
Lernpfad
dbt Grundlagen
8 Std.
dbt (Data Build Tool) ist ein echt starkes Tool, das von Datenanalysten und -ingenieuren verwendet wird, um Daten im modernen Datenstack zu transformieren, zu testen und zu dokumentieren.
Obwohl es vor allem für seine Modellierungsfunktionen bekannt ist, gibt's noch eine weitere wichtige Funktion: dbt Snapshot. Damit kannst du langsam wechselnde Dimensionen (SCD) in deinem Data Warehouse erfassen.
In diesem Tutorial erfährst du alles über dbt-Snapshots, wofür man sie benutzt und wie man sie einsetzt. Ich werde:
Wenn du mehr über dbt erfahren möchtest, schau dir unbedingt unseren Leitfaden „ “ an . Was ist dbt? Eine praktische Einführung für Dateningenieure „ “ und unser Kurs „Einführung in dbt“.
Ein dbt-Snapshot ist ein Mechanismus, um Änderungen in Datensätzen im Laufe der Zeit zu verfolgen, vor allem für Tabellen, in denen historische Änderungen standardmäßig nicht gespeichert werden. Snapshots werden hauptsächlich verwendet, um langsam wechselnde Dimensionen (SCD) vom Typ 2. Sie speichern Versionen von Zeilen, wenn sich verfolgte Spalten ändern.
Anwendungsfälle sind zum Beispiel:
dbt-Snapshots sind super, weil sie Datenänderungen im Laufe der Zeit aufzeichnen und so historische Analysen und Compliance-Berichte ermöglichen.
Hier sind ein paar Vorteile, die du mit Snapshots hast:
Snapshots können in bestimmten Situationen nützlich sein, zum Beispiel:
Snapshots lassen sich nahtlos in das Ökosystem von dbt integrieren und nutzen dessen Konfigurations- und Ausführungsmanagement, um historische Tabellen effizient zu erstellen.
Schauen wir uns mal die Arten von Modellen an, die in Daten verwendet werden.
Für die Daten gibt's zwei Modelle:
Diese beiden Modelle unterscheiden sich in ihrem Zweck, ihrer Speichermethode und ihren Anwendungsbereichen.
Hier eine kurze Zusammenfassung der Unterschiede:
|
Funktion |
Standardmodelle |
Schnappschüsse |
|
Zweck |
Aktuelle Zustandsänderungen |
Historische Nachverfolgung |
|
Lagerung |
Tabelle oder Ansicht mit aktuellen Daten |
Nur-Anhängen-Verlaufstabelle |
|
Am besten geeignet für |
Fakten-/Dimensionsmodelle |
Sich langsam verändernde Dimensionen |
Snapshots folgen normalerweise einem strukturierten Ablauf, der sicherstellt, dass alle Änderungen systematisch erfasst werden. Dabei sind folgende Schritte zu beachten:
dbt snapshot “ aus, um die aktuellen Daten mit den vorhandenen Snapshots zu vergleichen.Aber wie werden Änderungen in dbt verfolgt?
Alle Änderungen werden in der Tabelle „Ausgabe-Snapshot“ festgehalten.
Wenn eine Änderung gefunden wird, aktualisiert dbt das Feld „ dbt_valid_to “ für die vorherige Version mit dem aktuellen Zeitstempel und fügt eine neue Zeile mit dem Feld „ dbt_valid_from “ als aktuellen Zeitstempel ein.
Snapshots nutzen zwei Hauptstrategien, um Änderungen zu erkennen.
updated_at.|
Strategie |
Erkennungsmethode |
Am besten geeignet für |
|
Zeitstempel |
Aktualisierte Zeitstempel-Spalte |
Tabellen mit zuverlässigen Zeitstempeln für die letzte Änderung |
|
Überprüfen |
Direkter Vergleich von Spalten |
Tabellen ohne Zeitstempel-Spalten |
Datenänderungen, wie zum Beispiel Löschungen, können auch verfolgt werden, aber nicht standardmäßig. Es gibt aber eine Möglichkeit, das zu ändern, um solche endgültigen Löschungen zu überwachen.
invalidate_hard_deletes=True “, um gelöschte Zeilen mit dem Wert „ dbt_valid_to “ zu markieren und ihren letzten Status zu behalten.Hier ist ein Beispiel für eine Prüfstrategie, die unter Berücksichtigung von endgültigen Löschungen umgesetzt wird:
{%
snapshot customers_snapshot %}
{%
set config(
target_schema='snapshots',
unique_key='customer_id',
strategy='check',
check_cols=['tier'],
invalidate_hard_deletes=True
)
%}
SELECT * FROM {{ source('customers') }}
{% endsnapshot %}Jetzt, wo wir wissen, wie dbt-Snapshots funktionieren, schauen wir uns an, wie man sie einsetzt.
Um Snapshots zu üben, erstellen wir eine Beispieltabelle „Kunden“, die ein echtes Mitgliedersystem nachahmt. Das gibt uns ein paar konkrete Daten, um gängige Snapshot-Strategien zu testen.
import csv
from datetime import datetime
# Define the data
customers_data = [
["customer_id", "name", "tier", "updated_at"], # header row
[1, "Alice Tan", "Silver", "2025-07-01 10:00:00"],
[2, "Bob Lee", "Gold", "2025-07-01 10:00:00"],
[3, "Cheryl Lim", "Silver", "2025-07-01 10:00:00"]
]
# Write data to customers.csv
with open("customers.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerows(customers_data)Bevor du Snapshots machen kannst, musst du dein dbt-Projekt richtig einrichten. So stellst du sicher, dass deine Umgebung so eingerichtet ist, dass Modelle, Snapshots, Tests und Dokumentation auf strukturierte und skalierbare Weise verwaltet werden können.
pip install dbtErsetz „dbt-postgres” durch deinen Warehouse-Adapter, z. B. „dbt-snowflake” oder „dbt-bigquery”, je nachdem, was du benutzt.
1. Geh zum Projektordner, den du brauchst.
Hier speicherst du deine Analyse- oder ELT-Projekte. In diesem Fall speichern wir alle zugehörigen Dateien in diesem dbt-Projektordner.
cd ~/dbt-snapshot-project2. Starte ein neues dbt-Projekt.
Erstell eine Konfigurationsdatei namens dbt_project.yml:
Füge das Folgende in deine Projektdatei ein:
name: dbt_snapshots_project
version: '1.0'
profile: austinchia
seeds:
dbt_snapshots_project:
+quote_columns: false3. Teste deine Verbindung.
dbt debugDas sollte die Ausgabe des Befehls sein:
