
Kurs
Prompt-Engineering mit der OpenAI-API
4 Std.
47.9K
Große Sprachmodelle (Large Language Models, LLMs) generieren Text mithilfe einer Technik namens Autoregression, bei der das wahrscheinlichste nächste Wort in einer Sequenz auf der Grundlage der vorherigen Wörter vorhergesagt wird. LLM-gestützte Agenten wie ChatGPT sind außerdem so abgestimmt, dass sie der Absicht des Nutzers folgen. Daher vervollständigen sie nicht nur die Eingabesequenz, sondern erfassen auch die Absicht des Nutzers bei der Eingabe und generieren eine entsprechende Antwort.
Wenn du ChatGPT schon eine Weile ausprobiert hast, ist dir sicher aufgefallen, dass die Qualität einer Antwort auch von der Qualität der Benutzereingabe abhängt, d.h. der Agent gibt auf bestimmte Fragen "bessere" Antworten als auf andere.
Das Geheimnis, um die bestmögliche Antwort zu erhalten, besteht darin, zu verstehen, wie LLMs die Ausgabe erzeugen und die Eingabeaufforderung entsprechend zu formulieren. Die Techniken, die auf die Benutzereingaben angewendet werden, um das volle Potenzial des Modells auszuschöpfen, werden als Prompt Engineering bezeichnet.
In diesem Artikel werden wir eine der leistungsfähigsten Prompt-Engineering-Techniken untersuchen: Chain-of-Thought (CoT) Prompting. Bei dieser Technik wird die Aufforderung so strukturiert, dass es dem Modell leichter fällt, komplexe Aufgaben zu lösen, die logisches Denken oder Problemlösen erfordern. Es hat sich gezeigt, dass das gleiche Modell ohne CoT nicht die richtige Antwort liefert.
Obwohl LLMs für ihre Fähigkeit zur Verallgemeinerung bekannt sind, hängen die Fähigkeiten der Modelle von der Aufgabe ab. Bei der Verwendung von LLMs ist es wichtig zu bedenken, dass jedes Modell auf einer riesigen, aber begrenzten Datenbank trainiert wurde und für bestimmte Aufgaben optimiert worden ist. Während das Modell also in bestimmten Bereichen sehr leistungsfähig sein kann, kann es in anderen versagen.
Die Fähigkeiten des Modells hängen auch von der Zeit ab. Wenn du mir eine Summe von 5 Ziffern nennst, brauchst du etwas Zeit, um nachzudenken und die richtige Antwort zu finden. Wenn du es eilig hast, kannst du dich leicht verkalkulieren und bei deiner Antwort versagen.
Wenn wir einem Sprachmodell eine Aufgabe stellen, die zu komplex ist, um sie in der Zeit zu lösen, die es braucht, um das nächste Token zu berechnen, kann es sein, dass es nicht die richtige Antwort gibt.
Doch wie beim Menschen bedeutet das nicht unbedingt, dass das Modell unfähig ist, die Aufgabe zu bewältigen. Mit etwas Zeit oder Anleitung zum Nachdenken kann das Modell immer noch zuverlässig antworten.
Die Antwort des Modells und die dafür benötigte Zeit können auch von verschiedenen Faktoren beeinflusst werden, z. B. von der spezifischen Formulierung der Frage:
Chain-of-Thought-Prompting hilft LLMs, komplexe Aufgaben erfolgreich zu lösen, indem sie sowohl die Art der Formulierung der Aufforderung wählen als auch dem Modell die nötige Zeit oder die Schritte zur Verfügung stellen, um die richtige Antwort zu finden.
Chain-of-Thought-Prompting ist eine Technik, die die Leistung von Sprachmodellen verbessert, indem sie das Modell explizit auffordert, eine schrittweise Erklärung oder einen Argumentationsprozess zu erstellen, bevor es zu einer endgültigen Antwort kommt. Diese Methode hilft dem Modell, das Problem aufzuschlüsseln und keine Zwischenaufgaben zu überspringen, um Denkfehler zu vermeiden.
Der CoT ist effektiv, weil er hilft, den Aufmerksamkeitsmechanismus des LLM zu fokussieren. Durch die Zerlegung des Denkprozesses konzentriert sich das Modell jeweils auf einen Teil des Problems und minimiert so das Risiko von Fehlern, die durch die gleichzeitige Verarbeitung zu vieler Informationen entstehen könnten.
