Kurs
Datenbereinigung mit PySpark
4 Std.
33.2K
Daten, die kategorisiert werden können, aber keine inhärente Hierarchie oder Ordnung haben, werden als kategorische Daten bezeichnet. Mit anderen Worten: Es gibt keine mathematische Verbindung zwischen den Kategorien. Das Geschlecht einer Person (männlich/weiblich), die Augenfarbe (blau, grün, braun usw.), die Art des Fahrzeugs, das sie fährt (Limousine, Geländewagen, Lkw usw.), oder die Art der Früchte, die sie isst (Apfel, Banane, Orange usw.), sind Beispiele für kategorische Daten.
In diesem Lernprogramm werden wir die Methoden zur Verarbeitung und Vorverarbeitung von kategorialen Daten erläutern. Bevor wir die Bedeutung der Aufbereitung kategorischer Daten für Machine-Learning-Modelle diskutieren, definieren wir zunächst kategorische Daten und ihre Typen. Außerdem werden wir uns verschiedene Kodierungsmethoden, Methoden zur Analyse und Visualisierung von kategorialen Daten in Python und fortgeschrittene Ideen wie kategoriale Daten mit großer Kardinalität und verschiedene Kodierungsmethoden ansehen.
Informationen werden durch zwei verschiedene Formen von Daten dargestellt: kategorische Daten und numerische Daten. Daten, die kategorisiert oder in Gruppen zusammengefasst werden können, werden als kategorische Daten bezeichnet. Männer und Frauen fallen in die Kategorie Geschlecht, die Farben Rot, Grün und Blau fallen in die Kategorie Farben und die Kategorie Länder könnte die USA, Kanada, Mexiko usw. umfassen.
Numerische Daten beziehen sich auf Daten, die als Zahl ausgedrückt werden können. Beispiele für numerische Daten sind Größe, Gewicht und Temperatur.
Da die meisten Algorithmen für maschinelles Lernen für numerische Daten entwickelt wurden, werden kategorische Daten in diesem Bereich anders behandelt als numerische Daten. Bevor kategorische Daten als Input für ein maschinelles Lernmodell verwendet werden können, müssen sie zunächst in numerische Daten umgewandelt werden. Dieser Prozess der Umwandlung kategorischer Daten in eine numerische Darstellung wird als Kodierung bezeichnet.
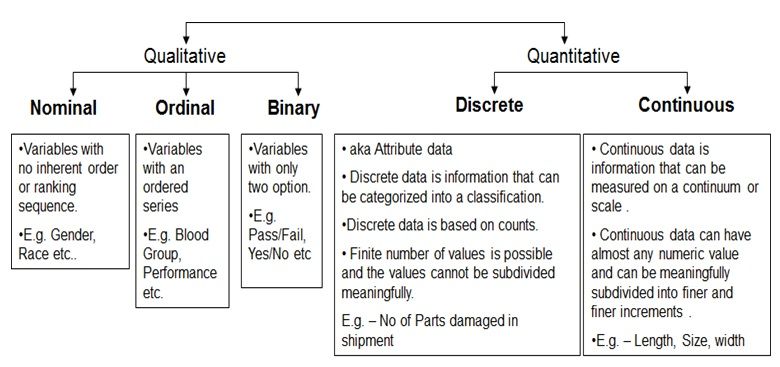
Qualitative und Quantitative Daten - Bildquelle
Es gibt zwei Arten von kategorialen Daten: nominale und ordinale.
Nominale Daten sind kategorische Daten, die in Gruppen eingeteilt werden können, denen aber keine Hierarchie oder Ordnung innewohnt. Beispiele für nominale Daten sind Markennamen (Coca-Cola, Pepsi, Sprite), Sorten von Pizzabelägen (Peperoni, Pilze, Zwiebeln) und Haarfarben (blond, braun, schwarz usw.). In unserem Leitfaden über nominale Variablen erfährst du mehr.
Ordinale Daten hingegen beschreiben Informationen, die kategorisiert werden können und eine bestimmte Reihenfolge oder Rangfolge haben. Das Bildungsniveau (High School, Bachelor, Master), die Arbeitszufriedenheit (sehr zufrieden, zufrieden, neutral, unzufrieden, sehr unzufrieden) und die Sternebewertung (1 Stern, 2 Sterne, 3 Sterne, 4 Sterne, 5 Sterne) sind einige Beispiele für ordinale Daten.
