Datenanalyse in Google Sheets
12.2K learners
Der Chi-Quadrat-Test ist ein statistischer Test, mit dem festgestellt werden kann, ob die beobachteten Häufigkeiten in einer oder mehreren Kategorien signifikant von den erwarteten Häufigkeiten abweichen oder nicht(Quelle). Im mathematischen Ausdruck ist es das Verhältnis von experimentell beobachteten Ergebnissen/Häufigkeiten (O) und den theoretisch erwarteten Ergebnissen (E) auf der Grundlage bestimmter Hypothesen, oder es wird berechnet, indem die Gesamtabweichung von den beobachteten und erwarteten Häufigkeiten durch die erwarteten Häufigkeiten geteilt wird.
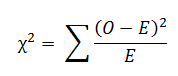
Wenn es keinen Unterschied zwischen den beobachteten und den erwarteten Häufigkeiten gibt, wäre der Chi-Quadrat-Wert gleich null. Wenn es einen Unterschied gibt, dann wäre der Wert des Chi-Quadrats größer als Null.
Wenn du den berechneten Wert mit den Tabellenwerten vergleichst, musst du den Freiheitsgrad berechnen. Dann kannst du vergleichen und eine Schlussfolgerung ziehen.
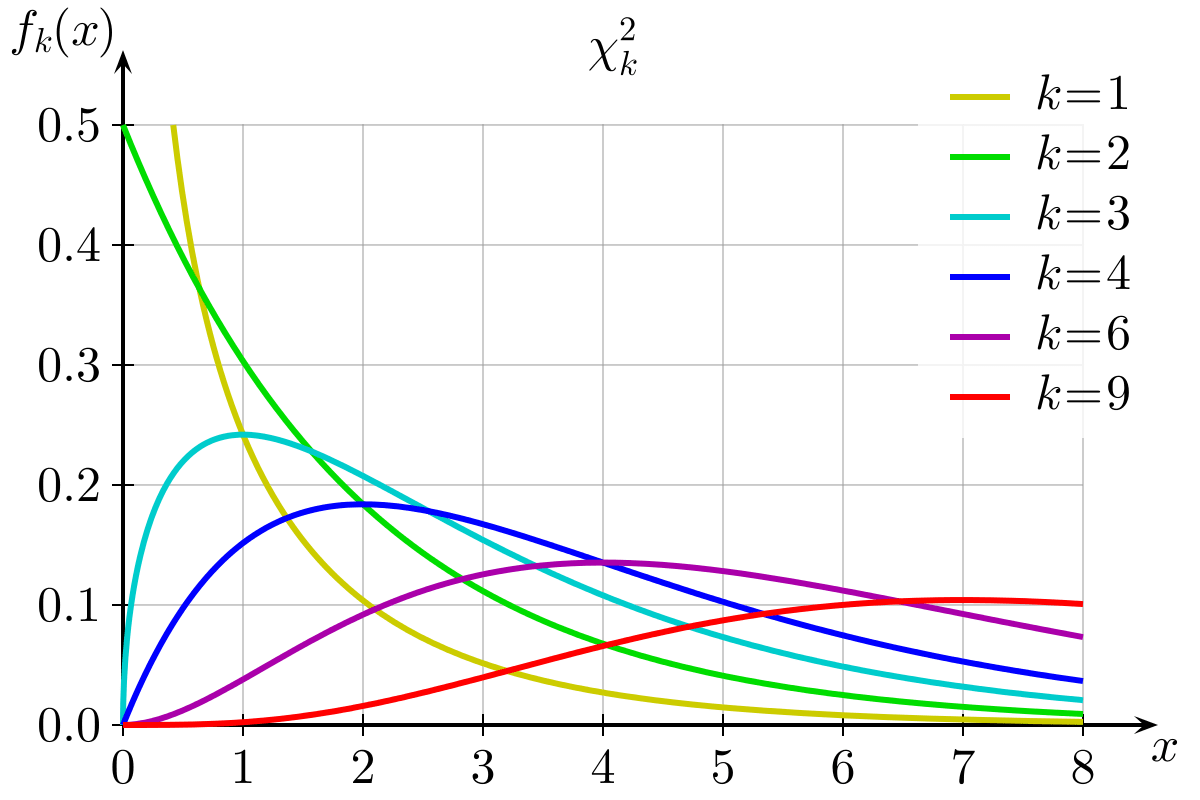
Diagramm der Chi-Quadrat-Wahrscheinlichkeitsverteilung: Bildquelle:
Es gibt drei Arten von Chi-Quadrat-Tests:
Kontingenztabelle: Dies ist eine Kreuztabelle oder eine Zwei-Wege-Tabelle. Du zeigst die eine Variable in einer Zeile und die andere in einer Spalte mit ihrer Häufigkeit an. Sie ist eine Art Häufigkeitsverteilungstabelle der kategorialen Variablen.
Beobachtete Frequenzen: Sind Zählungen aus experimentellen Daten. Mit anderen Worten: Du beobachtest das Geschehen und nimmst Messungen vor. (Quelle)
Erwartete Frequenzen: Sind Zählungen, die mithilfe der Wahrscheinlichkeitstheorie berechnet werden. Die erwarteten Häufigkeiten werden für jede Zelle in der Kontingenztabelle berechnet.
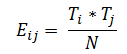
Wo,
Du kannst dir das auch so vorstellen: (Zeilensumme * Spaltensumme) / Gesamtsumme
Alternativhypothese (HA): Sie geht davon aus, dass die beiden Variablen mit der Bevölkerung in Verbindung stehen. Wenn du davon ausgehst, dass von zwei Methoden die Methode A der Methode B oder die Methode B der Methode A überlegen ist, dann wird diese Annahme als Alternativhypothese bezeichnet.
Freiheitsgrad: Die Anzahl der unabhängigen Variablen, aus denen die Statistik besteht, wird als Freiheitsgrad der Statistik bezeichnet.
Wo,
Dies wird für den Unabhängigkeitstest und den Homogenitätstest verwendet, nicht für die Anpassungsgüte.
Die Passgenauigkeit: Der Chi-Quadrat-Anpassungstest ist ein nichtparametrischer Test, der verwendet wird, um herauszufinden, inwieweit sich der beobachtete Wert eines bestimmten Phänomens signifikant vom erwarteten Wert unterscheidet. Bei diesem Test hast du nur eine Variable aus einer einzigen Population(Quelle).
Nullhypothese (H0): Bei der Chi-Quadrat-Anpassungsprüfung geht die Nullhypothese davon aus, dass es keinen signifikanten Unterschied zwischen dem beobachteten und dem erwarteten Wert gibt(Quelle).
Alternativhypothese (Ha): Beim Chi-Quadrat-Anpassungstest geht die Alternativhypothese davon aus, dass es einen signifikanten Unterschied zwischen dem beobachteten und dem erwarteten Wert gibt(Quelle).
Nehmen wir ein einfaches Beispiel: Du hast 120 Mal einen fairen sechsseitigen Würfel geworfen und die beobachteten Häufigkeiten erhalten.

Folglich,
p1 = p2 = p3 = p4 = p5 = p6 = 1/6
Ha = Mindestens ein p ist ungleich 1/6, oder die Daten stimmen nicht mit dem erwarteten überein.
Unabhängigkeitstest: Mit diesem Test wird geprüft, ob zwei kategoriale Variablen unabhängig sind oder nicht.
H0: Die Zeilenvariable ist unabhängig von der Spaltenvariable, oder es besteht keine signifikante Beziehung zwischen den Variablen Ha: Die Beziehung ist signifikant.
Kriterien und Entscheidungsregel: Der Ablehnungsbereich ist immer rechtsschwanzförmig, wobei die χ2-Verteilung mit (r-1)(c-1) Freiheitsgraden verwendet wird. (r = Anzahl der Zeilen, c = Anzahl der Spalten)
Verwirf H0, wenn χ2berechnet > χ2tabuliert
DOF = (r-1)(c-1)
H0: Die Häufigkeitszahl ist in der gesamten Bevölkerung gleich. Ha: Die Häufigkeitsauszählung in der Bevölkerung ist unterschiedlich.
Kriterien und Entscheidungsregel: Der Ablehnungsbereich ist immer rechtsschwanzförmig, wobei die χ2-Verteilung mit (r-1)(c-1) Freiheitsgraden verwendet wird. (r = Anzahl der Zeilen, c = Anzahl der Spalten)
Verwirf H0, wenn χ2berechnet > χ2tabuliert
DOF = (r-1)(c-1)
Angenommen, du möchtest die Fehler in den von einer Produktionsstätte hergestellten Möbeln anhand der Art der Fehler und der Produktionsschicht klassifizieren. Insgesamt wurden 390 Möbeldefekte erfasst und die Defekte wurden in die vier Typen A, B, C und D eingeteilt.
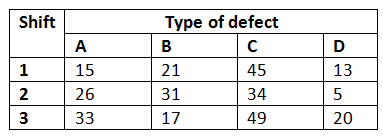
Quelle: Ingenieurstatistik Buch
Lösung: Du musst dir ansehen, ob die Fehlerarten von der Produktionsschicht abhängig sind oder nicht. Lösen wir das Problem also mit Excel.
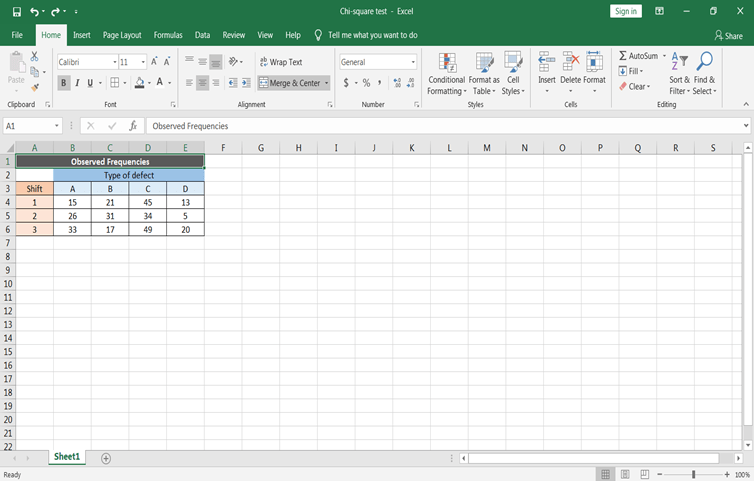
Die Null- und die Alternativhypothese im obigen Abschnitt zu definieren. Das Hauptziel ist es, zu prüfen, ob die Möbeldefekte unabhängig von der Produktionsschicht sind oder nicht:
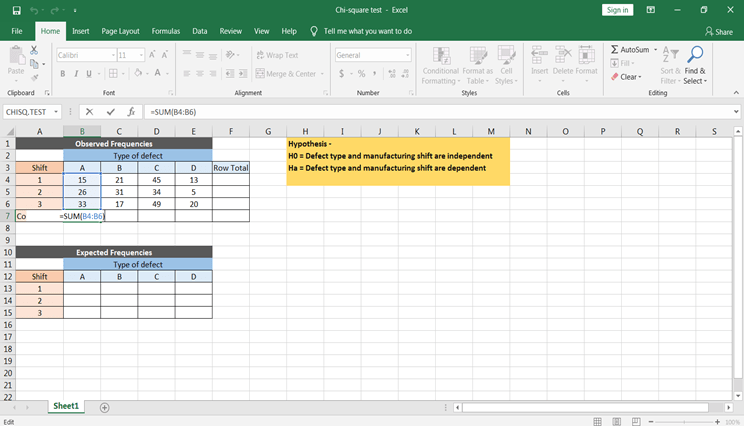
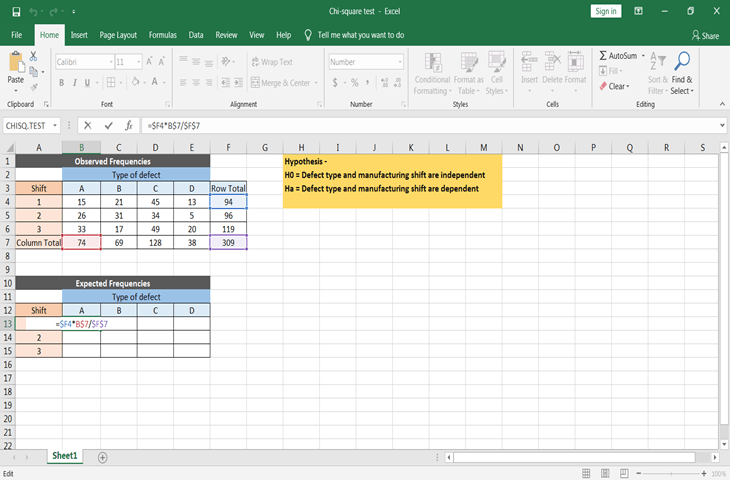
Vergiss nicht, die Zellen beim Anwenden der Formel absolut zu setzen, damit du die Formel für alle erwarteten Werte kopieren und einfügen kannst.
Bevor du den Chi-statistischen Wert oder den p-Wert berechnest, musst du zunächst das Signifikanzniveau bestimmen. Das bedeutet, auf welchem Signifikanzniveau du die Antwort wissen willst. Gehen wir von einem Signifikanzniveau α = 0,05 aus. Außerdem wäre der Freiheitsgrad = (r-1)(c-1) = (3-1)(4-1) = 6.
Es gibt zwei Möglichkeiten, die Chi-Quadrat-Statistik zu berechnen: Entweder mit der Formel χ^2= ∑(O-E)^2/E oder mit der Excel-Funktion, um den Wert der Chi-Quadrat-Statistik zu ermitteln.
Rechnen wir zunächst mit der Formel. Dazu musst du ∑(O-E)^2/E mit Excel berechnen. Dies kannst du mit dem folgenden Schritt tun -
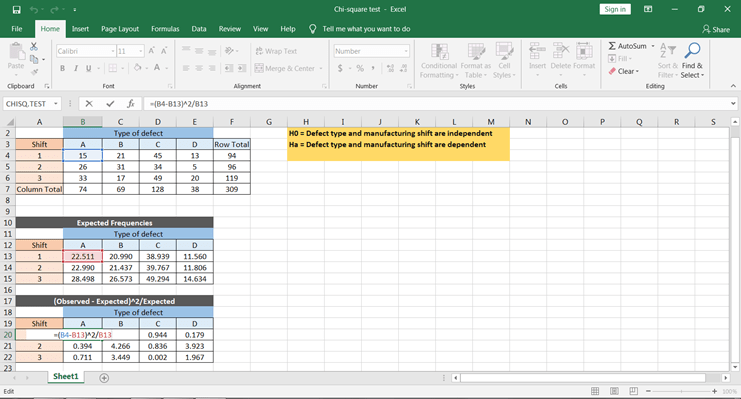
Du kannst alle Werte erhalten, indem du diese Formel kopierst und in alle Zellen einfügst.
Um die χ^2-Werte zu erhalten, nimmst du die Summe aller Werte und erhältst den Wert der Chi-Quadrat-Statistik.
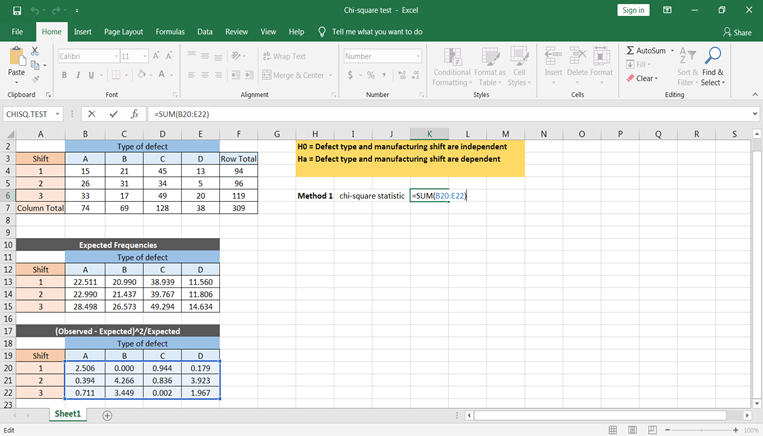
Aus den tabellarischen und berechneten Werten kannst du schließen, dass die Fehlerarten und die Schichtzeiten voneinander abhängig sind.

Jetzt wollen wir mit der Excel-Funktion rechnen. Die Funktion CHISQ.TEST() liefert den p-Wert, der direkt mit dem Signifikanzniveau verglichen werden kann, um die Ergebnisse zu ermitteln.
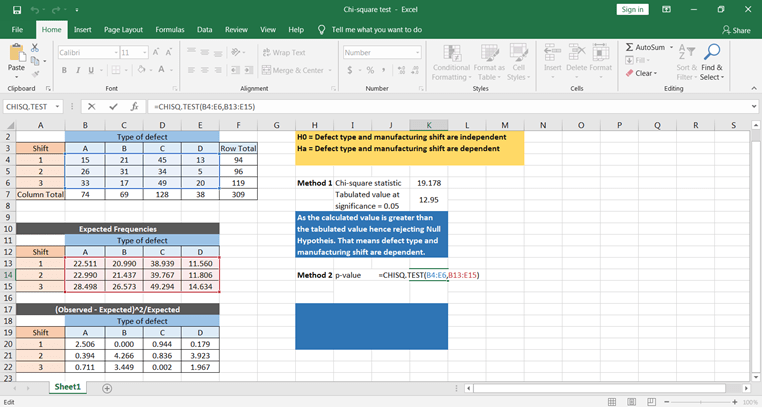
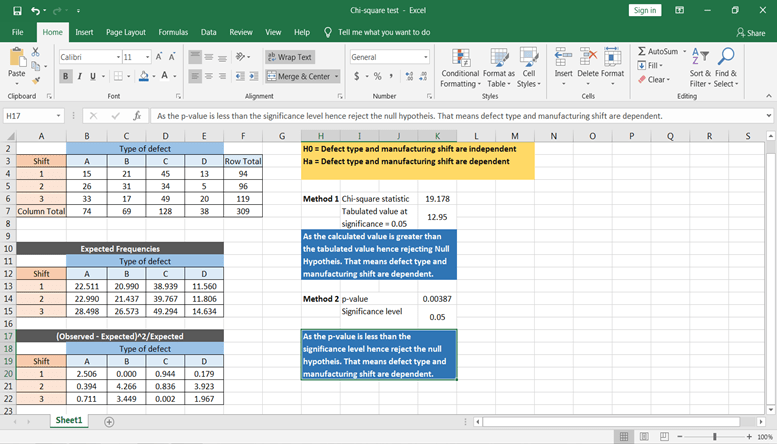
Aus dem p-Wert kannst du schließen, dass der Fehler von der Produktionsschichtzeit abhängt.
Vorteile:
Nachteile:
Glückwunsch, du hast es bis zum Ende dieses Tutorials geschafft!
In diesem Lernprogramm hast du viele Details des Chi-Quadrat-Tests behandelt. Du hast gelernt, was ein Chi-Quadrat-Test ist, welche Begriffe beim Chi-Quadrat-Test verwendet werden, welche Arten von Chi-Quadrat-Tests es gibt, welche Beispiele es für Chi-Quadrat-Tests gibt und wie man einen Chi-Quadrat-Test in Tabellenkalkulationen löst. Außerdem hast du dir die Vor- und Nachteile angesehen.
Hoffentlich kannst du jetzt die Chi-Quadrat-Konzepte anwenden, um die Hypothese zu testen. Danke fürs Lesen dieses Tutorials!
Schau dir unser Tutorial "Erste Schritte mit Tabellenkalkulationen" an.
Wenn du mehr über Statistik in Tabellenkalkulationen lernen möchtest, besuche den DataCamp-Kurs Statistik in Tabellenkalkulationen.
Erwerbe die Fähigkeiten, um Excel optimal zu nutzen - keine Erfahrung erforderlich.
Tabellenkalkulationskurse
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