Forscher bei Google stellten das Chain-of-Thought-Prompting im Jahr 2022 in einer Arbeit mit dem Titel "Chain of Thought Prompting Elicits Reasoning in Large Language Models" vor. Diese Forschung hat gezeigt, wie die Führung eines Modells durch eine Reihe von Zwischenschritten seine Leistung bei Aufgaben wie mathematischem Problemlösen, logischem Schlussfolgern und dem Beantworten von Fragen mit mehreren Schritten deutlich verbessert.
Schauen wir uns eines der vorgeschlagenen Beispiele an:
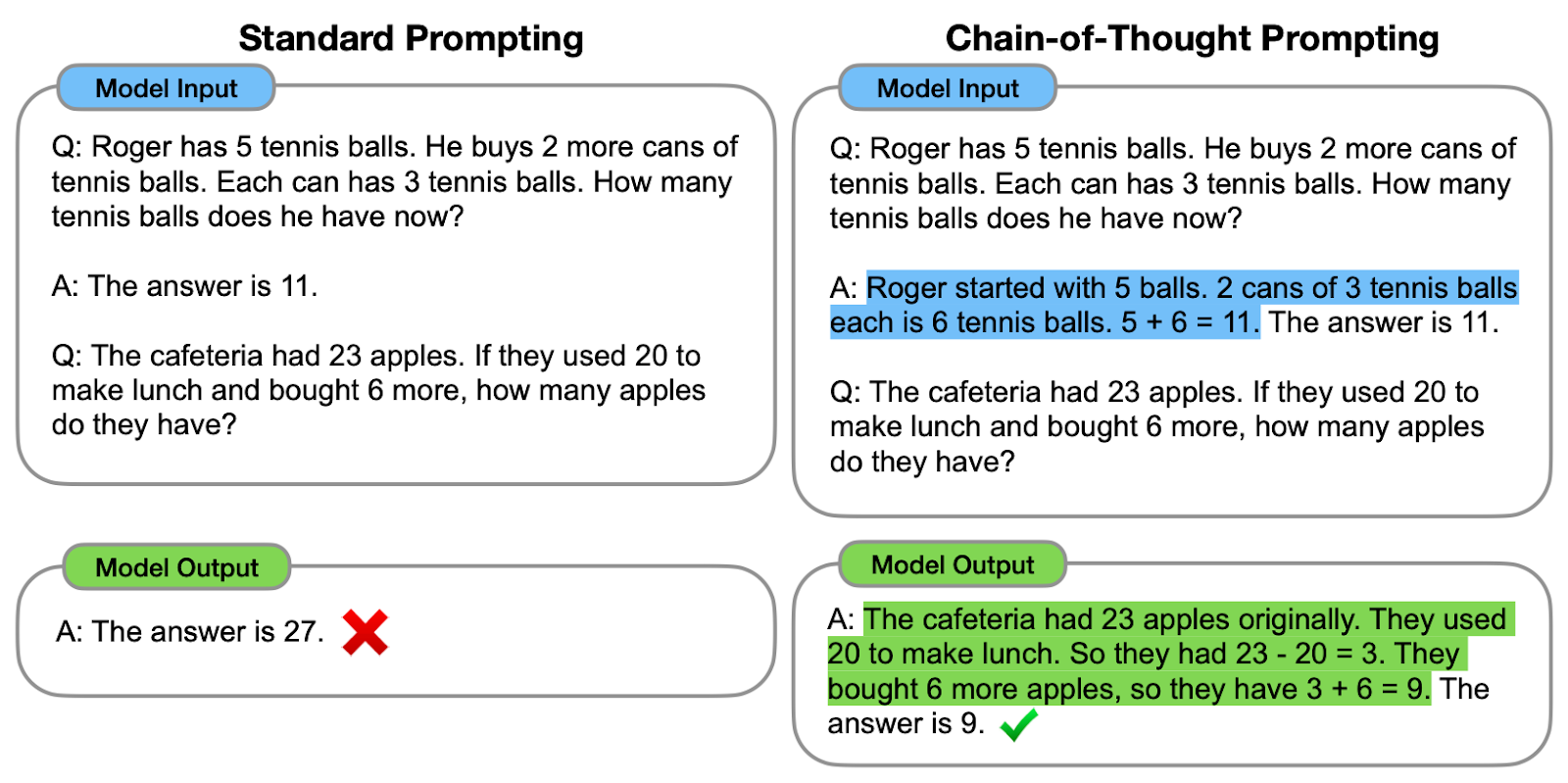
Vergleich zwischen Standard-Prompting und CoT-Prompting. Auf der linken Seite wird das Modell angewiesen, direkt die endgültige Antwort zu geben (Standard-Prompting). Auf der rechten Seite wird das Modell angewiesen, den Argumentationsprozess zu zeigen, der zur endgültigen Antwort führt (CoT-Prompting).
Wie wir beobachten können, hilft das Erstellen einer Gedankenkette - einer Reihe von Zwischenschritten - dem Modell, die richtige Antwort zu geben.
Die Originalautoren bezeichnen die Gedankenkette als eine Reihe von natürlichsprachlichen Zwischenschritten, die zum endgültigen Ergebnis führen, und bezeichnen diesen Ansatz als Chain-of-Thought-Prompting.
Der Prozess beginnt mit der Erarbeitung von Aufforderungen, die das Modell dazu ermutigen, das Problem Schritt für Schritt zu durchdenken und so die Zwischenschritte zu erzeugen, ohne direkt zur endgültigen Antwort zu springen. Dies kann mit verschiedenen Strategien geschehen:
Explizite Anweisungen zu geben bedeutet, das Problem in der Benutzerführung selbst zu zerlegen. Verwende zum Beispiel Sätze wie "Zuerst müssen wir bedenken, dass...", um das Modell aufzufordern, seinen Gedankengang zu beschreiben.
Lass es uns in Aktion sehen!
Stell dir vor, meine spanische Mutter hat mir das Familienrezept für die Zubereitung von Cold Brew geschickt:
input_text = """
¡Preparar café Cold Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""Nehmen wir an, wir wollen alle Wörter, die mit Kaffee zu tun haben, ins Englische übersetzen und ChatGPT für diese Aufgabe verwenden:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Hier ist die Antwort auf diese Aufforderung:
Wenn wir das Modell bitten, diese Aufgabe sofort zu erledigen, können wir sehen, dass es die Aufgabe falsch ausführt. Nicht nur, dass es nicht verwandte Kaffeewörter ausgibt, es gibt sie auch auf Spanisch aus, nicht auf Englisch.
Man könnte sagen, dass diese Aufgabe komplex ist, da sie zwei Schritte erfordert:
Stattdessen springt das Modell direkt zur abschließenden Aufgabe der Identifizierung der kaffeebezogenen Wörter und lässt den Übersetzungsschritt aus. Indem wir die Übersetzung als Zwischenaufgabe angeben oder die Aufgabe in die beiden Hauptschritte zerlegen, können wir das Modell zum richtigen Ergebnis führen:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
The task requires the following actions:
1 - Translate the given text into English.
2 - List each coffee-related word from the English text.
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Die Einbeziehung der oben genannten Gedankenkette führt zur richtigen Antwort:

Wenn du diese Technik lieber mit anderen LLMs als mit chatGPT oder der OpenAI API ausprobieren möchtest, wie in diesem Artikel, ist der Kurs "Developing Large Language Models" genau das Richtige für dich!
Manchmal ist es nicht nötig, das Problem in der Aufforderung selbst zu zerlegen. Die Universität Tokio schlug zusammen mit Google Research eine nette Methode zur Verbesserung der LLM-Antworten vor, die darin bestand, am Ende der ursprünglichen Aufforderung einfach "Lass uns Schritt für Schritt denken" hinzuzufügen.
Dieser einfache Satz fordert das Modell dazu auf, laut zu denken und alle erforderlichen Schritte zur Ausführung der Aufgabe durchzugehen.
Analysieren wir eines der Beispiele, die die Autoren in der Originalarbeit "Large Language Models are Zero-Shot Reasoners" vorgeschlagen haben:

Vergleich zwischen Standard-Prompting und der Verwendung von impliziten CoT-Anweisungen. Auf der linken Seite gibt das Modell sofort die endgültige Antwort auf die Aufgabe (Zero-Shot Prompting) und scheitert. Auf der rechten Seite wird das Modell mit einer impliziten CoT-Anweisung (CoT-Prompting) zur richtigen Antwort angeleitet.
[a] Im ersten Beispiel fordern die Autoren das Modell auf, ein arithmetisches Problem zu lösen, aber es scheitert an dieser Aufgabe.
