
Lernpfad
Python-Entwickler
28 Std.
Mit den üblichen PDF-Extraktionsprogrammen wie pypdf oder PDFMiner kriegst du zwar den reinen Text, aber die Struktur des Dokuments geht dabei verloren. Tabellen werden zu einem Durcheinander von Text, Überschriften vermischen sich mit dem Textkörper und Bilder verschwinden. Bei RAG-Systemen führen diese unordentlichen Daten zu schlechten Suchergebnissen und unzuverlässigen Antworten. Docling ist ein Open-Source-Toolkit von IBM Research, das Computer-Vision-Modelle nutzt, um Dokumentlayouts zu verstehen und dabei Tabellen, Bilder, Überschriften und Strukturen zu erhalten. Es verarbeitet Dokumente bis zu 30 Mal schneller als herkömmliche OCR-basierte Methoden und läuft direkt auf deinem Computer.
In diesem Tutorial bauen wir mit Docling einen Document Intelligence Assistant – eine Streamlit-Webapp, mit der du Dokumente hochladen, ihre Struktur anschauen und Fragen über einen RAG-basierten Chatbot stellen kannst. Du lernst, wie du mit Docling Dokumente in verschiedenen Formaten bearbeiten, Tabellen und Bilder extrahieren und anzeigen, mit ChromaDB einen Vektorspeicher aufbauen und mit LangGraph einen Dialogagenten erstellen kannst. Am Ende hast du eine funktionierende Anwendung, die komplexe Dokumente in strukturierte Daten umwandelt und intelligente Fragen-Antworten ermöglicht.
Vorschau der Anwendung:
Visualisierung der Dokumentstruktur:
Bevor du mit diesem Tutorial anfängst, solltest du Folgendes haben:
Technische Fähigkeiten: Vertrautheit mit Python-Klassen, Dekoratoren, Typ-Hinweisen und Kontextmanagern. Wir werden durchgehend asynchrone Operationen und Factory-Muster verwenden. Man muss wissen, wie große Sprachmodelle mit Eingabeaufforderungen, Tokens und Einbettungen funktionieren. Es ist gut, wenn du dich mit Such- und Generierungssystemen und Vektordatenbanken auskennst, aber das ist nicht unbedingt nötig – wir erklären dir die wichtigsten Sachen, während wir das Ganze aufbauen.
Entwicklungsumgebung: Python 3.10 oder höher mit pip für die Paketverwaltung. Ein Code-Editor wie VS Code ist empfehlenswert. Du brauchst einen OpenAI-API-Schlüssel von platform.openai.com – die Bearbeitung kostet etwa 0,10 bis 0,20 US-Dollar pro Dokument.
Zeitaufwand: Nimm dir 60 bis 90 Minuten Zeit, um das Tutorial durchzuarbeiten, einschließlich Lesen der Erklärungen, Schreiben von Code und Testen der Anwendung. Dieses Tutorial geht davon aus, dass du schon ein bisschen Python kannst.
Die meisten Tools zur Dokumentenbearbeitung behandeln PDFs wie Bilddateien oder Textströme. Die machen entweder OCR auf jeder Seite oder ziehen reinen Text raus, ohne zu kapieren, was sie da lesen. Docling macht es anders. Es ist ein Open-Source-Toolkit von IBM Research, das Computer-Vision-Modelle nutzt, um die Struktur von Dokumenten so zu verstehen, wie es ein Mensch tun würde.
Wenn du ein Dokument in Docling einspeist, analysieren es zwei KI-Modelle:
Diese Modelle wissen, dass ein Dokument nicht nur ein Haufen Text ist. Es hat eine Hierarchie, Beziehungen und Bedeutung.
Dieses Verständnis der Struktur ist wichtig für RAG-Systeme. Wenn du Anwendungen entwickelst, die das Generieren von Texten durch Suchfunktionen unterstützen, hat die Qualität deiner Dokumentenverarbeitung einen direkten Einfluss auf die Genauigkeit der Suche. Wenn deine PDF-Extraktion eine Finanz-Tabelle in wirren Text verwandelt, wird deine Vektorsuche nur Müll finden. Docling behält die Struktur bei, sodass du beim Aufteilen und Einbetten deiner Dokumente mit sauberen, übersichtlichen Daten arbeitest.
Docling unterstützt von Anfang an mehrere Dokumentformate:
Du kannst OCR auch für gescannte Dokumente aktivieren, indem du Programme wie EasyOCR, Tesseract oder RapidOCR benutzt. Das Toolkit kann in verschiedene Formate exportieren, darunter Markdown (super für LLMs), JSON (für strukturierte Datenpipelines) und DocTags (ein Format, das komplexe Elemente wie mathematische Gleichungen und Code-Blöcke erfasst).
