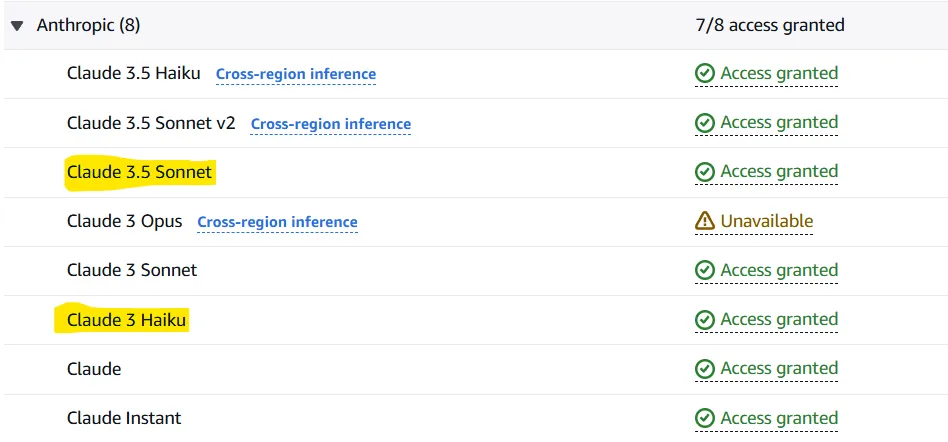
Note : Il peut vous être demandé d'attribuer une politique à l'utilisateur que vous avez créé. Vous pouvez tester cela si vous rencontrez des problèmes dans la sous-section suivante de notre article (Testez votre configuration). Si c'est le cas, consultez cette page. En résumé, vous devez donner à l'utilisateur que vous avez défini l'accès à AmazonBedrockFullAccess.
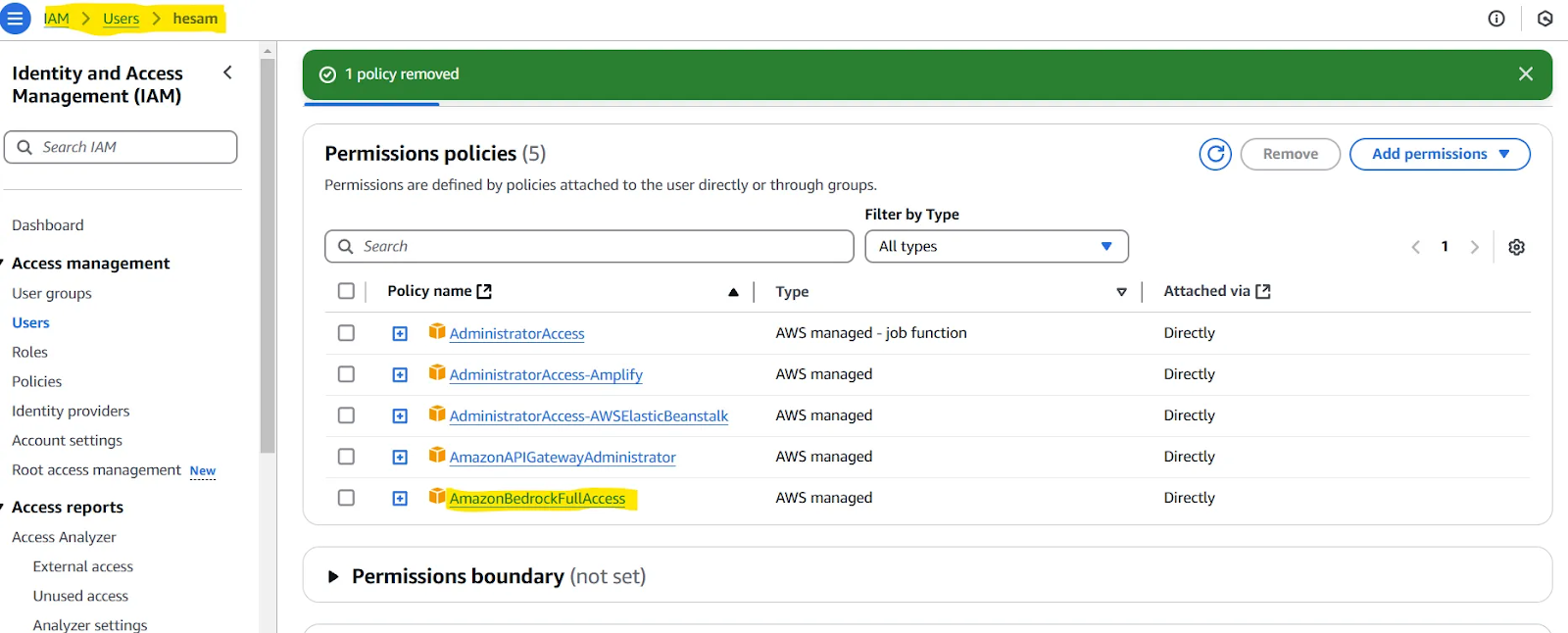
Pour vérifier si toutes les étapes précédentes ont été effectuées correctement, utilisez ce code :
import uuid
import asyncio
import json
import sys
from typing import Optional, List, Dict, Any
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.agents import (
BedrockLLMAgent,
BedrockLLMAgentOptions,
AgentResponse,
AgentCallbacks,
)
from multi_agent_orchestrator.types import ConversationMessage, ParticipantRole
orchestrator = MultiAgentOrchestrator(
options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=True,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
)
)
class BedrockLLMAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
# handle response streaming here
print(token, end="", flush=True)
tech_agent = BedrockLLMAgent(
BedrockLLMAgentOptions(
name="Tech Agent",
streaming=True,
description=(
"Specializes in technology areas including software development, hardware, AI, "
"cybersecurity, blockchain, cloud computing, emerging tech innovations, and pricing/costs "
"related to technology products and services."
),
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=BedrockLLMAgentCallbacks(),
)
)
orchestrator.add_agent(tech_agent)
async def handle_request(
_orchestrator: MultiAgentOrchestrator, _user_input: str, _user_id: str, _session_id: str
):
response: AgentResponse = await _orchestrator.route_request(
_user_input, _user_id, _session_id
)
# Print metadata
print("\nMetadata:")
print(f"Selected Agent: {response.metadata.agent_name}")
if response.streaming:
print("Response:", response.output.content[0]["text"])
else:
print("Response:", response.output.content[0]["text"])
if __name__ == "__main__":
USER_ID = "user123"
SESSION_ID = str(uuid.uuid4())
print("Welcome to the interactive Multi-Agent system. Type 'quit' to exit.")
while True:
# Get user input
user_input = input("\nYou: ").strip()
if user_input.lower() == "quit":
print("Exiting the program. Goodbye!")
sys.exit()
# Run the async function
asyncio.run(handle_request(orchestrator, user_input, USER_ID, SESSION_ID))Si vous pouvez demander et recevoir une réponse, tout fonctionne bien.
Le référentiel AWS Multi-Agent Orchestrator fournit plusieurs projets d'exemple en TypeScript et en Python. Nous allons maintenant écrire une application Python simplifiée composée de deux agents : L'agent développeur Python et l'agent expert ML.
Nous utiliserons également Chainlit, un paquetage Python open-source, pour mettre en œuvre une interface utilisateur simple pour l'application. Pour commencer, installez les bibliothèques nécessaires :
chainlit==1.2.0
multi_agent_orchestrator==0.0.18Nous utilisons le code ci-dessous pour notre application de démonstration, mais commençons par l'expliquer :
“anthropic.claude-3-haiku-20240307-v1:0” comme modèle pour notre classificateur. Ce classificateur choisira l'agent à utiliser lors de l'arrivée d'une nouvelle entrée utilisateur.MultiAgentOrchestrator et définissons certaines configurations.BedrockLLMAgent est utilisée pour créer nos agents. Chaque agent dispose d'un site name et d'un site description. Pour un agent, vous pouvez choisir n'importe lequel des modèles accessibles ou même utiliser Ollama pour les exécuter localement. En définissant streaming=True et en passant ChainlitAgentCallbacks() comme callback, les agents renverront des réponses en continu plutôt que complètes. Enfin, nous ajoutons chaque agent à l'orchestrateur.user_session est défini, ainsi que la section principale qui traite les messages de l'utilisateur et de l'agent.### 1
import uuid
import chainlit as cl
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator, OrchestratorConfig
from multi_agent_orchestrator.classifiers import BedrockClassifier, BedrockClassifierOptions
from multi_agent_orchestrator.agents import AgentResponse
from multi_agent_orchestrator.agents import BedrockLLMAgent, BedrockLLMAgentOptions, AgentCallbacks
from multi_agent_orchestrator.orchestrator import MultiAgentOrchestrator
from multi_agent_orchestrator.types import ConversationMessage
import asyncio
import chainlit as cl
class ChainlitAgentCallbacks(AgentCallbacks):
def on_llm_new_token(self, token: str) -> None:
asyncio.run(cl.user_session.get("current_msg").stream_token(token))
### 2
# Initialize the orchestrator & classifier
custom_bedrock_classifier = BedrockClassifier(BedrockClassifierOptions(