[b] Wenn du dann an die ursprüngliche Frage anfügst "Lass uns Schritt für Schritt denken", begründet das Modell die Antwort laut und hat Erfolg.
Bei der Anwendung dieses einfachen Tricks auf den MultiArith-Mathe-Datensatz fanden die Autoren heraus, dass diese implizite Anweisung die Genauigkeit von 18% auf 79% vervierfachte!
Wenn du daran interessiert bist, kannst du mehr über diese Technik unter "Use This Short Prompt to Boost ChatGPT's Outcome" lesen.
Wir haben den Begriff "Nullschuss" im obigen Abschnitt mehrmals verwendet. Zero-Shot bezieht sich auf die Fähigkeit eines Modells, eine Aufgabe auszuführen, ohne dass es explizit auf Beispiele für diese spezielle Aufgabe trainiert wurde.
Sie beruht auf der Fähigkeit des Modells, sich zu verallgemeinern und angemessene Antworten auf neue und bisher unbekannte Aufgaben zu geben. Das bedeutet, dass wir, wenn wir die Benutzeroberfläche von chatGPT öffnen und sofort eine Frage stellen, eine Null-Eingabeaufforderung machen.
Trotzdem gibt es Möglichkeiten, dem Modell mehrere Beispiele für ähnliche Aufgaben zu zeigen, die wir lösen wollen. Wenn du eine Reihe von Beispielen anführst, spricht man von One-Shot- und Some-Shot-Prompting, je nachdem, wie viele Beispiele du anführst.
Beim One-Shot Prompting wird dem Modell ein Beispiel gezeigt, das der Zielaufgabe ähnlich ist, um es anzuleiten.
Wenn wir zum Beispiel auf die erste Abbildung des Artikels zurückgreifen, können wir feststellen, dass das Modell dank des anschaulichen Beispiels in der Aufforderung die Gedankenkette erzeugt.
Das Few-Shot-Lernen funktioniert genauso wie das One-Shot-Lernen, aber die Anzahl der Beispiele ist höher, in der Regel etwa hundert. Die Leistung des Modells steigt linear mit der Anzahl der Beispiele.
Jason Wei und Denny Zhou et al. von Google haben das Few-Shot Prompting untersucht. Dieser Ansatz ist besonders nützlich für Aufgaben, die spezielleres oder domänenspezifisches Wissen erfordern, bei denen das Modell möglicherweise nicht über genügend Hintergrundwissen verfügt, um die Aufgabe mit einem Zero-Shot- oder One-Shot-Prompting zu lösen. Few-shot prompting wird manchmal als eine kleine Feinabstimmung des Modells auf eine Sammlung neuer oder besonderer Daten gesehen.
Weitere Beispiele für One-Shot- und Some-Shot-Prompting findest du unter "Verbessere die chatGPT-Leistung mit Prompt Engineering".
One-shot und few-shot Prompting sind keine CoT. Forscherinnen und Forscher haben jedoch erforscht, wie das Lernen mit wenigen Schüssen mit dem CoT-Prompting kombiniert werden kann, bekannt als "Few-shot CoT-Prompting". In einem "few-shot CoT" werden dem Modell einige Problembeispiele mit ihren Schritt-für-Schritt-Lösungen zur Verfügung gestellt, um seinen Denkprozess zu leiten.
Die Kombination von CoT-Prompting mit anderen Techniken, wie z.B. Retrieval-Augmented Generation oder interaktiver Abfrage, kann die Leistung und Zuverlässigkeit des Modells weiter verbessern. Durch die Integration von externen Wissensdatenbanken, Datenbanken oder Information Retrieval Systemen kann das Modell seine Schlussfolgerungen mit faktischen und aktuellen Informationen erweitern.
Labyrinth aus mathematischen Problemen, um zu veranschaulichen, wie CoT den Modellen helfen kann, durch den Wissensraum zu navigieren und komplexe Aufgaben zu lösen. Selbst erstelltes Bild mit ChatGPT 4o Bilderzeugung mit der folgenden Aufforderung "Stell dir einen Sprachmodell-Agenten durch ein Labyrinth mit mathematischen Problemen vor".
Es gibt mehrere Möglichkeiten, CoT in unsere Aufforderungen einzubeziehen:
Mehrere Frameworks können dir helfen, CoT und andere Prompt Engineering-Techniken zu implementieren, aber LangChain ist mein Favorit. Wenn du daran interessiert bist, LangChain als Teil deiner LLM-gestützten Projekte zu nutzen, ist der Kurs "LLM-Anwendungen mit LangChain entwickeln" ein idealer Startpunkt.
Chain-of-Thought-Prompting bietet mehrere Vorteile, vor allem um die Leistung und Zuverlässigkeit von Sprachmodellen bei komplexen Aufgaben zu verbessern.
Indem ein Problem in kleinere, überschaubare Schritte zerlegt wird, kann das Modell komplexe Aufgaben genauer bearbeiten. Zwischenschritte bieten Kontrollpunkte, an denen mögliche Fehler erkannt und korrigiert werden können, was zu genaueren endgültigen Antworten führt.
Der Grund, warum Aufgaben wie mathematische Probleme, logische Rätsel oder das Beantworten von Fragen mit mehreren Schritten von diesem Ansatz profitieren, ist, dass sie bereits von Natur aus mehrere Schritte des Denkens erfordern.
Der Schritt-für-Schritt-Argumentationsprozess ist transparent, so dass die Nutzer/innen nachvollziehen können, wie das Modell zu seinem Ergebnis gekommen ist. Diese Transparenz stärkt das Vertrauen in die Ergebnisse des Modells.
Es kann auch bei der Fehlersuche helfen, da die Nutzer/innen leichter erkennen können, wo das Modell in seinen Überlegungen falsch liegt.
Natürlich gibt es, wie bei jeder Technik, immer auch gewisse Nachteile, die es zu beachten gilt:
Es ist wichtig zu bedenken, dass CoT eine modellabhängige Technik ist. Daher hängt die Effektivität von CoT-Prompting weitgehend von den Fähigkeiten des zugrunde liegenden Sprachmodells ab.
Es kann auch eine Herausforderung sein, effektive CoT-Aufforderungen zu formulieren. Es erfordert ein sorgfältiges Design, um sicherzustellen, dass die Eingabeaufforderungen das Modell richtig durch den Denkprozess führen. Die Aktualisierung und Pflege von Aufforderungen für verschiedene Aufgabentypen und Bereiche kann zeitaufwändig sein und erfordert möglicherweise eine ständige Weiterentwicklung.
CoT-Aufforderungen sind möglicherweise nicht so effektiv für Aufgaben, bei denen es keinen klaren sequentiellen Denkprozess gibt. Außerdemkann es ohne zusätzliches Training oder Anpassungennicht gut auf völlig neue oder unerwartete Arten von Problemen verallgemeinert werden, daher ist es wichtig, eine aktuelle Wissensbasis und geeignete Aufforderungen zu haben.
Die CoT-Eingabeaufforderung erhöht zwar die Interpretierbarkeit durch schrittweise Erklärungen, sie kann aber auch zu längeren und ausführlicheren Ausgaben führen, was nicht immer für alle Anwendungen wünschenswert ist.
In diesem Artikel haben wir gesehen, wie das Chain-of-Thought-Prompting einen bedeutenden Fortschritt bei der Verbesserung der Argumentationsfähigkeiten von Large Language Models darstellt, und wir haben einige praktische Beispiele für seine Umsetzung vorgestellt.
Ob mit Prompt-Vorlagen, interaktivem Prompting oder Feedback-Schleifen, die Idee hinter diesen Ansätzen ist es, das Modell durch den Denkprozess zu führen und seine Fähigkeiten zu nutzen.
Darüber hinaus haben wir leistungsstarke Techniken wie One-Shot- und Little-Shot-Prompting erforscht, die die Leistung des Modells weiter verbessern und mit CoT kombiniert werden können, sowie die Vorteile und einige Einschränkungen, die wir nicht übersehen dürfen.
Überlege dir, ob du die in diesem Artikel besprochenen Techniken ausprobieren willst, um zuverlässigere und leistungsfähigere Prompts zu erstellen, und vergiss nicht: Prompt Engineering kann einen großen Einfluss auf deine Ergebnisse haben!
Mehr über Prompt Engineering erfährst du in den DataCamp-Kursen Understanding Prompt Engineering und ChatGPT Prompt Engineering for Developers. Du kannst dir auch einen separaten Leitfaden zur Sofortzertifizierung von Ingenieuren ansehen und herausfinden, welche Lernwege für dich am besten sind.
Top DataCamp Kurse
Kurs
Kurs
Kurs