
Cours
Ingénierie des prompts avec l'API OpenAI
4 h
48.1K
Les grands modèles linguistiques (LLM) génèrent du texte en utilisant une technique appelée autorégression, qui consiste à prédire le mot suivant le plus probable dans une séquence en fonction des mots précédents. Les agents dotés de LLM, tels que le ChatGPT, sont également adaptés pour suivre l'intention de l'utilisateur. Par conséquent, ils ne se contentent pas de compléter la séquence d'entrée, mais capturent l'intention de l'utilisateur sur l'entrée et génèrent une réponse en conséquence.
Si vous avez essayé le ChatGPT pendant un certain temps, je suis sûr que vous avez réalisé que la qualité d' une réponse donnée dépend également de la qualité de l'entrée de l'utilisateur, par exemple, l'agent fournit de "meilleures" réponses à certaines requêtes que d'autres.
Le secret pour obtenir la meilleure réponse possible est de comprendre comment les LLM génèrent la sortie et de formuler l'invite d'entrée en conséquence. L'ensemble des techniques appliquées aux données de l'utilisateur pour exploiter tout le potentiel du modèle est connu sous le nom de " Prompt Engineering".
Dans cet article, nous allons explorer l'une des techniques d'ingénierie des invites les plus puissantes : Invitation à la chaîne de pensée (CoT). Cette technique consiste à structurer l'invite de manière à faciliter l'accomplissement par le modèle de tâches complexes nécessitant un raisonnement ou la résolution de problèmes. Il a été démontré qu'en l'absence de CoT, ce même modèle ne permet pas d'obtenir la bonne réponse.
Bien que les LLM soient connus pour leur capacité de généralisation, les capacités des modèles dépendent de la tâche. Lorsque vous utilisez des LLM, il est important de tenir compte du fait que chaque modèle a été entraîné sur une base de données énorme mais limitée, et qu'il a été optimisé pour certaines tâches. Par conséquent, si le modèle peut être très performant dans certains domaines, il peut échouer dans d'autres.
Les capacités du modèle dépendent également du moment choisi. Comme pour les humains, si vous me donnez une somme de 5 chiffres, vous aurez besoin d'un certain temps pour réfléchir et donner la bonne réponse. Si vous le faites à la hâte, vous risquez de faire une erreur de calcul et d'échouer dans votre réponse.
De même, si nous confions à un modèle de langage une tâche trop complexe pour être accomplie dans le temps nécessaire au calcul du prochain jeton, il risque de ne pas fournir la bonne réponse.
Cependant, à l'instar des humains, cela ne signifie pas nécessairement que le modèle est incapable d'accomplir la tâche. Avec un peu de temps ou de conseils pour raisonner, le modèle peut encore être capable de répondre de manière fiable.
La réponse du modèle et le temps nécessaire pour la générer peuvent également être influencés par divers facteurs, tels que la formulation spécifique de la question :
La chaîne de pensée guide les MFR dans la résolution de tâches complexes, à la fois en choisissant la manière de formuler l'invite et en fournissant au modèle le temps ou les étapes nécessaires pour générer la bonne réponse.
L'incitation à la chaîne de pensée est une technique qui améliore les performances des modèles de langage en incitant explicitement le modèle à générer une explication étape par étape ou un processus de raisonnement avant d'arriver à une réponse finale. Cette méthode aide le modèle à décomposer le problème et à ne pas sauter de tâches intermédiaires afin d'éviter les échecs de raisonnement.
Le CoT est efficace parce qu'il aide à focaliser le mécanisme d'attention du LLM. La décomposition du processus de raisonnement permet au modèle de concentrer son attention sur une partie du problème à la fois, minimisant ainsi le risque d'erreurs qui pourraient résulter du traitement simultané d'un trop grand nombre d'informations.