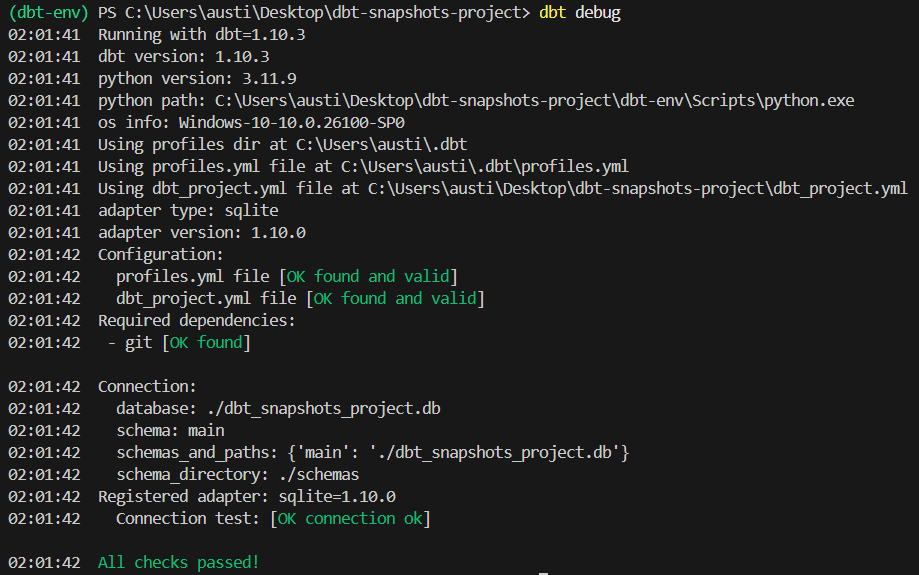
4. Lade die Samen in eine lokale Datenbank.
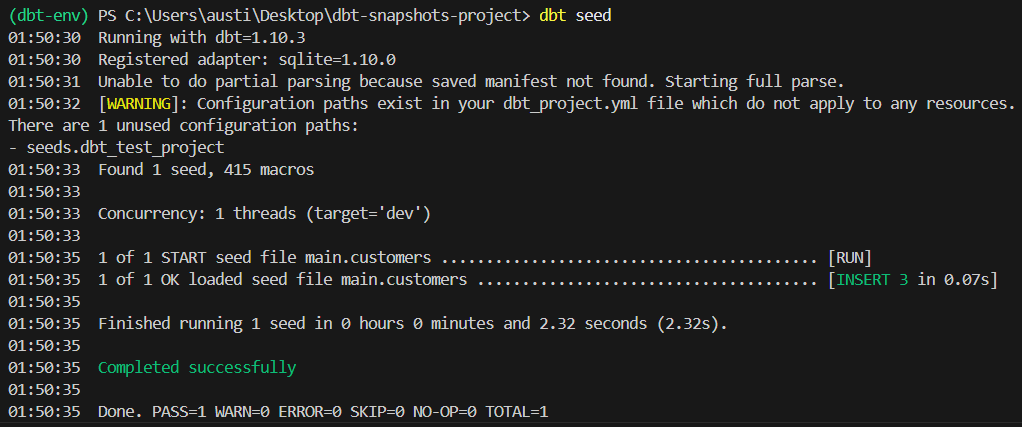
Führ den folgenden Befehl aus:
dbt seedDas sollte die Ausgabe des Befehls sein:
5. Mach deine Datenbank-Verbindungseinstellungen fertig
In der Datei „profiles.yml“, die normalerweise unter ~/.dbt/profiles.yml zu finden ist.
Hier ist, was in meiner Profil-Datei steht:
austinchia:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_snapshots_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_snapshots_project.db
extensions:
- "C:/sqlean/crypto.dll"Wenn du eine SQLite-Datenbank wie ich, musst du das SQLean .
6. Lade deine Daten in die dbt-Staging-Modelle:
Mach einen neuen Ordner namens „models“. Erstell in diesem Ordner eine Datei mit dem Namen „ stg_customers.sql “.
Kopiere den folgenden Code in die Datei:
SELECT
*
FROM {{ ref('customers') }}7. Erstell Staging-Modelle mit dem folgenden Befehl in dbt.
dbt run --select stg_customersDas sollte die Ausgabe des Befehls sein:
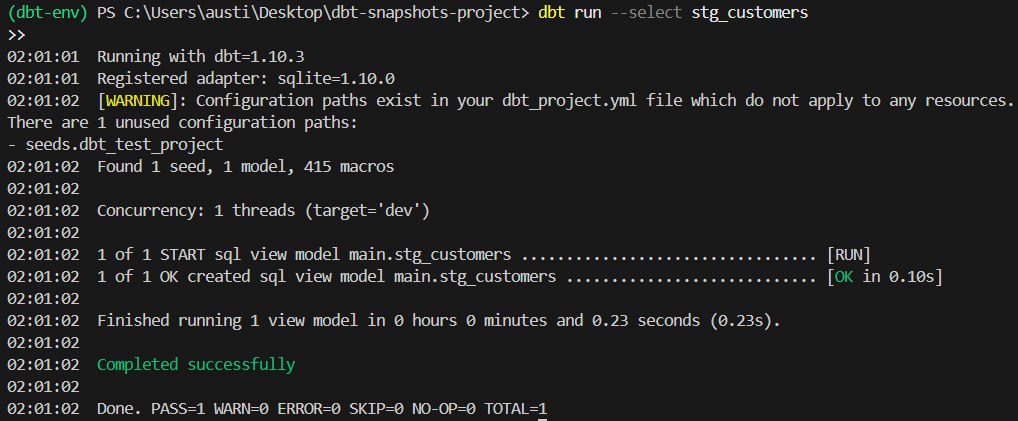
Für dieses Beispiel kannst du den folgenden Code verwenden, um einen Snapshot mit Zeitstempelstrategie durchzuführen.
{% snapshot customers_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='customer_id',
strategy='timestamp',
updated_at='updated_at'
)
}}
select * from {{ ref('customers') }}
{% endsnapshot %}Ausführen:
dbt snapshotIn diesem Befehl erstellt dbt die Snapshot-Tabelle, falls sie noch nicht vorhanden ist. Außerdem werden neue Zeilen für gefundene Änderungen eingefügt.
Das sollte die Ausgabe des Befehls sein:
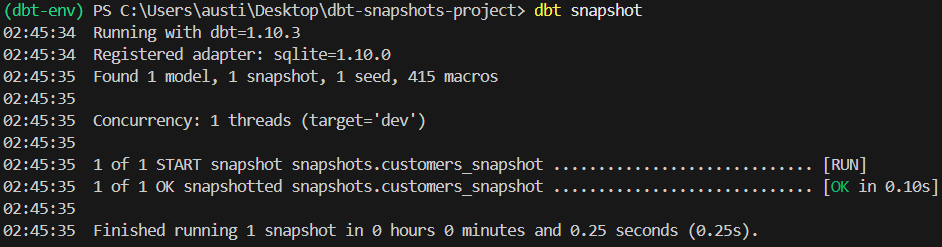
Nachdem du den Snapshot erstellt hast, sollte eine neue Datei namens „ snapshot.db “ in deinem Projektverzeichnis erstellt worden sein.
Ich hab das in VSCode geöffnet, um zu sehen, wie die Datei aussieht:

Wie du sehen kannst, gibt's da noch ein paar Spalten, wie zum Beispiel „ dbt_updated_at “ und so weiter. Diese sind entscheidend, um festzustellen, ob und wann Änderungen an den Daten vorgenommen wurden.
Weitere praktische Anleitungen zu dbt findest du in unserem Semantic Layer mit dbt.
Mit Snapshots können Teams einen vollständigen Prüfpfad aller Änderungen an beliebigen Attributen in einer Tabelle im Laufe der Zeit erfassen, was sie für Compliance, Fehlerbehebung und Analysen sehr nützlich macht.
customers -Tabelle mit den relevanten Feldern. Dazu gehören die Kunden-ID, der Name, die E-Mail-Adresse und der Zeitstempel „updated_at“, um zu verfolgen, wann Änderungen vorgenommen wurden.CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
updated_at TIMESTAMP
);Verwende den folgenden Code, um Daten in die Tabelle einzufügen. Diese Daten werden für die Originaldaten vor der Änderung verwendet.
INSERT INTO customers VALUES
(1, 'Alice Tan', 'alice@example.com', '2025-07-01 10:00:00'),
(2, 'Bob Lee', 'bob.lee@example.com', '2025-07-01 10:00:00');{% snapshot customers_email_snapshot %}
{%
set config(
target_schema='snapshots',
unique_key='customer_id',
strategy='check',
check_cols=['email'],
invalidate_hard_deletes=True
)
%}
SELECT * FROM {{ source('customers') }}
{% endsnapshot %}dbt snapshot “, um den Anfangszustand zu speichern.dbt snapshotAls Nächstes aktualisieren wir unsere ursprüngliche Tabelle, indem wir die Informationen eines Kunden ändern, um eine Datenänderung zu simulieren.
UPDATE customers
SET email = 'alice.tan@example.com', updated_at = '2025-07-02 09:00:00'
WHERE customer_id = 1;dbt snapshot “ nochmal, um die Änderung zu speichern.dbt snapshotUm die Unterschiede und Änderungen an den Daten zu sehen, musst du die Snapshot-Tabelle abfragen. Die Tabelle sollte beide Versionen der E-Mail-Adresse mit ihren jeweiligen Gültigkeitszeiträumen zeigen:
SELECT customer_id, email, dbt_valid_from, dbt_valid_to
FROM snapshots.customers_email_snapshot
ORDER BY customer_id, dbt_valid_from;Dieser Prozess stellt sicher, dass du einen vollständigen Änderungsverlauf für E-Mail-Updates behältst, was für DSGVO-Audits, die Nachverfolgung des Kontakthistorien oder die Analyse des Kundensupports super wichtig ist.
Mit einem guten Konfigurationsmanagement können Teams Snapshot-Implementierungen nahtlos über Projekte und Umgebungen hinweg skalieren.
dbt_project.yml “ kannst du Standardkonfigurationen für Snapshots festlegen, wie zum Beispiel das Zielschema oder Materialisierungen, die für alle Snapshots gelten sollen.Standardmäßig erstellt dbt die Felder „ dbt_valid_from “ und „ dbt_valid_to “. Du kannst diese mit den Konfigurationsoptionen „ valid_from “ und „ valid_to “ umbenennen, wenn dein Team aus Gründen der Übersichtlichkeit in BI- oder Datenverwaltungs-Tools andere Namenskonventionen braucht.
Migrationen können zu Problemen führen, wenn sie nicht richtig gemacht werden. Hier sind ein paar Punkte, auf die du bei der Migration deiner Snapshot-Konfigurationen achten solltest:
Datenänderungen können mit dbt-Snapshots verfolgt werden.
Zum Beispiel:
Die Implementierung von dbt-Snapshots in der Produktion erfordert ein durchdachtes Design, um Leistung, Wartbarkeit und Geschäftswert sicherzustellen.
Am besten hältst du dich an Folgendes:
In der Produktion solltest du deine Daten so optimieren, dass Datenänderungen effizient verfolgt werden können, ohne dein Produkt zu beeinträchtigen.
Hier sind ein paar Tipps:
unique_key “ und „validity“ hinzu, damit die Abfragen schneller gehen.Die Verwendung einer nicht eindeutigen ID „ unique_key “ führt zu falschen Zeilenversionen. Teste die Einzigartigkeitslogik immer vor dem Einsatz.
Snapshot-Aufblähung kann auch passieren, wenn unnötige historische Änderungen gespeichert werden (z. B. Spalten mit häufigen Aktualisierungen des Zeitstempels), können die Speicherkosten schnell steigen.
Die Verwendung von Snapshots in dbt kann ein paar technische Herausforderungen mit sich bringen:
Problem: Doppelte Zeilen im Snapshot, weil die eindeutigen Schlüssel nicht richtig definiert sind.
Lösung:
Problem: Langsame Abfragen bei der Analyse historischer Daten.
Lösung:
dbt_valid_from “ oder Datumsbereichen, um die Menge der gescannten Daten zu reduzieren.Häufige Probleme sind:
SELECT -Anweisungen kaputt.Lösungen:
dbt debug “ kannst du die Verbindung und die Konfiguration checken.Mit dbt-Snapshots können Analyse-Teams mit minimalem Aufwand robuste historische Datensätze erstellen, was Compliance-Analysen möglich macht. Wenn du mehr über DBT erfahren möchtest, schau dir unseren Kurs „ Einführung in dbt. Weitere Informationen und Anleitungen findest du in unserer Einführung in das dbt-utils-Paket und dbt-Tutorial.
Top-Kurse von DataCamp
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
