Curso
Engenharia rápida com a API OpenAI
4 h
47.9K
Os modelos de linguagem grandes (LLMs) geram texto usando uma técnica chamada autorregressão, que envolve a previsão da próxima palavra mais provável em uma sequência com base nas palavras anteriores. Os agentes com LLM, como o ChatGPT, também são ajustados para seguir a intenção do usuário. Portanto, eles não apenas concluem a sequência de entrada, mas capturam a intenção do usuário na entrada e geram uma resposta de acordo.
Se você já experimentou o ChatGPT por algum tempo, tenho certeza de que percebeu que a qualidade de uma determinada resposta também depende da qualidade da entrada do usuário, por exemplo, o agente fornece respostas "melhores" a determinadas consultas do que a outras.
O segredo para obter a melhor resposta possível é entender como os LLMs geram o resultado e formular o prompt de entrada de acordo. O conjunto de técnicas aplicadas à entrada do usuário para explorar todo o potencial do modelo é conhecido como Prompt Engineering.
Neste artigo, exploraremos uma das técnicas mais avançadas do Prompt Engineering: Solicitação de cadeia de pensamento (CoT). Essa técnica envolve a estruturação do prompt de forma a facilitar que o modelo conclua tarefas complexas que exijam raciocínio ou solução de problemas. Foi demonstrado que, sem a CoT, o mesmo modelo não fornece a resposta correta.
Embora os LLMs sejam conhecidos por sua capacidade de generalização, os recursos do modelo dependem da tarefa. Ao usar LLMs, é importante considerar que cada modelo foi treinado em um banco de dados enorme, porém limitado, e foi otimizado para determinadas tarefas. Portanto, embora o modelo possa ter um alto desempenho em determinados domínios, ele pode falhar em outros.
Os recursos do modelo também dependem do tempo. Como nos seres humanos, se você me der uma soma de 5 dígitos, precisará de algum tempo para pensar e responder com a resposta correta. Se você fizer isso com pressa, poderá facilmente calcular mal e falhar em sua resposta.
Da mesma forma, se dermos a um modelo de linguagem uma tarefa complexa demais para ser realizada no tempo necessário para calcular seu próximo token, ele poderá não fornecer a resposta correta.
No entanto, como acontece com os seres humanos, isso não significa necessariamente que o modelo seja incapaz de realizar a tarefa. Com algum tempo ou orientação para raciocinar, o modelo ainda pode ser capaz de responder de forma confiável.
A resposta do modelo e o tempo necessário para gerá-la também podem ser influenciados por vários fatores, como o texto específico da pergunta:
A solicitação do Chain-of-Thought orienta os LLMs a serem bem-sucedidos na solução de tarefas complexas, escolhendo a maneira de formular a solicitação e fornecendo ao modelo o tempo ou as etapas necessárias para gerar a resposta correta.
A solicitação de Chain-of-Thought é uma técnica que melhora o desempenho dos modelos de linguagem, solicitando explicitamente que o modelo gere uma explicação passo a passo ou um processo de raciocínio antes de chegar a uma resposta final. Esse método ajuda o modelo a decompor o problema e a não pular nenhuma tarefa intermediária para evitar falhas de raciocínio.
O CoT é eficaz porque ajuda a concentrar o mecanismo de atenção do LLM. A decomposição do processo de raciocínio faz com que o modelo concentre sua atenção em uma parte do problema de cada vez, minimizando o risco de erros que podem surgir do manuseio simultâneo de muitas informações.
Em 2022, pesquisadores do Google apresentaram o prompt Chain-of-Thought em um artigo intitulado "Chain of Thought Prompting Elicits Reasoning in Large Language Models". Essa pesquisa destacou como a orientação de um modelo por meio de uma série de etapas intermediárias de raciocínio melhorou significativamente seu desempenho em tarefas como resolução de problemas matemáticos, raciocínio lógico e resposta a perguntas de vários locais.