Les chercheurs de Google ont présenté l'incitation par chaîne de pensée dans un article intitulé "Chain of Thought Prompting Elicits Reasoning in Large Language Models" (incitation par chaîne de pensée suscitant le raisonnement dans de grands modèles linguistiques) en 2022. Cette recherche a mis en évidence la manière dont le fait de guider un modèle à travers une série d'étapes de raisonnement intermédiaires a permis d'améliorer de manière significative ses performances dans des tâches telles que la résolution de problèmes mathématiques, le raisonnement logique et la réponse à des questions multi-sauts.
Voyons l'un des exemples proposés :
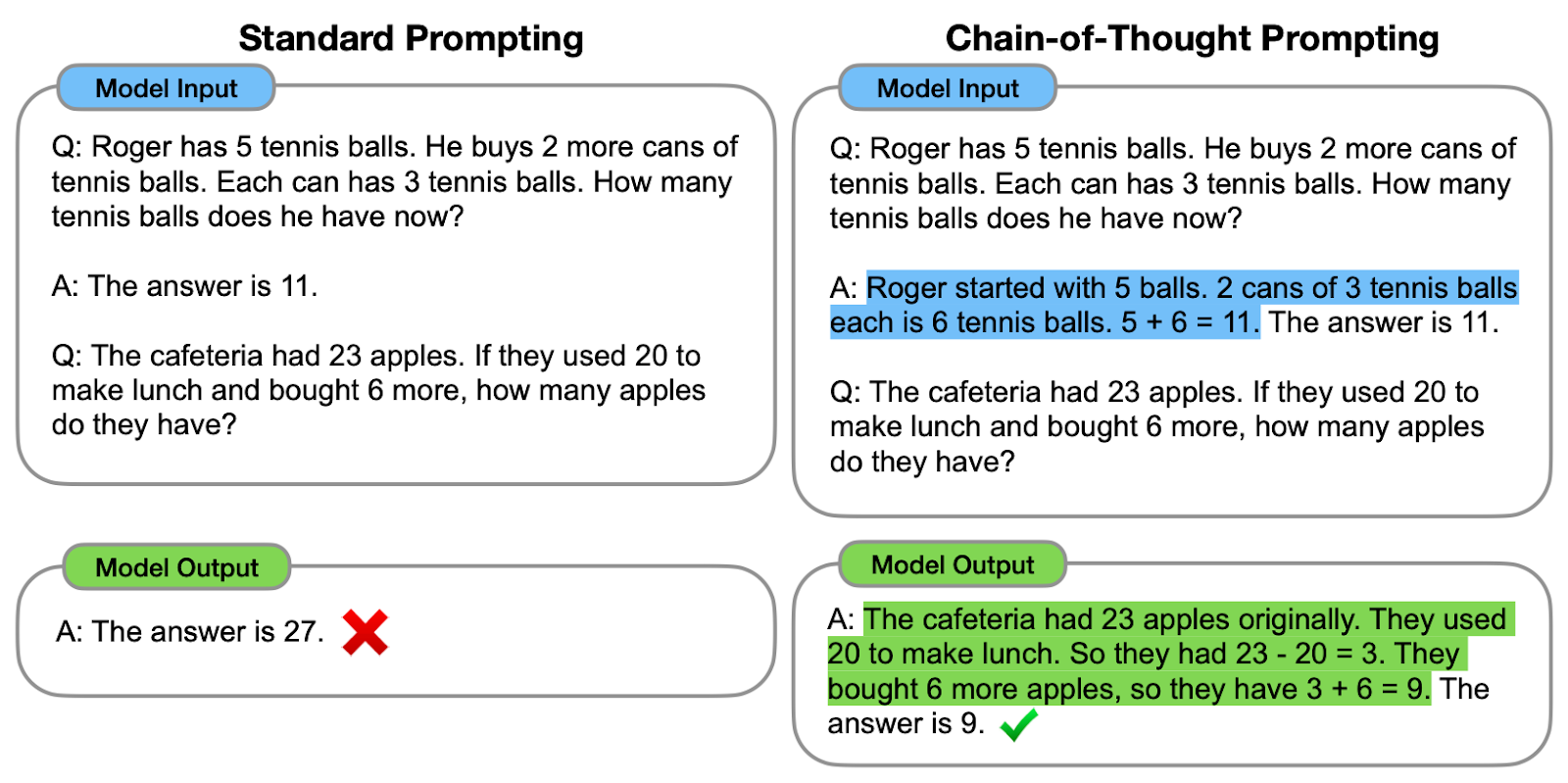
Comparaison entre l'incitation standard et l'incitation CoT. À gauche, le modèle est invité à fournir directement la réponse finale (incitation standard). À droite, le modèle est invité à montrer le processus de raisonnement qui a permis d'aboutir à la réponse finale (incitation CoT).
