
programa
Desarrollador Python
28 h
Las herramientas tradicionales de extracción de PDF, como pypdf o PDFMiner, proporcionan texto sin formato, pero pierden la estructura del documento. Las tablas se convierten en texto desordenado, los encabezados se mezclan con el contenido del cuerpo y las imágenes desaparecen. En los sistemas RAG, estos datos desordenados se traducen en una recuperación deficiente y respuestas poco fiables. Docling es un kit de herramientas de código abierto de IBM Research que utiliza modelos de visión artificial para comprender el diseño de los documentos, conservando las tablas, las imágenes, los encabezados y la estructura. Procesa documentos hasta 30 veces más rápido que los métodos tradicionales basados en OCR y se ejecuta localmente en tu equipo.
En este tutorial, utilizaremos Docling para crear un asistente de inteligencia documental, una aplicación web Streamlit que te permite cargar documentos, visualizar su estructura y hacer preguntas mediante un chatbot basado en RAG. Aprenderás a procesar documentos multiformato con Docling, extraer y mostrar tablas e imágenes, crear un almacén vectorial con ChromaDB y crear un agente conversacional con LangGraph. Al final, tendrás una aplicación funcional que transforma documentos complejos en datos estructurados y permite responder preguntas de forma inteligente.
Vista previa de la aplicación:
Visualización de la estructura del documento:
Antes de comenzar este tutorial, debes tener:
Habilidades técnicas: Familiaridad con las clases, los decoradores, las sugerencias de tipos y los gestores de contexto de Python. Utilizaremos operaciones asíncronas y patrones de fábrica en todo momento. Es necesario comprender cómo funcionan los modelos de lenguaje grandes con indicaciones, tokens e incrustaciones. Es útil estar familiarizado con los sistemas de generación aumentada por recuperación y las bases de datos vectoriales, pero no es imprescindible: explicaremos los conceptos básicos a medida que avancemos.
Configuración de desarrollo: Python 3.10 o superior con pip para la gestión de paquetes. Se recomienda utilizar un editor de código como VS Code. Necesitarás una clave API de OpenAI de platform.openai.com — el procesamiento cuesta aproximadamente entre 0,10 y 0,20 dólares por documento.
Compromiso de tiempo: Reserva entre 60 y 90 minutos para completar el tutorial, incluyendo la lectura de las explicaciones, la escritura del código y la prueba de la aplicación. Este tutorial requiere conocimientos intermedios de Python.
La mayoría de las herramientas de procesamiento de documentos tratan los archivos PDF como archivos de imagen o secuencias de texto. O bien ejecutan el OCR en cada página o extraen texto sin formato sin comprender lo que están leyendo. Docling adopta un enfoque diferente. Es un kit de herramientas de código abierto de IBM Research que utiliza modelos de visión por computadora para comprender la estructura de los documentos tal como lo haría un ser humano.
Cuando introduces un documento en Docling, dos modelos de IA lo analizan:
Estos modelos entienden que un documento no es solo un montón de texto. Tiene jerarquía, relaciones y significado.
Esta comprensión estructural es importante para los sistemas RAG. Cuando creas aplicaciones de generación aumentada por recuperación, la calidad del procesamiento de tus documentos influye directamente en la precisión de la recuperación. Si la extracción del PDF convierte una tabla financiera en texto desordenado, la búsqueda vectorial recuperará datos sin sentido. Docling conserva la estructura, por lo que cuando divides y embedes tus documentos, trabajas con datos limpios y organizados.
Docling admite múltiples formatos de documentos de forma predeterminada:
También puedes habilitar el OCR para documentos escaneados utilizando motores como EasyOCR, Tesseract o RapidOCR. El kit de herramientas exporta a varios formatos, incluyendo Markdown (ideal para LLM), JSON (para canalizaciones de datos estructurados) y DocTags (un formato que captura elementos complejos como ecuaciones matemáticas y bloques de código).
Más allá de la flexibilidad de formato, Docling ofrece ventajas de rendimiento. El procesamiento tradicional de documentos basado en OCR es lento porque trata cada página como una imagen que necesita reconocimiento de caracteres. Docling omite este paso en los documentos digitales, lo que permite un procesamiento mucho más rápido. Se ejecuta localmente en hardware estándar, por lo que no tienes que pagar costes de API ni enviar documentos confidenciales a servicios de terceros. La velocidad de procesamiento varía en función de la complejidad del documento, el número de páginas y las especificaciones del hardware, con un rendimiento típico que oscila entre menos de un segundo y varios segundos por página en hardware moderno.
