
Cursus
dbt Fondamentaux
8 h
dbt (data build tool) est un outil performant utilisé par les analystes et ingénieurs de données pour transformer, tester et documenter les données dans la pile de données moderne.
Bien qu'il soit largement reconnu pour ses capacités de modélisation, une autre fonctionnalité essentielle est dbt snapshot, qui vous permet de capturer les dimensions à évolution lente (SCD) dans votre entrepôt de données.
Ce tutoriel vous fournira une explication détaillée des instantanés dbt, de leurs cas d'utilisation et de leur mise en œuvre. Je vais :
Pour en savoir plus sur le dbt, veuillez consulter notre guide « Qu'est-ce que le dbt ? » à l'adresse . Introduction pratique pour les ingénieurs de données et notre cours Introduction à dbt.
Un instantané dbt est un mécanisme permettant de suivre les modifications apportées aux enregistrements au fil du temps, en particulier pour les tableaux dont les modifications historiques ne sont pas conservées par défaut. Les instantanés sont principalement utilisés pour implémenter les dimensions à évolution lente (SCD) de type 2. Ils stockent les versions des lignes lorsque les colonnes suivies changent.
Les cas d'utilisation incluent :
Les instantanés dbt sont précieux car ils servent à enregistrer les modifications apportées aux données au fil du temps, ce qui facilite l'analyse historique et la création de rapports de conformité.
Voici quelques avantages dont vous bénéficierez en utilisant les instantanés :
Les instantanés peuvent s'avérer utiles dans certaines situations particulières, telles que :
Les instantanés s'intègrent parfaitement à l'écosystème dbt, tirant parti de sa configuration et de sa gestion des exécutions pour créer efficacement des tableaux historiques.
Examinons les types de modèles utilisés dans les données à titre d'exemple.
Deux modèles sont utilisés pour les données :
Ces deux modèles diffèrent par leur objectif, leurs méthodes de stockage et leurs applications.
Voici un résumé de leurs différences :
|
Caractéristique |
Modèles standard |
Instantanés |
|
Objectif |
Transformations de l'état actuel |
Historique du cursus |
|
Stockage |
Tableau ou vue avec les données actuelles |
Tableau d'historique en mode ajout uniquement |
|
Idéal pour |
Modèles factuels/dimensionnels |
Dimensions changeant lentement |
Les instantanés suivent généralement un flux de travail structuré qui garantit que toutes les modifications sont enregistrées de manière systématique, en suivant les étapes suivantes :
dbt snapshot » pour comparer les données actuelles aux instantanés existants.Cependant, comment les modifications sont-elles suivies dans dbt ?
Toutes les modifications sont enregistrées dans le tableau Instantané de sortie.
Si une modification est détectée, dbt met à jour le champ « dbt_valid_to » (horodatage de la dernière modification) de la version précédente avec l'horodatage actuel et insère une nouvelle ligne avec le champ « dbt_valid_from » (horodatage de la dernière modification) comme horodatage actuel.
Les instantanés utilisent deux stratégies principales pour détecter les modifications.
updated_at.|
Stratégie |
Méthode de détection |
Idéal pour |
|
Horodatage |
Colonne « timestamp » mise à jour |
Tableaux avec horodatage fiable de la dernière modification |
|
Veuillez vérifier. |
Comparaison directe des colonnes |
Tableaux sans colonnes d'horodatage |
Les modifications apportées aux données, telles que les suppressions, peuvent également être suivies, mais pas par défaut. Cependant, il existe un moyen de modifier cela afin de surveiller ces modifications définitives.
invalidate_hard_deletes=True pour marquer les lignes supprimées avec une valeur d'dbt_valid_to, en conservant leur dernier état.Voici un exemple de stratégie de vérification mise en œuvre, tenant compte des suppressions définitives :
{%
snapshot customers_snapshot %}
{%
set config(
target_schema='snapshots',
unique_key='customer_id',
strategy='check',
check_cols=['tier'],
invalidate_hard_deletes=True
)
%}
SELECT * FROM {{ source('customers') }}
{% endsnapshot %}Maintenant que nous comprenons le fonctionnement des instantanés dbt, examinons comment les mettre en œuvre.
Pour vous exercer à créer des instantanés, nous allons créer un exemple de tableau clients qui imite un système d'adhésion réel. Cela nous fournit des données concrètes pour tester des stratégies courantes de capture instantanée.
import csv
from datetime import datetime
# Define the data
customers_data = [
["customer_id", "name", "tier", "updated_at"], # header row
[1, "Alice Tan", "Silver", "2025-07-01 10:00:00"],
[2, "Bob Lee", "Gold", "2025-07-01 10:00:00"],
[3, "Cheryl Lim", "Silver", "2025-07-01 10:00:00"]
]
# Write data to customers.csv
with open("customers.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerows(customers_data)Avant de pouvoir mettre en œuvre les instantanés, il est essentiel de configurer correctement votre projet dbt. Cela garantit que votre environnement est configuré pour gérer les modèles, les instantanés, les tests et la documentation de manière structurée et évolutive.
pip install dbtVeuillez remplacer dbt-postgres par votre adaptateur d'entrepôt, par exemple dbt-snowflake ou dbt-bigquery, en fonction de votre environnement.
1. Veuillez vous rendre dans le répertoire de vos projets.
C'est ici que vous stockerez vos projets d'analyse ou ELT. Dans ce cas, nous stockerons tous les fichiers associés dans ce dossier de projet dbt.
cd ~/dbt-snapshot-project2. Veuillez initialiser un nouveau projet dbt.
Créez un fichier de configuration nommé dbt_project.yml :
Veuillez coller le texte suivant dans votre fichier de projet :
name: dbt_snapshots_project
version: '1.0'
profile: austinchia
seeds:
dbt_snapshots_project:
+quote_columns: false3. Veuillez vérifier votre connexion.
dbt debugVoici ce que devrait afficher la commande :
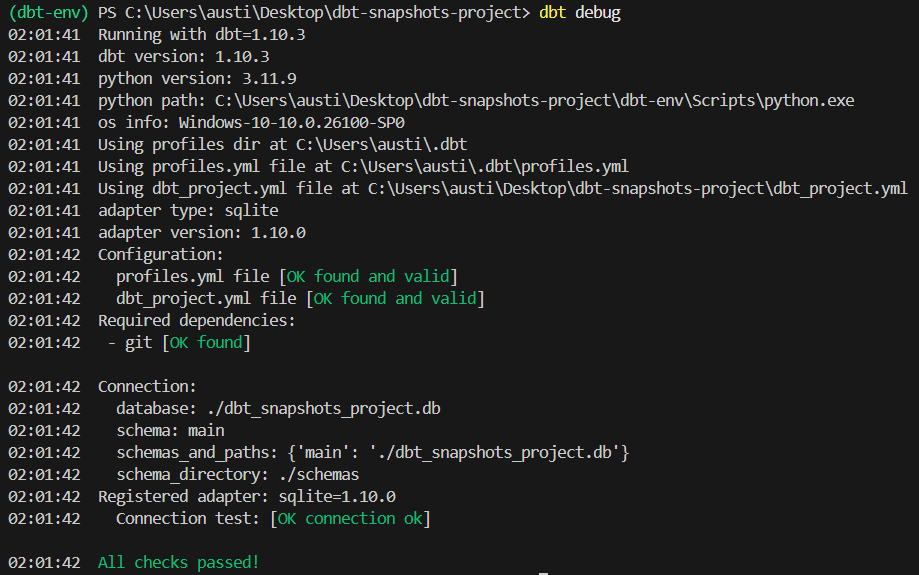
4. Veuillez enregistrer les semences dans une base de données locale.
Veuillez exécuter la commande suivante :
dbt seedVoici ce que devrait afficher la commande :
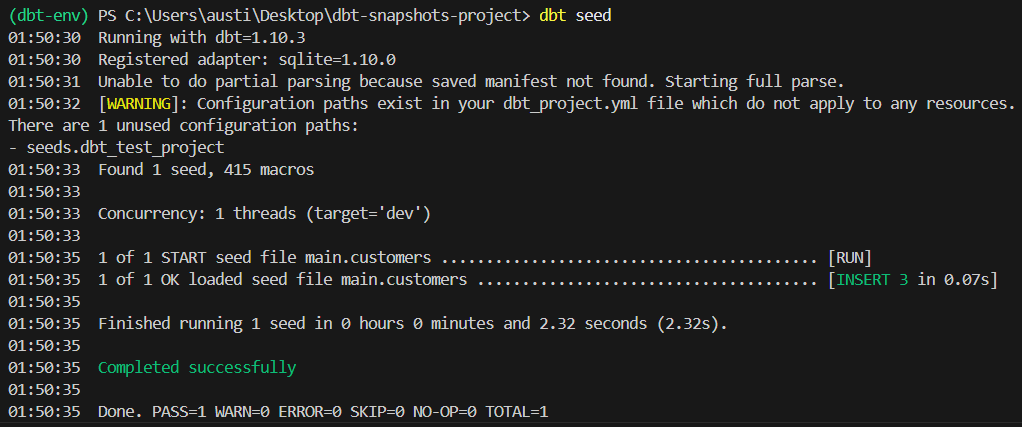
5. Veuillez configurer les paramètres de connexion à votre base de données.
Dans le fichier profiles.yml, généralement situé dans ~/.dbt/profiles.yml.
Voici le contenu de mon fichier de profils :
austinchia:
target: dev
outputs:
dev:
type: sqlite
threads: 1
database: ./dbt_snapshots_project.db
schema: main
schema_directory: ./schemas
schemas_and_paths:
main: ./dbt_snapshots_project.db
extensions:
- "C:/sqlean/crypto.dll"Si vous utilisez une base de données SQLite comme moi, vous devrez installer le extension SQLean également.
6. Intégrez vos données dans les modèles de staging dbt :
Veuillez créer un nouveau dossier nommé « models ». Dans ce dossier, veuillez créer un fichier nommé « stg_customers.sql ».
Veuillez coller le code suivant dans le fichier :
SELECT
*
FROM {{ ref('customers') }}7. Créez des modèles de staging à l'aide de la commande suivante dans dbt.
dbt run --select stg_customersVoici ce que devrait afficher la commande :
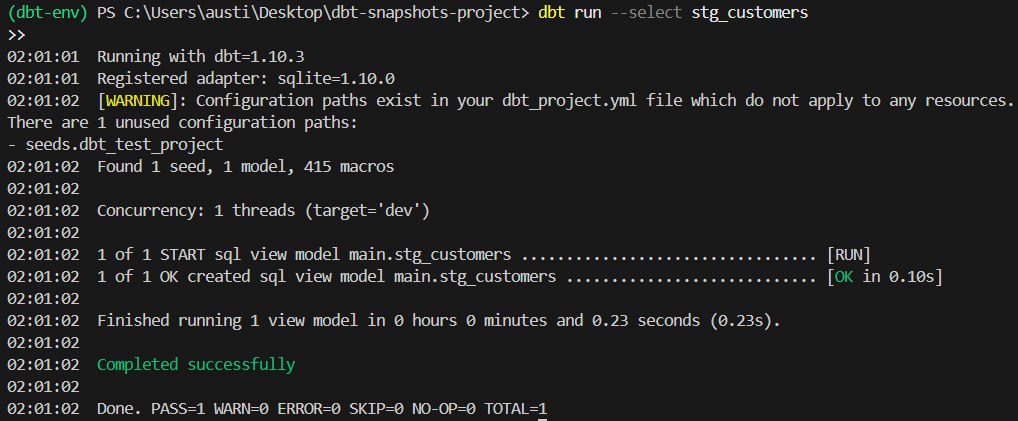
Dans cet exemple, vous pouvez utiliser le code suivant pour effectuer un instantané de stratégie d'horodatage.
{% snapshot customers_snapshot %}
{{
config(
target_schema='snapshots',
unique_key='customer_id',
strategy='timestamp',
updated_at='updated_at'
)
}}
select * from {{ ref('customers') }}
{% endsnapshot %}Exécuter :
dbt snapshotDans cette commande, dbt crée le tableau instantané s'il n'existe pas. Il insère également de nouvelles lignes pour les modifications détectées.
Voici ce que devrait afficher la commande :
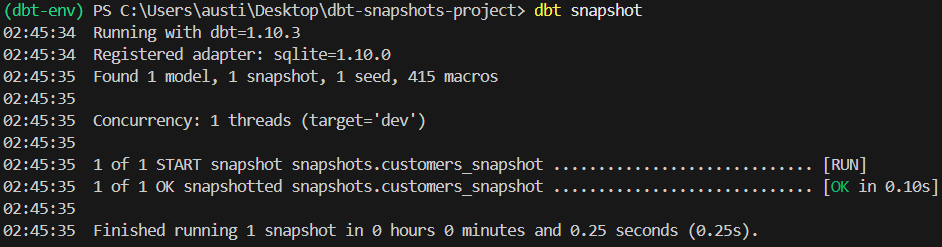
Maintenant que vous avez effectué votre instantané, vous devriez obtenir un nouveau fichier snapshot.db créé dans le répertoire de fichiers de votre projet.
J'ai ouvert ce fichier dans VSCode pour voir à quoi il ressemble :

Comme vous pouvez le constater, il contient des colonnes supplémentaires telles que « dbt_updated_at » (nom du fichier), etc. Ces informations sont essentielles pour déterminer si des modifications ont été apportées aux données et à quel moment elles ont été effectuées.
Pour obtenir des guides pratiques supplémentaires sur dbt, veuillez consulter notre guide Semantic Layer avec dbt..