Comme nous pouvons le constater, la génération d'une chaîne de pensée - une série d'étapes de raisonnement intermédiaires - aide le modèle à fournir la bonne réponse.
Les auteurs originaux désignent la chaîne de pensée comme la série d'étapes intermédiaires de raisonnement en langage naturel qui aboutissent au résultat final, ce qui donne à cette approche le nom de "chaîne de pensée".
Le processus commence par l'élaboration de messages-guides qui encouragent le modèle à réfléchir au problème étape par étape, générant ainsi les étapes intermédiaires sans sauter directement à la réponse finale. Pour ce faire, différentes stratégies peuvent être utilisées :
Donner des instructions explicites signifie décomposer le problème dans l'invite de l'utilisateur elle-même. Par exemple, en utilisant des phrases telles que "Tout d'abord, nous devons considérer..." pour inciter le modèle à détailler son processus de réflexion.
Voyons-le en action !
Imaginez que ma mère espagnole m'ait envoyé la recette familiale pour préparer du Cold Brew :
input_text = """
¡Preparar café Cold Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""Supposons que nous souhaitions traduire tous les mots liés au café en anglais et que nous voulions utiliser ChatGPT pour cette tâche :
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Voici la réponse à cette question :
Si nous demandons au modèle d'effectuer cette tâche immédiatement, nous pouvons constater qu'il l'exécute mal. Non seulement il sort des mots de café sans rapport avec le sujet, mais il les sort également en espagnol, et non en anglais.
On peut considérer que cette tâche est complexe car elle nécessite deux étapes :
Au lieu de cela, le modèle passe directement à la tâche finale d'identification des mots liés au café, sans passer par l'étape de la traduction. En spécifiant la traduction comme une tâche intermédiaire ou en décomposant la tâche en deux étapes principales, nous pouvons guider le modèle vers le résultat correct :
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
The task requires the following actions:
1 - Translate the given text into English.
2 - List each coffee-related word from the English text.
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)L'intégration de la chaîne de pensée ci-dessus permet d'obtenir la bonne réponse :

Si vous souhaitez essayer cette technique avec d'autres LLM plutôt qu'avec ChatGPT ou l'API OpenAI, comme dans cet article, le cours "Developing Large Language Models" est fait pour vous !
Parfois, il n'est pas nécessaire de décomposer le problème nous-mêmes dans l'invite. L'université de Tokyo, en collaboration avec Google Research, a proposé une méthode intéressante pour améliorer les réponses au LLM, qui consiste simplement à ajouter "Réfléchissons étape par étape" à la fin de la question originale.
Cette simple phrase incite le modèle à raisonner à haute voix et à suivre toutes les étapes nécessaires à l'exécution de la tâche.
Analysons l'un des exemples proposés par les auteurs dans l'article original "Large Language Models are Zero-Shot Reasoners" :

Comparaison entre l'incitation standard et l'utilisation d'instructions CoT implicites. À gauche, le modèle fournit immédiatement la réponse finale au problème (incitation zéro) et échoue. À droite, le modèle reçoit une instruction CoT implicite (CoT prompting) qui l'amène à la bonne réponse.
[a] Dans le premier exemple, les auteurs demandent au modèle de résoudre un problème arithmétique, mais il échoue dans cette tâche.