IBM ha seguido mejorando las capacidades de Docling. Lanzaron Granite-Docling, un modelo de lenguaje visual de 258 millones de parámetros que destaca por sus diseños complejos y ofrece compatibilidad multilingüe experimental (con el inglés como idioma principal y compatibilidad inicial con el árabe, el chino y el japonés). El kit de herramientas ahora también admite la extracción de imágenes con resolución configurable, que usaremos en nuestra aplicación para mostrar imágenes reales de archivos PDF junto con su contenido de texto.
Para nuestro caso de uso, Docling tiene sentido porque necesitamos datos estructurados, no solo texto sin formato. Si solo necesitas una extracción de texto básica, herramientas más sencillas como pypdf pueden ser suficientes. Pero, dado que estamos creando una aplicación de IA que procesa documentos para su análisis y conversación, el procesamiento consciente de la estructura de Docling es la mejor opción. Es especialmente útil cuando se trabaja con documentos técnicos, artículos de investigación o informes comerciales en los que las tablas y el diseño son importantes.
Antes de comenzar a crear el procesador de documentos, debes configurar la estructura del proyecto e instalar los paquetes necesarios. Esta sección trata sobre la configuración inicial: creación de directorios, instalación de dependencias y configuración de tus claves API.
Comienza creando un nuevo directorio para tu proyecto:
mkdir docling-demo
cd docling-demoDentro de este directorio, crea una carpeta src/ para tus módulos Python:
mkdir src
touch src/__init__.pyEl archivo __init__.py le indica a Python que src/ es un paquete, lo que permite importaciones como from src.document_processor import DocumentProcessor.
La estructura de tu proyecto:
docling-demo/
├── src/
│ └── __init__.pyCrea un archivo requirements.txt en la raíz de tu proyecto:
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2 La restricción numpy<2 existe porque las dependencias de Docling (TensorFlow y Transformers) requieren NumPy 1.x.
Instala los paquetes:
pip install -r requirements.txtLa primera instalación tarda unos minutos, ya que Docling descarga modelos de IA preentrenados (alrededor de 500 MB). Estos modelos se encargan del análisis del diseño y el reconocimiento de la estructura de las tablas. Se almacenan en caché localmente, por lo que las ejecuciones posteriores son más rápidas.
Crea un archivo .env para almacenar tu clave API de OpenAI:
OPENAI_API_KEY=your-openai-api-key-hereObtén tu clave API en platform.openai.com. Lo necesitarás para las integraciones y el agente de chat.
Crea una plantilla .env.example:
OPENAI_API_KEY=your-openai-api-key-hereAñade un método ` .gitignore ` para evitar el envío de datos confidenciales:
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Crea un archivo app.py en la raíz de tu proyecto. Crearemos este archivo gradualmente a lo largo del tutorial. Por ahora, añade las importaciones y la configuración básicas:
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Prueba tu configuración:
streamlit run app.pyStreamlit abre una ventana del navegador en http://localhost:8501 que muestra tu página básica.
Tu estructura final del proyecto (antes de añadir nuevos scripts en las próximas secciones):
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyUna vez preparado el entorno, podemos crear el procesador de documentos que utiliza Docling para extraer la estructura de los archivos cargados.
Nota: Las secciones siguientes desglosarán los scripts de la aplicación en fragmentos. Por lo tanto, para ver el panorama completo y seguirlo fácilmente, recomendamos abrir el repositorio GitHub de este proyecto en una pestaña separada.
📄 Script completo: src/document_processor.py
El procesador de documentos es donde Docling realiza su trabajo. Este componente toma los archivos cargados y los transforma en datos estructurados que podemos utilizar tanto para RAG como para visualización. Necesitamos dos resultados de este proceso: texto Markdown limpio para el almacén vectorial y el objeto de documento Docling original que conserve toda la información estructural, como tablas e imágenes.
Vamos a crear esto creando un nuevo archivo llamado document_processor.py en tu directorio src/. Crearemos una clase DocumentProcessor que configure el canal de procesamiento de Docling y gestione las cargas de archivos.
Docling te permite controlar cómo procesa los documentos mediante opciones de canalización. En el caso de los archivos PDF, puedes activar el OCR para documentos escaneados, activar el reconocimiento de estructuras de tablas y extraer imágenes:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
Creamos un objeto PdfPipelineOptions para configurar cómo Docling procesa los archivos PDF. Cada opción controla una capacidad de procesamiento específica: do_ocr habilita el reconocimiento óptico de caracteres para documentos escaneados, do_table_structure activa la detección y el análisis de tablas, generate_picture_images indica a Docling que extraiga las imágenes incrustadas como objetos PIL, y images_scale establece el multiplicador de resolución para las imágenes extraídas.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)DocumentConverter es el motor de procesamiento principal de Docling. Lo inicializamos con nuestras opciones de canalización PDF envueltas en un objeto PdfFormatOption, que asocia estos ajustes con archivos de entrada PDF específicos.
Veamos qué hace cada opción de canalización. La bandera do_ocr activa el reconocimiento óptico de caracteres. Al procesar archivos PDF digitales con capas de texto incrustadas, Docling omite automáticamente el OCR para ahorrar tiempo. Para documentos escaneados o imágenes que contienen texto, esta configuración indica a Docling que ejecute modelos de visión para extraer el texto.
La opción ` do_table_structure ` permite el reconocimiento de la estructura de la tabla. Sin esto, las tablas se extraen como texto sin formato y se pierde el formato. Cuando está habilitado, Docling utiliza su modelo de IA TableFormer para identificar filas, columnas, encabezados y relaciones entre celdas. Esta representación estructurada te permite exportar tablas como DataFrames de pandas más adelante, conservando el formato tabular.
Al configurar generate_picture_images en True, se habilita la extracción de imágenes. De forma predeterminada, Docling solo registra las ubicaciones de las imágenes sin extraer las imágenes reales. Al habilitar esta opción, obtendrás objetos de imagen PIL que podrás mostrar en tu interfaz de usuario o procesar con modelos de visión. El parámetro « images_scale » (Resolución de extracción) controla la resolución de extracción: un valor de 2,0 duplica la resolución para obtener una mejor calidad al mostrar imágenes o realizar análisis adicionales.
Una vez configurada la canalización, podemos añadir el método que procesa los archivos cargados a través de Streamlit. Este método gestiona los objetos de archivo de Streamlit, los guarda temporalmente, ejecuta la conversión de Docling y devuelve tanto el marcado para RAG como los documentos Docling para su visualización:
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
Streamlit proporciona los archivos cargados como objetos de archivo en memoria, pero Docling necesita archivos reales en el disco para procesarlos. Creamos un directorio temporal y escribimos cada archivo subido en él, conservando el nombre de archivo original.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()La llamada converter.convert() ejecuta el proceso completo de análisis de documentos de Docling. Identifica el diseño del documento, aplica OCR si es necesario, detecta tablas e imágenes y crea una representación estructurada. El procesamiento tardará entre 20 y 30 segundos sin extracción de imágenes, o entre 40 y 60 segundos con las imágenes activadas.
Una vez completada la conversión, exportamos al formato Markdown, que genera un texto limpio y compatible con LLM, conservando el formato adecuado: los encabezados siguen siendo encabezados, las listas mantienen su estructura y las tablas se convierten en tablas Markdown.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})Creamos dos representaciones de cada documento procesado. El objeto LangChain Document contiene el texto marcado como page_content con metadatos asociados, que se envían al almacén vectorial para RAG. El objeto de documento Docling original se almacena por separado con su nombre de archivo, conservando toda la información estructural (tablas, imágenes, jerarquía) para su posterior visualización.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
El bloque ` finally ` garantiza que los archivos temporales se limpien independientemente de si el procesamiento se realiza correctamente o falla. Devolvemos una tupla que contiene ambas representaciones del documento: Documentos LangChain para el sistema RAG y documentos Docling para la visualización de estructuras.
El procesador de documentos ya está listo. A continuación, crearemos la interfaz Streamlit que permite a los usuarios cargar archivos y ver el estado del procesamiento.
📄 Guion completo: src/structure_visualizer.py
Ahora que podemos procesar documentos con Docling, necesitamos una forma de visualizar lo que se ha extraído. El objeto documento Docling sin procesar contiene abundante información estructural (encabezados, tablas, imágenes y metadatos), pero no es fácil de usar en su formato original. Crearemos una capa de visualización que transforme estos datos en una interfaz interactiva con cuatro vistas: un panel de resumen, un esquema jerárquico, tablas interactivas e imágenes extraídas.
Crea un nuevo archivo llamado structure_visualizer.py en tu directorio src/. Este componente analizará la estructura del documento de Docling y lo organizará para su visualización.
Comienza creando una clase que envuelva un documento Docling y proporcione métodos para extraer diferentes elementos estructurales:
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
El inicializador toma un objeto DoclingDocument (el mismo objeto devuelto por DocumentConverter.convert()). Este objeto contiene todo lo que Docling ha extraído del documento. El atributo texts contiene todos los elementos de texto con sus etiquetas y posiciones, tables contiene datos de tablas con información sobre la estructura, pictures almacena metadatos de imágenes y datos de imágenes reales, y pages proporciona información a nivel de página.
Los documentos tienen una estructura que va más allá de los párrafos. Los encabezados crean una jerarquía que ayuda a los lectores a navegar por el contenido. A continuación, se explica cómo extraer esta jerarquía:
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyRepetimos todos los elementos de texto del documento, filtrando aquellos cuyas etiquetas contengan header. Cada elemento de texto tiene un atributo « label » (tipo de texto) que Docling asigna durante el análisis del diseño. Las etiquetas más comunes son section_header, page_header, title y la habitual text. El atributo prov (abreviatura de proveniencia) contiene información de posicionamiento, incluida la página en la que aparece el elemento. Extraemos el texto del encabezado, su número de página y deducimos su nivel jerárquico a partir del tipo de etiqueta.
Al mostrar el esquema, el nivel del encabezado determina la sangría. Un método auxiliar asigna tipos de etiquetas a niveles numéricos:
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Esto crea una jerarquía en la que los títulos de los documentos son de nivel 1, los encabezados de sección son de nivel 2, las subsecciones son de nivel 3 y cualquier otro encabezado es por defecto de nivel 4.
Una vez extraída la jerarquía de documentos, pasemos a las tablas. A diferencia de la simple extracción de texto, que convierte las tablas en cadenas desordenadas, Docling conserva su estructura como una de sus características más valiosas:
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoEl método ` table.export_to_dataframe(doc=self.doc) ` convierte la representación de tabla de Docling en un DataFrame de pandas. Extraemos los subtítulos y los números de página cuando están disponibles.
Además de las tablas, Docling puede extraer datos de imágenes reales de documentos. Esta es una función más reciente que va más allá del simple programa de las posiciones de las imágenes: recupera los bytes reales de la imagen para que puedas mostrarlos. (Hemos habilitado esta opción en las opciones de canalización del procesador de documentos).
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoCada imagen tiene información sobre su procedencia, incluyendo su número de página y las coordenadas del cuadro delimitador. El cuadro delimitador define la posición de la imagen en la página utilizando las coordenadas izquierda, superior, derecha e inferior.
Cuando la extracción de imágenes está habilitada, el objeto imagen tiene un atributo image que contiene los datos reales de la imagen. Accedemos a la imagen PIL a través de picture.image.pil_image, que devuelve un objeto PIL Image que Streamlit puede mostrar directamente con st.image(). El bloque try-except gestiona los casos en los que la extracción de imágenes falla o no está habilitada, recurriendo elegantemente a mostrar solo los metadatos.
El visualizador necesita un método más: un resumen de alto nivel que ofrezca a los usuarios una visión general de la estructura del documento:
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}Contamos el número de páginas, elementos de texto, tablas e imágenes del documento. El diccionario « text_types » desglosa los elementos del texto por sus etiquetas, mostrando cuántos títulos, encabezados, párrafos y otros elementos ha identificado Docling. Esto permite a los usuarios hacerse una idea rápida de la estructura y complejidad del documento.
Una vez completado el visualizador, vamos a integrarlo en Streamlit con cuatro pestañas: Resumen, jerarquía, tablas e imágenes.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])Creamos un menú desplegable para que los usuarios seleccionen qué documento analizar (útil cuando se cargan varios archivos). Después de obtener el documento Docling seleccionado del estado de la sesión, instanciamos el visualizador y creamos cuatro pestañas para diferentes vistas.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")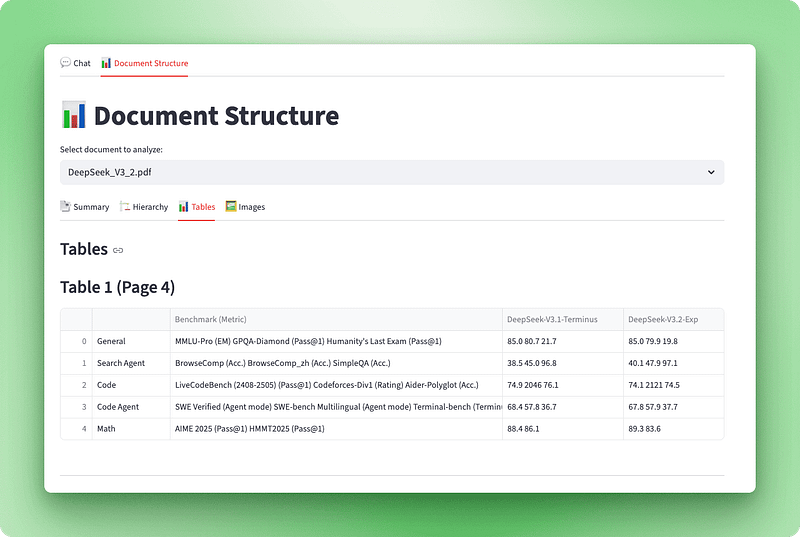
El visualizador de estructuras está completo. Los usuarios pueden cargar un documento y ver inmediatamente su anatomía: cuántas páginas, tablas e imágenes contiene, su estructura jerárquica con encabezados y secciones, tablas interactivas que pueden explorar y las imágenes reales extraídas del documento. Esta transparencia ayuda a los usuarios a comprender lo que Docling ha extraído y genera confianza en el sistema.
Una vez que el procesamiento y la visualización de documentos funcionan, podemos crear el sistema RAG que permite responder preguntas sobre estos documentos procesados.
📄 Scripts completos: src/vectorstore.py | src/tools.py
Una vez completado el procesamiento y la visualización de documentos, podemos desarrollar las capacidades de preguntas y respuestas. RAG (Retrieval Augmented Generation) permite a los usuarios hacer preguntas sobre sus documentos. El sistema convierte los documentos en incrustaciones, los almacena en una base de datos vectorial y recupera fragmentos relevantes para responder a las preguntas.
Esta sección abarca dos componentes: un gestor de almacenamiento vectorial que fragmenta e incrusta documentos, y una herramienta de búsqueda que recupera información relevante.
El almacén de vectores es donde se guardan las incrustaciones de documentos. Cuando los usuarios hacen una pregunta, buscamos fragmentos relevantes en este almacén y los enviamos al LLM como contexto.
Crea vectorstore.py en tu directorio src/:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaEstas importaciones incorporan componentes LangChain para el manejo de documentos, la división de texto, la generación de incrustaciones y el almacenamiento vectorial ChromaDB. Así es como funcionan juntos:
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)Inicializamos dos componentes clave. El modelo OpenAI « text-embedding-3-small » convierte texto en vectores. Es más pequeño y rápido que text-embedding-3-large, lo cual es importante cuando se incrustan cientos de fragmentos. El algoritmo de fragmentación de documentos ( RecursiveCharacterTextSplitter ) divide los documentos en fragmentos de 1000 caracteres con un solapamiento de 100 caracteres, lo que garantiza que la información importante situada en los límites de los fragmentos no se corte a mitad de una frase.
1000 caracteres equilibran precisión y contexto: los fragmentos más pequeños permiten una recuperación precisa, pero pierden contexto, mientras que los fragmentos más grandes conservan el contexto, pero diluyen la relevancia.
Añade el método chunking:
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksEl divisor gestiona los metadatos automáticamente, conservando la información de los documentos originales. Cada fragmento sabe de qué archivo procede, lo cual es importante cuando el agente cita fuentes en sus respuestas.
Ahora añade el método que crea el almacén vectorial:
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreChromaDB se encarga del trabajo pesado. Incrustas cada fragmento utilizando nuestro modelo de incrustaciones y almacenas los vectores en la memoria. Cuando realizas una búsqueda por similitud, ChromaDB calcula la similitud coseno entre el vector de consulta y todos los vectores de documentos, y devuelve los resultados más cercanos.
Con el almacén vectorial listo para gestionar incrustaciones, necesitamos proporcionar al agente una forma de consultarlo. Las herramientas son funciones que el LLM puede invocar cuando necesita información que no tiene.
Crea tools.py en tu directorio src/:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Esta función de fábrica utiliza un patrón de cierre: recibe un almacén vectorial y devuelve una herramienta que puede buscar en él. La herramienta mantiene el acceso al almacén de vectores sin necesidad de variables globales.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""El decorador ` @tool ` convierte esta función en una herramienta LangChain que el agente puede invocar. La sugerencia de tipo Annotated describe el parámetro, lo que ayuda al LLM a comprender qué pasar al invocar la herramienta.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."Recuperamos 8 fragmentos similares (k=8) del almacén de vectores. Esto proporciona al LLM suficiente contexto sin sobrecargarlo con información redundante. El número adecuado depende del tipo de documento: los documentos técnicos con información densa pueden funcionar mejor con menos fragmentos (k=4-6), mientras que los documentos narrativos pueden beneficiarse de un número mayor (k=10-12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)Formateamos cada fragmento con su nombre de archivo de origen y luego los unimos con separadores. El LLM recibe este contexto estructurado y lo utiliza para generar respuestas mientras cita las fuentes.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsEl manejo de errores garantiza que el agente reciba un mensaje claro si la búsqueda falla, en lugar de bloquearse. La función devuelve la herramienta configurada lista para que el agente la utilice.
La herramienta de almacenamiento y búsqueda de vectores ya está lista. A continuación, crearemos el agente LangGraph que coordina la recuperación y la generación para responder a las preguntas de los usuarios.
📄 Script completo: src/agent.py
La herramienta de búsqueda puede consultar el almacén vectorial, pero necesita un coordinador inteligente. El agente LangGraph decide cuándo realizar la búsqueda, interpreta los resultados y genera respuestas en lenguaje natural. También implementaremos la transmisión en directo para mostrar el progreso en tiempo real.
El agente recibe preguntas, decide cuándo buscar documentos y genera respuestas basadas en el contexto recuperado.
Crea agent.py en tu directorio src/:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverImportamos componentes para el manejo de herramientas, los modelos de chat de OpenAI, la implementación del agente ReAct de LangGraph y la memoria de conversación.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()Utilizamos gpt-4o-mini en lugar de gpt-5 porque es más rápido y económico, y además gestiona bien las preguntas y respuestas sobre documentos. La temperatura se establece en 0 para obtener respuestas coherentes y objetivas. MemorySaver proporciona memoria de conversación al agente, de modo que recuerda los intercambios anteriores dentro de una sesión.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentcreate_react_agent, de LangGraph, implementa el patrón ReAct (razonamiento + acción). El agente razona sobre lo que debe hacer, actúa utilizando herramientas, observa los resultados y repite el proceso hasta obtener una respuesta. Este patrón funciona bien para RAG porque el agente puede decidir cuándo buscar y cómo utilizar el contexto recuperado.
El agente ahora puede buscar y generar respuestas, pero los usuarios no deberían tener que esperar 10 segundos mirando una pantalla en blanco mientras trabaja. El streaming muestra el progreso en tiempo real: primero aparece un indicador de «pensando», luego «buscando» y, por último, la respuesta aparece carácter a carácter.