Indem man jeder Kategorie einen numerischen Wert gibt, der ihre Reihenfolge oder Rangfolge widerspiegelt, können Ordinaldaten in numerische Daten umgewandelt und beim maschinellen Lernen verwendet werden. Für Algorithmen, die empfindlich auf die Größe der Eingabedaten reagieren, kann dies hilfreich sein.
Die Unterscheidung zwischen nominalen und ordinalen Daten ist in der Praxis nicht immer offensichtlich und kann je nach Anwendungsfall variieren. Während manche Leute zum Beispiel die "Sterne-Bewertung" als ordinale Daten betrachten, können andere sie als nominale Daten betrachten. Das Wichtigste ist, dass du dir über die Beschaffenheit deiner Daten bewusst bist und die Kodierungsstrategie wählst, die die Beziehungen in deinen Daten am besten erfasst.
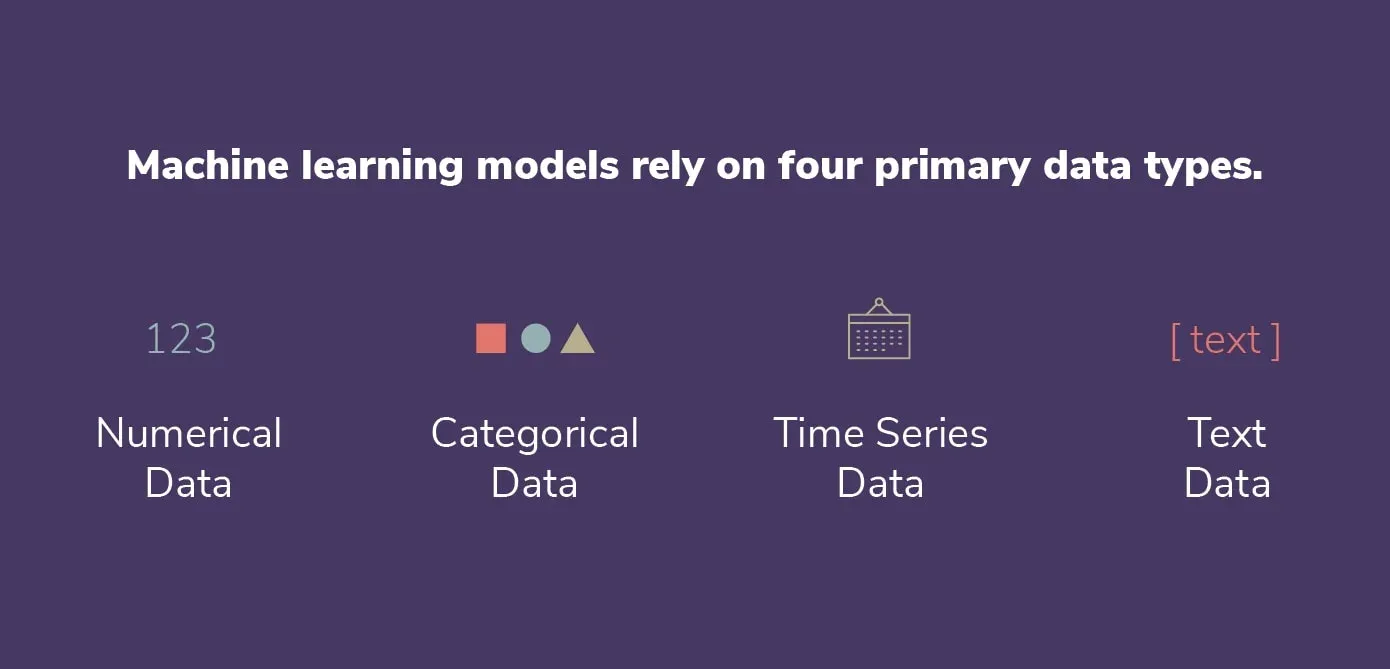
Die weit verbreitete Python Open-Source-Bibliothek pandas wird für die Datenanalyse und -manipulation verwendet. Es verfügt über leistungsstarke Funktionen für den Umgang mit strukturierten Daten, z. B. in Form von Datenrahmen und -reihen, die mit tabellarischen Daten mit beschrifteten Zeilen und Spalten umgehen können.
pandas bietet außerdem mehrere Funktionen zum Lesen und Schreiben verschiedener Dateitypen (csv, parquet, Datenbank usw.). Wenn du eine Datei mit Pandas liest, wird jeder Spalte ein Datentyp zugewiesen, der auf der Inferenz basiert. Hier sind alle Datentypen, die Pandas möglicherweise zuweisen kann:
Daten, die nicht in die anderen Datentypen passen, wie z. B. Strings, gemischte Arten oder andere Objekte, werden in Pandas durch die Kategorie- und Objektdatentypen dargestellt. Es gibt jedoch ein paar wichtige Unterschiede, die sich auf ihre Funktionsweise und Leistung auswirken.