[Ensuite, en ajoutant "Réfléchissons pas à pas" à la question initiale, le modèle raisonne la réponse à haute voix et réussit.
En appliquant cette astuce simple à l'ensemble de données mathématiques MultiArith, les auteurs ont constaté que cette instruction implicite quadruplait la précision, qui passait de 18 % à 79 % !
Si cela vous intéresse, vous pouvez en savoir plus sur cette technique en consultant "Use This Short Prompt to Boost ChatGPT's Outcome" (Utilisez cette courte incitation pour augmenter les résultats du chatGPT).
Nous avons utilisé plusieurs fois le terme "zéro coup" dans la section ci-dessus. L'expression "Zero-shot" fait référence à la capacité d'un modèle à effectuer une tâche sans avoir été explicitement formé sur des exemples de cette tâche spécifique.
Elle repose sur la capacité du modèle à généraliser et à générer des réponses appropriées à des tâches nouvelles et inédites. Cela signifie que lorsque nous ouvrons l'interface utilisateur du ChatGPT et que nous posons une question immédiatement, nous ne faisons pas d'incitation.
Néanmoins, il existe des moyens de montrer au modèle plusieurs exemples de tâches similaires que nous voulons résoudre. Le fait de fournir une série d'exemples démonstratifs est connu sous le nom de "one-shot" ou "few-shot", en fonction du nombre d'exemples fournis.
L'incitation ponctuelle consiste à montrer au modèle un exemple similaire à la tâche cible pour le guider.
Par exemple, si nous nous référons à la première figure de l'article, nous pouvons observer que le modèle génère la chaîne de pensée grâce à l'exemple démonstratif fourni dans l'invite.
L'apprentissage à quelques coups fonctionne de la même manière que l'apprentissage à un coup, mais le nombre d'exemples donnés est plus élevé, généralement autour d'une centaine. La performance du modèle augmente linéairement avec le nombre d'exemples.
L'incitation par quelques tirs a été étudiée par Jason Wei et Denny Zhou et al. de Google. Cette approche est particulièrement utile pour les tâches qui requièrent des connaissances plus spécialisées ou spécifiques à un domaine, lorsque le modèle peut ne pas disposer de connaissances de base suffisantes pour effectuer la tâche à l'aide d'un message-guide zéro ou un message-guide unique. L'incitation à quelques reprises est parfois considérée comme une petite mise au point du modèle sur un ensemble de données nouvelles ou spéciales.
Vous trouverez d'autres exemples d'incitations à une ou plusieurs reprises à la rubrique "Améliorer les performances du chatGPT grâce à l'ingénierie des incitations".
Les messages d'incitation à une ou plusieurs reprises ne font pas partie de la CdT. Cependant, les chercheurs ont étudié la manière dont l'apprentissage en quelques coups peut être combiné avec l'incitation à l'utilisation de la CdT, connue sous le nom d'"incitation à l'utilisation de la CdT en quelques coups". Dans le cadre d'un CoT à quelques plans, le modèle reçoit quelques exemples de problèmes ainsi que leurs solutions étape par étape afin de guider son processus de raisonnement.
La combinaison de l'incitation CoT à quelques coups avec d'autres techniques, telles que la génération augmentée par la recherche ou l'interrogation interactive, peut encore améliorer les performances et la fiabilité du modèle. L'intégration de bases de connaissances externes, de bases de données ou de systèmes de recherche d'informations permet au modèle d'améliorer son raisonnement à l'aide d'informations factuelles et actualisées.
Labyrinthe de problèmes mathématiques pour illustrer la manière dont la CoT peut aider les modèles à naviguer dans l'espace de connaissances et à résoudre des tâches complexes. Image auto-générée à l'aide de ChatGPT 4o avec l'invite suivante : "Imaginez un agent du modèle linguistique à travers un labyrinthe de problèmes mathématiques".
Il y a de multiples façons d'inclure le CdT dans nos messages-guides :
De nombreux frameworks peuvent vous aider à mettre en œuvre CoT et d'autres techniques de Prompt Engineering, mais LangChain est mon préféré. Si vous souhaitez utiliser LangChain dans le cadre de vos projets LLM, le cours "Développer des applications LLM avec LangChain" est un point de départ idéal.
L'incitation à la chaîne de pensée présente plusieurs avantages, notamment pour améliorer les performances et la fiabilité des modèles linguistiques dans des tâches complexes.
En décomposant un problème en étapes plus petites et plus faciles à gérer, le modèle peut traiter des tâches complexes avec plus de précision. Les étapes intermédiaires constituent des points de contrôle où les erreurs potentielles peuvent être détectées et corrigées, ce qui permet d'obtenir des réponses finales plus précises.
La raison pour laquelle les tâches telles que les problèmes mathématiques, les énigmes logiques ou les réponses à des questions à plusieurs bonds bénéficient de cette approche est qu'elles requièrent déjà naturellement plusieurs étapes de raisonnement.
Le processus de raisonnement étape par étape est transparent, ce qui permet aux utilisateurs de comprendre comment le modèle est arrivé à sa conclusion. Cette transparence renforce la confiance dans les résultats du modèle.
Il peut également faciliter le débogage, car les utilisateurs peuvent plus facilement repérer les erreurs de raisonnement du modèle.
Bien sûr, comme pour toute technique, il y a toujours des inconvénients à prendre en compte :
Il est important de considérer que le CoT est une technique qui dépend du modèle. Par conséquent, l'efficacité des messages-guides du CoT dépend largement des capacités du modèle linguistique sous-jacent.
Il peut également être difficile de rédiger des messages d'incitation à la coopération transfrontalière efficaces. Il faut une conception minutieuse pour s'assurer que les invites guident correctement le modèle tout au long du processus de raisonnement. La mise à jour et la maintenance des messages-guides pour différents types de tâches et de domaines peuvent prendre du temps et nécessiter une amélioration constante.
L'incitation par la CdT peut ne pas être aussi efficace pour les tâches qui ne comportent pas de processus de raisonnement séquentiel clair. En outre,il se peut qu'il ne s'adapte pas bien à des types de problèmes entièrement nouveaux ou inattendus sans formation ou adaptation supplémentaire, d'où l'importance de maintenir une base de connaissances à jour et des messages-guides adéquats.
Si l'invite CoT améliore l'interprétabilité en fournissant des explications étape par étape, elle peut également conduire à des résultats plus longs et plus verbeux, ce qui n'est pas toujours souhaitable pour toutes les applications.
Dans cet article, nous avons vu comment l'incitation par la chaîne de pensée représente une avancée significative dans l'amélioration des capacités de raisonnement des grands modèles de langage, ainsi que quelques exemples pratiques de sa mise en œuvre.
Qu'il s'agisse de modèles d'invite, d'invites interactives ou de boucles de rétroaction, l'idée sous-jacente à ces approches est de guider le modèle tout au long du processus de raisonnement et d'exploiter ses capacités.
En outre, nous avons exploré des techniques puissantes telles que l'incitation à une ou plusieurs reprises, qui améliorent encore les performances du modèle et peuvent être combinées avec le CoT, ainsi que les avantages et certaines limites que nous ne pouvons pas ignorer.
Envisagez d'essayer les techniques présentées dans cet article pour créer des invites plus fiables et plus performantes, et gardez à l'esprit ce qui suit : L'ingénierie rapide peut avoir un impact important sur vos résultats !
Vous pouvez en apprendre davantage sur l'ingénierie des invites en suivant les cours de DataCamp, Comprendre l'ingénierie des invites et ChatGPT Prompt Engineering for Developers. Vous pouvez également consulter un guide distinct sur la certification rapide en ingénierie et découvrir les meilleurs parcours de formation pour vous.
Les meilleurs cours de DataCamp
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach