
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Viele moderne Unternehmen verlassen sich auf semantische Schichten, um die Lücke zwischen den in Data Warehouses wie Snowflake gespeicherten Rohdaten und den Erkenntnissen in Dashboards oder Berichten zu schließen.
Eine semantische Ebene ist eine Abstraktion, die konsistente Metriken, Kennzahlen und Dimensionen für Analysen und Berichte definiert.
In diesem Tutorial wird gezeigt, wie man eine semantische Schicht mit dbt (data build tool), einem beliebten Framework zur Datentransformation und -modellierung, implementiert. Dieser Leitfaden enthält praktische Beispiele und Erkenntnisse, die dir helfen, das Konzept zu beherrschen.
Eine semantische Ebene übersetzt Rohdaten in konsistente, wiederverwendbare Metriken und Dimensionen und vereinfacht so die Datenanalyse. Es ist ein Werkzeug, um die Einheitlichkeit zwischen Teams und Tools zu wahren.
Sehen wir uns an, was dbt zum perfekten Werkzeug macht, um Daten- und Analytikingenieuren den Aufbau einer semantischen Schicht zu ermöglichen.
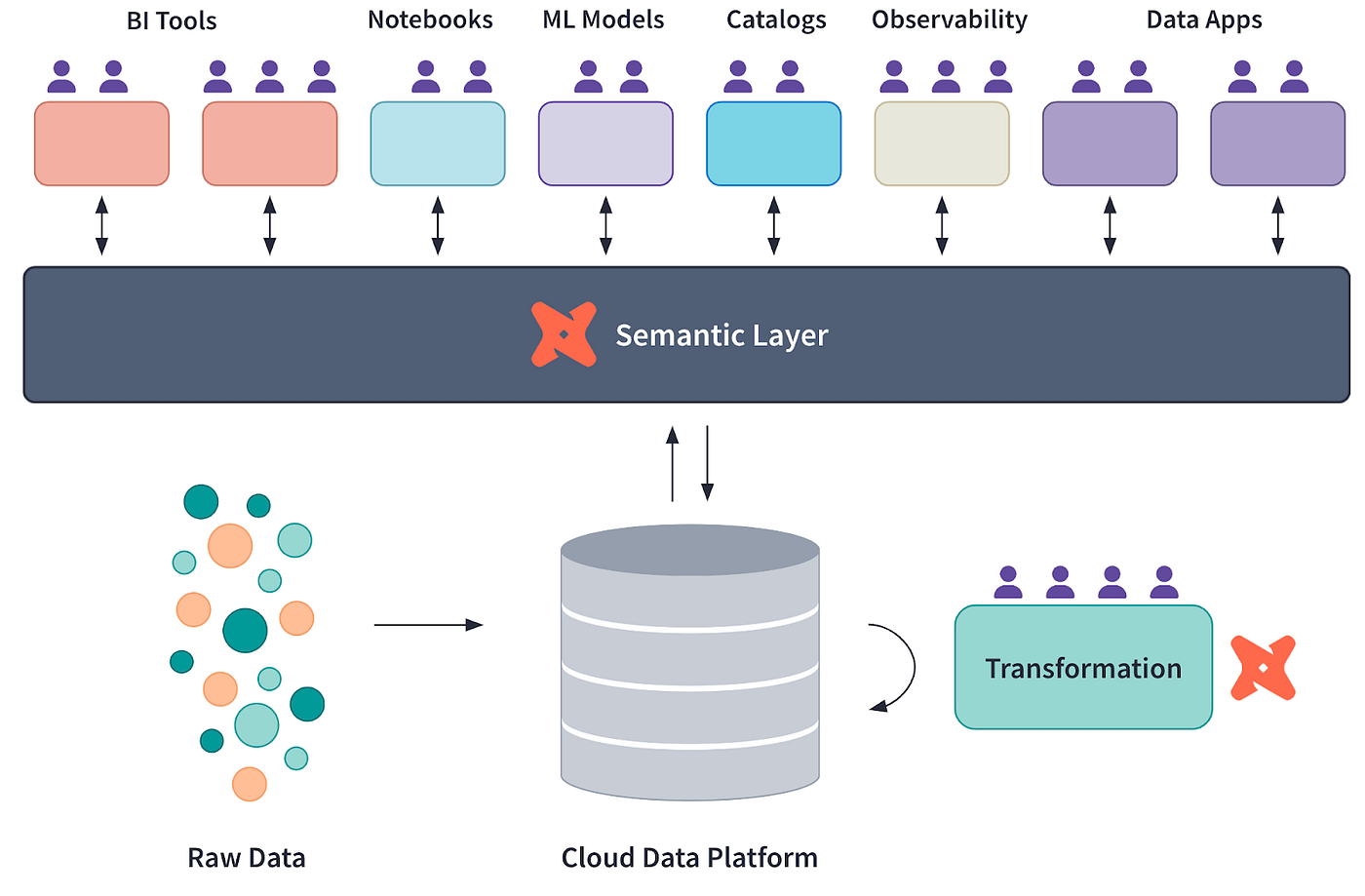
Konzeptdiagramm des dbt Semantic Layer, mitrtesy of dbt Labs
dbt ermöglicht es dir, komplexe Datentransformationen in wiederverwendbare, modulare Modelle zu zerlegen. Diese Modelle können hierarchisch geschichtet werden, wobei die grundlegenden Datenmodelle in die übergeordneten analytischen Modelle einfließen.
Dieser Ansatz macht die Pipeline wartbar und ermöglicht es den Teams, effektiver zusammenzuarbeiten, indem Änderungen an bestimmten Modellen isoliert werden, ohne das gesamte System zu beeinflussen.
Wenn du mehr über die grundlegenden Konzepte und Best Practices von dbt für die Datenmodellierung erfahren möchtest, schau dir das dbt Tutorial an: 7 wichtige Konzepte für Dateningenieure. Sie bietet Einblicke, die die hier dargestellten Strategien ergänzen.
Mit dbt werden Geschäftslogik und Metriken an einer Stelle definiert, um die Konsistenz zwischen verschiedenen Analysetools zu gewährleisten. Mit der dbt-Metrikenfunktion kannst du KPIs wie Umsatz, Konversionsraten oder Abwanderung einmal definieren und sie ohne Neudefinition in Dashboards, Berichten und Analysen verwenden. Dadurch werden Unstimmigkeiten reduziert und die Datenintegrität sichergestellt.
Die Integration von dbtin Git ermöglicht eine robuste Versionskontrolle, mit der du Änderungen im Laufe der Zeit verfolgen und überprüfen kannst. Zusammen mit der automatisch generierten Dokumentation schafft dbt eine lebendige, zugängliche Referenz für alle Datentransformations und Metriken. Das schafft Transparenz und ermöglicht es neuen Teammitgliedern, sich schnell einzuarbeiten, indem sie die dokumentierte Datenpipeline erkunden.
dbt arbeitet mit BI-Plattformen wie Looker, Tableau und Mode zusammen und ermöglicht die Integration der semantischen Ebene in Visualisierungstools. Mit dbt exposures kannst du dbt-Modelle direkt mit BI-Dashboards verknüpfen und so sicherstellen, dass alle Aktualisierungen in den Datenmodellen ohne manuelle Eingriffe in die Analysen übernommen werden.
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
