
Course
Prompt Engineering with the OpenAI API
4 hr
47.9K
Large Language Models (LLMs) generate text using a technique called autoregression, which involves predicting the most likely next word in a sequence based on the previous words. LLM-powered agents such as ChatGPT are also fine-tuned to follow the user intent. Therefore, they not only complete the input sequence but capture the user's intention on the input and generate a response accordingly.
If you have tried ChatGPT for a while, I am sure you have realized that the quality of a given answer also depends on the quality of the user input, e.g., the agent provides “better” responses to certain queries than others.
The secret to getting back the best possible answer is understanding how LLMs generate the output and formulating the input prompt accordingly. The set of techniques applied to the user input to exploit the model’s full potential is known as Prompt Engineering.
In this article, we will explore one of the most powerful Prompt Engineering techniques: Chain-of-Thought (CoT) prompting. This technique involves structuring the prompt in a way that makes it easier for the model to complete complex tasks requiring reasoning or problem-solving. It has been shown that, without CoT, the very same model fails to provide the correct answer.
Although LLMs are known for their ability to generalize, model capabilities depend on the task. When using LLMs, it is important to consider that each model has been trained on a huge yet limited database, and it has been optimized for certain tasks. Therefore, while the model can be highly performant in certain domains, it may fail in others.
Model capabilities also depend on the timing. As in humans, if you give me a sum of 5 digits, you will need some time to think and answer back with the correct answer. If you do it in a hurry, you could easily miscalculate and fail in your response.
Similarly, if we give a language model a task that is too complex to do in the time it takes to calculate its next token, it may fail to provide the correct answer.
Yet, akin to humans, that doesn’t necessarily mean the model is incapable of the task. With some time or guidance to reason things out, the model may still be able to answer reliably.
The model’s response and the required time to generate it can also be influenced by various factors, such as the specific wording of the question:
Chain-of-Thought prompting guides LLMs to succeed in solving complex tasks, both by choosing the way of formulating the prompt and providing the model with the required time or steps to generate the correct answer.
Chain-of-Thought prompting is a technique that improves the performance of language models by explicitly prompting the model to generate a step-by-step explanation or reasoning process before arriving at a final answer. This method helps the model to break down the problem and not skip any intermediate tasks to avoid reasoning failures.
CoT is effective because it helps focus the attention mechanism of the LLM. The decomposition of the reasoning process makes the model focus its attention on one part of the problem at a time, minimizing the risk of errors that might arise from handling too much information simultaneously.
Researchers at Google introduced Chain-of-Thought prompting in a paper titled “Chain of Thought Prompting Elicits Reasoning in Large Language Models” in 2022. This research highlighted how guiding a model through a series of intermediate reasoning steps significantly improved its performance on tasks on tasks such as mathematical problem-solving, logical reasoning, and multi-hop question answering.
Let’s see one of the proposed examples:
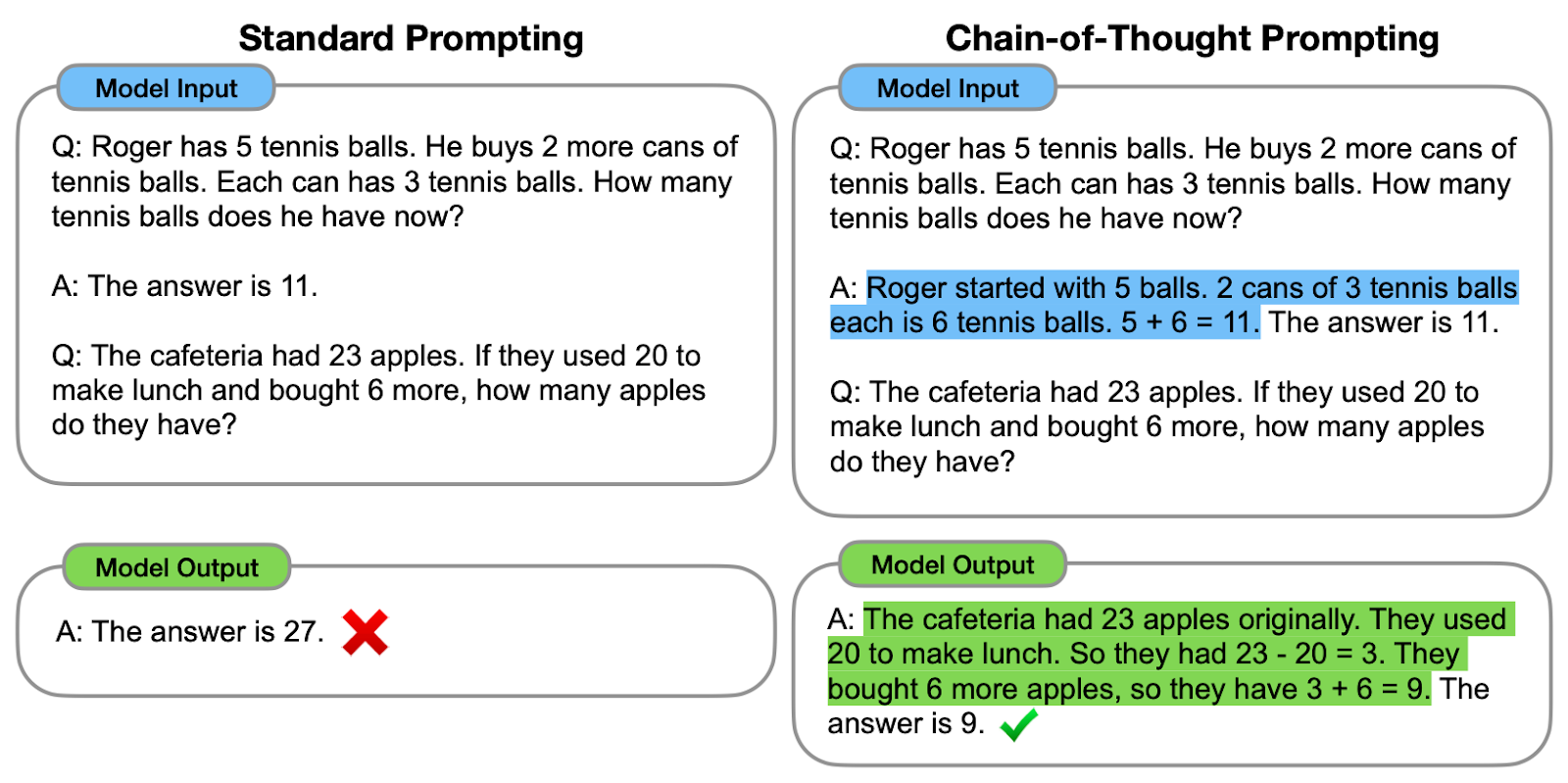
Comparison between standard prompting and CoT prompting. On the left, the model is instructed to directly provide the final answer (standard prompting). On the right, the model is instructed to show the reasoning process to get to the final answer (CoT prompting).
As we can observe, generating a chain of thought — a series of intermediate reasoning steps — helps the model to provide the correct answer.
The original authors refer to the chain of thought as the series of intermediate natural language reasoning steps that lead to the final output, referring to this approach as Chain-of-Thought prompting.
The process starts with crafting prompts that encourage the model to think through the problem in a step-by-step manner, thus generating the intermediate steps without jumping straight to the final answer. This can be done using different strategies:
Giving explicit instructions means decomposing the problem in the user prompt itself. For example, using sentences like “First, we need to consider…” to prompt the model to detail its thought process.
Let’s see it in action!
Imagine my Spanish mum has sent me the family recipe for preparing Cold Brew:
input_text = """
¡Preparar café Cold Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""Let’s say we are interested in translating all the coffee-related words to English, and we want to use ChatGPT for the task:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Here is the response to this prompt:
If we ask the model to do this task straight away, we can see that it performs the task wrongly. Not only does it output non-related coffee words, but it also outputs them in Spanish, not in English.
We could consider that this task is complex as it requires two steps:
Instead, the model jumps straight to the final task of identifying the coffee-related words, missing the translation step. By specifying the translation as an intermediate task or decomposing the task in the main two steps, we can guide the model towards the correct output:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
The task requires the following actions:
1 - Translate the given text into English.
2 - List each coffee-related word from the English text.
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Including the Chain-of-Thought above leads to the correct answer:

If you are interested in trying out this technique with other LLMs rather than ChatGPT or the OpenAI API, as in this article, the course “Developing Large Language Models” is for you!
Sometimes, there is no need to decompose the problem ourselves in the prompt. The University of Tokyo, together with Google Research, proposed a nice method to improve LLM responses that consisted of simply adding “Let’s think step by step" at the end of the original prompt.
This simple sentence prompts the model to reason out loud and go through all the required steps to carry out the task.
Let’s analyze one of the examples that the authors proposed in the original paper “Large Language Models are Zero-Shot Reasoners”:

Comparison between standard prompting and the usage of implicit CoT instructions. On the left, the model provides the final answer to the problem straight away (zero-shot prompting) and fails. On the right, the model is instructed with an implicit CoT instruction (CoT prompting) getting to the correct response.
[a] In the first example, the authors ask the model to solve an arithmetic problem, but it fails in this task.
[b] Then, by appending “Let’s think step by step” to the original question, the model reasons the answer out loud and succeeds.
Applying this simple trick to the MultiArith math dataset, the authors found that this implicit instruction quadrupled the accuracy from 18% to 79%!
If you are interested, you can read more about this technique at “Use This Short Prompt to Boost ChatGPT’s Outcome.”
We have used the term “zero-shot” in the section above several times. Zero-shot refers to the ability of a model to perform a task without having been explicitly trained on examples of that specific task.
