
Cursus
Développeur Python
28 h
Les outils traditionnels d'extraction de PDF tels que pypdf ou PDFMiner fournissent du texte brut, mais perdent la structure du document. Les tableaux se transforment en texte confus, les en-têtes se mélangent au contenu du corps et les images disparaissent. Pour les systèmes RAG, ces données désordonnées se traduisent par une recherche peu efficace et des réponses peu fiables. Docling est une boîte à outils open source développée par IBM Research qui utilise des modèles de vision par ordinateur pour analyser la mise en page des documents, en conservant les tableaux, les images, les titres et la structure. Il traite les documents jusqu'à 30 fois plus rapidement que les méthodes traditionnelles basées sur l'OCR et fonctionne localement sur votre ordinateur.
Dans ce tutoriel, nous utiliserons Docling pour créer un assistant d'intelligence documentaire, une application web Streamlit qui vous permet de télécharger des documents, de visualiser leur structure et de poser des questions à l'aide d'un chatbot alimenté par RAG. Vous apprendrez à traiter des documents multiformats avec Docling, à extraire et afficher des tableaux et des images, à créer un magasin vectoriel avec ChromaDB et à créer un agent conversationnel avec LangGraph. À la fin, vous disposerez d'une application fonctionnelle qui transforme des documents complexes en données structurées et permet de répondre intelligemment aux questions.
Aperçu de l'application :
Visualisation de la structure du document :
Avant de commencer ce tutoriel, il est recommandé de disposer des éléments suivants :
Compétences techniques: Maîtrise des classes Python, des décorateurs, des indications de type et des gestionnaires de contexte. Nous utiliserons des opérations asynchrones et des modèles d'usine tout au long du processus. Il est nécessaire de comprendre comment les grands modèles linguistiques fonctionnent avec les invites, les jetons et les intégrations. Une connaissance préalable des systèmes de génération augmentée par la recherche et des bases de données vectorielles est utile mais n'est pas obligatoire — nous expliquerons les concepts fondamentaux au fur et à mesure de notre progression.
Configuration de développement: Python 3.10 ou version ultérieure avec pip pour la gestion des paquets. Il est recommandé d'utiliser un éditeur de code tel que VS Code. Vous aurez besoin d'une clé API OpenAI disponible sur platform.openai.com — le traitement coûte environ 0,10 à 0,20 $ par document.
s relatives au temps à consacrer: Veuillez prévoir entre 60 et 90 minutes pour suivre le tutoriel, y compris la lecture des explications, la rédaction du code et le test de l'application. Ce tutoriel suppose que vous possédez des compétences intermédiaires en Python.
La plupart des outils de traitement de documents traitent les fichiers PDF comme des fichiers image ou des flux de texte. Ils exécutent soit un OCR sur chaque page, soit extraient du texte brut sans comprendre ce qu'ils lisent. Docling adopte une approche différente. Il s'agit d'une boîte à outils open source d'IBM Research qui utilise des modèles de vision par ordinateur pour comprendre la structure des documents comme le ferait un être humain.
Lorsque vous soumettez un document à Docling, deux modèles d'IA l'analysent:
Ces modèles comprennent qu'un document n'est pas simplement un ensemble de texte. Il comporte une hiérarchie, des relations et une signification.
Cette compréhension structurelle est importante pour les systèmes RAG. Lorsque vous développez des applications de génération augmentée par la recherche, la qualité du traitement de vos documents a une incidence directe sur la précision de la recherche. Si l'extraction de votre fichier PDF transforme un tableau financier en texte confus, votre recherche vectorielle renverra des résultats erronés. Docling préserve la structure, de sorte que lorsque vous découpez et intégrez vos documents, vous travaillez avec des données claires et organisées.
Docling prend en charge plusieurs formats de documents dès son installation :
Vous pouvez également activer la reconnaissance optique de caractères (OCR) pour les documents numérisés à l'aide de moteurs tels que EasyOCR, Tesseract ou RapidOCR. La boîte à outils permet l'exportation vers plusieurs formats, notamment Markdown (idéal pour les modèles d'apprentissage automatique), JSON (pour les pipelines de données structurées) et DocTags (un format qui capture des éléments complexes tels que les équations mathématiques et les blocs de code).
Au-delà de la flexibilité des formats, Docling offre des avantages en termes de performances. Le traitement traditionnel des documents basé sur la reconnaissance optique de caractères (OCR) est lent, car il traite chaque page comme une image nécessitant une reconnaissance de caractères. Docling omet cette étape pour les documents numériques, ce qui permet un traitement beaucoup plus rapide. Il fonctionne localement sur du matériel standard, vous n'avez donc pas à payer de frais d'API ni à envoyer de documents sensibles à des services tiers. La vitesse de traitement varie en fonction de la complexité du document, du nombre de pages et des spécifications matérielles. Sur un matériel moderne, la performance typique varie de moins d'une seconde à plusieurs secondes par page.
IBM a continué d'améliorer les capacités de Docling. Ils ont publié Granite-Docling, un modèle de langage visuel de 258 millions de paramètres qui excelle dans les mises en page complexes et offre une prise en charge multilingue expérimentale (avec l'anglais comme langue principale et une prise en charge préliminaire de l'arabe, du chinois et du japonais). La boîte à outils prend désormais en charge l'extraction d'images avec une résolution configurable, que nous utiliserons dans notre application pour afficher les images réelles des fichiers PDF à côté de leur contenu textuel.
Dans notre cas, Docling est pertinent car nous avons besoin de données structurées, et non pas simplement de texte brut. Si vous avez uniquement besoin d'une extraction de texte basique, des outils plus simples tels que pypdf pourraient suffire. Cependant, étant donné que nous développons une application d'IA qui traite des documents à des fins d'analyse et de conversation, le traitement sensible à la structure de Docling constitue le choix le plus approprié. Il est particulièrement utile lorsque l'on travaille avec des documents techniques, des articles de recherche ou des rapports commerciaux où les tableaux et la mise en page sont importants.
Avant de commencer à développer le processeur de documents, il est nécessaire de configurer la structure de votre projet et d'installer les paquets requis. Cette section traite de la configuration initiale : création de répertoires, installation des dépendances et configuration de vos clés API.
Commencez par créer un nouveau répertoire pour votre projet :
mkdir docling-demo
cd docling-demoDans ce répertoire, veuillez créer un dossier src/ pour vos modules Python :
mkdir src
touch src/__init__.py Le fichier __init__.py indique à Python que src/ est un paquet, permettant des importations telles que from src.document_processor import DocumentProcessor.
Structure de votre projet :
docling-demo/
├── src/
│ └── __init__.pyVeuillez créer un fichier requirements.txt à la racine de votre projet :
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2 La contrainte numpy<2 existe car les dépendances de Docling (TensorFlow et Transformers) nécessitent NumPy 1.x.
Veuillez installer les paquets :
pip install -r requirements.txtLa première installation prend quelques minutes, car Docling télécharge des modèles d'IA pré-entraînés (environ 500 Mo). Ces modèles gèrent l'analyse de la mise en page et la reconnaissance de la structure des tableaux. Ils sont mis en cache localement, ce qui accélère les exécutions suivantes.
Veuillez créer un fichier .env pour stocker votre clé API OpenAI :
OPENAI_API_KEY=your-openai-api-key-hereVeuillez obtenir votre clé API sur platform.openai.com. Vous en aurez besoin pour les intégrations et l'agent de chat.
Veuillez créer un modèle d' .env.example.
OPENAI_API_KEY=your-openai-api-key-hereVeuillez ajouter un « .gitignore » pour éviter de transmettre des données sensibles :
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Veuillez créer le fichier app.py à la racine de votre projet. Nous élaborerons ce fichier progressivement tout au long du tutoriel. Pour l'instant, veuillez ajouter les importations et la configuration de base :
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Veuillez vérifier votre configuration :
streamlit run app.pyStreamlit ouvre une fenêtre de navigateur à l'adresse http://localhost:8501 affichant votre page de base.
Structure finale de votre projet (avant l'ajout de nouveaux scripts dans les sections suivantes) :
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyUne fois l'environnement prêt, nous pouvons créer le processeur de documents qui utilise Docling pour extraire la structure des fichiers téléchargés.
Remarque : Les sections ci-dessous détaillent les scripts d'application par segments. Afin d'avoir une vue d'ensemble et de suivre facilement, nous vous recommandons d'ouvrir le dépôt GitHub de ce projet dans un onglet séparé.
📄 Script complet : src/document_processor.py
Le processeur de documents est l'endroit où Docling effectue son travail. Ce composant prend les fichiers téléchargés et les transforme en données structurées que nous pouvons utiliser à la fois pour le RAG et la visualisation. Ce processus doit générer deux résultats : un texte Markdown propre pour le stockage vectoriel et l'objet document Docling d'origine qui conserve toutes les informations structurelles telles que les tableaux et les images.
Veuillez créer un nouveau fichier nommé document_processor.py dans votre répertoire src/. Nous allons créer une classe DocumentProcessor qui configure le pipeline de traitement de Docling et gère les téléchargements de fichiers.
Docling vous permet de contrôler la manière dont il traite les documents grâce à des options de pipeline. Pour les fichiers PDF, vous pouvez activer la reconnaissance optique de caractères (OCR) pour les documents numérisés, activer la reconnaissance de la structure des tableaux et extraire des images :
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
Nous créons un objet PdfPipelineOptions afin de configurer la manière dont Docling traite les fichiers PDF. Chaque option contrôle une fonctionnalité de traitement spécifique : do_ocr active la reconnaissance optique de caractères pour les documents numérisés, do_table_structure active la détection et l'analyse des tableaux, generate_picture_images indique à Docling d'extraire les images intégrées en tant qu'objets PIL, et images_scale définit le multiplicateur de résolution pour les images extraites.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)Le moteur de traitement principal de Docling est l'DocumentConverter. Nous l'initialisons avec nos options de pipeline PDF encapsulées dans un objet PdfFormatOption, qui associe spécifiquement ces paramètres aux fichiers PDF d'entrée.
Examinons les fonctionnalités de chaque option de pipeline. Le drapeau do_ocr active la reconnaissance optique de caractères. Lors du traitement de fichiers PDF numériques contenant des couches de texte intégrées, Docling ignore automatiquement la reconnaissance optique de caractères (OCR) afin de gagner du temps. Pour les documents numérisés ou les images contenant du texte, ce paramètre indique à Docling d'utiliser des modèles de vision pour extraire le texte.
L'option do_table_structure permet la reconnaissance de la structure des tableaux. Sans cela, les tableaux sont extraits sous forme de texte brut et la mise en forme est perdue. Lorsque cette fonctionnalité est activée, Docling utilise son modèle d'intelligence artificielle TableFormer pour identifier les lignes, les colonnes, les en-têtes et les relations entre les cellules. Cette représentation structurée vous permet d'exporter ultérieurement des tableaux sous forme de DataFrame pandas, tout en conservant le format tabulaire.
Définir generate_picture_images sur True permet l'extraction d'images. Par défaut, Docling enregistre uniquement l'emplacement des images sans extraire les images elles-mêmes. En activant cette option, vous obtenez des objets image PIL que vous pouvez afficher dans votre interface utilisateur ou traiter avec des modèles de vision. Le paramètre « images_scale » (Résolution d'extraction) contrôle la résolution d'extraction. Une valeur de 2,0 double la résolution pour une meilleure qualité lors de l'affichage d'images ou de l'exécution d'analyses supplémentaires.
Une fois le pipeline configuré, nous pouvons ajouter la méthode qui traite les fichiers téléchargés via Streamlit. Cette méthode gère les objets fichiers de Streamlit, les enregistre temporairement, exécute la conversion Docling et renvoie à la fois le markdown pour RAG et les documents Docling pour la visualisation :
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
Streamlit fournit les fichiers téléchargés sous forme d'objets de fichiers en mémoire, mais Docling a besoin de fichiers réels sur le disque pour les traiter. Nous créons un répertoire temporaire et y enregistrons chaque fichier téléchargé, en conservant le nom de fichier d'origine.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()L'appel à l'converter.convert(). exécute l'ensemble du pipeline d'analyse de documents de Docling. Il identifie la mise en page du document, applique la reconnaissance optique de caractères (OCR) si nécessaire, détecte les tableaux et les images, et crée une représentation structurée. Veuillez prévoir 20 à 30 secondes pour le traitement sans extraction d'images, ou 40 à 60 secondes avec les images activées.
Une fois la conversion terminée, nous exportons au format Markdown, qui produit un texte propre et compatible avec les modèles LLM, tout en conservant la mise en forme appropriée : les en-têtes restent des en-têtes, les listes conservent leur structure et les tableaux sont convertis en tableaux Markdown.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})Nous créons deux représentations de chaque document traité. L'objet LangChain Document contient le texte Markdown sous forme d'page_content s avec les métadonnées associées. Ces informations sont transmises au magasin de vecteurs pour RAG. L'objet document Docling original est stocké séparément avec son nom de fichier, en conservant toutes les informations structurelles (tableaux, images, hiérarchie) pour une visualisation ultérieure.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
Le bloc ` finally ` garantit que les fichiers temporaires sont supprimés, que le traitement réussisse ou échoue. Nous renvoyons un tuple contenant les deux représentations du document : Documents LangChain pour le système RAG et documents Docling pour la visualisation de la structure.
Le processeur de documents est désormais opérationnel. Ensuite, nous allons créer l'interface Streamlit qui permet aux utilisateurs de télécharger des fichiers et de visualiser l'état d'avancement du traitement.
📄 Script complet: src/structure_visualizer.py
Maintenant que nous sommes en mesure de traiter des documents avec Docling, nous avons besoin d'un moyen de visualiser ce qui a été extrait. L'objet document Docling brut contient de nombreuses informations structurelles (titres, tableaux, images et métadonnées), mais il n'est pas convivial dans son format d'origine. Nous allons créer une couche de visualisation qui transforme ces données en une interface interactive comprenant quatre vues : un tableau de bord récapitulatif, une structure hiérarchique, des tableaux interactifs et des images extraites.
Veuillez créer un nouveau fichier nommé structure_visualizer.py dans votre répertoire src/. Ce composant analysera la structure du document Docling et l'organisera pour l'affichage.
Commencez par créer une classe qui encapsule un document Docling et fournit des méthodes permettant d'extraire différents éléments structurels :
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
L'initialiseur utilise un objet DoclingDocument (le même objet renvoyé par DocumentConverter.convert()). Cet objet contient tous les éléments extraits du document par Docling. L'attribut texts contient tous les éléments textuels avec leurs étiquettes et leurs positions, tables contient les données du tableau avec les informations sur la structure, pictures stocke les métadonnées et les données réelles de l'image, et pages fournit des informations au niveau de la page.
Les documents ont une structure qui va au-delà des simples paragraphes. Les titres créent une hiérarchie qui aide les lecteurs à naviguer dans le contenu. Voici comment extraire cette hiérarchie :
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyNous parcourons tous les éléments de texte du document, en filtrant ceux dont les étiquettes contiennent « header ». Chaque élément de texte possède un attribut d'label que Docling attribue lors de l'analyse de la mise en page. Les étiquettes courantes comprennent section_header, page_header, title et text. L'attribut prov (abréviation de provenance) contient des informations de positionnement, notamment la page sur laquelle l'élément apparaît. Nous extrayons le texte de l'en-tête, son numéro de page et déduisons son niveau hiérarchique à partir du type d'étiquette.
Lors de l'affichage du plan, le niveau de titre détermine l'indentation. Une méthode d'aide associe les types d'étiquettes à des niveaux numériques :
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Cela crée une hiérarchie dans laquelle les titres des documents sont de niveau 1, les en-têtes de section sont de niveau 2, les sous-sections sont de niveau 3 et tous les autres en-têtes sont par défaut de niveau 4.
Une fois la hiérarchie des documents extraite, nous allons traiter les tableaux. Contrairement à l'extraction de texte simple qui transforme les tableaux en chaînes de caractères désordonnées, Docling préserve leur structure, ce qui constitue l'une de ses fonctionnalités les plus précieuses :
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoLa méthode ` table.export_to_dataframe(doc=self.doc) ` convertit la représentation du tableau de Docling en un DataFrame pandas. Nous extrayons les légendes et les numéros de page lorsqu'ils sont disponibles.
En plus des tableaux, Docling est capable d'extraire les données d'image réelles des documents. Il s'agit d'une nouvelle fonctionnalité qui va au-delà du simple suivi des positions des images : elle récupère les octets réels de l'image afin que vous puissiez les afficher. (Nous avons activé cette option dans les paramètres du pipeline du processeur de documents.)
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoChaque image est accompagnée d'informations sur sa provenance, notamment son numéro de page et les coordonnées de son cadre. Le cadre de sélection définit la position de l'image sur la page à l'aide des coordonnées gauche, haut, droite et bas.
Lorsque l'extraction d'image est activée, l'objet image dispose d'un attribut image contenant les données d'image réelles. Nous accédons à l'image PIL via picture.image.pil_image, qui renvoie un objet PIL Image que Streamlit peut afficher directement avec st.image(). Le bloc try-except gère les cas où l'extraction d'image échoue ou n'est pas activée, en affichant simplement les métadonnées.
Le visualiseur nécessite une méthode supplémentaire : un résumé de haut niveau qui offre aux utilisateurs une vue d'ensemble de la structure du document :
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}Nous comptons le nombre de pages, d'éléments de texte, de tableaux et d'images dans le document. Le dictionnaire d'text_types s décompose les éléments de texte en fonction de leurs étiquettes, indiquant le nombre de titres, d'en-têtes, de paragraphes et d'autres éléments identifiés par Docling. Cela permet aux utilisateurs de se faire rapidement une idée de la structure et de la complexité du document.
Une fois le visualiseur terminé, intégrons-le à Streamlit avec quatre onglets : Résumé, hiérarchie, tableaux et images.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])Nous créons un menu déroulant pour permettre aux utilisateurs de sélectionner le document à analyser (ceci est utile lorsque plusieurs fichiers sont téléchargés). Après avoir récupéré le document Docling sélectionné à partir de l'état de session, nous instancions le visualiseur et créons quatre onglets pour différentes vues.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")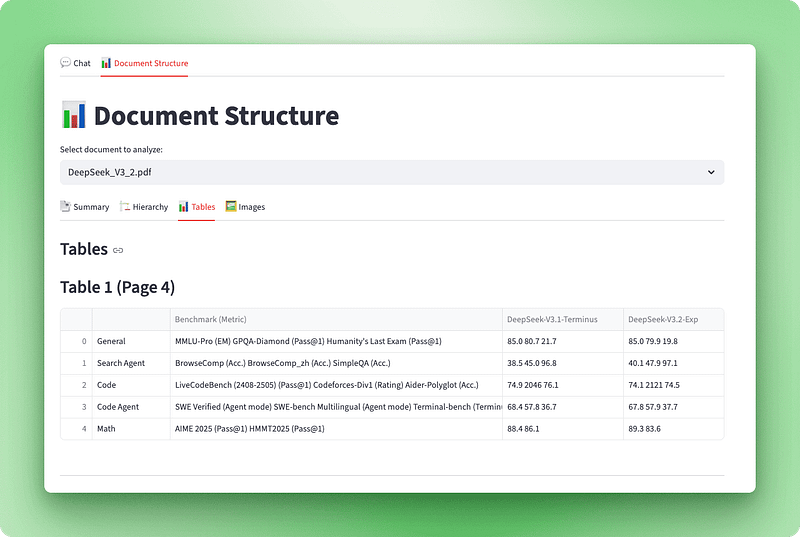
Le visualiseur de structure est désormais achevé. Les utilisateurs peuvent télécharger un document et immédiatement visualiser sa structure : le nombre de pages, de tableaux et d'images qu'il contient, sa structure hiérarchique avec les titres et les sections, les tableaux interactifs qu'ils peuvent explorer et les images réelles extraites du document. Cette transparence aide les utilisateurs à comprendre ce que Docling a extrait et renforce leur confiance dans le système.
Une fois le traitement et la visualisation des documents opérationnels, nous pouvons développer le système RAG qui permet de répondre aux questions posées sur ces documents traités.
📄 Scripts complets : src/vectorstore.py | src/tools.py
Une fois le traitement et la visualisation des documents terminés, nous pouvons développer les fonctionnalités de questions-réponses. La technologie RAG (Retrieval Augmented Generation) permet aux utilisateurs de poser des questions sur leurs documents. Le système convertit les documents en intégrations, les stocke dans une base de données vectorielle et récupère les fragments pertinents pour répondre aux questions.
Cette section traite de deux composants : un gestionnaire de stockage vectoriel qui découpe et intègre des documents, et un outil de recherche qui récupère les informations pertinentes.
Le magasin de vecteurs est l'emplacement où sont stockés les encodages de documents. Lorsque les utilisateurs posent une question, nous recherchons dans cette base de données les éléments pertinents et les transmettons au LLM en tant que contexte.
Veuillez créer le fichier vectorstore.py dans votre répertoire src/:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaCes importations intègrent les composants LangChain pour la gestion des documents, le fractionnement de texte, la génération d'intégrations et le stockage vectoriel ChromaDB. Voici comment ils collaborent :
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)Nous initialisons deux composants clés. Le modèle OpenAI « text-embedding-3-small » convertit le texte en vecteurs. Il est plus compact et plus rapide qu'text-embedding-3-large, ce qui est important lorsque l'on intègre des centaines de fragments. Le format de document de travail ( RecursiveCharacterTextSplitter ) divise les documents en blocs de 1 000 caractères avec un chevauchement de 100 caractères, garantissant ainsi que les informations importantes situées à la limite des blocs ne soient pas coupées au milieu d'une phrase.
1 000 caractères permettent d'équilibrer précision et contexte : des segments plus courts permettent une recherche précise mais perdent le contexte, tandis que des segments plus longs préservent le contexte mais affaiblissent la pertinence.
Veuillez ajouter la méthode de découpage :
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksLe séparateur traite automatiquement les métadonnées, en conservant les informations provenant des documents originaux. Chaque fragment sait de quel fichier il provient, ce qui est important lorsque l'agent cite des sources dans ses réponses.
Veuillez maintenant ajouter la méthode qui crée le magasin vectoriel :
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreChromaDB se charge des tâches complexes. Il intègre chaque segment à l'aide de notre modèle d'intégration et stocke les vecteurs en mémoire. Lorsque vous effectuez une recherche par similarité, ChromaDB calcule la similarité cosinus entre le vecteur de requête et tous les vecteurs de documents, renvoyant les correspondances les plus proches.
Une fois le magasin vectoriel prêt à traiter les intégrations, il est nécessaire de fournir à l'agent un moyen de l'interroger. Les outils sont des fonctions que le LLM peut appeler lorsqu'il a besoin d'informations qu'il ne possède pas.
Veuillez créer le fichier tools.py dans votre répertoire src/:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Cette fonction d'usine utilise un modèle de fermeture : elle reçoit un magasin vectoriel et renvoie un outil permettant d'effectuer des recherches dans celui-ci. Cet outil permet de conserver l'accès au magasin de vecteurs sans nécessiter de variables globales.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""Le décorateur @tool transforme cette fonction en un outil LangChain que l'agent peut appeler. Le type hint Annotated décrit le paramètre, aidant ainsi le LLM à comprendre ce qu'il doit transmettre lors de l'invocation de l'outil.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."Nous récupérons 8 segments similaires (k=8) à partir du magasin vectoriel. Cela fournit au LLM suffisamment de contexte sans le surcharger d'informations redondantes. Le nombre approprié dépend du type de document : les documents techniques contenant des informations denses peuvent être mieux adaptés à un nombre réduit de segments (k = 4-6), tandis que les documents narratifs peuvent bénéficier d'un nombre plus élevé (k = 10-12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)Nous formatons chaque bloc avec son nom de fichier source, puis nous les assemblons à l'aide de séparateurs. Le LLM reçoit ce contexte structuré et l'utilise pour générer des réponses tout en citant ses sources.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsLa gestion des erreurs garantit que l'agent reçoit un message clair en cas d'échec de la recherche, plutôt que de se bloquer. La fonction renvoie l'outil configuré, prêt à être utilisé par l'agent.
Le magasin de vecteurs et l'outil de recherche sont désormais opérationnels. Ensuite, nous allons créer l'agent LangGraph qui coordonne la récupération et la génération afin de répondre aux questions des utilisateurs.
📄 Script complet : src/agent.py
L'outil de recherche peut interroger le magasin vectoriel, mais il nécessite un coordinateur intelligent. L'agent LangGraph détermine quand effectuer une recherche, interprète les résultats et génère des réponses en langage naturel. Nous mettrons également en place un système de streaming afin de montrer les progrès en temps réel.
L'agent reçoit les questions, détermine quand effectuer une recherche dans les documents et génère des réponses en fonction du contexte récupéré.
Veuillez créer le fichier agent.py dans votre répertoire src/:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverNous importons des composants pour la gestion des outils, les modèles de chat d'OpenAI, l'implémentation de l'agent ReAct de LangGraph et la mémoire de conversation.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()Nous utilisons gpt-4o-mini plutôt que gpt-5 car il est plus rapide et plus économique tout en gérant efficacement les questions-réponses relatives aux documents. La température est réglée sur 0 pour obtenir des réponses cohérentes et factuelles. Le module de conversation ( MemorySaver ) permet à l'agent de mémoriser les échanges précédents au cours d'une session.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentcreate_react_agent, de LangGraph, met en œuvre le modèle ReAct (raisonnement + action). L'agent réfléchit à ce qu'il doit faire, agit à l'aide d'outils, observe les résultats et répète le processus jusqu'à ce qu'il obtienne une réponse. Ce modèle convient parfaitement à RAG, car l'agent peut déterminer quand effectuer la recherche et comment utiliser le contexte récupéré.
L'agent peut désormais rechercher et générer des réponses, mais les utilisateurs ne devraient pas avoir à attendre 10 secondes devant un écran vide pendant qu'il fonctionne. Le streaming affiche la progression en temps réel : d'abord, un indicateur « réflexion » apparaît, puis « recherche », puis la réponse s'affiche caractère par caractère.
Veuillez mettre à jour votre fonction render_chat() dans app.py afin de finaliser le traitement des réponses que nous avons précédemment marqué comme TODO :
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Nous ajoutons le message de l'utilisateur à l'historique de la conversation et l'affichons dans l'interface de chat.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}Nous créons des espaces réservés pour l'indicateur d'état et le message de réponse. La configuration comprend un identifiant de fil de discussion que LangGraph utilise pour conserver la mémoire de la conversation d'un tour à l'autre.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseCette fonction génératrice traite la sortie de flux de LangGraph. Nous suivons l'état à l'aide d'indicateurs afin d'afficher les messages d'état appropriés à mesure que l'agent progresse dans son flux de travail.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")Le paramètre « stream_mode="messages" » nous fournit les jetons LLM réels au fur et à mesure de leur génération, et non pas uniquement les résultats finaux. LangGraph émet des événements tout au long de l'exécution de l'agent : lorsqu'il commence à réfléchir, lorsqu'il fait appel à des outils et lorsqu'il génère du texte.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentLorsque le nœud agent commence à générer la réponse finale, nous actualisons le statut et commençons à produire des jetons de contenu. Chaque caractère s'affiche instantanément, ce qui permet une saisie fluide.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Une fois le streaming terminé, nous désactivons l'indicateur d'état. st.write_stream(), développé par Streamlit, gère automatiquement l'affichage token par token, en accumulant les tokens et en mettant à jour l'interface utilisateur de manière fluide. Le résultat est une expérience de chat réactive qui donne aux utilisateurs l'assurance que le système fonctionne correctement.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")Nous conservons la réponse complète à l'historique des messages et traitons toutes les erreurs qui surviennent pendant la diffusion en continu.
Le système RAG est désormais achevé. Les utilisateurs peuvent désormais télécharger des documents, les traiter avec Docling, explorer leur structure et avoir des conversations naturelles sur leur contenu. L'agent effectue des recherches de manière intelligente, cite ses sources et diffuse les réponses en continu pour une expérience fluide.
Votre assistant d'intelligence documentaire est prêt. Avant de déployer ou de partager l'application, il est recommandé de la tester afin de vérifier que tout fonctionne correctement.
Veuillez démarrer l'application à partir de la racine de votre projet :
streamlit run app.pyStreamlit ouvrira une fenêtre de navigateur à l'adresse http://localhost:8501. Vous devriez voir la barre latérale avec les commandes de téléchargement et deux onglets dans la zone principale.
Veuillez télécharger un exemple de document PDF contenant des tableaux et des images afin de tester l'ensemble des capacités de traitement :
Veuillez surveiller les indicateurs de traitement :
Une fois l'opération terminée, vous verrez « ✅ Prêt à discuter ! » dans la section Statut.
Veuillez passer à l'onglet « Structure du document » pour vérifier que Docling a correctement extrait tous les éléments :
Si les tableaux apparaissent vides ou si les images ne s'affichent pas, veuillez vérifier que vous avez activé les options « do_table_structure=True » (Activer les images) et « generate_picture_images=True » (Activer les tableaux) dans les options du pipeline.
Veuillez revenir à l'onglet « Chat » et évaluer l'agent à l'aide des questions suivantes :
Questions pertinentes pour débuter:
Questions spécifiques au document (à adapter en fonction de votre document) :
Questions complémentaires pour évaluer la mémoire conversationnelle :
Recherchez des réponses directes dans votre document avec des citations de sources, des jetons de flux fluides et des indicateurs d'état (« Réfléchit... », « Recherche dans les documents... », « Génère la réponse... »). Veuillez être attentif aux réponses génériques qui ne proviennent pas de votre document, aux citations de sources manquantes, aux réponses lentes sans indicateurs d'état ou aux erreurs concernant les clés API manquantes.
Erreur « Aucun module nommé « docling » »
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
Erreur « Clé API OpenAI introuvable »
Veuillez vérifier que le fichier .env existe avec OPENAI_API_KEY=your-key-here
Veuillez redémarrer Streamlit.
Le traitement prend plus de 60 secondes.
L'agent fournit des réponses générales.
Les tableaux s'affichent sous forme de DataFrames vides.
Veuillez confirmer votre adresse à l'adresse suivante : do_table_structure=True PdfPipelineOptions
Veuillez essayer un autre fichier PDF contenant des tableaux natifs.
L'application est désormais validée et prête à être utilisée. Vous pouvez le tester avec vos propres documents ou le mettre à disposition d'autres personnes.
Vous disposez désormais d'un assistant intelligent pour les documents qui traite les fichiers PDF, Word, PowerPoint et HTML tout en conservant leur structure. Docling extrait le texte, les tableaux, les images et la hiérarchie des documents que les utilisateurs peuvent explorer à l'aide d'onglets interactifs. Le système RAG, associé à ChromaDB et LangGraph, permet des questions-réponses conversationnelles avec des citations de sources diffusées en temps réel. Cela démontre comment le traitement de documents tenant compte de la structure améliore la qualité de la recherche par rapport à l'extraction de texte de base. Le code source complet est disponible sur le référentiel GitHub.
Cette fondation ouvre de multiples perspectives d'extension :
Pour approfondir vos connaissances sur les systèmes RAG et les applications LLM, notre piste Ingénierie IA couvre les concepts et les modèles que vous avez utilisés ici.
Apprenez avec DataCamp
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