Neben der Flexibilität beim Format bietet Docling auch Leistungsvorteile. Die traditionelle OCR-basierte Dokumentenverarbeitung ist langsam, weil sie jede Seite wie ein Bild behandelt, das eine Zeichenerkennung braucht. Docling lässt diesen Schritt bei digitalen Dokumenten einfach weg und macht die Verarbeitung dadurch viel schneller. Es läuft lokal auf handelsüblicher Hardware, sodass du keine API-Kosten zahlen oder sensible Dokumente an Drittanbieter schicken musst. Die Verarbeitungsgeschwindigkeit hängt von der Komplexität des Dokuments, der Seitenanzahl und den Hardware-Spezifikationen ab. Auf moderner Hardware dauert es normalerweise zwischen weniger als einer Sekunde und mehreren Sekunden pro Seite.
IBM hat die Funktionen von Docling weiter verbessert. Sie haben Granite-Docling, ein 258 Millionen Parameter umfassendes Vision-Language-Modell, das sich besonders gut für komplexe Layouts eignet und experimentelle Unterstützung für mehrere Sprachen bietet (mit Englisch als Hauptsprache und Unterstützung für Arabisch, Chinesisch und Japanisch in der Anfangsphase). Das Toolkit unterstützt jetzt auch die Bild-Extraktion mit einstellbarer Auflösung, die wir in unserer Anwendung nutzen werden, um neben dem Textinhalt auch die eigentlichen Bilder aus PDFs anzuzeigen.
Für unseren Anwendungsfall ist Docling sinnvoll, weil wir strukturierte Daten brauchen, nicht nur reinen Text. Wenn du nur einfache Texte extrahieren musst, reichen vielleicht einfachere Tools wie pypdf aus. Aber weil wir eine KI-App entwickeln, die Dokumente für Analysen und Gespräche verarbeitet, ist die strukturbewusste Verarbeitung von Docling die bessere Wahl. Das ist besonders nützlich, wenn du mit technischen Dokumenten, Forschungsarbeiten oder Geschäftsberichten arbeitest, bei denen Tabellen und Layout wichtig sind.
Bevor wir mit der Entwicklung des Dokumentenprozessors anfangen, musst du deine Projektstruktur einrichten und die benötigten Pakete installieren. In diesem Abschnitt geht's um die ersten Schritte: Verzeichnisse anlegen, Abhängigkeiten installieren und API-Schlüssel einrichten.
Mach zuerst ein neues Verzeichnis für dein Projekt:
mkdir docling-demo
cd docling-demoMach in diesem Verzeichnis einen Ordner namens „ src/ ” für deine Python-Module:
mkdir src
touch src/__init__.pyDie Datei „ __init__.py ” sagt Python, dass „ src/ ” ein Paket ist, sodass man Sachen wie „ from src.document_processor import DocumentProcessor ” importieren kann.
Deine Projektstruktur:
docling-demo/
├── src/
│ └── __init__.pyMach eine Datei namens „ requirements.txt “ in deinem Projektverzeichnis:
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2 Die Einschränkung „ numpy<2 ” gibt's, weil die Abhängigkeiten von Docling (TensorFlow und Transformers) NumPy 1.x brauchen.
Installiere die Pakete:
pip install -r requirements.txtDie erste Installation dauert ein paar Minuten, weil Docling vorab trainierte KI-Modelle runterlädt (ca. 500 MB). Diese Modelle kümmern sich um die Layoutanalyse und die Erkennung von Struktur der Tabelle. Sie werden lokal zwischengespeichert, sodass spätere Durchläufe schneller sind.
Mach eine Datei namens „ .env “, um deinen OpenAI-API-Schlüssel zu speichern:
OPENAI_API_KEY=your-openai-api-key-hereHol dir deinen API-Schlüssel von platform.openai.com. Du brauchst es für Einbettungen und den Chat-Agenten.
Mach mal 'ne Vorlage „ .env.example “:
OPENAI_API_KEY=your-openai-api-key-hereFüge einen „ .gitignore “ hinzu, um zu verhindern, dass sensible Daten übertragen werden:
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Mach in deinem Projektstammverzeichnis die Datei „ app.py “ an. Wir werden diese Datei im Laufe des Tutorials nach und nach erstellen. Füge vorerst die grundlegenden Importe und die Konfiguration hinzu:
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Teste deine Einrichtung:
streamlit run app.pyStreamlit öffnet ein Browserfenster unter http://localhost:8501, in dem deine Basisseite angezeigt wird.
Deine endgültige Projektstruktur (bevor wir in den nächsten Abschnitten neue Skripte hinzufügen):
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyJetzt, wo alles vorbereitet ist, können wir den Dokumentenprozessor erstellen, der Docling nutzt, um die Struktur aus den hochgeladenen Dateien zu extrahieren.
> Hinweis: In den folgenden Abschnitten werden die Anwendungsskripte in einzelne Teile zerlegt. Um den Überblick zu behalten und alles gut mitverfolgen zu können, empfehlen wir, das GitHub-Repository für dieses Projekt in einem separaten Tab zu öffnen.
📄 Vollständiges Skript: src/document_processor.py
Der Dokumentenprozessor ist der Ort, an dem Docling seine Arbeit macht. Diese Komponente nimmt hochgeladene Dateien und verwandelt sie in strukturierte Daten, die wir sowohl für RAG als auch für die Visualisierung nutzen können. Wir brauchen zwei Ergebnisse aus diesem Prozess: sauberen Markdown-Text für den Vektorspeicher und das ursprüngliche Docling-Dokumentobjekt, das alle Strukturinfos wie Tabellen und Bilder behält.
Lass uns das machen, indem wir eine neue Datei namens „ document_processor.py “ in deinem Verzeichnis „ src/ “ anlegen. Wir erstellen eine Klasse namens „ DocumentProcessor “, die die Verarbeitungs-Pipeline von Docling konfiguriert und Datei-Uploads abwickelt.
Mit Docling kannst du über Pipeline-Optionen steuern, wie Dokumente verarbeitet werden. Bei PDFs kannst du OCR für gescannte Dokumente einschalten, die Erkennung der Tabelle aktivieren und Bilder extrahieren:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
Wir erstellen ein „ PdfPipelineOptions “-Objekt, um festzulegen, wie Docling PDF-Dateien verarbeitet. Jede Option regelt eine bestimmte Verarbeitungsfunktion: „ do_ocr “ aktiviert die optische Zeichenerkennung für gescannte Dokumente, „ do_table_structure “ aktiviert die Erkennung von Tabellen und -analyse, „ generate_picture_images “ weist Docling an, eingebettete Bilder als PIL-Objekte zu extrahieren, und „ images_scale “ legt den Auflösungsmultiplikator für extrahierte Bilder fest.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)Der „ DocumentConverter ” ist Doclings Hauptverarbeitungsmodul. Wir starten es mit unseren PDF-Pipeline-Optionen, die in einem „ PdfFormatOption “-Objekt zusammengefasst sind, das diese Einstellungen speziell mit PDF-Eingabedateien verknüpft.
Schauen wir uns mal an, was die einzelnen Pipeline-Optionen machen. Das Flag „ do_ocr “ macht die optische Zeichenerkennung möglich. Wenn Docling digitale PDFs mit eingebetteten Textebenen bearbeitet, überspringt es automatisch die OCR, um Zeit zu sparen. Bei gescannten Dokumenten oder Bildern mit Text sagt diese Einstellung Docling, dass es Vision-Modelle ausführen soll, um den Text zu extrahieren.
Die Option „ do_table_structure “ macht die Erkennung der Struktur einer Tabelle möglich. Ohne diese Option werden Tabellen als reiner Text extrahiert, wobei die Formatierung verloren geht. Wenn das aktiviert ist, nutzt Docling sein TableFormer-KI-Modell, um Zeilen, Spalten, Überschriften und Beziehungen zwischen Zellen zu erkennen. Mit dieser strukturierten Darstellung kannst du Tabellen später als Pandas-DataFrames exportieren und dabei das Tabellenformat beibehalten.
Wenn du „ generate_picture_images “ auf „ True “ setzt, kannst du Bilder extrahieren. Standardmäßig speichert Docling nur die Speicherorte der Bilder, ohne die Bilder selbst zu extrahieren. Wenn du das aktivierst, bekommst du PIL-Bildobjekte, die du in deiner Benutzeroberfläche anzeigen oder mit Bildverarbeitungsmodellen bearbeiten kannst. Der Parameter „ images_scale “ regelt die Extraktionsauflösung – ein Wert von 2,0 verdoppelt die Auflösung für eine bessere Qualität bei der Anzeige von Bildern oder der Durchführung zusätzlicher Analysen.
Nachdem die Pipeline fertig ist, können wir die Methode hinzufügen, die die über Streamlit hochgeladenen Dateien verarbeitet. Diese Methode kümmert sich um die Dateiobjekte von Streamlit, speichert sie vorübergehend, führt die Konvertierung von Docling durch und gibt sowohl Markdown für RAG als auch Docling-Dokumente zur Visualisierung zurück:
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
Streamlit stellt hochgeladene Dateien als Dateiobjekte im Arbeitsspeicher zur Verfügung, aber Docling braucht zum Verarbeiten die eigentlichen Dateien auf der Festplatte. Wir machen ein temporäres Verzeichnis und speichern jede hochgeladene Datei dort, wobei wir den ursprünglichen Dateinamen behalten.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()Der Aufruf „ converter.convert() “ startet Doclings komplette Pipeline zur Dokumentanalyse. Es erkennt das Dokumentlayout, macht bei Bedarf OCR, findet Tabellen und Bilder und baut eine strukturierte Darstellung auf. Rechne mit 20 bis 30 Sekunden für die Verarbeitung ohne Bildextraktion oder mit 40 bis 60 Sekunden, wenn Bilder aktiviert sind.
Sobald die Konvertierung fertig ist, machen wir einen Export ins Markdown-Format. Das gibt uns sauberen, LLM-freundlichen Text, bei dem die richtige Formatierung erhalten bleibt – Überschriften bleiben Überschriften, Listen bleiben strukturiert und Tabellen werden in Markdown-Tabellen umgewandelt.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})Wir erstellen von jedem bearbeiteten Dokument zwei Darstellungen. Das LangChain- Document -Objekt hat den Markdown-Text als „ page_content ” mit den dazugehörigen Metadaten – das geht in den Vektorspeicher für RAG. Das ursprüngliche Docling-Dokumentobjekt wird separat mit seinem Dateinamen gespeichert, wobei alle Strukturinfos (Tabellen, Bilder, Hierarchie) für die spätere Visualisierung erhalten bleiben.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
Der Block „ finally “ sorgt dafür, dass temporäre Dateien gelöscht werden, egal ob die Verarbeitung klappt oder nicht. Wir geben ein Tupel zurück, das beide Dokumentdarstellungen enthält: LangChain-Dokumente für das RAG-System und Docling-Dokumente für die Strukturvisualisierung.
Der Dokumentenprozessor ist jetzt einsatzbereit. Als Nächstes machen wir die Streamlit-Oberfläche, mit der Leute Dateien hochladen und den Bearbeitungsstatus checken können.
📄 Vollständiges Skript: src/structure_visualizer.py
Jetzt, wo wir Dokumente mit Docling bearbeiten können, brauchen wir eine Möglichkeit, die extrahierten Inhalte anzuzeigen. Das rohe Docling-Dokumentobjekt hat viele strukturelle Infos (Überschriften, Tabellen, Bilder und Metadaten), ist aber in seiner ursprünglichen Form nicht so benutzerfreundlich. Wir machen eine Visualisierungsschicht, die diese Daten in eine interaktive Oberfläche mit vier Ansichten verwandelt: ein Dashboard mit Zusammenfassungen, eine hierarchische Gliederung, interaktive Tabellen und extrahierte Bilder.
Mach eine neue Datei namens „ structure_visualizer.py ” in deinem Verzeichnis „ src/ ”. Diese Komponente analysiert die Dokumentstruktur von Docling und macht sie für die Anzeige fertig.
Mach mal damit los, eine Klasse zu erstellen, die ein Docling-Dokument einbindet und Methoden zum Extrahieren verschiedener Strukturelemente bereitstellt:
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
Der Initialisierer braucht ein „ DoclingDocument “-Objekt (das gleiche Objekt, das von „ DocumentConverter.convert() “ zurückgegeben wird). Dieses Objekt hat alles, was Docling aus dem Dokument rausgeholt hat. Das Attribut „ texts “ hat alle Textelemente mit ihren Beschriftungen und Positionen, „ tables “ hat Daten einer Tabelle mit Strukturinfos, „ pictures “ speichert Bildmetadaten und die eigentlichen Bilddaten, und „ pages “ gibt Infos auf Seitenebene.
Dokumente haben mehr als nur Absätze. Überschriften machen eine Hierarchie, die den Lesern hilft, sich im Inhalt zurechtzufinden. So extrahierst du diese Hierarchie:
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyWir gehen alle Textelemente im Dokument durch und filtern die, die die Beschriftung „ header “ haben. Jedes Textelement hat ein Attribut namens „ label “, das Docling bei der Layoutanalyse hinzufügt. Häufige Labels sind „ section_header “, „ page_header “, „ title “ und das normale „ text “. Das Attribut „ prov “ (kurz für „Provenance“) hat Infos zur Positionierung, zum Beispiel auf welcher Seite das Element angezeigt wird. Wir holen den Text der Überschrift und die Seitenzahl raus und finden anhand des Labeltyps heraus, auf welcher Ebene sie steht.
Beim Anzeigen der Gliederung bestimmt die Überschriftenebene den Einzug. Eine Hilfsmethode ordnet Beschriftungstypen numerischen Stufen zu:
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Das macht eine Hierarchie, wo Dokumenttitel Stufe 1 sind, Abschnittsüberschriften Stufe 2, Unterabschnitte Stufe 3 und alle anderen Überschriften standardmäßig Stufe 4.
Nachdem wir die Dokumenthierarchie extrahiert haben, kümmern wir uns jetzt um die Tabellen. Im Gegensatz zur einfachen Textextraktion, die Tabellen in wirre Zeichenfolgen verwandelt, behält Docling ihre Struktur bei, was eine seiner wertvollsten Funktionen ist:
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoDie Methode „ table.export_to_dataframe(doc=self.doc) ” wandelt die Repräsentation der Tabelle von Docling in ein pandas DataFrame um. Wir holen Bildunterschriften und Seitenzahlen raus, wenn sie verfügbar sind.
Docling kann nicht nur Tabellen, sondern auch echte Bilddaten aus Dokumenten herausholen. Das ist eine neue Funktion, die mehr kann als nur die Position von Bildern zu verfolgen – sie holt sich die eigentlichen Bild-Bytes, damit du sie anzeigen kannst. (Wir haben das in den Pipeline-Optionen des Dokumentenprozessors aktiviert.)
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoJedes Bild hat Infos zur Herkunft, wie die Seitenzahl und die Koordinaten des Begrenzungsrahmens. Der Begrenzungsrahmen zeigt, wo das Bild auf der Seite hingehört, indem er die Koordinaten links, oben, rechts und unten angibt.
Wenn die Bildextraktion aktiviert ist, hat das Bildobjekt ein Attribut namens „ image “, das die eigentlichen Bilddaten enthält. Wir greifen über picture.image.pil_image auf das PIL-Bild zu, was ein PIL-Bildobjekt zurückgibt, das Streamlit direkt mit st.image() anzeigen kann. Der try-except-Block kümmert sich um Fälle, in denen die Bildextraktion nicht klappt oder nicht aktiviert wurde, und zeigt dann einfach die Metadaten an.
Der Visualisierer braucht noch eine weitere Funktion: eine allgemeine Zusammenfassung, die den Benutzern einen Überblick über die Dokumentstruktur gibt:
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}Wir zählen die Seiten, Textelemente, Tabellen und Bilder im Dokument. Das Wörterbuch „ text_types “ schaut sich die Textelemente anhand ihrer Bezeichnungen an und zeigt, wie viele Titel, Überschriften, Absätze und andere Elemente Docling gefunden hat. So kriegen die Nutzer schnell einen Eindruck von der Struktur und Komplexität des Dokuments.
Nachdem der Visualizer fertig ist, bauen wir ihn mit vier Registerkarten in Streamlit ein: Zusammenfassung, Hierarchie, Tabellen und Bilder.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])Wir machen ein Dropdown-Menü, damit die Leute auswählen können, welches Dokument sie analysieren wollen (praktisch, wenn mehrere Dateien hochgeladen werden). Nachdem wir das ausgewählte Docling-Dokument aus dem Sitzungsstatus geholt haben, starten wir den Visualizer und machen vier Registerkarten für verschiedene Ansichten.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")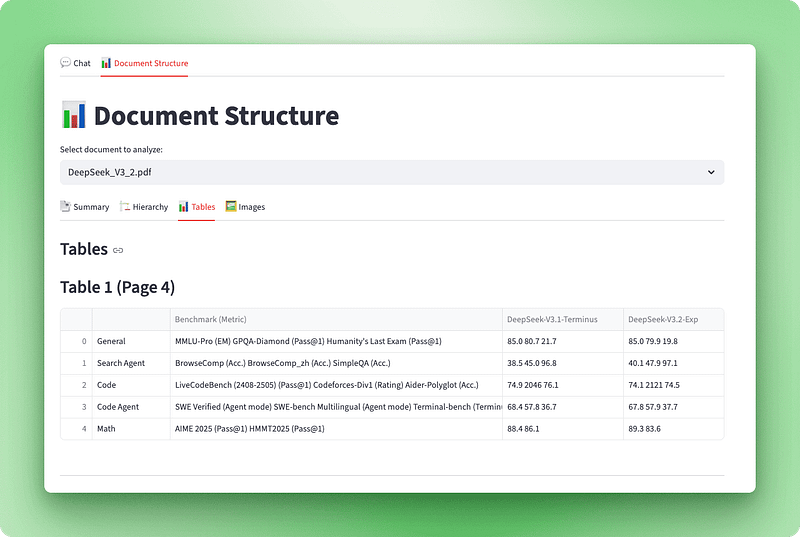
Der Strukturvisualisierer ist fertig. Du kannst ein Dokument hochladen und siehst sofort, wie es aufgebaut ist – wie viele Seiten, Tabellen und Bilder es hat, wie die Hierarchie mit Überschriften und Abschnitten aussieht, welche interaktiven Tabellen du erkunden kannst und welche Bilder aus dem Dokument extrahiert wurden. Diese Transparenz hilft den Nutzern zu verstehen, was Docling extrahiert hat, und schafft Vertrauen in das System.
Wenn die Dokumentenverarbeitung und -visualisierung läuft, können wir das RAG-System aufbauen, das die Beantwortung von Fragen zu diesen verarbeiteten Dokumenten ermöglicht.
📄 Vollständige Skripte: src/vectorstore.py | src/tools.py
Nachdem die Dokumentenverarbeitung und -visualisierung fertig sind, können wir die Q&A-Funktionen einrichten. Mit RAG (Retrieval Augmented Generation) kannst du Fragen zu deinen Dokumenten stellen. Das System wandelt Dokumente in Einbettungen um, speichert sie in einer Vektordatenbank und ruft relevante Teile ab, um Fragen zu beantworten.
Dieser Abschnitt geht auf zwei Teile ein: einen Vektorspeicher-Manager, der Dokumente in Teile zerlegt und einbettet, und ein Suchwerkzeug, das relevante Infos findet.
Der Vektorspeicher ist der Ort, wo die Dokumenteneinbettungen gespeichert werden. Wenn Leute eine Frage stellen, suchen wir in diesem Speicher nach passenden Teilen und geben sie als Kontext an das LLM weiter.
Mach mal die Datei „ vectorstore.py ” in deinem Verzeichnis „ src/ ”:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaDiese Importe bringen LangChain-Komponenten für die Dokumentenverarbeitung, Textzerlegung, Einbettungsgenerierung und ChromaDB-Vektorspeicherung mit. So arbeiten sie zusammen:
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)Wir starten zwei wichtige Teile. Das Modell „ text-embedding-3-small “ von OpenAI macht aus Text Vektoren. Es ist kleiner und schneller als text-embedding-3-large, was wichtig ist, wenn man Hunderte von Chunks einbettet. Der „ RecursiveCharacterTextSplitter ” teilt Dokumente in 1000-Zeichen-Blöcke mit einer Überlappung von 100 Zeichen auf, damit wichtige Infos an den Blockgrenzen nicht mitten im Satz abgeschnitten werden.
1000 Zeichen schaffen einen guten Mix aus Genauigkeit und Kontext – kleinere Teile sind super zum Suchen, aber der Kontext geht dabei verloren, größere Teile behalten den Kontext, aber die Relevanz wird schwächer.
Füge die Chunking-Methode hinzu:
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksDer Splitter kümmert sich automatisch um die Metadaten und behält die Infos aus den Originaldokumenten bei. Jeder Chunk weiß, aus welcher Datei er stammt, was wichtig wird, wenn der Agent in seinen Antworten Quellen angibt.
Jetzt füge die Methode hinzu, die den Vektorspeicher erstellt:
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreChromaDB übernimmt die schwere Arbeit. Es bettet jeden Block mit unserem Einbettungsmodell ein und speichert die Vektoren im Speicher. Wenn du eine Ähnlichkeitssuche machst, berechnet ChromaDB die Kosinusähnlichkeit zwischen dem Suchvektor und allen Dokumentvektoren und gibt die besten Treffer zurück.
Nachdem der Vektorspeicher für die Verarbeitung von Einbettungen bereit ist, müssen wir dem Agenten eine Möglichkeit geben, ihn abzufragen. Tools sind Funktionen, die das LLM aufrufen kann, wenn es Infos braucht, die es nicht hat.
Mach mal die Datei „ tools.py ” in deinem Verzeichnis „ src/ ”:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Diese Factory-Funktion nutzt ein Closure-Muster: Sie nimmt einen Vektor-Speicher entgegen und gibt ein Tool zurück, mit dem man darin suchen kann. Das Tool behält den Zugriff auf den Vektorspeicher, ohne globale Variablen zu brauchen.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""Der Dekorator „ @tool ” macht diese Funktion zu einem LangChain-Tool, das der Agent aufrufen kann. Der Typ-Hinweis „ Annotated “ erklärt den Parameter und hilft dem LLM zu verstehen, was beim Aufruf des Tools übergeben werden muss.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."Wir holen 8 ähnliche Blöcke (k=8) aus dem Vektorspeicher. So hat der LLM genug Kontext, ohne mit unnötigen Infos überladen zu werden. Die richtige Anzahl hängt von deinem Dokumenttyp ab – technische Dokumente mit vielen Infos funktionieren vielleicht besser mit weniger Blöcken (k=4-6), während erzählende Dokumente von mehr Blöcken profitieren könnten (k=10-12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)Wir formatieren jeden Block mit seinem Quelldateinamen und verbinden sie dann mit Trennzeichen. Der LLM nimmt diesen strukturierten Kontext auf und nutzt ihn, um Antworten zu generieren, während er Quellen angibt.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsDie Fehlerbehandlung sorgt dafür, dass der Agent eine klare Meldung bekommt, wenn die Suche nicht klappt, statt dass das Programm abstürzt. Die Funktion gibt das konfigurierte Tool zurück, das der Agent jetzt benutzen kann.
Der Vektorspeicher und die Suchfunktion sind jetzt einsatzbereit. Als Nächstes bauen wir den LangGraph-Agenten, der das Abrufen und Generieren von Infos koordiniert, um Fragen der Nutzer zu beantworten.
📄 Vollständiges Skript: src/agent.py
Das Suchwerkzeug kann den Vektorspeicher abfragen, braucht aber einen intelligenten Koordinator. Der LangGraph-Agent entscheidet, wann gesucht wird, schaut sich die Ergebnisse an und macht Antworten in natürlicher Sprache. Wir werden auch Streaming einführen, um den Fortschritt in Echtzeit zu zeigen.
Der Agent bekommt Fragen, entscheidet, wann er Dokumente durchsucht, und macht Antworten basierend auf dem gefundenen Kontext.
Mach mal die Datei „ agent.py ” in deinem Verzeichnis „ src/ ”:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverWir holen Teile für die Werkzeugverwaltung, die Chat-Modelle von OpenAI, die ReAct-Agentenimplementierung von LangGraph und den Gesprächsspeicher rein.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()Wir nutzen gpt-4o-mini statt gpt-5, weil es schneller und günstiger ist und trotzdem gut mit Dokumenten-Fragen und Antworten klappt. Die Temperatur wird auf 0 eingestellt, um konsistente, sachliche Antworten zu bekommen. Der „ MemorySaver “ gibt dem Agenten ein Gesprächsspeicher, sodass er sich an frühere Unterhaltungen innerhalb einer Sitzung erinnern kann.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentLangGraphs „ create_react_agent ” nutzt das ReAct-Muster (Reasoning + Acting). Der Agent überlegt, was er tun muss, macht was mit Tools, schaut sich die Ergebnisse an und wiederholt das Ganze, bis er eine Antwort hat. Dieses Muster passt super zu RAG, weil der Agent entscheiden kann, wann er sucht und wie er den gefundenen Kontext nutzt.
Der Agent kann jetzt nach Antworten suchen und sie generieren, aber die Nutzer sollten nicht 10 Sekunden lang auf einen leeren Bildschirm starren müssen, während er arbeitet. Beim Streaming sieht man den Fortschritt in Echtzeit – erst kommt 'ein Denksymbol', dann 'Suchen' und schließlich erscheint die Antwort Zeichen für Zeichen.
Aktualisiere deine Funktion „ render_chat() ” in „ app.py ”, um die zuvor mit „TODO” gekennzeichnete Antwortverarbeitung abzuschließen:
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Wir fügen die Nachricht des Benutzers zum Gesprächsverlauf hinzu und zeigen sie im Chat-Interface an.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}Wir machen Platzhalter für die Statusanzeige und die Antwortmeldung. Die Konfiguration enthält eine Thread-ID, die LangGraph benutzt, um den Gesprächsverlauf über mehrere Runden hinweg zu speichern.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseDiese Generatorfunktion verarbeitet die Stream-Ausgabe von LangGraph. Wir verfolgen den Status mit Flags, um die passenden Statusmeldungen anzuzeigen, während der Agent seinen Workflow durchläuft.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")Der Parameter „ stream_mode="messages" “ gibt uns echte LLM-Token, wie sie generiert werden, nicht nur die endgültigen Ergebnisse. LangGraph sendet während der ganzen Ausführung des Agenten Ereignisse – wenn er anfängt zu denken, wenn er Tools aufruft und wenn er Text erzeugt.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentSobald der Agentenknoten mit der Erstellung der endgültigen Antwort anfängt, aktualisieren wir den Status und fangen an, Inhaltstoken zu erzeugen. Jedes Zeichen wird sofort angezeigt, was für einen flüssigen Tippeffekt sorgt.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Sobald das Streaming fertig ist, löschen wir die Statusanzeige. Der Streamlit-Dienst „ st.write_stream() “ kümmert sich automatisch um die Anzeige der einzelnen Token, sammelt sie und aktualisiert die Benutzeroberfläche reibungslos. Das Ergebnis ist ein Chat-Erlebnis, das sich reaktionsschnell anfühlt und den Nutzern das Gefühl gibt, dass das System gut läuft.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")Wir speichern die komplette Antwort im Nachrichtenverlauf und kümmern uns um alle Fehler, die beim Streaming auftreten.
Das RAG-System ist fertig. Benutzer können jetzt Dokumente hochladen, sie mit Docling bearbeiten, ihre Struktur erkunden und natürliche Gespräche über den Inhalt führen. Der Agent sucht clever, gibt Quellen an und liefert Antworten, damit alles reibungslos läuft.
Dein Dokumenten-Assistent ist fertig. Bevor du die Anwendung bereitstellst oder freigibst, solltest du sie testen, um sicherzustellen, dass alles richtig funktioniert.
Starte die Anwendung aus deinem Projektstammverzeichnis:
streamlit run app.pyStreamlit öffnet ein Browserfenster unter http://localhost:8501. Du solltest die Seitenleiste mit den Upload-Steuerelementen und zwei Registerkarten im Hauptbereich sehen.
Lade ein Beispiel-PDF-Dokument mit Tabellen und Bildern hoch, um die ganzen Bearbeitungsfunktionen zu testen:
Beobachte die Bearbeitungsanzeigen:
Wenn du fertig bist, siehst du im Statusbereich „✅ Bereit zum Chatten!“.
Wechseln Sie zur Registerkarte „Dokumentstruktur“, um zu überprüfen, ob Docling alles richtig extrahiert hat:
Wenn Tabellen leer angezeigt werden oder Bilder nicht erscheinen, schau mal nach, ob du „ do_table_structure=True “ und „ generate_picture_images=True “ in den Pipeline-Optionen aktiviert hast.
Geh zurück zur Registerkarte „Chat“ und probier den Agenten mit diesen Beispielfragen aus:
Gute Einstiegsfragen:
Fragen zum Dokument (pass sie an dein Dokument an):
Weiterführende Fragen um das Gesprächsgedächtnis zu checken:
Such nach direkten Antworten aus deinem Dokument mit Quellenangaben, flüssigen Streaming-Tokens und Statusindikatoren („Denke nach…“, „Durchsuche Dokumente…“, „Erstelle Antwort…“). Pass auf allgemeine Antworten auf, die nicht aus deinem Dokument stammen, fehlende Quellenangaben, langsame Antworten ohne Statusangaben oder Fehler wegen fehlender API-Schlüssel.
Fehler „Kein Modul namens ‚docling‘“
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
Fehler „OpenAI-API-Schlüssel nicht gefunden“
Überprüfe, ob die Datei „ .env “ da ist mit OPENAI_API_KEY=your-key-here
Starte Streamlit neu
Die Verarbeitung dauert länger als 60 Sekunden.
Der Agent gibt allgemeine Antworten.
Tabellen werden als leere DataFrames angezeigt
Bestätige do_table_structure=True in PdfPipelineOptions
Probier mal eine andere PDF-Datei mit nativen Tabellen aus.
Die Anwendung ist jetzt validiert und einsatzbereit. Du kannst es mit deinen eigenen Dokumenten ausprobieren oder für andere bereitstellen, damit sie es nutzen können.
Du hast jetzt einen funktionierenden Document Intelligence Assistant, der PDFs, Word-Dokumente, PowerPoint-Präsentationen und HTML-Dateien verarbeitet und dabei ihre Struktur beibehält. Docling holt Texte, Tabellen, Bilder und die Dokumentstruktur raus, die du über interaktive Registerkarten anschauen kannst. Das RAG-System, zusammen mit ChromaDB und LangGraph, macht es möglich, Fragen und Antworten zu haben, wo die Quellenangaben in Echtzeit eingeblendet werden. Das zeigt, wie die strukturbewusste Dokumentverarbeitung die Suchqualität im Vergleich zur einfachen Textextraktion verbessert. Der komplette Quellcode ist im GitHub-Repository.
Diese Grundlage bietet viele Möglichkeiten für Erweiterungen:
Für eine genauere Untersuchung von RAG-Systemen und LLM-Anwendungen bietet unser KI-Engineering der Lernpfad deckt die Konzepte und Muster ab, die du hier benutzt hast.
Lerne mit DataCamp
Lernpfad
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes