Cours
Nettoyer des données avec PySpark
4 h
33.2K
Les données qui peuvent être catégorisées mais qui n'ont pas de hiérarchie ou d'ordre inhérent sont appelées données catégoriques. En d'autres termes, il n'y a pas de lien mathématique entre les catégories. Le sexe d'une personne (homme/femme), la couleur de ses yeux (bleu, vert, brun, etc.), le type de véhicule qu'elle conduit (berline, SUV, camion, etc.) ou le type de fruit qu'elle consomme (pomme, banane, orange, etc.) sont des exemples de données catégorielles.
Dans ce tutoriel, nous décrirons les méthodes de traitement et de prétraitement des données catégorielles. Avant d'aborder l'importance de la préparation des données catégorielles pour les modèles d'apprentissage automatique, nous allons d'abord définir les données catégorielles et leurs types. En outre, nous examinerons plusieurs méthodes d'encodage, des méthodes d'analyse et de visualisation de données catégorielles en Python, ainsi que des idées plus avancées comme les données catégorielles à grande cardinalité et diverses méthodes d'encodage.
Les informations sont représentées par deux formes de données différentes : les données catégorielles et les données numériques. Les données qui peuvent être catégorisées ou regroupées sont appelées données catégorielles. Les hommes et les femmes entrent dans la catégorie des sexes, les couleurs rouge, verte et bleue dans la catégorie des couleurs, et la catégorie des pays peut inclure les États-Unis, le Canada, le Mexique, etc.
Les données numériques sont des données qui peuvent être exprimées sous la forme d'un nombre. La taille, le poids et la température sont des exemples de données numériques.
En termes simples, les données catégorielles sont des informations qui peuvent être classées en catégories, tandis que les données numériques sont des informations qui peuvent être exprimées sous la forme d'un nombre.Comme la majorité des algorithmes d'apprentissage automatique sont créés pour fonctionner avec des données numériques, les données catégorielles sont traitées différemment des données numériques dans ce domaine. Avant que les données catégorielles puissent être utilisées comme entrées dans un modèle d'apprentissage automatique, elles doivent d'abord être transformées en données numériques. Ce processus de conversion des données catégorielles en représentation numérique est connu sous le nom d'encodage.
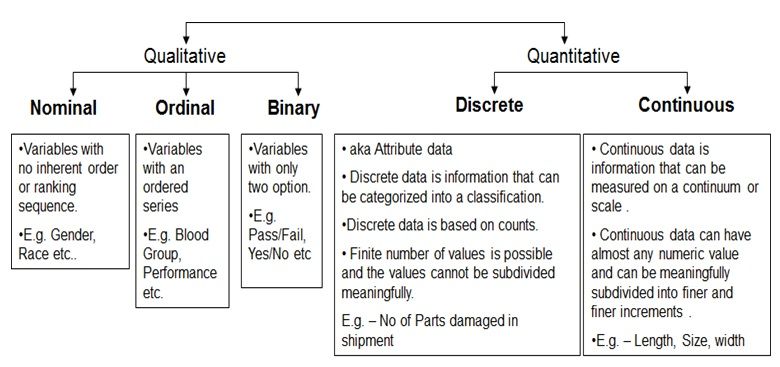
Données qualitatives et quantitatives - Source de l'image
Il existe deux types de données catégorielles : les données nominales et les données ordinales.
Les données nominales sont des données catégoriques qui peuvent être divisées en groupes, mais ces groupes n'ont pas de hiérarchie ou d'ordre intrinsèque. Les noms de marques (Coca-Cola, Pepsi, Sprite), les variétés de garnitures de pizza (pepperoni, champignons, oignons) et la couleur des cheveux (blonds, bruns, noirs, etc.) sont des exemples de données nominales. Consultez notre guide sur les variables nominales pour en savoir plus.
Les données ordinales, quant à elles, décrivent des informations qui peuvent être catégorisées et qui présentent un ordre ou un classement distinct. Les niveaux d'éducation (lycée, licence, maîtrise), les niveaux de satisfaction au travail (extrêmement satisfait, satisfait, neutre, insatisfait, très insatisfait) et les classements par étoiles (1 étoile, 2 étoiles, 3 étoiles, 4 étoiles, 5 étoiles) sont quelques exemples de données ordinales.
En donnant à chaque catégorie une valeur numérique qui reflète son ordre ou son classement, les données ordinales peuvent être transformées en données numériques et utilisées dans l'apprentissage automatique. Pour les algorithmes qui sont sensibles à la taille des données d'entrée, cela peut être utile.
La distinction entre les données nominales et ordinales n'est pas toujours évidente dans la pratique et peut varier en fonction du cas d'utilisation particulier. Par exemple, si certaines personnes considèrent le "classement par étoiles" comme une donnée ordinale, d'autres le considèrent comme une donnée nominale. Le plus important est d'être conscient de la nature de vos données et de choisir la stratégie d'encodage qui capture le mieux les relations dans vos données.
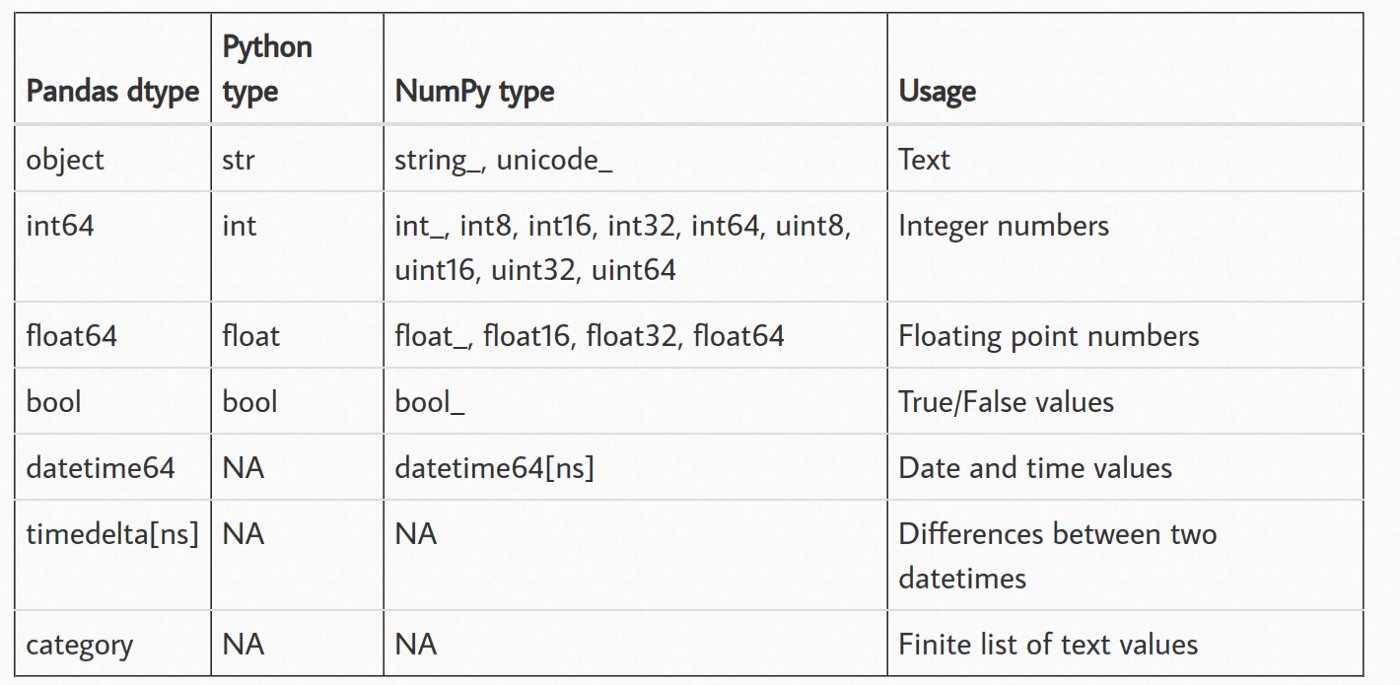
La bibliothèque open-source Python pandas, très répandue, est utilisée pour l'analyse et la manipulation des données. Il possède de solides capacités de traitement des données structurées, notamment sous la forme de cadres de données et de séries qui peuvent traiter des données tabulaires avec des lignes et des colonnes étiquetées.