Les instantanés permettent aux équipes de capturer une piste d'audit complète des modifications apportées à n'importe quel attribut d'un tableau au fil du temps, ce qui les rend très utiles pour la conformité, le débogage et l'analyse.
customers s avec les champs pertinents. Cela inclut l'identifiant client, le nom, l'adresse e-mail et l'horodatage updated_at pour suivre les modifications apportées.CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
updated_at TIMESTAMP
);Veuillez utiliser le code suivant pour insérer des données dans le tableau. Ces données seront utilisées pour les données d'origine avant la modification.
INSERT INTO customers VALUES
(1, 'Alice Tan', 'alice@example.com', '2025-07-01 10:00:00'),
(2, 'Bob Lee', 'bob.lee@example.com', '2025-07-01 10:00:00');{% snapshot customers_email_snapshot %}
{%
set config(
target_schema='snapshots',
unique_key='customer_id',
strategy='check',
check_cols=['email'],
invalidate_hard_deletes=True
)
%}
SELECT * FROM {{ source('customers') }}
{% endsnapshot %}dbt snapshot pour enregistrer l'état initial.dbt snapshotEnsuite, nous mettrons à jour notre tableau initial en modifiant les informations d'un client afin de simuler une modification des données.
UPDATE customers
SET email = 'alice.tan@example.com', updated_at = '2025-07-02 09:00:00'
WHERE customer_id = 1;dbt snapshot pour enregistrer la modification.dbt snapshotPour afficher les différences et les modifications apportées aux données, vous devez interroger le tableau instantané. Le tableau doit indiquer les deux versions de l'adresse électronique avec leurs périodes de validité respectives :
SELECT customer_id, email, dbt_valid_from, dbt_valid_to
FROM snapshots.customers_email_snapshot
ORDER BY customer_id, dbt_valid_from;Ce processus vous garantit de conserver un historique complet des modifications apportées aux mises à jour par e-mail, ce qui est essentiel pour les audits RGPD, le suivi de l'historique des contacts ou l'analyse du service client.
Une gestion efficace de la configuration permet aux équipes de déployer facilement des implémentations instantanées à travers différents projets et environnements.
dbt_project.yml pour définir les configurations par défaut des instantanés, telles que le schéma cible ou les matérialisations, applicables à tous les instantanés.Par défaut, dbt crée les champs « dbt_valid_from » et « dbt_valid_to ». Vous pouvez renommer ces éléments à l'aide des options de configuration « valid_from » et « valid_to » si les normes de votre équipe exigent des conventions de dénomination différentes pour plus de clarté dans les outils de BI ou de gouvernance des données.
Les migrations peuvent entraîner certaines incohérences si elles ne sont pas gérées correctement. Voici quelques points à prendre en compte lors de la migration de vos configurations de clichés instantanés :
Les modifications apportées aux données peuvent être suivies à l'aide des instantanés dbt.
Par exemple :
La mise en œuvre des instantanés dbt en production nécessite une conception réfléchie afin de garantir les performances, la maintenabilité et la valeur commerciale.
Il est recommandé de suivre ces conseils :
En production, vous souhaiterez optimiser vos données afin que les modifications puissent être suivies efficacement sans affecter votre produit.
Voici quelques conseils :
unique_key » et « validity » afin d'accélérer les requêtes.L'utilisation d'un identifiant unique ( unique_key ) entraîne une version incorrecte des lignes. Veuillez toujours tester la logique d'unicité avant le déploiement.
La surcharge des instantanés peut également se produire lorsque stocker des modifications historiques inutiles (par exemple, des colonnes avec des mises à jour fréquentes de l'horodatage) peut augmenter rapidement les coûts de stockage.
L'utilisation des instantanés dans dbt peut présenter certaines difficultés techniques spécifiques :
Problème : Lignes en double dans l'instantané en raison de clés uniques mal définies.
Solution :
Problème : Les requêtes sont lentes lors de l'analyse des données historiques.
Solution :
dbt_valid_from » ou par plage de dates afin de réduire le volume de données analysées.Les problèmes courants incluent :
SELECT de l'instantané.Solutions :
dbt debug pour vérifier la connexion et la configuration.Les instantanés dbt permettent aux équipes d'analyse de créer des ensembles de données historiques robustes avec un minimum de frais d'ingénierie, ce qui facilite l'analyse de la conformité. Si vous souhaitez en savoir plus sur la TCD, notre cours sur l'Introduction à la TCD. Pour plus d'informations et d'autres guides, veuillez consulter notre Introduction au package dbt-utils et tutoriel dbt.
Meilleurs cours DataCamp
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min