Der kategoriale Datentyp wurde für Informationen geschaffen, die nur wenige mögliche Werte haben, wie Kategorien oder Etiketten. Intern werden kategorische Daten als eine Sammlung von Zahlen dargestellt, was im Vergleich zum entsprechenden Objektdatentyp einige Operationen beschleunigen und Speicherplatz sparen kann. Außerdem können kategorische Daten logisch angeordnet werden und erleichtern effektive Gruppierungs- und Aggregationsverfahren.
Auf der anderen Seite dient der Objektdatentyp als Auffangbecken für Informationen, die nicht in die anderen Datentypen passen. Listen, Wörterbücher und andere Objekte sind nur ein paar Beispiele für die vielen verschiedenen Arten von Daten, die sie enthalten können. Obwohl Objektdaten sehr flexibel sind, können sie auch langsamer sein und mehr Speicherplatz verbrauchen als kategorische Daten derselben Größe und einige der speziellen Operationen, die mit Kategoriedaten möglich sind, können nicht durchgeführt werden.
Im Allgemeinen solltest du den kategorialen Datentyp verwenden, wenn deine Daten nur eine kleine Anzahl möglicher Werte haben und du sie häufig gruppieren oder aggregieren möchtest. In allen anderen Fällen ist der Objektdatentyp normalerweise eine sichere Option. Der ideale Datentyp hängt jedoch letztendlich von deinem speziellen Anwendungsfall und den Eigenschaften deiner Daten ab.
Sehen wir uns ein Beispiel an, indem wir eine csv-Datei von GitHub lesen.
# read csv using pandas
data = pd.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
# check the head of dataframe
data.head()Ausgabe:
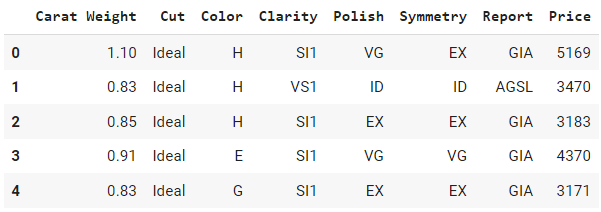
Kannst du erkennen, welche dieser Spalten kategorisch und welche numerisch sind? Alle Spalten in diesem Beispiel sind kategorisch, mit Ausnahme von "Karat-Gewicht" und "Preis". Um zu sehen, ob wir damit richtig liegen, überprüfen wir die Standard-Datentypen.
# check the data types
data.dtypesAusgabe:

Beachte, dass der "Preis" dem Typ "int64" zugewiesen ist, das "Karat-Gewicht" dem Typ "float64" und der Rest der Spalten Objekte sind, genau wie wir es erwartet haben.
In pandas, einer beliebten Datenanalysebibliothek in Python, gibt es ein paar Funktionen, mit denen du kategoriale Datentypen in deinem Datensatz schnell analysieren kannst. Lasst uns diese nacheinander untersuchen:
value_counts() ist eine Funktion in der Pandas-Bibliothek, die die Häufigkeit jedes einzelnen Wertes in einer kategorialen Datenspalte zurückgibt. Diese Funktion ist nützlich, wenn du dir einen schnellen Überblick über die Verteilung einer kategorialen Variable verschaffen willst, z. B. über die häufigsten Kategorien und ihre Häufigkeit.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check value counts of Cut column
data['Cut'].value_counts()Ausgabe:

Wenn du die Verteilung visualisieren willst, kannst du mit der Bibliothek `plotly` ein interaktives Balkendiagramm zeichnen.
import plotly.express as px
cut_counts = data['Cut'].value_counts()
fig = px.bar(x=cut_counts.index, y=cut_counts.values)
fig.show()Ausgabe:
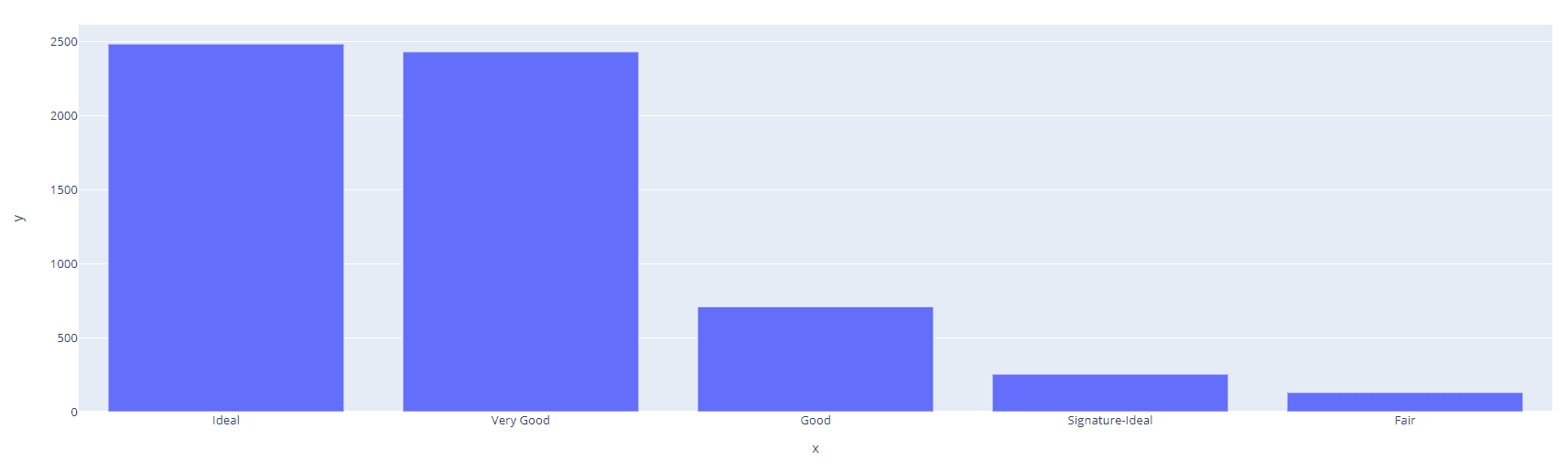
groupby() ist eine Funktion in Pandas, mit der du Daten nach einer oder mehreren Spalten gruppieren und Aggregatfunktionen wie Summe, Mittelwert und Anzahl anwenden kannst. Diese Funktion ist nützlich, wenn du komplexere Analysen für kategoriale Daten durchführen willst, z. B. um den Durchschnitt einer numerischen Variable für jede Kategorie zu berechnen. Sehen wir uns ein Beispiel an:
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# average carat weight and price by Cut
data.groupby(by = 'Cut').mean()Ausgabe:
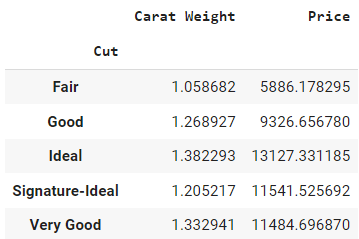
Es wird nur ein Datenrahmen mit numerischen Spalten zurückgegeben. Der "by"-Parameter innerhalb der "groupby"-Methode legt die Spalte fest, für die du die Gruppierung durchführen willst, und der "mean()"-Parameter außerhalb der Klammern ist die Aggregationsmethode.
Das Ergebnis kann so interpretiert werden, dass der Durchschnittspreis eines Diamanten mit fairem Schliff bei 5.886 liegt und das Durchschnittsgewicht 1,05 beträgt, verglichen mit dem Durchschnittspreis von 11.485 für einen Diamanten mit sehr gutem Schliff.
crosstab() ist eine Funktion in Pandas, die eine Kreuztabelle erstellt, die die Häufigkeitsverteilung von zwei oder mehr kategorialen Variablen anzeigt. Diese Funktion ist nützlich, wenn du die Beziehung zwischen zwei oder mehr kategorialen Variablen sehen willst, z. B. wie die Häufigkeit einer Variable mit einer anderen Variable zusammenhängt.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# cross tab of Cut and Color
pd.crosstab(index=data['Cut'], columns=data['Color'])
Ausgabe:
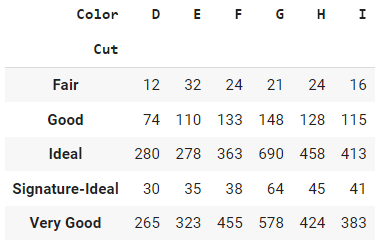
Die Ausgabe der Kreuztabellenfunktion in Pandas ist eine Tabelle, die die Häufigkeitsverteilung von zwei oder mehr kategorialen Variablen zeigt. Jede Zeile der Tabelle steht für eine eindeutige Kategorie in einer der Variablen, und jede Spalte steht für eine eindeutige Kategorie in der anderen Variable. Die Einträge in der Tabelle sind die Häufigkeitszahlen der Kombinationen von Kategorien in den beiden Variablen.
pivot_table()` ist eine Funktion in Pandas, die Pivot-Tabellen erstellt, die ähnlich wie Kreuztabellen sind, aber mehr Flexibilität bieten. Diese Funktion ist nützlich, wenn du mehrere kategoriale Variablen und ihre Beziehung zu einer oder mehreren numerischen Variablen analysieren willst. Mit Pivot-Tabellen kannst du Daten auf verschiedene Arten aggregieren und die Ergebnisse in kompakter Form anzeigen.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# create pivot table
pd.pivot_table(data, values='Price', index='Cut', columns='Color', aggfunc=np.mean)
Ausgabe:
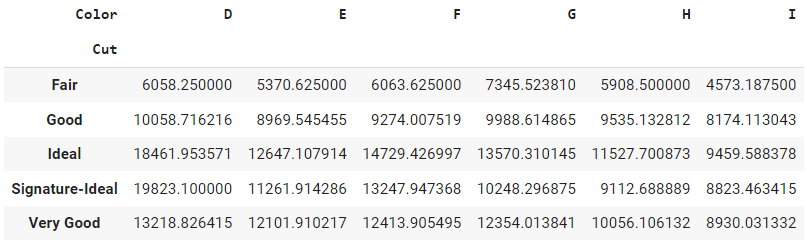
Diese Tabelle zeigt den Durchschnittspreis für jeden Diamantenschliff und jede Farbe. Die Zeilen stehen für die verschiedenen Diamantschliffe, die Spalten für die verschiedenen Diamantfarben und die Einträge in der Tabelle für den Durchschnittspreis des Diamanten.
Die Funktion pivot_table ist nützlich, wenn du numerische Daten über mehrere Variablen in einem Tabellenformat zusammenfassen und vergleichen möchtest. Mit dieser Funktion kannst du die Daten mit verschiedenen Funktionen (z. B. Mittelwert, Summe, Anzahl usw.) zusammenfassen und in ein Format bringen, das leicht zu lesen und zu analysieren ist.
Kategoriale Daten können in der Regel nicht direkt von Algorithmen des maschinellen Lernens verarbeitet werden, da die meisten Algorithmen in erster Linie nur für numerische Daten ausgelegt sind. Bevor kategoriale Merkmale als Input für Algorithmen des maschinellen Lernens verwendet werden können, müssen sie daher als numerische Werte kodiert werden.
Es gibt verschiedene Techniken, um kategoriale Merkmale zu kodieren, z. B. One-Hot-Encoding, Ordinal-Encoding und Target-Encoding. Die Wahl der Kodierungstechnik hängt von den spezifischen Merkmalen der Daten und den Anforderungen des verwendeten maschinellen Lernalgorithmus ab.
Eine heiße Kodierung ist ein Prozess, bei dem kategoriale Daten als eine Menge von Binärwerten dargestellt werden, wobei jede Kategorie einem eindeutigen Binärwert zugeordnet wird. Bei dieser Darstellung wird nur ein Bit auf 1 gesetzt und die anderen auf 0, daher der Name "one hot". Dies wird häufig beim maschinellen Lernen verwendet, um kategorische Daten in ein Format umzuwandeln, das Algorithmen verarbeiten können.