model_id='anthropic.claude-3-haiku-20240307-v1:0',
inference_config={
'maxTokens': 500,
'temperature': 0.7,
'topP': 0.9
}
))
### 3
orchestrator = MultiAgentOrchestrator(options=OrchestratorConfig(
LOG_AGENT_CHAT=True,
LOG_CLASSIFIER_CHAT=True,
LOG_CLASSIFIER_RAW_OUTPUT=True,
LOG_CLASSIFIER_OUTPUT=True,
LOG_EXECUTION_TIMES=True,
MAX_RETRIES=3,
USE_DEFAULT_AGENT_IF_NONE_IDENTIFIED=False,
MAX_MESSAGE_PAIRS_PER_AGENT=10,
),
classifier=custom_bedrock_classifier
)
### 4
def create_python_dev():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Python Developer Agent",
streaming=True,
description="Experienced Python developer specialized in writing, debugging, and evaluating only Python code.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
def create_ml_expert():
return BedrockLLMAgent(BedrockLLMAgentOptions(
name="Machine Learning Expert",
streaming=True,
description="Expert in areas related to machine learning including deep learning, pytorch, tensorflow, scikit-learn, and large language models.",
model_id="anthropic.claude-3-sonnet-20240229-v1:0",
callbacks=ChainlitAgentCallbacks()
))
# Add agents to the orchestrator
orchestrator.add_agent(create_python_dev())
orchestrator.add_agent(create_ml_expert())
### 5
@cl.on_chat_start
async def start():
cl.user_session.set("user_id", str(uuid.uuid4()))
cl.user_session.set("session_id", str(uuid.uuid4()))
cl.user_session.set("chat_history", [])
@cl.on_message
async def main(message: cl.Message):
user_id = cl.user_session.get("user_id")
session_id = cl.user_session.get("session_id")
msg = cl.Message(content="")
await msg.send() # Send the message immediately to start streaming
cl.user_session.set("current_msg", msg)
response:AgentResponse = await orchestrator.route_request(message.content, user_id, session_id, {})
# Handle non-streaming or problematic responses
if isinstance(response, AgentResponse) and response.streaming is False:
# Handle regular response
if isinstance(response.output, str):
await msg.stream_token(response.output)
elif isinstance(response.output, ConversationMessage):
await msg.stream_token(response.output.content[0].get('text'))
await msg.update()
if __name__ == "__main__":
cl.run()Il est maintenant temps d'exécuter l'application. Pour ce faire, exécutez d'abord chainlit run [app.py](<http://app.py/>) -w. Vous pouvez maintenant tester votre application dans le nouvel onglet ouvert dans votre navigateur.