Vamos ver um dos exemplos propostos:
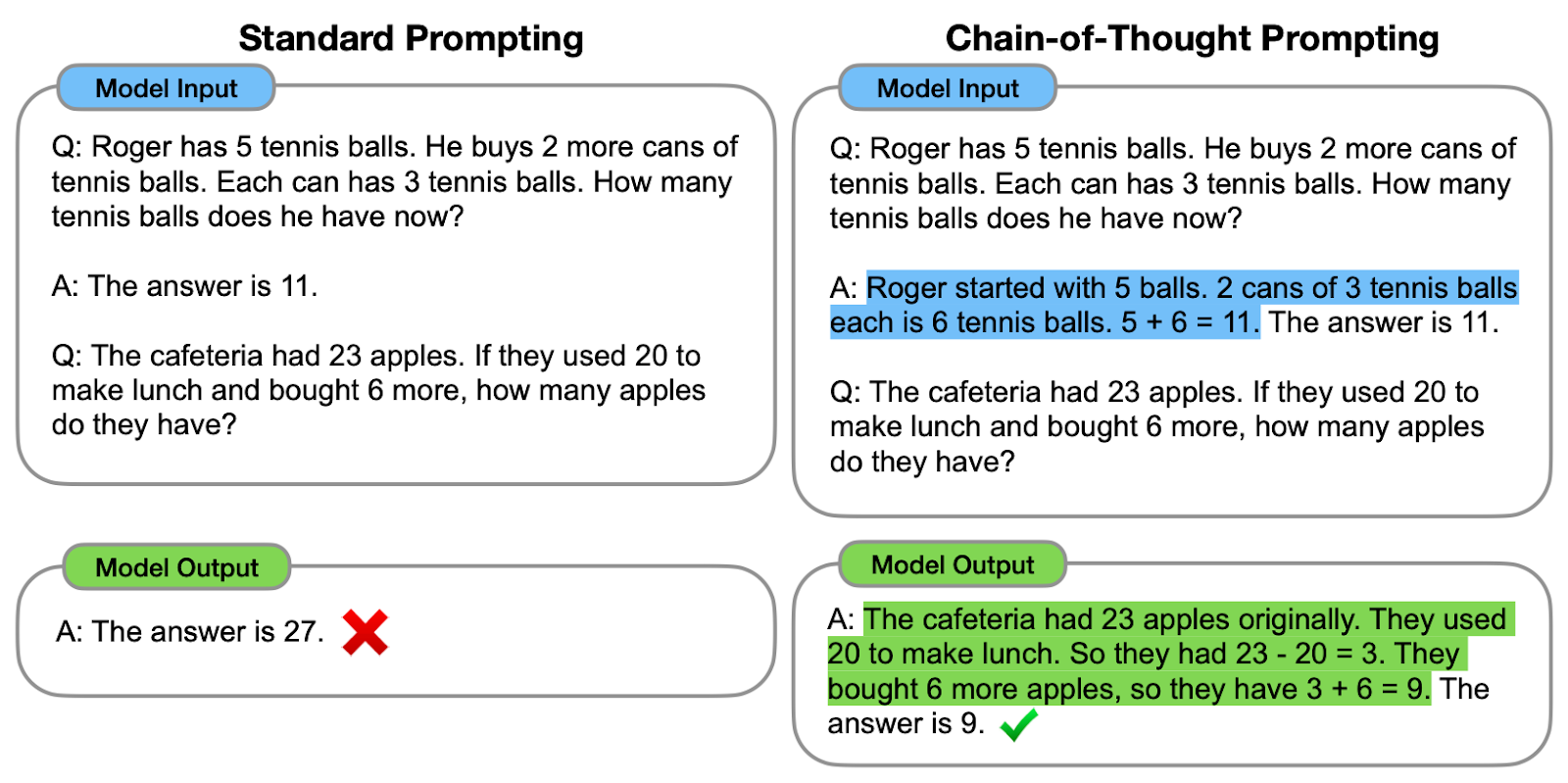
Comparação entre a solicitação padrão e a solicitação de CoT. À esquerda, o modelo é instruído a fornecer diretamente a resposta final (estímulo padrão). À direita, o modelo é instruído a mostrar o processo de raciocínio para chegar à resposta final (solicitação de CoT).
Como podemos observar, a geração de uma cadeia de pensamento - uma série de etapas intermediárias de raciocínio - ajuda o modelo a fornecer a resposta correta.
Os autores originais se referem à cadeia de raciocínio como a série de etapas intermediárias de raciocínio em linguagem natural que levam ao resultado final, referindo-se a essa abordagem como solicitação de cadeia de raciocínio.
O processo começa com a elaboração de prompts que incentivam o modelo a pensar no problema passo a passo, gerando assim as etapas intermediárias sem ir direto para a resposta final. Isso pode ser feito usando diferentes estratégias:
Fornecer instruções explícitas significa decompor o problema no próprio prompt do usuário. Por exemplo, você pode usar frases como "First, we need to consider..." (Primeiro, precisamos considerar...) para que o modelo detalhe seu processo de pensamento.
Vamos ver isso em ação!