Actualiza la función ` render_chat() ` en ` app.py ` para completar el manejo de respuestas que marcamos anteriormente con TODO:
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Añadimos el mensaje del usuario al historial de la conversación y lo mostramos en la interfaz del chat.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}Creamos marcadores de posición para el indicador de estado y el mensaje de respuesta. La configuración incluye un identificador de hilo que LangGraph utiliza para mantener la memoria de la conversación entre turnos.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseEsta función generadora procesa la salida de flujo de LangGraph. Realizamos un seguimiento del estado con indicadores para mostrar los mensajes de estado adecuados a medida que el agente avanza en su flujo de trabajo.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")El parámetro « stream_mode="messages" » nos proporciona tokens LLM reales a medida que se generan, no solo los resultados finales. LangGraph emite eventos durante toda la ejecución del agente: cuando empieza a pensar, cuando llama a herramientas y cuando genera texto.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentCuando el nodo agente comienza a generar la respuesta final, actualizamos el estado y comenzamos a producir tokens de contenido. Cada token se muestra inmediatamente, lo que crea un efecto de escritura fluido.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Una vez completada la transmisión, borramos el indicador de estado. st.write_stream(), de Streamlit, se encarga automáticamente de mostrar los tokens uno por uno, acumulándolos y actualizando la interfaz de usuario con fluidez. El resultado es una experiencia de chat que responde rápidamente y da a los usuarios la confianza de que el sistema funciona.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")Guardamos la respuesta completa al historial de mensajes y gestionamos cualquier error que se produzca durante la transmisión.
El sistema RAG está completo. Ahora los usuarios pueden subir documentos, procesarlos con Docling, explorar su estructura y mantener conversaciones naturales sobre el contenido. El agente realiza búsquedas inteligentes, cita fuentes y transmite respuestas para ofrecer una experiencia fluida.
Tu asistente de inteligencia documental está listo. Antes de implementarla o compartirla, debes probar la aplicación para verificar que todo funcione correctamente.
Inicia la aplicación desde la raíz de tu proyecto:
streamlit run app.pyStreamlit abrirá una ventana del navegador en http://localhost:8501. Deberías ver la barra lateral con los controles de carga y dos pestañas en el área principal.
Sube un documento PDF de muestra con tablas e imágenes para probar todas las capacidades de procesamiento:
Observa los indicadores de procesamiento:
Cuando hayas terminado, verás «✅ ¡Listo para chatear!» en la sección de estado.
Cambia a la pestaña «Estructura del documento» para verificar que Docling ha extraído todo correctamente:
Si las tablas aparecen vacías o las imágenes no se muestran, comprueba que has habilitado do_table_structure=True y generate_picture_images=True en las opciones de canalización.
Vuelve a la pestaña «Chat» y prueba al agente con estas preguntas de ejemplo:
Buenas preguntas iniciales:
Preguntas específicas sobre el documento (adapta en función de tu documento):
Preguntas de seguimiento para evaluar la memoria conversacional:
Busca respuestas directas en tu documento con citas de fuentes, tokens de transmisión fluida e indicadores de estado («Pensando...», «Buscando documentos...», «Generando respuesta...»). Ten cuidado con las respuestas genéricas que no provienen de tu documento, las citas de fuentes que faltan, las respuestas lentas sin indicadores de estado o los errores sobre claves API que faltan.
Error «No existe ningún módulo llamado 'docling'».
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
Error «No se ha encontrado la clave API de OpenAI»
Verifica que exista el archivo .env con OPENAI_API_KEY=your-key-here
Reiniciar Streamlit
El procesamiento tarda más de 60 segundos.
El agente da respuestas genéricas.
Las tablas se muestran como DataFrame vacíos.
Confirmar do_table_structure=True en PdfPipelineOptions
Prueba con otro PDF con tablas nativas.
La aplicación ya está validada y lista para su uso. Puedes probarlo con tus propios documentos o implementarlo para que otros lo utilicen.
Ahora tienes un asistente de inteligencia documental que procesa archivos PDF, documentos de Word, presentaciones de PowerPoint y archivos HTML conservando su estructura. Docling extrae texto, tablas, imágenes y la jerarquía de los documentos, que los usuarios pueden explorar a través de pestañas interactivas. El sistema RAG, combinado con ChromaDB y LangGraph, permite realizar preguntas y respuestas conversacionales con citas de fuentes transmitidas en tiempo real. Esto demuestra cómo el procesamiento de documentos consciente de la estructura mejora la calidad de la recuperación en comparación con la extracción de texto básica. El código fuente completo está disponible en el repositorio GitHub.
Esta base abre múltiples direcciones para la ampliación:
Para una exploración más profunda de los sistemas RAG y las aplicaciones LLM, nuestro ingeniería de IA El programa cubre los conceptos y patrones que has utilizado aquí.
Aprende con DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Matt Crabtree
13 min
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Nadia mhadhbi
Tutorial
Josep Ferrer