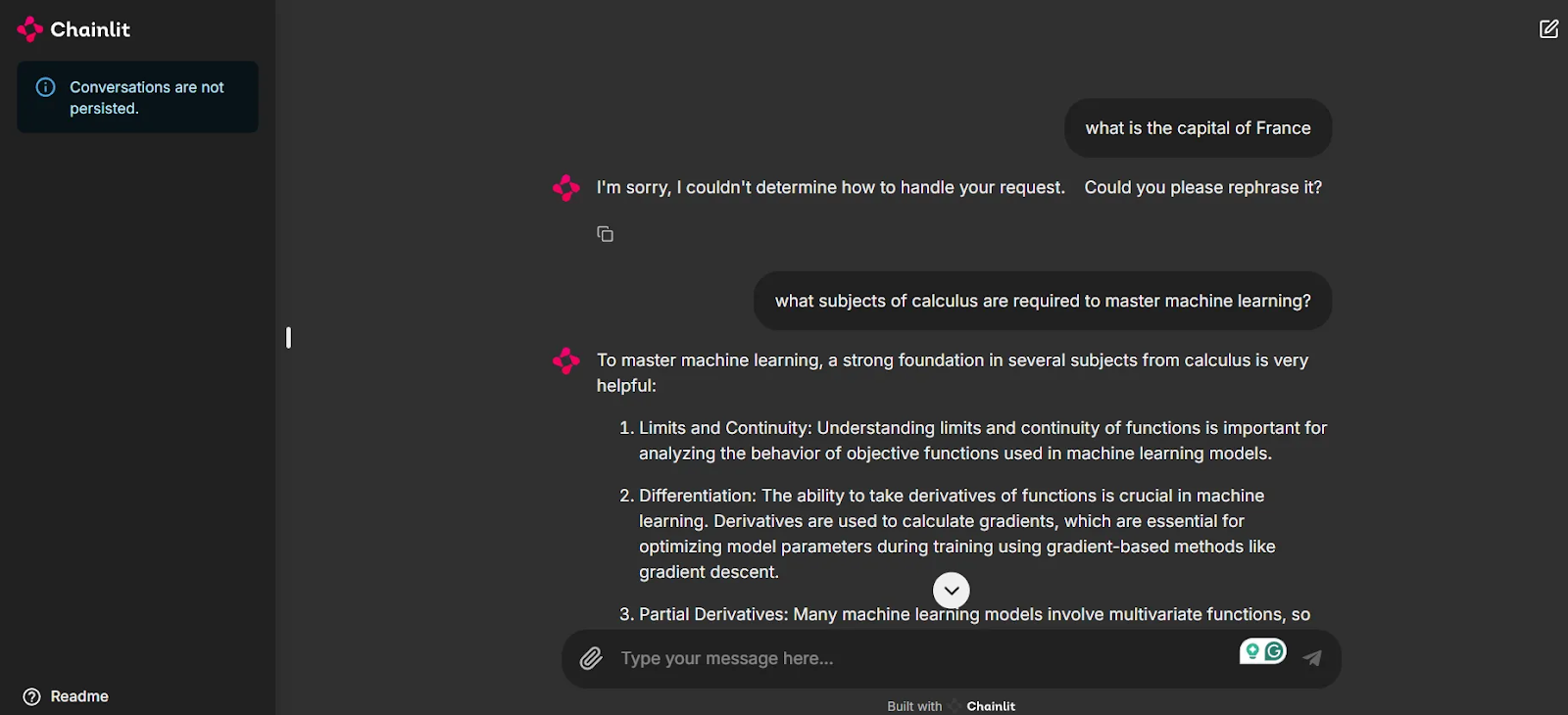
Comme vous pouvez le voir dans la capture d'écran, nous disposons maintenant d'une interface utilisateur pour tester notre application et discuter avec les agents.
Remarquez que la première question "Quelle est la capitale de la France ?" n'étant liée à aucun de nos agents, le système ne fournit pas de réponse. C'est la clé pour que les chats restent pertinents et pour éviter de dépenser des crédits inutiles lorsque vous utilisez ces modèles. Cependant, lorsqu'une question connexe est posée, notreagent Machine Learning Expert entre en jeu pour donner une réponse, grâce au routage intelligent de l'Orchestrateur Multi-Agents.
Dans ce blog, nous avons présenté le récent cadre AWS Multi-Agent Orchestrator, souligné certaines de ses caractéristiques uniques, décrit les étapes pour configurer l'environnement, exploré les modèles fondamentaux servis par Amazon Bedrock, et mis en œuvre un projet de démonstration.
Au moment de la rédaction de cet article, le cadre ne dispose pas d'une documentation complète et détaillée. Pour bénéficier d'autres fonctionnalités, telles que l'utilisation de la mémoire et des outils, vous devez lire la base de code et jeter un coup d'œil aux projets d'exemple fournis.
Garder un œil curieux sur les cadres de l'IA agentique est un choix judicieux pour suivre l'évolution de ce domaine en plein essor. L'AWS Multi-Agent Orchestrator est une option prometteuse construite sur les infrastructures des services AWS, et son développement mérite d'être suivi.
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Fereshteh Forough
4 min