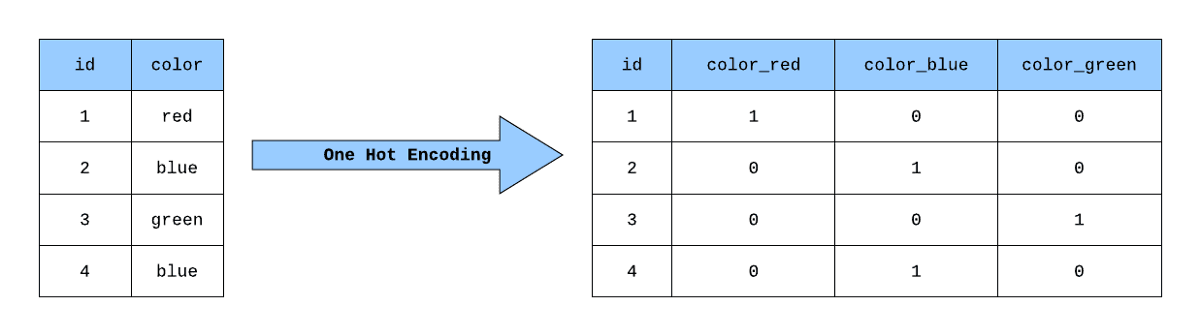
Eine Möglichkeit, dies in Pandas zu erreichen, ist die Methode `pd.get_dummies()`. Es handelt sich um eine Funktion in der Pandas-Bibliothek, mit der kategoriale Variablen in einem DataFrame mit einem Schlag kodiert werden können. Sie nimmt einen DataFrame und gibt einen neuen DataFrame mit binären Spalten für jede Kategorie zurück. Hier ist ein Beispiel dafür, wie du es verwenden kannst:
Angenommen, wir haben einen Datenrahmen mit einer Spalte "Obst", die kategoriale Daten enthält:
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# show head
df = pd.DataFrame(data)
df.head()
Ausgabe:

# apply get_dummies function
df_encoded = pd.get_dummies(df["fruit"])
df_encoded .head()
Ausgabe:
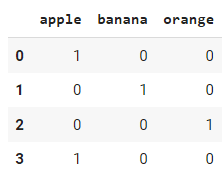
Auch wenn `pandas.get_dummies` einfach zu benutzen ist, ist es gängiger, `OneHotEncoder` aus der sklearn-Bibliothek zu verwenden, vor allem wenn du Aufgaben des maschinellen Lernens erledigst. Der Hauptunterschied ist, dass `pandas.get_dummies` keine Kodierungen lernen kann; es kann nur eine One-Hot-Kodierung für den Datensatz durchführen, den du als Eingabe übergibst. Sklearn.OneHotEncoder" ist eine Klasse, die gespeichert und in Zukunft für die Umwandlung anderer eingehender Datensätze verwendet werden kann.
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# one-hot-encode using sklearn
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded_results = encoder.fit_transform(df).toarray()
Ausgabe:
Die Label-Kodierung ist eine Technik zur Kodierung kategorischer Variablen als numerische Werte, wobei jeder Kategorie eine eindeutige ganze Zahl zugeordnet wird. Nehmen wir zum Beispiel an, wir haben eine kategoriale Variable "Farbe" mit drei Kategorien: "rot", "grün" und "blau". Wir können diese Kategorien mit Hilfe des Label-Encoding wie folgt kodieren (rot: 0, grün: 1, blau: 2).
Die Kodierung von Bezeichnungen kann für einige Algorithmen des maschinellen Lernens, die numerische Eingaben benötigen, nützlich sein, da sie es ermöglicht, kategoriale Daten so darzustellen, dass die Algorithmen sie verstehen können. Es ist jedoch wichtig zu bedenken, dass die Kodierung von Labels eine willkürliche Reihenfolge der Kategorien einführt, die nicht unbedingt eine sinnvolle Beziehung zwischen ihnen widerspiegelt. In manchen Fällen kann dies zu Problemen bei der Analyse führen, vor allem, wenn die Reihenfolge als eine Art ordinale Beziehung interpretiert wird.
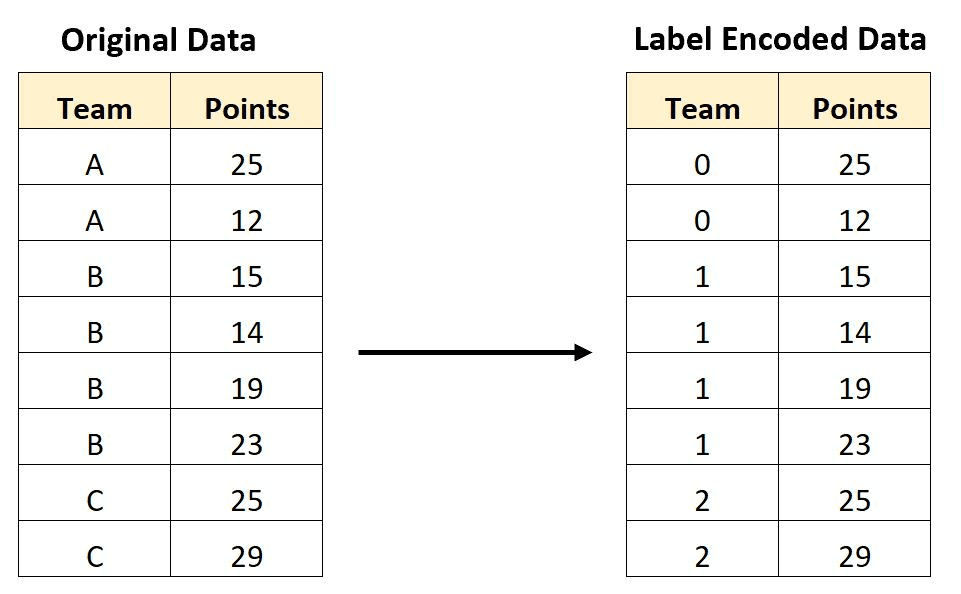
Kodierte Daten beschriften. Bildquelle
One-Hot-Encoding und Label-Encoding sind beides Techniken, um kategoriale Variablen als numerische Werte zu kodieren, aber sie haben unterschiedliche Eigenschaften und sind für verschiedene Anwendungsfälle geeignet.
Die One-Hot-Kodierung stellt jede Kategorie als binäre Spalte dar, wobei eine 1 das Vorhandensein der Kategorie und eine 0 ihr Fehlen anzeigt. Nehmen wir zum Beispiel an, wir haben eine kategoriale Variable "Farbe" mit drei Kategorien: "rot", "grün" und "blau". Bei der One-Hot-Codierung würde diese Variable als drei binäre Spalten dargestellt:
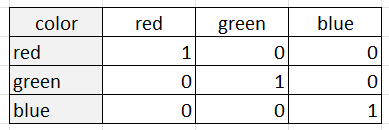
Eine einseitige Kodierung ist angebracht, wenn die Kategorien keine eigene Ordnung oder Beziehung zueinander haben. Das liegt daran, dass bei der One-Hot-Codierung jede Kategorie als eigenständige Einheit behandelt wird, die keine Beziehung zu den anderen Kategorien hat. Die One-Hot-Codierung ist auch nützlich, wenn die Anzahl der Kategorien relativ klein ist, da die Anzahl der Spalten bei einer sehr großen Anzahl von Kategorien unhandlich werden kann.
Bei der Label-Kodierung hingegen wird jede Kategorie als eindeutige Ganzzahl dargestellt. Zum Beispiel könnte die Variable "Farbe" mit drei Kategorien als Label kodiert werden:
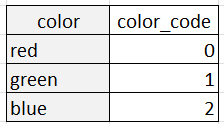
Die Kodierung von Bezeichnungen ist sinnvoll, wenn die Kategorien eine natürliche Reihenfolge oder Beziehung zueinander haben, wie z. B. bei ordinalen Variablen wie "klein", "mittel" und "groß". In diesen Fällen sollten die ganzzahligen Werte, die den Kategorien zugewiesen werden, die Reihenfolge der Kategorien widerspiegeln. Die Labelcodierung kann auch nützlich sein, wenn die Anzahl der Kategorien sehr groß ist, da sie die Dimensionalität der Daten reduziert.
Im Allgemeinen wird die One-Hot-Kodierung in Anwendungen des maschinellen Lernens häufiger verwendet, da sie flexibler ist und die Probleme der Mehrdeutigkeit und der willkürlichen Anordnung vermeidet, die bei der Label-Kodierung auftreten können. In bestimmten Kontexten, in denen die Kategorien eine natürliche Reihenfolge haben, oder bei einer sehr großen Anzahl von Kategorien kann die Kodierung von Bezeichnungen jedoch nützlich sein.
Eine hohe Kardinalität bezieht sich auf eine große Anzahl von eindeutigen Kategorien in einem kategorialen Merkmal. Der Umgang mit hoher Kardinalität ist eine häufige Herausforderung bei der Kodierung kategorischer Daten für maschinelle Lernmodelle. Eine hohe Kardinalität kann zu einer spärlichen Datendarstellung führen und sich negativ auf die Leistung einiger Machine-Learning-Modelle auswirken. Hier sind einige Techniken, die bei hoher Kardinalität in kategorialen Merkmalen eingesetzt werden können:
Dabei werden unregelmäßige Kategorien zu einer einzigen Kategorie zusammengefasst. Dadurch verringert sich die Anzahl der eindeutigen Kategorien und auch die Sparsamkeit in der Datendarstellung.
Bei der Zielkodierung werden die kategorialen Werte durch den mittleren Zielwert der jeweiligen Kategorie ersetzt. Sie bietet eine kontinuierlichere Darstellung der kategorialen Daten und kann helfen, die Beziehung zwischen dem kategorialen Merkmal und der Zielvariable zu erfassen.
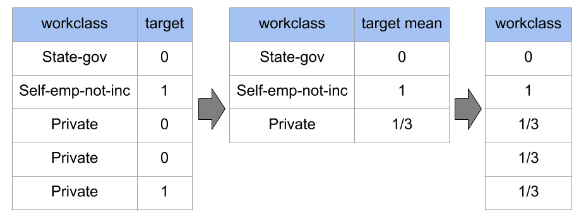
Das Weight of Evidence-Encoding ist ähnlich wie das Target-Encoding, berücksichtigt aber die Verteilung der Zielvariable für jede Kategorie. Der WOE einer Kategorie wird als Logarithmus des Verhältnisses zwischen dem Mittelwert des Ziels für die Kategorie und dem Mittelwert für die gesamte Population berechnet.
Das Feature-Engineering ist ein wichtiger Schritt bei der Vorbereitung von Daten für Machine-Learning-Modelle. Dabei werden neue Merkmale aus den vorhandenen Merkmalen erstellt, um die Leistung der Modelle zu verbessern. Hier sind ein paar Möglichkeiten, wie du kategoriale Daten mit Hilfe von Feature Engineering bearbeiten kannst:
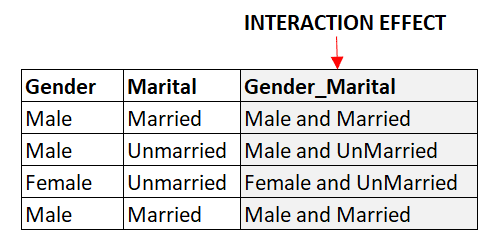
Interaktionsvariablen sind neue Merkmale, die durch die Kombination von zwei oder mehr bestehenden Merkmalen entstehen. Wenn wir zum Beispiel zwei kategoriale Merkmale haben, "Geschlecht" und "Familienstand", können wir ein neues Merkmal "Geschlecht - Familienstand" erstellen, um die Interaktion zwischen den beiden Merkmalen zu erfassen. Dies kann helfen, nicht-lineare Beziehungen zwischen den Merkmalen und der Zielvariablen zu erfassen.
Beim Binning werden kontinuierliche numerische Variablen in diskrete Bins unterteilt. Dies kann dazu beitragen, die Anzahl der eindeutigen Werte im Merkmal zu reduzieren, was bei der Codierung kategorischer Daten von Vorteil sein kann. Binning kann auch dabei helfen, nicht-lineare Beziehungen zwischen den Merkmalen und der Zielvariablen zu erfassen.
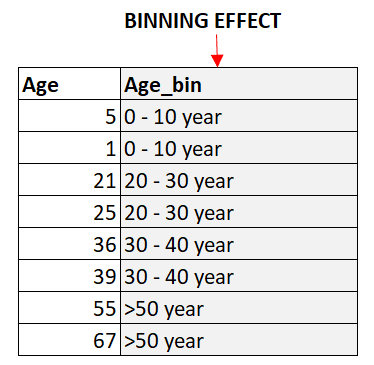
Zyklische Variablen sind Variablen, die sich über einen bestimmten Zeitraum wiederholen. Die Stunde des Tages ist zum Beispiel eine zyklische Variable, da sie sich alle 24 Stunden wiederholt. Die Codierung zyklischer Variablen kann helfen, die periodischen Muster in den Daten zu erfassen. Ein gängiger Ansatz zur Kodierung zyklischer Variablen besteht darin, zwei neue Merkmale zu erstellen, von denen eines den Sinus der Variablen und das andere den Kosinus der Variablen darstellt.
Erlerne die Fähigkeiten, die du brauchst, in deinem eigenen Tempo - von den Grundlagen der Nicht-Programmierung bis hin zu Data Science und maschinellem Lernen.
Erfahre mehr über Python
Kurs
Kurs
Kurs