Imagine que minha mãe espanhola me enviou a receita de família para preparar o Cold Brew:
input_text = """
¡Preparar café Cold Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""Digamos que você esteja interessado em traduzir todas as palavras relacionadas a café para o inglês e que queira usar o ChatGPT para essa tarefa:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Aqui está a resposta a essa solicitação:
Se pedirmos ao modelo que faça essa tarefa imediatamente, veremos que ele a executa de forma incorreta. Além de emitir palavras não relacionadas ao café, ele também as emite em espanhol e não em inglês.
Podemos considerar que essa tarefa é complexa, pois requer duas etapas:
Em vez disso, o modelo salta diretamente para a tarefa final de identificar as palavras relacionadas ao café, deixando de lado a etapa de tradução. Ao especificar a tradução como uma tarefa intermediária ou decompor a tarefa nas duas etapas principais, podemos orientar o modelo para o resultado correto:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
The task requires the following actions:
1 - Translate the given text into English.
2 - List each coffee-related word from the English text.
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)A inclusão da cadeia de raciocínio acima leva à resposta correta:

Se você estiver interessado em experimentar essa técnica com outros LLMs em vez do ChatGPT ou da API OpenAI, como neste artigo, o curso "Developing Large Language Models" é para você!
Às vezes, não há necessidade de decompor o problema por conta própria no prompt. A Universidade de Tóquio, juntamente com o Google Research, propôs um bom método para melhorar as respostas do LLM, que consistia simplesmente em acrescentar "Vamos pensar passo a passo" no final do prompt original.
Essa frase simples faz com que o modelo raciocine em voz alta e siga todas as etapas necessárias para realizar a tarefa.
Vamos analisar um dos exemplos que os autores propuseram no artigo original "Large Language Models are Zero-Shot Reasoners":

Comparação entre a solicitação padrão e o uso de instruções implícitas de CoT. À esquerda, o modelo fornece a resposta final para o problema imediatamente (solicitação de disparo zero) e falha. À direita, o modelo é instruído com uma instrução implícita de CoT (CoT prompting) para obter a resposta correta.
[a] No primeiro exemplo, os autores pedem que o modelo resolva um problema de aritmética, mas ele falha nessa tarefa.
[b] Em seguida, ao acrescentar "Vamos pensar passo a passo" à pergunta original, o modelo raciocina a resposta em voz alta e é bem-sucedido.
Ao aplicar esse truque simples ao conjunto de dados matemáticos MultiArith, os autores descobriram que essa instrução implícita quadruplicou a precisão de 18% para 79%!
Se estiver interessado, você pode ler mais sobre essa técnica em "Use This Short Prompt to Boost ChatGPT's Outcome".
Usamos o termo "zero-shot" na seção acima várias vezes. Zero-shot refere-se à capacidade de um modelo de executar uma tarefa sem ter sido explicitamente treinado em exemplos dessa tarefa específica.
Ele se baseia na capacidade do modelo de generalizar e gerar respostas apropriadas para tarefas novas e não vistas anteriormente. Isso significa que, quando abrimos a interface de usuário do ChatGPT e fazemos uma pergunta imediatamente, estamos fazendo um prompt de disparo zero.
No entanto, há maneiras de mostrar ao modelo vários exemplos de tarefas semelhantes que queremos resolver. O fornecimento de uma série de exemplos demonstrativos é conhecido como estímulo de um ou poucos estímulos, dependendo do número de exemplos fornecidos.
A solicitação de uma única vez envolve mostrar ao modelo um exemplo que seja semelhante à tarefa-alvo para orientação.
Por exemplo, se você voltar à primeira figura do artigo, poderá observar que o modelo gera a cadeia de pensamento graças ao exemplo demonstrativo fornecido no prompt.
O aprendizado de poucas tentativas funciona da mesma forma que o de uma tentativa, mas o número de exemplos dados é maior, normalmente em torno de cem. O desempenho do modelo aumenta linearmente com o número de exemplos.
A solicitação de poucos disparos foi estudada por Jason Wei e Denny Zhou et al. do Google. Essa abordagem é particularmente útil para tarefas que exigem conhecimento mais especializado ou específico do domínio, em que o modelo pode não ter conhecimento prévio suficiente para executar a tarefa usando o prompt de disparo zero ou de disparo único. Às vezes, o prompt de poucos disparos é visto como um pequeno ajuste fino do modelo em uma coleção de dados novos ou especiais.
Veja mais exemplos de solicitações de um e poucos disparos em "Melhore o desempenho do ChatGPT com a engenharia de solicitações".