It relies on the model’s ability to generalize and generate appropriate responses to new and previously unseen tasks. That means that when we open ChatGPT’s user interface and ask a question straightaway, we are doing zero-shot prompting.
Nevertheless, there are ways to show the model several examples of similar tasks that we want to solve. Providing a series of demonstrative examples is known as one-shot and few-shot prompting, depending on the number of examples provided.
One-shot prompting involves showing the model one example that is similar to the target task for guidance.
For example, if we refer back to the first Figure of the article, we can observe that the model generates the Chain-of-Thought thanks to the demonstrative example provided in the prompt.
Few-shot learning works the same as one-shot, but the number of examples given is higher, typically around a hundred. The performance of the model increases linearly with the number of examples.
Few-shot prompting was studied by Jason Wei and Denny Zhou et al. from Google. This approach is particularly useful for tasks that require more specialized or domain-specific knowledge, where the model may not have sufficient background knowledge to perform the task using zero-shot or one-shot prompting. Few-shot prompting is sometimes seen as a small fine-tuning of the model on a collection of new or special data.
See more examples of one-shot and few-shot prompting at “Improve ChatGPT Performance with Prompt Engineering.”
One-shot and few-shot prompting are not CoT. However, researchers have explored how few-shot learning can be combined with CoT prompting, known as “Few-shot CoT prompting.” In a few-shot CoT, the model is provided with a few examples of problems along with their step-by-step solutions to guide its reasoning process.
Combining few-shot CoT prompting with other techniques, such as retrieval-augmented generation or interactive querying, can further enhance the model’s performance and reliability. Integrating external knowledge bases, databases, or information retrieval systems allows the model to enhance its reasoning with factual and up-to-date information.
Maze of mathematical problems to illustrate how CoT can help the models navigate through the knowledge space and solve complex tasks. Self-generated image using ChatGPT 4o image generation with the following prompt “Imagine a Language Model agent through a maze of mathematical problems”.
There are multiple ways to include CoT in our prompts:
Multiple frameworks can help you implement CoT and other Prompt Engineering techniques, but LangChain is my favorite. If you are interested in using LangChain as part of your LLM-powered projects, the course “Developing LLM Applications with LangChain” is an ideal starting point.
Chain-of-Thought prompting offers several benefits, particularly in enhancing the performance and reliability of language models in complex tasks.
By breaking down a problem into smaller, manageable steps, the model can handle complex tasks more accurately. Intermediate steps provide checkpoints where potential errors can be caught and corrected, leading to more accurate final answers.
The reason why tasks such as mathematical problems, logical puzzles, or multi-hop question answering, benefit from this approach is because they already naturally require multiple steps of reasoning.
The step-by-step reasoning process is transparent, allowing users to understand how the model arrived at its conclusion. This transparency builds trust in the model’s outputs.
It can also help in debugging since users can more easily spot where the model might have gone wrong in its reasoning.
Of course, as with any technique, there are always certain downsides worth considering:
It is important to consider that CoT is a model-dependent technique. Therefore, the effectiveness of CoT prompting largely depends on the capabilities of the underlying language model.
Crafting effective CoT prompts can also be challenging. It requires careful design to ensure that the prompts guide the model correctly through the reasoning process. Updating and maintaining prompts for different types of tasks and domains can be time-consuming and may require constant refinement.
CoT prompting may not be as effective for tasks that do not have a clear sequential reasoning process. Moreover, it may not generalize well to entirely new or unexpected types of problems without additional training or adaptation, so maintaining an up-to-date knowledge base and suitable prompts is crucial.
While CoT prompting increases interpretability by providing step-by-step explanations, it can also lead to longer and more verbose outputs, which may not always be desirable for all applications.
In this article, we have seen how Chain-of-Thought prompting represents a significant advancement in enhancing the reasoning capabilities of Large Language Models, along with some practical examples of its implementation.
Whether using prompt templates, interactive prompting, or feedback loops, the idea behind these approaches is to guide the model through the reasoning process and exploit its capabilities.
Additionally, we have explored powerful techniques such as one-shot and few-shot prompting that further enhance the model’s performance and can be combined with CoT, along with the benefits and some limitations that we cannot overlook.
Consider trying the techniques discussed in this article to build more reliable, high-performing prompts, and bear in mind: Prompt Engineering can have a big impact on your outputs!
You can learn more about prompt engineering through DataCamp’s courses, Understanding Prompt Engineering and ChatGPT Prompt Engineering for Developers. You can also check out a separate guide to prompt engineering certification and find out what the best learning paths are for you.
Top DataCamp Courses
Course
Course
Course
blog
Dr Ana Rojo-Echeburúa
12 min
Tutorial
Dr Ana Rojo-Echeburúa
Tutorial
Moez Ali
Tutorial
Moez Ali
code-along
Andrea Valenzuela
code-along
Olivier Mertens