pandas fournit également plusieurs fonctions pour lire et écrire différents types de fichiers (csv, parquet, base de données, etc.). Lorsque vous lisez un fichier à l'aide de pandas, chaque colonne se voit attribuer un type de données basé sur l'inférence. Voici tous les types de données que pandas peut attribuer :
Les données qui ne correspondent pas aux autres types de données, y compris les chaînes, les types mixtes ou d'autres objets, sont représentées par les types de données catégorie et objet dans pandas. Cependant, ils présentent quelques différences significatives qui ont un impact sur leur fonctionnement et leurs performances.
Le type de données catégoriques a été créé pour les informations qui n'ont que quelques valeurs possibles, comme les catégories ou les étiquettes. En interne, les données catégorielles sont représentées sous la forme d'une collection de nombres, ce qui permet d'accélérer certaines opérations et d'économiser de la mémoire par rapport au type de données objet correspondant. En outre, les données catégorielles peuvent être organisées de manière logique et facilitent des procédures de regroupement et d'agrégation efficaces.
D'autre part, le type de données objet sert de fourre-tout pour les informations qui n'entrent pas dans les autres types de données. Les listes, les dictionnaires et autres objets ne sont que quelques exemples des nombreux types de données qu'il peut contenir. Bien que les données objet offrent une grande flexibilité, elles peuvent également être plus lentes et consommer plus de mémoire que les données catégorielles de même taille et ne peuvent pas être soumises à certaines des opérations spécialisées possibles avec les données catégorielles.
En général, vous pouvez envisager d'utiliser le type de données catégoriques si vos données ont un petit nombre de valeurs possibles et si vous avez l'intention de faire beaucoup de regroupements ou d'agrégations. Le type de données objet est généralement une option sûre dans tous les autres cas. Le type de données idéal dépend toutefois de votre cas d'utilisation unique et des propriétés de vos données.
Prenons un exemple en lisant un fichier csv depuis GitHub.
# read csv using pandas
data = pd.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
# check the head of dataframe
data.head()Sortie :
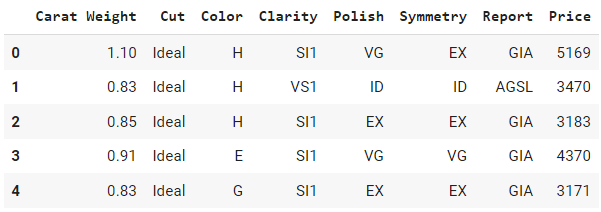
Pouvez-vous identifier parmi ces colonnes celles qui sont catégorielles et celles qui sont numériques ? Eh bien, toutes les colonnes de cet exemple sont catégoriques, à l'exception de `Poids du carat` et de `Prix.` Voyons si nous avons raison en vérifiant les types de données par défaut.
# check the data types
data.dtypesSortie :

Remarquez que `Price` est de type `int64`, `Poids du carat` de type `float64`, et que le reste des colonnes sont des objets, exactement comme nous l'avions prévu.
Il existe quelques fonctions dans pandas, une bibliothèque d'analyse de données populaire en Python, qui vous permettent d'analyser rapidement les types de données catégorielles dans votre ensemble de données. Examinons-les une à une :
`value_counts()` est une fonction de la bibliothèque pandas qui renvoie la fréquence de chaque valeur unique dans une colonne de données catégorielles. Cette fonction est utile lorsque vous souhaitez obtenir une compréhension rapide de la distribution d'une variable catégorielle, comme les catégories les plus courantes et leur fréquence.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check value counts of Cut column
data['Cut'].value_counts()Sortie :

Si vous souhaitez visualiser la distribution, vous pouvez utiliser la bibliothèque `plotly` pour dessiner un diagramme à barres interactif.
import plotly.express as px
cut_counts = data['Cut'].value_counts()
fig = px.bar(x=cut_counts.index, y=cut_counts.values)
fig.show()Sortie :
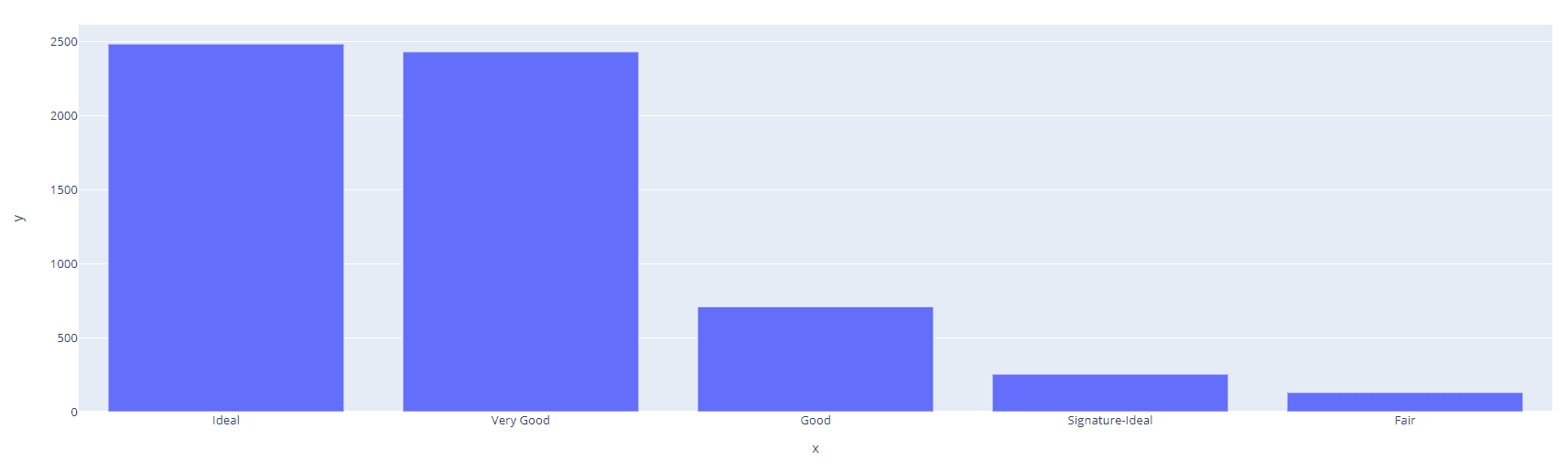
`groupby()` est une fonction de Pandas qui vous permet de regrouper des données par une ou plusieurs colonnes et d'appliquer des fonctions d'agrégation telles que la somme, la moyenne et le nombre. Cette fonction est utile lorsque vous souhaitez effectuer des analyses plus complexes sur des données catégorielles, telles que le calcul de la moyenne d'une variable numérique pour chaque catégorie. Prenons un exemple :
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# average carat weight and price by Cut
data.groupby(by = 'Cut').mean()Sortie :
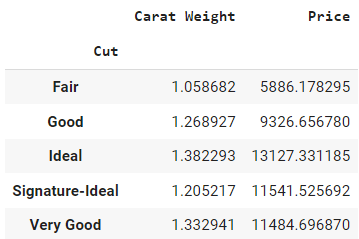
Il ne renverra qu'un cadre de données comportant uniquement des colonnes numériques. Le paramètre `by` à l'intérieur de la méthode `groupby` définit la colonne sur laquelle vous voulez effectuer l'opération de group by, puis `mean()` à l'extérieur des parenthèses est la méthode d'agrégation.
Le résultat peut être interprété comme le prix moyen d'un diamant de taille "fair" est de 5 886, et le poids moyen est de 1,05 par rapport au prix moyen de 11 485 pour un diamant de taille "very good".
`crosstab()` est une fonction de pandas qui crée un tableau croisé, qui montre la distribution de fréquence de deux ou plusieurs variables catégorielles. Cette fonction est utile lorsque vous voulez voir la relation entre deux ou plusieurs variables catégorielles, par exemple comment la fréquence d'une variable est liée à une autre variable.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# cross tab of Cut and Color
pd.crosstab(index=data['Cut'], columns=data['Color'])
Sortie :
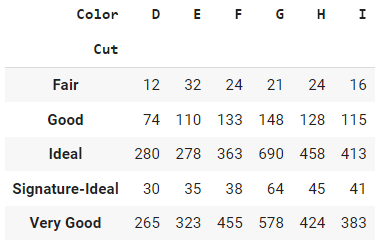
La sortie de la fonction crosstab dans pandas est un tableau qui montre la distribution de fréquence de deux variables catégorielles ou plus. Chaque ligne du tableau représente une catégorie unique dans l'une des variables, et chaque colonne représente une catégorie unique dans l'autre variable. Les entrées du tableau sont les comptes de fréquence des combinaisons de catégories dans les deux variables.
`pivot_table()` est une fonction de Pandas qui crée des tableaux croisés dynamiques, qui sont similaires aux tableaux croisés mais avec plus de flexibilité. Cette fonction est utile lorsque vous souhaitez analyser plusieurs variables catégorielles et leur relation avec une ou plusieurs variables numériques. Les tableaux croisés dynamiques vous permettent d'agréger des données de plusieurs façons et d'afficher les résultats sous une forme compacte.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# create pivot table
pd.pivot_table(data, values='Price', index='Cut', columns='Color', aggfunc=np.mean)
Sortie :
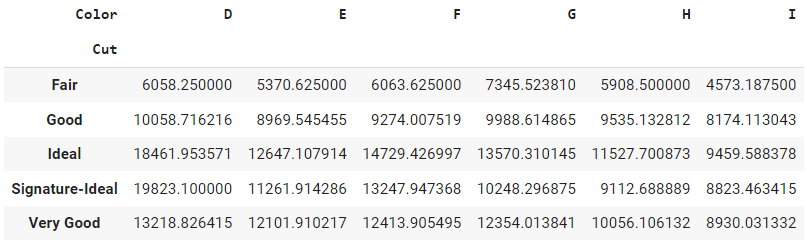
Ce tableau indique le prix moyen de chaque taille de diamant pour chaque couleur. Les tableaux représentent les différentes tailles de diamant, les colonnes représentent les différentes couleurs de diamant et les entrées du tableau correspondent au prix moyen du diamant.
La fonction tableau croisé dynamique est utile lorsque vous souhaitez résumer et comparer les données numériques de plusieurs variables sous la forme d'un tableau. Cette fonction vous permet d'agréger les données à l'aide de différentes fonctions (telles que la moyenne, la somme, le nombre, etc.) et de les organiser dans un format facile à lire et à analyser.
Les données catégorielles ne peuvent généralement pas être traitées directement par les algorithmes d'apprentissage automatique, car la plupart d'entre eux sont principalement conçus pour fonctionner avec des données numériques uniquement. Par conséquent, avant que les caractéristiques catégorielles puissent être utilisées comme entrées dans les algorithmes d'apprentissage automatique, elles doivent être codées sous forme de valeurs numériques.
Il existe plusieurs techniques d'encodage des caractéristiques catégorielles, notamment l'encodage d'un seul point, l'encodage ordinal et l'encodage de la cible. Le choix de la technique d'encodage dépend des caractéristiques spécifiques des données et des exigences de l'algorithme d'apprentissage automatique utilisé.
Le codage à chaud est un processus de représentation des données catégorielles sous la forme d'un ensemble de valeurs binaires, où chaque catégorie est associée à une valeur binaire unique. Dans cette représentation, un seul bit est mis à 1, et les autres sont mis à 0, d'où le nom "one hot". Cette méthode est couramment utilisée dans l'apprentissage automatique pour convertir les données catégorielles dans un format que les algorithmes peuvent traiter.
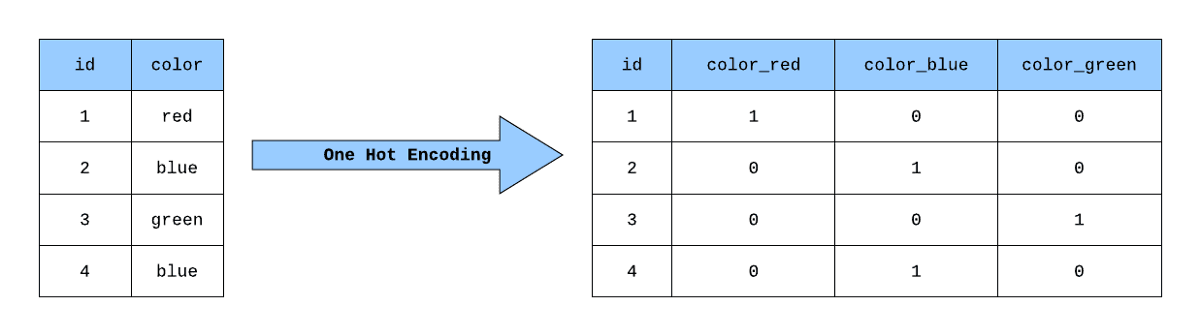
Une façon d'y parvenir dans pandas est d'utiliser la méthode `pd.get_dummies()`. Il s'agit d'une fonction de la bibliothèque Pandas qui peut être utilisée pour effectuer un encodage à un coup sur des variables catégorielles dans un DataFrame. Elle prend un DataFrame et renvoie un nouveau DataFrame avec des colonnes binaires pour chaque catégorie. Voici un exemple d'utilisation :
Supposons que nous ayons un cadre de données avec une colonne "fruit" contenant des données catégorielles :
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# show head
df = pd.DataFrame(data)
df.head()
Sortie :

# apply get_dummies function
df_encoded = pd.get_dummies(df["fruit"])
df_encoded .head()
Sortie :
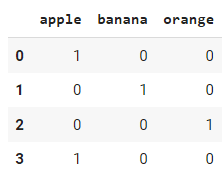
Même si `pandas.get_dummies` est facile à utiliser, une approche plus courante est d'utiliser `OneHotEncoder` de la bibliothèque sklearn, en particulier lorsque vous effectuez des tâches d'apprentissage automatique. La principale différence est que `pandas.get_dummies` ne peut pas apprendre les encodages ; il ne peut effectuer qu'un encodage à chaud sur le jeu de données que vous lui passez en entrée. D'autre part, `sklearn.OneHotEncoder` est une classe qui peut être sauvegardée et utilisée pour transformer d'autres ensembles de données à l'avenir.
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# one-hot-encode using sklearn
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded_results = encoder.fit_transform(df).toarray()
Sortie :
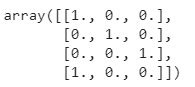
Le codage par étiquette est une technique permettant de coder des variables catégorielles sous forme de valeurs numériques, chaque catégorie se voyant attribuer un nombre entier unique. Par exemple, supposons que nous ayons une variable catégorielle "couleur" avec trois catégories : "rouge", "vert" et "bleu". Nous pouvons coder ces catégories en utilisant le codage des étiquettes comme suit (en rouge) : 0, vert : 1, bleu : 2).
Le codage des étiquettes peut être utile pour certains algorithmes d'apprentissage automatique qui nécessitent des entrées numériques, car il permet de représenter les données catégorielles d'une manière compréhensible pour les algorithmes. Cependant, il est important de garder à l'esprit que l'encodage des étiquettes introduit un ordre arbitraire des catégories, qui ne reflète pas nécessairement une relation significative entre elles. Dans certains cas, cela peut entraîner des problèmes dans l'analyse, en particulier si l'ordre est interprété comme ayant une sorte de relation ordinale.
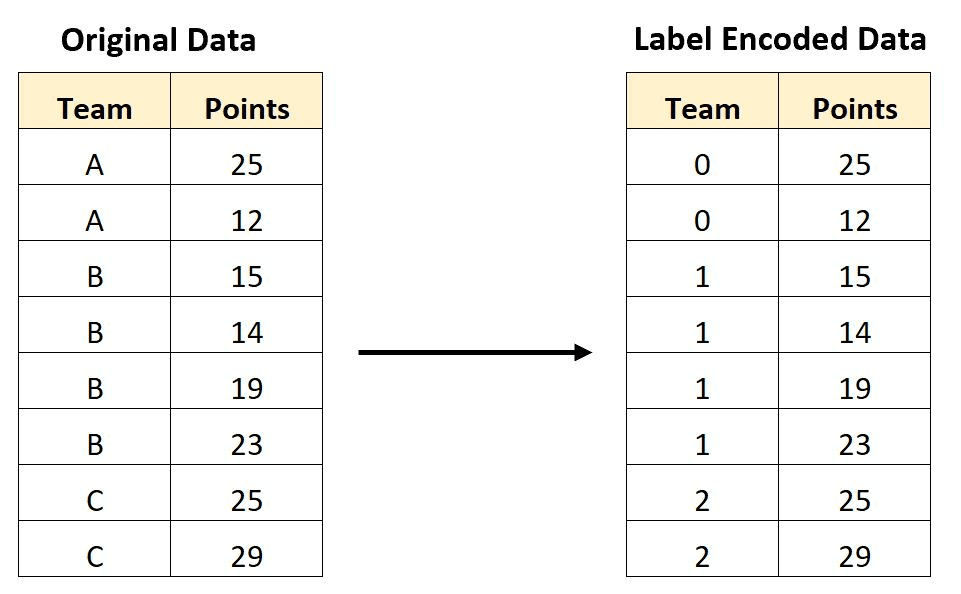
Étiqueter les données codées. Image Source
L'encodage à une chaleur et l'encodage d'étiquettes sont deux techniques permettant d'encoder des variables catégorielles sous forme de valeurs numériques, mais elles présentent des propriétés différentes et conviennent à des cas d'utilisation différents.
Le codage à une chaleur représente chaque catégorie comme une colonne binaire, avec un 1 indiquant la présence de la catégorie et un 0 indiquant son absence. Par exemple, supposons que nous ayons une variable catégorielle "couleur" avec trois catégories : "rouge", "vert" et "bleu". Le codage à une chaleur représenterait cette variable sous la forme de trois colonnes binaires :
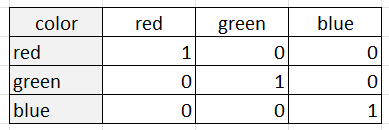
Le codage à un seul point est approprié lorsque les catégories n'ont pas d'ordre ou de relation intrinsèque entre elles. Cela s'explique par le fait que l'encodage à une touche traite chaque catégorie comme une entité distincte sans relation avec les autres catégories. Le codage à une chaleur est également utile lorsque le nombre de catégories est relativement faible, car le nombre de colonnes peut devenir difficile à gérer lorsque le nombre de catégories est très élevé.
Le codage des étiquettes, quant à lui, représente chaque catégorie sous la forme d'un nombre entier unique. Par exemple, la variable "couleur" comportant trois catégories peut être codée comme suit :
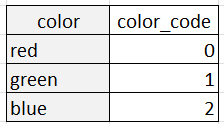
L'encodage des étiquettes est approprié lorsque les catégories ont un ordre ou une relation naturelle entre elles, comme dans le cas de variables ordinales telles que "petit", "moyen" et "grand". Dans ce cas, les valeurs entières attribuées aux catégories doivent refléter l'ordre des catégories. Le codage des étiquettes peut également être utile lorsque le nombre de catégories est très élevé, car il réduit la dimensionnalité des données.
En général, le codage à une touche est plus couramment utilisé dans les applications d'apprentissage automatique, car il est plus souple et évite les problèmes d'ambiguïté et d'ordre arbitraire qui peuvent survenir avec le codage des étiquettes. Toutefois, le codage des étiquettes peut être utile dans certains contextes où les catégories ont un ordre naturel ou lorsqu'il s'agit d'un très grand nombre de catégories.
Une cardinalité élevée correspond à un grand nombre de catégories uniques dans une caractéristique catégorielle. La gestion d'une cardinalité élevée est un défi courant dans l'encodage de données catégorielles pour les modèles d'apprentissage automatique. Une cardinalité élevée peut conduire à une représentation éparse des données et avoir un impact négatif sur les performances de certains modèles d'apprentissage automatique. Voici quelques techniques qui peuvent être utilisées pour traiter la cardinalité élevée des caractéristiques catégorielles :
Il s'agit de combiner des catégories peu fréquentes en une seule catégorie. Cela permet de réduire le nombre de catégories uniques et de réduire l'éparpillement de la représentation des données.
L'encodage de la cible remplace les valeurs catégorielles par la valeur cible moyenne de cette catégorie. Elle fournit une représentation plus continue des données catégorielles et peut aider à saisir la relation entre la caractéristique catégorielle et la variable cible.
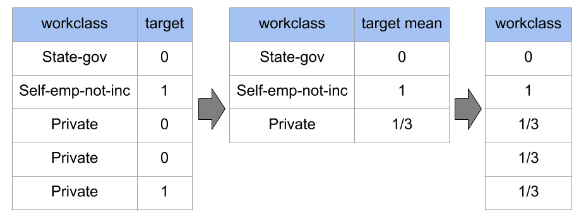
Le codage du poids de la preuve est similaire au codage de la cible, mais il prend en compte la distribution de la variable cible pour chaque catégorie. Le WOE d'une catégorie est calculé comme le logarithme du rapport entre la moyenne de la cible pour la catégorie et la moyenne pour l'ensemble de la population.
L'ingénierie des caractéristiques est une étape importante dans la préparation des données pour les modèles d'apprentissage automatique. Il s'agit de créer de nouvelles caractéristiques à partir des caractéristiques existantes afin d'améliorer les performances des modèles. Voici quelques façons d'effectuer l'ingénierie des caractéristiques sur des données catégorielles :
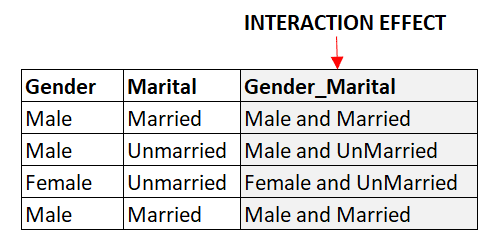
Les variables d'interaction sont de nouvelles caractéristiques créées en combinant deux ou plusieurs caractéristiques existantes. Par exemple, si nous disposons de deux caractéristiques catégorielles, "Sexe" et "État matrimonial", nous pouvons créer une nouvelle caractéristique, "Sexe-État matrimonial", pour capturer l'interaction entre les deux caractéristiques. Cela peut aider à saisir les relations non linéaires entre les caractéristiques et la variable cible.
Le regroupement est le processus qui consiste à diviser les variables numériques continues en catégories discrètes. Cela permet de réduire le nombre de valeurs uniques dans la caractéristique, ce qui peut s'avérer utile pour coder des données catégorielles. L'organisation en binômes peut également permettre de saisir les relations non linéaires entre les caractéristiques et la variable cible.
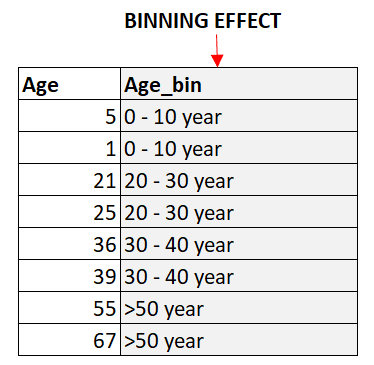
Les variables cycliques sont des variables qui se répètent sur une période donnée. Par exemple, l'heure du jour est une variable cyclique puisqu'elle se répète toutes les 24 heures. Le codage de variables cycliques peut aider à capturer les modèles périodiques dans les données. Une approche courante du codage des variables cycliques consiste à créer deux nouvelles caractéristiques, l'une représentant le sinus de la variable et l'autre le cosinus de la variable.
Apprenez les compétences dont vous avez besoin à votre propre rythme, des notions essentielles de non-codage à la science des données et à l'apprentissage automatique.
En savoir plus sur Python
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min