As solicitações de um ou poucos disparos não são CoT. No entanto, os pesquisadores exploraram como a aprendizagem de poucos disparos pode ser combinada com a solicitação de CoT, conhecida como "solicitação de CoT de poucos disparos". Em uma CoT de poucos disparos, o modelo recebe alguns exemplos de problemas, juntamente com suas soluções passo a passo, para orientar seu processo de raciocínio.
A combinação do prompt de CoT de poucos disparos com outras técnicas, como a geração aumentada por recuperação ou a consulta interativa, pode melhorar ainda mais o desempenho e a confiabilidade do modelo. A integração de bases de conhecimento externas, bancos de dados ou sistemas de recuperação de informações permite que o modelo aprimore seu raciocínio com informações factuais e atualizadas.
Labirinto de problemas matemáticos para ilustrar como a CoT pode ajudar os modelos a navegar pelo espaço de conhecimento e resolver tarefas complexas. Imagem gerada por você mesmo usando a geração de imagens do ChatGPT 4o com o seguinte prompt "Imagine um agente do Modelo de Linguagem em um labirinto de problemas matemáticos".
Há várias maneiras de incluir a CoT em nossos prompts:
Várias estruturas podem ajudar você a implementar a CoT e outras técnicas de Prompt Engineering, mas a LangChain é a minha favorita. Se você estiver interessado em usar o LangChain como parte de seus projetos baseados no LLM, o curso "Developing LLM Applications with LangChain" é um ponto de partida ideal.
A solicitação de Chain-of-Thought oferece vários benefícios, especialmente para melhorar o desempenho e a confiabilidade dos modelos de linguagem em tarefas complexas.
Ao dividir um problema em etapas menores e gerenciáveis, o modelo pode lidar com tarefas complexas com mais precisão. As etapas intermediárias fornecem pontos de verificação onde os possíveis erros podem ser detectados e corrigidos, levando a respostas finais mais precisas.
O motivo pelo qual tarefas como problemas matemáticos, quebra-cabeças lógicos ou respostas a perguntas de vários locais se beneficiam dessa abordagem é que elas já exigem naturalmente várias etapas de raciocínio.
O processo de raciocínio passo a passo é transparente, permitindo que os usuários entendam como o modelo chegou à sua conclusão. Essa transparência gera confiança nos resultados do modelo.
Isso também pode ajudar na depuração, pois os usuários podem identificar mais facilmente onde o modelo pode ter errado em seu raciocínio.
É claro que, como em qualquer técnica, sempre há certas desvantagens que vale a pena considerar:
É importante considerar que a CoT é uma técnica dependente do modelo. Portanto, a eficácia da solicitação de CoT depende muito dos recursos do modelo de linguagem subjacente.
A elaboração de prompts de CoT eficazes também pode ser um desafio. Isso requer um projeto cuidadoso para garantir que os prompts guiem o modelo corretamente pelo processo de raciocínio. A atualização e a manutenção de prompts para diferentes tipos de tarefas e domínios podem consumir muito tempo e exigir refinamento constante.
A solicitação de CoT pode não ser tão eficaz para tarefas que não tenham um processo de raciocínio sequencial claro. Além disso,ele pode não se generalizar bem para tipos de problemas totalmente novos ou inesperados sem treinamento ou adaptação adicional, portanto, é fundamental manter uma base de conhecimento atualizada e avisos adequados.
Embora a solicitação de CoT aumente a interpretabilidade ao fornecer explicações passo a passo, ela também pode levar a resultados mais longos e detalhados, o que nem sempre é desejável para todos os aplicativos.
Neste artigo, vimos como a solicitação de Chain-of-Thought representa um avanço significativo no aprimoramento dos recursos de raciocínio dos modelos de linguagem grande, juntamente com alguns exemplos práticos de sua implementação.
Seja usando modelos de aviso, aviso interativo ou loops de feedback, a ideia por trás dessas abordagens é guiar o modelo pelo processo de raciocínio e explorar seus recursos.
Além disso, exploramos técnicas poderosas, como a solicitação de um e poucos disparos, que melhoram ainda mais o desempenho do modelo e podem ser combinadas com a CoT, juntamente com os benefícios e algumas limitações que não podemos ignorar.
Considere a possibilidade de experimentar as técnicas discutidas neste artigo para criar prompts mais confiáveis e de alto desempenho, e lembre-se disso: A Prompt Engineering pode ter um grande impacto em seus resultados!
Você pode saber mais sobre a engenharia de prompt nos cursos da DataCamp, Understanding Prompt Engineering e ChatGPT Prompt Engineering for Developers. Você também pode consultar um guia separado sobre certificação em engenharia rápida e descobrir quais são as melhores trilhas de aprendizagem para você.
Principais cursos da DataCamp
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita

